

Simultaneous Fault Detection and Control of Two-dimensional Fornasini-Marchesini Systems
-
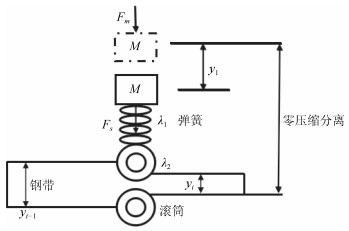
摘要: 本文研究二维Fornasini-Marchesini (FM)系统的同时故障检测与控制问题.针对故障和干扰的有限频特性, 设计满足有限频性能指标的故障检测滤波器/控制器, 在实现故障检测目标的同时兼顾控制性能.借助于二维广义KYP引理, 将有限频性能指标转化为矩阵不等式条件.在此基础上, 采用构造切平面的方法以及两步算法解决设计过程中出现的非凸问题.最后, 将所提出的方法应用于带钢轧制过程以验证其有效性.Abstract: The paper addresses the problem of integrated fault detection and control of two-dimensional (2-D) Fornasini-Marchesini (FM) systems. A fault detection filter/controller is designed simultaneously to detect faults in finite frequency domain and satisfy some control specifications. By means of the generalized KYP lemma, the finite frequency performance indices are transformed into matrix inequality conditions. Based on these conditions, a method of constructing a tangent plane and a two-step algorithm are proposed to solve the obtained non-convex problem. The effectiveness of the proposed method is illustrated by an example about metal rolling process.
-
Key words:
- 2-D system /
- FM model /
- fault detection /
- integrated design
1) 本文责任编委 邓方 -
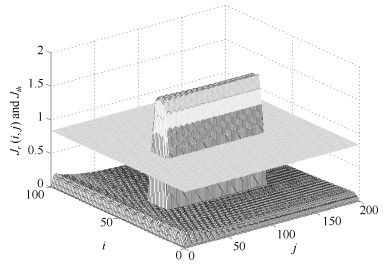
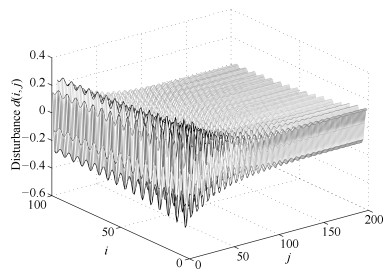
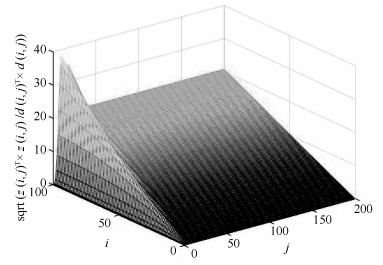
图 4 三维空间中的残差评价函数$ {J_r}(i, j)$和阈值$ {J_{th}}$
Fig. 4 Residual evalution function $ {J_r}(i, j)$ and threshold $ {J_{th}}$ in three-dimensional space
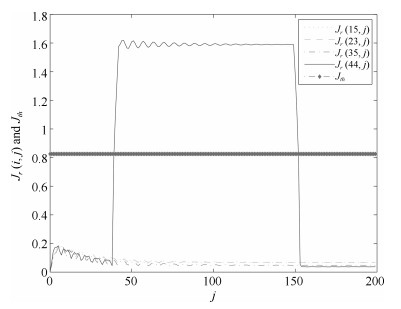
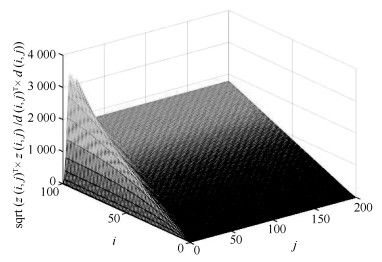
图 5 二维空间中的残差评价函数$ {J_r}(i, j)$和阈值$ {J_{th}}$
Fig. 5 Residual evalution function $ {J_r}(i, j)$ and threshold $ {J_{th}}$ in two-dimensional space
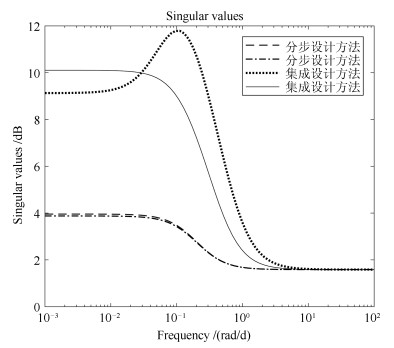
图 6 故障到残差传递函数${G_{\tilde yf}}({\omega _1}, {\omega _2})$的奇异值比较
Fig. 6 Singular value comparison of transfer functions ${G_{\tilde yf}}({\omega _1}, {\omega _2})$ from fault to residual signal
-
[1] Kaczorek T. Two-Dimensional Linear Systems. Berlin: Springer-Verlag, 1985. [2] Du C, Xie L, Control and Filtering of Two-Dimensional Systems. Berlin: Springer-Verlag, 2002. [3] Kaczorek T. New stability tests of positive standard and fractional linear systems. Circuits and Systems, 2011, 20(4): 261-268 [4] Ye S X, Wang W Q. Stability analysis and stabilization for a class of 2-D nonlinear discrete systems. International Journal of Systems Science, 2011, 42(5): 839-851 doi: 10.1080/00207721.2010.518255 [5] 程子豪, 卜旭辉, 梁嘉琪, 闫帅可.