

-
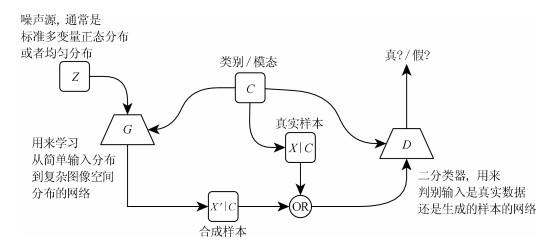
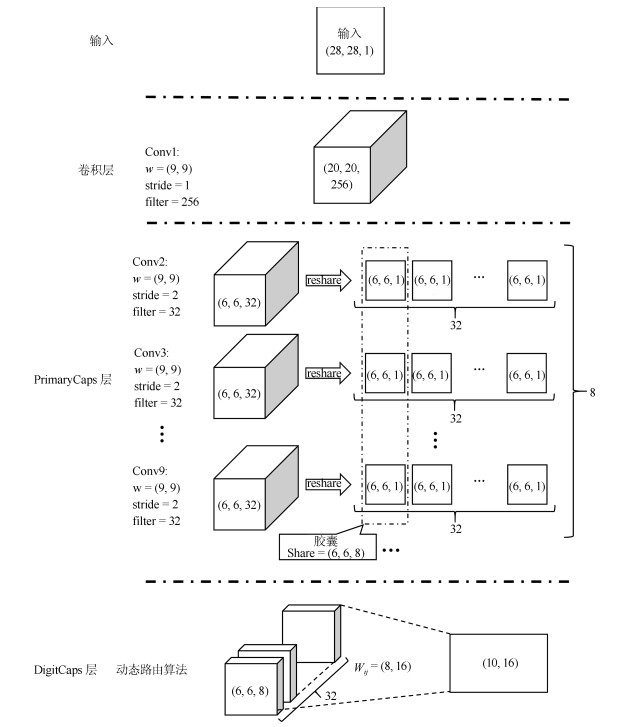
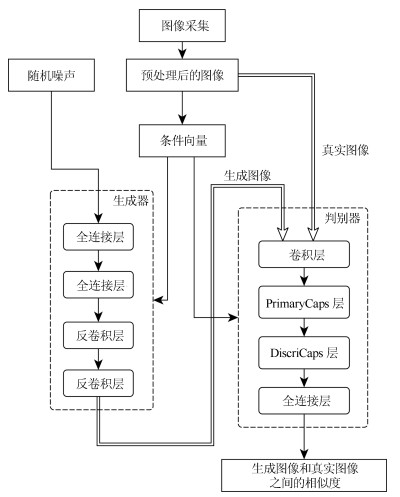
摘要: 生成式对抗网络(Generative adversarial networks, GAN)是主要的以无监督方式学习深度生成模型的方法之一.基于可微生成器网络的生成式建模方法, 是目前最热门的研究领域, 但由于真实样本分布的复杂性, 导致GAN生成模型在训练过程稳定性、生成质量等方面均存在不少问题.在生成式建模领域, 对网络结构的探索是重要的一个研究方向, 本文利用胶囊神经网络(Capsule networks, CapsNets)重构生成对抗网络模型结构, 在训练过程中使用了Wasserstein GAN (WGAN)中提出的基于Earth-mover距离的损失函数, 并在此基础上加以条件约束来稳定模型生成过程, 从而建立带条件约束的胶囊生成对抗网络(Conditional-CapsuleGAN, C-CapsGAN).通过在MNIST和CIFAR-10数据集上的多组实验, 结果表明将CapsNets应用到生成式建模领域是可行的, 相较于现有类似模型, C-CapsGAN不仅能在图像生成任务中稳定生成高质量图像, 同时还能更有效地抑制模式坍塌情况的发生.Abstract: Generative adversarial networks (GAN) is one of the main methods of learning deep generative models in an unsupervised fashion. The generative modeling method based on a network of differential generators is the hottest research field, but due to the complexity of the real sample distribution, the GAN has many problems in the stability of training process and the quality of generation. In the field of generative modeling, the exploration of network structure is an important research direction. And in this paper, we use the capsule networks (CapsNets) to reconstruct the structure of GAN, and the loss function based on Earth-mover distance proposed in Wasserstein GAN (WGAN) is used in the training process, and then we add the conditional constraints to stabilize the model generation process. According to the above, a conditional generative adversarial capsule networks (C-CapsGAN) is established. The results of multiple simulation experiments on the MINIST and CIFAR-10 datasets show that it is feasible to apply the CapsNets to the generative modeling field. Besides, compared with the existing similar model, C-CapsGAN can not only stably produce high-quality images in the image generation task, but also inhibit the occurrence of pattern collapse more effectively.
-
Key words:
- Generative adversarial networks (GAN) /
- Capsule networks (CapsNets) /
- image generation /
- conditional model
1) 本文责任编委 金连文 -

