

Evolutionary Optimization Framework Based on Transfer Learning of Similar Historical Information
-
摘要: 现有进化算法大都从问题的零初始信息开始搜索最优解, 没有利用先前解决相似问题时获得的历史信息, 在一定程度上浪费了计算资源.将迁移学习的思想扩展到进化优化领域, 本文研究一种基于相似历史信息迁移学习的进化优化框架.从已解决问题的模型库中找到与新问题匹配的历史问题, 将历史问题对应的知识迁移到新问题的求解过程中, 以提高种群的搜索效率.首先, 定义一种基于多分布估计的最大均值差异指标, 用来评价新问题与历史模型之间的匹配程度; 接着, 将相匹配的历史问题的知识迁移到新问题中, 给出一种基于模型匹配程度的进化种群初始化策略, 以加快算法的搜索速度; 然后, 给出一种基于迭代聚类的代表个体保存策略, 保留求解过程中产生的优势信息, 用于更新历史模型库; 最后, 将自适应骨干粒子群优化算法嵌入到所提框架, 给出一种基于相似历史信息迁移学习的骨干粒子群优化算法.针对多个改进的典型测试函数, 实验结果表明, 所提迁移策略可以加速粒子群的搜索过程, 显著提高算法的收敛速度和搜索效率.Abstract: Most of existing evolutionary algorithms search optimal solutions from zero initial information of a given problem. Because of the lacking a mechanism to use historical information, this must waste computing resources to some extent when solving a problem similar to old ones. This paper extends the idea of transfer learning to the field of evolutionary optimization, and studies a new evolutionary optimization framework based the transfer learning of similar historical information. To improve the search efficiency of the population, the proposed framework finds out the history problem from the model library, which matches current new problem, and transfers the knowledge of the historical problem into optimization process of the new problem. First, a maximum mean discrepancy indicator based on multi-distribution estimation is defined to evaluate the matching degree between a new problem and historical models. Secondly, the knowledge of matched historical problem is transferred into the new problem, and a new initialization strategy of the population based on matching degree is given to accelerate the search speed of the algorithm. Next, a preservation strategy based on iterative clustering is presented to save good information generated during the evolutionary process, for updating the model library. Finally, embedding an adaptive bare-bones particle swarm optimization (PSO) into the proposed framework, a bare-bones PSO algorithm based on the transfer learning of similar historical information is presented. Testing on several improved typical functions, experimental results show that the proposed transfer strategy accelerates the search process of the particle swarm, and significantly improve the convergence speed and the search efficiency of the proposed PSO algorithm.
-
Key words:
- Evolutionary optimization /
- transfer learning /
- particle swarm optimization (PSO) /
