

-
摘要: 面向机载LiDAR数据的道路提取算法的常用数据结构存在局限: 2D格网及TIN表达多次回波数据时存在的信息损失会影响提取结果的完整性且提取结果为2D形式; 点云的空间结构及拓扑信息难以利用, 由此导致算法设计的困难.为此, 提出了一种基于灰度体元模型的3D道路提取算法.算法首先将LiDAR数据规则化为灰度体元模型(灰度为体元内LiDAR点的平均强度值的量化表示); 然后选取道路种子体元进而搜寻并标记种子及其3D连通区域为道路体元; 最后利用数学形态学优化提取结果.基于ISPRS提供的包含不同复杂程度的城区路网LiDAR数据测试"邻域尺度"和"灰度差阈值"参数的敏感性及提出的算法的精度.实验结果表明: 56邻域为最佳邻域尺度、2为最佳灰度差阈值; 道路提取的平均质量、完整度及正确率分别为70%、86.77%及81.13%;对相对平坦的单层路网及起伏较大的复杂路网均可成功提取.Abstract: 2D grid, TIN and point cloud, which are the commonly used methods to represent LiDAR data for road extraction, have defects, for example, it is difficult for 2D grid and TIN to represent multiple return LiDAR data and thus influences the integrity of grid and TIN-based road extraction results and their extraction results are 2D, it is difficult for point cloud to use its topological and adjacent information and thus leads to the difficulty in the design of point-based road extraction algorithm. To overcome these restrictions, a grayscale voxel model (GVM) based 3D road extraction algorithm is presented. LiDAR data are regularized into GVM in which the grayscale of a voxel corresponds to the quantized mean intensity of the LIDAR points within the voxel. Road seed voxels are selected and then seeds and their 3D connected regions are labeled as road voxels. The extracted road result is optimized using mathematical morphology. ISPRS urban LiDAR datasets, which are representative of road networks of different complexities, are used to analyze the sensitivity of "adjacency size" and "intensity difference threshold" parameters and assess the accuracy of the proposed algorithm quantitatively. The experiment results indicate that: 1) 56-adjacency is the optimal adjacency size and 2 is the optimal intensity difference threshold; 2) The average quality, completeness and correctness of road extraction were 70%, 86.77% and 81.13%, respectively; 3) Roads in the relatively flat single layer road network and the undulating complex road network can both be successfully extracted.
-
Key words:
- LiDAR /
- road extraction /
- grayscale voxel model /
- intensity /
- 3D
1) 本文责任编委 吴毅红 -
表 1 各不同邻域尺度及$T_{i}$下的道路提取算法总误差
Table 1 Total errors of the proposed algorithm with different adjacent sizes and $T_{i}$
CSite2/CSite3提取结果总误差(%) $T_{i}$ 6邻域 18邻域 26邻域 56邻域 64邻域 1 46.30/40.64 32.26/31.87 25.89/24.15 20.47/17.94 17.98/12.44 2 39.57/32.32 28.34/25.02 19.07/18.87 12.81/8.29 18.73/15.65 3 34.25/30.06 26.16/19.21 20.83/10.33 15.58/13.84 23.16/20.45 4 37.29/33.12 30.21/20.04 24.56/12.87 26.74/16.51 29.86/25.31  下载: 导出CSV
下载: 导出CSV
表 2 提出的算法的精度
Table 2 The accuracy of the proposed algorithm
