

Cyber-Physical Cooperative Localization Algorithms for Underwater Vehicle With Asynchronous Time Clock
-
摘要: 在异步时钟下研究了一种基于信息物理融合的水下潜器协同定位问题.首先,构建了由浮标、传感器和潜器组成的水下信息物理融合系统架构.然后,考虑水下异步时钟影响,设计了基于传感器与潜器交互通信的异步定位策略,给出了潜器协同定位问题.为求解上述协同定位问题,分别提出了基于扩展卡尔曼滤波(Extended Kalman filter,EKF)与无迹卡尔曼滤波(Unscented Kalman filter,UKF)的水下潜器协同定位算法.最后,对上述定位算法的有界性以及克拉美罗下界(Cramér-Rao lower bound,CRLB)进行了分析.仿真结果表明,上述算法可有效消除异步时钟对水下定位的影响.同时基于无迹卡尔曼滤波的定位算法可提高定位精度.Abstract: With consideration of asynchronous time clock, this paper studies a cyber-physical cooperative localization problem for underwater vehicle. We firstly construct an architecture of underwater cyber-physical system, including buoys, sensors and vehicle. Then, considering the influence of asynchronous time clock, we design an asynchronous localization strategy which is based on the cooperation communication between sensors and vehicle, and we formulize the cooperative localization problem for underwater vehicle. In order to solve this cooperative localization problem, the extended Kalman filter (EKF) and unscented Kalman filter (UKF) based cooperative localization algorithms are proposed, respectively. Finally, we give the boundedness and Cramér-Rao lower bound (CRLB) for these algorithms. Simulation results show that the proposed algorithms can effectively eliminate the influence of asynchronous time clock on underwater localization. Meanwhile, the UKF-based localization algorithm can improve the localization accuracy.
-
Key words:
- Localization /
- underwater vehicle /
- cyber physical systems /
- asynchronous /
- underwater sensor networks
1) 本文责任编委 孟凡利 -
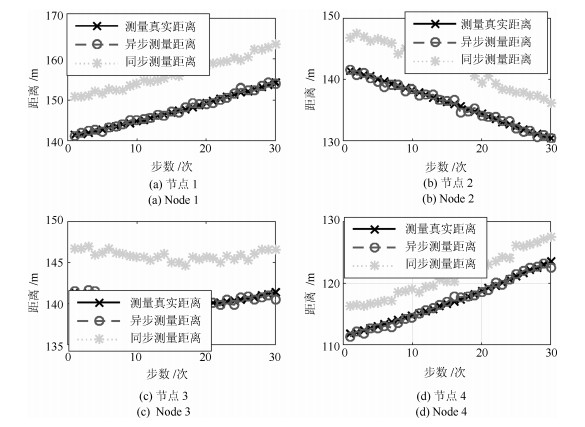
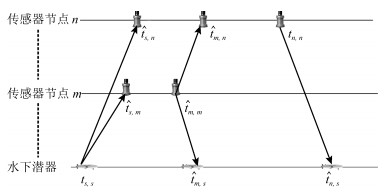
图 3 同步测量与异步测量距离比较
Fig. 3 Distance comparison with synchronous and asynchronous measurements

图 4 同步测量与异步测量距离误差比较
Fig. 4 Distance error comparison with synchronous and asynchronous measurements

图 5 穷举法、扩展卡尔曼和无迹卡尔曼定位轨迹
Fig. 5 Trajectories with exhaustive, EKF-based and UKF-based methods
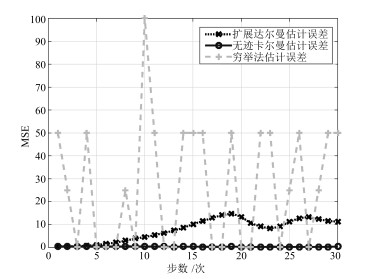
图 6 穷举法、扩展卡尔曼与无迹卡尔曼MSE比较
Fig. 6 Comparison of MSE for exhaustive, EKF and UKF based methods

