

-
摘要: 复杂仿真模型一般具有多个不同类型且带有相关性的输出,现有验证方法存在变量信息缺失、变量相关性度量不准确等问题.为此,提出基于变量选择和概率分布差异相结合的多变量仿真结果验证方法,考虑不确定性的影响,对选取到具有相关性的多个变量进行联合验证.首先,引入分形维数和互信息方法对多元异类输出进行相关性分析,提取相关变量子集.而后对相关变量子集中的各变量提取数据特征,进而计算各相关变量子集关于数据特征的联合概率分布,采用概率分布差异法度量仿真输出和参考输出联合概率分布的差异,并将其转化为一致性程度;在此基础上综合多个验证结果得到模型可信度.通过实例应用及对比实验,验证了方法的有效性.Abstract: Complex simulation models often generate the multivariate and different types of output, some problems such as the lacking variables information and the inaccuracy correlation measurement are involved in the existing validation methods. A novel validation method combining variables selection with area metric is proposed, the multiple outputs with correlation are selected for the associated validation under uncertainty. The fractal dimension and mutual information methods are primarily applied to analyze the correlation among multivariate and divise responses and extract the correlated variable subsets. Next, the interesting data characteristics of all variables are extracted in subset and the corresponding joint cumulative distribution function (JCDF) of each subset related to any characteristic is calculated. The area metric is used to measure the difference between the simulation and reference output JCDFs of multivariate characteristics in each subset, and the differences are transformed into the consistency degrees. Then the multiple validation results are integrated to obtain the model credibility. Finally, the method is validated through the application case and comparison experiments.1) 本文责任编委 莫红
-

图 2 考虑相关性的多元输出仿真结果验证方法流程
Fig. 2 Procedures of multivariate simulation result validation under correlation
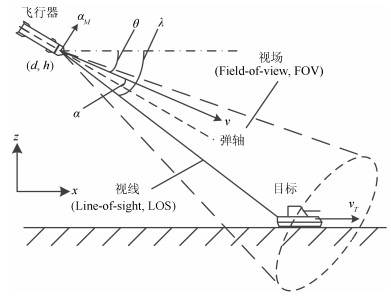
图 3 纵向平面内弹目相对运动几何关系
Fig. 3 Geometrical relationship of relative missile-target movement in longitudinal plane
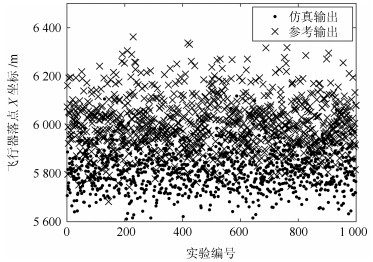
图 8 飞行器落点X坐标输出散点图
Fig. 8 Scatter diagram of X-direction drop point coordinates of the flight vehicle
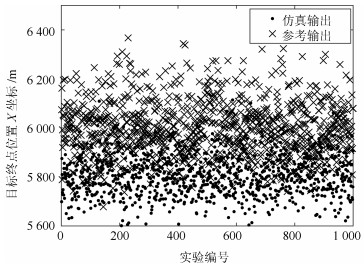
图 9 目标终点位置X坐标输出散点图
Fig. 9 Scatter diagram of X-direction terminal point coordinates of the target vehicle
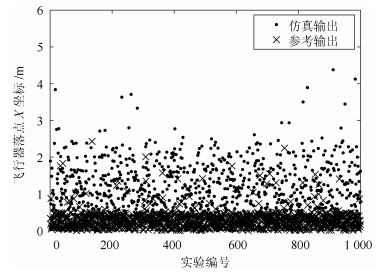
图 10 飞行器落点Z坐标输出散点图
Fig. 10 Scatter diagram of the terminal point of the target in the Z direction
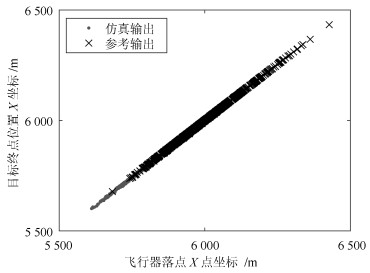
图 11 飞行器落点X坐标与目标终点位置X坐标间的关系
Fig. 11 Relationship of X-direction coordinates between drop point of flight vehicle and terminal point of target
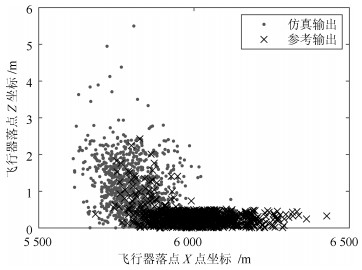
图 12 飞行器落点X方向坐标与Z方向坐标间的关系
Fig. 12 Relationship between X-direction and Z-direction coordinates of the drop point of flight vehicle
