

-
摘要: 视频场景复杂多变, 视频采集设备不一致等原因, 导致无约束视频中充斥着大量的遮挡和人脸旋转, 视频人脸识别方法的准确率不高且性能不稳定.为解决上述问题, 本文提出了一种基于QPSO优化的流形学习的视频人脸识别算法.该算法将视频人脸识别视为图像集相似度度量问题, 首先帧图像对齐后提取纹理特征并进行融合, 再利用带有QPSO优化的黎曼流形大幅度简约维度以获得视频人脸的内在表示, 相似度则由凸包距离表示, 最后利用SVM分类器获得分类结果.通过在Youtube Face数据库和Honda/UCSD数据库上与当前主流算法进行的对比实验, 验证了本文算法的有效性, 所提算法识别精度较高, 误差较低, 并且对光照和表情变化具有较强的鲁棒性.Abstract: The highly complex video scene and the inconsistent video acquisition equipment have made the unconstrained videos full of occlusion and face rotation, thereby, resulting in both low accuracy and unstable performance of video face recognition. To solve the problem, we propose a novel method by integrating the quantum behaved particle swarm optimization (QPSO) and the Riemannian manifold learning. It outperforms the existing state-of-art methods owing to the followed contributions: 1) the algorithm treats each face video as an image set, so that the texture features can be extracted from the aligned frame image; 2) the internal representation of video face is obtained by the QPSO Riemannian manifold, enabling the similarity measurement using the distance between convex hulls; 3) the classification is conducted using the common-practiced SVM classifier, to some extent, guaranteeing the good prediction performance. The experiments on both the YouTube Face database and the Honda/UCSD database have shown that the proposed algorithm is not only of higher accuracy, but also more robust to the illumination and expression changes, as compared to the other methods.
-
Key words:
- Video-based face recognition /
- quantum-behaved particle swarm optimization /
- Riemannian manifold learning /
- video similarity
1) 本文责任编委 左旺孟 -
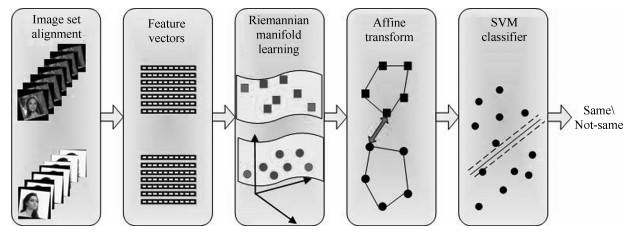
图 1 基于QPSO优化黎曼流形的视频人脸识别算法框架
Fig. 1 The framework of proposed video face recognition algorithm based on manifold learning
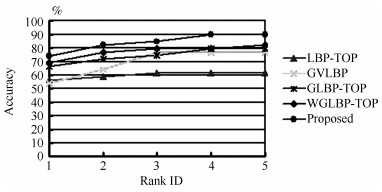
图 4 不同算法在Honda/UCSD上的CMC曲线
Fig. 4 The CMC curves of different algorithms on Honda/UCSD database
表 1 不同纹理描述算子在YouTube Face数据库上的识别率(%)
Table 1 Recognition rate of different texture description operators on YouTube Face database (%)
LBP CSLBP LBP CSLBP Method Acc±SE AUC EER Acc±SE AUC EER Acc±SE AUC EER Acc±SE AUC EER min dist 65.7±1.6 70.66 35.20 63.08±1.0 67.29 37.36 65.60±1.7 70.01 35.64 66.04±2.24 71.21 34.88 max dist 57.90±1.7 61.06 42.64 56.46±2.2 58.80 43.76 55.70±2.4 58.10 45.32 57.44±2.21 59.91 43.20 mean dist 63.72±2.2 68.34 36.84 61.10±2.1 64.86 39.52 62.86±1.4 66.98 38.20 63.88±2.18 67.88 37.20 median dist 63.46±2.0 68.16 36.80 60.84±2.1 64.81 39.44 62.70±1.5 66.81 38.36 63.50±2.33 67.70 37.52 mean min 65.12±1.7 69.99 35.84 62.62±1.5 66.48 38.28 65.48±1.8 69.22 36.56 65.48±2.15 70.04 35.96  下载: 导出CSV
下载: 导出CSV
表 2 不同算法在YouTube Face数据库上的识别率(%)
Table 2 Recognition rate of different algorithm on YouTube Face database (%)
With Logmap With MDS Method Acc±SE AUC EER Acc±SE AUC EER min dist 49.60±0.9 51.24 48.56 51.22±1.4 49.39 50.40 max dist 50.00±0.2 50.71 49.96 50.20±2.0 50.74 49.56 mean dist 50.16±0.6 50.64 49.48 49.64±1.2 50.09 50.68 median dist 50.06±0.6 50.60 49.64 49.18±1.2 50.03 50.60 mean min 50.18±0.7 50.43 49.48 50.16±0.7 49.55 50.68
下载: 导出CSV
表 3 黎曼流形在YouTube Face数据库上的识别率(%)
Table 3 Recognition rate of manifold learning on YouTube Face database (%)
