

-
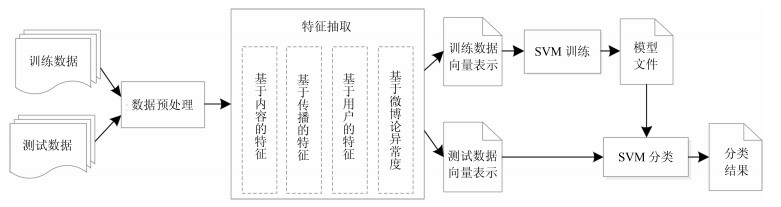
摘要: 以微博为代表的社交媒体在为公众提供信息共享平台的同时, 也为谣言提供了可乘之机.开展微博中谣言的识别和清理方法研究, 对维护社会的安全稳定有着重要的现实意义.本文针对新浪微博平台中谣言识别的问题, 提出了一种基于评论异常度的微博谣言识别方法.首先采用D-S理论实现微博评论异常度的计算方法; 然后利用评论异常度与微博的内容特征、传播特征、用户特征对微博进行抽象表示; 最后再利用SVM (Support vector machine)构建一个基于评论异常度的谣言识别模型, 实现对新浪微博中谣言微博的识别.实验表明, 本文提出的谣言识别模型对新浪微博中谣言识别具有较好的效果, 谣言微博识别的F1值达到了96.2 %, 相较于现有文献的最好结果提高了1.3 %.Abstract: Microblog plays an important role in social network service, while providing an information communication platform for users, it also provides a loophole for rumors. It is of great practical significance to automatically detect and clean up rumors in microblogs for the security and stability of society. In this paper, a rumor detecting method based on comment abnormality is presented. Firstly, we use D-S theory to implement the calculation method of comment abnormality. And then, we combine the comment abnormality, text features, propagation features and user characteristics to abstractly represent Sina Weibo. Finally, we use SVM (Support vector machine) to build a rumor detecting model based on comment abnormality. The experimental results show that the rumor detecting model proposed can effectively improve the detecting performance. And the F-measure of the rumor detecting is up to 96.2 %, which is up by 1.3 % compared with the best value in other literatures.
-
Key words:
- Rumor detecting /
- Sina Weibo /
- comment abnormality /
- D-S theory /
- SVM
-

图 1 谣言微博与普通微博的评论数对比
Fig. 1 Comparison of the number of comments between rumor Weibo and ordinary Weibos

图 2 谣言微博与普通微博的评论文本对比
Fig. 2 Comparison of the comment texts between rumor Weibo and ordinary Weibo

图 4 用户的普通微博与谣言微博平均评论数对比
Fig. 4 Comparison of the average number of comments between rumor Weibo and ordinary Weibo for some users

