

-
摘要: 随着网络结构的不断扩大和日益复杂, 重叠社区发现技术对挖掘复杂网络深层潜在结构具有重要意义. 本文提出一种基于时间加权的重叠社区检测算法. 该方法考虑了用户兴趣的时间因素, 构建带有时间加权链接的用户-用户图. 接着, 基于网络节点的影响力计算用户全局相似度, 在此基础上通过计算节点的中心度作为度量节点对社区结构影响力的重要性指标, 从而提出一种社区中心点的选取方法. 最后, 通过效用函数的迭代计算实现重叠社区检测. 利用人工网络和真实网络对提出的算法进行验证, 实验结果表明: 相对于传统的社区发现方法, 该算法在社区发现质量和计算效率方面都优于许多已有重叠社区发现算法.Abstract: With the continuous expansion and complexity of network structure, overlapping community discovery technology is of great signiflcance to excavate the deep potential structure of complex network. This article presents an overlapping community detection algorithm based on time time-weighted. Considering the time factor of user interest, this method constructs a user-user graph with time-weighted links. Then, the global similarity of users is calculated based on the influence of network nodes. On this basis, the centrality of nodes is calculated as an important index to measure the impact of nodes on community structure, and a method to select community centers is proposed. Finally, overlapping community detection is realized by iteration of utility function. The proposed algorithm is validated by artiflcial network and real network. The experimental results show that compared with traditional community discovery methods, the proposed algorithm outperforms many existing overlapping community discovery algorithms in terms of community discovery quality and computational efficiency.
-
Key words:
- Social network /
- time-weighted /
- overlap /
- community /
- detection
1) 本文责任编委 段书凯 -

图 1 Polblogs数据集中参数α对Q值的影响结果
Fig. 1 The influence of different α on the Q in Polblogs data set
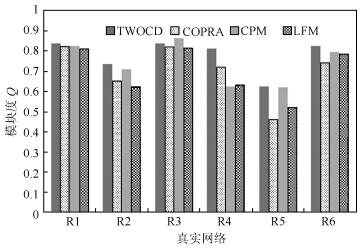
图 5 真实数据集上各算法性能对比实验
Fig. 5 Comparison results of different algorithms on real networks
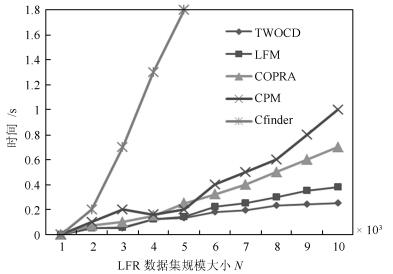
表 1 LFR基准网络生成参数说明
Table 1 Parameter setting of LFR benchmark network generation
参数 说明 N 网络的节点数目 k 网络中节点的平均度数 Cmin 最小社区的节点数目 Cmax 最大社区的节点数目 on 重叠节点的个数 om 重叠节点所从属的社区个数 mu 社区混合参数  下载: 导出CSV
下载: 导出CSV
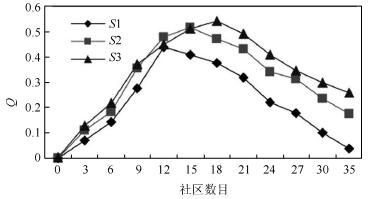
表 2 人工网络数据集
Table 2 Artificial network datasets
编号 N k Cmin Cmax mu on om S1 10 000 20 50 100 0.1~0.7 1 000 3 S2 100 000 20 100 200 0.1~0.7 5 000 2 S3 10 000 20 100 200 0.1 1 000 2~7
下载: 导出CSV
表 3 真实数据集
Table 3 Real datasets
编号 名称 节点数 边数 平均度 R1 Karate 34 78 4.75 R2 Doplphins 62 159 5.13 R3 Polbooks 105 441 8.40 R4 Football 115 613 10.66 R5 Folbogs 1 490 16 715 22.44 R6 DBLP 4 000 8 301 2.52
下载: 导出CSV
表 4 mu在不同取值时各算法在人工网络S1上的NMI实验结果
Table 4 NMI experimental results of different algorithms on S1 under different mu value
mu 0.1 0.2 0.3 0.4 0.5 0.6 0.7 TWOCD 0.53 0.45 0.34 0.24 0.23 0.22 0.22 COPRA 0.85 0.79 0.71 0.62 0.42 0.22 0.22 CPM 0.82 0.8 0.62 0.48 0.21 0.22 0.22 LFM 0.52 0.42 0.35 0.22 0.22 0.22 0.22
下载: 导出CSV
表 5 om在不同取值时各算法在人工网络S2上的NMI实验结果
Table 5 NMI experimental results of different algorithms on S2 under different om value
om 2 3 4 5 6 7 8 TWOCD 0.92 0.95 0.88 0.84 0.78 0.72 0.75 COPRA 0.93 0.9 0.83 0.78 0.71 0.65 0.6 CPM 0.92 0.87 0.81 0.78 0.69 0.62 0.62 LFM 0.76 0.68 0.66 0.67 0.65 0.66 0.5
下载: 导出CSV
表 6 on在不同取值时各算法在人工网络S3上的NMI实验结果
Table 6 NMI experimental results of different algorithms on S3 under different on value
on 1 000 2 000 3 000 4 000 5 000 6 000 7 000 TWOCD 0.95 0.95 0.89 0.76 0.67 0.56 0.38 COPRA 0.89 0.83 0.78 0.58 0.32 0.21 0.21 CPM 0.82 0.84 0.79 0.7 0.6 0.47 0.28 LFM 0.43 0.33 0.23 0.23 0.24 0.24 0.24