一类存在数据丢失二维离散系统的$H_\infty$滤波, 控制理论与应用, 2016, 33(4): 523-529 https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201604014.htmCheng Zi-Hao, Bu Xu-Hui, Liang Jia-Qi, Yan Shuai-Ke. $H$-infinity filtering for a class of two-dimensional discrete systems with data dropouts. Control Theory & Applications, 2016, 33(4): 523-529 https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201604014.htm [6] Ding D W, Du X, Li X L. Finite-frequency model reduction of two-dimensional digital filters. IEEE Transactions on Automatic Control, 2015, 60(6): 1624-1629 doi: 10.1109/TAC.2014.2359305 [7] 王振华, 沈毅.广义系统的有限频域故障估计器设计.自动化学报, 2018, 44(3): 545-551 doi: 10.16383/j.aas.2018.c160500Wang Zhen-Hua, Shen Yi. Fault estimator design for descriptor systems in finite frequency domain. Acta Automatica Sinica, 2018, 44(3): 545-551 doi: 10.16383/j.aas.2018.c160500 [8] 周萌, 王振华, 王昶, 沈毅. Lipschitz非线性系统的${H_-}/{L_\infty} $故障检测观测器设计.控制理论与应用, 2018, 35(6): 778-785 https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201806007.htmZhou Meng, Wang Zhen-Hua, Wang Chang, Shen Yi. ${H_-}/{L_\infty} $ Fault detection observer design for lipschitz systems. Control Theory & Applications, 2018, 35(6): 778-785 https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201806007.htm [9] 汤文涛, 王振华, 王烨, 沈毅.基于未知输入集员滤波器的不确定系统故障诊断.自动化学报, 2018, 44(9): 1717-1724 doi: 10.16383/j.aas.2017.c170123Tang Wen-Tao, Wang Zhen-Hua, Wang Ye, Shen Yi. Fault diagnosis for uncertain systems based on unknown input set-membership filters. Acta Automatica Sinica, 2018, 44(9): 1717-1724 doi: 10.16383/j.aas.2017.c170123 [10] 董炜, 刘明明, 王良顺, 赵辉, 辜勋, 基于群决策的道岔控制电路故障诊断方法.自动化学报, 2018, 44(6): 1005-1014 doi: 10.16383/j.aas.2017.c160715Dong Wei, Liu Ming-Ming, Wang Liang-Shun, Zhao Hui, Gu Xun. Fault diagnosis for railway turnout control circuit based on group decision making. Acta Automatica Sinica, 2018, 44(6): 1005-1014 doi: 10.16383/j.aas.2017.c160715 [11] Bisiacco M, Valcher M E. Observer-based fault detection and isolation for 2D state-space model. Multidimensional Systems and Signal Processing, 2006, 17(2): 219-241 [12] Wu L, Yao X, Zheng W X. Generalized ${H_2}$ fault detection for two-dimensional markovian jump systems. Automatica, 2012, 48(12): 1741-1750 [13] Bisiacco M, Valcher M E. The general fault detection and isolation problem for 2D state-space models. Systems & Control Letters, 2006, 55(11): 894-899 [14] Ren Y Y, Ding D W. Fault detection for two-dimensional Roesser systems with sensor faults. IEEE Access, 2016, 4: 6197-6203 doi: 10.1109/ACCESS.2016.2613114 [15] Ren Y Y, Ding D W. Finite-frequency fault detection for two-dimensional Fornasini-Marchesini dynamical systems. International Journal of Systems Science, 2017, 48(12): 2610-2621 doi: 10.1080/00207721.2017.1333169 [16] Jacobson C A, Nett C N. An integrated approach to control and diagnostics using the four parameter