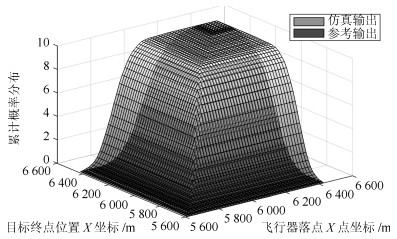
图 13 仿真和参考静态输出变量子集Ⅰ的联合CDF对比
Fig. 13 JCDF comparison of variable subset I between static simulation and reference output
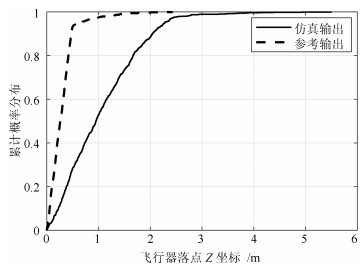
图 14 仿真和参考静态输出变量子集Ⅱ的CDF对比
Fig. 14 Comparison of variable subset Ⅱ between static simulation and reference output
表 1 常用变量选择方法对比
Table 1 Comparison of general variable selection methods
变量选择方法 是否为原变量集的子集 是否支持非线性相关关系 个体决策所占比例 是否需要训练样本集 运行速度与变量个数的关系 SVD 否 否 是 否 线性增长 PCA 否 否 是 否 线性增长 KNN 是 是 是 是 指数增长 DT 是 是 是 是 指数增长 BN 是 是 是 是 指数增长 FD 是 是 是 否 线性增长  下载: 导出CSV
下载: 导出CSV
表 2 飞行器末制导过程的不确定参数取值
Table 2 Uncertainty parameters values in the terminal guidance process of flight vehicle
变量名 仿真模型参数分布 参考系统参数分布 大气密度系数${{C}_{{ }\!\!\rho\!\!{ }}}$ $N\left( 0, 0.033 \right)$ $N\left( 0, 0.033 \right)$ 升力系数${{C}_{{D}}}$ $N(0, 0.05)$ $N(0.02, 0.07)$ 阻力系数${{C}_{{L}}}$ $N(0, 0.033)$ $N(0.02, 0.033)$ 初始弹道倾角${{{\theta }_{0}}}~/{{\rm rad}}$ $N\left( 0.17, 0.09 \right)$ $N\left( 0.26, 0.07 \right)$ 初始视线角${{{\lambda }_{0}}}~/{{\rm rad}}$ $N\left( 0.17, 0.09 \right)$ $N\left( 0.17, 0.09 \right)$
下载: 导出CSV
表 3 待验证的模型输出
Table 3 Model outputs to be validated
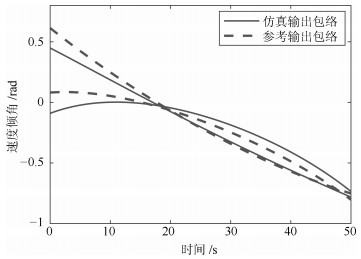
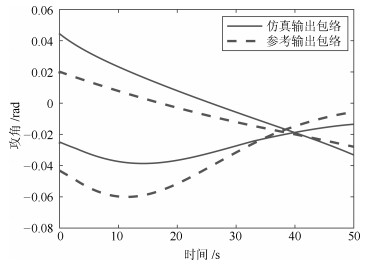
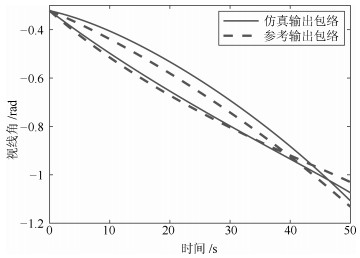
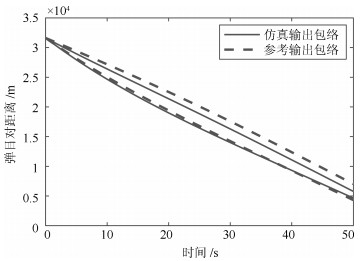
变量类型 变量名 动态 弹道倾角${\theta }~$(rad) 动态 攻角${\alpha }$ (rad) 动态 视线角${\lambda }~$(rad) 动态 弹目相对距离${{{D}_{{MT}}}}~$(m) 动态 目标速度${{v}_{{T}}}~$(m/s) 静态 飞行器落点X坐标${{{x}_{{f}}}}~$(m) 静态 飞行器落点Z坐标${{{z}_{{f}}}}~$(m) 静态 目标终点位置X坐标${{{x}_{{Tf}}}}~$(m) 静态 目标终点位置Z坐标${{{z}_{{Tf}}}}~$(m)
下载: 导出CSV
表 4 多元输出变量选择结果
Table 4 Variables selection results of multiple outputs
输出类型 变量子集Ⅰ 变量子集Ⅱ 变量子集Ⅲ 动态 $\theta $, $\alpha$, $\lambda$, ${{D}_{{MT}}}$ ${{v}_{{T}}}$ - 静态 ${{x}_{{f}}}$, ${{x}_{{Tf}}}$ ${{z}_{{f}}}$ ${{z}_{{Tf}}}$
下载: 导出CSV
表 5 动态输出均值曲线的一致性分析结果
Table 5 Consistency analysis results of the mean curves of dynamic outputs
变量名 位置特征一致性 形状特征一致性 $\theta $ 0.92 0.74 $\alpha$ 0.63 0.60 $\lambda$ 0.98 0.74 ${{D}_{{MT}}}$ 0.97 0.61
下载: 导出CSV
表 6 仿真和参考输出变量子集的一致性分析结果
Table 6 Consistency analysis results of the variables subset of the simulation and reference outputs
输出变量类型 变量子集标号 累积概率分布差异 可信度结果 动态 变量子集Ⅰ 位置差异: $8.92\times {{10}^{{-8}}}$ 位置特征: 0.99 动态 变量子集Ⅰ 形状差异: $1.1\times {{10}^{{-3}}}$ 形状特征: 0.94 动态 变量子集Ⅱ 0 1 静态 变量子集Ⅰ $1.6\times {{10}^{5}}$ 0.84 静态 变量子集Ⅱ 0.5 0.9 静态 变量子集Ⅲ 0 1
下载: 导出CSV
表 7 验证实验的不确定参数取值
Table 7 Uncertainty parameters values for validation experiments
