

A Reliability Communication Approach for Power Wide Area Protection System Based on UDP
-
摘要:
电力广域保护系统从点到点通信逐步走向网络化通信, 如何在拥塞状态下保障业务的实时性和可靠性, 成为亟待解决的问题. 针对传输控制协议(Transmission control protocol, TCP)不能保障实时性以及用户数据报协议(User datagram protocol, UDP)不能保障可靠性的问题, 本文提出一种联合应用层纠错、检错和重发机制的UDP传输方案, 在提供低时延传输服务的同时也能保障报文的可靠性. 考虑到算法的复杂性, 选择本原BCH (Bose-Chaudhuri-Hocquenghem)码作为纠错编码算法, 设计了编码分组方法, 并通过实验验证了分组方法的正确性; 对增加纠错机制后的报文实时性进行了理论分析和仿真验证; 为了解决突发误码和丢包情况下的可靠性问题, 进一步设计了应用层检错和重发机制, 并分析了时延. 分析表明, 在应用层增加本文所设计的纠错、检错和重发机制后增加的时延几乎可以忽略不计. 最后给出了所提方法的联合应用算法, 并进行了可靠性分析, 结果表明本文方案的可靠性高于其他UDP传输方案.
Abstract:The communications of a wide area protection system are transforming from point-to-point to networked connections. Guaranteeing the real-time and reliability of communication services under a congestion state has become an urgent issue. Aiming at the problem of transmission control protocol (TCP) cannot guarantee real-time and user datagram protocol (UDP) cannot guarantee reliability, a UDP transmission scheme based on the mechanism of combining error correction, error detection, and retransmission for application messages is proposed. This scheme can provide low delay and reliable transmission service for applications. An original BCH (Bose-Chaudhuri-Hocquenghem) code is selected as the error correction coding algorithm considering the complexity of the algorithms, and a coding grouping method is designed. An experiment to verify the grouping method is also presented. We conduct theoretical analysis and simulations to verify the real-time of a message after employing the error correction mechanism. To provide reliability under the condition of having burst errors and packet loss, the mechanisms of error detection in the application layer and datagram