

A New Algorithm for Mining High Utility Sequential Patterns Based on Pattern-growth
-
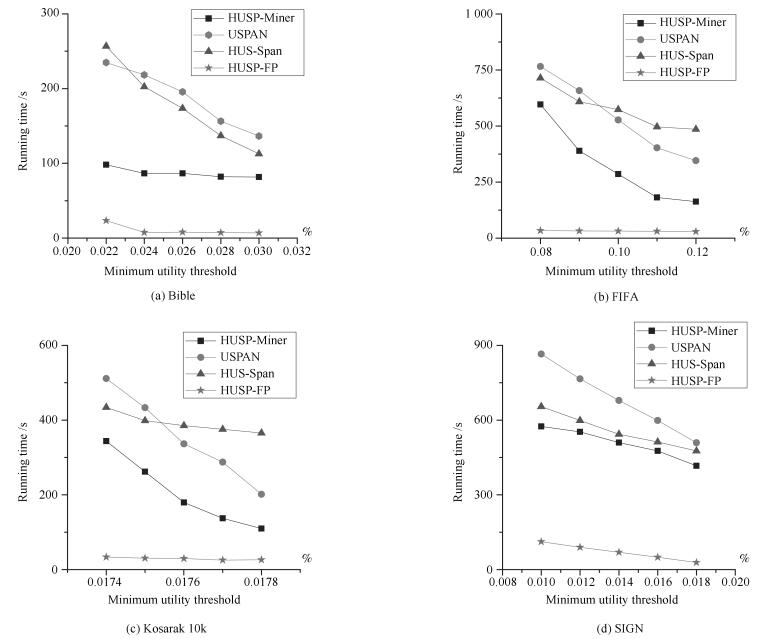
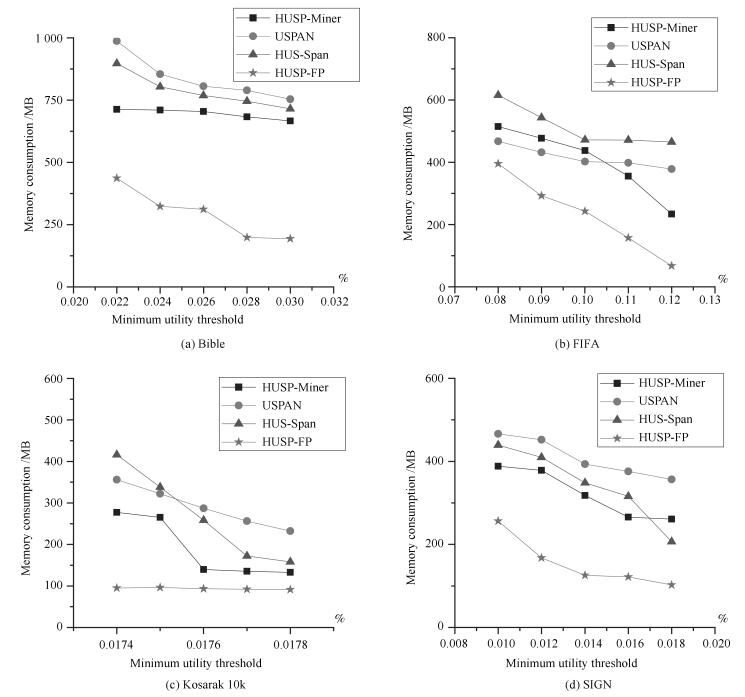
摘要: 高效用序列模式挖掘是数据挖掘领域的一项重要内容, 在生物信息学、消费行为分析等方面具有重要的应用.与传统基于频繁项模式挖掘方法不同, 高效用序列模式挖掘不仅考虑项集的内外效用, 更突出项集的时间序列含义, 计算复杂度较高.尽管已经有一定数量的算法被提出应用于解决该类问题, 挖掘算法的时空效率依然成为该领域的主要研究热点问题.鉴于此, 本文提出一个基于模式增长的高效用序列模式挖掘算法HUSP-FP.依据高效用序列项集必须满足事务效用闭包属性要求, 算法首先在去除无用项后建立全局树, 进而采用模式增长方法从全局树上获取全部高效用序列模式, 避免产生候选项集. 在实验环节与目前效率较好的HUSP-Miner、USPAN、HUS-Span三类算法进行了时空计算对比, 实验结果表明本文给出算法在较小阈值下仍能有效挖掘到相关序列模式, 并且在计算时间和空间使用效率两方面取得了较大的提高.Abstract: High utility sequential pattern mining is an important research topic in data mining. It plays an important role in many applications, such as bioinformatics and consumer behavior analysis. Difierent from traditional itemsets mining methods which take the appear numbers or the utility of the itemsets into account, high utility sequential pattern mining not only concerns the inner and outer utility but also the sequences of the items in the transactions, its computational complexity increases compared to the single frequent itemsets mining or high utility itemsets mining. Although a number of algorithms have been proposed to solve such problem, the e–ciency of mining algorithms is still the main research topic in this fleld. In view of this, this paper proposes an e–cient high utility sequential pattern mining algorithm named HUSP-FP based on pattern growth. Because the transaction utility value of the sequence itemset should satisfy the downward closure property, a global tree is established based on the sequential items in the transactions of the dataset after removing useless items. the HUSP-FP algorithm can e–ciently extract sequential patterns from global tree without generating candidate itemsets. Comparing with the state-of-the-art high-utility sequential pattern mining algorithms of HUSP-Miner、USPAN and HUS-Span in our experiments, the proposed HUSP-FP out-performed its counterpart signiflcantly.
-
Key words:
- High utility sequential pattern /
- pattern growth /
- downward closure property /
- data mining
-
煤、石油、天然气等传统能源日渐枯竭, 可再生能源的利用逐渐得到各个国家的重视. 风力发电和光伏发电是目前应用最为广泛的可再生能源发电技术[1]. 然而, 风能和光伏能源固有的随机和间歇性特点会对电网的稳定运行和电能质量带来不利影响. 为了解决上述问题, 微电网作为集成分布式电源的解决方案, 已成为当前电力行业的研究热点[2-3]. 微电网是由分布式发电单元(微源)、储能装置、相关负荷、电力电子转换接口和通信网络组成的小型发配电系统. 目前, 现有微电网工程主要以交流微电网形式存在, 以匹配传统交流电网和交流用电设备[4]. 随着直流可再生能源和直流负载日益增多, 通过直流母线相连组成直流微电网, 不仅可以降低交流/直流功率转换的功率损耗, 还无需考虑频率控制和无功功率问题.
电压平衡和负荷分配(负载共享)是直流微电网的两个基本控制任务[5]. 电压平衡能够确保母线所连接负载的正常工作, 负荷分配可以防止任一微源的过度出力. 直流微电网的母线电压能够反映系统的功率平衡, 通过控制微电网的母线电压平衡, 即可控制各微源、储能装置及负载间的功率平衡, 从而维持微电网的稳定运行[6]. 微电网实现微源间负荷的合理分配是微电网协调控制的重要目标. 文献[7-9]通过不同方法对负荷分配及电压平衡进行研究, 然而, 这两个基本控制任务是相互竞争的, 在实现母线电压平衡的同时需要保证负荷公平分配. 为了实现这一控制目标, 集中式控制、分散式控制以及分布式控制方法得到了广泛的应用[10]. 集中式控制需要获取全局的状态信息, 对通信系统具有高度的依赖性, 一旦某个子系统出现故障, 将会导致整个系统无法正常运行, 降低了系统运行的可靠性[11]. 与集中控制相比, 分散控制仅需局部信息就地控制, 不会因为个别单元的故障影响其余单元. 但由于缺少各单元之间的通信联系, 很难进行系统层级的优化调节, 往往达不到期望的效果. 而分布式控制可以结合两者的优点, 利用局部通信获取反应全局状态的有效信息, 从系统层面协调控制各分布式发电单元[12]. 因此急需一种基于分布式控制策略的下垂控制器从系统层面解决微电网的电压平衡和负荷分配问题, 下面对相关文献进行综述.
下垂控制已在直流微电网的控制中得到广泛应用. 文献[13]采用传统下垂控制对直流母线电压进行调整, 但该下垂方法会导致电流共享差, 同时还会导致直流母线电压下降. 为此文献[14]提出一种适用于直流微电网并联变换器的下垂指数控制算法. 通过在线计算虚拟电阻来合理调节负载分配, 有效降低了循环电流. 虽然下垂控制减少了对通信系统的依赖, 保证了该控制方法的可靠性, 但控制器只检测本单元的直流母线电压, 使得工作模式只由母线电压决定. 与下垂控制相比, 分层控制对负荷分配和电压平衡的控制更加全面, 该控制方法进一步提高了系统的可靠性. 文献[15]提出了一种基于分布式算法的直流微电网自适应下垂控制策略, 以达到均流和调压的目的. 但算法的稳定性和收敛速度会受到通讯延时和测量误差的影响. 文献[16]提出一种电压电流的双补偿分布式二次控制方法来解决线缆阻抗造成的负荷分配失衡问题. 但前提条件是线缆阻抗较小, 否则将无法保证输出电流的精度. 为提高微源电压平衡和负载共享精度, 文献[17]提出了一种改进的分布式二次控制方案, 该方案同时采用移压和调坡方法, 在减小电压偏差的同时, 提高负载共享精度, 文献[18]通过引入直流母线电压二次协调控制来实现电压恢复和电流的精确分配. 文献[19]提出了一种新的分布式控制策略来实现负荷分配和电压平衡. 通过在有限时间内达到所需的流形, 保证微电网加权平均电压与加权平均参考电压相同的前提下, 实现比例电流共享.