试验编号 参考系统${{\theta }_{0}}$取值 实验组Ⅰ ${{\theta }_{0}}$取值 实验组Ⅱ ${{\theta }_{0}}$取值 1 $N\left( 0.26, 0.07 \right)$ 0.26 $N\left( 0.15, 0.07 \right)$ 2 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.04 \right)$ $N\left( 0.21, 0.07 \right)$ 3 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.07 \right)$ 4 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.1 \right)$ $N\left( 0.31, 0.07 \right)$ 5 $N\left( 0.26, 0.07 \right)$ $N\left( 0.26, 0.13 \right)$ $N\left( 0.37, 0.07 \right)$
下载: 导出CSV
-
[1] 李伟, 焦松, 陆凌云, 杨明.基于特征差异的仿真模型验证及选择方法.自动化学报, 2014, 40(10):2134-2144 http://www.aas.net.cn/CN/abstract/abstract18488.shtmlLi Wei, Jiao Song, Lu Ling-Yun, Yang Ming. Validation and selection of simulation model based on the feature differences. Acta Automatica Sinica, 2014, 40(10):2134-2144 http://www.aas.net.cn/CN/abstract/abstract18488.shtml [2] 杨明, 钱晓超, 李伟.基于数据特征的仿真动态输出验证方法.系统工程与电子技术, 2016, 38(2):457-463 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201602032Yang Ming, Qian Xiao-Chao, Li Wei. Simulation dynamic output validation method based on the data feature. Systems Engineering and Electronics, 2016, 38(2):457-463 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201602032 [3] Oberkampf W L, Trucano T G, Hirsch C. Verification, validation, and predictive capability in computational engineering and physics. Applied Mechanics Reviews, 2004, 57(5):345-384 doi: 10.1115/1.1767847 [4] Oberkampf W L, Barone M F. Measures of agreement between computation and experiment:Validation metrics. Journal of Computational Physics, 2006, 217(1):5-36 doi: 10.1016/j.jcp.2006.03.037 [5] Oberkampf W L, Trucano T G. Verification and validation in computational fluid dynamics. Progress in Aerospace Sciences, 2002, 38(1):209-272 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1109.3563 [6] Liu Y, Chen W, Arendt P, Huang H Z. Towards a better understanding of model validation metrics. Journal of Mechanical Design, 2011, 133(7):071005 doi: 10.1115/1.4004223 [7] Ling Y, Mahadevan S. Quantitative model validation techniques:New insights. Reliability Engineering and System Safety, 2013, 111:217-231 doi: 10.1016/j.ress.2012.11.011 [8] Rebba R, Huang S P, Liu Y M, Mahadevan S. Statistical validation of simulation models. International Journal of Materials and Product Technology, 2006, 25(1-3):164-181 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_6ba738ce08ef690dd265c27334d7b4ee [9] Jiang X M, Yuan Y, Mahadevan S, Liu X. An investigation of Bayesian inference approach to model validation with non-normal data. Journal of Statistical Computation and Simulation, 2013, 83(10):1829-1851 doi: 10.1080/00949655.2012.672572 [10] Sankararaman S, Mahadevan