图 7 MNIST上d_loss变化趋势(PrimaryCaps层胶囊个数为32)
Fig. 7 Trends of d_loss on MNIST (32 capslue in PrimaryCaps layer)
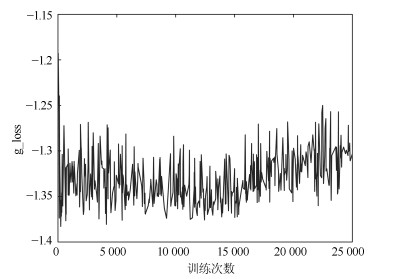
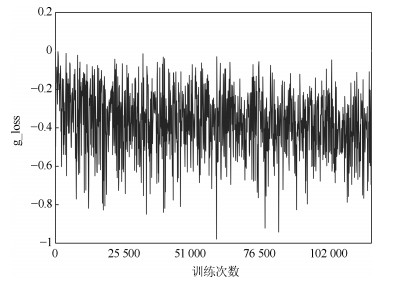
图 8 MNIST上g_loss变化趋势(PrimaryCaps层胶囊个数为32)
Fig. 8 Trends of g_loss on MNIST (32 capslue in PrimaryCaps layer)

图 9 C-CapsGAN-32在MNIST数据集训练生成结果(从左到右分别从Epoch1、5、10、15、20、24采样得到)
Fig. 9 Sample images generated by C-CapsGAN-32 in MNIST dataset (sampled from Epoch1, 5, 10, 15, 20, 24 from left to right)
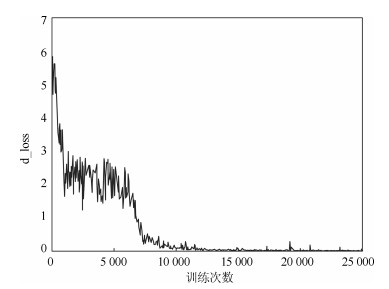
图 10 MNIST上d_loss变化趋势(PrimaryCaps层胶囊个数为24)
Fig. 10 Trends of d_loss on MNIST (24 capslue in PrimaryCaps layer)
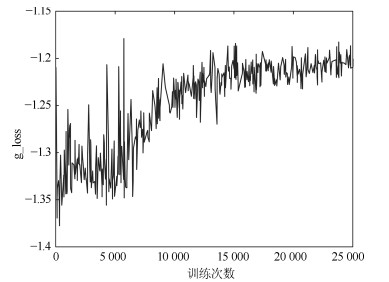
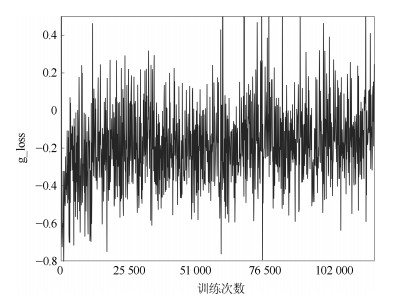
图 11 MNIST上g_loss变化趋势(PrimaryCaps层胶囊个数为24)
Fig. 11 Trends of g_loss on MNIST (24 capslue in PrimaryCaps layer)

图 12 C-CapsGAN-24在MNIST数据集训练生成结果(从左到右分别从Epoch1、5、10、15、20、24采样得到)
Fig. 12 Sample images generated by C-CapsGAN-24 in MNIST dataset (sampled from Epoch1, 5, 10, 15, 20, 24 from left to right)
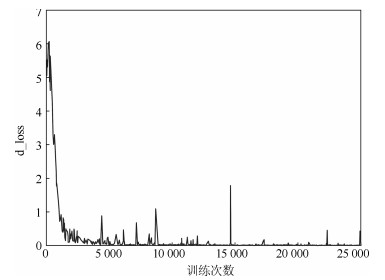
图 13 MNIST上d_loss变化趋势(PrimaryCaps层胶囊个数为16)
Fig. 13 Trends of d_loss on MNIST (16 capslue in PrimaryCaps layer)
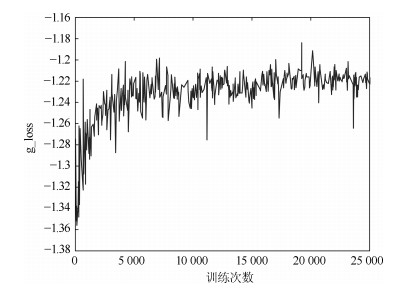
图 14 MNIST上g_loss变化趋势(PrimaryCaps层胶囊个数为16)
Fig. 14 Trends of g_loss on MNIST (16 capslue in PrimaryCaps layer)