上述文献虽然提出了多种实现负载共享或电压平衡的方法, 但并没有在系统层面通过设计下垂控制器实现负载共享和电压平衡之间的最优平衡. 本文给出一种新的基于分布式策略的下垂控制器设计方法, 能够在统一的框架下实现直流微电网负载共享和电压平衡. 具体贡献总结如下:
1)将直流微电网的负载共享和电压平衡问题转化为多目标优化问题, 其性能指标与微源的容量密切相关且能在负载共享和电压平衡之间实现权衡. 通过最优化该性能指标求得同时实现负载共享和电压平衡的最优解, 即集中式控制策略, 并通过设计的下垂控制器实现微电网的电压平衡和负荷分配.
2)给出一种能够降低通信负担的分布式控制策略, 通过理论分析证明了该分布式策略能够指数收敛到多目标优化问题的最优解. 与集中式策略相比, 该分布式控制策略能在不增加系统复杂度的情况下, 降低系统的通信负担, 提高微电网的灵活性和稳定性.
1. 直流微电网建模
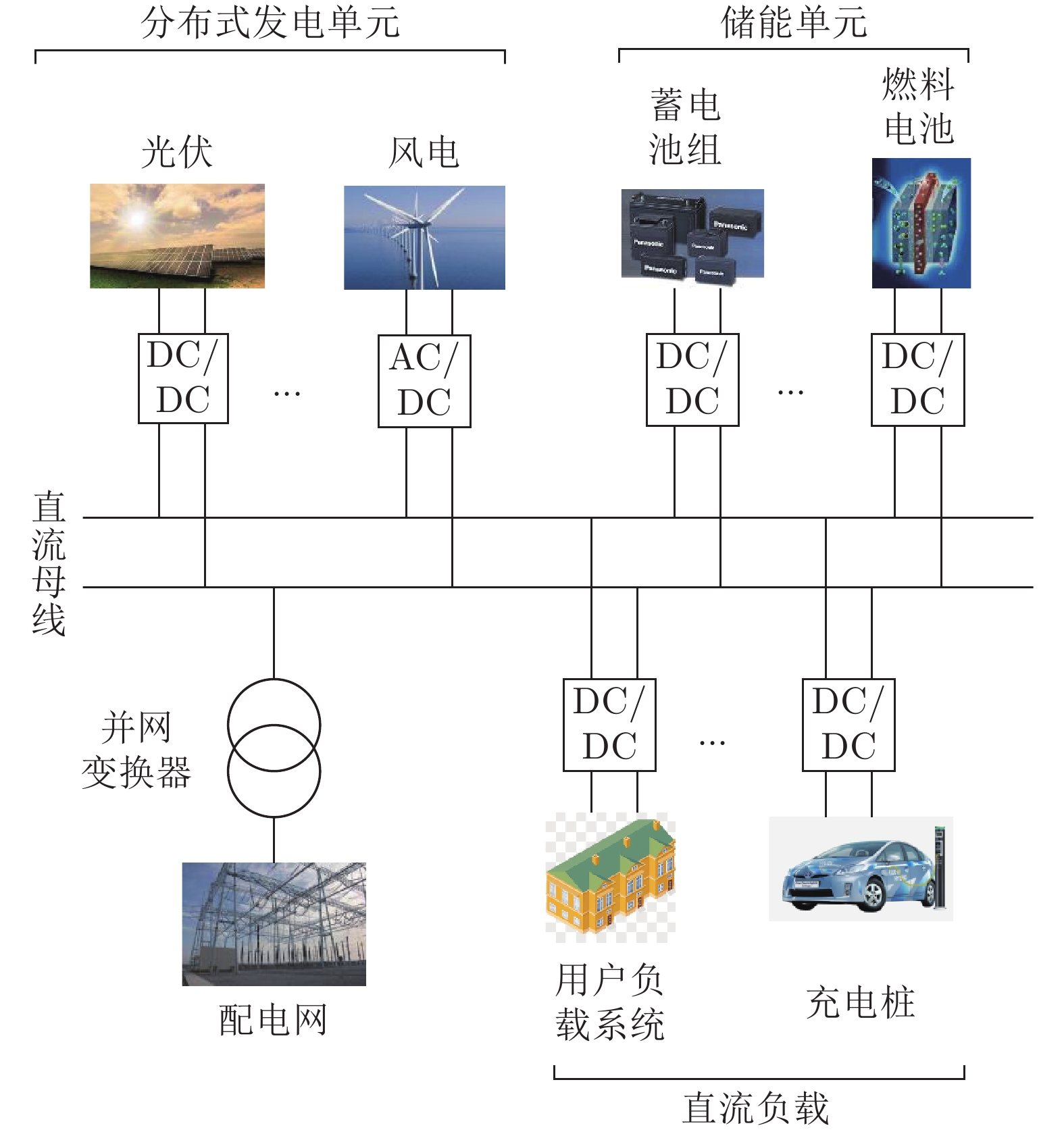
图1给出了用户级直流微电网的典型结构. 从图中可以看出, 直流微电网主要由微源, 储能单元, 负载单元、并网变换器及无线通信网络组成.
分布式发电单元主要有风力和光伏等可再生能源构成, 可采用下垂控制和最大功率跟踪控制两种运行模式; 储能单元具有平衡功率的作用, 同时承担着电源和负载的角色, 在用电低谷时段可以作为负荷储存电能, 在用电高峰时段又将电能回馈到微电网; 并网变换器作为微电网与配电网的接口维持直流母线稳定, 并根据各单元发出能量以及负载吸收能量情况工作于逆变或整流状态. 本文研究的是多用户级微电网通过直流传输线互联所构成的系统级微电网, 如图2所示.
为满足实际生活生产所需, 将多个用户级直流微电网两两互联构成系统级微电网. 用户级微电网通过使用通信网络进行信息交换, 以此实现信息共享, 提高了系统级微电网的可伸缩性和扩展性.
1.1 用户级微电网模型
本文假设分布式电源采用下垂控制模式, 储能单元和负荷具有恒流特性. 根据文献[12]可知, 采用电压−电流下垂控制的变换器稳态运行时, 输出端等效为一个理想电压源和电阻的串联. 最大功率控制变换器输出模型[20] 可等效为电流为
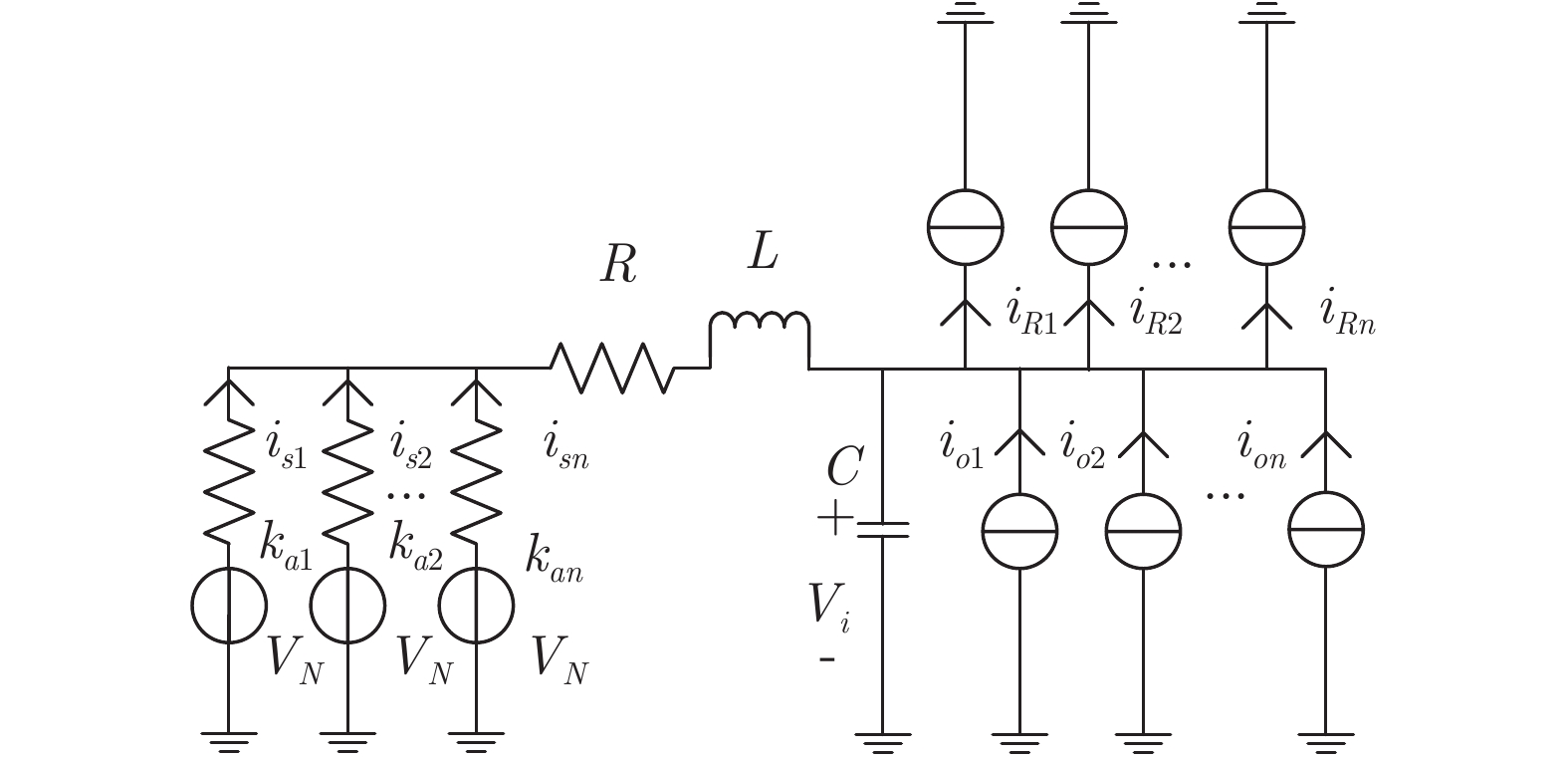
$ I_o $ 的电流源. 恒功率负载电路可等效为电流为$ I_R $ 的电流源. 假设因此, 用户级微电网$ i $ 的等效电路模型如图3所示.图3中,
$ V_N $ 为变换器空载输出电压,$ V_i $ 为母线电压;$ i_{si} $ 为变换器输出电流即电源输出电流,$ i_{oi} $ 为储能单元的输出电流,$ i_{Ri} $ 为恒功率负载的电流;$ k_{ai} $ 为下垂系数;$ L $ 、$ R $ 、$ C $ 为母线阻抗及滤波电容的等效模型. 当微电网达到稳态运行时, 电感$ L $ 和电容$ C $ 可以忽略不计. 一般情况下, 用户级微电网的母线较短, 可以忽略母线电阻$ R $ (若不忽略母线电阻的影响, 只需将下垂系数进行修正即可). 因此母线电压及电流可以表示为$$ V_i = V_N -k_i I_{si} $$ (1) $$ I_{si} = I_{Ri} -I_{oi} \hspace{5pt}$$ (2) 其中
$$\begin{split} &k_i = 1/\displaystyle\sum\limits_{j = 1}^n {\dfrac{1}{k_{aj} }} \\ &I_{si} = i_{s1} +i_{s2} +\cdots +i_{sn}\end{split} \hspace{10pt}$$ $$ I_{Ri} = i_{R1} +i_{R2} +\cdots +i_{Rn} $$ $$ I_{oi} = i_{o1} +i_{o2} +\cdots +i_{on} \hspace{10pt}$$ 1.2 系统级微电网模型
如图2所示, 该系统级微电网由
$ n $ 个用户级微电网互联构成. 从图论的角度分析, 可以将每个用户级微电网看做节点, 用户级微电网之间的直流传输线看做边, 因此可将直流微电网建模为无向连通图$ \vartheta = (\nu, \varepsilon ) $ , 其中,$ \nu { = \{}1,2,\cdot \cdot \cdot, {{n}\}} $ 是非空节点集合,$ \varepsilon \subseteq v\times v $ 是边的集合.$ \varepsilon _{ij} = (i,j)\in \varepsilon $ 代表节点$ i $ 和$ j $ 通过直流传输线连接, 对应直流传输线的阻抗为$ R_{ij} >0 $ 、$ L_{ij} >0 $ , 节点$ j $ 称之为$ i $ 的邻居节点,$N_i = \left\{ {j\left| {\varepsilon _{ij} \in \varepsilon } \right.} \right\}$ 是$ i $ 邻居节点的集合.$ A = [\omega _{ij} ]\in $ ${\bf R}^{n\times n}$ 为图的加权邻接矩阵用来描述节点与边之间关系, 当$ \varepsilon _{ij} \in \varepsilon $ 时,$ \omega _{ij} = \dfrac{1}{R_{ij} } $ ; 否则,$ \omega _{ij} = 0 $ . 图$ \vartheta $ 的度矩阵${{D}} = {\rm diag}\{\varpi _1, \varpi _2, \cdot \cdot \cdot, \varpi _n \}$ , 其对角元素$ \varpi _i = $ $ \displaystyle\sum\nolimits_{j\in N_i } {\omega _{ij} } $ , 因此, 图$ \vartheta $ 的拉普拉斯矩阵为$Y = $ $ D-A$ ,$ Y = Y^{\rm T} $ . 此外, 假设每一个节点都可以与其邻居节点相互通信, 即该系统级微电网的通信拓扑与物理拓扑相同.下面只给出节点
$ i $ 和$ j $ 的互联结构, 如图4所示. 在节点$ i $ 中, 分布式电源、储能单元和直流负载通过直流母线$ i $ 连接在了一起, 对应的电流分别为$ I_{si} $ 、$ I_{oi} $ 、$ I_{Ri} $ , 方向如图所示. 母线$ i $ 的电压为$ V_i $ , 母线$ i $ 和$ j $ 通过直流传输线相连接, 对应传输线电流为$ I_{ij} $ . 根据基尔霍夫电流定律可知, 节点$ i $ 处注入电流$ I_{si} $ 、$ I_{oi} $ 之和等于流出量$ I_{Ri} $ 、$ I_{ij} $ 之和, 即$I_{si} +I_{oi} = $ $ I_{Ri} +\displaystyle\sum\nolimits_{j\in N_i } {I_{ij} } $ . 令$ I_{ci} = I_{Ri} -I_{oi} $ , 则$I_{si} = I_{ci} + $ $ \displaystyle\sum\nolimits_{j\in N_i } {I_{ij} } $ . 类似文献[10], 可以假设电感$ L_{ij} $ 足够小, 使得$L_{ij} \dfrac{{\rm d}I_{ij} }{{\rm d}t} = 0$ , 则可以得到$I_{ij} = \dfrac{V_i -V_j }{R_{ij} }$ 或$I_{ji} =$ $ \dfrac{V_j -V_i }{R_{ji} } $ . 又因为直流传输线的电阻$ R_{ij} = R_{ji} $ , 因此可得$ I_{ij} = -I_{ji} $ . 