controller. IEEE Control Systems Magazine, 1991, 11(2): 22-29 [17] Wang H, Yang G H. Simultaneous fault detection and control for uncertain linear discrete time systems. IET Control Theory & Applications, 2009, 3(5): 583-594 [18] Marcos A S, Balas G J. A robust integrated controller$/$diagnosis aircraft application. International Journal of Robust and Nonlinear Control, 2005, 15(12): 531-551 doi: 10.1002/rnc.1010 [19] Khosrowjerdi M J, Nikoukhah R, Safari S N. A mixed ${H_2}/{H_\infty} $ approach to simultaneously fault detection and control. Automatica, 2004, 40(2): 261-267 doi: 10.1016/j.automatica.2003.09.011 [20] Ren Y Y, Ding D W. Integrated fault detection and control for two-dimensional Roesser systems. International Journal of Systems Science, 2017, 15(2): 722-731 [21] Fornasini E, Marchesini G. State-space realization theory of two-dimensional filters. IEEE Transactions on Automatic Control, 1976, 21(4): 484-492 doi: 10.1109/TAC.1976.1101305 [22] Li X W, Gao H J. Finite Frequency Analysis and Synthesis Based on Generalized KYP Lemma[Ph. D. dissertation], Harbin Institute of Technology, 2015. [23] Skelton R E, Iwasaki T, Grigoriadis K M. A Unified Algebraic Approach to Linear Control Design. USA: Taylor & Francis, 1998. [24] Wang H, Yang G H. A finite frequency domain approach to fault detection for linear discrete-time systems. International Journal of Control, 2008, 81(7): 1162-1171 doi: 10.1080/00207170701691513 [25] Li X W, Gao H J. Generalized Kalman-Yakubovich-Popov lemma for 2-D FM LSS model. IEEE Transactions on Automatic Control, 2012, 57(12): 3090-3103 doi: 10.1109/TAC.2012.2200370 [26] Hinamoto T. Stability of 2-D discrete systems described by the Fornasini-Marchesini second model. IEEE Transactions on Circuits Systems I: Fundamental Theory and Applications, 1997, 44(3): 254-257 doi: 10.1109/81.557373 [27] Li X J, Yang G H. Fault detection in finite frequency domain for multi-delay uncertain systems with application to ground vehicle. International Journal of Robust and Nonlinear Control, 2014, 25(18): 3780-3798 [28] Iwasaki T, Hara S. Feedback control synthesis of multiple domain speciflcations via generalized KYP lemma. International Journal of Robust and Nonlinear Control, 2007, 17(5): 415-434 [29] Wang Z, Shang H. Kalman filter based fault detection for two-dimensional systems. Journal of Process Control, 2015, 28: 83-94 doi: 10.1016/j.jprocont.2015.03.002 [30] Ding S X. Model-Based Fault Diagnosis Techniques: Design Schemes Algorithms and Tools. Berlin: Springer-Verlag, 2008. -

 下载:
下载:

计量
- 文章访问数: 1655
- HTML全文浏览量: 228
- PDF下载量: 189
- 被引次数: 0