- model matching
1) 本文责任编委 魏庆来 -
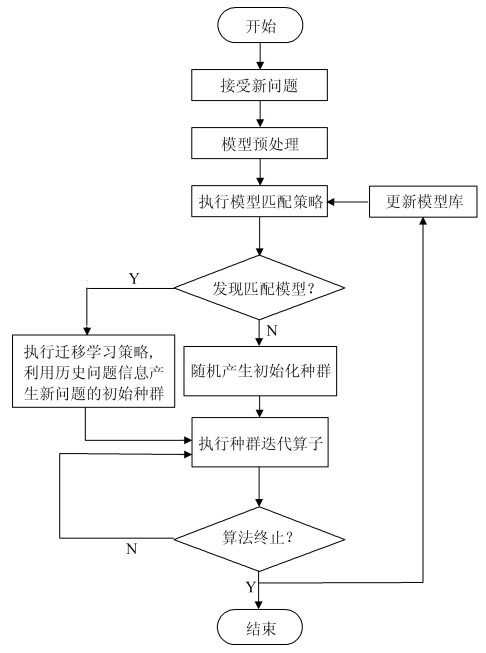
图 1 所提基于迁移学习的进化算法框架
Fig. 1 Evolutionary algorithm framework based on transfer learning
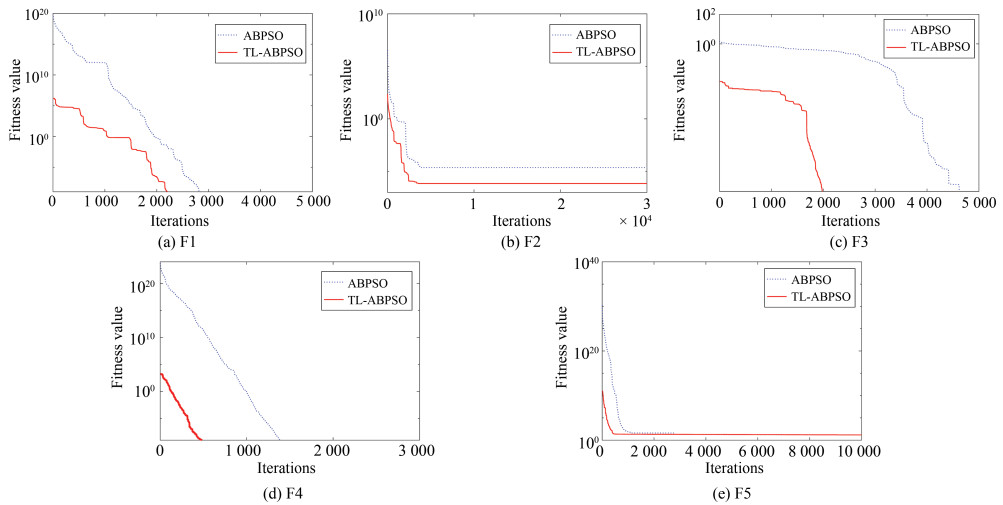
图 2 优化第1组测试函数时ABPSO和TL-ABPSO算法的收敛曲线
Fig. 2 Convergence curves of ABPSO and TL-ABPSO algorithms for the first set of test functions
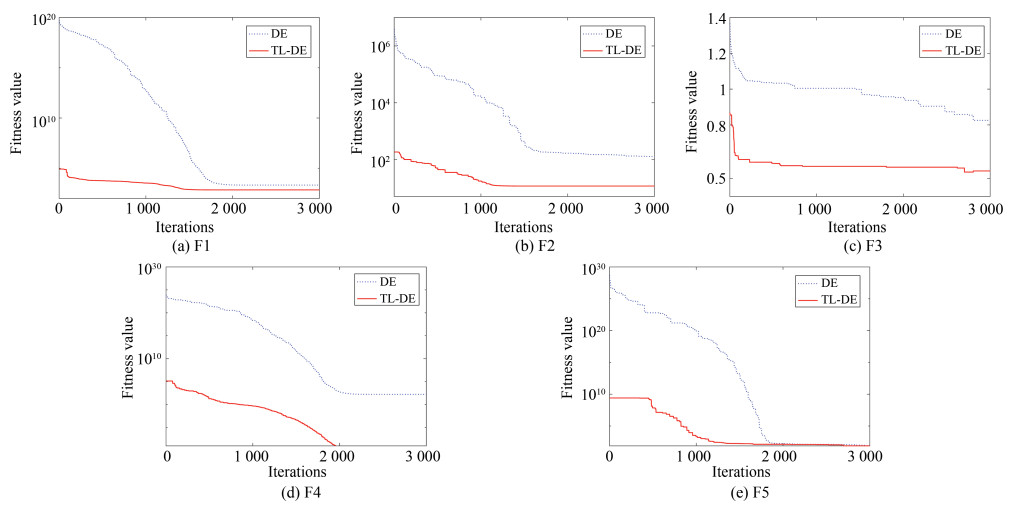
图 3 优化第1组测试函数时DE和TL-DE算法的收敛曲线
Fig. 3 Convergence curves of DE and TL-DE algorithms for the first set of test functions
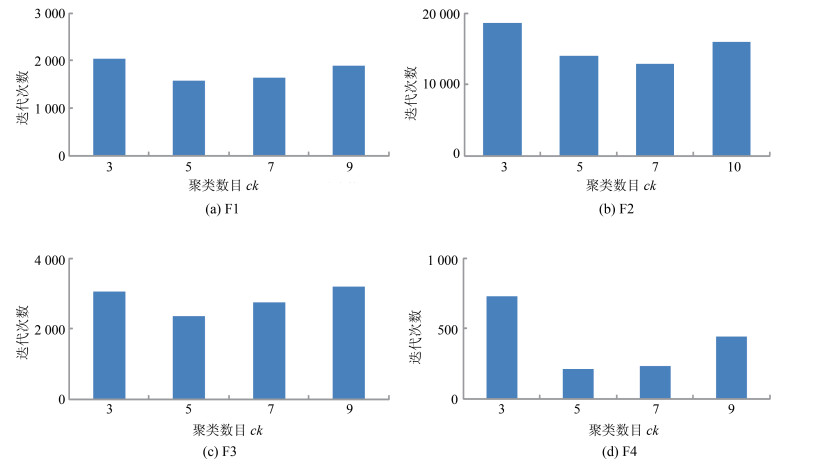
图 4 在不同参数ck取值下, TL-ABPSO找到问题最优解所需平均迭代次数
Fig. 4 The average iteration time required by TL-ABPSO to find the optimal solution under different ck value
表 1 源域中保存的历史优化函数
Table 1 optimization functions saved in the source domain
函数名称 表达式 定义域 最优解 维数 Sphere $f(x) = \sum\limits_{i = 1}^n{x_i^2}$ $[-100, 100]$ 0 30 Rastrigin $f(x) = \sum\limits_{i = 1}^n {(x_i^2 - 10\cos (2\pi{x_i}) + 10)}$ $[-5.12, 5.12]$ 0 30 Ackley ${f(x) = - 20\exp ( - 0.2\sqrt {\frac{{\rm{1}}}{{{\rm{30}}}}\sum\limits_{i = 1}^n {x_i^2} } ){\kern 1pt} - \exp (\frac{1}{{30}}\sum\limits_{i = 1}^n {\cos 2\pi {x_i}} ) + 20 + e{\kern 1pt} }$ $[-32, 32]$ 0 30 Griewank $f(x) = \frac{1}{{4\, 000}}\sum\limits_{i = 1}^n{x_i^2} - \prod\limits_{i = 1}^n {\cos(\frac{{{x_i}}}{{\sqrt i }}) +1}$ $[-600, 600]$ 0 30 Rosenbrock $f(x) = \sum\limits_{i = 1}^n {(100{{({x_{i +1}} - x_i^2)}^2} + {{({x_i} - 1)}^2})}$ $[-30, 30]$ 0 30  下载: 导出CSV
下载: 导出CSV
表 2 目标域中新的优化函数
Table 2 New optimization functions in the target domain
函数名称 表达式 定义域 最优解 维数 F1: 修改后Sphere $f(x) = \sum\limits_{i = 1}^n {x_i^{10}} $ $[-100, 100] $ 0 30 F2:修改后Rastrigin $f(x) = \sum\limits_{i = 1}^n {(x_i^{10} - 10\sin(2\pi {x_i}))} $ $[-5.12, 5.12]$ 0 30 F3: 修改后Ackley $\begin{array}{*{20}{c}} {f(x) = - 20\exp \left( { - 0.2 \times \sqrt[{10}]{{\frac{1}{{30}}\sum\limits_{i = 1}^n {x_i^{10}} }}} \right) - }\\ {\exp \left( {\frac{1}{{30}}\sum\limits_{i = 1}^n {\sin } 2\pi {x_i}} \right) + 20 + 1} \end{array}$ $[-32, 32]$ 0 30 F4: 修改后Griewank $f(x) = \frac{1}{{4\, 000}}\sum\limits_{i = 1}^n {x_i^{10}} - \prod\limits_{i = 1}^n {{{\sin}}(\frac{{{x_i}}}{{\sqrt i }})} $ $[-600, 600] $ 0 30 F5: 修改Rosenbrock $f(x) = \sum\limits_{i = 1}^n {(100{{({x_{i + 1}} - x_i^{10})}^2} + {{({x_i} - 1)}^{10}})} $ $[-30, 30] $ 0 30 F6: Shifted Sphere 文献[32] $[-100, 100]$ $-450$ 30 F7: Shifted rotated Rastrigin 文献[32] $[-5, 5]$ $-330$ 30 F8: Shifted rotated Ackley 文献[32] $[-32, 32]$ $-140$ 30 F9: Shifted rotated Griewank 文献[32] $[-600, 600]$ $-180$ 300 F10: Shifted Rosenbrock 文献[32] $[-100, 100]$ 390 30
