

Time Series Prediction Based on Improved Differential Evolution and Echo State Network
-
摘要:
针对回声状态网络无法根据不同的时间序列有效地选择储备池参数的问题, 本文提出一种新型预测模型, 利用改进的差分进化算法来优化回声状态网络. 其中差分进化算法的缩放因子F、交叉概率CR和变异策略自适应调整, 以提高算法的寻优性能. 为验证本文方法的有效性, 对Lorenz时间序列、大连月平均气温 − 降雨量数据集进行仿真实验. 由实验结果可知, 本文提出的模型可以提高时间序列的预测精度, 且具有良好的泛化能力及实际应用价值.
Abstract:For the echo state network, it is difficult to select the suitable reservoir parameters for different time series. In this paper, we propose a new prediction model which uses an improved differential evolution algorithm to optimize the parameters of the echo state network. The scale factor and crossover probability of differential evolution algorithms are adaptively adjusted. In addition, offspring generation strategy is also adaptively adjusted. To verify the effectiveness of the proposed method, experiments were conducted on Lorenz time series, and monthly average temperature - rainfall time series of Dalian. Experimental results show that the model can improve forecast accuracy and has good generalization ability and practicability.
-
Key words:
- Time series /
- predictive model /
- differential evolution /
- echo state network
-

图 3 Lorenz-x(t)序列: IDE-ESN的预测曲线及误差曲线
Fig. 3 Lorenz-x(t) series: prediction and error curves obtained by IDE-ESN
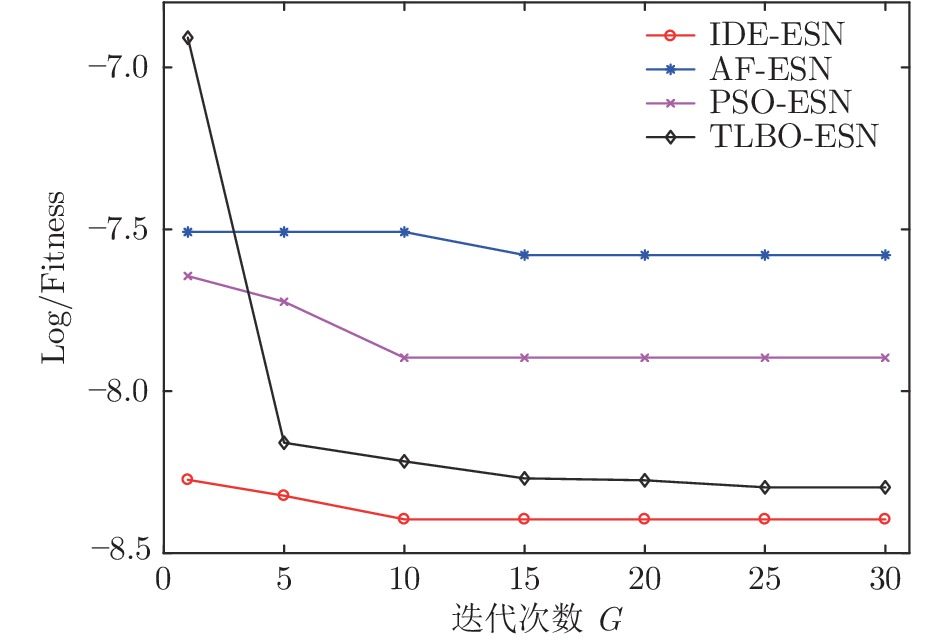
图 4 Lorenz-x(t)序列: 不同模型的适应度曲线
Fig. 4 Lorenz-x(t) series: the curves of fitness for different models
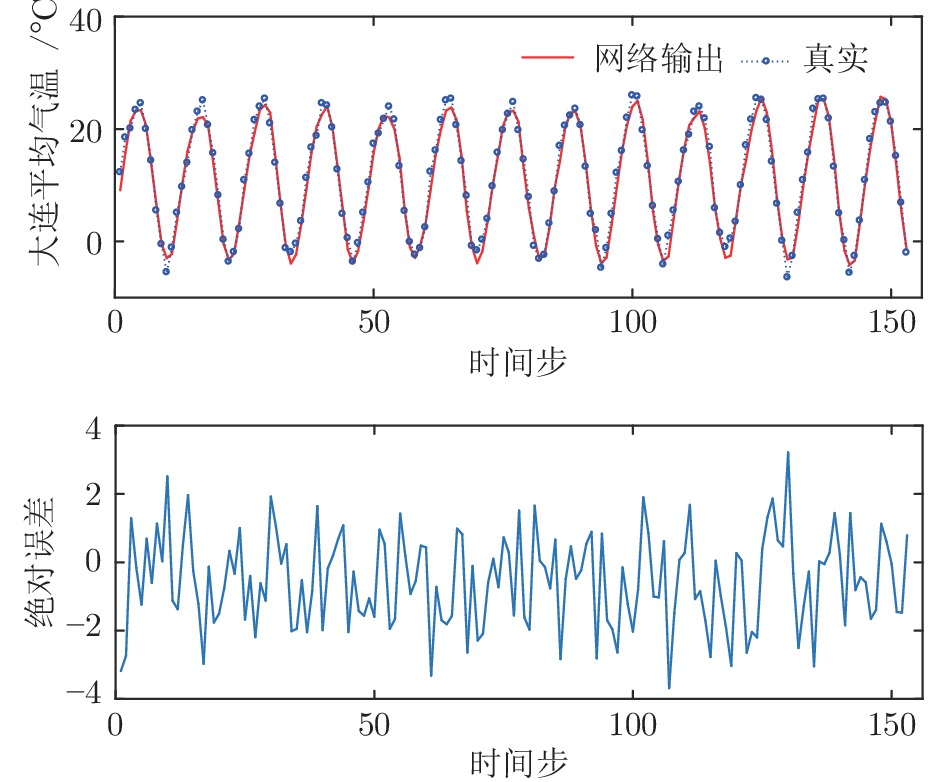
图 5 大连月平均气温: IDE-ESN的预测曲线及误差曲线
Fig. 5 Dalian monthly average temperature series: prediction and error curves obtained by IDE-ESN

图 6 大连月平均气温: 不同模型的适应度曲线
Fig. 6 Dalian monthly average temperature series: the curves of Fitness for differential models
表 1 Lorenz-x(t)序列: IDE-ESN模型参数
Table 1 Lorenz-x(t) series: parameters in IDE-ESN
储备池参数 取值 储备池规模 50 稀疏度 0.0210 谱半径 0.9589 输入变化因子 0.0600  下载: 导出CSV
下载: 导出CSV
表 2 Lorenz-x(t) 序列: 测试集仿真结果
Table 2 Lorenz-x(t) time series: prediction results on the test dataset
模型 RMSE SMAPE NRMSE AF-ESN 2.0850E-06 1.8571E-07 2.7992E-07 PSO-ESN 1.0139E-06 1.0211E-07 1.3613E-07 ELM 1.8422E-03 6.6638E-04 2.1061E-04 TLBO-ESN 7.7210E-07 1.6737E-07 1.0528E-07 IDE-ESN 3.2156E-07 9.8008E-08 4.3089E-08
下载: 导出CSV
表 3 Lorenz-x(t) 序列: 不同模型的运行时间
Table 3 Lorenz-x(t) series: run time of different models
模型 AF-ESN PSO-ESN TLBO-ESN IDE-ESN 时间 1405.4289 s 47.6972 s 168.3124 s 102.8856 s
下载: 导出CSV
表 4 大连月平均气温: IDE-ESN模型参数
