

-
摘要: 行为识别是计算机视觉领域很重要的一个研究问题,其在安全监控、机器人设计、无人驾驶和智能家庭设计等方面都有着非常重要的应用.基于传统RGB视频的行为识别方法由于容易受背景、光照等行为无关因素的影响,导致识别精度不高.廉价RGB-D摄像头出现之后,人们开始从一个新的途径解决行为识别问题.基于RGB-D摄像头的行为识别通过聚合RGB、深度和骨架三种模态的行为数据,可以融合不同模态的行为信息,从而可以克服传统RGB视频行为识别的缺陷,也因此成为近几年的一个研究热点.本文系统地综述了RGB-D行为识别领域的研究进展和展望.首先,对近年来RGB-D行为识别领域中常用的公共数据集进行简要的介绍;同时也系统地介绍了多模态RGB-D行为识别研究领域的典型模型和最新进展,其中包括卷积神经网络(Convolution neural network,CNN)和循环神经网络(Recurrent neural network,RNN)等深度学习技术在RGB-D行为识别的应用;最后,在三个公共RGB-D行为数据库上对现有方法的优缺点进行了比较和分析,并对未来的相关研究进行了展望.Abstract: Action recognition is an important research topic in computer vision, which is critical in some real-world applications including security monitoring, robot design, self driving and smart home system etc.. The existing single modality RGB based action recognition approaches are easily suffered from the illumination variation, background clutter, which leads to an inferior recognition performance. The emergence of low-cost RGB-D cameras opens a new dimension for addressing the problem of action recognition. It can overcome the drawbacks of single modality by outputting RGB, depth, and skeleton modalities, each of which can describe actions from one perspective. In this paper, we mainly review the current advances in RGB-D action recognition. Firstly, we briefly introduce some datasets popularly used in the research of RGB-D action recognition, then we review the literatures and the state-of-the-art recognition models based on convolution neural network (CNN) and recurrent neural network (RNN). Finally, we discuss the advantages and disadvantages of these methods through the experiments on three datasets and provide some problems needing addressing in the future.
-
Key words:
- RGB-D /
- action recognition /
- skeleton /
- deep learning
1) 本文责任编委 王亮 -
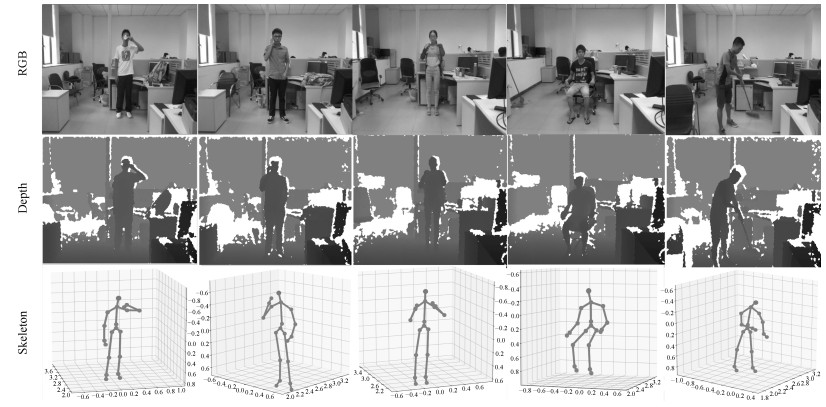
图 1 RGB-D数据样例(图中为SYSU 3DHOI数据库中的部分样本, 从上到下依次为彩色数据(RGB), 深度数据(Depth)和骨架数据(Skeleton), 从左到右的所对应的行为分别为“喝水”、“打电话”、“背包”、“坐下”、“打扫”.从图中可以看到, 每种模态的数据从不同角度刻画行为内容.)
Fig. 1 Some RGB-D samples captured by Kinect (This figure presents some samples from SYSU 3DHOI set. The examples for RGB, depth and skeleton modalities are provided in the first, second, and third rows, respectively. Each column in the figure gives a sample of action "drinking", "calling", "packing", "sitting down", and "sweeping", respectively. As shown, each of the modalities characterizes actions from one perspective.)