下载: 导出CSV
表 3 比较算法优化第1组测试函数所得实验结果
Table 3 Experimental results obtained by comparison algorithm for the first set of test functions
优化函数 比较算法 指标SR (%) 指标Fave 指标Time (s) 指标AC SPSO 100 2.635 ×103 1.539 0 BBPSO-MC 66.67 - 2.960 1.8241×10-5 函数F1 BBJ 63.33 - 7.614 8.6800×10-6 ABPSO 100 3.730×103 3.150 0 TL-ABPSO 100 1.574×103 1.860 0 SPSO 0 - 9.722 5.169×101 BBPSO-MC 26.67 - 12.761 1.824×10-0 {函数F2} BBJ 0 - 20.169 8.680×10-6 ABPSO 72 - 21.083 7.067×10-5 TL-ABPSO 100 1.283×104 20.183 0 SPSO 0 - 12.769 1.494×100 BBPSO-MC 100 2.815×104 13.185 0 函数F3 BBJ 0 - 22.356 1.350 ×10-2 ABPSO 100 3.568×103 17.514 0 TL-ABPSO 100 2.214×103 7.9190 0 SPSO 0 - 8.726 3.312×10-4 BBPSO-MC 100 1.163×103 3.820 0 函数F4 BBJ 0 - 9.947 2.366×10-5 ABPSO 100 8.110×102 4.706 0 TL-ABPSO 100 2.310×102 3.370 0 SPSO 0 - 10.154 2.908×101 BBPSO-MC 0 - 15.651 2.277×101 函数F5 BBJ 0 - 25.425 1.861×101 ABPSO 0 - 31.817 1.281×101 TL-ABPSO 0 - 49.476 1.253×101
下载: 导出CSV
表 4 比较算法优化第2组测试函数所得实验结果
Table 4 Experimental results obtained by comparison algorithm for the second set of test functions
优化函数 比较算法 指标SR (%) 指标Fave 指标Time (s) 指标AC SPSO 100 3.525×103 10.105 0 BBPSO-MC 66.67 - 12.132 0 函数F6 BBJ 0 - 14.835 0 ABPSO 100 1.066×103 7.451 0 TL-ABPSO 100 1.421×102 7.160 0 SPSO 0 - 36.853 4.279×101 BBPSO-MC 33.33 - 62.168 3.800×10-3 函数F7 BBJ 50 - 57.679 1.893×100 ABPSO 72 - 39.707 0 TL-ABPSO 100 7.467×103 22.704 0 SPSO 0 - 33.796 1.329×102 BBPSO-MC 26.67 - 61.905 2.095×101 函数F8 BBJ 0 - 62.813 2.094×101 ABPSO 44.33 - 166.905 8.231×10-2 TL-ABPSO 63.33 - 214.023 1.709×10-4 SPSO 0 - 39.021 5.483×102 BBPSO-MC 0 - 62.722 7.901×10-3 函数F9 BBJ 0 - 54.329 1.040×101 ABPSO 0 - 125.621 5.286×101 TL-ABPSO 0 - 183.422 9.567×10-4 SPSO 0 - 36.927 2.908×101 BBPSO-MC 0 - 61.933 2.674×101 函数F10 BBJ 0 - 51.946 3.597×101 ABPSO 0 - 122.359 1.922×101 TL-ABPSO 0 - 180.816 1.347×101
下载: 导出CSV
-
[1] 李元诚, 李宗圃, 杨立群, 王蓓. 基于改进量子差分进化的含分布式电源的配电网无功优化. 自动化学报, 2017, 43(7): 1280-1288 doi: 10.16383/j.aas.2017.e150304Li Yuan-Cheng, Li Zong-Pu, Yang Li-Qun, Wang Bei. Reactive power optimization of distribution network with distributed power supply based on improved quantum difference evolution. Acta Automatica Sinica, 2017, 43(7): 1280- 1288 doi: 10.16383/j.aas.2017.e150304 [2] 余伟伟, 谢承旺, 闭应洲, 夏学文, 李雄, 任柯燕, 赵怀瑞, 王少峰. 一种基于自适应模糊支配的高维多目标粒子群算. 