

-
摘要: 复杂仿真模型一般具有多个不同类型且带有相关性的输出,现有验证方法存在变量信息缺失、变量相关性度量不准确等问题.为此,提出基于变量选择和概率分布差异相结合的多变量仿真结果验证方法,考虑不确定性的影响,对选取到具有相关性的多个变量进行联合验证.首先,引入分形维数和互信息方法对多元异类输出进行相关性分析,提取相关变量子集.而后对相关变量子集中的各变量提取数据特征,进而计算各相关变量子集关于数据特征的联合概率分布,采用概率分布差异法度量仿真输出和参考输出联合概率分布的差异,并将其转化为一致性程度;在此基础上综合多个验证结果得到模型可信度.通过实例应用及对比实验,验证了方法的有效性.Abstract: Complex simulation models often generate the multivariate and different types of output, some problems such as the lacking variables information and the inaccuracy correlation measurement are involved in the existing validation methods. A novel validation method combining variables selection with area metric is proposed, the multiple outputs with correlation are selected for the associated validation under uncertainty. The fractal dimension and mutual information methods are primarily applied to analyze the correlation among multivariate and divise responses and extract the correlated variable subsets. Next, the interesting data characteristics of all variables are extracted in subset and the corresponding joint cumulative distribution function (JCDF) of each subset related to any characteristic is calculated. The area metric is used to measure the difference between the simulation and reference output JCDFs of multivariate characteristics in each subset, and the differences are transformed into the consistency degrees. Then the multiple validation results are integrated to obtain the model credibility. Finally, the method is validated through the application case and comparison experiments.
-
无人艇作为一种常见的自主无人系统, 在海上巡逻[1]、水质监测[2]、海上救援[3]和海上资源探测[4]等任务中发挥着重要作用. 由于单无人艇在续航、载荷和任务多样性方面存在限制, 难以满足日益复杂的海上作业需求, 因此多无人艇(Multiple unmanned surface vehicles, Multi-USVs)协同作业受到了广泛关注. 其中, 多无人艇协同导航是实现多艇协同作业的关键, 近年来被广泛研究[5-11]. 现有的无人艇控制方法通常需要建立精确的动力学和运动学模型. 在开放未知海域, 洋流、风速和暗礁等因素也使得多无人艇系统对自主协同导航提出更高的要求. 因此, 如何通过无人艇之间的相互协作, 以最快速度和最低成本成功导航至多个目标点是当前极富挑战性的难题.
近年来, 多智能体强化学习(Multi-agent reinforcement learning, MARL)在解决复杂的多智能体决策问题上展现了巨大的潜力[12-16], 受到研究者们的广泛关注. 许多经典的MARL算法被提出, 如值分解网络[17] (Value decomposition networks, VDN)、单调值函数分解[18] (Monotonic value function factorisation, QMIX)、多智能体确定性策略梯度[19] (Multi-agent deep deterministic policy gradient, MADDPG)、多智能体近端策略优化[20] (Multi-agent proximal policy optimization, MAPPO)、反事实多智能体策略梯度[21] (Counterfactual multi-agent policy gradients, COMA)等. 在此基础上, 研究者们对多无人艇系统进行了深入研究[22]. Wang等[23]基于MADDPG算法, 针对多无人艇系统的协同目标入侵问题, 提出一种可扩展的MARL算法, 实现了多无人艇系统规模的自适应调节. Xia等[24]针对无人艇舰队的协同多目标狩猎问题, 提出一种基于MADDPG的部分可观测多目标搜索近端策略优化算法. Zhao等[25]利用确定性策略梯度(Deep deterministic policy gradient, DDPG)算法, 提出一种随机制动的MARL方法, 实现了欠驱动多无人艇编队的路径跟踪. 同样地, 基于MADDPG策略, 文献[26]针对多无人艇目标跟踪问题, 通过V型概率数据提取和Safe DDPG动作约束方法, 有效地实现了多无人艇的目标跟踪任务. 针对多无人艇协调追逐问题, Gan等[27]提出基于MA-POCA的MARL方法, 构建了障碍辅助追逐框架, 显著提高了多无人艇系统的协同追逐效率. 类似地, 针对多无人艇追逃游戏, 文献[13]提出一种分布式捕捉策略优化方法, 通过双向门控循环单元特征网络提取观测序列以及虚拟障碍和课程学习, 提升策略的泛化能力与收敛速度, 从而实现了多无人艇的捕捉. 这些基于数据驱动的MARL算法是通过智能体与环境交互收集大量的经验数据, 从而有可能从这些经验数据中学习出接近最优的协同策略. 高质量的经验数据通常能使模型的训练过程事半功倍, 而这些数据的获取依赖智能体在当前策略的基础上对环境进行进一步探索. 然而, 过度的探索又会使系统无法充分利用已有的策略来获取最大化的奖励, 从而导致性能下降. 因此, 如何平衡智能体对环境的探索与对当前策略的利用是提升学习效率的关键.
在强化学习算法中, 注入噪声是一种常见的提升探索的手段[28-31]. 例如, 文献[28-29]通过在动作输出增加噪声来模拟输出扰动, 使智能体以一定概率访问环境中的其他状态. 文献[30]在策略的模型参数上(如神经网络权重)增加噪声, 使得策略避免陷入局部最优, 从而提高其探索能力. 而文献[31]则是在优势函数输出端增加噪声来对策略的优化目标进行扰动, 从而间接提升策略在接下来与环境交互过程中的探索能力. 这些方法通过添加噪声影响策略的优化过程或其动作输出, 从而帮助智能体发现未知的高奖励区域. 尽管现有的方法在提升智能体探索能力上卓有成效, 但是无法从根源上解决探索与利用之间存在的矛盾. 此外, 在多智能体系统中, 由于智能体之间相互作用, 若仅在个体上增加噪声, 可能会破坏多体之间的协作关系. 因此, 本文在集中训练和分散执行(Centralized training and decentralized execution, CTDE)框架基础上, 从提升优势函数的泛化性能出发, 考虑从优势函数的输入端增加噪声来模拟扰动, 提出一种基于优势函数输入扰动的多智能体近端策略优化(Noise-advantage multi-agent proximal policy optimization, NA-MAPPO)方法. 这种方法通过将学习出的泛化能力更高的优势函数作为各智能体策略的优化目标, 在提升智能体各自策略探索能力的同时, 保证联合策略对多智能体之间协作关系的利用, 从而提升多智能体系统对整个环境的探索效率. 通过在模拟多无人艇协同导航任务中的实验验证, 本文所提方法与基准算法相比, 有效提升了多无人艇协同导航任务的成功率, 缩短了策略的训练时间以及任务的完成时间. 另外, 本文方法不仅能够实现多无人艇的多分配导航任务, 而且能够进一步推广至多无人机、多机器人等多智能体系统中, 协助各类智能体实现协同控制任务, 并提高方法性能.