retransmission are further designed, and their real-time performance is analyzed. The analysis reveals that the increased delays are nearly negligible when exploring the mechanisms designed in this study of error correction, error detection, and retransmission. Moreover, this paper presents a comprehensive application algorithm of the scheme and analyzes its reliability. The result shows that the reliability provided by the proposed scheme is higher than the other UDP transmission scheme.
-
Key words:
- Power wide area protection /
- network communication /
- error correction /
- real-time /
- reliability
1) 收稿日期 2018-09-30 录用日期 2019-05-08 Manuscript received September 30, 2018; accepted May 8, 2019 国家自然科学基金 (51977155, 51377122), 国家电网公司科技项目 (针对网络攻击的电网信息物理系统协同运行态势感知与主动防御方法研究) 资助 Supported by National Natural Science Foundation of China (51977155, 51377122) and the Science and Technology Project of State Grid Corporation of China (Research on Cooperative Situation Awareness and Active Defense Method of Cyber Physical Power System for Cyber Attack) 本文责任编委 陈积明 Recommended by Associate Editor CHEN Ji-Ming 1. 武汉大学 武汉 430072 2. 空天信息安全与可信计算教育部重点实验室 武汉 430072 3. 南瑞集团有限公司 (国网电力科学研2) 究院有限公司) 南京 211106 4. 国电南瑞科技股份有限公司 南京 211106 5. 智能电网保护和运行控制国家重点实验室 南京 211106 1. Wuhan University, Wuhan 430072 2. Key Laboratory of Aerospace Information Security and Trusted Computing, Ministry of Education, Wuhan 430072 3. NARI Group Corporation (State Grid Electric Power Research Institute), Nanjing 211106 4. NARI Technology Co. Ltd., Nanjing 211106 5. State Key Laboratory of Smart Grid Protection and Control, Nanjing 211106 -
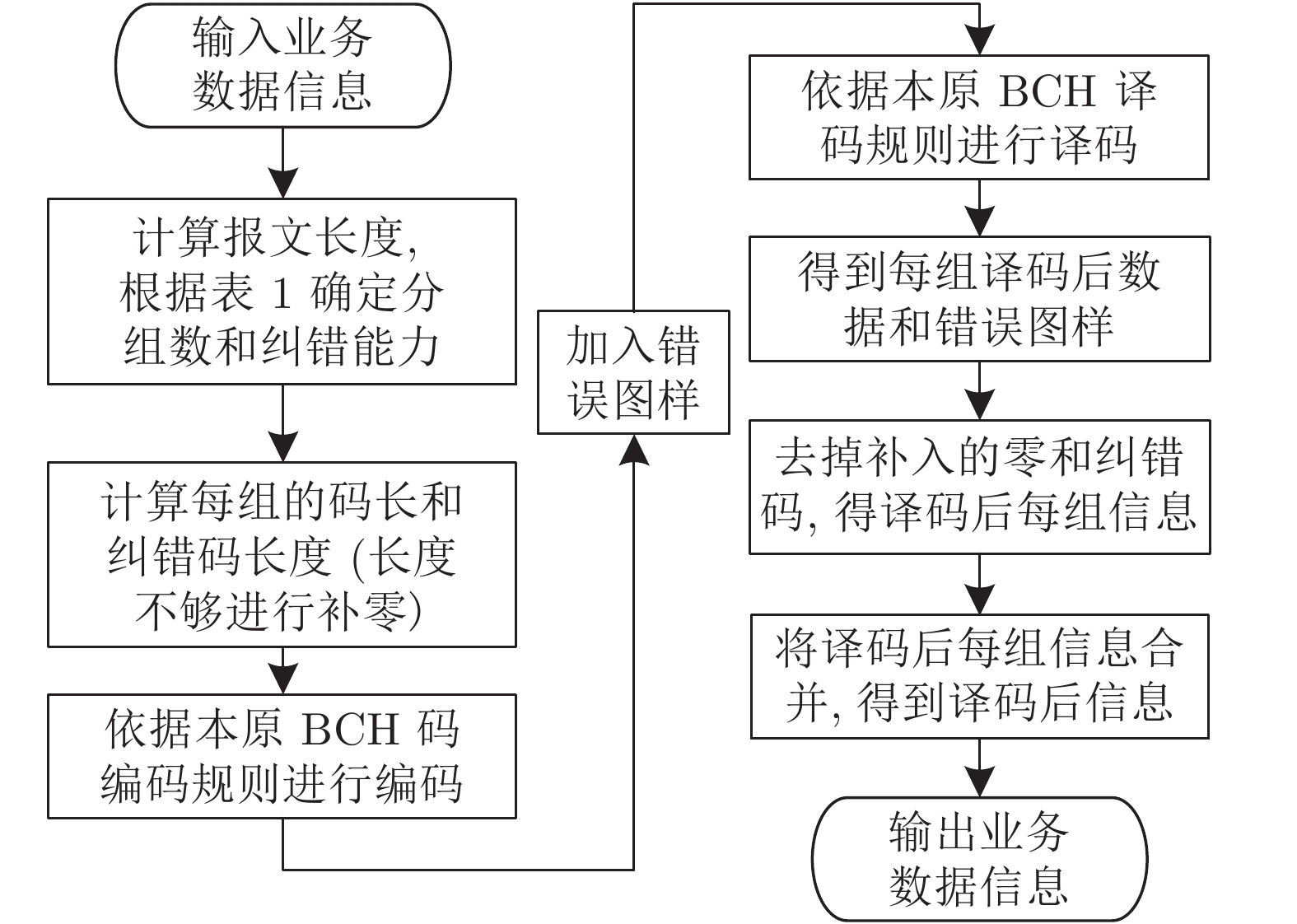
图 1 纠错算法实验程序流程图
Fig. 1 Flowchart of the experiment program for error correction algorithm