由以上分析可知母线$ i $ 处的电流关系式为$ I_{si} = I_{ci} +\displaystyle\sum\nolimits_{j\in N_i } {\dfrac{V_i -V_j }{R_{ij} }} $ , 定义向量${\boldsymbol \delta }= [1,1,\cdots , $ $1]^{\rm T}, $ $ {\boldsymbol k} = {\rm{diag}}\left\{ {k_1, k_2, \cdot \cdot \cdot, k_n } \right\}, $ ${{\boldsymbol{I}}_{\boldsymbol{c}}} =[I_{c1}, I_{c2}, \cdot \cdot \cdot, I_{cn} ]^{\rm T},$ $ {\boldsymbol{V}}=[V_1, V_2, \cdot \cdot \cdot, V_n ]^{\rm T}, $ $ {{\boldsymbol{I}}_{\boldsymbol{s}}} =[I_{s1}, I_{s2}, \cdot \cdot \cdot, I_{sn} ]^{\rm T}. $ 将$ n $ 个节点的等式联立可得系统级微电网模型,$$ I_s = YV+I_c $$ (3) $$ V = \delta V_N -kI_s $$ (4) 若定义
${{\boldsymbol{I'}}_{\boldsymbol{s}}} = {\rm diag}\{I_{s1}, I_{s2}, \cdot \cdot \cdot, I_{sn}\}$ ,$ {\boldsymbol{{k'}}} = \left[ k_1, \right.$ $\left. k_2, \cdot \cdot \cdot,k_n \right] $ , 则式(4)变为$ V = \delta V_N -I'_s k' $ , 可求得$$ k' = I_s^{'-1} (\delta V_N -V) $$ (5) 即可以通过微源输出电流
$ I_s $ 和母线电压$ V $ 设计所需要的下垂系数, 这是本文的所要解决的基本问题之一.2. 本文的控制目标
负荷分配和电压平衡是直流微电网的两个基本控制任务. 这两个控制任务是相互竞争的, 很难同时实现比例负荷分配和理想母线电压分布.
2.1 电压平衡
一般情况下, 为了保证微电网的电压平衡, 需要调节各节点电压使其接近额定值, 即:
$$ \mathop {\lim }\limits_{t\to \infty } \left| {V_i (t)-V_i^{ref} } \right|\to \tau,\quad i\in \nu $$ (6) $ V_i^{ref} $ 是节点的额定电压值,$ \tau $ 是足够小的常数.可以看出当母线电压
$ V = V^{ref} $ 时, 母线电压达到最优分布. 但实际情况还要受到分布式电源输出电流的限制, 只能调节母线电压$ V $ 尽可能地接近额定电压$ V^{ref} $ . 在对输出电流没有限制的情况下, 母线电压可以达到最优分布, 求得母线输出电流$ I_s = I_c +YV^{ref} $ , 从而计算出满足电压平衡的下垂系数$ k $ . 进一步分析可知, 下垂系数与母线额定电压$ V^{ref} $ 和电源输出电流$ I_s $ 紧密相关, 通过额定电压$ V^{ref} $ 和电流$ I_s $ 可确定唯一的下垂系数$ k $ . 由于未考虑负荷分配的影响, 电源的出力受到较大影响. 这种情况具有较大的局限性, 只满足于特定情形.2.2 比例负荷分配
首先给出比例负荷分配条件, 即所有的微源出力满足以下条件:
$$ \frac{I_{si} }{m_i } = \frac{I_{sj} }{m_j } = \mu, \quad i,j\in v $$ (7) 其中,
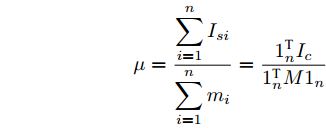
$ m_i >0 $ 和$ m_j >0 $ 分别代表与微源$ i $ 和$ j $ 额定容量有关的比例系数,$ \mu >0 $ 称为微源的负载率. 由式(3)可知$ 1_n^{\rm T} I_s = 1_n^{\rm T} I_c $ . 则由式(7)可得:$$ \mu = \frac{\displaystyle\sum\limits_{i = 1}^n {I_{si} } }{\displaystyle\sum\limits_{i = 1}^n {m_i} } = \frac{1_n^{\rm T} I_c }{1_n^{\rm T} M1_n } $$ 因此, 在不考虑电压平衡的情况下, 要实现比例负荷分配需要满足
$I_s = \mu M^{-1}\delta,\ M={\rm diag}\{m_i\}$ . 由于拉普拉斯矩阵$ Y $ 的秩小于$ n $ , 则非齐次线性方程组$ YV = I_s -I_c $ 有无穷组解. 由式(5)可知对应的下垂系数为无穷个. 但通过对第2.1节内容的分析可知这无穷组解很难实现母线电压最优分布, 只能挑选出一组最优解. 因此, 只考虑比例负荷分配的情况, 对母线电压平衡具有较大影响, 具有很大的局限性.2.3 负荷分配和电压平衡的权衡
从以上分析可以看出, 实现电压平衡的同时很难实现负荷的比例分配, 反之亦然. 为了解决上面两种方案的局限性, 需要在负荷分配和电压平衡之间实现适当的权衡, 使其在直流微电网的控制中达到资源分配的合理性. 因此, 本文在文献[5]的基础上引入以下多目标优化问题:
$$ \begin{split} \mathop {\min }\limits_{V_i I_{si} } J =\;& \frac{a}{2}\sum\limits_{i = 1}^n {\left( {\frac{I_{si} }{m_i }-\mu } \right)} ^2 +\\ &\frac{b}{2}\sum\limits_{i = 1}^n {m_i (V_i } -V^{ref})^2 \end{split} $$ (8) 约束条件: 式(3)
其中,
$ a>0 $ 和$ b>0 $ 满足$ a+b = 1 $ 为权衡系数, 用于调整负荷分配和电压平衡的比重, 确保二者之间的平衡. 在实际应用中, 可以根据微电网的整体性能要求改变$ a $ 和$ b $ 的数值. 从式(8)可以看出, 性能指标$ J $ 包含两项: 第一项是电流项, 用于处理负荷分配问题, 由系数$ a $ 调整其比重; 第二项是电压项, 用于处理电压平衡问题, 由权重系数$ b $ 调整其比重. 因此, 通过对性能指标$ J $ 进行优化, 可以实现负荷分配和电压稳定的权衡. 与文献[5]相比, 电压项增加了一个权重系数$ m_i $ , 也就是说本文采用的是加权平方和. 此处选择与微源容量相关的$ m_i $ 作为加权系数可以减小大容量微源的相关偏差, 一般来说, 大容量的微源对电网电压的维持作用更大.综上所述, 本文的研究目标是根据已建立的直流微电网模型, 构建一种新的分布式控制策略能够在负荷分配和电压平衡之间实现适当的权衡. 最后通过设计下垂系数实现系统级微电网的电压平衡和负荷分配.
3. 多目标优化问题求解
经过上一节的分析, 可以将微电网的电压平衡和负荷分配问题转化为多目标优化问题. 首先求解式(8)得到一组能够实现式电压平衡和负荷分配的最优下垂系数. 然后通过构建一种新的分布式控制策略实现式(8)的多目标优化问题, 解决系统级微电网的电压平衡和负荷分配问题.
3.1 集中式控制策略
定理 1. 基于多目标优化问题求解, 实现控制目标(6)和(7)的系统级微电网的最优下垂系数设计如下:
$$ k^\ast = {\rm diag}\{I_s^{'-1} (\delta V_N-V^\ast)\} $$ (9) 其中,
$I'_s\; =\; {\rm diag}\{YV^\ast +I_c \}, $ $V^\ast \;=\; (aYMMY+ $ $ bM^{-1})^{-1}(bM^{-1}V^{ref}-$ $ aYM(MI_c -\mu \delta)) $ 为母线电压的最优值.证明.
将式(8)中的性能指标改写为矩阵形式:
$$ \begin{split} J =\;& \frac{a}{2}(MI_s -\mu \delta )^{\rm T}(MI_s -\mu \delta ) +\\ & \frac{b}{2}(V-V^{ref})^{\rm T}M^{-1}(V-V^{ref}) \end{split} $$ (10) 将约束条件式(3)代入上式,
$$ \begin{split} J =\;& \frac{a}{2}(M(YV+I_c )-\mu \delta )^{\rm T}(M(YV+I_c )-\mu \delta ) +\\ & \frac{b}{2}(V-V^{ref})^{\rm T}M^{-1}(V-V^{ref}) \\[-12pt] \end{split} $$ (11) 对上式求偏导可得:
$$ \begin{split} \frac{\partial J}{\partial V} =\;& (aYMMY+bM^{-1})V +\\& aYM(MI_c -\mu \delta )-bM^{-1}V^{ref} \end{split} $$ (12) 由于对角矩阵
$ M>0 $ , 因此矩阵$ aYMMY+ $ $bM^{-1} $ 为正定矩阵. 令$ \dfrac{\partial J}{\partial V}=0 $ , 可求得最优母线电压$ V^\ast $ , 将$ V^\ast $ 代入式(3)可得最优电流解$ I_s^\ast $ .多目标优化问题(8)的全局最优解为(
$ I_s ^\ast $ ,$ V_{bus}^\ast ) $ , 将得到的最优解代入式(5)可以设计出实现控制目标的最优下垂系数(9). □从定理1中可以看出最优下垂系数与权衡系数
$ a $ 和$ b $ 密切相关, 通过调整参数$ a $ 和$ b $ , 可以得到不同情况下的最优下垂系数, 这间接反映了下垂系数可以对负荷分配和电压平衡进行权衡. 尤其, 当$ a=0 $ 时表示不考虑比例负荷分配的影响实现理想的电压平衡; 当$ b=0 $ 时表示不考虑电压平衡的影响实现比例负荷分配.3.2 分布式控制策略
上一节基于多目标优化问题求解设计出实现负荷分配和电压平衡的最优下垂系数. 从定理1中可以看出, 该下垂系数的设计需要获取所有母线电压信息, 而母线电压的计算是通过一个能够获取微电网全局信息的集中式控制策略实现的. 在实际应用中, 这一要求通常不能满足, 尤其是在分布式目标大规模渗透的情况下, 使用一个中央控制器与所有发电机和负载进行通信, 这对于微电网来说是昂贵的, 有时是不切实际的. 而分布式控制方案可以通过与邻居节点的信息交换实现全局最优. 因此, 本节提出一种新的求解母线电压的分布式控制策略, 如下所示:
$$ \dot {V}_i (t) = r_1 a\varphi _i (t)-r_2 bm_i \left( {V_i -V_i^{ref} } \right) \hspace{40pt}$$ (13) $$ \dot {\varphi }_i (t) = -\frac{r_1 }{r_2 }\varphi _i (t)-\sum\limits_{j\in N_i } {\frac{1}{R_{ij} }} \left(\frac{\Delta I_{si} (t)}{m_i }-\frac{\Delta I_{sj} (t)}{m_j }\right) $$ (14) 其中,
$ \Delta I_{si} (t)=\dfrac{I_{si} (t)}{m_i }-\mu $ ,$ \varphi _i (t) $ 为辅助变量,$ r_1 >0 $ 和$ r_2 >0 $ 为控制器增益.可以看出分布式控制策略(13)和(14)是通过获取邻居节点的信息实现的. 很明显, 节点
$ i $ 的控制更新只依赖于其自身的电压信息和相邻节点的电流信号. 在这个方案中, 节点的辅助变量$ \varphi _i (t) $ 用来估计当前节点的电流负载率和理想负载率$ \mu $ 之间的偏差. 接下来给出分布式策略(13)和(14)指数收敛到母线电压最优解的结论, 见如下定理:定理 2. 给定控制器增益
$r_1$ 和$r_2$ 以及系数$ a $ 和$ b $ , 分布式控制策略(13)和(14)指数收敛于最优解$ V^\ast $ , 其收敛率为$ \rho = \min \left\{ {\dfrac{r_1 }{r_2 },r_2 bm_i, i = 1,\cdots, n} \right\} $ .证明. 令
$ \varphi (t) = \left[ {\varphi _1 (t),\varphi _2 (t),\cdot \cdot \cdot, \varphi _n (t)} \right]^{\rm T} $ , 将分布式控制策略(13)和(14)改写为矩阵形式如下:$$ \dot {V}(t) = r_1 a\varphi (t)-r_2 bM^{-1}(V-V^{ref}) $$ (15) $$ \dot {\varphi }(t) = -\frac{r_1 }{r_2 }\varphi (t)-YM\Delta I_s (t) \hspace{35pt}$$ (16) 假设上式的平衡点为
$ (\bar {V},\bar {\varphi }) $ , 则在该平衡点上有$$ r_1 a\bar {\varphi }-r_2 bM^{-1}(\bar {V}-V^{ref})=0 $$ (17) $$ -\frac{r_1 }{r_2 }\bar {\varphi }-YM\Delta \bar {I}_s =0 \hspace{47pt}$$ (18) 其中,
$ \Delta \bar {I}_s =MI-\mu \delta $ . 由式(17), 可得$\bar {\varphi } = $ $ -\;\dfrac{r_2 }{r_1 }YM\Delta \bar {I}_s,$ 将其代入式(18)得$aYM\Delta \bar {I}_s\; - $ $ bM^{-1}(\bar {V}-V^{ref})=0$ , 结合等式(3)整理后可得最优解$ V^\ast $ . 这表明式分布式控制策略(13)和(14)的平衡点$ \bar {V} $ 与最优解$ V^\ast $ 完全一致.下面给出上述分布式控制策略收敛性得证明. 定义误差变量
$ \tilde {V}(t) = V(t)-\bar {V} $ 和$ \tilde {\varphi }(t) = \varphi (t)-\bar {\varphi } $ , 结合式(15) ~ (18)可得:$$ \dot {\tilde {V}}(t) = r_1 a\tilde {\varphi }(t)-r_2 bM^{-1}\tilde {V}(t) $$ (19) $$ \dot {\tilde {\varphi }}(t) = -\frac{r_1 }{r_2 }\tilde {\varphi }(t) \hspace{60pt}$$ (20) 定义
$ z(t) = [\tilde {V}(t),\tilde {\varphi }(t)] $ , 可得$ \dot {z}(t) = Hz(t) $ , 其中$$ H=\left[ {{\begin{array}{*{20}c} {-r_2 bM^{-1}} & {r_1 aE} \\ 0 & {-\dfrac{r_1 }{r_2 }E} \end{array} }} \right] $$ $ E $ 为对应维数的单位矩阵, 可知误差系统的解为$z(t) = {\rm e}^{Ht}z(0)$ .$ H $ 的特征值为$ -r_2 bm_i, i = 1,\cdots, n $ ,$ -\dfrac{r_1 }{r_2 } $ , 可以看出$ H $ 的所有特征值都小于零, 所以可知$\left\| {z(t)} \right\|\le \left\| {{\rm e}^{Ht}} \right\|\left\| {z(0)} \right\|\le {\rm e}^{-\rho t}\left\| {z(0)} \right\|$ . 结果表明$ t $ 趋近于无穷大时,$ z(t) $ 趋近于0, 收敛率为$ \rho. $ □定理2表明, 通过分布式控制(13)和(14)可以实现全局最优解, 相较于集中控制该分布式控制方案实际应用性更高. 同时, 通过适当的调整控制器增益