下载: 导出CSV
表 7 真实数据集上各算法在不同参数取值下性能对比结果
Table 7 Comparison results of different algorithms on different parameter in real networks
Data set LFM COPRA CPM TWOCD α Q v Q k Q α, β Q Karate 0.8 0.813 2 0.825 2 0.823 0.4, 0.8 0.8463 Football 1.1 0.645 2 0.656 4 0.707 0.4, 0.8 0.7246 Doplphins 0.8 0.812 6 0.821 5 0.924 0.3, 0.7 0.9005 Polbooks 0.9 0.634 8 0.717 8 0.795 0.4, 0.9 0.7342 Folbogs 1.4 0.122 2 0.466 6 0.625 0.4, 0.8 0.6257 DBLP 0.8 0.787 9 0.745 3 0.797 0.4, 0.8 0.8143
下载: 导出CSV
-
[1] Newman M E J. The Structure and function of complex networks. SIAM Review, 2003, 45(2): 167-256 doi: 10.1137/S003614450342480 [2] 潘剑飞, 董一鸿, 陈华辉, 等. 基于结构紧密性的重叠社区发现算法. 电子学报, 2019, 47(001): 145-152 https://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201901019.htmPan Jian-Fei, Dong Yi-Hong, Chen Hua-Hui, et al. The overlapping community discovery algorithm based on compact structure. Acta Electronic Sinica, 2019, 47(001): 145-152 https://www.cnki.com.cn/Article/CJFDTOTAL-DZXU201901019.htm [3] 李慧, 马小平, 施珺, 李存华, 仲兆满, 蔡虹. 复杂网络环境下基于信任传递的推荐模型研究. 自动化学报, 2018, 44(2): 363-376 doi: 10.16383/j.aas.2018.c160395Li Hui, Ma Xiao-Ping, Shi Jun, Li Cun-Hua, Zhong Zhao-man, Cai Hong. A recommendation model by means of trust transition in complex network environment. Acta Automatica Sinica, 2018, 44(2): 363-376 doi: 10.16383/j.aas.2018.c160395 [4] Xu M, Li Y, Li R, et al. EADP: An extended adaptive density peaks clustering for overlapping community detection in social networks. Neurocomputing, 2019, 337(14): 287-302 http://www.sciencedirect.com/science/article/pii/S092523121930102X [5] Gergely P, Imre D, Illés F, Tamás V. Uncovering the overlapping community structure of complex networks in nature and society. Nature, 2005, 435: 814-818 doi: 10.1038/nature03607 [6] Farkas I, ábel D, Palla G, et al. Weighted network modules. New Journal of Physics, 2007, 9(6): 180 doi: 10.1088/1367-2630/9/6/180 [7] Zhang Z, Wang Z. Mining overlapping and hierarchical communities in complex networks. Physica A: Statistical Mechanics and Its Applications, 2015, 421: 25-33 doi: 10.1016/j.physa.2014.11.023 [8] Wang L. Using the relationship of shared neighbors to find hierarchical overlapping communities for effective connectivity in IoT. In: Proceedings of the 6th International Conference on Pervasive Computing and Applications. New York, USA: IEEE, 2011. 400-406 [9] 陈俊宇, 周刚, 南煜, 曾琦. 一种半监督的局部扩展式重叠社区发现方法. 计算机研究与发展, 2016, 53(6): 1376-1388 https://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201606019.htmChen Jun-Yu, Zhou Gang, Nan Yu, Zeng Qi. Semi-supervised local expansion method for overlapping community detection. Journal of Computer Research and Development, 2016, 53(6): 1376-1388 https://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201606019.htm [10] Lancichinetti A, Fortunato S, Kertész J. Detecting the overlapping and hierarchical community structure in complex networks. New Journal of Physics, 2009, 11(3): 15-33 http://scitation.aip.org/getabs/servlet/GetabsServlet?prog=normal&id=VIRT01000019000015000092000001&idtype=cvips&gifs=Yes [11] Murphy R J L. Reliability of marking in eight GCE examinations. British Journal of Educational Psychology, 2011, 48(2): 196-200 doi: 10.1111/j.2044-8279.1978.tb02385.x/abstract [12] Lancichinetti A, Radicchi F, Ramasco J J, et al. Finding statistically significant communities in networks. PloS One, 2011, 6(4): e18961 doi: 10.1371/journal.pone.0018961 [13] Yang J, Zhang X D. Finding overlapping communities using seed set. Physica A: Statistical Mechanics and Its Applications, 2017, 467(1): 96-106 [14] Su Y J, LeeC C. Overlapping community detection with seed set expansion by local cluster coefficient. In: Proceedings of the International Conference on Consumer Electronics Piscataway, New York, USA: IEEE, 2017. 