1. 背景介绍
1.1 部分观测马尔科夫决策过程
本文将多无人艇协同导航任务建模为一个部分观测马尔科夫决策过程(Partially observable Markov decision process, POMDP). 具体地, 定义元组$ \langle {N,\;S,\;A,\;O,\;R,\;P,\;\gamma } \rangle $表示一个POMDP, 其中$ N $表示无人艇的数量; $ S $表示多无人艇的联合状态空间; $ A = \left\{ {{a_1},\;\cdots,\;{a_N}} \right\} $表示多无人艇系统的联合动作空间, $ {a_i} $表示第$ \;i $个无人艇的动作空间; $ O = \left\{ {{o_1},\;\cdots,\; {o_N}} \right\} $表示多无人艇系统的联合观测空间, $ {o_i} $表示第$ \,i $个无人艇的局部观测; $ R $表示奖励函数; $ P(s'|s,\;A) $是状态转移函数, 即当多无人艇系统在当前状态$ s $下采取联合动作$ A $时, 有概率$ P $进入下一个状态$ s' $; $ \gamma \in (0,\;1) $是折扣因子. 在每个时间步$ t $, 第$ i $个无人艇接收到一个部分观测$ o^i_t $, 根据策略$ {\pi ^i}(o_t^i;\;{\theta ^i}) $执行行动$ a^i_t $. 第$ i $个无人艇的目标是学习一个策略$ {\pi ^i}(o_t^i;\;{\theta ^i}) $来最大化$ {{{\mathrm{E}}}}(G_i) $, 其中$o_t^i $是第$i $个无人艇在时刻$t $的部分观测, $ {\theta ^i} $是第$ i $个无人艇策略网络的参数, $ {G_i} $是折扣累积回报, 定义为$ G_i = \sum\nolimits_{\substack{t = 0}}^{H} {\gamma^t r_t^i} $, $ H $是时间步数, $r_t^i $是第$i $个无人艇在时刻$t $获得的奖励.
1.2 多无人艇协同导航
1.2.1 问题描述
本文考虑的任务场景如图1所示, 图中$ N $个无人艇(表示为$ {U_1},\;\cdots,\;{U_N} $)随机分布在包含障碍物和$ M $个动态或静态任务(表示为$ {T_1},\;\cdots,\;{T_M} $)的区域中. 无人艇任务点的初始位置随机设置. 本文的研究目标是设计有效的协同导航策略使得多无人艇在无碰撞的前提下, 通过协同实现以最短路径到达多个任务点. 本文研究的是无人艇数量等于任务数量的情况, 即$ N=M $的情况.
1.2.2 运动学模型
无人艇的运动学模型通常使用两个坐标系来共同描述: 体固定坐标系和惯性坐标系. 通过这两种坐标系可以有效地描述无人艇的运动和姿态. 如图2所示, 体固定坐标系(表示为$ \left\{ b\right\} $)附着在无人艇体上, $ {O_b} $表示原点, 位于无人艇的质心, $ {x_b} $轴和$ {y_b} $轴分别指向无人艇的前进方向和与前进方向垂直的无人艇的右方. 惯性坐标系(表示为$ \left\{ e\right\} $)是相对地球的坐标系, $ {O_e} $表示原点, $ {x_e} $, $ {y_e} $分别指向北、东. 无人艇的模型表示如下
 图 2 无人艇的惯性坐标系和体固定坐标系Fig. 2 The body-fixed coordinate system and inertial coordinate system of USV
图 2 无人艇的惯性坐标系和体固定坐标系Fig. 2 The body-fixed coordinate system and inertial coordinate system of USV$$ \begin{aligned} \left\{ {\begin{aligned} &{\dot \eta = \mathcal{R}(\eta )v}\\ &{\mathcal{M}\dot v + \mathcal{C}(v)v + \mathcal{D}(v)v = f} \end{aligned}} \right. \end{aligned} $$ (1) 其中, $ \eta = [x,\; y,\; \varphi]^{\rm{T}} $表示无人艇的姿态矢量, $ (x,\;y) $为无人艇在惯性坐标系下的坐标, $ \varphi \in [- \pi,\;\pi] $表示无人艇的航向角; $ v = [{v_u},\;{v_v},\;{v_r}]^{\rm{T}} $代表无人艇的速度矢量, $ {v_u} $和$ {v_v} $分别表示沿$ {x_b} $轴和$ {y_b} $轴方向的激荡速度和摇摆速度, $ {v_r} $表示角速度; $ \mathcal{M} \in \bf{R}^{{3\times 3}} $表示惯性矩阵(Inertia matrix), 包含刚体质量和附加质量; $ {\mathcal{C}(v)} $为科里奥利和向心矩阵(Coriolis and centripetal matrix); $ {\mathcal{D}(v)} $表示阻尼矩阵(Damping matrix), 用于描述水的摩擦力; $ \mathcal{R}(\eta) $是一个旋转矩阵, 表示将无人艇的速度矢量从体固定坐标系旋转到惯性坐标系的变换矩阵, 具体定义如下
$$ \begin{aligned} \begin{array}{l} \mathcal{R}(\eta ) = \left[ {\begin{array}{*{20}{c}} {\cos (\varphi )}&{ - \sin (\varphi )}&0\\ {\sin (\varphi )}&{\cos (\varphi )}&0\\ 0&0&1 \end{array}} \right] \end{array} \end{aligned} $$ (2) $ {f} $是控制力和力矩, 具体表述如下
$$ \begin{aligned} f = \left[ \begin{array}{*{20}{c}} \tau_x\\ \tau_y\\ \tau_n \end{array} \right] = \left[ \begin{array}{*{20}{c}} T_{port}+ T_{stdb}\\ 0\\ \dfrac{{(T_{{port}} - T_{stdb})\times l_b}}{2} \end{array} \right] \end{aligned} $$ (3) 其中, $ \tau_x $和$ \,\tau_y $分别表示沿着无人艇运动方向的力以及与运动方向垂直的力, $ \tau_n $表示控制无人艇运动的力矩; $ T_{{port}} $, $ T_{stdb} $分别表示作用在无人艇尾部的左舷推进器以及右舷推进器上的推力; $ l_b $是无人艇横梁的长度.
2. 算法
为了解决局部最优以及样本利用率低等问题, 本文提出一种新的MARL算法, 称为NA-MAPPO, 以更好的性能完成多无人艇协同导航任务. NA-MAPPO通过在优势函数的输入端增加噪声来模拟输入扰动, 从而提升优势函数的泛化能力, 进而更好地指导策略的优化方向、提升策略的协同探索能力. 本文采用经验共享机制, 即所有的无人艇共享一个经验池, 同时所有无人艇的Actor网络参数和Critic网络参数都是共享的. 通过这种经验共享机制, 可以有效地提高样本的使用效率.
