

-
摘要: 深度卷积生成式对抗网络(Deep convolutional generative adversarial networks, DCGANs) 是一种改进的生成式对抗网络, 尽管生成图像效果比传统GANs有较大提升, 但在训练方法上依然存在改进的空间. 本文提出了一种基于训练图像子样本集构建的DCGANs训练方法. 推导给出了DCGANs的生成样本、子样本与总体样本的统计分布关系, 结果表明子样本集分布越趋近于总体样本集, 则生成样本集也越接近总体样本集. 设计了基于样本一阶颜色矩和清晰度的特征空间的子样本集构建方法, 通过改进的按概率抽样方法使得构建的子样本集之间近似独立同分布并且趋近于总体样本集分布. 为验证本文方法效果, 利用卡通人脸图像和Cifar10图像集, 对比分析本文构建子样本集与随机选取样本的DCGANs训练方法以及其他训练策略实验结果. 结果表明, 在Batchsize约为2 000的条件下, 测试误差、KL距离、起始分数指标有所提高, 从而得到更好的生成图像.
-
关键词:
- 深度卷积生成式对抗网络 /
- 子样本集构建 /
- 深度学习 /
- 样本特征 /
- 联合概率密度
Abstract: Deep convolutional generative adversarial networks (DCGANs) is an improved generative adversarial networks (GANs). There are some improvements in training method although the efiect of generated images are better than traditional GANs. This work proposes a DCGANs training method based on training image subsample set construction. The statistical distribution relations of DCGANs generated samples, subsamples and all samples are derived. The results show that the distributions of subsample sets are closer to the whole sample set, and the generated sample set is closer to the whole sample set. And then, a subsample set construction method is designed based on sample flrst order color moment and sharpness feature space. These subsample sets are approximately independent identically distributed each other and similar to the whole sample set distribution by improved probability sampling method. To validate the efiectiveness of this method, cartoon face image set and Cifar10 image set are used, the experimental results of DCGANs training method based on subsample set construction and random selection and other training strategies are compared and analyzed. The results show that under the condition that Batchsize is about 2 000, the test error, KL divergence, inception score are improved, so that better images could be generated.-
Key words:
- Deep convolutional generative adversarial networks (DCGANs) /
- subsample set construction /
- deep learning /
- sample feature /
- joint probability density
-
水面无人艇是一种无需人工操作的自主水面舰艇, 具有自主性强、成本低、灵活性高等优势. 它可以在危险或人类难以进入的水域执行任务, 广泛应用于民用和军事领域. 例如, 在环境监测、渔业管理、海上搜救、物流运输、通信中继、侦察监视及巡逻防御等方面发挥重要作用[1-6]. 然而, 由于单个无人艇的执行能力有限, 往往难以胜任复杂水域任务. 在此背景下, 多无人艇(Multiple unmanned surface vehicle, Multi-USV)协同作业正逐渐成为未来的发展趋势. 在协同作业中, 多艘无人艇通过协同工作, 共同完成复杂水域任务, 如大范围的海洋协同监测、搜索与救援、水下地形协同测绘和水下目标协同探测等. 值得注意的是, 在某些实际应用场景中, 通过引入无人艇之间的竞争交互机制, 可以有效提升多无人艇协同作业的能力[7-8]. 在这种情形下, 底层信息交互拓扑图往往被建模为符号图. 特别地, 二分编队跟踪控制是符号图下多无人艇系统编队控制领域的基础研究课题之一, 旨在设计一组分布式控制协议, 使得多无人艇系统能够以预设的二分编队构型跟踪参考轨迹[8].
在多无人艇系统编队控制领域, 基于反推控制方法的研究成果丰硕[5, 9-12]. 反推控制是一种基于Lyapunov 理论的递归控制方案设计方法, 自20世纪90年代起便受到系统与控制领域学者们的广泛关注[13-15]. 该方法通过将高阶非线性系统拆分为多个较为简单的低阶系统, 并引入虚拟控制器和参数自适应更新律, 以确保闭环系统的稳定性, 从而逐步推导出实际控制器[14]. 然而, 反推控制方法在控制器设计过程中通常需要使用参考轨迹的高阶导数, 并对系统动力学模型的要求较高. 为了克服这些挑战, 文献[16] 引入命令滤波技术, 避免对虚拟控制器求导, 显著降低了计算负担, 简化了控制律的设计和形式, 从而使得该方法能够适用于更广泛的非线性系统. 然而, 基于命令滤波反推方法的多无人艇系统二分编队跟踪控制的研究目前见诸文献的结果还相对较少.
如文献[17-18] 所述, 无人艇在执行实际任务时, 往往会受到风、浪、水流等环境因素的干扰, 这些因素可能导致无人艇的运行不稳定甚至引发事故. 为了增强控制系统的稳定性和鲁棒性, 考虑模型不确定性变得尤为重要. 在处理具有模型不确定性的非线性系统控制问题时, 确保参数收敛性是一个核心环节, 因为它能够提升闭环系统的整体稳定性和鲁棒性. 传统基于梯度下降法的参数自适应律设计方法, 存在参数漂移的潜在威胁. 在此基础上, 添加阻尼项可以有效抑制其影响, 但是在这种参数自适应律设计方法下人们往往难以证明闭环系统的渐近稳定性. 此外, 在传统的自适应控制中, 必须满足一个严格的持续激励 (Persistent excitation, PE) 条件, 以保证参数的收敛性. 然而, 在实际场景下, PE条件通常难以验证. 为了放松PE条件, 在文献[19]和文献[20]中分别提出了并行学习和复合学习技术, 在较弱的区间激励(Interval excitation, IE) 条件下, 确保了参数的收敛性. 此外, 与并行学习方法相比, 由于复合学习自适应律的设计不依赖于系统状态的导数, 在实际应用中往往更具有优势. 另一方面, 无人艇在执行任务时通常要求快速的控制响应. 引入有限时间或固定时间控制技术[21-22] 可以使受控系统在有限时间内达成目标. 此外, 有限时间及固定时间控制技术不仅可以保证跟踪误差的快速收敛, 而且对不确定性具有良好的鲁棒性.
基于以上讨论, 本文针对模型参数不确定下多无人艇系统的固定时间二分编队跟踪控制问题, 提出一组融合命令滤波、复合学习及反推控制技术的分布式控制协议. 本文的贡献可以概括为以下两个方面: 在反推控制方法中引入命令滤波, 有效地避免了对虚拟控制器求导, 极大地降低了计算负担, 且简化了分布式控制协议的形式; 在反推控制方法中引入复合学习, 使得提出的控制协议在不满足PE条件的情况下, 不仅能够确保编队误差的固定时间收敛性, 也能够确保参数估计误差的固定时间收敛性.
本文使用的符号: $ {\bf{R}}^n $和$ {\bf{R}}^{n\times m} $分别表示 $ n $ 维向量空间和$ n\times m $ 阶实矩阵的集合; $ {\rm diag}\{R_i\}= {\rm diag}\{R_1,\;\cdots,\;R_N\} $表示块对角矩阵, 其中矩阵$ R_1,\;\cdots,\;R_N\in{\bf{R}}^{n\times n} $ 在该矩阵的对角线上; $ \varnothing $ 表示空集; $ \Vert\cdot\Vert $ 表示向量的$ 2 $ 范数; $ {\rm sign}(\cdot) $ 表示符号函数; $ |\cdot| $ 表示标量的绝对值; $ \otimes $ 表示Kronecker积; 给定向量函数$ \delta(t)=(\delta_1(t),\;\cdots,\;\delta_N(t))^{\mathrm{T}}\in{\bf{R}}^{N} $和常数$ \gamma > 0 $, 定义$ {\rm sig}\{\delta(t)\}^{\gamma} = (|\delta_1(t)|^{\gamma}{\rm sign}(\delta_1(t)),\; \cdots,$ $ |\delta_N(t)|^{\gamma}{\rm sign}(\delta_N(t)))^{\rm T} $; 给定对称矩阵$ Q\in{\bf{R}}^{m\times m} $, $ Q>{\bf{0}} $ 表示$ Q $ 是正定矩阵, $ \lambda_{\min}(Q),\; $ $ \lambda_{\max}(Q) $ 分别表示对称矩阵$ Q $ 的最小和最大特征值; $ I_n $ 表示$ n $ 维单位矩阵.
1. 预备知识和问题描述
1.1 代数图论
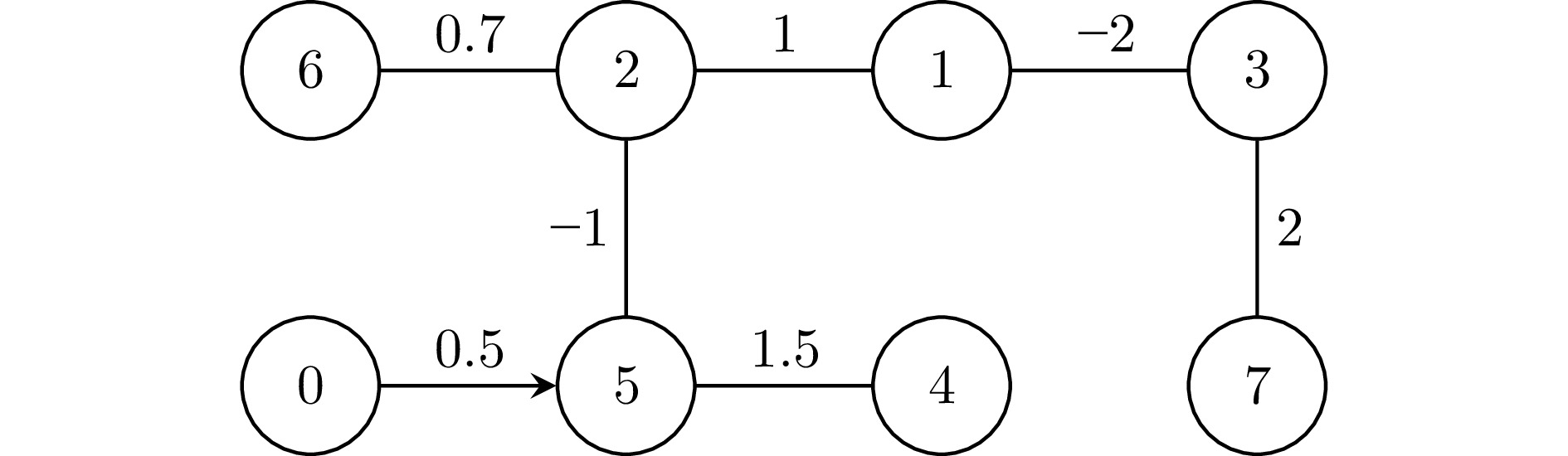
给定一个符号无向图$ {\cal{G}}=({\cal{I}},\; {\cal{E}},\; {\cal{A}}) $ 用以描述多无人艇系统的通信情况, 其中, $ {\cal{I}}=\{1,\; 2,\; \cdots,\; N\} $, $ {\cal{E}}=\{(i,\; j): i,\;j\in{\cal{I}}\} \subseteq{\cal{I}}\times{\cal{I}} $ 和$ {\cal{A}}=[a_{ij}]\in {\bf{R}}^{N\times N} $分别表示节点集、边集和符号邻接矩阵, 满足: 若$ (j,\;i)\in{\cal{E}} $ 则表示智能体$ i $可以接收到智能体 $ j $的信息, 否则表示不能接收到; 若$ i\neq j $ 且$ (j,\; i)\in{\cal{E}} $ 则$ a_{ij}\neq 0 $, 否则$ a_{ij}=0 $. 节点 $ i $ 的邻居集定义为$ {\cal{N}}_i=\{j: a_{ij}\neq 0\} $. 通信拓扑图的 Laplacian 矩阵定义为$ {\cal{L}}={\rm diag}\Big\{\sum\nolimits_{j\in{\cal{N}}_i}|a_{ij}|\Big\}-{\cal{A}} $. 给定一个包含$ N+1 $ 个节点的符号有向图$ {\cal{\bar{G}}}=({\cal{\bar{I}}},\;{\cal{\bar{E}}}) $, 其中, $ {\cal{\bar{I}}}= {\cal{I}}\cup\{0\} $; $ {\cal{\bar{E}}}\subseteq {\cal{I}} \times{\cal{I}} $; 节点0表示领航无人艇, 它仅向跟随无人艇传递信息而不接收信息. 牵引矩阵记为$ {\cal{B}}={\rm diag}\{b_i\} $, 满足: 若无人艇$ i $能接收到领航者的信息则$ b_i>0 $; 否则, $ b_i=0 $.