表 1 现有RGB-D行为数据库的对比(更完整的数据库介绍请参见文献[17])
Table 1 Comparison of some existing RGB-D action datasets (Please refer to [17] for more details about the datasets)
数据库 数据类型 类别数 个体数 视频数 交互比例 是否公开下载 发表年份 MSRAction[18] Depth 20 10 567 $\leq70 \%$ 全部公开 2010 CAD 60[15] RGB-D 14 4 68 $85.7 \%$ 全部公开 2011 UTKinect[19] RGB-D 10 10 200 $\geq 30 \%$ 全部公开 2012 MSRActionPair[20] RGB-D 6 10 360 100% 全部公开 2013 CAD-120[16] RGB-D 10 4 120 100% 全部公开 2013 MSRDaily[12] RGB-D 16 10 320 $87.5 \%$ 全部公开 2013 Multiview[14] RGB-D 8 8 3 815 $100 \%$ 部分公开 2013 RGBD-HuDaAct[21] RGB-D 12 30 1 189 100% 全部公开 2013 Comp. Activities[22] RGB-D 16 14 693 $75 \%$ 全部公开 2014 ORGBD[23] RGB-D 7 36 386 100% 全部公开 2014 TJU dataset[24] RGB-D 22 20 1 760 $\leq 13.6 \%$ 全部公开 2015 SYSU 3DHOI[1] RGB-D 12 40 480 $100 \%$ 全部公开 2016 NTU[25] RGB-D 60 40 56 880 $100 \%$ 全部公开 2016  下载: 导出CSV
下载: 导出CSV
表 2 在NTU RGB-D数据库上各种方法的识别结果对比(“RGB-D”指同时使用RGB、深度和骨架三种模态数据)
Table 2 Comparison of action recognition accuracies on the NTU RGB-D dataset ("RGB-D" indicates that the approach employs all the RGB, depth, and skeleton modalities for recognition)
方法 数据模态 准确度(%) 个体交叉 视角交叉 HON4D[29] 深度 30.6 7.3 Skeletal quads[50] 骨架 38.6 41.4 Lie group[37] 骨架 50.1 52.8 Hierarchical RNN[39] 骨架 59.1 64.0 Deep RNN[17] 骨架 59.3 64.1 Dynamic skeletons[13] 骨架 60.2 65.2 Deep LSTM[17] 骨架 60.7 67.3 Part-aware LSTM[17] 骨架 62.9 70.3 ST-LSTM[40] 骨架 65.2 76.1 ST-LSTM + Trust gate[40] 骨架 69.2 77.7 STA-LSTM[41] 骨架 73.4 81.2 Deep multimodal[48] RGB-D 74.9 — Multiple stream[51] RGB-D 79.7 81.43 Skeleton and depth[52] 深度+骨架 75.2 83.1 Clips+CNN+MTLN[43] 骨架 79.6 84.8 VA-LSTM[42] 骨架 79.4 87.6 Pose-attention[53] RGB +骨架 82.5 88.6 Deep bilinear[54] RGB-D 85.4 90.7 HCN[45] 骨架 86.5 91.1 DA-Net[55] RGB 88.12 91.96 SR-TSL[56] 骨架 84.8 92.4
下载: 导出CSV
表 3 在MSR数据库上各种方法的识别结果对比
Table 3 Comparison of action recognition accuracies on the MSR daily activity dataset
方法 数据模态 准确度(%) Dynamic temporal warping[57] 骨架 54 3D Joints and LOP Fourier[12] 深度+骨架 78 HON4D[23] 深度 80.00 SSFF[58] RGB-D 81.9 HFM[1, 59] RGB-D 84.38 Deep model (RGGP)[60] RGB-D 85.6 Actionlet ensemble[12] 深度+骨架 85.75 Super normal[19] 深度 86.25 Bilinear[61] 深度 86.88 DCSF + Joint[62] RGB-D 88.2 MPCCA[1, 63] RGB-D 90.62 MTDA[1, 64] RGB-D 90.62 LFF + IFV[65] 骨架 91.1 Group sparsity[33] 骨架 95 JOULE[1] RGB-D 95 Range sample[28] 深度 95.6 Deep multi modal[48] RGB-D 97.5
下载: 导出CSV
表 4 在SYSU 3D HOI数据库上各种方法的识别结果对比(“RGB-D”指同时使用RGB、深度和骨架三种模态数据)
Table 4 Comparison of action recognition accuracies on the SYSU 3D HOI Dataset ("RGB-D" indicates that the approach employs all the RGB, depth, and skeleton modalities for recognition)
下载: 导出CSV
-
[1] Hu J F, Zheng W S, Lai J H, Zhang J G. Jointly learning heterogeneous features for RGB-D activity recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11):2186-2200 doi: 10.1109/TPAMI.2016.2640292 [2] Wang J, Liu Z C, Chorowski J, Chen Z Y, Wu Y. Robust 3D action recognition with random occupancy patterns. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 872-885 [3] 刘智, 董世都.利用深度视频中的关节运动信息研究人体行为识别.计算机应用与软件, 2017, 34(2):189-192, 219 doi: 10.3969/j.issn.1000-386x.2017.02.033Liu Zhi, Dong Shi-Du. Study of human action recognition by using skeleton motion information in depth video. Computer Applications and Software, 2017, 34(2):189-192, 219 doi: 10.3969/j.issn.1000-386x.2017.02.033 [4] 王松涛, 周真, 曲寒冰, 李彬. RGB-D图像的贝叶斯显著性检测.自动化学报, 2017, 43(10):1810-1828 http://www.aas.net.cn/CN/abstract/abstract19157.shtmlWang Song-Tao, Zhou Zhen, Qu Han-Bing, Li Bin. Bayesian saliency detection for RGB-D images. Acta Automatica Sinica, 2017, 43(10):1810-1828 http://www.aas.net.cn/CN/abstract/abstract19157.shtml [5] 王鑫, 沃波海, 管秋.基于流形学习的人体动作识别.中国图象图形学报, 2014, 19(6):914-923 http://d.old.wanfangdata.com.cn/Thesis/D01014489Wang Xin, Wo Bo-Hai, Guan Qiu. Human action recognition based on manifold learning. Chinese Journal of Image and Graphics, 2014, 19(6):914-923 http://d.old.wanfangdata.com.cn/Thesis/D01014489 [6] 刘鑫, 许华荣, 胡占义.