Table 4 Dalian monthly average temperature-rainfall series: parameters in IDE-ESN
储备池参数 取值 储备池规模 47 稀疏度 0.0206 谱半径 0.9802 输入变化因子 0.0459
下载: 导出CSV
表 5 大连月平均气温: 测试集仿真结果
Table 5 Dalian monthly average temperature series: prediction results for the test dataset
模型 RMSE SMAPE NRMSE AF-ESN 1.8042 0.2902 0.1820 PSO-ESN 1.6511 0.2956 0.1666 ELM 5.4235 0.6704 0.5520 TLBO-ESN 1.6726 0.2088 0.1708 IDE-ESN 1.4215 0.2741 0.1440
下载: 导出CSV
表 6 大连月平均气温: 不同模型的运行时间
Table 6 Dalian monthly average temperature series: run time of different models
模型 AF-ESN PSO-ESN TLBO-ESN IDE-ESN 时间 347.1955 s 10.5115 s 31.1971 s 15.1921 s
下载: 导出CSV
-
[1] Su C H, Cheng C H. A hybrid fuzzy time series model based on ANFIS and integrated nonlinear feature selection method for forecasting stock. Neurocomputing, 2016, 205: 264−273 doi: 10.1016/j.neucom.2016.03.068 [2] Haidar A, Verma B. A novel approach for optimizing climate features and network parameters in rainfall forecasting. Soft Computing, 2018, 22(24): 8119−8130 doi: 10.1007/s00500-017-2756-7 [3] Arthun M, Eldevik T, Viste E, Drange H, Furevik T, Johnson H L, et al. Skillful prediction of northern climate provided by the ocean. Nature Communications, 2017, 8: 15875 doi: 10.1038/ncomms15875 [4] Wang X, Jiang R, Li L, Lin Y, Zheng X, Wang F. Capturing car-following behaviors by deep learning. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(3): 910−920 doi: 10.1109/TITS.2017.2706963 [5] 周平, 刘记平. 基于数据驱动多输出ARMAX建模的高炉十字测温中心温度在线估计. 自动化学报, 2018, 44(3): 552−561Zhou Ping, Liu Ji-Ping. Data-driven multi-output ARMAX model for online estimation of central temperatures for cross temperature measuring in blast furnace ironmaking. Acta Automatica Sinica, 2018, 44(3): 552−561 [6] 张颜颜, 唐立新. 改进的数据驱动子空间算法求解钢铁企业能源预测问题. 控制理论与应用, 2012, 29(12): 1616−1622Zhang Yan-Yan, Tang Li-Xin. Improved data-driven subspace algorithm for energy prediction in iron and steel industry. Control Theory and Application, 2012, 29(12): 1616−1622 [7] 郑念祖, 丁进良. 基于Regression GAN的原油总氢物性预测方法. 自动化学报, 2018, 44(5): 915−921Zheng Nian-Zu, Ding Jin-Liang. Regression GAN based prediction for physical of total hydrogen in crude oil. Acta Automatica Sinica, 2018, 44(5): 915−921 [8] Hearst M A, Dumais S T, Osuna E, Platt J, Scholkopf B. Support vector machines. IEEE Intelligent Systems and Their Applications, 1998, 13(4): 18−28 doi: 10.1109/5254.708428 [9] Trappey A J, Hsu F C, Trappey C V, Lin C I. Development of a patent document classification