定义 1[23]. 若存在节点集的划分$ {\cal{I}}_1,\; {\cal{I}}_2 $ 满足: 1) $ {\cal{I}}_1\cup{\cal{I}}_2={\cal{I}} $; 2) $ {\cal{I}}_1\cap{\cal{I}}_2=\varnothing $; 3) 若$ i,\;j $ 同属于一个集合$ {\cal{I}}_1 $或$ {\cal{I}}_2 $, 则$ a_{ij}\geq 0 $, 否则$ a_{ij}\leq 0 $, 则符号图$ {\cal{G}} $被称作结构平衡的.
引入对角矩阵$ E={\rm diag}\{\varepsilon_i\} $, 其中, $ \varepsilon_i=1,\; i\in {\cal{I}}_1 $; $ \varepsilon_i=-1,\; i\in{\cal{I}}_2 $. 定义$ {\cal{\tilde{L}}}=E{\cal{L}}E $.
1.2 固定时间稳定性
定义2[24]. 给定如下非线性系统
$$ \dot{x}(t)=f(t,\;x(t)) $$ 式中, $ x(t)\in{\bf{R}}^n,\; f(t,\;x(t))\in{\bf{R}}^n $分别表示系统状态和局部 Lipschitz 连续函数. 若该系统的原点是全局渐进稳定的, 且存在与状态初值无关的时刻$ T $满足$ x(t)=0,\; \forall t\geq T $, 则称原点是固定时间稳定的.
引理 1[25]. 若存在常数$ c_1,\;c_2,\; m_1,\; m_2 $和连续径向无界标量函数$ {\cal{V}}(x(t)) $, 满足$ c_1>0,\; c_2>0 $, $ 0< m_1<1<m_2 $ 以及
$$ \dot{{\cal{V}}}(x(t))\leq -c_1{\cal{V}}^{m_1}(x(t))-c_2{\cal{V}}^{m_2}(x(t)) $$ 则原点是固定时间稳定的, 且稳定时间$ T_s $满足
$$ T_s\leq\frac{1}{c_1(1-m_1)}+\frac{1}{c_2(m_2-1)} $$ 进一步地, 若下式成立
$$ \dot{{\cal{V}}}(x(t))\leq -c_1{\cal{V}}^{m_1}(x(t))-c_2{\cal{V}}^{m_2}(x(t))+{\cal{C}} $$ 式中, $ {\cal{C}}>0 $为常参数, 则称原点是实用固定时间稳定的, 且稳定时间$ T_s $满足
$$ T_s\leq\frac{1}{c_1c(1-m_1)}+\frac{1}{c_2c(m_2-1)},\;\quad c\in(0,\;1) $$ 1.3 问题描述
考虑由$ N $艘无人艇组成的集群二分编队跟踪系统. 第$ i,\; i\in{\cal{I}} $艘跟随无人艇的运动学与动力学模型描述为[8]
$$ \dot{\eta}_i(t)=R(\psi_i(t))v_i(t) $$ (1) $$ M_i \dot{v}_i(t)=f_i(v_i(t))+\tau_i(t)+\phi_{i}(v_i(t))\Theta_i $$ (2) 式中, $ \eta_i(t)\;=\;(x_i(t),\; y_i(t),\; \psi_i(t))^{\rm T}\in{\bf{R}}^3 $, $ (x_i(t),\; y_i(t))^{\rm T}\in {\bf{R}}^2 $ 和$ \psi_i(t)\in{\bf{R}} $ 分别表示第$ i $艘无人艇在地面坐标系下的位置向量和偏航角; $ v_i(t)=(u_i^1(t),\; u_i^2(t),\; u_i^3(t))^{\rm T}\in{\bf{R}}^3 $表示第$ i $艘无人艇在体坐标系下的速度向量, $ u_i^1(t),\; u_i^2(t) $和$ u_i^3(t) $分别表示前向速度、横向速度和转向角速度; $ \tau_i(t)\in{\bf{R}}^3 $表示第$ i $艘无人艇的控制输入; $ R(\psi_i(t))\in{\bf{R}}^{3\times 3} $是转换矩阵, 形式如下
$$ R(\psi_i(t))= \left[\begin{array}{ccc} \cos(\psi_i(t))& -\sin(\psi_i(t))& 0\\ \sin(\psi_i(t))& \cos(\psi_i(t))& 0\\ 0 & 0 & 1 \end{array}\right] $$ $ f_i(v_i(t))=(f_{i1}(v_i(t)),\, f_{i2}(v_i(t)),\, f_{i3}(v_i(t)))^{\mathrm{T}}\in{\bf{R}}^{3} $ 是一个非线性向量函数; $M_i\in{\bf{R}}^{3\times 3}>{\bf{0}} $表示惯性矩阵; $ \phi_{i}(v_i(t))\Theta_i\in{\bf{R}}^{3} $表示参数不确定性, $ \phi_{i}(v_i(t))\in {\bf{R}}^{3\times m} $是已知的非线性函数, $ \Theta_i\in{\bf{R}}^{m} $是未知的常参数. 领航无人艇0的状态信号记为$ \eta_0(t)=(x_0(t),\; y_0(t),\; \psi_0(t))\in{\bf{R}}^3 $和$ v_0(t)\in{\bf{R}}^3 $.
期望编队向量记为$ h=(h_{1}^{\mathrm{T}},\;\cdots,\;h_{N}^{\mathrm{T}})^{\mathrm{T}}\in{\bf{R}}^{3N} $, 其中, $ h_{i}=(h_{i}^1,\;h_{i}^2,\;h_{i}^3)^{\mathrm{T}}\in{\bf{R}}^3,\; i\in{\cal{I}} $表示无人艇$ i $与领航无人艇$ 0 $之间期望的位置差. $ h_{i} $仅用于描述期望编队构型, 不用于为跟随无人艇提供参考轨迹. 本文的控制目标是: 设计一组分布式控制器, 使得遭受模型参数不确定性影响的多无人艇系统 (1) ~ (2) 实现固定时间二分编队跟踪, 即
$$ \lim_{t\rightarrow T_i}\Vert e_i(t) \Vert=0,\;\quad \forall i\in{\cal{I}} $$ 式中, $ T_i>0 $ 是一个常参数; $ e_i(t)=\eta_i(t)-h_i\;- \varepsilon_i\eta_0(t)\in{\bf{R}}^3 $ 是编队误差. 为设计控制器, 给出以下假设、引理和定义.
假设 1. 有向图$ {\cal{\bar{G}}} $ 具有有向生成树, $ 0 $是其根节点; 无向图$ {\cal{G}} $是连通的且结构平衡的.
假设 2. 参考轨迹$ \eta_0(t) $及其一阶导数$ \dot{\eta}_0(t) $是有界的, 即, 存在正常数$ \bar{\eta}_0\in {\bf{R}} $, 使得$ \Vert\eta_0(t)\Vert\leq \bar{\eta}_0 $和$ \Vert\dot{\eta}_0(t)\Vert\leq \bar{\eta}_0 $成立. 此外, $ \bar{\eta}_0 $仅部分和领航无人艇有通信的无人艇可知.
引理 2[26]. 给定标量函数$ z_1(t),\; \cdots,\; z_{\bar{\rho}}(t) $ 和常数$ \vartheta $, 以下不等式成立
$$ \left\{\begin{split} &\left(\sum_{\rho=1}^{\bar{\rho}} z_{\rho}(t)\right)^{\vartheta}\leq \sum_{\rho=1}^{\bar{\rho}}z_{\rho}^{\vartheta}(t),\;\quad 0 <\vartheta\leq 1\\ & \bar{\rho}^{1-\vartheta}\left(\sum_{\rho=1}^{\bar{\rho}} z_{\rho}(t)\right)^{\vartheta}\leq \sum_{\rho=1}^{\bar{\rho}}z_{\rho}^{\vartheta}(t),\; \quad \vartheta > 1 \end{split}\right. $$ 定义 3[27]. 给定一个矩阵函数$ \Delta(t)\in{\bf{R}}^{n\times m} $, 若存在常数$ \tilde{t},\; \mu $满足$ 0<\tilde{t}<t,\; \mu>0 $使$ \int_{t-\tilde{t}}^t\Delta^{\rm T} (\sigma)\;\times \Delta(\sigma) {\mathrm{d}}\sigma\geq \mu I_m,\; \forall t\geq 0 $ 成立, 则 $ \Delta(t) $ 被称作PE信号.
定义 4[27]. 给定一个矩阵函数$ \Delta(t)\in{\bf{R}}^{n\times m} $, 若存在常数$ \hat{t},\; \tilde{t},\; \mu $满足$ 0<\tilde{t}<\hat{t},\; \mu>0 $使$ \int_{\hat{t}-\tilde{t}}^{\hat{t}}\Delta^{\rm T} (\sigma) \times \; \Delta(\sigma){\mathrm{d}}\sigma\geq \mu I_m $成立, 则$ \Delta(t) $被称作IE信号.
注 1. 在分布式场景下, 无人艇$ i,\; i\in{\cal{I}} $仅能获得相对信息$ \eta_i(t)-{\rm sign}(a_{ij})\eta_j(t) $和 $ h_{ij}=h_i- {\rm sign} (a_{ij})h_j $; 部分与领航无人艇有通信连接的无人艇能获得全局信息$ \eta_0(t) $和$ h_i $.
注 2. 对比定义3和定义4, IE条件明显弱于PE条件.