图 10 谣言微博与普通微博评论异常度分布对比
Fig. 10 Comparison of the comment abnormality distribution between rumor Weibos and ordinary Weibos
表 1 微博谣言识别基础特征体系
Table 1 The basic feature system of Weibo rumor detecting
特征种类 特征名称 特征描述 微博内容特征 $Length$ 微博文本的长度 $Has\_Multimedia$ 微博文本中是否含有多媒体信息, 如图片、视频和外部链接 $Emotion\_Tendency$ 微博的情感倾向, 分为正向情感和负向情感 $Number\_of\_@$ 微博文本中的@数量 $Number\_of\_topics$ 微博文本参与的话题数量 微博传播特征 $Time\_Span$ 微博发布时间与用户注册时间的间隔天数 $Client\_Type$ 发布微博的客户端类型, 包括移动客户端和非移动客户端 $Participation$ 网民参与度, 评论数和转发数两者之和与评论数、转发数和点赞数三者之和的比值 微博用户特征 $Has\_Verify$ 用户是否为认证用户 $Has\_Description$ 用户是否有自述信息 $Influence$ 用户影响力, 用户粉丝数与用户粉丝数和关注数两者之和的比值 $Register\_Time$ 用户的注册时间 $Number\_of\_blogs$ 用户的微博数量  下载: 导出CSV
下载: 导出CSV
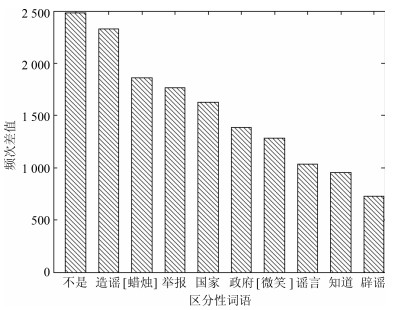
表 2 谣言微博评论的区分性词集
Table 2 The identified word sets of rumor Weibo comments
类别 词集 $Zwords$ 造谣, 举报, 谣言, 辟谣, 不实, 传谣 $Gwords$ 不是, [蜡烛], 国家, 政府, [微笑], 知道, 真相, 新闻, 脑子, 真的, 祈祷, 呵呵, 智障, 没有, 恶心, 消息, 是不是, 口德, 真是, 相信, 素质, 打死, 事实, 智商, 抵制, 他妈的, 怒骂, 证据, 老百姓, [吃惊], 新浪, 不要脸, 证实, 脑残, [拜拜], 垃圾, 可怕, 小心, 尼玛, 传播, 暴力, 难道, 神经病, 法律, 公道, 记者, 媒体, 赶紧, 去死吧, 真假, 可能, 删除, 网警, 乱说, 不信, 打脸, 假新闻, 眼球, 国人, 键盘, 官方, 人性, 理智, 良心, 明显, 所谓, 民众, 不用, 无辜, 底线, 言论, 该死, 肯定, 水军, 真的假, 遭报应, 有意思, 侮辱, 生命, 央视, 闭嘴, 活该, 愤怒, 确定, 喷子, [怒], 煽动, 真实, 常识, 骂人, 缺德, 鄙视, 无知, 不删
下载: 导出CSV
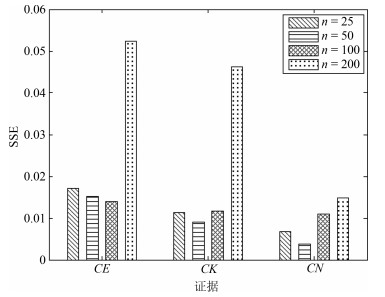
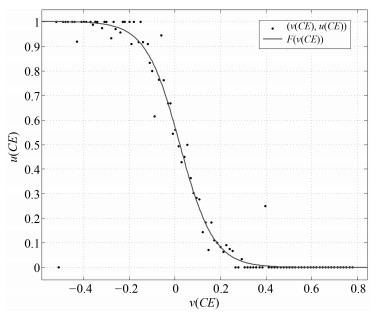
表 3 $CE$、$CK$、$CN$的取值范围
Table 3 The range of values of $CE$, $CK$ and $CN$
证据 取值范围 $ CE$ [$-0.530$, 0.782] $ CK$ [0, 0.178] $ CN$ [$-7.245$, 8.231]
下载: 导出CSV
表 4 不同特征的准确率比较
Table 4 Comparison of accuracies of different features
序号 特征 准确率 1 $Length$ 0.513 2 $Has\_Multimedia$ 0.627 3 $Emotion\_Tendency$ 0.601 4 $Number\_of\_@$ 0.543 5 $Number\_of\_topics$ 0.515 6 $Time\_Span$ 0.633 7 $Client\_Type$ 0.645 8 $Participation$ 0.563 9 $Has\_Verify$ 0.671 10 $Has\_Description$ 0.532 11 $Influence$ 0.513 12 $Register\_Time$ 0.639 13 $Number\_of\_blogs$ 0.703 14 $Comment\_Abnormality$ 0.831
下载: 导出CSV
表 5 不同特征集合的组合情况
Table 5 Combination of different feature sets
对照实验 特征组合描述 基本特征组合 内容特征+传播特征+用户特征 特征组合1 基本特征组合+评论情感异常度 特征组合2 基本特征组合+评论情感异常度+评论用词异常度+评论数目异常度 特征组合3 基本特征组合+微博评论异常度
下载: 导出CSV
表 6 不同特征集合的实验结果对比
Table 6 Comparison of experimental results of different feature sets
特征组合 准确率 召回率 F1值 基本特征组合 0.868 0.913 0.890 特征组合1 0.902 0.930 0.916 特征组合2 0.928 0.937 0.933 特征组合3 0.954 0.971 0.962
下载: 导出CSV
-
[1] Qazvinian V, Rosengren E, Radev D R, Mei Q Z. Rumor has it: Identifying misinformation in microblogs. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Edinburgh, United Kingdom: Association for Computational Linguistics, 2011. 1589-1599 [2] Takahashi T, Igata N. Rumor detection on twitter. In: Proceedings of the 6th International Conference on Soft Computing and Intelligent Systems, and the 13th International Symposium on Advanced Intelligence Systems. Kobe, Japan: IEEE, 2013. 