2.1 状态空间
多无人艇协同导航策略学习主要通过与环境的交互进行, 因此适当的环境建模是多无人艇之间进行有效决策的基础. 本文中, 第$ i $艘无人艇的局部观测状态空间$ {o_i} $包括位置信息$ (x_i,\;y_i) $, 航向角$ \varphi_i $, 激荡速度$ v_{u_i} $, 摇摆速度$ \,v_{v_i} $以及角速度$\, v_{r_i} $信息. 利用这些信息能够准确描述第$ i $艘无人艇的位置信息和运动状态. 为降低状态空间的维数, 提高学习效率, 利用无人艇与其他无人艇的相对位置$ ({r_{{u_{xi}}}},\;{r_{{u_{yi}}}}) $以及无人艇与所有任务间的相对位置$ ({r_{{t_{xi}}}},\;{r_{{t_{yi}}}}) $来表示无人艇系统状态空间内的目标信息, 具体定义如下
$$ \begin{aligned} {o_i} = \left\{{x_i},\;{y_i},\;\varphi_i ,\;{v_{{u_i}}},\;{v_{{v_i}}},\;{v_{{r_i}}},\;{r_{{u_{xi}}}},\;{r_{{u_{yi}}}},\;{r_{{t_{xi}}}},\;{r_{{t_{yi}}}}\right\} \end{aligned} $$ (4) 进一步得出, 多无人艇系统联合状态空间$ S $的表达式为
$$ \begin{aligned} S = \left\{ {{o_1},\;{o_2},\;\cdots,\;{o_i},\;\cdots,\;{o_N}} \right\} \end{aligned} $$ (5) 2.2 动作空间
由于无人艇的运动是由作用在艇尾部的差动推力控制的, 因此本文将动作定义为差动推力. 第$ i $个无人艇的动作$ a_i $以及联合动作空间$ A $定义如下
$$ \begin{aligned} a_{i}=\left\{{T_{iport}},\;{T_{istdb}}\right\} \end{aligned} $$ (6) $$ \begin{aligned} A = \left\{ {{a_1},\;{a_2},\;\cdots,\;{a_i},\;\cdots,\;{a_N}} \right\} \end{aligned} $$ (7) 其中, $ T_{iport} $, $ T_{istdb} $分别表示作用在第$ i $个无人艇尾部的左舷推进器以及右舷推进器上的推力.
2.3 奖励函数
强化学习算法的成功很大程度依赖于奖励函数的设置, 奖励函数在无人艇的策略评估以及策略改进上起着重要的作用. 本文通过两个方面对奖励函数进行具体设计, 首先对整个多无人艇系统设计一个包含差分信息的奖励函数$ r_{t}^{diff} $用于奖励无人艇更加接近任务点的行为. 具体地, 针对第$ j $个任务点, 计算与其最近的无人艇在两个相邻时刻$ t-1 $和$ t $时之间的距离差, 即$ d_j^{t - 1} - d_j^t $, 进而得出整个多无人艇系统的差分奖励函数为$ r_{t}^{diff} = \sum\nolimits_{j = 1}^M (d_j^{t - 1} - d_j^t) $. 可以看出, 当相邻时刻无人艇距离任务点更接近时, $ d_j^{t - 1} - d_j^t>0 $, 奖励为正值, 说明此时环境返回了更大的奖励; 反之, 环境返回了一个负的奖励值. 在本文中, 将每个智能体的奖励函数设置为整个多无人艇系统的全局奖励函数, 以促进无人艇之间的协作, 即$ r_{t,\;i}^{diff}=r_{t}^{diff},\; i=1,\;\cdots,\; N $.
与此同时, 本文还定义了惩罚函数$ r_{t,\;i}^{collide1} $, $ r_{t,\;i}^{collide2} $, 用来惩罚无人艇之间发生碰撞或者无人艇与障碍物发生碰撞的情况, 以期有效避免碰撞的发生. 这样, 就得到了第$ i $个无人艇在时刻$ t $的奖励函数$ r_{t}^i $, 具体定义如下
$$ \begin{aligned} r_{t}^i = r_{t,\;i}^{diff} + r_{t,\;i}^{collide1} + r_{t,\;i}^{collide2} \end{aligned} $$ (8) $$ \begin{aligned} \left\{ \begin{aligned} & r_{t,\;i}^{diff} = \sum\limits_{j = 1}^M {(d_j^{t - 1} - d_j^t)} \\ &d_j^t = \min \left\{ {dis({T_j},\;U_1^t),\; \cdots ,\; dis({T_j},\;U_N^t)} \right\} \\ &d_j^{t - 1} = \min \left\{ {dis({T_j},\;U_1^{t - 1}),\; \cdots,\; dis({T_j},\;U_N^{t - 1})} \right\} \end{aligned} \right. \end{aligned} $$ (9) 其中, $ U_i^t $表示$ t $时刻第$ i $个无人艇; $ T_j $表示第$ j $个任务; $ r_{t,\;i}^{collide1} = \left\{ {0,\; - 1} \right\} $, 具体地, 当无人艇i在时刻$ \,t $与其余无人艇发生碰撞时, $ r_{t,\;i}^{collide1} = - 1 $, 否则$ r_{t,\;i}^{collide1} =0 $; $ r_{t,\;i}^{collide2} = \left\{ {0,\; - 1} \right\} $, 当无人艇$ i $在时刻$ t $与障碍物发生碰撞时, $ r_{t,\;i}^{collide2} = - 1 $, 否则$ r_{t,\;i}^{collide2} = 0 $; $ dis({T_j},\;U_i^t) $表示时刻$ \,t $无人艇$ \,i $与任务$ j $之间的欧氏距离. 本文采用集中式训练的方式, 集中式训练通过优化基于全局信息的$ Q $函数, 既能最大化每个智能体自身的奖励, 又能引导智能体学习有效的协作策略, 从而实现团队奖励的目标. 奖励函数的示意图如图3所示, 图3绘制了三个无人艇在相邻时刻$ t $, $ t-1 $, $ t+1 $的运动轨迹, 其中黑色的方块表示障碍物.
注 1. 本文主要考虑任务点个数与无人艇个数相等的情况. 对于无人艇个数小于任务点个数的情况, 即$ N<M $时, 本文方法依然能够确保多无人艇系统以最优策略实现多任务导航, 但是剩余$ M-N $个任务点将处于任务未完成的状态. 而对于$ N>M $的情况, 本文方法将无法直接适用. 因为本文的奖励机制只考虑了距离任务点较近的$ M $个无人艇, 对于$ N-M $个偏离任务点的无人艇将无法在奖励机制的引导下达到确定的状态, 导致多无人艇系统存在不稳定因素. 在未来的工作中, 我们将针对该情况设计可行的奖励机制, 确保多无人艇系统在$ N>M $的情况下, 仍然能够实现高效、稳定的协同控制.
