

Optimal Energy Consumption Trajectory Planning for Mobile Robot Based on Motion Control and Frequency Domain Analysis
-
摘要: 本文针对两轮自平衡可移动机器人, 提出了一种新的能耗最优运动轨迹规划方法.本文将轨迹规划与由轨迹跟踪控制器和机器人动力学方程组成的运动控制模型相结合, 基于期望轨迹与实际电机输入电压间的传递函数和能量在时域和频域上的对应关系, 通过频域分析的方法得到了具有明确机理表达的线性能耗模型, 并采用最小二乘线性回归法对模型参数进行辨识.对于能耗最优轨迹, 由全局路径规划得到的路径点作为局部轨迹规划的局部目标点, 通过一定的数学转换和参数求导, 可直接得到相邻两个局部目标点间的能耗最优运行轨迹和对应的运行时间.通过仿真实验证明了本文所提能耗模型的准确性和所得轨迹的能耗最优性.Abstract: In this paper, a new optimal trajectory planning algorithm to minimize energy consumption for two-wheeled self-balancing motion robot is proposed. The trajectory planning is combined with the motion control model composed of trajectory tracking controller and robot dynamics model, and based on the transfer function between the desired trajectory and actual motor input voltage and the corresponding relationship of energy in time domain and frequency domain, a linear energy consumption model with clear mechanism expression is obtained by frequency-domain analysis and the model parameters are identified by the least square linear regression method. For the optimal trajectory, select the way points obtained by global path planning as the local target points of the local trajectory planning, through a certain mathematical transformations and derivative of parameters, the optimal operational trajectory and operational time of each two target points are determined directly. Through simulation experiments, the accuracy of the proposed energy consumption model and minimum energy consumption of the obtained trajectory are verified.
-
Key words:
- Trajectory planning /
- minimum energy consumption /
- motion robot /
- frequency-domain analysis
1) 本文责任编委 贺威 -
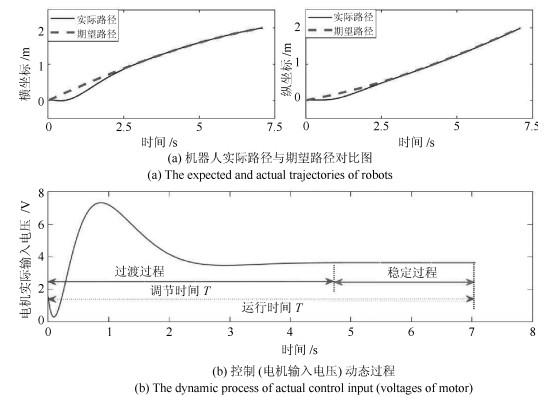
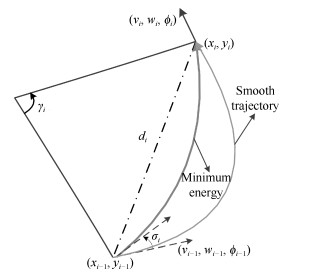
图 1 机器人实际路径与期望路径对比图以及对应的控制器动态过程示意图
Fig. 1 The actual path of the robot is compared with the expected path and the controller dynamic process
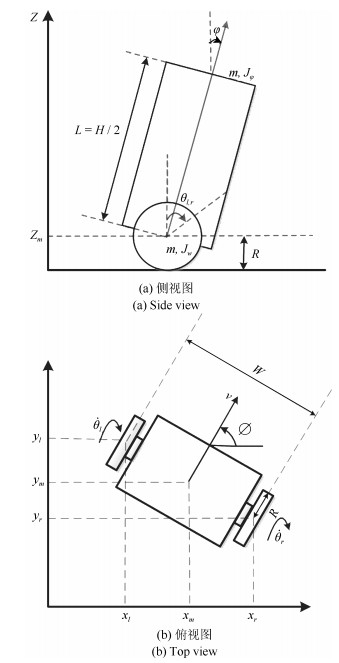
图 2 两轮自平衡小车侧视图与俯视图
Fig. 2 The side view and top view of two-wheel self-balancing robot

图 3 本文采用的轨迹规划和控制系统体系结构
Fig. 3 Architecture of the mobile robot trajectory planning and control system in this paper
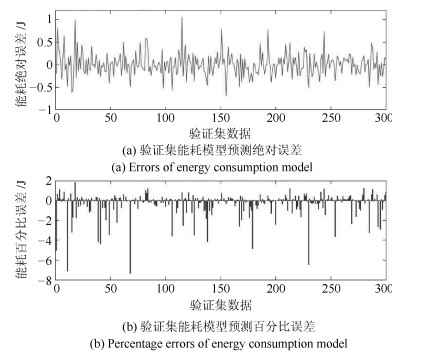
图 5 能耗模型验证集拟合效果误差图
Fig. 5 Modeling errors of energy consumption model in validation set

图 7 能耗最优期望轨迹与实际轨迹对比图
Fig. 7 Comparison diagram of the optimal energy consumption desired trajectory and actual trajectory
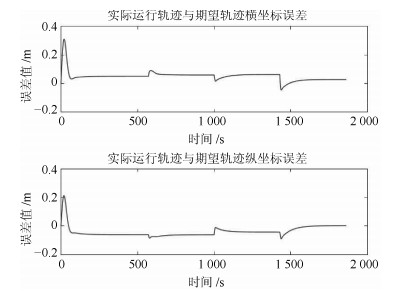
图 8 能耗最优期望轨迹与实际轨迹坐标误差图
Fig. 8 Coordinate error graph of the optimal energy consumption desired trajectory and actual trajectory

图 9 真实能耗与运行时间和轨迹圆心角关系图