2. 复合学习固定时间二分编队控制协议设计
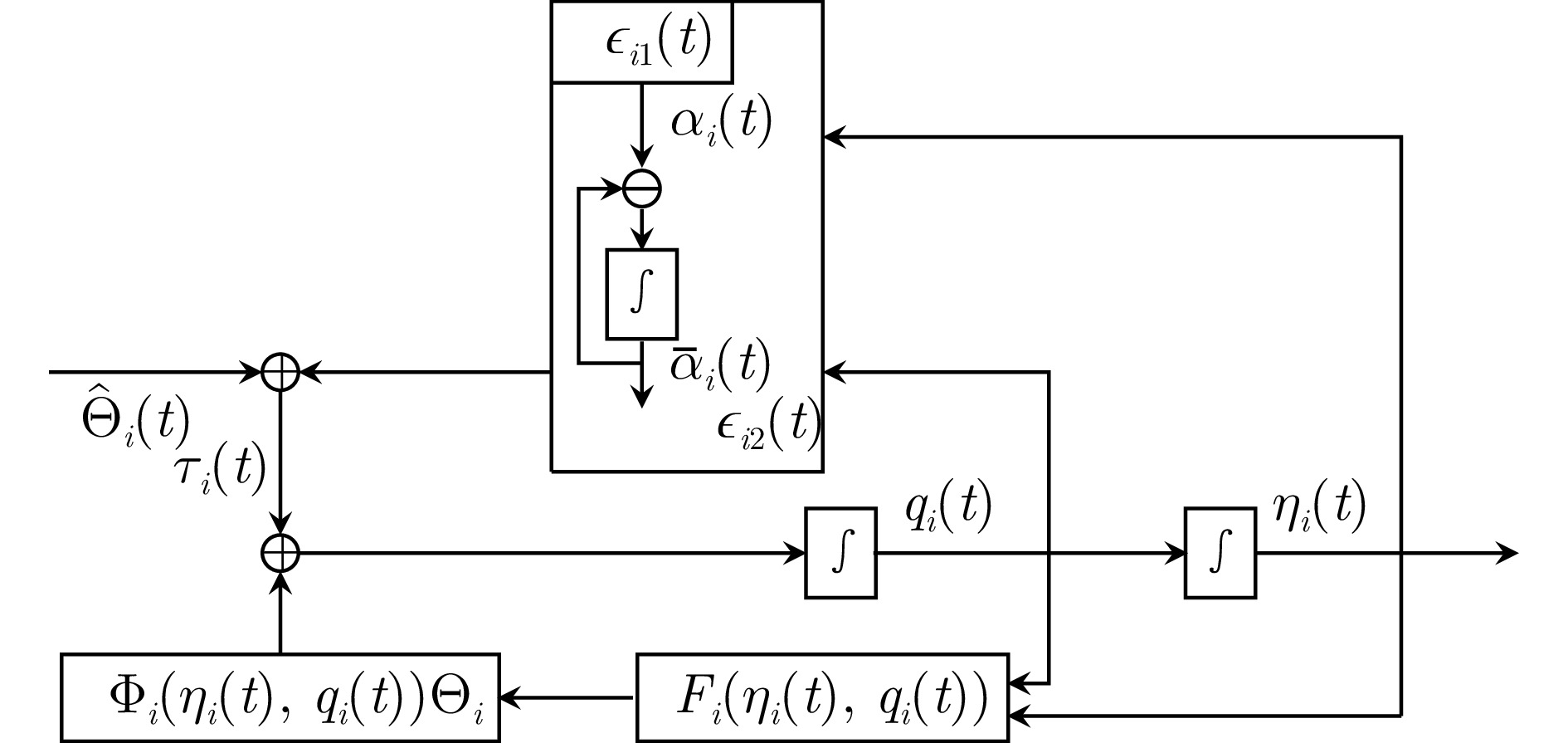
在本节中, 提出了一组复合学习固定时间二分编队控制协议, 图1中给出了控制程序和控制信号框图.
2.1 控制器设计
令$ q_i(t)=R(\psi_i(t))v_i(t) $, 则系统(1) ~ (2)可转化为
$$ \dot{\eta}_i(t)= q_i(t) $$ (3) $$ \begin{split} \dot{q}_i(t)=&\; F_i(\eta_i(t),\;q_i(t)) +g_i(\eta_i(t),\;q_i(t))\tau_i(t)\;+\\ & \Phi_{i}(\eta_i(t),\;q_i(t))\Theta_i \end{split} $$ (4) 式中, $ F_i(\eta_i(t),\,q_i(t))\;\;=\;\;R(\psi_i(t))M_i^{-1}f_i(v_i(t))\;+ \dot{R} (\psi_i(t)) v_i(t) $, $ g_i(\eta_i(t),\;q_i(t))\;\;=\;\;R(\psi_i(t))M_i^{-1} $ 以及$ \Phi_{i} (\eta_i(t),\; q_i(t))= R(\psi_i(t))M_i^{-1}\phi_{i}(v_i(t)) $.
对于第$ i,\; i\in{\cal{I}} $ 艘无人艇, 定义如下的局部跟踪误差信号
$$ \begin{split} \epsilon_{i1}(t)=&\;\sum\limits_{j\in{\cal{N}}_i}|a_{ij}|\left(\eta_i(t)-{\rm sign}(a_{ij})\eta_j(t)-h_{ij}\right)+\\ & b_i\left(\eta_i(t)-\varepsilon_i\eta_0(t)-h_i\right)\\[-1pt] \end{split} $$ (5) $$ \epsilon_{i2}(t)= q_i(t)-\bar{\alpha}_i(t) $$ (6) 式中, $ \alpha_i(t)\in{\bf{R}}^{3} $ 为虚拟控制输入, $ \bar{\alpha}_i(t)\in{\bf{R}}^{3} $ 为$ \alpha_i(t) $ 的命令滤波对应量, 其满足
$$ \dot{\bar{\alpha}}_i(t)=-w_i\tilde{\alpha}_i(t) $$ (7) 其中, $ \tilde{\alpha}_i(t)=\bar{\alpha}_i(t)-\alpha_i(t) $ 为滤波误差, $ w_i>0 $ 为常参数. 接下来, 介绍无人艇控制协议的具体设计程序.
步骤 1. 定义$ \epsilon_{1}(t)=(\epsilon_{11}^{\rm T}(t),\;\cdots,\;\epsilon_{N1}^{\rm T}(t))^{\rm T} $. 根据(3)、(5)和(6)可得
$$ \dot{\epsilon}_{1}(t)=\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)\Xi(t)$$ (8) 式中, $ \Xi(t)= \begin{pmatrix} \epsilon_{12}(t)+\tilde{\alpha}_1(t)+\alpha_1(t)-\varepsilon_1\dot{\eta}_0(t)\\ \vdots\\ \epsilon_{N2}(t)+\tilde{\alpha}_N(t)+\alpha_N(t)-\varepsilon_N\dot{\eta}_0(t)\\ \end{pmatrix} . $虚拟控制输入设计为:
$$ \begin{split} \alpha_i(t)=\;&-\left(k_{i1}+\frac{1}{2}+\nu_i\right)\epsilon_{i1}(t)\;-\\ & \eta_{0i}(t)\frac{\epsilon_{i1}(t)}{\sqrt{\|\epsilon_{i1}(t)\|^2+\rho_i^2(t)}}\;-\\ & \sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i1}(t)\}^{m_l} \end{split} $$ (9) 式中, $ k_{i1}>0,\; c_l>0,\; 0<m_1<1<m_2,\; \nu_i>0 $为待设计的常参数; $ \rho_i(t)\in{\bf{R}}>0 $满足$ \int_0^{+\infty}\rho_i(t){\mathrm{d}}t< +\infty $和$ |\rho_i(t)|\leq\bar{\rho}_i $; $ \eta_{0i}(t)\in{\bf{R}} $是对$ \bar{\eta}_0 $的估计, 根据下式更新:
$$ \dot{\eta}_{0i}(t)=-\sum_{l=1}^2c_l{\rm sig}\{\xi_i(t)\}^{m_l} $$ (10) 其中, $ \xi_i(t) = \sum\nolimits_{j\in {\cal{N}}_i}|a_{ij}|(\eta_{0i}(t)-\eta_{0j}(t))+b_i(\eta_{0i}(t)\;- \bar{\eta}_0) $.
将 (9) 代入 (8) 可得闭环误差系统
$$ \dot{\epsilon}_{1}(t)=\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)\tilde{\Xi}(t) $$ (11) 式中
$$\begin{split} &\tilde{\Xi}(t)=\epsilon_{2}(t)+\tilde{\alpha}(t)-{\rm diag}\left\{\left(k_{i1}+\frac{1}{2}+ \nu_i\right)\otimes I_3\right\}\times \\ &\;\;\;\; \epsilon_{1}(t) - \begin{pmatrix} \displaystyle\frac{\eta_{01}(t)\epsilon_{11}(t)}{\sqrt{\|\epsilon_{11}(t)\|^2+\rho_1^2(t)}}+\varepsilon_1\dot{\eta}_0(t)\\\vdots\\ \displaystyle\frac{\eta_{0N}(t)\epsilon_{N1}(t)}{\sqrt{\|\epsilon_{N1}(t)\|^2+\rho_N^2(t)}}+\varepsilon_N\dot{\eta}_0(t)\\ \end{pmatrix} -\\ &\;\;\;\; \sum\limits_{l=1}^2c_l{\rm sig}\{\epsilon_{1}(t)\}^{m_l}\end{split} $$ 其中, $ \epsilon_{2}(t) = (\epsilon_{12}^{\rm T}(t),\;\cdots,\; \epsilon_{N2}^{\rm T}(t))^{\rm T}$和 $ \tilde{\alpha}(t) = (\tilde{\alpha}_1^{\rm T}(t),\; \cdots,\;\tilde{\alpha}_N^{\rm T}(t))^{\rm T} $.
选择如下的 Lyapunov 函数
$$ V_{1}(t)=\frac{1}{2}\epsilon_{1}^{\mathrm{T}}(t)\left(({\cal{L}}+{\cal{B}})\otimes I_3\right)^{-1}\epsilon_{1}(t) $$ 由 (11) 可推出
$$ \begin{split} \dot{V}_{1}(t) \leq\;& -\epsilon_{1}^{\mathrm{T}}(t){\rm diag}\left\{\left(k_{i1}+\nu_i\right)\otimes I_3\right\}\epsilon_{1}(t)\ +\\ & \frac{1}{2}\epsilon_{2}^{\mathrm{T}}(t)\epsilon_{2}(t) -\sum\limits_{l=1}^2c_l\epsilon_{1}^{\mathrm{T}}(t){\rm sig}\{\epsilon_{1}(t)\}^{m_l}\ -\\ & \sum\limits_{i=1}^N\frac{\tilde{\eta}_{0i}(t)\|\epsilon_{i1}(t)\|^2}{\sqrt{\|\epsilon_{i1}(t)\|^2+\rho_i^2(t)}} +\sum\limits_{i=1}^N\bar{\eta}_0\rho_i(t)\ +\\ & \epsilon_{1}^{\mathrm{T}}(t)\tilde{\alpha}(t)\\[-1pt] \end{split} $$ (12) 式中, $ \tilde{\eta}_{0i}(t)=\eta_{0i}(t)-\bar{\eta}_0 $ 表示参数估计误差. 定义全局参数估计误差$ \tilde{\eta}_{0}(t)=(\tilde{\eta}_{01}^{\rm T}(t),\;\cdots,\;\tilde{\eta}_{0N}^{\rm T}(t))^{\rm T} $.