2.4 NA-MAPPO
本文所提NA-MAPPO方法主要考虑在第$ i $个无人艇优势函数的输入端增加采样噪声向量$ {{x^i}}, i=1,\;\cdots,\; N $, 其满足如下高斯分布
$$ \begin{aligned} x^i\sim {\rm{N}}(0,\; 1) \end{aligned} $$ (10) $$ \begin{aligned} {\tilde A^{\theta ,\;i}} = r_t^i + \gamma V_{\phi} \left( s_{t+1},\;x^i \right) - V_{\phi} {\left( s_t ,\;x^i \right)} \end{aligned} $$ (11) 其中, $ V_{\phi} \left(s_{t},\;x^i \right) $和$ V_{\phi} {\left(s_{t+1},\;x^i\right)} $分别表示扰动后状态$ s_t $以及状态$ s_{t+1} $的价值; $ {\tilde A^{\theta,\;i}} $表示第$ i $个无人艇输入端注入噪声后的优势函数. 在实验中默认使用单位矩阵作为协方差矩阵, 在每个输入维度上, 噪声都是从均值为$ 0 $、方差为1的高斯分布中采样得到的. 通过在优势函数的输入端引入高斯噪声来模拟输入扰动. 这种噪声添加方式一方面提供了适度的扰动幅度, 促进了探索; 另一方面保持了策略的稳定性, 从而可以很好地提升优势函数的泛化能力.
本文采用Actor-Critic方法, 通过在线方式更新多无人艇系统的随机导航策略. Actor是一个参数为$ \theta $的神经网络, 用于拟合多无人艇系统的导航策略$ {\tilde\pi _\theta } \left({{a_t^i}\left| {{o_t^i}} \right.} \right) $, 即将无人艇的局部观测$ {o_t^i} $映射到连续动作空间. Critic是一个参数为$ \phi $的神经网络, 用于拟合无人艇系统的值函数$ {V_\phi } \left({{s_t}} \right) $, 完成对无人艇系统导航策略的评估. 为了稳定导航策略的训练, NA-MAPPO采用CTDE框架, 即智能体在与环境交互时利用局部信息进行决策, 在训练时使用全局信息进行训练. 算法具体框架如图4所示.
 图 4 NA-MAPPO示意图, 灰色部分为分散执行部分, 蓝色部分为集中训练部分Fig. 4 Diagram of NA-MAPPO, the gray section represents the decentralized execution part, while the blue section represents the centralized training part
图 4 NA-MAPPO示意图, 灰色部分为分散执行部分, 蓝色部分为集中训练部分Fig. 4 Diagram of NA-MAPPO, the gray section represents the decentralized execution part, while the blue section represents the centralized training part在集中训练阶段, Critic学习一个集中的值函数, 该函数基于所有智能体状态$ S = \left\{ {{o_1},\;{o_2},\;\cdots,\;{o_N}} \right\} $计算集中值函数$ {V_\phi } \left(s \right) $, 从全局的角度对智能体的策略进行评估, 从而更好地指导智能体行动. 然后, Critic网络通过最小化损失$ L \left(\phi \right) $来更新集中值函数. 以第$ i $个无人艇为例, $ L \left(\phi \right) $的定义为
$$ \begin{aligned} L \left( \phi \right) = {\rm {E}} \left({{{\left( {V_\phi \left( {{o_t^1},\;{o_t^2},\;\cdots,\;{o_t^N}\left| \phi \right.} \right) - {y^{MAPPO}}} \right)}^2}}\right) \end{aligned} $$ (12) 其中, $ y^{MAPPO} = r^i_t + \gamma V_{\phi'}(o_{t+1}^1,\, o_{t+1}^2,\, \cdots,\, o_{t+1}^N | \phi' ) $, $ \phi $是Critic网络的参数, $ \phi ' $是目标Critic网络的参数. 利用式(13)可对Actor网络的参数$ \theta $进行更新, 促使无人艇学习到一个累积收益最高的导航策略, 具体地
$$ \begin{aligned} \theta = \arg \max_\theta J_{clip}^{\theta,\; i} \left( \theta \right) \end{aligned} $$ (13) $$ \begin{split} J_{{clip}}^{\theta,\; i}(\theta) = \;&{\rm{E}}_t (\min ( \rho_t^i(\theta) \tilde{A}^{\theta,\; i},\; \\ & {clip}(\rho_t^i(\theta),\; 1 - \varepsilon,\; 1 + \varepsilon) \tilde{A}^{\theta,\; i} )) \end{split} $$ (14) $$ \begin{aligned} \rho_t^i \left( \theta \right) = \frac{\tilde{\pi}_\theta \left( a_t^i \mid o_t^i \right)}{\tilde{\pi}_{\theta_{{old}}} \left( a_t^i \mid o_t^i \right)} \end{aligned} $$ (15) $$ \begin{split} &clip(\rho_t^i(\theta),\; 1 - \varepsilon,\; 1 + \varepsilon) = \\& \quad\left\{ \begin{aligned} &1 + \varepsilon,\; && \rho_t^i(\theta) \geq 1 + \varepsilon \\ &\rho_t^i(\theta),\; & &1 - \varepsilon < \rho_t^i(\theta) < 1 + \varepsilon \\ &1 - \varepsilon,\; && \rho_t^i(\theta) \leq 1 - \varepsilon \end{aligned} \right. \end{split} $$ (16) 其中, $ {\tilde\pi _\theta } $表示受到扰动的当前策略, $ {\tilde\pi}_{\theta_{old}} $表示受到扰动的旧策略, 本文取$ \varepsilon=0.2 $.
在分散执行阶段, 无人艇基于局部信息进行决策. 首先, 将第$ i $个无人艇在时刻$ t $的局部观测$ o^i_t $输入到策略网络, 策略网络会产生在当前观测$ o^i_t $的动作分布的均值$ \mu({{o^i_t}}) $和方差$ \sigma(o^i_t) $. 然后, 将噪声信号$ {\varepsilon^i_t} $与方差$ \sigma(o^i_t) $相乘, 并对方差进行缩放, 基于分布$ {\rm{N}} \left(\mu(o^i_t),\; \sigma \left(o^i_t \right) \varepsilon^i_t \right) $采样得到动作, 即
$$ \begin{aligned} {a_{i,\;t}} = \mu({{o^i_t}}) + \sigma({{o^i_t}}) {\varepsilon^i_t} \end{aligned} $$ (17) 为进一步提升多无人艇在环境中的探索能力, 本文同时考虑在动作输出端增加不同类别的噪声, 包括高斯噪声和具有时序特征的OU (Ornstein-Uhlenbeck)噪声[32]. 为了区分不同动作输出端噪声对策略探索的影响, 本文将动作输出带有高斯噪声的方法称作NA-WN-MAPPO, 而将动作输出带有OU噪声的方法称作NA-OU-MAPPO. 第3节对这些方法进行详细的比较和分析.
2.5 经验共享策略
在多无人艇协同执行任务的场景中, 状态、动作空间庞大, 而无人艇系统能够探索的空间是有限的, 并且样本利用率低. 此外, 多无人艇系统的导航策略不仅仅取决于自身的策略, 还会受到其余无人艇动作的影响, 因此本文设计了经验共享机制. 如图5所示, 经验共享机制分为两个方面, 一方面是经验池数据的共享, 即将所有无人艇收集到的信息集中放到一个经验池中进行存储, 基于共享的经验池采集经验数据进行训练, 从而提高样本的利用率; 另一方面是网络参数的共享, 本实验涉及的无人艇均是同质的无人艇, 即所有无人艇的Actor网络以及Critic网络的参数是共享的, 从而可以提高模型的训练速度. 在算法1中, 本文提供了NA-MAPPO的伪代码.