Fig. 9 The relational graph of real energy consumption with running time and track circle angle
表 1 两轮自平衡机器人模型参数
Table 1 Two-wheel self-balancing robot model parameters
机器人参数 参数值 $M$ 机器人质量 3.2 (kg) $R$ 车轮半径 0.15 (m) $W$ 车体宽度 0.35 (m) $f_m$ 电机与轮轴摩擦系数 0.0022 $f_w$ 车轮与地面摩擦系数 0.035 $R_m$ 电机内阻 6.69 ($\Omega$) $P_s$ 非机械元件功率 6 (w)  下载: 导出CSV
下载: 导出CSV
表 2 两轮自平衡机器人初始能耗模型参数
Table 2 Initial energy consumption model parameters of two-wheel self-balancing robot
参数 数值 参数 数值 参数 数值 $a1$ 172.2 $a6$ 1.37 $a11$ 4.27 $a2$ 7.57 $a7$ 16.26 $a12$ 1.09 $a3$ 13.2 $a8$ $-$4.39 $a13$ 5.82 $a4$ $-$0.66 $a9$ $-$1.11 $b1$ 20.83 $a5$ $-$0.94 $a10$ 15.97 $b2$ 0.93
下载: 导出CSV
表 3 能耗最优轨迹仿真结果
Table 3 Energy consumption optimal trajectory simulation results
轨迹序列 分段能耗$E_{\rm {total}}$ (J) 运行时间$T$(s) 线速度$v$ (m/s) 角速度$w $(rad/s) 方向角改变$\sigma$ (°) 1 336.97 28.46 0.499 0.011 36.28 2 252.43 21.42 0.523 $-$0.011 $-$20.68 3 256.15 21.38 0.526 0.017 33.06 4 270.15 21.62 0.527 0.03 61
下载: 导出CSV
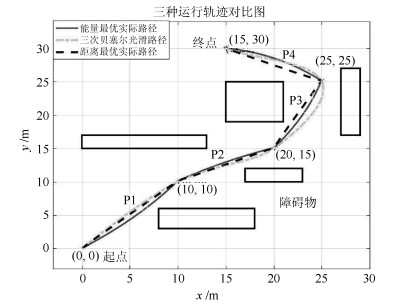
表 4 与其他方法仿真结果比较
Table 4 Compare with other methods simulation results
轨迹序列 能耗最优算法 路径最短策略 三次贝塞尔曲线 1 336.97 338.15 345.5 2 252.43 252.03 265.72 3 256.15 255.89 290.72 4 270.15 283.82 292.3 总能耗(J) 1 115.7 1 129.8 1 203.3 运行时间(s) 92.88 92.88 81.32 能耗比率(%) 100 101.26 107.85
下载: 导出CSV
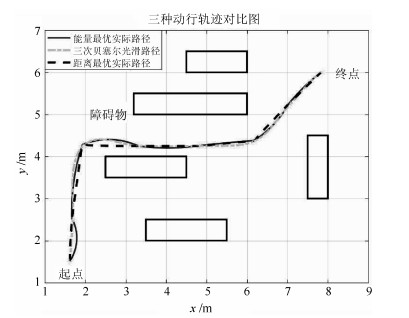
表 5 与其他方法仿真结果比较
Table 5 Compare with other methods simulation results
轨迹序列 能耗最优算法 路径最短策略 三次贝塞尔曲线 1 28.43 30.811 26.03 2 40.56 39.87 52.4 3 33.61 36.36 35.12 4 33.89 33.62 36.12 5 30.91 30.93 32.33 6 28.57 29.02 28.82 7 24.68 24.56 25.28 总能耗(J) 220.64 225.18 236.1 运行时间(s) 18.6 18.6 15.3 能耗比率(%) 100 102.06 107
下载: 导出CSV
-
[1] Mei Y G, Lu Y H, Hu Y C, Lee C S G. Deployment of mobile robots with energy and timing constraints. IEEE Transactions on Robotics, 2006, 22(3): 507-522 https://ieeexplore.ieee.org/document/1638342/ [2] Tokekar P, Karnad N, Isler V. Energy-optimal trajectory planning for car-like robots. Autonomous Robots, 2014, 37(3): 279-300 doi: 10.1007/s10514-014-9390-3 [3] 成伟明.移动机器人自主导航中的路径规划与跟踪控制技术研究[博士学位论文], 南京理工大学, 中国, 2007Cheng Wei-Ming. Research on Some Issues of Path Plan and Tracking Control for Autonomous Ground Vehicle[Ph. D. dissertation], Nanjing University of Science and Technology, China, 2007 [4] Chou C C, Lian F L. Velocity space approach with region analysis and look-ahead verification for robot navigation. In: Proceedings of the 48th IEEE Conference on Decision and Control, the 28th Chinese Control Conference. Shanghai, China: IEEE, 2009. 