

-
摘要: 近年来深度神经网络(Deep neural network,DNN)从众多机器学习方法中脱颖而出,引起了广泛的兴趣和关注.然而,在主流的深度神经网络模型中,其参数数以百万计,需要消耗大量的计算和存储资源,难以应用于手机等移动嵌入式设备.为了解决这一问题,本文提出了一种基于动态量化编码(Dynamic quantization coding,DQC)的深度神经网络压缩方法.不同于现有的采用静态量化编码(Static quantitative coding,SQC)的方法,本文提出的方法在模型训练过程中同时对量化码本进行更新,使码本尽可能减小较大权重参数量化引起的误差.通过大量的对比实验表明,本文提出的方法优于现有基于静态编码的模型压缩方法.Abstract: Recently, deep neural network (DNN) stands out from many machine learning methods and has attracted wide interest and attention. However, it is difficult to apply DNN to mobile embedded devices such as mobile phones due to millions of parameters for the mainstream model of deep neural network, which requires a lot of calculation and storage resources. To address this problem, this paper proposes a deep neural network compressing method based on dynamic quantization coding (DQC). Different from the existing static quantitative coding (SQC) methods, the proposed method updates the quantized codebook in the training process, so as to minimize the error caused by large weight parameters. Numerous experiments show that the proposed method is superior to the existing model compression method based on SQC.1) 本文责任编委 胡清华
-
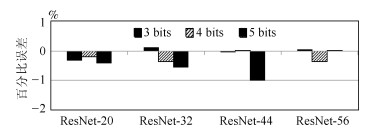
图 3 码本中无0, SQC和DQC的量化比较
Fig. 3 Quantization performance of SQC and DQC with 0 in codebook