$ r_1 $ ,$ r_2 $ 可获得一个较为理想的收敛速度.4. 仿真研究
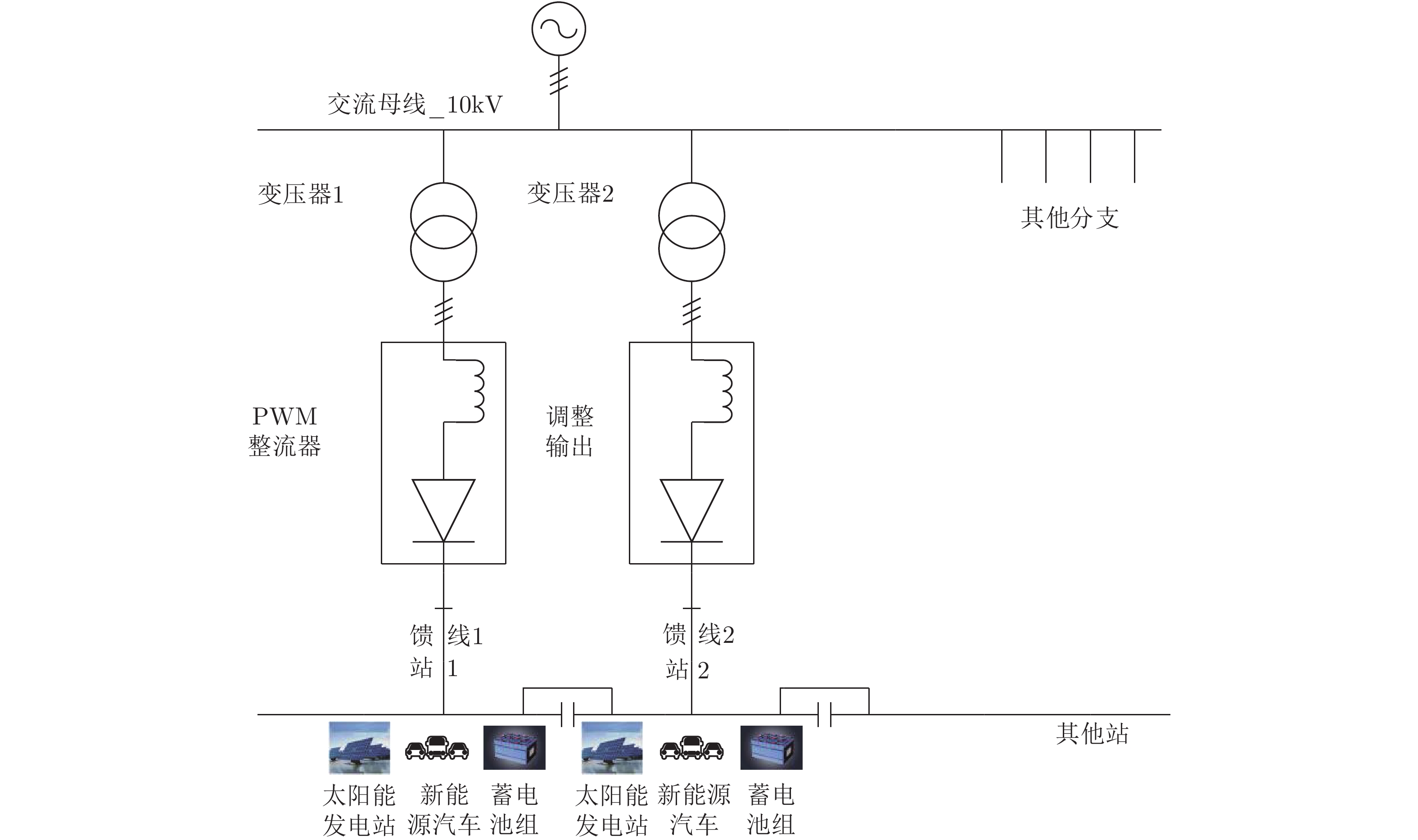
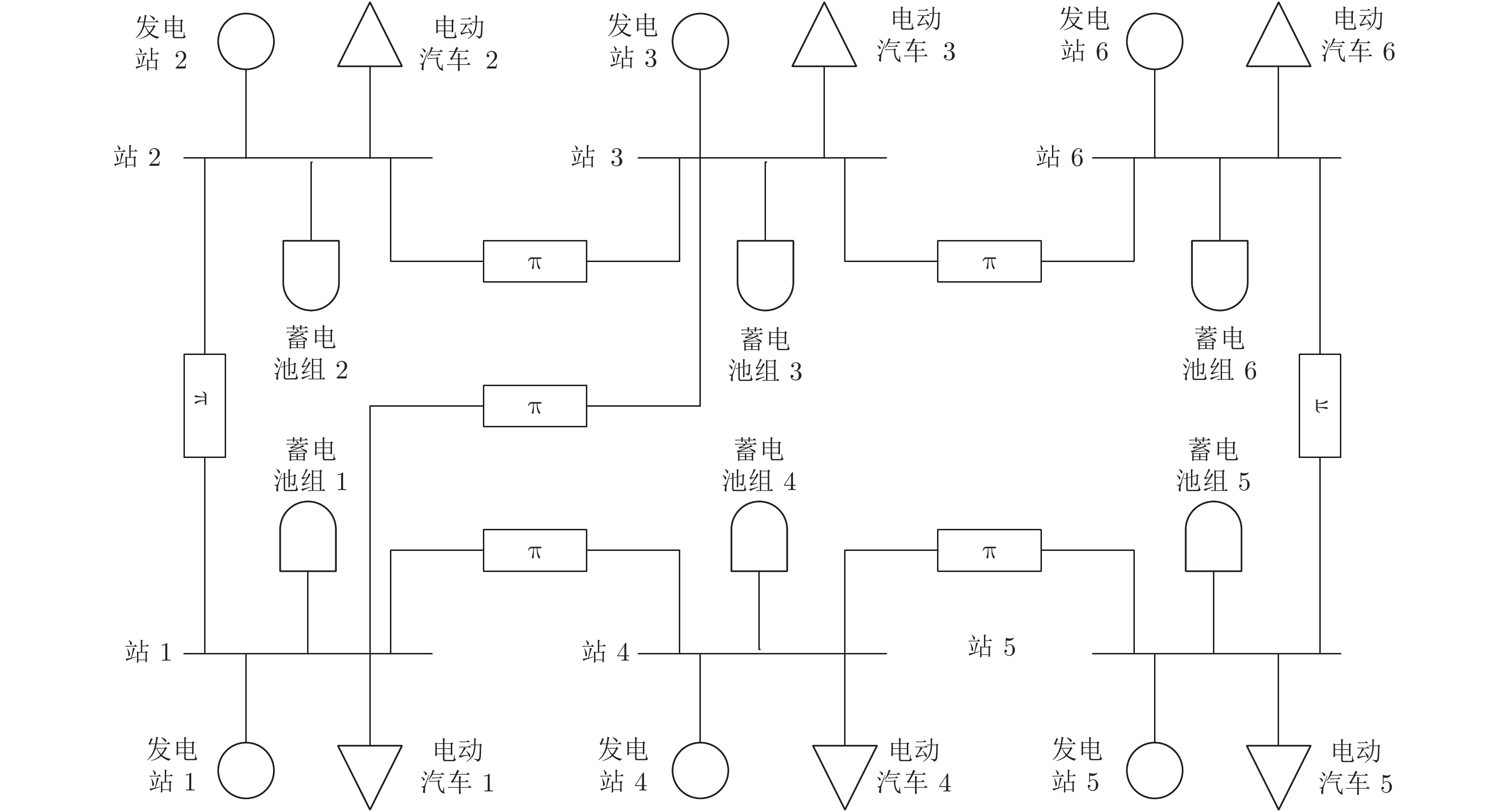
为了验证本文设计的下垂控制器以及分布式策略的有效性, 借助文献[21]的实例, 以新能源电动汽车充换电站网络作为仿真系统. 如图5所示, 新能源汽车充换电站由馈线及太阳能发电站供电. 6个充换电站相互连接组成供电半径约为5公里的供电网络. 每个充换电站都配有独立的太阳能发电系统且可以通过通信网络与相物理连接的充换电站通信. 综上所述, 尽管该内部结构、电路保护、负载条件和储能单元都非常复杂, 但馈线终端的每各站点都可以看作是直流网络的一个节点, 所以该新能源汽车充换电站是一个系统级直流微电网.
类似于文献[5], 采用改进的6母线直流微电网对新能源汽车充换电站进行建模, 如图6所示. 其微源、储能单元、负荷和母线分别代表太阳能发电站和馈线, 蓄电池组, 新能源电动汽车和充换电站站. 所有仿真验证均采用
${ \rm{Matlab}} $ 软件进行, 相关参数来自文献[5], 具体数值如下:节点之间的传输线电阻为
$ R_{12} = R_{21} = 0.40, \; $ $R_{13} = R_{31} = 0.37, \; R_{14} = R_{41} = 0.34, \; R_{23} = R_{32} = 0.38, \; $ $ R_{36} = R_{63} = 0.40,R_{45} = R_{54} = 0.31, \; R_{56} = R_{65} = 0.36 $ . 比例系数分别为:$m_1 = m_2 = 1.50, \; m_3 = m_4 = 1.75, $ $ m_5 = m_6 = 2.00 $ . 节点的额定电压$V_i^{ref} = 380\,{\rm V}$ .负载电流为:
$$ \begin{array}{l} I_{c1} = 721\,{\rm A},I_{c2} = 743\,{\rm A},I_{c3} = 818\,{\rm A}, \\ I_{c4} = 830\,{\rm A},I_{c5} = 921\,{\rm A},I_{c6} = 903\,{\rm A}. \end{array} $$ 初始电压为:
$$ \begin{array}{l} V_1 (0) = 360\,{\rm V},V_2 (0) = 390{\rm V},V_3 (0) = 370{\rm V}, \\ V_4 (0) = 380{\rm V},V_5 (0) = 400{\rm V},V_6 (0) = 350{\rm V}. \end{array} $$ 控制增益设为:
$ r_1 = 3,r_2 = 10 $ .4.1 集中式控制策略
假设权重系数为
$ a = 0.5,b = 0.5 $ , 由定理1求出下垂系数, 母线电压以及微源输出电流的最优解为$$ \begin{split}& k_1^\ast = 0.1042,k_2^\ast = 0.1088,k_3^\ast = 0.0854, \\ &k_4^\ast = 0.0862,k_5^\ast = 0.0710,k_6^\ast = 0.0684. \\ &V_1^\ast = 375.8394, V_2^\ast = 372.1973,V_3^\ast = 379.2690, \\ &V_4^\ast = 379.0309,V_5^\ast = 383.9641,V_6^\ast = 386.4960. \\ &I_{s1}^\ast = 711.4490,I_{s2}^\ast = 715.2852,I_{s3}^\ast = 827.8112, \\ &I_{s4}^\ast = 823.4735,I_{s5}^\ast = 929.8805,I_{s6}^\ast = 928.1005. \end{split} $$ 从计算数据可以看出, 母线电压基本稳定在参考电压附近, 输出电流基本实现了比例分配. 由此说明基于集中式控制策略设计的下垂控制器能够实现负荷共享和电压平衡的权衡.
4.2 分布式控制策略
基于分布式控制方案(13)和(14), 得到下垂系数
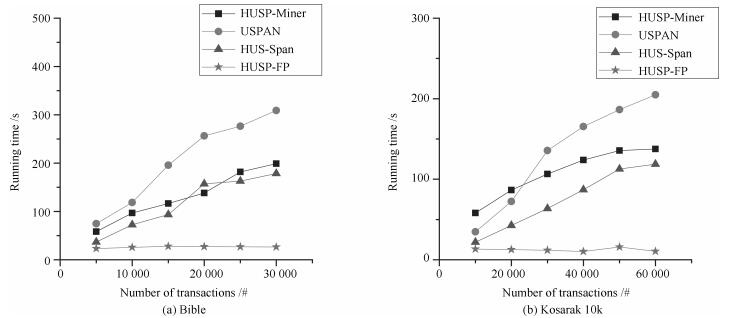
$ k $ , 母线电压$ V $ 以及输出电流$ I_s $ 随时间变化的曲线, 如图7所示. 图中可以看出曲线最终都处于平衡状态. 从图中可以看出分布式控制方案(13)和(14)所得的下垂系数$ k $ , 母线电压$ V $ 和输出电流$ I_s $ 的曲线收敛于定理1中的最优解. 因此证明了本文提出的分布式控制策略的有效性.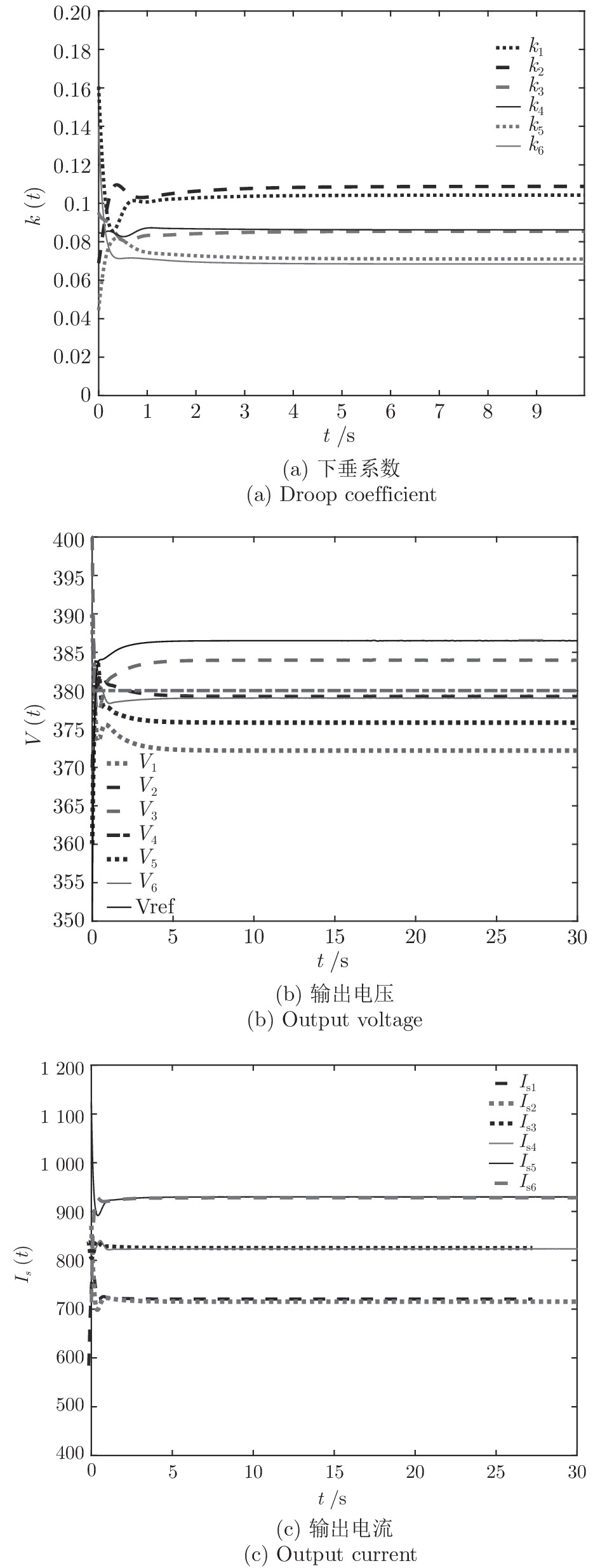 图 7 基于分布式方案的
图 7 基于分布式方案的$k, V, I_s $ 的演化曲线$a = 0.5$ Fig. 7 When$a = 0.5$ , the evolution curve of$k, V, I_s $ based on the distributed scheme4.3 负载共享与电压平衡的权衡
如上所述, 可以通过调整权重系数
$ a $ 实现微电网母线电压平衡和负荷分配的权衡. 这一节我们将通过仿真实例来研究权重系数变化时所提出的基于分布式控制策略的下垂控制器性能. 假设系数$ a $ 和$ b $ 的变化规律如下:1)
$t\in [0\,{\rm s},10\,{\rm s}],a = 0.10,b = 0.90$ 2)
$t\in [10\,{\rm s},20\,{\rm s}],a = 0.50,b = 0.50$ 3)
$t\in [20\,{\rm s},30\,{\rm s}],a = 0.90,b = 0.10$ 下垂系数, 母线电压以及输出电流随时间的变曲线如图8所示. 从图中可以看出, 在
$t = [0\,{\rm s},10\,{\rm s}]$ 时, 电压平衡的性能要优于负荷的比例分配; 而在$t = [20\,{\rm s},30\,{\rm s}]$ 时, 恰巧相反. 在$t = [10\,{\rm s},20\,{\rm s}]$ 时, 系统基本实现了电压平衡和负荷的比例分配, 且具有较好的性能. 因此, 可以根据实际情况通过调整权重系数实现电压平衡和负荷分配的权衡. 需要指出的是母线电压$ V $ 的变化曲线与下垂系数$ k $ 的变化曲线相似, 由此可以确定母线电压$ V $ 受到下垂系数$ k $ 的控制. 图 8
图 8$a = 0.1, 0.5, 0.9$ 的$k, V, I_s/m$ 的演化曲线Fig. 8 When$a = 0.1, 0.5, 0.9$ , the evolution curve of$k, V, I_s/m$ 4.4 负载变化时的性能
由于车辆进出站充电, 每个充换电站的负荷需求会发生频繁的变化. 因此, 通过负载变化对所提的分布式控制策略的性能进行验证. 假设在
$10\,{\rm s}\sim$ $20\,{\rm s}$ 母线2的负载下降30 %, 然后恢复. 当$ a = b = 0.5 $ 时, 下垂系数, 母线电压以及输出电流随时间的变曲线如图9所示. 从图中可以看出, 当负载在$t = 10\,{\rm s}$ 和$t = 20\,{\rm s}$ 发生变化时, 系统能够在下垂控制器的作用下迅速作出响应, 使得母线电压和输出电流作出相应的调整, 最终趋于稳定. 因此本文使用分布式控制策略能够增加系统的鲁棒性. 图 9 负载变化对
图 9 负载变化对$k, V, I_s $ 的影响$a = 0.5$ Fig. 9 When$a = 0.5$ , effect of load change on$k, V, I_s $ 4.5 即插即用的性能