步骤 2. 利用 (4)、(6) 和 (7) 可得
$$ \begin{split} \dot{\epsilon}_{i2}(t)=\;& g_i(\eta_i(t),\;q_i(t))\Big(g_i^{-1}(\eta_i(t),\;q_i(t))w_i\tilde{\alpha}_i(t)\ +\\ & \tau_i(t) +g_i^{-1}(\eta_i(t),\;q_i(t))\Phi_{i}(\eta_i(t),\;q_i(t))\Theta_i\ +\\ & g_i^{-1}(\eta_i(t),\;q_i(t))F_i(\eta_i(t),\;q_i(t))\Big)\\[-1pt] \end{split} $$ (13) 控制输入可以设计为
$$ \begin{split} \tau_i(t)=&\;-g_i^{-1}(\eta_i(t),\;q_i(t))\Big(\Big(k_{i2}+\frac{1}{2}\Big)\epsilon_{i2}(t)\ +\\ & F_i(\eta_i(t),\;q_i(t)) +\sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i2}(t)\}^{m_l}\ +\\ & w_i\tilde{\alpha}_i(t) +\Phi_{i}(\eta_i(t),\;q_i(t))\hat{\Theta}_i(t)\Big)\end{split} $$ (14) 式中, $ k_{i2}>0 $为待设计的常参数, $ \hat{\Theta}_i(t)\in{\bf{R}}^{m} $是对$ \Theta_i $的估计.
将 (14) 代入 (13) 可得闭环误差系统
$$ \begin{split} \dot{\epsilon}_{i2}(t)=&-\left(k_{i2}+\frac{1}{2}\right)\epsilon_{i2}(t)-\Phi_{i}(\eta_i(t),\;q_i(t))\tilde{\Theta}_i(t)\ -\\ & \sum_{l=1}^2c_l{\rm sig}\{\epsilon_{i2}(t)\}^{m_l}\\[-1pt]\end{split} $$ (15) 式中, $ \tilde{\Theta}_i(t)=\hat{\Theta}_i(t)-\Theta_i $ 为参数估计误差.
为了自适应地估计未知参数$ \Theta_i $, 给出滤波信号$ q_{i}^{f}(t)\in{\bf{R}}^3,\; H_{i}^{f}(t)\in{\bf{R}}^3,\; \Phi_{i}^{f}(t)\in{\bf{R}}^{3\times m} $和辅助变量$ \Lambda_i(t)\in{\bf{R}}^{m\times m},\; \Upsilon_i(t)\in{\bf{R}}^{m} $, 其按下式更新
$$ \left\{ \begin{array}{l} \beta_i\dot{q}_{i}^{f}(t)+q_{i}^{f}(t)=q_i(t)\\ \beta_i\dot{H}_{i}^{f}(t)+H_{i}^{f}(t)= H_{i}(t) \\ \beta_i\dot{\Phi}_{i}^{f}(t)+\Phi_{i}^{f}(t)=\Phi_{i}(\eta_i(t),\;q_i(t)) \end{array}\right. $$ (16) $$ \left\{\begin{split} &\Lambda_{i}(t)=\int_{t-o_i}^t\Phi_{i}^{f{\mathrm{T}}}(\sigma)\Phi_{i}^{f}(\sigma){\mathrm{d}}\sigma\\ &\Upsilon_{i}(t)=\int_{t-o_i}^t\Phi_{i}^{f{\mathrm{T}}}(\sigma) \left(\frac{q_{i}(\sigma)- q_{i}^{f}(\sigma)} {\beta_i}-H_{i}^{f}(\sigma)\right){\mathrm{d}}\sigma \end{split}\right. $$ (17) 式中, $ \beta_i>0 $, $ t>o_i\geq0 $是常数, $ H_{i}(t)\;=\;F_i (\eta_i(t), q_i(t))+g_i(\eta_i(t),\;q_i(t))\tau_i(t) $. 联立 (4)、(16) 和 (17) 可得
$$ \Lambda_{i}(t)\Theta_{i}=\Upsilon_{i}(t) $$ (18) 定义如下的预测误差函数$ {\cal{P}}_i(t)\in{\bf{R}}^{m} $:
$$ \begin{aligned} {\cal{P}}_i(t)= \begin{cases} \Lambda_{i}(t)\hat{\Theta}_i(t),\;& t<p_i\;\\ \Lambda_{i}(p_i)\hat{\Theta}_i(t)-\Upsilon_{i}(p_i),\;& t\geq p_i\; \end{cases} \end{aligned} $$ (19) 式中, $ p_i $是矩阵$ \Lambda_{i}(t)>{\bf{0}} $的时刻. 参数估计$ \hat{\Theta}_i(t) $的更新律设计如下:
$$ \begin{split} \dot{\hat{\Theta}}_i(t)=\ &\Gamma_i\Phi_{i}^{\mathrm{T}}(\eta_i(t),\;q_i(t))\epsilon_{i2}(t)\ -\\ & \Gamma_i\Lambda_{i}^{\mathrm{T}}(t)\sum_{l=1}^2c_l{\rm sig}\{{\cal{P}}_i(t)\}^{m_l} \end{split} $$ (20) 式中, $ \Gamma_i\in{\bf{R}}^{m\times m}>{\bf{0}} $ 代表参数学习率.
选择如下的 Lyapunov 函数:
$$ V_{2}(t)=\frac{1}{2}\epsilon_{2}^{\mathrm{T}}(t)\epsilon_{2}(t)+\frac{1}{2}\sum_{i=1}^N\tilde{\Theta}_i^{\mathrm{T}}(t)\Gamma_i^{-1}\tilde{\Theta}_i(t) $$ 根据 (15) 和 (20), 对于$ t\geq \max _{i\in{\cal{I}}}\{p_i\} $有
$$ \begin{split} \dot{V}_{2}(t)=\ &-\epsilon_{2}^{\rm T}(t){\rm diag}\left\{\left(k_{i2}+\frac{1}{2}\right)\otimes I_3\right\}\epsilon_{2}(t)\ -\\& \sum_{l=1}^2c_l\epsilon_{2}^{\rm T}(t){\rm sig}\{\epsilon_{2}(t)\}^{m_l}\ -\\& \sum_{l=1}^2c_l{\cal{P}}^{\rm T}(t){\rm sig}\{{\cal{P}}(t)\}^{m_l}\\[-1pt] \end{split} $$ (21) 式中, $ {\cal{P}}(t)=({\cal{P}}_1^{\rm T}(t),\;\cdots,\;{\cal{P}}_N^{\rm T}(t))^{\rm T} $.
注 3. 由 (5) 可推出, $ \epsilon_{1}(t)=(({\cal{L}}+{\cal{B}})\otimes I_3)e(t) $, 其中, $ e(t)=(e_1^{\rm T}(t),\;\cdots,\;e_N^{\rm T}(t))^{\mathrm{T}} $. 此外, 在假设1满足时, 有$ {\cal{L}}+{\cal{B}}>{\bf{0}} $和$ {\cal{\tilde{L}}}+{\cal{B}}>{\bf{0}} $成立.
2.2 稳定性分析
在给出最终稳定性结果之前, 首先给出如下引理.
引理 3. 在假设1和假设2满足时, 全局参数估计误差$ \tilde{\eta}_{0}(t) $在固定时间内收敛到零, 收敛时间$ T_{\eta} $满足$ T_{\eta}\leq\frac{1}{\kappa_1(1-\iota_1)}+\frac{1}{\kappa_2(\iota_2-1)} $.
证明. 根据 (10) 有
$$ \dot{\tilde{\eta}}_{0}(t)=-\sum_{l=1}^2c_l{\rm sig}\{(({\cal{\tilde{L}}}+{\cal{B}})\otimes I_3)\tilde{\eta}_{0}(t)\}^{m_l}$$ (22) 选择如下的 Lyapunov 函数
$$ L(t)=\frac{1}{2}\tilde{\eta}_{0}^{\rm T}(t)(({\cal{\tilde{L}}}+{\cal{B}})\otimes I_3)\tilde{\eta}_{0}(t)$$ (23) 由 (22) 可推出
$$ \dot{L}(t)=-\kappa_1L^{\iota_1}(t)-\kappa_2L^{\iota_2}(t) $$ (24) 式中, $ \iota_1 = \frac{1+m_1}{2},\; \iota_2 = \frac{1+m_2}{2},\; \kappa_1 = c_1(2\lambda_{\min}({\cal{\tilde{L}}} + {\cal{B}}))^{\iota_1},\; \kappa_2=c_2(2\lambda_{\min}({\cal{\tilde{L}}}+{\cal{B}}))^{\iota_2}(3N)^{1-\iota_2} $. 根据引理1可知, $ \tilde{\eta}_{0}(t) $固定时间收敛到零, 收敛时间 $ T_{\eta} $满足$ T_{\eta}\leq \frac{1}{\kappa_1(1-\iota_1)}+\frac{1}{\kappa_2(\iota_2-1)} $. 因此, 存在时刻$ \tilde{t}\geq T_{\eta} $有$ \tilde{\eta}_{0}(t)= {\bf{0}},\; \forall t\geq \tilde{t} $.
□ 注 4. 在实际情形下, 无人艇系统状态信号$ \eta_i(t),\; $$ \eta_0(t) $是有界的; 根据假设2, 信号$ \dot{\eta}_0(t) $也是有界的. 因此, 根据 (5) 可推出$ \epsilon_{i1}(t) $是有界的. 此外, 根据引理3可知, $ \eta_{0i}(t) $是有界的. 综上, 由 (9) 可推断出$ \alpha_i(t) $是有界的. 注意, 如果$ \alpha_i(t) $是有界的, 那么$ \tilde{\alpha}_i(t) $是有界的. 在此情况下, 存在常数$ \check{\alpha}_i>0 $使得$ \Vert\tilde{\alpha}_i(t)\Vert\leq\check{\alpha}_i $.
定理1给出了本文的稳定性结果.
定理 1. 在假设1和假设2满足时, 多无人艇系统 (3) ~ (4) 在控制协议 (14) 和参数自适应律 (20) 的驱动下可以实现实用固定时间二分编队跟踪控制, 收敛时间$ T_{{\cal{P}}} $满足$ T_{{\cal{P}}}\leq\max_{i\in{\cal{I}}}\;\{\;\tilde{t},\;p_i\;\}\ + \frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)}+\frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} $.