图 7 扩展卡尔曼与无迹卡尔曼MSE与CRLB比较
Fig. 7 Comparison of MSE and CRLB for UKF and EKF-based methods
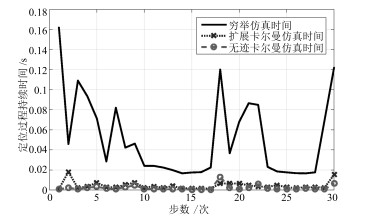
图 8 算法仿真定位用时比较
Fig. 8 Localized trajectories of underwater vehicle different interference intensities
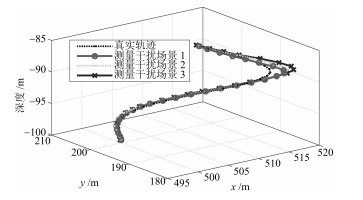
图 9 不同干扰强度下潜器定位轨迹
Fig. 9 Positioning trajectories of submersible under different interference intensities

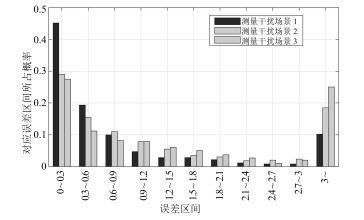
图 10 不同干扰强度下潜器定位误差
Fig. 10 Positioning errors of underwater vehicle under different interference intensities
-
[1] Han G J, Xu H H, Duong T Q, Jiang J F, Hara T. Localization algorithms of wireless sensor networks:a survey. Telecommunication Systems, 2013, 52(4):2419-2436 doi: 10.1007/s11235-011-9564-7 [2] 丁文东, 徐德, 刘希龙, 张大朋, 陈天.移动机器人视觉里程计综述.自动化学报, 2018, 44(3):385-400 http://www.aas.net.cn/CN/abstract/abstract19233.shtmlDing Wen-Dong, Xu De, Liu Xi-Long, Zhang Da-Peng, Chen Tian. Review on visual odometry for mobile robots. Acta Automatica Sinica, 2018, 44(3):385-400 http://www.aas.net.cn/CN/abstract/abstract19233.shtml [3] He J P, Cheng P, Chen J M, Shi L, Lu R X. Time synchronization for random mobile sensor networks. IEEE Transactions on Vehicular Technology, 2014, 63(8):3935-3946 doi: 10.1109/TVT.2014.2307076 [4] Wang Y, Ho K C. Unified near-field and far-field localization for AOA and hybrid AOA-TDOA positionings. IEEE Transactions on Wireless Communications, 2018, 17(2):1242-1254 doi: 10.1109/TWC.2017.2777457 [5] Xu S, Doǧançay K. Optimal sensor placement for 3-D angle-of-arrival target localization. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(3):1196-1211 doi: 10.1109/TAES.2017.2667999 [6] Wang J, Zhang X, Gao Q H, Ma X R, Feng X Y, Wang H Y. Device-free simultaneous wireless localization and activity recognition with wavelet feature. IEEE Transactions on Vehicular Technology, 2017, 66(2):1659-1669 doi: 10.1109/TVT.2016.2555986 [7] Liu J, Wang Z H, Peng Z, Cui J H, Fiondella L. Suave: swarm underwater autonomous vehicle localization. In: Proceedings of the 2014 IEEE INFOCOM-IEEE Conference on Computer Communications. Toronto, ON, Canada: IEEE, 2014. 64-72 [8] Zhou Z, Peng Z, Cui J H, Shi Z J, Bagtzoglou A. Scalable localization with mobility prediction for underwater sensor networks. IEEE Transactions on Mobile Computing, 2011, 10(3):335-348 doi: 10.1109/TMC.2010.158 [9] Luo H J, Wu K S, Gong Y J, Ni L M. Localization for drifting restricted floating ocean sensor networks. IEEE Transactions on Vehicular Technology, 2016, 65(12):9968-9981 doi: 10.1109/TVT.2016.2530145 [10] 贺华成, 王磊, 金鑫, 徐胜文.半潜平台锚泊辅助动力定位时域模拟研究.海洋工程, 2016, 34(5):117-124 http://d.old.wanfangdata.com.cn/Periodical/hygc201605014He Hua-Cheng, Wang Lei, Jin Xin, Xu Sheng-Wen. Research on time-domain simulations of mooring-assisted dynamic positioning system for a semi-submersible platform. The Ocean Engineering, 2016, 34(5):117-124 http://d.old.wanfangdata.com.cn/Periodical/hygc201605014 [11] Yan J, Xu Z Q, Wan Y, Chen C L, Luo X Y. Consensus estimation-based target localization in underwater acoustic sensor networks. International Journal of Robust and Nonlinear Control, 2017, 27(9):1607-1627 [12] Yan J, Xu Z Q, Luo X Y, Chen C L, Guan X P. Feedback-based target localization in underwater sensor networks:a multi-sensor fusion approach. IEEE Transactions on Signal and Information Processing over Networks, 2019, 5(1):168-180 doi: 10.1109/TSIPN.2018.2866335 [13] 徐博, 白金磊, 郝燕玲, 高伟, 刘亚龙.