在实际中, 经常出现部分充换电站因维修而停用或新建充换电站的情况, 这就要求新能源汽车充换电站系统具有即插即用的特性. 接下来, 通过充换电站的加入和退出对所提的分布式控制策略的性能进行验证. 假设在
$10\,{\rm s}\sim20\,{\rm s}$ 内独立运行的充换电站7接入系统, 其他时间独立运行. 其参数为$ R_{57} = $ $R_{75} =0.40\,\Omega ,$ $R_{67} \;=\; R_{76} \;=\;0.35\,\Omega,$ $V_7 (0) = 365\,{\rm V},$ $I_{c7} = $ $660\,{\rm A}$ 和$ m_7 = 1.50 $ . 当$ a = b = 0.5 $ 时, 下垂系数, 母线电压以及输出电流随时间的变曲线如图10所示. 从图中可以看出, 当节点7在$t = 10\,{\rm s}$ 和$t = 20\,{\rm s}$ 加入和退出时, 系统能够在下垂控制器的作用下迅速作出响应, 使得母线电压和输出电流作出相应的调整, 最终趋于稳定. 仿真结果表明分布式控制策略(13)和(14)使系统对新节点的接入和退出具有良好的适应性.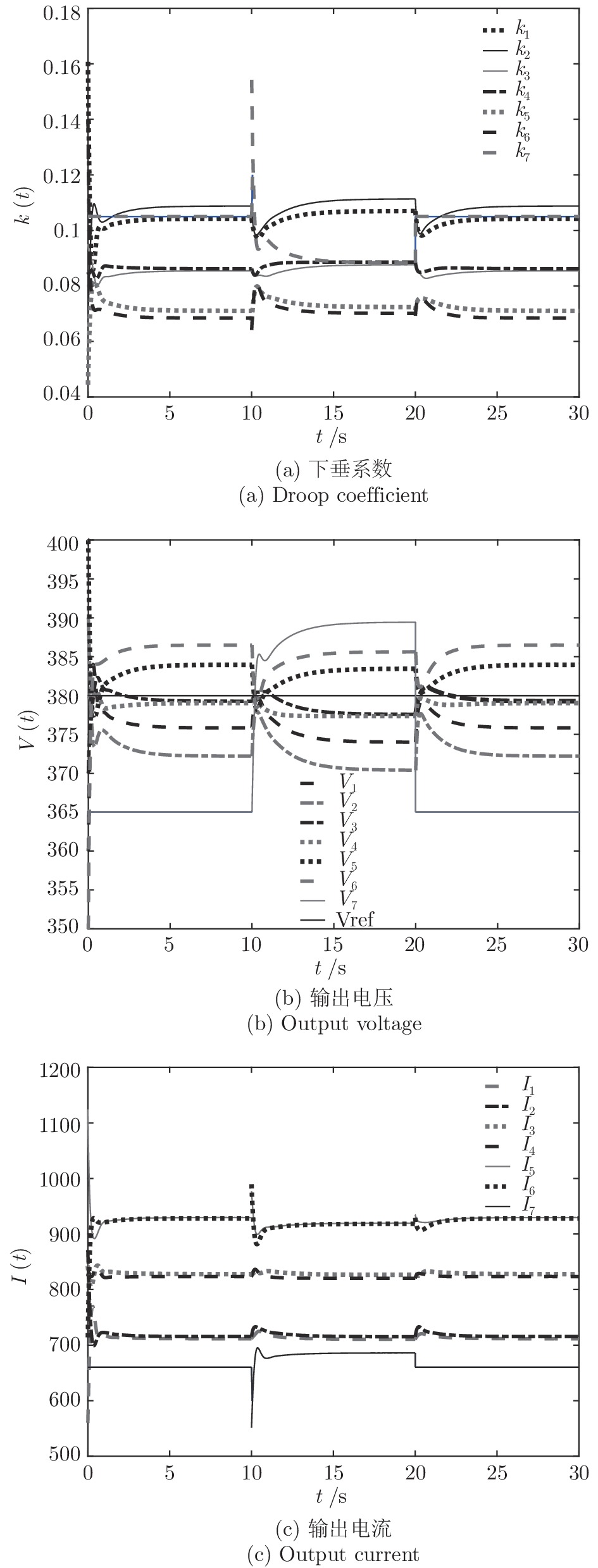 图 10 节点7接入和退出对
图 10 节点7接入和退出对$k, V, I_s $ 的影响$a = 0.5$ Fig. 10 When$a = 0.5$ , influence of node 7 access and exit on$k, V, I_s $ 5. 总结
本文针对直流微电网中的负荷分配和电压平衡问题进行了研究. 分析了没有负荷分配影响时的电压平衡以及没有电压平衡影响时的负荷分配问题, 发现这两种情况具有较大的局限性. 因此将微电网的负荷分配和电压平衡问题转化为一种多目标优化问题, 通过权衡系数来调整电压平衡和负荷分配的比重. 然后给出多目标优化问题的最优解, 通过集中式策略设计的下垂控制器实现微电网的电压平衡和负荷的比例分配. 为了降低系统的通信负担和提高系统的可靠性, 提出一种新的只需与邻居节点交换信息的分布式控制策略. 理论结果表明, 该分布式控制策略与集中式策略具有完全一致的性能. 最后, 基于新能源汽车充换电站系统进行了仿真研究, 通过仿真结果可以看出适当的调节下垂系数可以实现电压平衡和负荷分配的权衡. 同时还表明该控制算法具有较快的收敛速率, 良好的鲁棒特性和即插即用性.
-
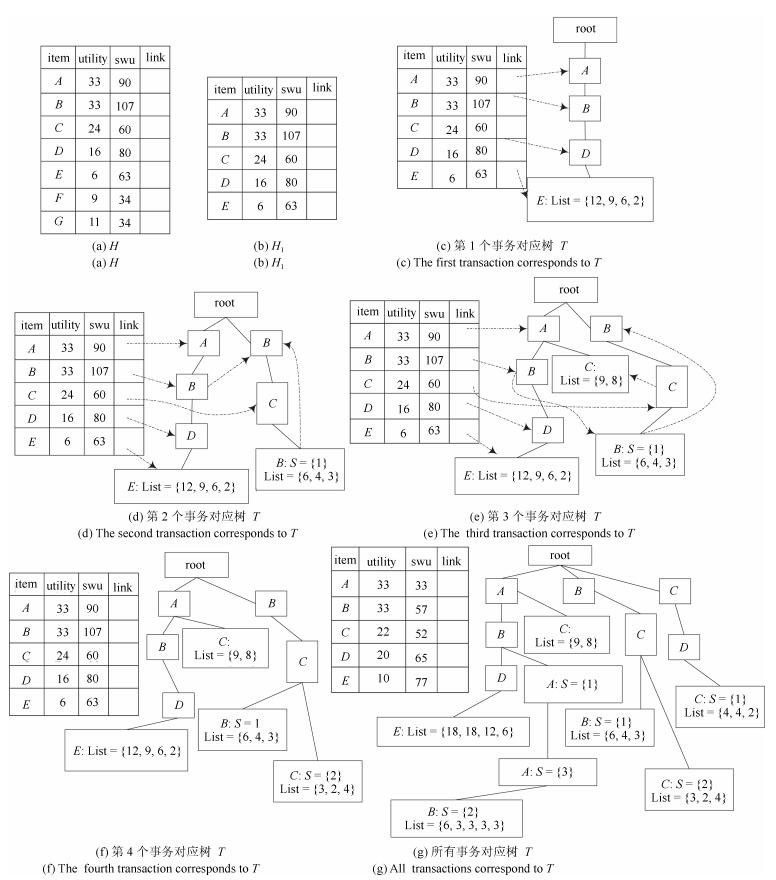
表 1 高效用数据集
Table 1 High utility dataset
TID Transaction (item, quantity) $ t_1 $ $ (A, 4) (B, 3) (D, 3) (E, 1) $ $ t_2 $ $ (B, 2) (C, 2) (B, 1) (G, 4) $ $ t_3 $ $ (A, 3) (C, 4) $ $ t_4 $ $ (B, 1) (C, 1) (C, 2) $ $ t_5 $ $ (A, 2) (B, 3) (D, 3) (E, 2) (F, 9) $ $ t_6 $ $ (C, 2) (D, 2) (C, 1) (G, 7) $ $ t_7 $ $ (A, 2) (B, 1) (A, 1) (A, 1) (B, 1) $  下载: 导出CSV
下载: 导出CSV
表 2 利润表(外部效用值)
Table 2 A Profit Table (External utility value)
TID Transaction (item, quantity) $ A $ 3 $ B $ 3 $ C $ 2 $ D $ 2 $ E $ 2 $ F $ 1 $ G $ 1
下载: 导出CSV
表 3 算法复杂度比较
Table 3 Comparisons of algorithm complexity
算法 事务存储 效用存储 挖掘方式 候选项 HUSP-FP 全局树 叶子结点 模式增长, 一次性完成 无 HUSP-Miner 序列表格 序列树结点 表格搜索, 深度剪枝 有 USPAN 序列字典树 效用矩阵 枚举搜索, 剩余量剪枝 有 HUS-Span 序列枚举树 链表 效用上界深度搜索 有
下载: 导出CSV
表 4 算法复杂度比较
Table 4 Data characteristics
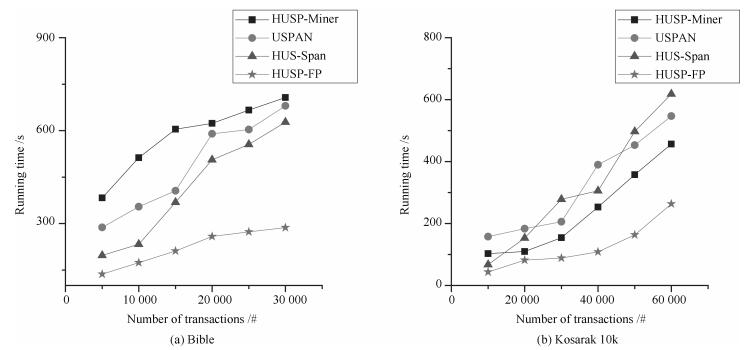
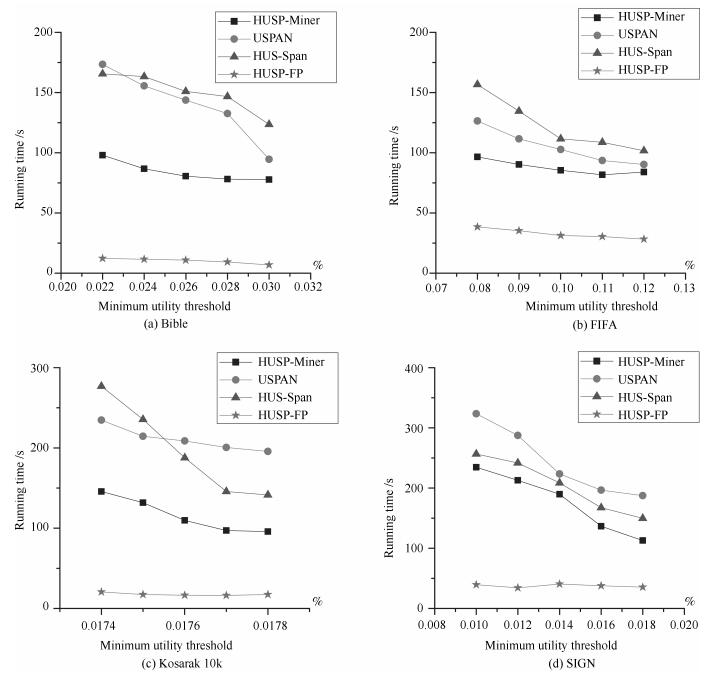
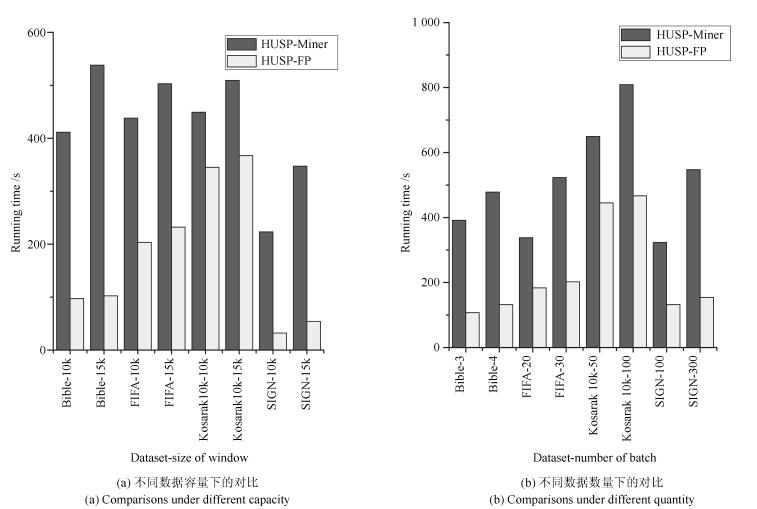
数据集 项数 序列事务项集平均长度 序列事务总数 Bible 13 905 21.64 36 369 FIFA 13 749 45.32 573 060 Kosarak 10k 39 998 11.64 638 811 SIGN 267 93.00 730
下载: 导出CSV
-
[1] Michele D, Fabrizio B, Jacopo L, Jacopo R, Salvatore T, Federico. Sequential pattern mining for ICT risk assessment and management. Journal of Logical and Algebraic Methods in Programming, 2019, 102(1): 1-16 http://www.sciencedirect.com/science/article/pii/S235222081830021X [2] Maryam A, Leyli M, Raffaela M. A sequential pattern mining model for application workload prediction in cloud environment. Journal of Network and Computer Applications, 2018, 105(3): 21-62 http://www.sciencedirect.com/science/article/pii/S1084804517304198 [3] Xue Yun, Li Tie-Chen, Liu Zhi-Wen, Pang Chao-Yi, Li Mei-Hang, Liao Zheng-Ling. A new approach for the deep order preserving submatrix problem based on sequential pattern mining. International Journal of Machine Learning and Cybernetics, 2018, 9(2): 263-279 doi: 10.1007/s13042-015-0384-z [4] Trang V, Bay V, Bac L. Mining sequential patterns with itemset constraints. Knowledge and Information Systems, 2018, 57(2): 311-330 doi: 10.1007/s10115-018-1161-6 [5] Shou Zhen-Yu, Di Xuan. Similarity analysis of frequent sequential activity pattern mining. Emerging Technologies, 2018, 96(11): 122-143 [6] Bac L, Duy T, Van N, Quang M, Philippe F V. An efficient algorithm for hiding high utility sequential patterns. International Journal of Approximate Reasoning, 2018, 95: 77-92 doi: 10.1016/j.ijar.2018.01.005 [7] Liu J Q Zhang X X, Benjamin C, Li J Y, Farkhund I. Opportunistic mining of top-n high utility patterns. Information Sciences, 2018, 441(5): 171-186 [8] Song W, Rong K K. Mining high utility sequential patterns using maximal remaining utility. In: Proceedings of Data Mining and Big Data. Shanghai, China: Springer, 2018. 