图 3 网络畅通时采用TCP和UDP的业务最大时延
Fig. 3 Maximum delays of messages using TCP and UDP when the network is uncongested

图 4 网络拥塞时采用TCP和UDP的业务最大时延
Fig. 4 Maximum delays of messages using TCP and UDP when the network is congested
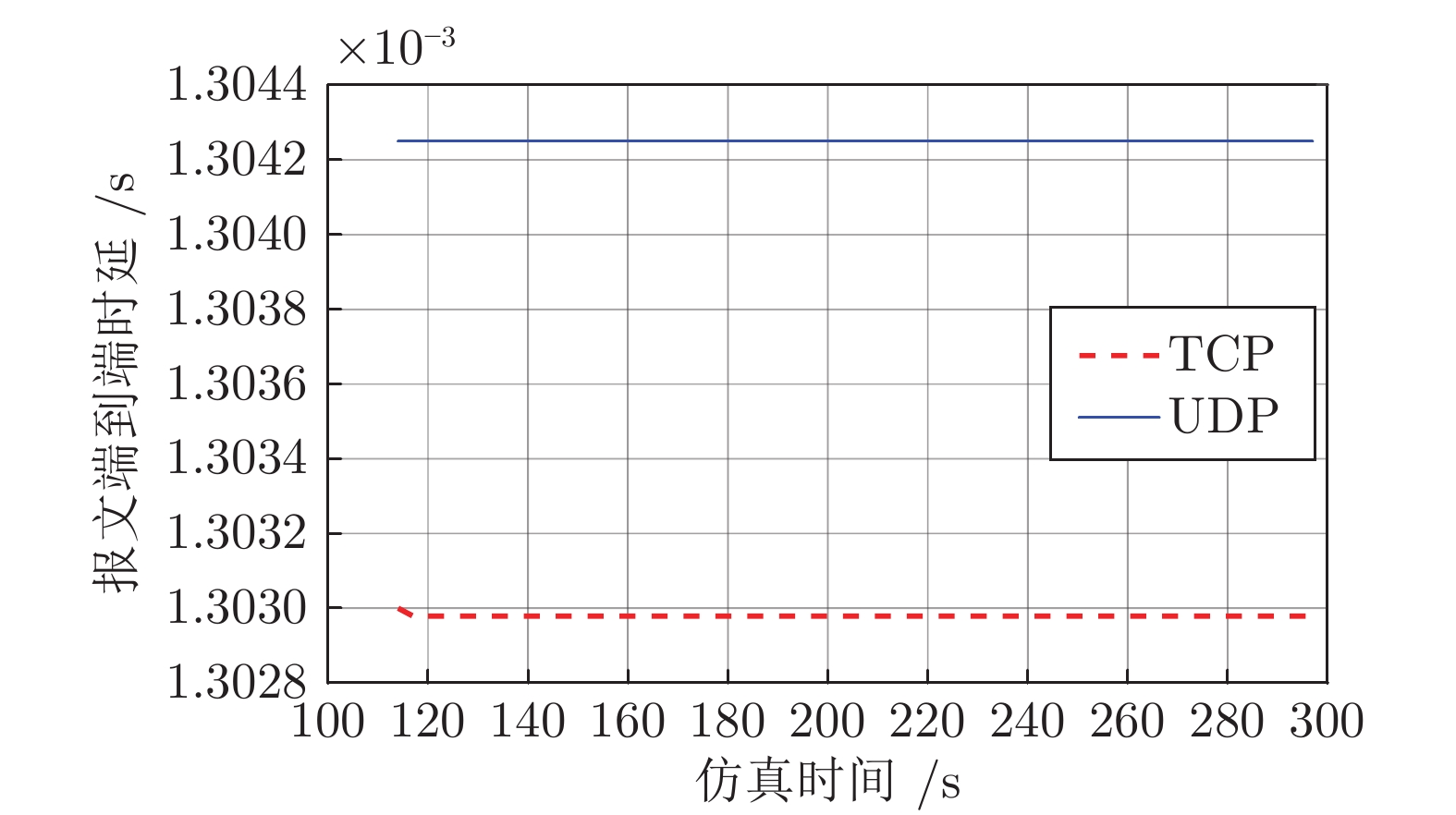
图 5 网络畅通时TCP和UDP传输下报文的端到端最大时延
Fig. 5 Maximum end-to-end delays in TCP and UDP transmission modes when network is uncongested
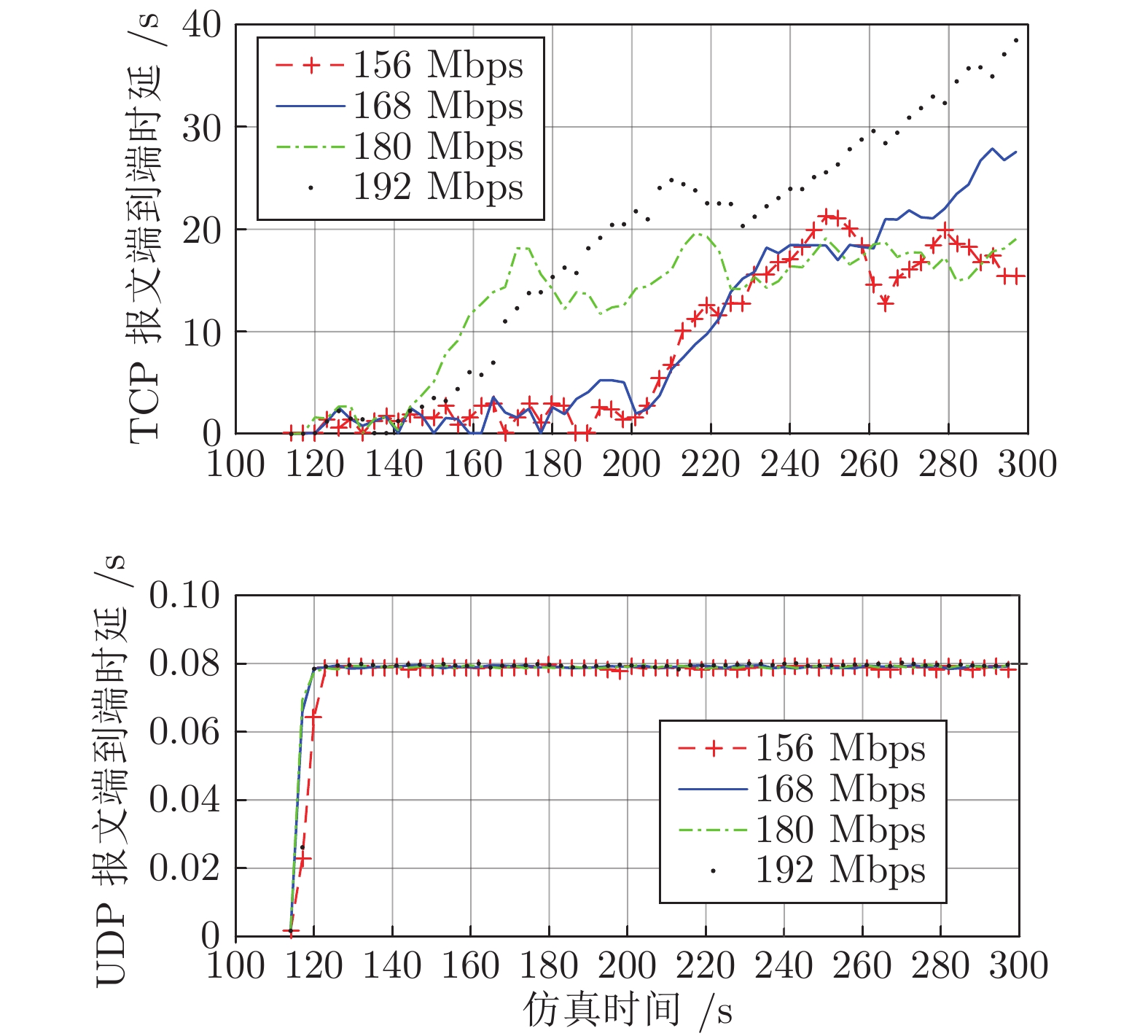
图 6 4种拥塞流量时TCP和UDP报文的端到端最大时延
Fig. 6 Maximum end-to-end delay of TCP and UDP packets in four types of congestion traffic

图 7 报文连续发送N次的总时延构成
Fig. 7 Composition of the total delay when the message is transmitted N copies
表 1 一种本原BCH码分组方法
Table 1 A grouping method of original BCH code
应用层报文长度 (byte) 分组数 (n, k) 每组加入的纠错码长度 (bit) 每组纠错位数 (bit) 总纠错位数 (bit) 参考信道误比特数 1~59 1 [511, 493] 18 2 2 1 60~115 4 [255, 247] 8 1 4 1 116~231 8 [255, 247] 8 1 8 2 232~462 16 [255, 247] 8 1 16 4 463~1400 64 [255, 247] 8 1 64 12  下载: 导出CSV
下载: 导出CSV
-
[1] 严佳梅, 许剑冰, 倪明, 余文杰. 通信系统中断对电网广域保护控制系统的影响. 电力系统自动化, 2016, 40(5): 17−24 doi: 10.7500/AEPS20150820004Yan Jian-Mei, Xu Jian-Bing, Ni Ming, Yu Wen-Jie. Impact of communication system interruption on power system wide area protection and control system. Automation of Electric Power Systems, 2016, 40(5): 17−24 doi: 10.7500/AEPS20150820004 [2] Teng S H, Wu N Q, Zhu H B. SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA Journal of Automatica Sinica, 2018, 5(1): 108−118 doi: 10.1109/JAS.2017.7510730 [3] 梅生伟, 朱建全. 智能电网中的若干数学与控制科学问题及其展望. 自动化学报, 2013, 39(2): 119−131 doi: 10.1016/S1874-1029(13)60014-2Mei Sheng-Wei, Zhu Jian-Quan. Mathematical and control scientic issues of smart grid and its prospects. Acta Automatica Sinica, 2013, 39(2): 119−131 doi: 10.1016/S1874-1029(13)60014-2 [4] 杨飞生, 汪璟, 潘泉, 康沛沛. 