自动化学报, 2018, 44(12): 2278-2289 doi: 10.16383/j.aas.2018.c170573Yu Wei-Wei, Xie Cheng-Wang, Bi Ying-Zhou, Xia Xue-Wen, Li Xiong, Ren Ke-Yan, Zhao Huai-Rui, Wang Shao-Feng. Many-objective particle swarm optimization based on adaptive fuzzy dominance. Acta Automatica Sinica, 2018, 44(12): 2278-2289 doi: 10.16383/j.aas.2018.c170573 [3] 王东风, 孟丽. 粒子群优化算法的性能分析和参数选择. 自动化学报, 2016, 42(10): 1552-1561 doi: 10.16383/j.aas.2016.c150774Wang Dong-Feng, Meng Li. Performance analysis and parameter selection of PSO algorithms. Acta Automatica Sinica, 2016, 42(10): 1552-1561 doi: 10.16383/j.aas.2016.c150774 [4] Tang L, Wang X. A hybrid multiobjective evolutionary algorithm for multiobjective optimization problems. IEEE Transactions on Evolutionary Computation, 2013, 17(1): 20 -45 doi: 10.1109/TEVC.2012.2185702 [5] 田梦楚, 薄煜明, 陈志敏, 吴盘龙, 赵高鹏. 萤火虫算法智能优化粒子滤波. 自动化学报, 2016, 42(1): 89-97 doi: 10.16383/j.aas.2016.c150221Tian Meng-Chu, Bo Yu-Ming, Chen Zhi-Min, Wu Pan-Long, Zhao Gao-Peng. Firefly algorithm intelligence optimized particle filter. Acta Automatica Sinica, 2016, 42(1): 89-97 doi: 10.16383/j.aas.2016.c150221 [6] 徐茂鑫, 张孝顺, 余涛. 迁移蜂群优化算法及其在无功优化中的应用. 自动化学报, 2017, 43(1): 83-93 doi: 10.16383/j.aas.2017.c150791Xu Mao-Xin, Zhang Xiao-Shun, Yu Tao. Transfer bees optimizer and its application on reactive power optimization. Acta Automatica Sinica, 2017, 43(1): 83-93 doi: 10.16383/j.aas.2017.c150791 [7] Zhang X Y, Tian Y, Cheng R, Jin Y C. An efficient approach to nondominated sorting for evolutionary multiobjective optimization. IEEE Transactions on Evolutionary Computation, 2015, 19(2): 201-213 doi: 10.1109/TEVC.2014.2308305 [8] Patvardhan C, Bansal S, Srivastav A. Quantum-inspired evolutionary algorithm for difficult knapsack problems. Memetic Computing, 2015, 7(2): 135-155 doi: 10.1007/s12293-015-0162-1 [9] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359 doi: 10.1109/TKDE.2009.191 [10] Murre J M J. Transfer of learning in backpropagation and in related neural network models. Connectionist Models of Memory and Language, London: UCL Press, 1995. 73-93 [11] Pratt L Y. Discriminability-based transfer between neural networks. Advances in Neural Information Processing Systems, 1992, 5: 204-211 http://dl.acm.org/citation.cfm?id=668046 [12] Mihalkova L, Huynh T, Mooney R J. Mapping and revising Markov logic networks for transfer learning. In: Proceedings of the 22nd Conference on Artificial Intelligence (AAAI-07). Vancouver, Canada: AAAI, 2007. 