算法1. NA-MAPPO
1) 初始化策略网络$ \pi_{\theta} $的参数为$ \theta $和值网络$ V_{\phi} $的参数为$ \phi $, 并令$ \pi_{\theta'} = \pi_{\theta} $, 经验池$ D $, 批量$ b_{num} $, 训练回合数$ E $, 训练步数$ T_{step} $, 迭代更新数$ T $, 软更新因子为$ \tau $;
2) 采样高斯噪声$ {x^i} \sim {\rm{N}} \left({0,\;1} \right),\; i=1,\;\cdots,\;{{N}} $;
3) for $ i=1 $ to $ E $ do
4) 初始状态$ s_0=\left\{o_0^1,\;o_0^2,\;o_0^3,\;\cdots,\;o_0^N\right\} $
5) for $ s=1 $ to $ T_{step} $ do
6) $ a_t = \left\{\pi_\theta^i(o_t^i),\;i=1,\;\cdots,\;N \right\} $;
7) 执行动作$ a_t $, 得到奖励$ r_t $, 进入$ s_{t+1} $;
8) 将$\{ {s_t,\; a_t,\; r_t,\; s_{t+1}} \}$存入经验池$ D $;
9) $ s_t = s_{t+1} $;
10) end for
11) 从经验池$ D $中采集批量数据$ b_{num} $;
12) 计算扰动优势函数$ {\tilde A^{\theta,\;i}} $;
13) for $ T=1 $ to $ 50 $ do
14) 通过最小化$ L(\phi) $更新值网络的参数;
15) 通过最大化$ J_{clip}^{\theta,\;i} \left(\theta \right) $更新策略网络的参数;
16) end for
17) 清空经验池$ D $;
18) 更新目标值网络的参数
$ {\phi '} \gets \tau {\phi} + (1 - \tau){\phi'} $
19) end for
3. 仿真实验和分析
3.1 环境设定
本文基于gym环境构建了多无人艇协同导航环境仿真平台. 场景的大小设置为500 m × 500 m, 包括多无人艇、动态和静态障碍、动态和静态任务. 为了训练出泛化性更强、更适应真实海洋环境的策略, 在搭建仿真环境时考虑了洋流、暗礁、风速等因素对多无人艇系统协同控制的影响. 在仿真环境中, 通过随机扰动来模拟海上洋流和风速, 帮助多智能体学习稳定的策略, 使得无人艇以及任务点在受到洋流和风速干扰的情况下, 依然能够以最优策略到达动态变化的任务点, 完成多无人艇协同导航任务. 对于暗礁, 在实验中引入了不同形状、不同尺寸的障碍物, 来模拟现实世界中的暗礁, 从而评估无人艇在遇到各种障碍物时的避障能力和导航能力. 在此基础上, 本文创建了复杂多样的训练场景, 使多无人艇系统能够更全面地探索观测空间, 获得高质量的训练数据, 提高训练策略的鲁棒性和泛化性. 实验场景如图6所示. 图6中包含四个实验场景, 其中场景1包含三艘无人艇以及三个静态任务, 场景2包含四艘无人艇以及多个静态障碍物和四个静态任务, 场景3包含五艘无人艇以及五个动态任务和多个静态障碍, 场景4包含六艘无人艇以及六个动态任务和多个动态障碍. 各场景中, 红色圆点表示静态任务, 红色圆点加箭头表示动态任务, 其中箭头的方向表示任务移动的方向; 黑色矩形以及黑色圆点分别表示静态障碍物以及动态障碍物, 其中, 黑色圆点上的箭头表示障碍物移动的方向.
3.2 实验结果
为了验证本文方法的有效性, 对比不同实验场景下的学习曲线、学习稳定时的累积回合奖励以及导航时间和导航成功率, 从多个角度验证所提方法的有效性.
不同实验场景下学习曲线: 本文比较以下配置的性能: 1) MAPPO; 2)向动作输出端注入白噪声(WN-MAPPO); 3)向动作输出端注入OU噪声(OU-MAPPO); 4)在优势函数输入端增加噪声(NA-MAPPO); 5)在优势函数输入端增加噪声的同时在动作空间注入白噪声(NA-WN-MAPPO); 6)在优势函数输入端增加噪声的同时在动作空间注入OU噪声(NA-OU-MAPPO). 本文使用累积回合奖励作为性能指标来衡量方法的性能. 如图7所示, NA-MAPPO方法相比基准MAPPO方法显著提升了性能, 表明通过对优势函数输入端注入扰动, 能够有效增加策略在环境交互过程中的探索能力, 进而促进智能体探索高奖励区域. 同时, 仅在动作输出端注入噪声的方法OU-MAPPO和WN-MAPPO相比MAPPO也提升了性能, 其中OU噪声效果优于白噪声. 这说明在多无人艇协同导航任务中, 在动作输出端增加OU噪声比增加白噪声效果更好, 这是因为相较于没有时间关联性的高斯噪声而言, OU噪声具有时序特征, 与以往的历史状态关联, 因此能够促进智能体进行大尺度的全局探索. 从实验结果可以看出, 优势函数输入端和动作空间的噪声注入结合(NA-WN-MAPPO、NA-OU-MAPPO)表现出更优异的性能, 尤其是NA-OU-MAPPO取得了最好的结果. 这表明在优势函数输入端增加噪声的同时在动作空间注入时间相关的OU噪声, 能更有效地探索策略空间, 避免策略陷入局部最优.
不同实验场景下导航成功率和导航时间: 为进一步验证本文方法的有效性, 对基于MAPPO、WN-MAPPO、OU-MAPPO、NA-MAPPO、NA-WN-MAPPO、NA-OU-MAPPO算法训练好的模型在图6中的四个实验场景下进行进一步的测试, 比较平均任务成功率(多无人艇系统完成多任务次数与执行多任务总次数的比值)以及平均导航时间(从第一个无人艇开始行动到最后一个无人艇到达其导航地点的时间). 此外, 本文规定, 如果多无人艇不能在100步之内到达所要导航的任务点, 则认为导航失败, 此时的导航时间设定为50 s. 实验结果如图8、图9所示. 导航成功率、导航时间、累积回合奖励对比如表1所示. 从实验结果可以看出, MAPPO、WN-MAPPO、OU-MAPPO以及NA-MAPPO在简单场景(场景1和场景2)中成功率略有不同, 但在涉及动态障碍和动态任务的复杂环境中(场景3和场景4), NA-MAPPO的成功率明显高于其他算法. 随着场景变得更加复杂和无人艇数量的增加, NA-MAPPO的平均导航时间明显低于其他算法. 在复杂环境中, 尤其是复杂的动态环境, NA-WN-MAPPO、NA-OU-MAPPO算法表现出显著的优势. 详细的训练参数如表2所示.