图 4 码本中有0, SQC和DQC的量化效果比较
Fig. 4 Quantization performance of SQC and DQC without 0 in codebook
表 1 LeNet在Softmax-loss下量化效果
Table 1 Quantization performance of LeNet under Softmax-loss
位宽 码本无0 码本有0 3 99.29 % 99.22 % 4 99.30 % 99.25 % 5 99.35 % 99.32 %  下载: 导出CSV
下载: 导出CSV
表 2 LeNet在Softmax-loss+L1下量化效果
Table 2 Quantization performance of LeNet under Softmax-loss and L1
位宽 码本无0 码本有0 3 98.69 % 99.25 % 4 99.09 % 99.25 % 5 99.14 % 99.27 %
下载: 导出CSV
表 3 LeNet在Softmax-loss+L2下量化效果
Table 3 Quantization performance of LeNet under Softmax-loss and L2
位宽 码本无0 码本有0 3 99.26 % 99.29 % 4 99.29 % 99.28 % 5 99.36 % 99.28 %
下载: 导出CSV
表 4 ResNet-20在不同码本下量化效果
Table 4 Quantization performance of ResNet-20 under different codebook
位宽 码本无0 码本有0 3 90.07 % 90.78 % 4 91.71 % 91.91 % 5 92.63 % 92.82 %
下载: 导出CSV
表 5 ResNet-32在不同码本下量化效果
Table 5 Quantization performance of ResNet-32 under different codebook
位宽 码本无0 码本有0 3 91.44 % 92.11 % 4 92.53 % 92.36 % 5 92.87 % 92.33 %
下载: 导出CSV
表 6 ResNet-44在不同码本下量化效果
Table 6 Quantization performance of ResNet-44 under different codebook
位宽 码本无0 码本有0 3 92.68 % 92.53 % 4 93.14 % 93.37 % 5 93.28 % 93.14 %
下载: 导出CSV
表 7 ResNet-56在不同码本下量化效果
Table 7 Quantization performance of ResNet-56 under different codebook
位宽 码本无0 码本有0 3 92.72 % 92.69 % 4 93.54 % 93.39 % 5 93.21 % 93.24 %
下载: 导出CSV
表 8 固定码本下量化效果
Table 8 Quantization performance of SQC
网络 3 bits码本 3bits码本 3 bits码本 3 bits码本 3 bits码本 3 bits码本 SQC无0 SQC有0 SQC无0 SQC有0 SQC无0 SQC有0 ResNet-20 92.72 % 92.69 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-32 93.54 % 93.39 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-44 93.21 % 93.24 % 92.72 % 92.69 % 92.72 % 92.69 % ResNet-56 93.21 % 93.24 % 92.72 % 92.69 % 92.72 % 92.69 %
下载: 导出CSV
表 9 Deep compression与DQC的实验比较
Table 9 Comparison of deep compression and DQC
压缩方法 位宽 准确率 Deep compression 5 99.20 % DQC 5 99.70 %
下载: 导出CSV
表 10 量化为5 bits时INQ和DQC在CIFAR-10上的准确率比较
Table 10 Compare the accuracy of INQ and DQC on CIFAR-10 with 5 bits
网络 INQ DQC码本无0 DQC码本有0 ResNet-20 91.01 % 92.63 % 92.82 % ResNet-32 91.78 % 92.87 % 92.33 % ResNet-44 92.30 % 93.28 % 93.14 % ResNet-56 92.29 % 93.21 % 93.24 %
下载: 导出CSV
-
[1] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc, 2012. 1097-1105 [2] Russakovsky O, Deng J, Su H, et al. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision, 2015, 115(3):211-252 http://d.old.wanfangdata.com.cn/NSTLHY/NSTL_HYCC0214533907/ [3] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Computer Science, 2014 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1080/01431161.2018.1506593 [4] Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions. In: Proceeding of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA: IEEE, 2015. 1-9 [5] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770-778 [6] He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks. In: Proceeding of the European Conference on Computer Vision. Springer International Publishing, 2016. 630-645 [7] Gong Y C, Liu L, Yang M, Bourdev L. Compressing deep concolutional net-works using vector quantization. arXiv preprint, arXiv: 1412.6115v1, 2014. [8] Chen W, Wilson J T, Tyree S, et al. Compressing Neural Networks with the Hashing Trick. Computer Science, 2015:2285-2294 http://arxiv.org/abs/1504.04788 [9] Han S, Mao H, Dally W J. Deep compression:compressing deep neural networks with pruning, trained quantization and Huffman coding. Fiber, 2015, 56(4):3-7 [10] Courbariaux M, Bengio Y, David J P. BinaryConnect: training deep neural networks with binary weights during propagations. arXiv preprint, arXiv: 1511.00363, 2015. [11] Courbariaux M, Hubara I, Soudry D, et al. Binarized neural networks: training deep neural networks with weights and activations constrained to +1 or -1. arXiv preprint, arXiv: 1602.02830, 2016. [12] Rastegari M, Ordonez V, Redmon J, et al. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In: Proceedings of the European Conference on Computer Vision. Springer, Cham, 2016. 525-542 [13] Li Z, Ni B, Zhang W, Yang X, Gao W. Performance Guaranteed Network Acceleration via High-Order Residual Quantization. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017. 2603-2611 [14] Li F, Zhang B, Liu B. Ternary weight networks. arXiv preprint, arXiv: 1605.04711, 2016. [15] Zhu C Z, Han S, Mao H Z, Dally W J. Trained ternary quantization. arXiv preprint, arXiv: 1612.01064, 2016. [16] Cai Z, He X, Sun J, Vasconcelos N. Deep Learning with Low Precision by Half-Wave Gaussian Quantization. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). arXiv preprint, arXiv: 1702.00953, 2017. [17] Zhou A J, Yao A B, Guo Y W, Xu L, Chen Y R. Incremental network quantization: towards lossless CNNs with low-precision weights. arXiv preprint, arXiv: 1702.03044, 2017. [18] Song Han, Jeff Pool, John Tran, William J. Dally. Learning Both Weights and Connections for Efficient Neural Networks. arXiv: 1506.02626, 2015. [19] Anwar S, Sung W Y. Coarse pruning of convolutional neural networks with random masks. In: Proceedings of the Int'l Conference on Learning and Representation (ICLR). IEEE, 2017. 134-145 [20] Li H, Kadav A, Durdanovic I, Samet H, Graf H P. Pruning filters for efficient ConvNets. In: Proceedings of the Int'l Conference on Learning and Representation (ICLR). IEEE, 2017. 34-42 [21] Luo J H, Wu J, Lin W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. 2017: arXiv: 1707.06342 [22] Hu H, Peng R, Tai Y W, Tang C K. Network trimming: a data-driven neuron pruning approach towards efficient deep architectures. In: Proceedings of the Int'l Conference on Learning and Representation (ICLR). IEEE, 2017. 214-222 [23] Luo J, Wu J. An Entropy-based Pruning Method for CNN Compression. CoRR, 2017. abs/1706.05791 [24] Yang T, Chen Y, Sze V. Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6071-6079 [25] Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network. Computer Science, 2015, 14(7):38-39 [26] Romero A, Ballas N, Kahou SE, Chassang A, Gatta C, Bengio Y. Fitnets: Hints for thin deep nets. In: Proceedings of the Int'l Conference on Learning and Representation (ICLR). IEEE, 2017. 124-133 [27] Zagoruyko S, Komodakis N.Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. CoRR, 2016. abs/1612.03928 [28] Zhang X, Zou J, He K, et al. Accelerating very deep convolutional networks for classification and detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10):1943-1955 doi: 10.1109/TPAMI.2015.2502579 [29] Lebedev V, Ganin Y, Rakhuba M, et al. Speeding-up convolutional neural networks using fine-tuned CP-decomposition. Computer Science, 2015. [30] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size. 2016. [31] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. 2017. arXiv: 1704.04861 [32] Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. 2017. [33] Bengio, Yoshua, Léonard, Nicholas, and Courville, Aaron. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv: 1308.3432, 2013. [34] LeCun, Bottou, Bengio, Haffner. Gradient-based learning applied to document recognition. In: Proceedings of the IEEE, 1998. 86(11): 2278-2324 [35] Krizhevsky A. Learning multiple layers of features from tiny images. Handbook of Systemic Autoimmune Diseases, 2009, 1(4). -

 下载:
下载:


计量
- 文章访问数: 1708
- HTML全文浏览量: 786
- PDF下载量: 159
- 被引次数: 0