网络攻击下信息物理融合电力系统的弹性事件触发控制. 自动化学报, 2019, 45(1): 110−119Yang Fei-Sheng, Wang Jing, Pan Quan, Kang Pei-Pei. Resilient event-triggered control of grid cyber-physical systems against cyber attack. Acta Automatica Sinica, 2019, 45(1): 110−119 [5] Liu N, Zhang J H, Liu W X. Toward key management for communications of wide area primary and backup protection. IEEE Transactions on Power Delivery, 2010, 25(3): 2030−2032 doi: 10.1109/TPWRD.2010.2045930 [6] Begovic M, Novosel D, Karlsson D, Henville C, Michel G. Wide-area protection and emergency control. Proceedings of the IEEE, 2005, 93(5): 876−891 doi: 10.1109/JPROC.2005.847258 [7] 汪剑, 韩蕾, 覃琴, 杜鑫. 广域保护通信网络综述. 电力系统通信, 2012, 33(240): 5−8Wang Jian, Han Lei, Qin Qin, Du Xin. Summary of wide-area protection communication network. Telecommunications for Electric Power System, 2012, 33(240): 5−8 [8] 朱海婷, 丁伟, 缪丽华, 龚俭. UDP流量对TCP往返延迟的影响. 通信学报, 2013, 34(1): 19−29Zhu Hai-Ting, Ding Wei, Miao Li-Hua, Gong Jian. Effect of UDP traffic on TCP' s round-trip delay. Journal on Communications, 2013, 34(1): 19−29 [9] 罗万明, 林闯, 阎保平. TCP/IP拥塞控制研究. 计算机学报, 2001, 24(1): 1−17 doi: 10.3321/j.issn:0254-4164.2001.01.001Luo Wan-Ming, Lin Chuang, Yan Bao-Ping. A survey of congestion control in the internet. Chinese Journal of Computers, 2001, 24(1): 1−17 doi: 10.3321/j.issn:0254-4164.2001.01.001 [10] Serizawa Y, Imamura H, Kiuchi M. Performance evaluation of IP-based relay communications for wide-area protection employing external time synchronization. Proceeding of Power Engineering Society Summer Meeting, 2001, 2: 909−914 [11] Stahlhut J W, Browne T J, Heydt G T, Vittal V. Latency viewed as a stochastic process and its impact on wide area power system control signals. IEEE Transactions on Power Systems, 2008, 23(1): 84−91 doi: 10.1109/TPWRS.2007.913210 [12] 熊小萍. 