5971-5976 [5] Fox D, Burgard W, Thrun S. The dynamic window approach to collision avoidance. IEEE Robotics and Automation Magazine, 1997, 4(1): 23-33 doi: 10.1109-100.580977/ [6] Henkel C, Bubeck A, Xu W L. Energy efficient dynamic window approach for local path planning in mobile service robotics. IFAC-PapersOnLine, 2016, 49(15): 32-37 [7] Khatib O. Real-time obstacle avoidance for manipulators and mobile robots. In: Proceedings of the 1985 IEEE International Conference on Robotics and Automation. St. Louis, MO, USA, USA: IEEE, 1985. 500-505 [8] 韩伟, 孙凯彪.基于模糊人工势场法的智能全向车路径规划.计算机工程与应用, 2018, 54(6): 105-109 http://d.old.wanfangdata.com.cn/Periodical/jsjgcyyy201806019Han Wei, Sun Kai-Biao. Research on dynamic path planning of fuzzy artificial potential field method. Computer Engineering and Applications, 2018, 54(6): 105-109 http://d.old.wanfangdata.com.cn/Periodical/jsjgcyyy201806019 [9] 郑慧君, 陈俞强.基于改进蚁群的路径导航算法.控制工程, 2016, 23(4): 608-612 http://d.old.wanfangdata.com.cn/Periodical/jczdh201604030Zheng Hui-Jun, Chen Yu-Qiang. Improved ACO-based path navigation algorithm. Control Engineering of China, 2016, 23(4): 608-612 http://d.old.wanfangdata.com.cn/Periodical/jczdh201604030 [10] Lamini C, Benhlima S, Elbekri A. Genetic algorithm based approach for autonomous mobile robot path planning. Procedia Computer Science, 2018, 127: 180-189 doi: 10.1016/j.procs.2018.01.113 [11] Sahoo B, Parhi D R, Kumar P B. Analysis of path planning of humanoid robots using neural network methods and study of possible use of other AI techniques. Emerging Trends in Engineering, Science and Manufacturing, to be published [12] Duleba I, Sasiadek J Z. Nonholonomic motion planning based on Newton algorithm with energy optimization. IEEE Transactions on Control Systems Technology, 2003, 11(3): 355-363 doi: 10.1109/TCST.2003.810394 [13] Kim C H, Kim B K. Minimum-energy translational trajectory generation for differential-driven wheeled mobile robots. Journal of Intelligent and Robotic Systems, 2007, 49(4): 367-383 doi: 10.1007/s10846-007-9142-0 [14] Mei Y G, Lu Y H, Hu Y C, Lee C S G. Energy-efficient motion planning for mobile robots. In: Proceedings of the 2004 IEEE International Conference on Robotics and Automation. New Orleans, LA, USA: IEEE, 2004. 4344-4349 [15] Elbanhawi M, Simic M, Jazar R N. Continuous path smoothing for car-like robots using B-spline curves. Journal of Intelligent and Robotic Systems, 2015, 80(S1): 23-56 doi: 10.1007/s10846-014-0172-0 [16] 陈灵, 王森, 胡豁生, 麦当劳-麦尔·克劳斯, 费敏锐.保证智能轮椅平滑通过狭窄通道的路径曲率优化算法.自动化学报, 2016, 42(12): 1874-1885 doi: 10.16383/j.aas.2016.c160185Chen Ling, Wang Sen, Hu Huo-Sheng, Mcdonald-Maier K, Fei Min-Rui. Novel path curvature optimization algorithm for intelligent wheelchair to smoothly pass a narrow space. Acta Automatica Sinica, 2016, 42(12): 1874-1885 doi: 10.16383/j.aas.2016.c160185 [17] Liu S, Sun D. Minimizing energy consumption of wheeled mobile robots via optimal motion planning. IEEE/ASME Transactions on Mechatronics, 2014, 19(2): 401-411 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=7c4096c470e2d3336d08f96769acdad7 [18] 卜新萍, 苏虎, 邹伟, 王鹏, 周海.