证明. 选择如下的 Lyapunov 函数$ V(t)= V_{1}(t) + \; V_{2}(t) $. 根据 (12) 和 (21), 对于$ t\;\geq\; \max_{i\in{\cal{I}}} \{\tilde{t}, p_i\}, \nu_i\geq o_i $ 有
$$ \begin{split} \dot{V}(t) \leq\;&\ \epsilon_{1}^{\rm T}(t)\tilde{\alpha}(t) -\sum\limits_{l=1}^2c_l\epsilon_{1}^{\rm T}(t){\rm sig}\{\epsilon_{1}(t)\}^{m_l}\ -\\ & \epsilon_{1}^{\rm T}(t){\rm diag}\left\{\nu_i\otimes I_3\right\}\epsilon_{1}(t) +\sum\limits_{i=1}^N\bar{\eta}_0\rho_i(t)\ -\\ & \sum_{l=1}^2c_l\epsilon_{2}^{\rm T}(t){\rm sig}\{\epsilon_{2}(t)\}^{m_l}\ -\\ & \sum_{l=1}^2c_l{\cal{P}}^{\rm T}(t){\rm sig}\{{\cal{P}}(t)\}^{m_l}\leq\\ & -\sum_{l=1}^2c_l\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_l}+\iota \end{split} $$ 式中, $ \epsilon_{{\cal{P}}}(t) = (\epsilon_{1}^{\rm T}(t),\;\epsilon_{2}^{\rm T}(t),\; {\cal{P}}^{\rm T}(t))^{\rm T} $, $ \iota = \sum\nolimits_{i=1}^N\frac{1}{4o_i}\check{\alpha}_i^2 + \; \sum\nolimits_{i=1}^N\bar{\eta}_0\bar{\rho}_i $, $ o_i>0 $是合适的常参数, 通过选取$ o_i $和$ \rho_i(t) $可以使残差集任意小. 因为对于$ t\;\geq \;\max _{i\in{\cal{I}}} \{\tilde{t}, p_i\} $有
$$ \zeta_1\epsilon_{{\cal{P}}}^{\rm T}(t)\epsilon_{{\cal{P}}}(t)\leq V(t) \leq\zeta_2\epsilon_{{\cal{P}}}^{\rm T}(t)\epsilon_{{\cal{P}}}(t) $$ 式中, $ \zeta_1=\min\limits_{i\in{\cal{I}}}\left\{\frac{1}{2},\;\frac{1}{2\lambda_{\min}\left(\Lambda_{i}^{\mathrm{T}}(t)\Gamma_i\Lambda_{i}(t)\right)},\;\frac{1}{2\lambda_{\max}\left({\cal{L}}+{\cal{B}}\right)}\right\},\; $ $ \zeta_2=\min\limits_{i\in{\cal{I}}}\left\{\frac{1}{2},\;\frac{1}{2\lambda_{\max}\left(\Lambda_{i}^{\mathrm{T}}(t)\Gamma_i\Lambda_{i}(t)\right)},\;\frac{1}{2\lambda_{\min}\left({\cal{L}}+{\cal{B}}\right)}\right\} $. 因此, 根据引理2可以推断出
$$ \begin{split} &-c_1\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_1} \leq -\bar{\kappa}_1V^{\bar{\iota}_1}(t)\\ & -c_2\epsilon_{{\cal{P}}}^{\rm T}(t){\rm sig}\{\epsilon_{{\cal{P}}}(t)\}^{m_2} \leq -\bar{\kappa}_2V^{\bar{\iota}_2}(t) \end{split} $$ 式中, $ \bar{\iota}_1 = \frac{m_1+1}{2},\; \bar{\kappa}_1=c_1\left(\frac{1}{\zeta_2}\right)^{\bar{\iota}_1},\; \bar{\iota}_2 = \frac{m_2+1}{2} $ 和$ \bar{\kappa}_2= c_2((6+m)N)^{1-\bar{\iota}_2}\left(\frac{1}{\zeta_2}\right)^{\bar{\iota}_2} $. 进一步有
$$ \dot{V}(t) \leq -\sum_{l=1}^2\bar{\kappa}_lV^{\bar{\iota}_l}(t)+\iota,\;\quad t\geq \max\limits_{i\in{\cal{I}}}\{\tilde{t},\;p_i\} $$ 根据引理1可知, 误差向量$ \epsilon_1(t),\; \epsilon_2(t),\; {\cal{P}}(t) $固定时间收敛到原点的任意小邻域, 收敛时间$ T_{{\cal{P}}} $满足$ T_{{\cal{P}}}\leq\max_{i\in{\cal{I}}}\{\tilde{t},\;p_i\}+\frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)}+\frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} $. 根据 (19), 当$ t\geq \max_{i\in{\cal{I}}}\{\tilde{t},\;p_i\} $时, 有$ {\cal{P}}_i(t)=\Lambda_i(p_i)\tilde{\Theta}_i(t) $且$ \Lambda_i(p_i) $可逆. 因此, 参数估计误差$ \tilde{\Theta}_i(t),\; i\in{\cal{I}} $也固定时间收敛到原点的任意小邻域. 综上, 多无人艇系统 (3) ~ (4) 在控制协议 (14) 和参数自适应律 (20) 的驱动下可以实现实用固定时间二分编队跟踪控制.
□ 注 5. 根据定理1可知, 所设计的控制器不仅能使得误差信号$ \epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i\in{\cal{I}} $ 固定时间收敛到原点的任意小邻域, 而且能使得参数估计误差$ \tilde{\Theta}_i(t) $ 收敛到零的任意小邻域.
注 6. 根据 (18) 可知, 通过引入滤波信号$ q_{i}^{f}(t)$, $ H_{i}^{f}(t) $, $ \Phi_{i}^{f}(t) $ 和辅助变量$ \Lambda_i(t) $, $ \Upsilon_i(t) $, 并联立 (4) 可以推导出$ \Theta_{i} $ 与$ \Lambda_{i}(t),\; \Upsilon_{i}(t) $ 的关系. 进一步地, 可以构建包含$ \tilde{\Theta}_i(t) $ 的参数更新律 (20). 此外, 由定理1的证明过程可知, 当参数更新律设计为 (20) 且信号$ \Lambda_{i}(t) $ 满足较弱的 IE 条件时, 参数估计误差的收敛性可以确保.
3. 仿真实验
本节给出一个仿真实例以验证提出的控制协议的可行性. 考虑一个无人艇二分编队集群, 包含$ 7 $ 艘跟随无人艇和$ 1 $ 艘领航无人艇. 无人艇间的通信互动在图2中描述, 且$ E={\rm diag}\{1,\;1,\;-1,\; -1,\;-1,\; 1,\;-1\} $. 期望编队构型如下所示:
$$ \begin{split} &h_{1}=(1,\;1,\;0)^{\rm T},\;\ \ \qquad h_{2}=(3,\;1,\;0)^{\rm T},\;\\ & h_{3}=(-1,\;-1,\;0)^{\rm T},\;\quad h_{4}=(-3,\;-1,\;0)^{\rm T},\;\\ & h_{5}=(-3,\;-3,\;0)^{\rm T},\;\quad h_{6}=(2,\;3,\;0)^{\rm T},\;\\ & h_{7}=(-1,\;-3,\;0)^{\rm T} \end{split} $$ 跟随无人艇$ i,\; i=1,\;2,\;\cdots,\;7 $的动力学信息如下所示:
$$ \begin{split} &M_i= \left[\begin{array}{ccc} 26&0&0\\ 0&34&1.1\\ 0&1.1&2.8 \end{array}\right]\\& f_i(v_i(t))=-C_i(v_i(t))-D_i(v_i(t)) \end{split} $$ 式中,
$$ C_i(v_i(t))= \left[\begin{array}{c} C_i^{1}(v_i(t))u_i^3(t)\\ C_i^{2}(v_i(t))u_i^3(t)\\ -C_i^{1}(v_i(t))u_i^1(t)-C_i^{2}(v_i(t))u_i^2(t) \end{array} \right]$$ $$ D_i(v_i(t))= \left[\begin{array}{c} D_i^1(v_i(t))u_i^1(t)\\ D_i^2(v_i(t))u_i^2(t)+D_i^3(v_i(t))u_i^3(t)\\ D_i^4(v_i(t))u_i^2(t)+D_i^5(v_i(t))u_i^3(t) \end{array}\right] $$ $$ C_i^{1}(v_i(t))=-34u_i^2(t)-1.1u_i^3(t) $$ $$ C_i^{2}(v_i(t))=26u_i^1(t)$$ $$ D_i^{1}(v_i(t))=0.73+1.33|u_i^1(t)|+5.87(u_i^1(t))^2 $$ $$ D_i^{2}(v_i(t))=0.86+36.3|u_i^2(t)|+8.1|u_i^3(t)| $$ $$ D_i^{3}(v_i(t))=-0.11+0.85|u_i^2(t)|+3.5|u_i^3(t)| $$ $$ D_i^{4}(v_i(t))=-0.11-5.1|u_i^2(t)|-0.13|u_i^3(t)| $$ $$ D_i^{5}(v_i(t))=-1.9-0.1|u_i^2(t)|+0.75|u^3_i(t)| $$ 未知参数设置为$ \Theta_1=(1,\; 1.5,\; 5)^{\rm T},\; \Theta_2=(2.5,\; 3 ,$ $3.5)^{\rm T},\; \Theta_3\;=\;(0.5,\; 1.0,\; 8)^{\rm T},\; $ $ \Theta_4\;=\;(3.7,\; $ $ 3.7,\; $ $ 6)^{\rm T}, $ $ \Theta_5\;=\;-(0.7,\; $ $ 0.8,\; $ $ 5)^{\rm T},\; $ $ \Theta_6\;=\;-(1.1,\; $ $ 2.1,\; $ $ 7)^{\rm T} $和$ \Theta_7\;=\;-(2,\; $ $ 3,\; $ $ 6)^{\rm T} $. 已知函数选取为$ \phi_{i}\;(v_i\;(t))= \begin{pmatrix}\phi_{i}^{1}(v_i(t))& 0 &\phi_{i}^{2}(v_i(t))\\ 0& \phi_{i}^{3}(v_i(t)) &0\\ 0& 0 &\phi_{i}^{4}(v_i(t))\end{pmatrix}. $ 式中, $ \phi_{i}^{1}(v_i(t))= $ $\sin(u_i^1(t))\cos(1.5u_i^2(t)) + 2 $, $ \phi_{i}^{2}(v_i(t)) = ||\sin^{\rm T}(v_i(t))\;\times $$ \sin(v_i(t))|| $, $ \phi_{i}^{3}(v_i(t)) $ $ =\,\sin(2u_i^2(t))\cos(u_i^3(t))+2 $ 和$ \phi_{i}^{4}(v_i(t))= $ $ \sin(0.2u_i^1(t))\cos(0.2u_i^3(t))+2 $.