电力系统广域通信网络可靠性分析与优化设计[博士学位论文]. 广西大学, 中国, 2014.Xiong Xiao-Ping. Reliability Analysis and Optimal Design of Wide Area Communication Network in Power System [Ph.D. dissertation]. Guangxi University, China, 2014. [13] 王阳光. 应对灾变的广域保护信息处理及通信技术研究[博士学位论文]. 华中科技大学, 中国, 2010.Wang Yang-Guang. Research on Information Management and Communication Technology of Wide Area Protection Coping with Power Grid Catastrophe [Ph.D. dissertation]. Huazhong University of Science and Technology, China, 2010. [14] 邢宁哲. 智能电网中通信网络可靠性保障技术的研究[博士学位论文]. 北京交通大学, 中国, 2017.Xing Ning-Zhe. Research on the Guarantee Technologies of Communication Networks Reliability in Smart Grid [Ph.D. dissertation]. Beijing Jiaotong University, China, 2017. [15] 董雪源. 基于互联网技术的电力系统广域保护通信体系研究[博士学位论文]. 西南交通大学, 中国, 2012.Dong Xue-Yuan. Studies on the Internet Technology Based Communication System in Power System Wide Area Protection [Ph.D. dissertation]. Southwest Jiaotong University, China, 2012. [16] 范开俊, 徐丙垠, 陈羽, 韩国政, 逯怀东. 配电网分布式控制实时数据的GOOSE over UDP传输方式. 电力系统自动化, 2016, 40(4): 115−120 doi: 10.7500/AEPS20150615006Fan Kai-Jun, Xu Bing-Yin, Chen Yu, Han Guo-Zheng, Lu Huai-Dong. Goose over UDP transmission mode for real-time data of distributed control application in distribution networks. Automation of Electric Power Systems, 2016, 40(4): 115−120 doi: 10.7500/AEPS20150615006 [17] 肖行诠, 苟骁毅, 肖岚, 李乐, 温丽丽, 段刚, 等. 基于UDP协议的局域网 WAMS数据低延迟可靠传输方法. 电力自动化设备, 2011, 31(10): 148−152 doi: 10.3969/j.issn.1006-6047.2011.10.031Xiao Xing-Quan, Gou Xiao-Yi, Xiao Lan, Li Le, Wen Li-Li, Duan Gang, et al. UDP-based small-delay and reliable transfer of WAMS data in LAN. Electric Power Automation Equipment, 2011, 31(10): 148−152 doi: 10.3969/j.issn.1006-6047.2011.10.031 [18] 张新昌, 张项安. 