基于非均匀环境建模与三阶Bezier曲线的平滑路径规划.自动化学报, 2017, 43(5): 710-724 doi: 10.16383/j.aas.2017.c160262Bu Xin-Ping, Su Hu, Zou Wei, Wang Peng, Zhou Hai. Smooth path planning based on non-uniformly modeling and cubic Bezier curves. Acta Automatica Sinica, 2017, 43(5): 710-724 doi: 10.16383/j.aas.2017.c160262 [19] Wang Y, Wang S, Tan M, Zhou C, Wei Q P. Real-time dynamic Dubins-Helix method for 3-D trajectory smoothing. IEEE Transactions on Control Systems Technology, 2015, 23(2): 730-736 doi: 10.1109/TCST.2014.2325904 [20] Wang Y, Wang S, Tan M. Path generation of autonomous approach to a moving ship for unmanned vehicles. IEEE Transactions on Industrial Electronics, 2015, 62(9): 5619-5629 doi: 10.1109/TIE.2015.2405904 [21] Yang J, Qu Z H, Wang J, Conrad K. Comparison of optimal solutions to real-time path planning for a mobile vehicle. IEEE Transactions on Systems, Man, and Cybernetics, Part A: Systems and Humans, 2010, 40(4): 721-731 doi: 10.1109/TSMCA.2010.2044038 [22] Kim H, Kim B K. Minimum-energy translational trajectory planning for battery-powered three-wheeled omni-directional mobile robots. In: Proceedings of the 10th International Conference on Control, Automation, Robotics and Vision. Hanoi, Vietnam: IEEE, 2008. 1730-1735 [23] 王建辉, 顾树生.自动控制原理.北京:清华大学出版社, 2007.Wang Jian-Hui, Gu Shu-Sheng. Principles of Automatic Control. Beijing: Tsinghua University Press, 2007. [24] Ljung L.系统辨识:使用者的理论.北京:清华大学出版社, 2002.Ljung L. System Identification: User Theory. Beijing: Tsinghua University Press, 2002. [25] Hart P E, Nilsson N J, Raphael B. A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107 doi: 10.1109/TSSC.1968.300136 [26] 高志伟, 代学武.两轮自平衡小车LQR-PID最优平衡和轨迹跟踪控制器设计.第28届中国过程控制会议.重庆, 中国: 中国自动化学会, 2017.Gao Zhi-Wei, Dai Xue-Wu. Design of LQR-PID optimal equilibrium and trajectory tracking controller based on two-wheeled self-balancing robot. In: Proceedings of the 28th Chinese Process Control Conference. Chongqing, China: Chinese Association of Automation, 2017. [27] Trzynadlowski A M. Energy optimization of a certain class of incremental motion DC drives. IEEE Transactions on Industrial Electronics, 1988, 35(1): 60-66 doi: 10.1109/41.3063 [28] Pollard S. On Parseval$'$s theorem. Proceedings of the London Mathematical Society, 1926, s2-25(1): 237-246 doi: 10.1112/plms/s2-25.1.237 -

 下载:
下载:

计量
- 文章访问数: 3040
- HTML全文浏览量: 910
- PDF下载量: 540
- 被引次数: 0