73-74 [15] Gregory S. Fuzzy overlapping communities in networks. Journal of Statistical Mechanics-Theory and Experiment, 2011, 2: P02017 [16] Eustace J, Wang X, Cui Y. Overlapping community detection using neighborhood ratio matrix. Physica A: Statistical Mechanics and its Applications, 2015, 421: 510-521 doi: 10.1016/j.physa.2014.11.039 [17] Raj E D, Babu L D D. A fuzzy adaptive resonance theory inspired overlapping community detection method for online social networks. Knowledge-Based Systems, 2016, 112(1): 75-87 doi: 10.5555/3045900.3050946 [18] Su Jianhan, Havens T C. Quadratic program-based modularity maximization for fuzzy community deterction in social network. IEEE Trans. on Fuzzy Systems, 2015, 23(5): 1356-1371 doi: 10.1109/TFUZZ.2014.2360723 [19] Javed M A, Younis M S, Latif S, et al. Community detection in networks: A multidisciplinary review. Journal of Network and Computer Applications, 2018, 108(15): 87-111 http://www.sciencedirect.com/science/article/pii/S1084804518300560 [20] Chen Naiyue, Liu Yun, Chao H C. Overlapping community detection using non-negative matrix factorization with orthogonal and sparseness constraints. IEEE Access, 2018, 6: 21266-21274 doi: 10.1109/ACCESS.2017.2783542 [21] Ahn Y Y, Lehmann S, Bagrow J, et al. Hierarchical link clustering in complex networks. American Physical Society, 2009, 3(2009): 1-10. http://meetings.aps.org/link/baps.2009.mar.v9.1 [22] Shi C, Cai Y, Fu D, et al. A link clustering based overlapping community detection algorithm. Data & Knowledge Engineering, 2013, 87: 394-404 http://ieeexplore.ieee.org/document/6574677/ [23] Lim S, Ryu S, Kwon S, et al. LinkSCAN: Overlapping community detection using the link-space transformation. In: Proceedings of the 30th International Conference on Data Engineering. New York, USA: IEEE, 2014. 292-303 [24] Li M M, Liu J. A link clustering based memetic algorithm for overlapping community detection. Physica A: Statistical Mechanics and Its Application, 2018, 503(1): 410-423 http://www.sciencedirect.com/science/article/pii/S037843711830253X [25] Gregory S. Finding overlapping communities in networks by label propagation. New Journal of Physics, 2009, 12(10): 2011-2024 http://arxiv.org/abs/0910.5516v3 [26] Xie J, Szymanski B K. Towards linear time overlapping community detection in social networks. In: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, New York, USA: IEEE, 2012. 25-36 [27] Gaiter C, Chen M M, Szymanski B, et al. Identifying robust communities and multi-community nodes by combining top-down and bottom-up approaches to clustering. Scientific Reports, 2015, 5: 16361 doi: 10.1038/srep16361 [28] Brin S, Page L. Reprint of: The anatomy of a large-scale hypertextual web search engine. Computer Networks, 2012, 56(18): 3825-3833 doi: 10.1016/j.comnet.2012.10.007 -

 下载:
下载:



计量
- 文章访问数: 1766
- HTML全文浏览量: 480
- PDF下载量: 187
- 被引次数: 0