452-457 [3] Castillo C, Mendoza M, Poblete B. Information credibility on twitter. In: Proceedings of the 20th International Conference on World Wide Web. Hyderabad, India: ACM, 2011. 675-684 [4] Suzuki Y. A credibility assessment for message streams on microblogs. In: Proceedings of the 2010 International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. Fukuoka, Japan: IEEE, 2010. 527-530 [5] Ma J, Gao W, Mitra P, Kwon S, Jansen B J, Wong K F, Cha M. Detecting rumors from microblogs with recurrent neural networks. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: AAAI Press, 2016. 3818-3824 [6] Yang F, Liu Y, Yu X H, Yang M. Automatic detection of rumor on Sina Weibo. In: Proceedings of the 2012 ACM SIGKDD Workshop on Mining Data Semantics. Beijing, China: ACM, 2012. Article No. 13 [7] 高明霞, 陈福荣.基于信息融合的中文微博可信度评估方法.计算机应用, 2016, 36(8): 2071-2075, 2081 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyy201608003Gao Ming-Xia, Chen Fu-Rong. Credibility evaluating method of Chinese microblog based on information fusion. Journal of Computer Applications, 2016, 36(8): 2071-2075, 2081 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyy201608003 [8] Wu K, Yang S, Zhu K Q. False rumors detection on Sina Weibo by propagation structures. In: Proceedings of IEEE the 31st International Conference on Data Engineering, Seoul, South Korea: IEEE, 2015. 651-662 [9] 祖坤琳, 赵铭伟, 郭凯, 林鸿飞.新浪微博谣言检测研究.中文信息学报, 2017, 31(3): 198-204 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zwxxxb201703027Zu Kun-Lin, Zhao Ming-Wei, Guo Kai, Lin Hong-Fei. Research on the detection of rumor on Sina Weibo. Journal of Chinese Information Processing, 2017, 31(3): 198-204 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zwxxxb201703027 [10] Mendoza M, Poblete B, Castillo C. Twitter under crisis: Can we trust what we RT? In: Proceedings of the 1st Workshop on Social Media Analytics. Washington D.C., USA: ACM, 2010. 71-79 [11] Yang J, Counts S, Morris M R, Hoff A. Microblog credibility perceptions: Comparing the USA and China. In: Proceedings of the 2013 Conference on Computer Supported Cooperative Work. San Antonio, Texas, USA: ACM, 2013. 575-586 [12] 毛二松, 陈刚, 刘欣, 王波.基于深层特征和集成分类器的微博谣言检测研究.计算机应用研究, 2016, 33(11): 3369-3373 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyyyj201611037Mao Er-Song, Chen Gang, Liu Xin, Wang Bo. Research on detecting micro-blog rumors based on deep features and ensemble classifier. Application Research of Computers, 2016, 33(11): 3369-3373 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyyyj201611037 [13] 张仰森, 郑佳, 唐安杰.基于多特征融合的微博用户权威度定量评价方法.