领航无人艇参考轨迹如下:
$$ \eta_0(t)= \left[\begin{array}{c} 3\sin(0.025\pi t)\\ 2\sin(0.05\pi t)\\ \pi\cos(0.02\pi t) \end{array}\right]$$ 无人艇系统状态初始值设置为$ \eta_1(0)\,=\,5(-1, -2.1,\;1.3)^{\rm T} $, $ v_1(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_2(0)\,=\,0.1(-1, -2.1,\;1.3)^{\rm T} $, $ v_2(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_3(0)\,=\,(-1, -2.1,\;1.3)^{\rm T} $, $ v_3(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_4(0) $ $ =\;(-1, -2.1,\;1.3)^{\rm T} $, $ v_4(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_5(0)\,=\,(-1, -2.1,\; 1.3)^{\rm T} $, $ v_5(0)\,=\,3(1,\;2,\;-1.3)^{\rm T} $, $ \eta_6(0)\,=\,10(-1, -2.1,\;1.3)^{\rm T} $, $ v_6(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $, $ \eta_7(0)\,=\,(-1, -2.1,\;1.3)^{\rm T} $ 和$ v_7(0)\,=\,(1,\;2,\;-1.3)^{\rm T} $. 参数估计初值选取为$ \eta_{01}(t)=4 $, $ \eta_{02}(t)=5 $, $ \eta_{03}(t)\,=\,6 $, $ \eta_{04}(t)\,=\, 7 $, $ \eta_{05}(t)\,=\,8 $, $ \eta_{06}(t)\,=\,9 $, $ \eta_{07}(t)\,=\,10 $, $ \hat{\Theta}_1(0)\,=\,(6, $ $ 6 $, $ 9)^{\rm T} $, $ \hat{\Theta}_2(0)\,=\,(7.5 $, $ 13.5 $, $ 7.5)^{\rm T} $, $ \hat{\Theta}_3(0)\,=\, (9.9 $, $ 5.1 $, $ 6.9)^{\rm T} $, $ \hat{\Theta}_4(0)\;=\;3(-4.1 $, $ -2.2 $, $ -3.7)^{\rm T} $, $ \hat{\Theta}_5(0)\,=\, 3(-3.5 $, $ 2.7 $, $ 0.7)^{\rm T} $, $ \hat{\Theta}_6(0)\,=\,3(7.1 $, $ 5 $, $ -1.7)^{\rm T} $ 和$ \hat{\Theta}_7(0)\,=\,3(1.3 $, $ 7.2 $, $ 1.7)^{\rm T} $. 命令滤波对应量的初始值设置为$ \bar{\alpha}_i(0)\,=\,i(0.5,\;1,\;0.75)^{\rm T} $. 控制器参数选取为$ c_1=c_2=10,\; m_1=0.5,\; m_2 = 1.5,\; w_i=1.6,\; k_{i1}= k_{i2}=25 $ 和$ \beta_i=0.1 $.
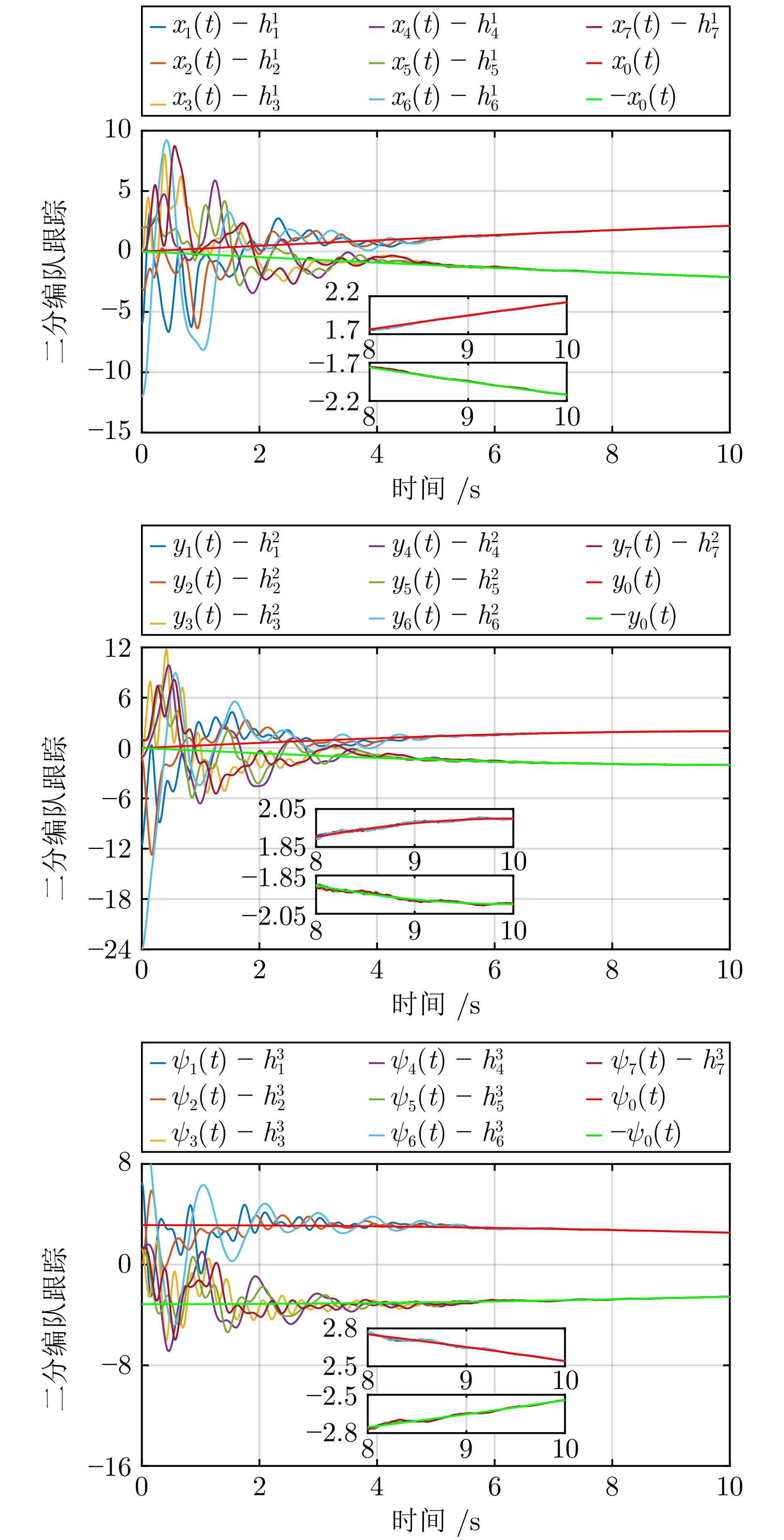
记$ \epsilon_{i1}(t) = (\epsilon_{i1}^1(t),\,\epsilon_{i1}^2(t),\,\epsilon_{i1}^3(t))^{\rm T}, $ $ \epsilon_{i2}(t) = $ $ (\epsilon_{i2}^1(t),\, \epsilon_{i2}^2(t),\,\epsilon_{i2}^3(t))^{\rm T}, $ $ \Theta_i = (\Theta_i^1,\,\Theta_i^2,\,\Theta_i^3)^{\rm T} $ 和$ \hat{\Theta}_i\,(t) = $ $(\hat{\Theta}_i^1(t), \hat{\Theta}_i^2(t) $, $ \hat{\Theta}_i^3(t))^{\rm T} $. 参数估计误差轨迹分别在图3和图4中描述. 观察图3和图4可知, 参数估计误差信号$ \tilde{\eta}_{0i}(t),\, i = 1,\,2,\,\cdots,\,7 $ 在 2 ($ 2 < \frac{1}{\kappa_1(1-\iota_1)} + \frac{1}{\kappa_2(\iota_2-1)} = 17.73 $) s内收敛到零; 参数估计误差信号$ \tilde{\Theta}_{i}(t), i=1,\;2,\;\cdots,\;7 $ 在 4 ($ 4 < \frac{1}{\bar{\kappa}_1c(1-\bar{\iota}_1)} + \frac{1}{\bar{\kappa}_2c(\bar{\iota}_2-1)} > 26.1 $) s内收敛到零的小邻域. 局部跟踪误差轨迹$ \epsilon_{i1}(t), \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7 $ 在图5中给出, 它们在5 ($ 5< 26.1 $) s内收敛到零的小邻域. 图6揭示了在提出的控制协议下, 多无人艇系统可实现固定时间二分编队跟踪控制.