S. Integration of model verification, validation, and calibration for uncertainty quantification in engineering systems. Reliability Engineering & System Safety, 2015, 138:194-209 http://cn.bing.com/academic/profile?id=9763b054e4ac4c68d873cecf339e3d5f&encoded=0&v=paper_preview&mkt=zh-cn [11] Wang H Y, Li W, Qian X C. An improved Jousselme evidence distance. In: Proceedings of the 16th Asia Simulation Conference. Beijing, China: Springer Verlag, 2016. 08-11 [12] Ferson S, Oberkampf W L. Validation of imprecise probability models. International Journal of Reliability and Safety, 2009, 3(1-3):3-22 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e23b65177f5228b1cfa982554009aab5 [13] Ferson S, Oberkampf W L, Ginzburg L. Model validation and predictive capability for the thermal challenge problem. Computer methods in Applied Mechanics and Engineering, 2008, 197(29-32):2408-2430 doi: 10.1016/j.cma.2007.07.030 [14] Jiang X M, Mahadevan S, Urbina A. Bayesian nonlinear structural equation modeling for hierarchical validation of dynamical systems. Mechanical Systems and Signal Processing, 2010, 24(4):957-975 doi: 10.1016/j.ymssp.2009.10.002 [15] Rebba R, Mahadevan S. Validation of models with multivariate output. Reliability Engineering & System Safety, 2006, 91(8):861-871 http://cn.bing.com/academic/profile?id=0c955876f7032def65f7daff4b18e7bc&encoded=0&v=paper_preview&mkt=zh-cn [16] Jiang X M, Mahadevan S. Bayesian inference method for model validation and confidence extrapolation. Journal of Applied Statistics, 2009, 36(6):659-677 doi: 10.1080/02664760802499295 [17] Zhan Z F, Fu Y, Yang R J, Peng Y H. Bayesian based multivariate model validation method under uncertainty for dynamic systems. Journal of Mechanical Design, 2012, 134(3):034502 doi: 10.1115/1.4005863 [18] Li W, Chen W, Jiang Z, Lu Z Z, Liu Y. New validation metrics for models with multiple correlated responses. Reliability Engineering & System Safety, 2014, 127:1-11 http://cn.bing.com/academic/profile?id=5cca6d1b2cff2b22ee5644d8fb5c0f6a&encoded=0&v=paper_preview&mkt=zh-cn [19] Zhao L F, Lu Z Z, Yun W Y, Wang W J. Validation metric based on Mahalanobis distance for models with multiple correlated responses. Reliability Engineering & System Safety, 2017, 159:80-89 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=873e8c39ee8f0888abe3f211d871b4ad [20] Sousa E P, Traina A J, Wu L, Faloutsos C. A fast and effective method to find correlations among attributes in databases. Data Mining and Knowledge Discovery, 2007, 14(3):367-407 doi: 10.1007-s10618-006-0056-4/ [21] 何宽, 陈森发.