电子学报, 2017, 45(11): 2800-2809 doi: 10.3969/j.issn.0372-2112.2017.11.030Zhang Yang-Sen, Zheng Jia, Tang An-Jie. A quantitative evaluation method of micro-blog user authority based on multi-feature fusion. Acta Electronica Sinica, 2017, 45(11): 2800-2809 doi: 10.3969/j.issn.0372-2112.2017.11.030 [14] 刘雅辉, 靳小龙, 沈华伟, 鲍鹏, 程学旗.社交媒体中的谣言识别研究综述.计算机学报, 2018, 41(7): 1536-1558 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjxb201807007Liu Ya-Hui, Jin Xiao-Long, Shen Hua-Wei, Bao Peng, Cheng Xue-Qi. A survey on rumor identification over social media. Chinese Journal of Computers, 2018, 41(7): 1536-1558 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjxb201807007 [15] Bordia P, Difonzo N, Schulz C A. Source characteristics in denying rumors of organizational closure: Honesty is the best policy. Journal of Applied Social Psychology, 2000, 30(11): 2309-2321 doi: 10.1111/j.1559-1816.2000.tb02438.x [16] Sevastianov P, Dymova L, Bartosiewicz P. A framework for rule-base evidential reasoning in the interval setting applied to diagnosing type 2 diabetes. Expert Systems with Applications, 2012, 39(4): 4190-4200 doi: 10.1016/j.eswa.2011.09.115 [17] Mokhtari K, Ren J, Roberts C, Wang J. Decision support framework for risk management on sea ports and terminals using fuzzy set theory and evidential reasoning approach. Expert Systems with Applications, 2012, 39(5): 5087-5103 doi: 10.1016/j.eswa.2011.11.030 [18] 李文立, 郭凯红. D-S证据理论合成规则及冲突问题.系统工程理论与实践, 2010, 30(8): 1422-1432 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xtgcllysj201008010Li Wen-Li, Guo Kai-Hong. Combination rules of D-S evidence theory and conflict problem. Systems Engineering-Theory & Practice, 2010, 30(8): 1422-1432 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xtgcllysj201008010 [19] 赵秋月, 左万利, 田中生, 王英.一种基于改进D-S证据理论的信任关系强度评估方法研究.计算机学报, 2014, 37(4): 873-883 http://d.wanfangdata.com.cn/periodical/jsjxb201404013Zhao Qiu-Yue, Zuo Wan-Li, Tian Zhong-Sheng, Wang Ying. A method for assessment of trust relationship strength based on the improved D-S evidence theory. Chinese Journal of Computers, 2014, 37(4): 873-883 http://d.wanfangdata.com.cn/periodical/jsjxb201404013 [20] Zhang Q, Zhang S Y, Dong J, Xiong J H, Cheng X Q. Automatic detection of rumor on social network. In: Proceedings of the 4th CCF Conference on Natural Language Processing and Chinese Computing. Nanchang, China: Springer, 2015. 113-122 [21] Chang C C, Lin C J. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): Article No. 27 [22] 陈燕方, 李志宇, 梁循, 齐金山.在线社会网络谣言检测综述.计算机学报, 2018, 41(7): 1648-1676 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjxb201807012Chen Yan-Fang, Li Zhi-Yu, Liang Xun, Qi Jin-Shan. Review on rumor detection of online social networks. Chinese Journal of Computers, 2018, 41(7): 1648-1676 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjxb201807012 -

 下载:
下载:


计量
- 文章访问数: 1590
- HTML全文浏览量: 554
- PDF下载量: 229
- 被引次数: 0