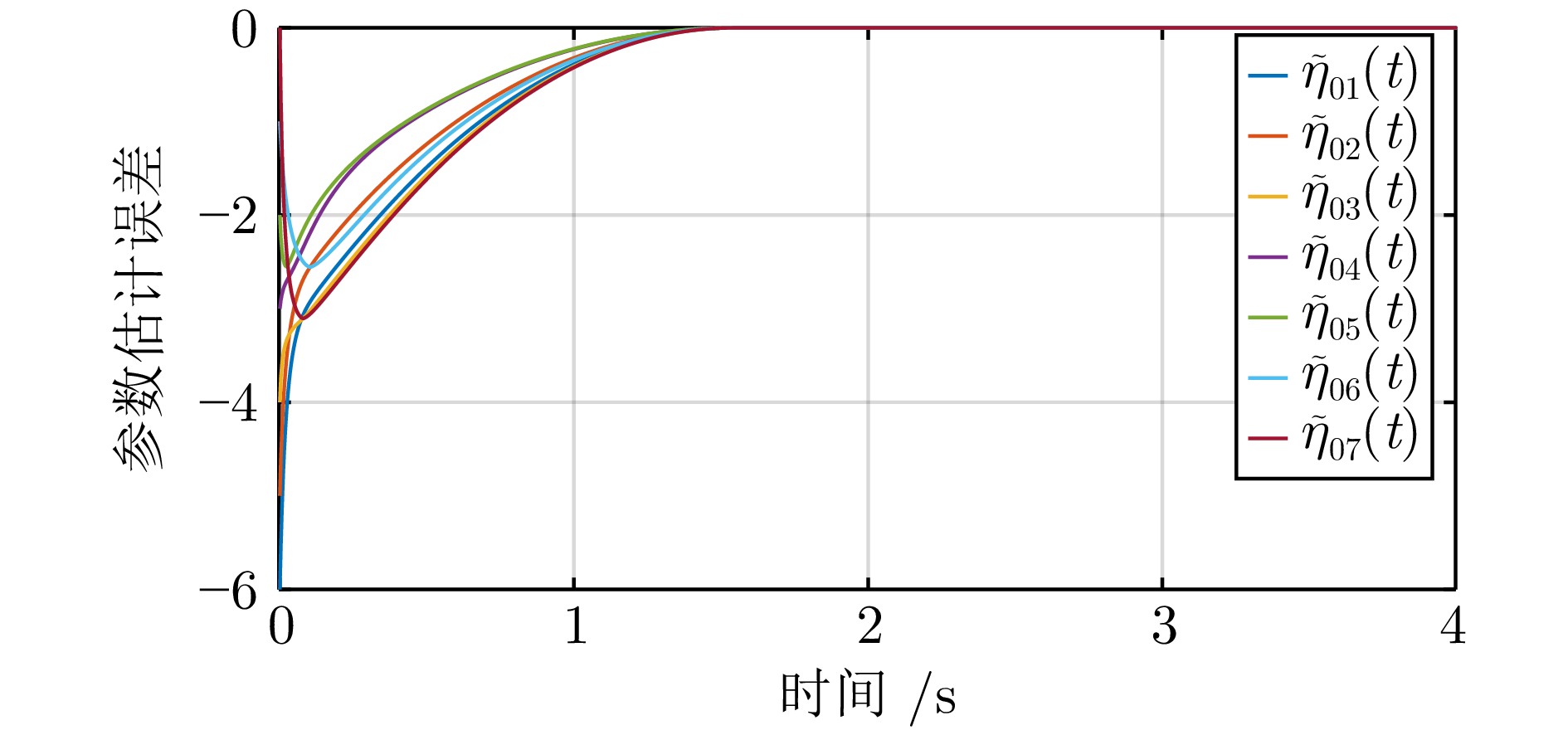 图 3 参数估计误差 $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 3 Parameter estimation errors $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$
图 3 参数估计误差 $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 3 Parameter estimation errors $\tilde{\eta}_{0i}(t),\; i=1,\;2,\;\cdots,\;7$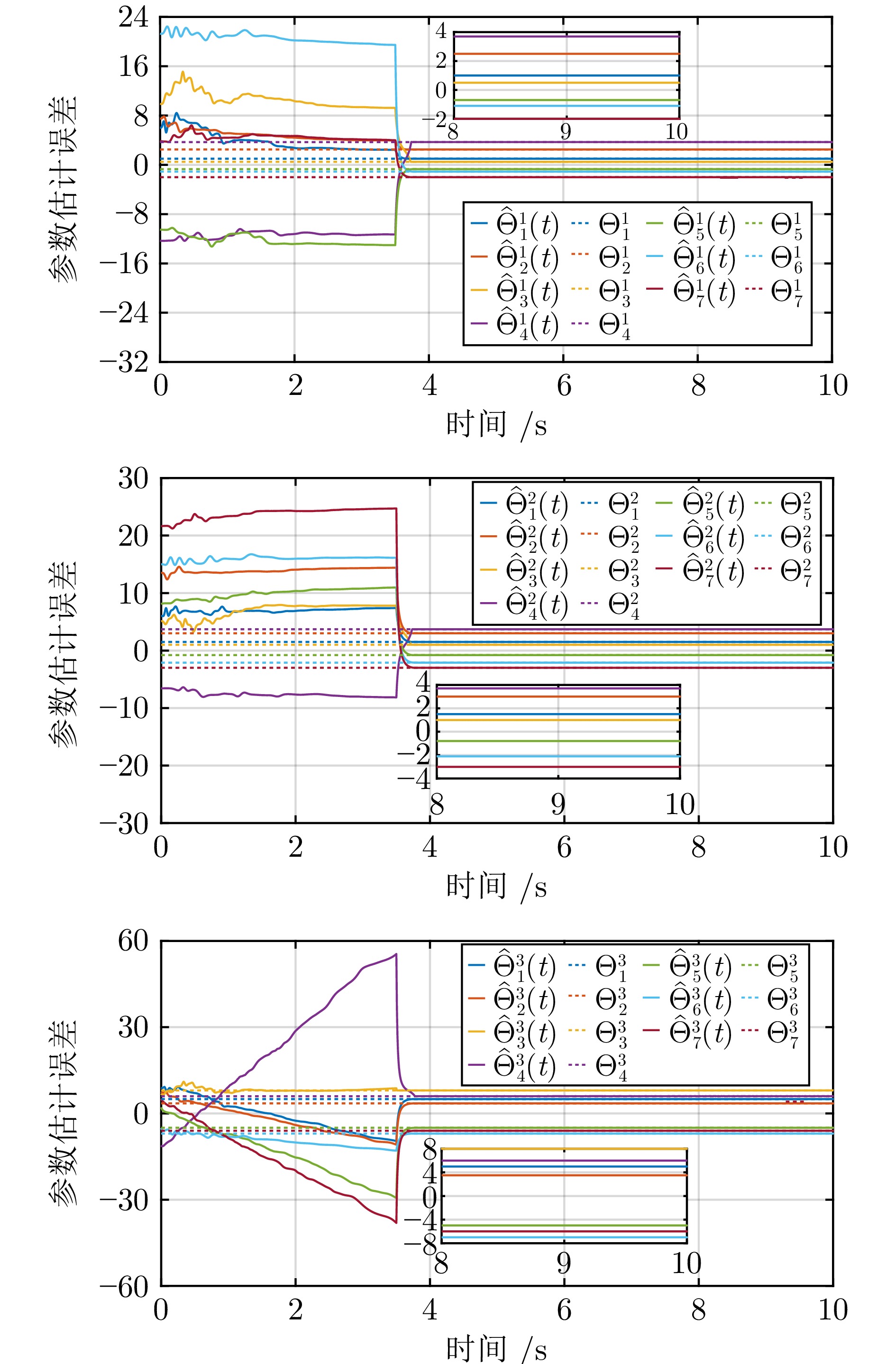 图 4 参数估计误差$\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 4 Parameter estimation errors $\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$
图 4 参数估计误差$\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 4 Parameter estimation errors $\tilde{\Theta}_{i}(t),\; i=1,\;2,\;\cdots,\;7$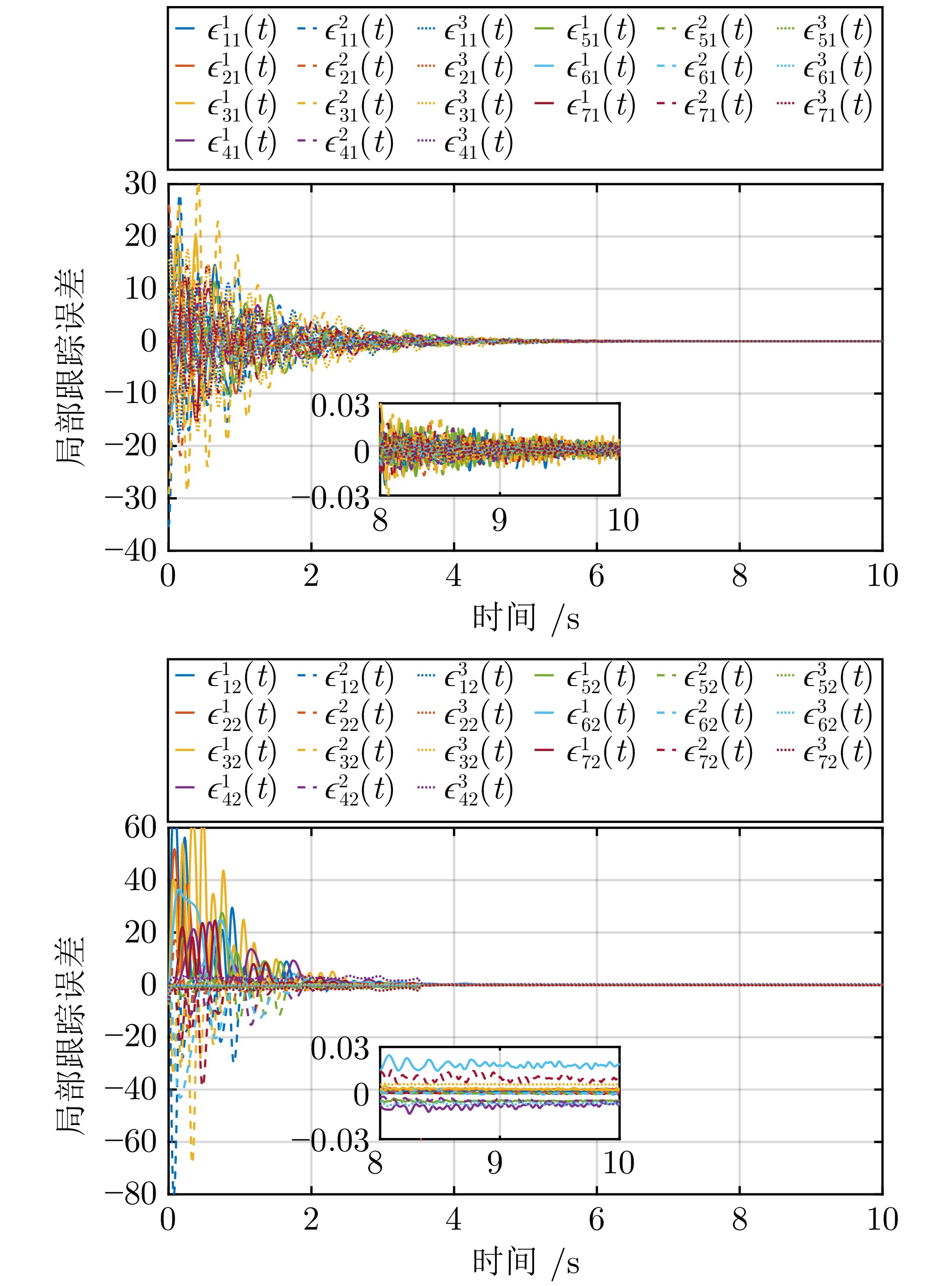 图 5 局部跟踪误差$\epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 5 Local tracking errors $\epsilon_{i1}(t),\;$ $\epsilon_{i2}(t),\;$ $i=1,\;2,\;\cdots,\;7$
图 5 局部跟踪误差$\epsilon_{i1}(t),\; \epsilon_{i2}(t),\; i=1,\;2,\;\cdots,\;7$Fig. 5 Local tracking errors $\epsilon_{i1}(t),\;$ $\epsilon_{i2}(t),\;$ $i=1,\;2,\;\cdots,\;7$4. 结束语
通过设计基于命令滤波与复合学习的反推控制协议, 解决了模型参数不确定下多无人艇系统的固定时间二分编队跟踪控制问题. 与已有的相关工作相比, 本文具有以下优势: 通过引入命令滤波技术, 提出的控制协议避免了计算虚拟控制输入的导数, 极大地简化了分布式控制器的设计; 通过引入复合学习技术, 在不需要 PE 条件的情况下, 保证了跟踪误差和参数估计误差的固定时间收敛性. 未来主要关注有向符号图下具有时变参数不确定性影响的多无人艇系统固定时间分布式控制问题, 以及多无人机−无人艇跨域协同控制问题.