466-477 [9] Ahmed, Chowdhury F. A novel approach for mining high-utility sequential patterns in sequence databases. Electronics and Telecommunications Research Institute, 2010, 32(5): 676-686 doi: 10.4218/etrij.10.1510.0066 [10] Yin J F, Zheng Z G, Cao L B. Uspan: An efficient algorithm for mining high utility sequential patterns. In: Proceeding of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: IEEE, 2012. 660-666 [11] Wang J Z, Huang J L, Chen Y C. On efficiently mining high utility sequential patterns. Knowledge and Information Systems, 2016, 49(2): 597-627 doi: 10.1007/s10115-015-0914-8 [12] Deng Z H, Ma S L, Li H. An efficient data structure for fast mining high utility itemset. Computer Science, 2015, 41: 214-223 doi: 10.1007/s10489-017-1130-x [13] Zhang B B, Jerry L, Philippe F V. Mining of high utility-probability sequential patterns from uncertain databases. Plos One, 2017, 12(7): e0180931 doi: 10.1371/journal.pone.0180931 [14] Zihayat M, Chen Y, An A. Memory-adaptive high utility sequential pattern mining over data streams. Machine Learning, 2017, 106: 799-836 doi: 10.1007/s10994-016-5617-1 [15] Zihayat M, Wu Cheng-Wei, An A. Efficiently mining high utility sequential patterns in static and streaming data. Intelligent Data Analysis, 2017, 21: 103-135 doi: 10.3233/IDA-170874 [16] Liu Meng-Chi, Qu Jun-Feng. Mining high utility itemsets without candidate generation. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management. Maui. USA: ACM, 2012. 55-64 [17] Philippe F V, Wu Cheng-Wei, Souleymane Z, Vincent S. FHM: faster high-utility itemset mining using estimated utility co-occurrence pruning. Intelligent Data Analysis, Switzerland: Springer, 2014. 83-92 [18] 王乐, 熊松泉, 常艳芬, 王水. 基于模式增长方式的高效用模式挖掘算法. 自动化学报, 2015, 41(9): 1616-1626 doi: 10.16383/j.aas.2015.c150056Wang Le, Xiong Song-Quan, Chang Yan-Fen, Wang Shui. An algorithm for mining high utility patterns based on pattern-growth. Acta Automatica Sinica, 2015, 41(9): 1616-1626 doi: 10.16383/j.aas.2015.c150056 [19] Philippe F V, Antonio G, Ted G. Spmf: a java open source pattern mining library. Journal of Machine Learning Research, 2014, 15: 3389-3393 [20] Zihayat M, Wu Cheng-Wei, An A. Efficient mining of high-utility sequential rule. In: Proceedings of Machine Learning and Data Mining. Hamburg, Germany: Springer, 2015. 157-171 [21] Martínez B M, Martínezá F, Troncoso A, Mining quantitative association rules based on evolutionary computation and its application to atmospheric pollution. Integrated Computer Aided Engineering, 2010, 17(3): 227-242 doi: 10.3233/ICA-2010-0340 [22] Vincent S T, Wu Cheng-Wei, Bai E S. UP-Growth: An efficient algorithm for high utility itemset mining. In: Proceedings of Knowledge Discovery and Data Mining. New York, USA: ACM, 2010. 253-262 期刊类型引用(5)
1. 韩永明,王新鲁,耿志强,朱群雄,毕帅,张红斌. 基于AMOWOA的区域综合能源系统运行优化调度. 自动化学报. 2024(03): 576-588 .  本站查看
本站查看2. 李远征,张虎,刘江平,赵勇,连义成. 基于电网线路传输安全的电力市场分布式交易模型研究. 自动化学报. 2024(10): 1938-1952 . 本站查看3. 贾晓振,胡江凯,王大鹏,梁晨. 长时间序列格点数据管理平台的设计与实践. 气象科技. 2024(06): 797-806 . 百度学术4. 罗鹏,刘永慧,苏庆堂. 耦合程度加深的电-气综合能源系统的建模及仿真. 控制工程. 2023(11): 2125-2133 . 百度学术5. 张化光,孙宏斌,刘德荣,王剑辉,孙秋野. “分布式信息能源系统”专题特约主编寄语. 中国电机工程学报. 2020(17): 5401-5403 . 百度学术其他类型引用(16)
-