多AUV协同导航问题的研究现状与进展.自动化学报, 2015, 41(3):445-461 http://www.aas.net.cn/CN/abstract/abstract18624.shtmlXu Bo, Bai Jin-Lei, Hao Yan-Ling, Gao Wei, Liu Ya-Long. The research status and progress of cooperative navigation for multiple AUVs. Acta Automatica Sinica, 2015, 41(3):445-461 http://www.aas.net.cn/CN/abstract/abstract18624.shtml [14] Yan J, Yang X, Luo X Y, Chen C L. Energy-Efficient data collection over AUV-Assisted underwater acoustic sensor network. IEEE Systems Journal, 2018, 12(4):3519-3530 doi: 10.1109/JSYST.2017.2789283 [15] Carroll P, Mahmood K, Zhou S L, Zhou H, Xu X K, Cui J H. On-demand asynchronous localization for underwater sensor networks. IEEE Transactions on Signal Processing, 2014, 62(13):3337-3348 doi: 10.1109/TSP.2014.2326996 [16] Liu J, Wang Z H, Cui J H, Zhou S L, Yang B. A Joint Time synchronization and localization design for mobile underwater sensor networks. IEEE Transactions on Mobile Computing, 2016, 15(3):530-543 doi: 10.1109/TMC.2015.2410777 [17] Mortazavi E, Javidan R, Dehghani M J, Kavoosi V. A robust method for underwater wireless sensor joint localization and synchronization. Ocean Engineering, 2017, 137:276-286 doi: 10.1016/j.oceaneng.2017.04.006 [18] Zhang B B, Wang H Y, Zheng L M, Wu J F, Zhuang Z W. Joint synchronization and localization for underwater sensor networks considering stratification effect. IEEE Access, 2017, 5:26932-26943 doi: 10.1109/ACCESS.2017.2778425 [19] Yan J, Zhang X N, Luo X Y, Wang Y X, Chen C L, Guan X P. Asynchronous localization with mobility prediction for underwater acoustic sensor networks. IEEE Transactions on Vehicular Technology, 2018, 67(3):2543-2556 doi: 10.1109/TVT.2017.2764265 [20] Caccia M, Veruggio G. Guidance and control of a reconfigurable unmanned underwater vehicle. Control Engineering Practice, 2000, 8(1):21-37 doi: 10.1016/S0967-0661(99)00125-2 [21] Julier S J, Uhlmann J K. New extension of the Kalman filter to nonlinear systems. In: Proceedings of the 1997 SPIE 3068, Signal Processing, Sensor Fusion, and Target Recognition VI. Orlando, FL, USA: SPIE, 1997. [22] Julier S, Uhlmann J, Durrant-Whyte H. A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Transactions on Automatic Control, 2000, 45(3):477-482 doi: 10.1109/9.847726 [23] Xiong K, Zhang H Y, Chan C W. Performance evaluation of UKF-based nonlinear filtering. Automatica, 2006, 42(2):261-270 doi: 10.1016/j.automatica.2005.10.004 [24] Lefebvre T, Bruyninckx H, De Schuller J. Comment on "A new method for the nonlinear transformation of means and covariances in filters and estimators"[with authors0 reply]. IEEE Transactions on Automatic Control, 2002, 47(8):1406-1409 doi: 10.1109/TAC.2002.800742 [25] Reif K, Gunther S, Yaz E, Unbehauen R. Stochastic stability of the discrete-time extended Kalman filter. IEEE Transactions on Automatic Control, 1999, 44(4):714-728 doi: 10.1109/9.754809 [26] Li W Y, Wei G L, Han F, Liu Y R. Weighted average consensus-based unscented Kalman filtering. IEEE Transactions on Cybernetics, 2016, 46(2):558-567 doi: 10.1109/TCYB.2015.2409373 -

 下载:
下载:


计量
- 文章访问数: 2770
- HTML全文浏览量: 333
- PDF下载量: 513
- 被引次数: 0