基于GPU和Kinect的快速物体重建.自动化学报, 2012, 38(8):1288-1297 http://www.aas.net.cn/CN/abstract/abstract13669.shtmlLiu Xin, Xu Hua-Rong, Hu Zhan-Yi. GPU based fast 3D-object modeling with Kinect. Acta Automatica Sinica, 2012, 38(8):1288-1297 http://www.aas.net.cn/CN/abstract/abstract13669.shtml [7] 王亮, 胡卫明, 谭铁牛.人运动的视觉分析综述.计算机学报, 2002, 25(3):225-237 doi: 10.3321/j.issn:0254-4164.2002.03.001Wang Liang, Hu Wei-Ming, Tan Tie-Niu. A survey of visual analysis of human motion. Chinese Journal of Computers, 2002, 25(3):225-237 doi: 10.3321/j.issn:0254-4164.2002.03.001 [8] Georgia Gkioxari, Ross Girshick, Piotr Dollár, Kaiming He. Detecting and Recognizing Human-Object Interactions. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, 2018. DOI: 10.1109/CVPR.2018.00872 [9] Kläser A, Marszalek M, Schmid C. A spatio-temporal descriptor based on 3D-gradients. In: Proceedings of the 2008 British Machine Vision Conference. Leeds, UK: British Machine Vision Association, 2008. [10] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2):91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [11] Wang X Y, Han T X, Yan S C. An HOG-LBP human detector with partial occlusion handling. In: Proceedings of the 12th International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 32-39 [12] Wang J, Liu Z C, Wu Y, Yuan J S. Learning actionlet ensemble for 3D human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5):914-927 doi: 10.1109/TPAMI.2013.198 [13] Hu J F, Zheng W S, Lai J H, Zhang J G. Jointly learning heterogeneous features for RGB-D activity recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 5344-5352 [14] Wei P, Zhao Y B, Zheng N N, Zhu S C. Modeling 4D human-object interactions for event and object recognition. In: Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Sydney: IEEE, 2013. 3272-3279 [15] Sung J, Ponce C, Selman B, Saxena A. Human activity detection from RGBD images. In: Proceedings of the 16th AAAI Conference on Plan, Activity, and Intent Recognition. San Francisco, USA: AAAI, 2011. 47-55 [16] Koppula H S, Gupta R, Saxena A. Learning human activities and object affordances from RGB-D videos. The International Journal of Robotics Research, 2013, 32(8):951-970 doi: 10.1177/0278364913478446 [17] Shahroudy A, Liu J, Ng T T, Wang G. NTU RGB+D: a large scale dataset for 3D human activity analysis. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. [18] Zhu Y, Chen W B, Guo G D. Evaluating spatiotemporal interest point features for depth-based action recognition. Image and Vision Computing, 2014, 32(8):453-464 doi: 10.1016/j.imavis.2014.04.005 [19] Yang X D, Tian Y L. Super normal vector for activity recognition using depth sequences. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 804-811 [20] Zhang J, Li W Q, Ogunbona P O, Wang P C, Tang C. RGB-D-based action recognition datasets:a survey. Pattern Recognition, 2016, 60:86-105 doi: 10.1016/j.patcog.2016.05.019 [21] Li W Q, Zhang Z Y, Liu Z C. Action recognition based on a bag of 3D points. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. San Francisco, USA: IEEE, 2010. 9-14 [22] Xia L, Chen C C, Aggarwal J K. View invariant human action recognition using histograms of 3D joints. In: Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence, USA: IEEE, 2012. 20-27 [23] Oreifej O, Liu Z C. HON4D: histogram of oriented 4D normals for activity recognition from depth sequences. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013. 716-723 [24] Ni B B, Wang G, Moulin P. RGBD-HuDaAct:a color-depth video database for human daily activity recognition. Consumer Depth Cameras for Computer Vision:Research Topics and Applications. London, UK:Springer, 2013. 193-208 [25] Lillo I, Soto A, Niebles J C. Discriminative hierarchical modeling of spatio-temporally composable human activities. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 812-819 [26] Yu G, Liu Z C, Yuan J S. Discriminative orderlet mining for real-time recognition of human-object interaction. In: Proceedings of the 12th Asian Conference on Computer Vision. Singapore: Springer, 2014. 50-65 [27] Liu A A, Nie W Z, Su Y T, Ma L, Hao T, Yang Z X. Coupled hidden conditional random fields for RGB-D human action recognition. Signal Processing, 2015, 112:74-82 doi: 10.1016/j.sigpro.2014.08.038 [28] Lu C W, Jia J Y, Tang C K. Range-sample depth feature for action recognition. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 772-779 [29] Shotton J, Sharp T, Kipman A, Fitzgibbon A, Finocchio M, Blake A, et al. Real-time human pose recognition in parts from single depth images. Communications of the ACM, 2013, 56(1):116-124 [30] Hussein M E, Torki M, Gowayyed M A, El-Saban M. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing, China: AAAI, 2013. 2466-2472 [31] Lv F J, Nevatia R. Recognition and segmentation of 3-D human action using HMM and multi-class AdaBoost. In: Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: Springer, 2006. 359-372 [32] Yang X D, Tian Y L. EigenJoints-based action recognition using naive-Bayes-nearest-neighbor. In: Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 14-19 [33] Luo J J, Wang W, Qi H R. Group sparsity and geometry constrained dictionary learning for action recognition from depth maps. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 1809-1816 [34] Ofli F, Chaudhry R, Kurillo G, et al. Sequence of the most informative joints (SMIJ):a new representation for human skeletal action recognition. Journal of Visual Communication and Image Representation, 2014, 25(1):24-38 doi: 10.1016/j.jvcir.2013.04.007 [35] Zhu Y, Chen W B, Guo G D. Fusing spatiotemporal features and joints for 3D action recognition. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Portland, USA: IEEE, 2013. 486-491 [36] Zanfir M, Leordeanu M, Sminchisescu C. The moving pose: an efficient 3D kinematics descriptor for low-latency action recognition and detection. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 2752-2759 [37] Vemulapalli R, Arrate F, Chellappa R. Human action recognition by representing 3D skeletons as points in a Lie group. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 588-595 [38] Fragkiadaki K, Levine S, Felsen P, Malik J. Recurrent network models for human dynamics. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4346-4354 [39] Du Y, Wang W, Wang L. Hierarchical recurrent neural network for skeleton based action recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 1110-1118 [40] Liu J, Shahroudy A, Xu D, Kot A C, Wang G. Skeleton-based action recognition using spatio-temporal LSTM network with trust gates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12):3007-3021 doi: 10.1109/TPAMI.2017.2771306 [41] Song S J, Lan C L, Xing J L, Zeng W J, Liu J Y. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2017. 4263-4270 [42] Zhang P F, Lan C L, Xing J L, Zeng W J, Xue J R, Zheng N N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2136-2145 [43] Ke Q H, Bennamoun M, An S J, Sohel F, Boussaid F. A new representation of skeleton sequences for 3D action recognition. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 4570-4579 [44] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556, 2014. [45] Li C, Zhong Q Y, Xie D, Pu S L. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv preprint arXiv: 1804.06055, 2018. [46] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770-778 [47] Shahroudy A, Ng T T, Yang Q X, Wang G. Multimodal multipart learning for action recognition in depth videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10):2123-2129 doi: 10.1109/TPAMI.2015.2505295 [48] Shahroudy A, Ng T T, Gong Y H, Wang G. Deep multimodal feature analysis for action recognition in RGB+D videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(5):1045-1058 doi: 10.1109/TPAMI.2017.2691321 [49] Du W B, Wang Y L, Qiao Y. RPAN: an end-to-end recurrent pose-attention network for action recognition in videos. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 3745-3754 [50] Evangelidis G, Singh G, Horaud R. Skeletal quads: human action recognition using joint quadruples. In: Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014. 4513-4518 [51] Garcia N C, Morerio P, Murino V. Modality distillation with multiple stream networks for action recognition. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. [52] Rahmani H, Bennamoun M. Learning action recognition model from depth and skeleton videos. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 5833-5842 [53] Baradel F, Wolf C, Mille J. Human action recognition: pose-based attention draws focus to hands. In: Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). Venice, Italy: IEEE, 2017. [54] Hu J F, Zheng W S, Pan J H, Lai J H, Zhang J G. Deep bilinear learning for RGB-D action recognition. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. [55] Wang D A, Ouyang W L, Li W, Xu D. Dividing and aggregating network for multi-view action recognition. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. [56] Si C Y, Jing Y, Wang W, Wang L, Tan T N. Skeleton-based action recognition with spatial reasoning and temporal stack learning. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. [57] Müller M, Röder T. Motion templates for automatic classification and retrieval of motion capture data. In: Proceedings of the 2006 ACM SIGGRAPH/Eurographics Symposium on Computer Animation. Vienna, Austria: Eurographics Association Aire-la-Ville, 2006. 137-146 [58] Shahroudy A, Wang G, Ng T T. Multi-modal feature fusion for action recognition in RGB-D sequences. In: Proceedings of the 6th International Symposium on Communications, Control and Signal Processing (ISCCSP). Athens, Greece: IEEE, 2014. 1-4 [59] Cao L L, Luo J B, Liang F, Huang T S. Heterogeneous feature machines for visual recognition. In: Proceedings of the 12th International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 1095-1102 [60] Liu L, Shao L. Learning discriminative representations from RGB-D video data. In: Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing, China: AAAI, 2013. 1493-1500 [61] Kong Y, Fu Y. Bilinear heterogeneous information machine for RGB-D action recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 1054-1062 [62] Xia L, Aggarwal J K. Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013. 2834-2841 [63] Cai Z W, Wang L M, Peng X J, Qiao Y. Multi-view super vector for action recognition. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 596-603 [64] Zhang Y, Yeung D Y. Multi-task learning in heterogeneous feature spaces. In: Proceedings of the 25th AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2011. [65] Yu M Y, Liu L, Shao L. Structure-preserving binary representations for RGB-D action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(8):1651-1664 doi: 10.1109/TPAMI.2015.2491925 [66] Gao Y, Beijbom O, Zhang N, Darrell T. Compact bilinear pooling. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 317-326 [67] Hu J F, Zheng W S, Ma L Y, Gang W, Lai J H, Zhang J G. Early action prediction by soft regression. In: Proceedings of the 2018 IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018. 1-1 [68] Hu J F, Zheng W S, Ma L Y, Wang G, Lai J H. Real-time RGB-D activity prediction by soft regression. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 280-296 [69] Barsoum E, Kender J, Liu Z C. HP-GAN: probabilistic 3D human motion prediction via GAN. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Salt Lake City, USA: IEEE, 2018. [70] Liu J, Shahroudy A, Wang G, Duan L Y, Kot A C. SSNet: scale selection network for online 3D action prediction. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. -

 下载:
下载:

计量
- 文章访问数: 5895
- HTML全文浏览量: 2392
- PDF下载量: 2160
- 被引次数: 0