and search platform using a back-propagation network. Expert Systems with Applications, 2006, 31(4): 755−765 doi: 10.1016/j.eswa.2006.01.013 [10] Huang G B, Zhu Q Y, Siew C K. Extreme learning machine: Theory and application. Neurocomputing, 2006, 70: 489−502 doi: 10.1016/j.neucom.2005.12.126 [11] Jaeger H, Haas H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science, 2004, 304(5667): 78−80 doi: 10.1126/science.1091277 [12] 韩敏, 任伟杰, 许美玲. 一种基于L1范数正则化的回声状态网络. 自动化学报, 2014, 40(11): 2428−2435Han Min, Ren Wei-Jie, Xu Mei-Ling. An improved echo state network via L1-norm regularization. Acta Automatica Sinica, 2014, 40(11): 2428−2435 [13] 伦淑娴, 林健, 姚显双. 基于小世界回声状态网的时间序列预测. 自动化学报, 2015, 41(9): 1669−1679Lun Shu-Xian, Lin Jian, Yao Xian-Shuang. Time series prediction with an improved echo state network using small world network. Acta Automatica Sinica, 2015, 41(9): 1669−1679 [14] Han M, Xu M. Laplacian echo state network for multivariate time series prediction. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(1): 238−244 doi: 10.1109/TNNLS.2016.2574963 [15] 李德才, 韩敏. 基于鲁棒回声状态网络的混沌时间序列预测研究. 物理学报, 2011, 60(10): 108903 doi: 10.7498/aps.60.108903Li De-Cai, Han Min. Chaotic time series prediction based on robust echo state network. Acta Physica Sinica, 2011, 60(10): 108903 doi: 10.7498/aps.60.108903 [16] 韩敏, 王亚楠. 基于Kalman滤波的储备池多元时间序列在线预报器. 自动化学报, 2010, 36(1): 169−173 doi: 10.3724/SP.J.1004.2010.00169Han Min, Wang Ya-Nan. Multivariate time series online predictor with Kalman filter trained reservoir. Acta Automatica Sinica, 2010, 36(1): 169−173 doi: 10.3724/SP.J.1004.2010.00169 [17] Xu D, Lan J, Principe J C. Direct adaptive control: an echo state network and genetic algorithm approach[C]. In: Proceedings of the 2005 IEEE International Joint Conference on Neural Networks. Montreal, Canada: IEEE, 2005. 3: 1483−1486 [18] Wang J S, Han S, Guo Q P. Echo state networks based predictive model of vinyl chloride monomer convention velocity optimized by artificial fish swarm algorithm. Soft Computing, 2014, 18(3): 457−468 doi: 10.1007/s00500-013-1068-9 [19] Chouikhi N, Ammar B, Rokbani N, Alimi A M. PSO-based analysis of echo state network parameters for time series forecasting. Applied Soft Computing, 2017, 55: 211−225 doi: 10.1016/j.asoc.2017.01.049 [20] 孙晓燕, 陈姗姗, 巩敦卫, 张勇. 基于区间适应值交互式遗传算法的加权多输出高斯过程代理模型. 