表 1 导航成功率、导航时间、累计回合奖励对比Table 1 Comparison of navigation success rate, navigation time, and cumulative episode reward导航成功率(%) MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 45 75 90 95 98 98 场景2 72 70 88 90 93 95 场景3 40 70 84 88 90 93 场景4 35 60 80 86 90 92 导航时间(s) MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 34 30 25 22 20 20 场景2 33 33 32 32 28 22 场景3 42 36 34 32 30 25 场景4 45 38 36 34 34 26 累积回合奖励 MAPPO WN-MAPPO OU-MAPPO NA-MAPPO NA-WN-MAPPO NA-OU-MAPPO 场景1 42.93 45.45 52.50 68.50 70 72.6 场景2 70.00 65.80 78.02 90.50 100 100.0 场景3 109.05 120.85 136.47 143.33 151 154.0 场景4 134.05 143.36 153.09 190.66 200 200.0 表 2 实验超参数设置Table 2 Experimental hyperparameter setting参数 值 折扣因子$ \gamma $ 0.9000 Critic网络的学习率$ {\alpha _w} $ 0.0010 Actor网络的学习率$ {\alpha _u} $ 0.0001 目标Critic网络的学习率$ {\alpha _{w'}} $ 0.0010 批量$ N _{\mathrm{batch}}$ 1024 缓冲器尺寸$ M_{\mathrm{buffer}} $ 10000 软更新因子$ \tau $ 0.0010 隐藏层1神经元数 128 隐藏层2神经元数 128 4. 结论
本文提出一种基于优势函数输入扰动的多智能体近端策略优化方法. 在集中训练和分散执行框架基础上, 通过在优势函数输入端注入扰动, 有效提升了优势函数的泛化能力, 促进了策略对未知奖励区域的探索. 与现有的基准算法相比, 所提方法能够有效提升多无人艇协同导航任务的成功率, 缩短策略的训练时间以及任务的完成时间, 有效缓解了多无人艇协同策略易陷入局部最优的问题.
-

图 2 考虑相关性的多元输出仿真结果验证方法流程
Fig. 2 Procedures of multivariate simulation result validation under correlation
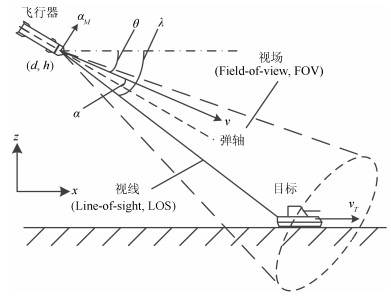
图 3 纵向平面内弹目相对运动几何关系
Fig. 3 Geometrical relationship of relative missile-target movement in longitudinal plane
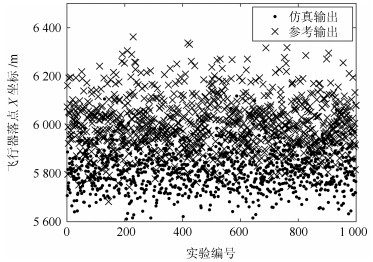
图 8 飞行器落点X坐标输出散点图
Fig. 8 Scatter diagram of X-direction drop point coordinates of the flight vehicle
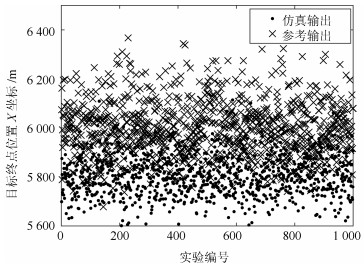
图 9 目标终点位置X坐标输出散点图
Fig. 9 Scatter diagram of X-direction terminal point coordinates of the target vehicle
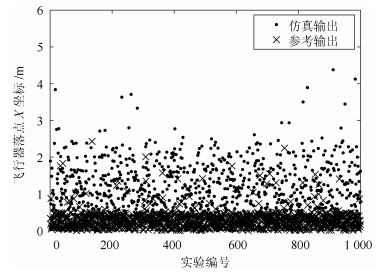
图 10 飞行器落点Z坐标输出散点图
Fig. 10 Scatter diagram of the terminal point of the target in the Z direction
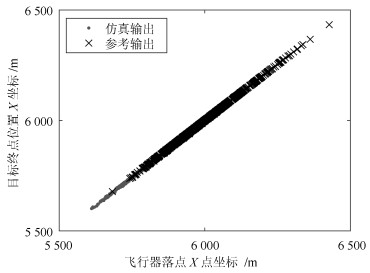
图 11 飞行器落点X坐标与目标终点位置X坐标间的关系
Fig. 11 Relationship of X-direction coordinates between drop point of flight vehicle and terminal point of target
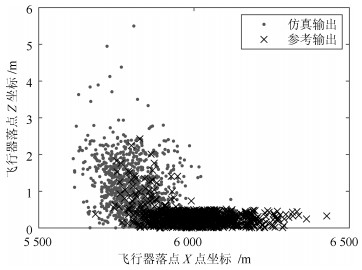
图 12 飞行器落点X方向坐标与Z方向坐标间的关系
Fig. 12 Relationship between X-direction and Z-direction coordinates of the drop point of flight vehicle
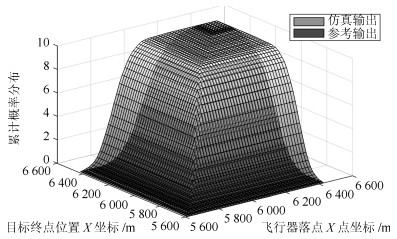
图 13 仿真和参考静态输出变量子集Ⅰ的联合CDF对比
Fig. 13 JCDF comparison of variable subset I between static simulation and reference output
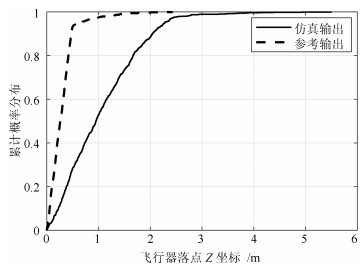
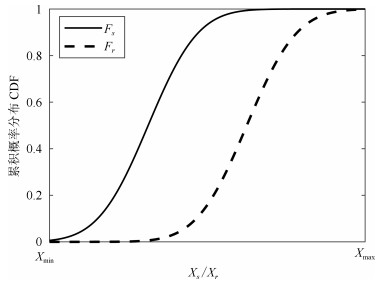
图 14 仿真和参考静态输出变量子集Ⅱ的CDF对比
Fig. 14 Comparison of variable subset Ⅱ between static simulation and reference output
表 1 常用变量选择方法对比
Table 1 Comparison of general variable selection methods
变量选择方法 是否为原变量集的子集 是否支持非线性相关关系 个体决策所占比例 是否需要训练样本集 运行速度与变量个数的关系 SVD 否 否 是 否 线性增长 PCA 否 否 是 否 线性增长 KNN 是 是 是 是 指数增长 DT 是 是 是 是 指数增长 BN 是 是 是 是 指数增长 FD 是 是 是 否 线性增长  下载: 导出CSV
下载: 导出CSV
表 2 飞行器末制导过程的不确定参数取值
Table 2 Uncertainty parameters values in the terminal guidance process of flight vehicle
变量名 仿真模型参数分布 参考系统参数分布 大气密度系数${{C}_{{ }\!\!\rho\!\!{ }}}$ $N\left( 0, 0.033 \right)$ $N\left( 0, 0.033 \right)$ 升力系数${{C}_{{D}}}$ $N(0, 0.05)$ $N(0.02, 0.07)$ 阻力系数${{C}_{{L}}}$ $N(0, 0.033)$ $N(0.02, 0.033)$ 初始弹道倾角${{{\theta }_{0}}}~/{{\rm rad}}$ $N\left( 0.17, 0.09 \right)$ $N\left( 0.26, 0.07 \right)$ 初始视线角${{{\lambda }_{0}}}~/{{\rm rad}}$ $N\left( 0.17, 0.09 \right)$ $N\left( 0.17, 0.09 \right)$
下载: 导出CSV
表 3 待验证的模型输出
Table 3 Model outputs to be validated
变量类型 变量名 动态 弹道倾角${\theta }~$(rad) 动态 攻角${\alpha }$ (rad) 动态 视线角${\lambda }~$(rad) 动态 弹目相对距离${{{D}_{{MT}}}}~$(m) 动态 目标速度${{v}_{{T}}}~$(m/s) 静态 飞行器落点X坐标${{{x}_{{f}}}}~$(m) 静态 飞行器落点Z坐标${{{z}_{{f}}}}~$(m) 静态 目标终点位置X坐标${{{x}_{{Tf}}}}~$(m) 静态 目标终点位置Z坐标${{{z}_{{Tf}}}}~$(m)
下载: 导出CSV
表 4 多元输出变量选择结果
Table 4 Variables selection results of multiple outputs
输出类型 变量子集Ⅰ 变量子集Ⅱ 变量子集Ⅲ 动态 $\theta $, $\alpha$, $\lambda$, ${{D}_{{MT}}}$ ${{v}_{{T}}}$ - 静态 ${{x}_{{f}}}$, ${{x}_{{Tf}}}$ ${{z}_{{f}}}$ ${{z}_{{Tf}}}$
下载: 导出CSV
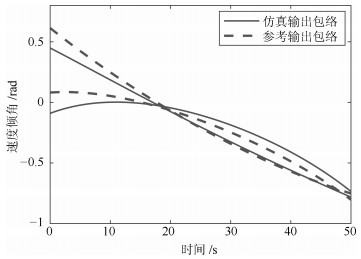
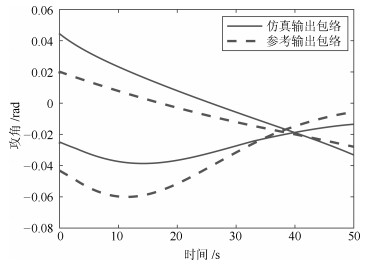
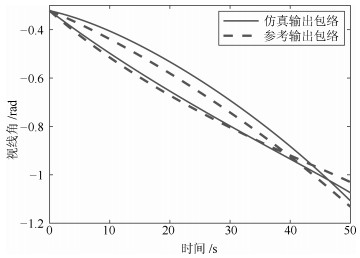
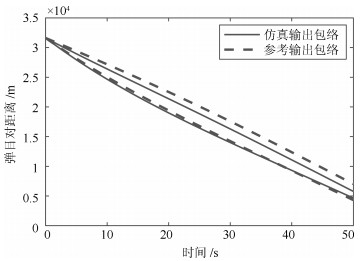
表 5 动态输出均值曲线的一致性分析结果
Table 5 Consistency analysis results of the mean curves of dynamic outputs
变量名 位置特征一致性 形状特征一致性 $\theta $ 0.92 0.74 $\alpha$ 0.63 0.60 $\lambda$ 0.98 0.74 ${{D}_{{MT}}}$ 0.97 0.61