-

图 6 生成样本(随机, Batchsize = 2 000, 卡通人脸)
Fig. 6 Generated samples (random, 2 000, cartoon face)

图 7 生成样本(构建, Batchsize = 2 000, 卡通人脸)
Fig. 7 Generated samples (constructing, 2 000, cartoon face)

图 8 生成样本(随机, Batchsize 2 048, Cifar10)
Fig. 8 Generated samples (random, 2 048, Cifar10)

图 9 生成样本(构建, Batchsize = 2 048, Cifar10)
Fig. 9 Generated samples (constructing, 2 048, Cifar10)

图 11 生成样本(128 (正则化), 卡通人脸)
Fig. 11 Generated samples (128 (regularizer), cartoon face)
表 1 不同Batchsize下总体覆盖率
Table 1 Total coverage rate of different Batchsize
数据集 Batchsize 构建采样(%) 随机采样(%) 差距值(%) 卡通人脸 512 80.68 99.96 19.28 1 024 89.20 99.96 10.76 2 000 93.20 97.59 4.39 Cifar10 512 78.57 99.33 20.76 1 024 87.54 98.30 10.76 2 048 92.52 98.30 5.78  下载: 导出CSV
下载: 导出CSV
表 2 不同Batchsize下$ KL(f_{X_i}(x)||f_X(x)) $数据
Table 2 $ KL(f_{X_i}(x)||f_X(x)) $ data under difierent Batchsize
数据集 Batchsize 均值 标准差 最小值 中值 最大值 卡通人脸 128 1.3375 0.0805 1.1509 1.3379 1.6156 1 024 0.3109 0.0147 0.2849 0.3110 0.3504 1 024* 0.2366 0.0084 0.2154 0.2365 0.2579 2 000 0.1785 0.0089 0.1652 0.1778 0.1931 2 000* 0.1144 0.0042 0.1049 0.1150 0.1216 Cifar10 128 1.4125 0.0772 1.1881 1.4155 1.6037 1 024 0.3499 0.0155 0.3215 0.3475 0.3886 1 024* 0.2692 0.0063 0.2552 0.2687 0.2836 2 048 0.1994 0.0085 0.1830 0.2004 0.2148 2 048* 0.1372 0.0040 0.1281 0.1372 0.1462 带"*"项是构建子样本集相关数据, 下同
下载: 导出CSV
表 3 卡通人脸数据集实验结果对比
Table 3 Experimental results comparison of cartoon face dataset
Batchsize epoch 测试误差($ \times10^{-3} $) KL IS ($ \sigma\times10^{-2} $) 1 024 135 8.03 $ \pm $ 2.12 0.1710 3.97 $ \pm $ 2.62 1 024* 135 8.23 $ \pm $ 2.10 0.1844 3.82 $ \pm $ 2.02 2 000 200 7.68 $ \pm $ 2.21 0.1077 3.95 $ \pm $ 2.32 2 000* 200 7.18 $ \pm $ 2.13 0.0581 4.21 $ \pm $ 2.53
下载: 导出CSV
表 4 Cifar10数据集实验结果对比
Table 4 Experimental results comparison of Cifar10 dataset
Batchsize epoch 测试误差($ \times10^{-2} $) KL IS ($ \sigma\times10^{-2} $) 1 024 100 1.43 $ \pm $ 0.38 0.2146 5.44 $ \pm $ 6.40 1 024* 100 1.48 $ \pm $ 0.35 0.2233 5.36 $ \pm $ 6.01 2 048 200 1.40 $ \pm $ 0.39 0.2095 5.51 $ \pm $ 5.83 2 048* 200 1.35 $ \pm $ 0.37 0.1890 5.62 $ \pm $ 5.77
下载: 导出CSV
表 5 卡通人脸数据集不同策略对比
Table 5 Different strategies comparison of cartoon face dataset
Batchsize epoch 测试误差($ \times10^{-3} $) KL IS ($ \sigma\times10^{-2} $) 1 024* 135 8.23 $ \pm $ 2.10 0.1844 3.82 $ \pm $ 2.02 2 000* 200 7.18 $ \pm $ 2.13 0.0581 4.21 $ \pm $ 2.53 128 (a) 25 8.32 $ \pm $ 2.07 0.1954 3.62 $ \pm $ 2.59 128 (b) 25 8.15 $ \pm $ 2.15 0.1321 3.92 $ \pm $ 4.59 128 (c) 25 8.07 $ \pm $ 2.10 0.1745 3.89 $ \pm $ 4.45 128 (d) 25 8.23 $ \pm $ 2.26 0.1250 4.02 $ \pm $ 3.97
下载: 导出CSV
表 6 Cifar10数据集不同策略对比
Table 6 Different strategies comparison of Cifar10 dataset
Batchsize epoch 测试误差($ \times10^{-2} $) KL IS ($ \sigma\times10^{-2} $) 1 024* 100 1.48 $ \pm $ 0.35 0.2233 5.36 $ \pm $ 6.01 2 048* 200 1.35 $ \pm $ 0.37 0.1890 5.62 $ \pm $ 5.77 128 (a) 25 1.81 $ \pm $ 0.41 0.2813 4.44 $ \pm $ 3.66 128 (b) 25 1.64 $ \pm $ 0.40 0.2205 4.61 $ \pm $ 3.80 128 (c) 25 1.70 $ \pm $ 0.41 0.2494 4.62 $ \pm $ 4.80 128 (d) 25 1.63 $ \pm $ 0.42 0.2462 4.94 $ \pm $ 5.79
下载: 导出CSV
-
[1] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S et al. Generative adversarial nets. In: Proceedings of International Conference on Neural Information Processing Systems. Montreal, Canada: 2014. 2672-2680 [2] Creswell A, White T, Dumoulin V, Arulkumaran K, Sengupta B, Bharath A A. Generative adversarial networks: An overview. IEEE Signal Processing Magazine, 2018, 35(1): 53-65 doi: 10.1109/MSP.2017.2765202 [3] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003Wang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: The state of the art and beyond. Acta Automatica Sinica, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003 [4] 王万良, 李卓蓉. 生成式对抗网络研究进展. 通信学报, 2018, 39(2): 135-148 https://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201802014.htmWang Wan-Liang, Li Zuo-Rong. Advances in generative adversarial network. Journal of Communications, 2018, 39(2): 135-148 https://www.cnki.com.cn/Article/CJFDTOTAL-TXXB201802014.htm [5] Salimans T, Goodfellow I J, Zaremaba W, Cheung V, Radford A, Chen X. Improved techniques for training GANs. In: Proceedings of International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. [6] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784v1, 2014. [7] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. In: Proceedings of International Conference on Learning Representations. San Juan, Puerto Rico: 2016. [8] Denton E, Chintala S, Szlam A, Fergus R. Deep generative image using a Laplacian pyramid of adversarial networks. In: Proceedings of International Conference on Neural Information Processing Systems. Montreal, Canada: 2015. 1486-1494 [9] Odena A. Semi-Supervised learning with generative adversarial networks. arXiv preprint arXiv: 1606.01583v2, 2016. [10] Donahue J, Krahenbuhl K, Darrell T. Adversarial feature learning. In: Proceedings of International Conference on Learning Representations. Toulon, France: 2017. [11] Zhang H, Xu T, Li H S, Zhang S T, Wang X G, Huang X L et al. StackGAN: text to photo-realistic image synthesis with stacked generative adversarial networks. In: Proceedings of International Conference on Computer Vision. Venice, Italy: 2017. [12] Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P. InfoGAN: interpretable representation learning by information maximizing generative adversarial nets. In: Proceedings of International Conference on Neural Information Processing Systems. Barcelona, Spain: 2016. [13] Qi G J. Loss-sensitive generative adversarial networks on lipschitz densities. arXiv preprint arXiv: 1701.06264v5, 2017. [14] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. arXiv preprint arXiv: 1701.07875v3, 2017. [15] Yu L T, Zhang W N, Wang J, Yu Y. SeqGAN: sequence generative adversarial nets with policy gradient. In: Proceedings of The Thirty-First AAAI Conference on Artificial Intelligence. San Francisco, USA: 2017. [16] 王功明, 乔俊飞, 乔磊. 一种能量函数意义下的生成式对抗网络. 自动化学报, 2018, 44(5): 793-803 doi: 10.16383/j.aas.2018.c170600Wang Gong-Ming, Qiao Jun-Fei, Qiao Lei. A generative adversarial network in terms of energy function. Acta Automatica Sinica, 2018, 44(5): 793-803 doi: 10.16383/j.aas.2018.c170600 [17] Do-Omri A, Wu D L, Liu X H. A self-training method for semi-supervised GANs. arXiv preprint arXiv: 1710.10313v1, 2017. [18] Gulrajani I, Ahmed G, Arjovsky M, Dumoulin V, Courville A. Improved training of wasserstein GANs. In: Proceedings of International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 5769-5579 [19] Daskalakis C, Ilyas A, Syrgkanis V, Zeng H Y. Training GANs with optimism. In: Proceedings of International Conference on Learning Representations. Vancouver, Canada: 2018. [20] Mescheder L, Geiger A, Nowozin S. Which training methods for GANs do actually converge? In: Proceedings of International Conference on Machine Learning. Stockholm, Sweden: 2018. 3481-3490 [21] Keskar N S, Mudigere D, Nocedal J, Smelyanskiy M, Tang P T P. On large-batch training for deep learning: generalization GAP and sharp minmax. In: Proceedings of International Conference on Learning Representations. New Orleans, USA: 2017. [22] Goyal P, Dollar P, Girshick R, Noordhuis P, Wesolowski L, Kyrola A et al. Accurate, large minibatch SGD: training ImageNet in 1 hour. arXiv preprint arXiv: 1706.02677v2, 2018. [23] Li M, Zhang T, Chen Y Q, Smola A J. Efficient mini-batch training for stochastic optimization. In: Proceedings of Acm Sigkdd International Conference on Knowledge Discovery & Data Mining. New York, USA: 2014. 661-670 [24] Bottou L, Frank E C, Nocedal J. Optimization methods for large-scale machine learning. arXiv preprint arXiv: 1606.04838v3, 2018. [25] Dekel O, Gilad-Bachrach R, Shamir O, Xiao L. Optimal distributed online prediction using mini-batches. Journal of Machine Learning Research, 2012, 13(1): 165-202 [26] 郭懋正. 实变函数与泛函分析. 北京: 北京大学出版社, 2005. 67-69Guo Mao-Zheng. Real Analysis and Functional Analysis. Beijing: Peking University press, 2005. 67-69 [27] 何书元. 概率论. 北京: 北京大学出版社, 2006. 52-56He Shu-Yuan. Probability Theory. Beijing: Peking University press, 2006. 52-56 [28] Xu Q T, Huang G, Yuan Y, Huo C, Sun Y, Wu F et al. An empirical study on evaluation metrics of generative adversarial networks. arXiv preprint arXiv: 1806.07755v2, 2018. 期刊类型引用(5)
1. 王本斐,张荣辉,冯国栋,Manandhar Ujjal,郭戈. 基于事件触发的直流微电网无差拍预测控制. 自动化学报. 2024(03): 475-485 .  本站查看
本站查看2. 米阳,张浩杰,钱翌明,邢海军,龚锦霞,孙改平. 基于扩散算法的无下垂分布式储能控制. 上海交通大学学报. 2024(06): 836-845 . 百度学术3. 王睿,孙秋野,张化光. 信息能源系统的信-物融合稳定性分析. 自动化学报. 2023(02): 307-316 . 本站查看4. 邢阳阳,马冬梅,党晓圆,关正伟. 不对称电网故障下直流母线电压平衡控制方法. 计算机仿真. 2023(05): 162-165+196 . 百度学术5. 谭久俞,宋鑫,王思远. 微电网负荷平衡优化运行控制技术及仿真分析. 科技创新与应用. 2023(31): 75-78 . 百度学术其他类型引用(8)
-

 下载:
下载:








计量
- 文章访问数: 1105
- HTML全文浏览量: 218
- PDF下载量: 149
- 被引次数: 13