自动化学报, 2014, 40(2): 172−184Sun Xiao-Yan, Chen Shan-Shan, Gong Dun-Wei, Zhang Yong. Weighted multi-output Gaussian process-based surrogate of interactive genetic algorithm with individual′s interval fitness. Acta Automatica Sinica, 2014, 40(2): 172−184 [21] Du W, Ying W, Yan G, Zhu Y, Cao X. Heterogeneous strategy particle swarm optimization. IEEE Transactions on Circuits and Systems II: Express Briefs, 2017, 64(4): 467−471 doi: 10.1109/TCSII.2016.2595597 [22] Mavrovouniotis M, Muller F M, Yang S. Ant colony optimization with local search for dynamic traveling salesman problems. IEEE Transactions on Cybernetics, 2017, 47(7): 1743−1756 doi: 10.1109/TCYB.2016.2556742 [23] Zhang Z, Wang K, Zhu L, Wang Y. A Pareto improved artificial fish swarm algorithm for solving a multi-objective fuzzy disassembly line balancing problem. Expert Systems with Applications, 2017, 86: 165−176 doi: 10.1016/j.eswa.2017.05.053 [24] 胡蓉, 钱斌. 一种求解随机有限缓冲区流水线调度的混合差分进化算法. 自动化学报, 2009, 35(12): 1580−1586Hu Rong, Qian Bin. A hybrid differential evolution algorithm for stochastic flow shop scheduling with limited buffers. Acta Automatica Sinica, 2009, 35(12): 1580−1586 [25] Rao R V, Savsani V J, Vakharia D P. Teaching-learning-based optimization: A novel method for constrained mechanical design optimization problems. Computer-Aided Design, 2011, 43: 303−315 doi: 10.1016/j.cad.2010.12.015 [26] Xu M L, Han M, Lin H F. Wavelet-denoising multiple echo state networks for multivariate time series prediction. Information Sciences, 2018, 465: 439−458 doi: 10.1016/j.ins.2018.07.015 [27] 周晓根, 张贵军, 郝小虎. 局部抽象凸区域剖分差分进化算法. 自动化学报, 2015, 41(7): 1315−1327Zhou Xiao-Gen, Zhang Gui-Jun, Hao Xiao-Hu. Differential evolution algorithm with local abstract convex region partition. Acta Automatica Sinica, 2015, 41(7): 1315−1327 [28] 丁进良, 杨翠娥, 陈立鹏, 柴天佑. 基于参考点预测的动态多目标优化算法. 自动化学报, 2017, 43(2): 313−320Ding Jin-Liang, Yang Cui-E, Chen Li-Peng, Chai Tian-You. Dynamic multi-objective optimization algorithm based on reference point prediction. Acta Automatica Sinica, 2017, 43(2): 313−320 [29] Zhang J Q, Sanderson A C. JADE: Adaptive differential evolution with optional external archive. IEEE Transactions on Evolutionary Computation, 2009, 13(5): 945−958 doi: 10.1109/TEVC.2009.2014613 [30] Zhao S Z, Suganthan P N, Das S. Self-adaptive differential evolution with multi-trajectory search for large-scale optimization. Soft Computing, 2011, 15: 2175−2185 doi: 10.1007/s00500-010-0645-4 -

 下载:
下载:


计量
- 文章访问数: 5316
- HTML全文浏览量: 3706
- PDF下载量: 348
- 被引次数: 0