608-614 [13] Mihalkova L, Mooney R J. Transfer learning with Markov logic networks. In: Proceedings of the ICML-06 Workshop on Structural Knowledge Transfer for Machine Learning, Pittsburgh, PA, USA: 2006. [14] Gupta R, Ratinov L. Text categorization with knowledge transfer from heterogeneous data sources. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence, Chicago, Illinois, USA: AAAI, 2008. 842-847 [15] Ling X, Xue G R, Dai W Y, Jiang Y, Yang Q, Yu Y. Can Chinese web pages be classified with English data source? In: Proceedings of the 17th International Conference on World Wide Web, Beijing, China: WWW, 2008. 969-978 [16] Dinh T T H, Chu T H, Nguyen Q U, Transfer learning in genetic programming. In: Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan: IEEE, 2015. 1145-1151 [17] Koçer B, Arslan A. Genetic transfer learning. Expert Systems with Applications, 2010, 37(10): 6997-7002 doi: 10.1016/j.eswa.2010.03.019 [18] Feng L, Ong Y S, Tan A H, Tsang Z W. Memes as building blocks: A case study on evolutionary optimization + transfer learning for routing problems. Memetic Computing, 2015, 7(3): 159-180 doi: 10.1007/s12293-015-0166-x [19] Jiang M, Huang Z Q, Qiu L M, Huang W Z, Yen G G. Transfer learning based dynamic multiobjective optimization algorithms. IEEE Transactions on Evolutionary Computation, 2018, 22(4): 501-514 doi: 10.1109/TEVC.2017.2771451 [20] Rosenstein M T, Marx Z, Pack Kaelbling L, Dietterich T G. To transfer or not to transfer. In: Proceedings of the NIPS 2005 Workshop on Transfer Learning, 2005. % Rosenstein M T. To transfer or not to transfer. NIPS-2005 Workshop on Inductive Transfer: 10 Years Later. 2005, S20 [21] Shi Y H, Eberhart R C. A modified particle swarm optimizer. In: Proceedings of the 1998 IEEE International Conference on Evolutionary Computation, Anchorage, AK, USA: IEEE, 1998. 69-73 [22] 韩红桂, 卢薇, 乔俊飞. 一种基于多样性信息和收敛度的多目标粒子群优化算. 电子学报, 2018, 46(2): 315-324 doi: 10.3969/j.issn.0372-2112.2018.02.009Han Hong-Gui, Lu Wei, Qiao Jun-Fei. A multi-objective particle swarm optimization algorithm based on diversity information and convergence, Chinese Journal of Electronics, 2018, 46(2): 315-324 doi: 10.3969/j.issn.0372-2112.2018.02.009 [23] 张倩, 李明, 王雪松, 程玉虎, 朱美强. 一种面向多源领域的实例迁移学习. 自动化学报, 2014, 40(6): 1176-1183 doi: 10.3724/SP.J.1004.2014.01176Zhang Qian, Li Ming, Wang Xue-Song, Cheng Yu-Hu, Zhu Mei-Qiang. An example of migration learning for multi-sources. Acta Automatica Sinica, 2014, 40(6): 1176-1183 doi: 10.3724/SP.J.1004.2014.01176 [24] 王俊, 李石君, 杨莎, 金红, 余伟. 