基于一类因果关系图的综合评价方法及应用.控制与决策. 2010, 25(10):1513-1518 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201010013He Kuan, Chen Sen-fa. Comprehensive evaluation method based on one of causal diagram and its application. Control and Decision, 2010, 25(10):1513-1518 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201010013 [22] Yamamoto H, Yamaji H, Fukusaki E, Ohno H, Fukuda H. Canonical correlation analysis for multivariate regression and its application to metabolic fingerprinting. Biochemical Engineering Journal, 2008, 40(2):199-204 doi: 10.1016/j.bej.2007.12.009 [23] Nelsen R B. An Introduction to Copulas. 2nd Edition. New York:Springer-Verlag, 2006. 8-25 [24] Tseng F M, Yu H C, Tzeng G H. Applied hybrid grey model to forecast seasonal time series. Technological Forecasting and Social Change, 2001, 67(2-3):291-302 doi: 10.1016/S0040-1625(99)00098-0 [25] Kwak N, Choi C H. Input feature selection by mutual information based on Parzen window. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(12):1667-1671 doi: 10.1109/TPAMI.2002.1114861 [26] 王金甲, 陈春.分层向量自回归的多通道脑电信号的特征提取研究.自动化学报, 2016, 42(8):1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtmlWang Jin-Jia, Chen Chun. Multi-channel eeg feature extraction using hierarchical vector autoregression. Acta Automatica Sinica, 2016, 42(8):1215-1226 http://www.aas.net.cn/CN/abstract/abstract18911.shtml [27] 毛文涛, 蒋梦雪, 李源, 张仕光.基于异常序列剔除的多变量时间序列结构化预测.自动化学报, 2017, 44(4):619-634 http://www.aas.net.cn/CN/abstract/abstract19254.shtmlMao Wen-Tao, Jiang Meng-Xue, Li Yuan, Zhang Shi-Guang. Structural prediction of multivariate time series based on outlier elimination. Acta Automatica Sinica, 2017, 44(4):619-634 http://www.aas.net.cn/CN/abstract/abstract19254.shtml [28] Han M, Liu X X. Feature selection techniques with class separability for multivariate time series. Neurocomputing, 2013, 110:29-34 doi: 10.1016/j.neucom.2012.12.006 [29] 林圣琳, 李伟, 马萍, 杨明.基于Hilbert-Huang变换的仿真模型排序评估方法.系统工程与电子技术, 2017, 39(9):2137-2142 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201709032Lin Sheng-Lin, Li Wei, Ma Ping, Yang Ming. Ranking evaluation of simulation models based on Hilbert-Huang transform. Systems Engineering and Electronics, 2017, 39(9):2137-2142 http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201709032 [30] Zhou Di, Sun Sheng, Teo K L. Guidance laws with finite time convergence. Journal of Guidance, Control, and Dynamics, 2009, 32(6):061401 http://d.old.wanfangdata.com.cn/Periodical/hebgydxxb201804002 -

 下载:
下载:

计量
- 文章访问数: 2466
- HTML全文浏览量: 324
- PDF下载量: 88
- 被引次数: 0
