

-
摘要:
针对深度神经网络模型学习照应语和候选先行语的语义信息忽略了每一个词在句中重要程度, 且无法关注词序列连续性关联和依赖关系等问题, 提出一种结合语境多注意力独立循环神经网络(Contextual multi-attention independently recurrent neural network, CMAIR) 的维吾尔语人称代词指代消解方法. 相比于仅依赖照应语和候选先行语语义信息的深度神经网络, 该方法可以分析上下文语境, 挖掘词序列依赖关系, 提高特征表达能力. 同时, 该方法结合多注意力机制, 关注待消解对多层面语义特征, 弥补了仅依赖内容层面特征的不足, 有效识别人称代词与实体指代关系. 该模型在维吾尔语人称代词指代消解任务中的准确率为90.79 %, 召回率为83.25 %, F值为86.86 %. 实验结果表明, CMAIR模型能显著提升维吾尔语指代消解性能.
Abstract:The deep neural network model learns the semantic information of anaphora and candidate antecedent, ignores the importance of each word in the sentence, and cannot pay attention to the continuous association and dependence of the word sequence. This paper proposes a Uyghur personal pronoun anaphora resolution method based on contextual multi-attention independent recurrent neural network (CMAIR). Compared with deep neural networks that rely only on the semantic information of anaphora and candidate antecedent, this method can analyze context relations, mine word sequence dependencies, and improve feature expression ability. At the same time, this method combines the multiattention mechanism, pays attention to the multi-layer semantic features to be resolved, efiectively compensates for the lack of content-level features, and efiectively recognizes the relationship between personal pronouns and entities. The precision rate of this method in the Uyghur personal pronoun anaphora resolution task is 90.79 %, the recall rate is 83.25 %, and the F value is 86.86 %. The experimental results show that the CMAIR model can signiflcantly improve the performance of Uyghur personal pronoun anaphora resolution.
-
Key words:
- Attention mechanism /
- context /
- independently recurrent neural network /
- anaphora resolution
1) 本文责任编委 张民 -

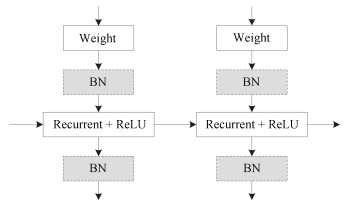
图 3 多注意力机制IndRNN模型框架图
Fig. 3 IndRNN model framework with multiple attention mechanisms
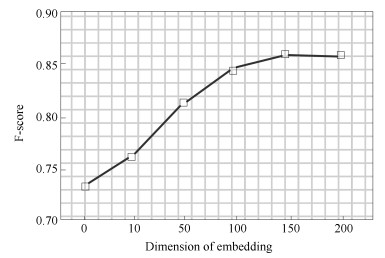
图 5 不同维度词向量分类F-score比较
Fig. 5 Comparison of difierent dimension word vector classiflcation F-score
表 1 词语句中成分标注
Table 1 Component labeling of words in sentences