下载: 导出CSV
表 6 仿真和参考输出变量子集的一致性分析结果
Table 6 Consistency analysis results of the variables subset of the simulation and reference outputs
输出变量类型 变量子集标号 累积概率分布差异 可信度结果 动态 变量子集Ⅰ 位置差异: $8.92\times {{10}^{{-8}}}$ 位置特征: 0.99 动态 变量子集Ⅰ 形状差异: $1.1\times {{10}^{{-3}}}$ 形状特征: 0.94 动态 变量子集Ⅱ 0 1 静态 变量子集Ⅰ $1.6\times {{10}^{5}}$ 0.84 静态 变量子集Ⅱ 0.5 0.9 静态 变量子集Ⅲ 0 1
下载: 导出CSV
表 7 验证实验的不确定参数取值
Table 7 Uncertainty parameters values for validation experiments
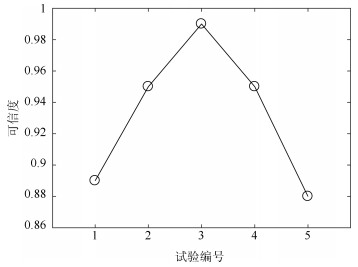
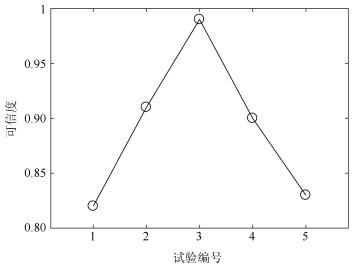
试验编号 参考系统${{\theta }_{0}}$取值 实验组Ⅰ ${{\theta }_{0}}$取值 实验组Ⅱ ${{\theta }_{0}}$取值 1 $N\left( 0.26, 0.07 \right)$ 0.26 $N\left( 0.15, 0.07 \right)$ 2 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.04 \right)$ $N\left( 0.21, 0.07 \right)$ 3 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.07 \right)$ 4 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.1 \right)$ $N\left( 0.31, 0.07 \right)$ 5 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.13 \right)$ $N\left( 0.37, 0.07 \right)$
下载: 导出CSV
-
[1] 李伟, 焦松, 陆凌云, 杨明.基于特征差异的仿真模型验证及选择方法.自动化学报, 2014, 40(10):2134-2144 http://www.aas.net.cn/CN/abstract/abstract18488.shtmlLi Wei, Jiao Song, Lu Ling-Yun, Yang Ming. Validation and selection of simulation model based on the feature differences. Acta Automatica Sinica, 2014, 40(10):2134-2144 http://www.aas.net.cn/CN/abstract/abstract18488.shtml [2] 杨明, 钱晓超, 李伟.基于数据特征的仿真动态输出验证方法.系统工程与电子技术, 2016, 38(2):457-463 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201602032Yang Ming, Qian Xiao-Chao, Li Wei. Simulation dynamic output validation method based on the data feature. Systems Engineering and Electronics, 2016, 38(2):457-463 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201602032 [3] Oberkampf W L, Trucano T G, Hirsch C. Verification, validation, and predictive capability in computational engineering and physics. Applied Mechanics Reviews, 2004, 57(5):345-384 doi: 10.1115/1.1767847 [4] Oberkampf W L, Barone M F. Measures of agreement between computation and experiment:Validation metrics. Journal of Computational Physics, 2006, 217(1):5-36 doi: 10.1016/j.jcp.2006.03.037 [5] Oberkampf W L, Trucano T G. Verification and validation in computational fluid dynamics. Progress in Aerospace Sciences, 2002, 38(1):209-272 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1109.3563 [6] Liu Y, Chen W, Arendt P, Huang H Z. Towards a better understanding of model validation metrics. Journal of Mechanical Design, 2011, 133(7):071005 doi: 10.1115/1.4004223 [7] Ling Y, Mahadevan S. Quantitative model validation techniques:New insights. Reliability Engineering and System Safety, 2013, 111:217-231 doi: 10.1016/j.ress.2012.11.011 [8] Rebba R, Huang S P, Liu Y M, Mahadevan S. Statistical validation of simulation models. International Journal of Materials and Product Technology, 2006, 25(1-3):164-181 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_6ba738ce08ef690dd265c27334d7b4ee [9] Jiang X M, Yuan Y, Mahadevan S, Liu X. An investigation of Bayesian inference approach to model validation with non-normal data. Journal of Statistical Computation and Simulation, 2013, 83(10):1829-1851 doi: 10.1080/00949655.2012.672572 [10] Sankararaman S, Mahadevan S. Integration of model verification, validation, and calibration for uncertainty quantification in engineering systems. Reliability Engineering & System Safety, 2015, 138:194-209 http://cn.bing.com/academic/profile?id=9763b054e4ac4c68d873cecf339e3d5f&encoded=0&v=paper_preview&mkt=zh-cn [11] Wang H Y, Li W, Qian X C. An improved Jousselme evidence distance. In: Proceedings of the 16th Asia Simulation Conference. Beijing, China: Springer Verlag, 2016. 