数据 $R_{com}$(%) $R_{cor}$(%) $R_{q}$(%) CSite2 84.83 80.76 70.57 CSite3 88.71 81.50 73.84
下载: 导出CSV
表 3 Terrasolid道路提取精度
Table 3 The road extraction accuracy of Terrasolid
数据 $R_{com}$ (%) $R_{cor}$ (%) $R_{q}$ (%) CSite2 88.2 64.1 59.1 CSite3 93.8 56.9 54.8
下载: 导出CSV
-
[1] Matikainen L, Karila K, Hyyppa J, Litkey P, Puttonen E, Ahokas E. Object-based analysis of multispectral airborne laser scanner data for land cover classification and map updating. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 128: 298-313 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=79984fbea9862f0a930a7c93acf19b17 [2] Morsy S, Shaker A, El-Rabbany A. Multispectral LiDAR data for land cover classification of urban areas. Sensors. 2017, 17(5): 958 [3] Hui Z, Hu Y, Jin S, Yao Z Y. Road centerline extraction from airborne LiDAR point cloud based on hierarchical fusion and optimization. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 118: 22-36 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=28233cc10b86445d7235b3bc0428331f [4] 原战辉.基于机载LiDAR点云数据提取城区道路研究[硕士论文].西南交通大学, 中国, 2018Yuan Zhan-Hui. Research on Urban Road Extraction Based on Airborne LIDAR Point Cloud Data[Master thesis]. Southwest Jiaotong University, China, 2018 [5] 王濮, 邢艳秋, 王成, 习晓环, 骆社周.机载LiDAR数据提取山区道路方法研究.遥感技术与应用, 2017, 32(5): 851-857 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ygjsyyy201705009Wang Pu, Xing Yan-Qiu, Wang Cheng, Xi Xiao-Huan, Luo She-Zhou. Road extraction using airborne LiDAR data in mountainous areas. Remote Sensing Technology and Application, 2017, 32(5): 851-857 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ygjsyyy201705009 [6] Huo L, Silva C A, Klauberg C, Mohan M, Zhao L J, Tang P, Hudak A T. Supervised spatial classification of multispectral LiDAR data in urban areas. Plos One, 2018, 13(10): e0206185 [7] Sturari M, Frontoni E, Pierdicca R, Mancini A, Malinverni E S, Tassetti A N, Zingaretti P. Integrating elevation data and multispectral high-resolution images for an improved hybrid land use/land cover mapping. European Journal of Remote Sensing, 2017, 50(1): 1-17 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1080/22797254.2017.1274572 [8] 惠振阳.从机载LiDAR点云中提取城市道路网的关键技术研究[博士论文].中国地质大学, 中国, 2017Hui Zhen-Yang. Research on Some Key Techniques of Extracting City Road Networks from Airborne LiDAR Point Cloud[P.D. dissertation]. China University of Geosciences, China, 2017 [9] 胡澄宇.基于机载LiDAR的林间道路提取方法研究[硕士论文].西南交通大学, 中国, 2016Hu Cheng-Yu. Study on Forest Road Extraction Based on Airborne LiDAR Point Cloud[Master thesis]. Southwest Jiaotong Universtiy, China, 2016 [10] Ferraz A, Mallet C, Chehata N. Large-scale road detection in forested mountainous areas using airborne topographic lidar data. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 112: 23-36 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=11bfc8f0d414d2222458453ce1f23ffc [11] Peng J, Gao G. A method for main road extraction from airborne LiDAR data in urban area. In: Proceedings of the 2011 International Conference on Electronics, Communications and Control. Ningbo, China: IEEE, 2011. 2425-2428 [12] 彭检贵, 马洪超, 高广, 赵亮亮.利用机载LiDAR点云数据提取城区道路.测绘通报, 2012, (9): 16-19 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chtb201209006Peng Jian-Gui, Ma Hong-Chao, Gao Guang, Zhao Liang-Liang. Road extraction from airborne LiDAR point clouds data in urban area. Bulletin of Surveying and Mapping, 2012, (9): 16-19 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chtb201209006 [13] Choi Y W, Jang Y W, Lee H J, Cho G S. Three-dimensional LiDAR data classifying to extract road point in urban area. IEEE Geoscience and Remote Sensing Letters, 2008, 5(4): 725-729 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f35ba8c1e5d91528123fb1c82861424d [14] Matkan A A, Hajeb M, Sadeghian S. Road extraction from lidar data using support vector machine classification. Photogrammetric Engineering and Remote Sensing, 2014, 80(5): 409-422 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e335ac4ed68da753c40785af701acdf7 [15] Hu X, Li Y, Shan J, Zhang J, Zhang Y. Road centerline extraction in complex urban scenes from LiDAR data based on multiple features. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(11): 7448-7456 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=422ac8541c7f6cfce39cf34a7a09236d [16] 龚亮, 张永生, 李正国, 包全福.基于强度信息聚类的机载LiDAR点云道路提取.测绘通报, 2011, (9): 15-17 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chtb201109005Gong Liang, Zhang Yong-Sheng, Li Zheng-Guo, Bao Quan-Fu. Automated road extraction from LiDAR data based on clustering of intensity. Bulletin of Surveying and Mapping, 2011, (9): 15-17 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=chtb201109005 [17] 袁鹏飞, 黄荣刚, 胡平波, 杨必胜.基于多光谱LiDAR数据的道路中心线提取.地球信息科学学报, 2018, 20(4): 452-461 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=0120181103802104Yuan Peng-Fei, Huang Rong-Gang, Hu Ping-Bo, Yang Bi-Sheng. Road extraction method based on multi-spectral LiDAR data. Journal of Geo-information Science, 2018, 20(4): 452-461 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=0120181103802104 [18] Mario S, Linh T, Belén R, Debra L. Automatic extraction of road features in urban environments using dense ALS data. International Journal of Applied Earth Observation and Geoinformation, 2018, 64: 226-236 [19] Ferraz A, Mallet C, Chehata N. Large-scale road detection in forested mountainous areas using airborne topographic lidar data. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 112: 23-36 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=11bfc8f0d414d2222458453ce1f23ffc [20] Zhao R, Pang M, Wang J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. International Journal of Geographical Information Science, 2018, 32(5): 1-20 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1080/13658816.2018.1431840 [21] Niemeyer J, Rottensteiner F, Soergel U, Heipke C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2016, XLI-B3: 655-662 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=Doaj000004727273 [22] Yang Z, Jiang W, Xu B, Zhu Q, Jiang S, Huang W. A convolutional neural network-based 3D semantic labeling method for ALS point clouds. Remote Sensing, 2017, 9(9): 936-953 [23] 陈飞.基于机载LiDAR点云的道路提取方法研究[硕士论文].西南交通大学, 中国, 2013Chen Fei. A Study of Methods for Road Extraction from Airborne LIDAR Data[Master thesis]. Southwest Jiaotong Universtiy, China, 2013 [24] 徐玉军.基于机载激光雷达点云数据的分层道路提取算法研究[硕士论文].吉林大学, 中国, 2013Xu Yu-Jun. Research on Hierarchical Road Extraction Algorithm Based on Airborne LiDAR Point Cloud[Master thesis]. Jilin University, China, 2013 [25] 黄先锋, 李娜, 张帆, 万文辉.利用LiDAR点云强度的十字剖分线法道路提取.武汉大学学报(信息科学版), 2015, 40(12): 1563-1569Huang Xian-Feng, Li Na, Zhang Fan, Wan Wen-Hui. Automatic power lines extraction method from airborne LiDAR point cloud. Geomatics and Information Science of Wuhan University, 2015, 40(12): 1563-1569 [26] 丁小华.基于LiDAR数据的城市道路提取方法研究[硕士论文].中国地质大学, 中国, 2013Ding Xiao-Hua. Building Extraction Based on the LiDAR Point Cloud Data and Image Fusion[Master thesis]. China University of Geosciences, China, 2013 [27] Hagstrom S T. Voxel-based LIDAR Analysis And Applications[Ph.D. dissertation], Rochester Institute of Technology, America, 2014 [28] Rutzinger M, Rottensteiner F, Pfeifer N. A comparison of evaluation techniques for building extraction from airborne laser scanning. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2009, 2(1): 11-20 [29] Zhang T Y, Suen C Y. A fast parallel algorithm for thinning digital patterns. Communications of the ACM, 1984, 27(3): 236-239 -

 下载:
下载:

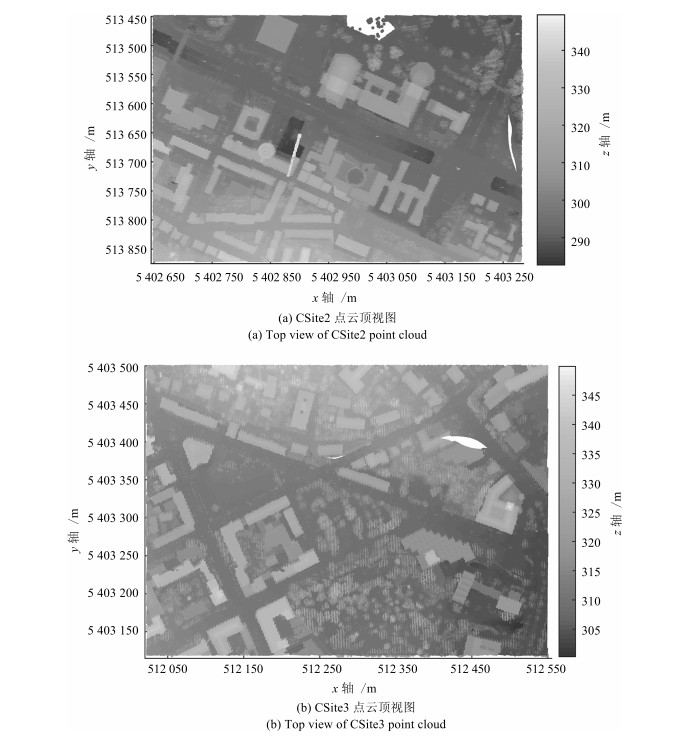

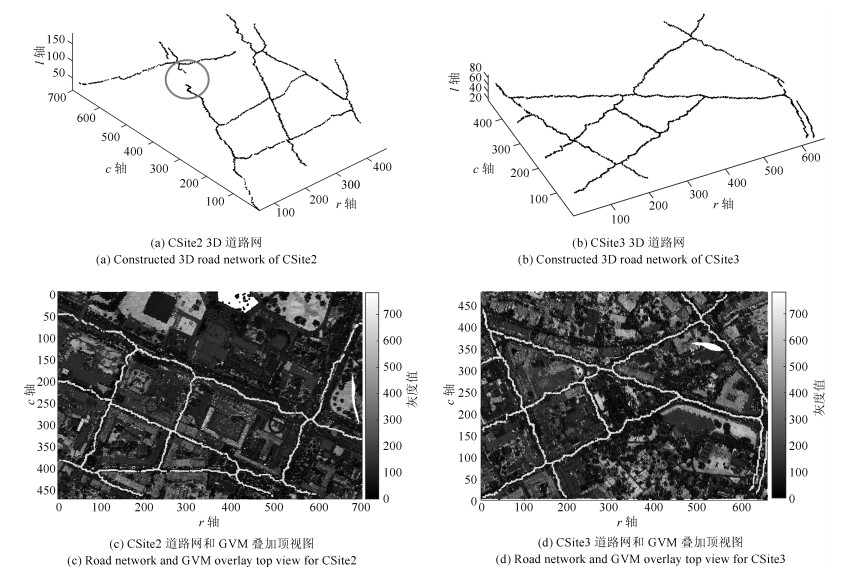
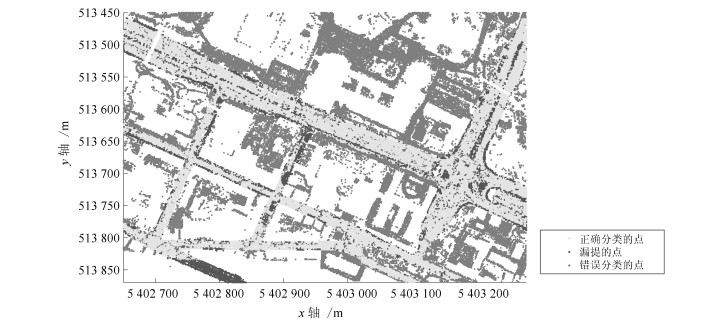


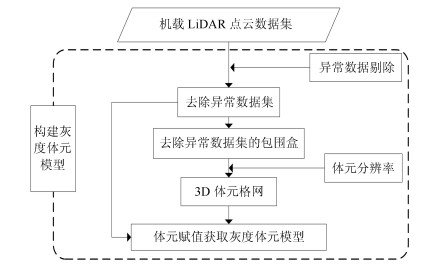
图(7) / 表(3)
计量
- 文章访问数: 763
- HTML全文浏览量: 269
- PDF下载量: 108
- 被引次数: 0