层次化保护控制系统及其网络通信技术研究. 电力系统保护与控制, 2014, 42(19): 129−133 doi: 10.7667/j.issn.1674-3415.2014.19.020Zhang Xin-Chang, Zhang Xiang-An. Research on hierarchical protection and control system and its communication technology. Power System Protection and Control, 2014, 42(19): 129−133 doi: 10.7667/j.issn.1674-3415.2014.19.020 [19] 刘育权, 华煌圣, 李力, 王莉, 刘金生. 多层次的广域保护控制体系架构研究与实践. 电力系统保护与控制, 2015, 43(5): 112−122Liu Yu-Quan, Hua Huang-Sheng, Li Li, Wang Li, Liu Jin-Sheng. Research and application of multi-level wide-area protection system. Power System Protection and Control, 2015, 43(5): 112−122 [20] 吴科成, 林湘宁, 鲁文军, 刘沛. 分层式电网区域保护系统的原理和实现. 电力系统自动化, 2007, 31(3): 72−78 doi: 10.3321/j.issn:1000-1026.2007.03.015Wu Ke-Cheng, Lin Xiang-Ning, Lu Wen-Jun, Liu Pei. Principle and realization of the hierarchical region protective system for power systems. Automation of Electric Power Systems, 2007, 31(3): 72−78 doi: 10.3321/j.issn:1000-1026.2007.03.015 [21] Technical Brochure No. 187, CIGRE. System Protection Schemes in Power Networks, June, 2001. [22] 徐天奇, 尹项根, 游大海, 王阳光. 3层式广域保护系统通信网络. 电力系统自动化, 2008, 16(32): 28−33Xu Tian-Qi, Yin Xiang-Gen, You Da-Hai, Wang Yang-Guang. Communication network for three-level wide area protection system. Automation of Electric Power Systems, 2008, 16(32): 28−33 [23] Adamiak M G, Apostolov A P, Begovic M M, Henville C F, Martin K E, Michel G L, et al. Wide area protection: technology and infrastructures. IEEE Transactions on Power Delivery, 2006, 21(2): 601−609 doi: 10.1109/TPWRD.2005.855481 [24] 王新梅, 肖国镇. 纠错码 — 原理与方法. 西安电子科技大学出版社, 2001.Wang Xin-Mei, Xiao Guo-Zhen. Error Correction Code: Principles and Methods. Xidian University Press, 2001. -

 下载:
下载:

计量
- 文章访问数: 1537
- HTML全文浏览量: 337
- PDF下载量: 114
- 被引次数: 0