08-11 [12] Ferson S, Oberkampf W L. Validation of imprecise probability models. International Journal of Reliability and Safety, 2009, 3(1-3):3-22 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e23b65177f5228b1cfa982554009aab5 [13] Ferson S, Oberkampf W L, Ginzburg L. Model validation and predictive capability for the thermal challenge problem. Computer methods in Applied Mechanics and Engineering, 2008, 197(29-32):2408-2430 doi: 10.1016/j.cma.2007.07.030 [14] Jiang X M, Mahadevan S, Urbina A. Bayesian nonlinear structural equation modeling for hierarchical validation of dynamical systems. Mechanical Systems and Signal Processing, 2010, 24(4):957-975 doi: 10.1016/j.ymssp.2009.10.002 [15] Rebba R, Mahadevan S. Validation of models with multivariate output. Reliability Engineering & System Safety, 2006, 91(8):861-871 http://cn.bing.com/academic/profile?id=0c955876f7032def65f7daff4b18e7bc&encoded=0&v=paper_preview&mkt=zh-cn [16] Jiang X M, Mahadevan S. Bayesian inference method for model validation and confidence extrapolation. Journal of Applied Statistics, 2009, 36(6):659-677 doi: 10.1080/02664760802499295 [17] Zhan Z F, Fu Y, Yang R J, Peng Y H. Bayesian based multivariate model validation method under uncertainty for dynamic systems. Journal of Mechanical Design, 2012, 134(3):034502 doi: 10.1115/1.4005863 [18] Li W, Chen W, Jiang Z, Lu Z Z, Liu Y. New validation metrics for models with multiple correlated responses. Reliability Engineering & System Safety, 2014, 127:1-11 http://cn.bing.com/academic/profile?id=5cca6d1b2cff2b22ee5644d8fb5c0f6a&encoded=0&v=paper_preview&mkt=zh-cn [19] Zhao L F, Lu Z Z, Yun W Y, Wang W J. Validation metric based on Mahalanobis distance for models with multiple correlated responses. Reliability Engineering & System Safety, 2017, 159:80-89 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=873e8c39ee8f0888abe3f211d871b4ad [20] Sousa E P, Traina A J, Wu L, Faloutsos C. A fast and effective method to find correlations among attributes in databases. Data Mining and Knowledge Discovery, 2007, 14(3):367-407 doi: 10.1007-s10618-006-0056-4/ [21] 何宽, 陈森发.基于一类因果关系图的综合评价方法及应用.控制与决策. 2010, 25(10):1513-1518 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201010013He Kuan, Chen Sen-fa. Comprehensive evaluation method based on one of causal diagram and its application. Control and Decision, 2010, 25(10):1513-1518 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201010013 [22] Yamamoto H, Yamaji H, Fukusaki E, Ohno H, Fukuda H. Canonical correlation analysis for multivariate regression and its application to metabolic fingerprinting. Biochemical Engineering Journal, 2008, 40(2):199-204 doi: 10.1016/j.bej.2007.12.009 [23] Nelsen R B. An Introduction to Copulas. 2nd Edition. New York:Springer-Verlag, 2006. 8-25 [24] Tseng F M, Yu H C, Tzeng G H. Applied hybrid grey model to forecast seasonal time series. Technological Forecasting and Social Change, 2001, 67(2-3):291-302 doi: 10.1016/S0040-1625(99)00098-0 [25] Kwak N, Choi C H. Input feature selection by mutual information based on Parzen window. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(12):1667-1671 doi: 10.1109/TPAMI.2002.1114861 [26] 王金甲, 陈春.分层向量自回归的多通道脑电信号的特征提取研究.自动化学报, 2016, 42(8):1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtmlWang Jin-Jia, Chen Chun. Multi-channel eeg feature extraction using hierarchical vector autoregression. Acta Automatica Sinica, 2016, 42(8):1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtml [27] 毛文涛, 蒋梦雪, 李源, 张仕光.基于异常序列剔除的多变量时间序列结构化预测.自动化学报, 2017, 44(4):619-634 http://www.aas.net.cn/CN/abstract/abstract19254.shtmlMao Wen-Tao, Jiang Meng-Xue, Li Yuan, Zhang Shi-Guang. Structural prediction of multivariate time series based on outlier elimination. Acta Automatica Sinica, 2017, 44(4):619-634 http://www.aas.net.cn/CN/abstract/abstract19254.shtml [28] Han M, Liu X X. Feature selection techniques with class separability for multivariate time series. Neurocomputing, 2013, 110:29-34 doi: 10.1016/j.neucom.2012.12.006 [29] 林圣琳, 李伟, 马萍, 杨明.基于Hilbert-Huang变换的仿真模型排序评估方法.系统工程与电子技术, 2017, 39(9):2137-2142 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201709032Lin Sheng-Lin, Li Wei, Ma Ping, Yang Ming. Ranking evaluation of simulation models based on Hilbert-Huang transform. Systems Engineering and Electronics, 2017, 39(9):2137-2142 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201709032 [30] Zhou Di, Sun Sheng, Teo K L. Guidance laws with finite time convergence. Journal of Guidance, Control, and Dynamics, 2009, 32(6):061401 http://d.old.wanfangdata.com.cn/Periodical/hebgydxxb201804002 -


 下载:
下载:






计量
- 文章访问数: 2262
- HTML全文浏览量: 244
- PDF下载量: 87
- 被引次数: 0