 下载:
下载:
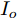
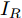

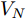
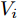
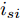
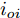
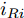
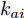
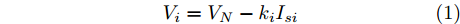
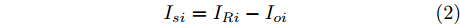
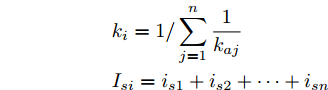
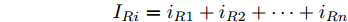
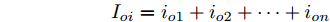
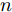
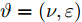
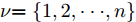
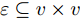
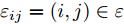

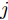
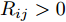
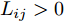
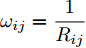
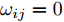
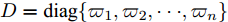
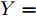

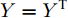

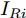
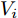
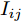
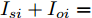
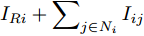
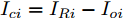
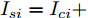
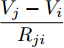
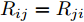
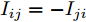
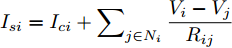
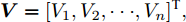
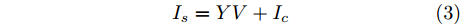
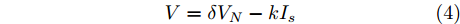
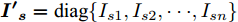
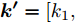
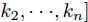
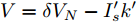
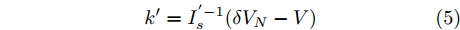
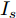
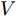

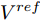
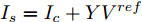
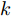
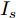
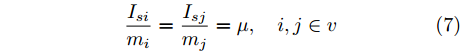
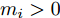
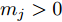

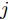
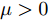
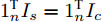
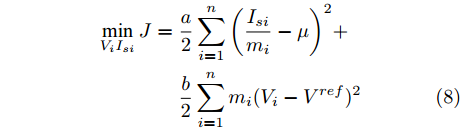
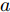
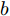
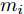
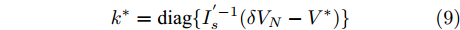
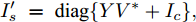
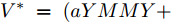
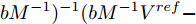
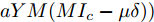
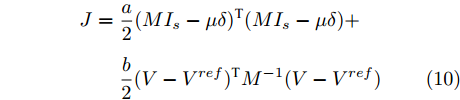
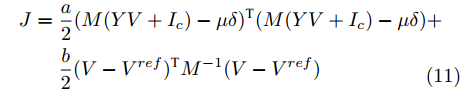
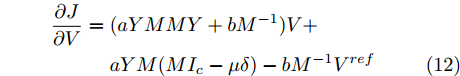
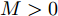
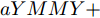
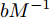
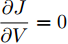
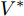
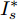
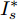
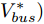
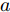
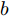

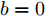
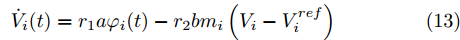
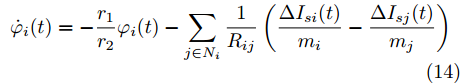
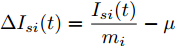
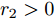

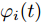
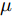
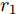
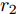
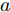
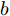
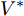
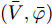
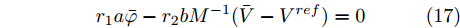
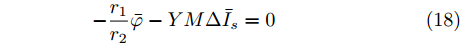
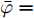
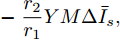
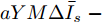
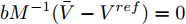
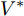
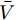
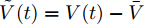
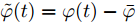
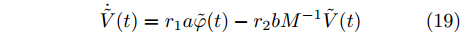
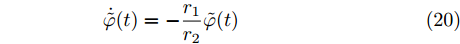
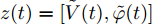
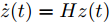

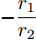
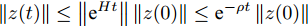
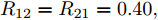
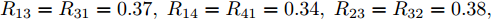

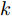
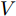
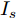
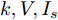

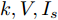


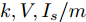
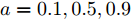
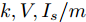
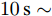
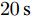
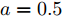
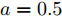
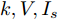
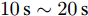
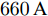

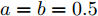
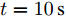
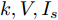
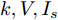


计量
- 文章访问数: 1258
- HTML全文浏览量: 256
- PDF下载量: 206
- 被引次数: 21