一种新的用于跨领域推荐的迁移学习模型. 计算机学报, 2017, 40(10): 2367-2380 doi: 10.11897/SP.J.1016.2017.02367Wang Jun, Li Shi-Jun, Yang Sha, Jin Hong, Yu Wei. A new migration learning model for cross-domain recommendation. Chinese Journal of Computers, 2017, 40(10): 2367-2380 doi: 10.11897/SP.J.1016.2017.02367 [25] 姜海燕, 刘昊天, 舒欣, 徐彦, 伍艳莲, 郭小清. 基于最大均值差异的多标记迁移学习算法. 信息与控制, 2016, 45(4): 463-478 https://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201604015.htmJiang Hai-Yan, Liu Hao-Tian, Shu Xin, Xu Yan, Wu Yan-Lian, Guo Xiao-Qing. Multi-label migration learning algorithm based on large mean difference. Information and Control, 2016, 45(4): 463-478 https://www.cnki.com.cn/Article/CJFDTOTAL-XXYK201604015.htm [26] Zhang Y, Gong D W, Sun X Y, Geng N. Adaptive bare-bones particle swarm optimization algorithm and its convergence analysis. Soft Computing, 2014, 18(7): 1337-1352 doi: 10.1007/s00500-013-1147-y [27] Clerc M, Kennedy J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Transactions on Evolutionary Computation, 2002, 6(1): 58-73 doi: 10.1109/4235.985692 [28] Omran M G H, Engelbrecht A P, Salman A. Bare bones differential evolution. European Journal of Operational Research, 2009, 196(1): 128-139 doi: 10.1016/j.ejor.2008.02.035 [29] Shi Y H, Eberhart R C. Empirical study of particle swarm optimization. In: Proceedings of the 2002 IEEE Conference on Evolutionary Computation, Washington DC, USA: IEEE, 2002. 320-324 [30] Zhang H, Kennedy D D, Rangaiah G P, Bonilla-Petriciolet A. Novel bare-bones particle swarm optimization and its performance for modeling vapor——liquid equilibrium data. Fluid Phase Equilibria, 2011, 301(1): 33-45 doi: 10.1016/j.fluid.2010.10.025 [31] Blackwell T. A study of collapse in bare bones particle swarm optimization. IEEE Transactions on Evolutionary Computation, 2012, 16(3): 354-372 doi: 10.1109/TEVC.2011.2136347 [32] Suganthan P N, Hansen N, Liang J J, Deb K, Chen Y P, Auger A, Tiwari S. Problem Definitions and Evaluation Criteria for the CEC 2005 Special Session on Real-parameter Optimization. Technical Report for CEC 2005 Special Session, 2005. [Online], available: http://www3.ntu.edu.sg/home/EPNSugan, April 1, 2018 [33] Qin A K, Huang V L, Suganthan P N. Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Transactions on Evolutionary Computation, 2009, 13(2): 398-417 doi: 10.1109/TEVC.2008.927706 -

 下载:
下载:

计量
- 文章访问数: 1794
- HTML全文浏览量: 730
- PDF下载量: 328
- 被引次数: 0