表 2 词性标注
Table 2 Part of speech tagger

表 3 hand-crafted特征
Table 3 The feature of hand-crafted
照应语词性 词性一致 单复数一致 性别一致 先行语语义角色 照应语语义角色 存在嵌套 人称代词 非人称代词 是 否 是 否 是 否 未知 施事者 受事者 无 施事者 受事者 无 是 否 1 0 1 0 1 0 1 0 0.5 1 0.5 0 1 0.5 0 0 1  下载: 导出CSV
下载: 导出CSV
表 4 实验参数设置
Table 4 Hyper parameters of experiment
Parameter Parameter description Value t Training epochs 50 b Batch 100 d Dropout rate 0.5 l IndRNN layers 3 k Kernel Size 3
下载: 导出CSV
表 5 与以往研究对比(%)
Table 5 Compared with previous studies (%)
Model P R F Tian 82.33 72.07 76.86 Li 88 80 83.81 CMAIR 90.79 83.25 86.86
下载: 导出CSV
表 6 不同模型消解性能对比(%)
Table 6 Comparison of different model anaphora resolution performance (%)
Model P R F CNN 75.47 74.16 74.81 ATT-CNN-1 80.14 77.46 78.78 ATT-CNN-2 82.37 78.80 80.55 ATT-CNN-3 83.02 79.61 81.27
下载: 导出CSV
表 7 不同特征类型对指代消解性能影响(%)
Table 7 The effect of different feature types on the anaphora resolution (%)
特征类型 P R F Vattention + Vcontext 83.29 79.43 81.31 Vhand-crafted + Vattention 86.81 80.24 83.40 CMAIR 90.79 83.25 86.86
下载: 导出CSV
-
[1] Zelenko D, Aone C, Tibbetts J. Coreference resolution for information extraction. In: Proceedings of the 2004 ACL Workshop on Reference Resolution and its Applications. Barcelona, Spain: ACL, 2004. 9-16 [2] Deemter K V, Kibble R. On coreferring: Coreference in muc and related annotation schemes. Computational Linguistics, 2000, 26(4): 629-637 doi: 10.1162/089120100750105966 [3] Kim Y. Convolutional neural networks for sentence classification. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 1746-1751 [4] Irsoy O, Cardie C. Opinion mining with deep recurrent neural networks. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 720-728 [5] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Beijing, China: ACL, 2015. 1556-1566 [6] Chen C, Ng V. Chinese zero pronoun resolution with deep neural networks. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016. 778-788 [7] Chen C, Ng V. Deep reinforcement learning for mention-ranking coreference models. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Texas, USA: ACL, 2016. 2256-2262 [8] Iida R, Torisawa K, Oh J H. Intra-sentential subject zero anaphora resolution using multi-column convolutional neural network. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Texas, USA: ACL, 2016. 1244-1254 [9] Mnih V, Heess N, Graves A. Recurrent models of visual attention. In: Proceedings of the Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2204-2212 [10] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[Online], available: https://arxiv.org/pdf/1409.0473v6.pdf, December 27, 2018 [11] Yin W, Sch\"{u}tze H, Xiang B, Zhou B. Abcnn: Attention-based convolutional neural network for modeling sentence pairs. In: Proceedings of the 2016 Transactions of the Association for Computational Linguistics. Texas, USA: ACL, 2016. 259-272 [12] Wang Y, Huang M, Zhao L. Attention-based lstm for aspect-level sentiment classification. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Texas, USA: ACL, 2016. 606-615 [13] Soon W M, Ng H T, Lim D C Y. On coreferring: A machine learning approach to coreference resolution of noun phrases. Computational Linguistics, 2001, 27(4): 521-544 doi: 10.1162/089120101753342653 [14] Ng V, Cardie C. Improving machine learning approaches to coreference resolution. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Pennsylvania, USA: ACL, 2002. 104-111 [15] Yang X, Zhou G, Su J, Tan C L. Coreference resolution using competition learning approach. In: Proceedings of the 41th Annual Meeting on Association for Computational Linguistics. Sapporo, Japan: ACL, 2003. 176-183 [16] Chen C, Ng V. Chinese zero pronoun resolution: an unsupervised approach combining ranking and integer linear programming. Springer Verlag, 2014, 36(5): 823-834 doi: 10.5555/2892753.2892778 [17] Clark K, Manning C D. Deep reinforcement learning for mention-ranking coreference models[Online], available: https://arxiv.org/pdf/1609.08667.pdf, December 27, 2018 [18] Yin Q, Zhang Y, Zhang W, Liu T. Chinese zero pronoun resolution with deep memory network. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Texas, USA: ACL, 2016. 606-615 [19] 李敏, 禹龙, 田生伟, 吐尔根·依布拉音, 赵建国. 基于深度学习的维吾尔语名词短语指代消解. 自动化学报, 2017, 43(11): 1984-1992 doi: 10.16383/j.aas.2017.c160330Li Min, Yu Long, Tian Sheng-Wei, Turglm Ibrahim, Zhao Jian-Guo. Coreference resolution of uyghur noun phrases based on deep learning. Acta Automatica Sinica, 2017, 43(11): 1984-1992 doi: 10.16383/j.aas.2017.c160330 [20] 田生伟, 秦越, 禹龙, 吐尔根·依布拉音, 冯冠军. 基于Bi-LSTM的维吾尔语人称代词指代消解. 电子学报, 2018, 46(7): 1691-1699 doi: 10.3969/j.issn.0372-2112.2018.07.022Tian Sheng-Wei, Qin Yue, Yu Long, Turglm Ibrahim, Feng Guan-Jun. Anaphora resolution of uyghur personal pronouns based on Bi-LSTM. Acta Electronica Sinica, 2018, 46(7): 1691-1699 doi: 10.3969/j.issn.0372-2112.2018.07.022 [21] 李冬白, 田生伟, 禹龙, 吐尔根·依布拉音, 冯冠军. 基于深度学习的维吾尔语人称代词指代消解. 中文信息学报, 2017, 31(4): 80-88 https://www.cnki.com.cn/Article/CJFDTOTAL-MESS201704012.htmLi Dong-Bai, Tian Sheng-Wei, Yu Long, Turglm Ibrahim, Feng Guan-Jun. Deep learning for pronominal anaphora resolution in uyghur. Journal of Chinese Information Processing, 2017, 31(4): 80-88 https://www.cnki.com.cn/Article/CJFDTOTAL-MESS201704012.htm [22] Li S, Li W, Cook C, Zhu C, Gao Y. Independently recurrent neural network (indrnn): Building A longer and deeper rnn. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Utah, USA: IEEE, 2018. 5457-5466 [23] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space[Online], available: https://arxiv.org/pdf/1301.3781.pdf, December 27, 2018 [24] Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 2011, 12(7): 2121-2159 http://web.stanford.edu/~jduchi/projects/DuchiHaSi10.html [25] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors[Online], available: https://arxiv.org/pdf/1207.0580.pdf, December 27, 2018 -

 下载:
下载:



计量
- 文章访问数: 1276
- HTML全文浏览量: 376
- PDF下载量: 145
- 被引次数: 0