图 15 C-CapsGAN-16在MNIST数据集训练生成结果(从左到右分别从Epoch1、5、10、15、20、24采样得到)
Fig. 15 Sample images generated by C-CapsGAN-16 in MNIST dataset (sampled from Epoch1, 5, 10, 15, 20, 24 from left to right)

图 16 传统GAN在MNIST数据集训练的生成结果(从左到右分别从Epoch1、5、10、15、20、24采样得到)
Fig. 16 Sample images generated by GAN in MNIST dataset (sampled from Epoch1, 5, 10, 15, 20, 24 from left to right)

图 17 DCGAN在MNIST数据集训练生成结果(从左到右分别从Epoch1、5、10、15、20、24采样得到)
Fig. 17 Sample images generated by DCGAN in MNIST dataset (sampled from Epoch1, 5, 10, 15, 20, 24 from left to right)

图 20 C-CapsGAN生成的样本图像
Fig. 20 Sample images generated by C-CapsGAN in CIFAR-10 dataset

图 23 C-CapsGAN在Epoch分别为55、65、75随机采样的样本
Fig. 23 Sample images generated by C-CapsGAN in CIFAR-10 dataset (sampled from Epoch55, 65, 75 from left to right)
-
[1] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde- Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [2] Kurach K, Lucic M, Zhai X, et al. The GAN Landscape: Losses, Architectures, Regularization, and Normalization. arXiv preprint, arXiv: 1807.04720, 2018. [3] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003Wang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: the state of the art and beyond. Acta Electronica Sinica, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003 [4] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint, arXiv: 1511.06434, 2015. [5] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint, arXiv: 1411.1784, 2014. [6] Arjovsky M, Bottou L. Towards principled methods for training generative adversarial networks. arXiv preprint, arXiv: 1701.04862, 2017. [7] Arjovsky M, Chintala S, Bottou L. Wasserstein gan. arXiv preprint, arXiv: 1701.07875, 2017. [8] 林懿伦, 戴星原, 李力, 王晓, 王飞跃.人工智能研究的新前线:生成式对抗网络.自动化学报, 2018, 44(5): 775-792 doi: 10.16383/j.aas.2018.y000002Lin Yi-Lun, Dai Xing-Yuan, Li Li, Wang Xiao, Wang Fei-Yue. The new frontier of AI research: generative adversarial networks. Acta Electronica Sinica, 2018, 44(5): 775-792 doi: 10.16383/j.aas.2018.y000002 [9] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324 doi: 10.1109/5.726791 [10] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates, Inc., 2012. 1097-1105 [11] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Long Beach, USA: Springer, 2017. 3856-3866 [12] Hinton G E, Krizhevsky A, Wang S D. Transforming auto-encoders. In: Proceedings of the 21st International Conference on Artificial Neural Networks. Espoo, Finland: Springer, 2011. 44-51 [13] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A. Improved training of wasserstein GANs. arXiv preprint, arXiv: 1704.00028, 2017. [14] 王坤峰, 左旺孟, 谭营, 秦涛, 李力, 王飞跃.生成式对抗网络:从生成数据到创造智能.自动化学报, 2018, 44(5): 769-774 doi: 10.16383/j.aas.2018.y000001Wang Kun-Feng, Zuo Wang-Meng, Tan Ying, Qin Tao, Li Li, Wang Fei-Yue. Generative adversarial networks: from generating data to creating intelligence. Acta Electronica Sinica, 2018, 44(5): 769-774 doi: 10.16383/j.aas.2018.y000001 [15] Jaiswal A, AbdAlmageed W, Natarajan P. CapsuleGAN: Generative Adversarial Capsule Network. arXiv preprint, arXiv: 1802.06167, 2018. [16] Kussul E, Baidyk T. Improved method of handwritten digit recognition tested on MNIST database. Image and Vision Computing, 2004, 22(12): 971-981 doi: 10.1016/j.imavis.2004.03.008 [17] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint, arXiv: 1502.03167, 2015. [18] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv: 1207.0580, 2012 -

 下载:
下载:





计量
- 文章访问数: 3222
- HTML全文浏览量: 843
- PDF下载量: 373
- 被引次数: 0