With Logmap Without Logmap Method Acc±SE AUC EER Acc±SE AUC EER min dist 49.60±0.9 51.24 48.56 66.04±2.2 71.21 34.88 max dist 50.00±0.2 50.71 49.96 57.44±2.2 59.91 43.20 mean dist 50.16±0.6 50.64 49.48 63.88±2.1 67.88 37.20 median dist 50.06±0.6 50.60 49.64 63.50±2.3 67.70 37.52 mean min 50.18±0.7 50.43 49.48 65.48±2.1 70.04 35.96
下载: 导出CSV
表 4 不同算法在YouTube Face视频人脸数据库上的实验结果(%)
Table 4 Recognition rate of different algorithms on YouTube Face database (%)
CSLBP FPLBP LBP Fusion Method AUC EER AUC EER AUC EER AUC EER min dist 67.29 37.36 70.01 35.64 70.66 35.2 71.21 34.88 max dist 58.8 43.76 58.1 45.32 61.06 42.64 59.91 43.2 mean dist 64.86 39.52 66.98 38.2 68.34 36.84 67.88 37.2 median dist 64.81 39.44 66.81 38.36 68.16 36.8 67.70 37.52 most frontal 63.61 40.36 64.24 40.04 66.5 38.72 66.23 38.4 nearest pose 63.24 40.32 64.35 40.2 66.87 37.88 66.29 38 MSM 64.64 40.04 63.85 40.24 66.19 38.28 66.33 38.28 CMSM 65.17 39.76 68.35 37.16 67.26 38.36 69.81 36.04 $\left \|U_1^{\rm T}U_2\right \|$ 67.68 37.4 69.37 35.8 69.78 35.96 70.64 35.32 Linear AHISD 60.06 42.32 60.14 42.28 64.55 39.24 64.71 39.28 Kernel CHISD 66.65 38.6 67.01 38.56 68.89 37.2 68.35 37.4 Proposed 67.52 30.55 74.21 29.55 79.43 28.34 77.35 32.02
下载: 导出CSV
表 5 不同算法在Honda/UCSD视频人脸数据库上的首选识别率
Table 5 Recognition rate of different algorithms on Honda/UCSD database
Algorithm Accuracy (%) ${GVLBP}_{1,4,1}+{1NN}$ 53.8 ${LBP}$-${TOP}_{4,4,4,1,1,1} + {1NN}$ 53.8 ${LBP}$-${TOP}_{8,8,8,1,1,1} + {1NN}$ 56.4 ${GLBP}$-${TOP}_{8,8,8,1,1,1} + {1NN}$ 66.7 ${GLBP}$-${TOP}_{8,8,8,1,1,1} + {1NN}$ 69.2 The proposed 74.4
下载: 导出CSV
-
[1] Jeremiah R B, Kevin W B, Patrick J F, Soma B. Face recognition from video: a review. International Journal of Pattern Recognition and Artificial Intelligence, 2012, 26(5): 1266002-1-1266002-53 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0211234766/ [2] Wolf L, Hassner T, Maoz I. Face recognition in unconstrained videos with matched background similarity. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO, USA: IEEE, 2011. 529-534 [3] 于谦, 高阳, 霍静, 庄韫恺.视频人脸识别中判别性联合多流形分析.软件学报, 2015, 26(11): 2897-2911 http://d.old.wanfangdata.com.cn/Periodical/rjxb201511013Yu Qian, Gao Yang, Huo Jing, Zhuang Yun-Kai. Discriminative joint multi-manifold analysis for video-based face recognition. Journal of Software, 2015, 26(11): 2897-2911 http://d.old.wanfangdata.com.cn/Periodical/rjxb201511013 [4] Wang W, Wang R P, Huang Z W, Chen X L. Discriminant analysis on Riemannian manifold of Gaussian distributions for face recognition with image sets. IEEE Transactions on Image Processing, 2018, 21(1): 151-163 [5] 於俊, 汪增福.一种鲁棒高精度的人脸三维运动跟踪算法.计算机研究与发展, 2014, 51(4): 802-812 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201404011Yu Jun, Wang Zeng-Fu. A robust and high accurate 3D facial motion tracking algorithm. Journal of Computer Research and Development, 2014, 51(4): 802-812 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201404011 [6] Wong K M, Zhang J K, Liang J P, Jiang H Y. Mean and median of PSD matrices on a riemannian manifold: application to detection of narrow-band sonar signals. IEEE Transactions on Signal Processing, 2017, 65(24): 6536-6550 doi: 10.1109/TSP.2017.2760288 [7] Zhao G Y, Ahonen T, Matas J, Pietikainen M. Rotation-invariant image and video description with local binary pattern features. IEEE Transactions on Image Processing, 2012, 21(4): 1465-1477 doi: 10.1109/TIP.2011.2175739 [8] Heikkila M, Pietikainen M, Schmid C. Description of interest regions with local binary patterns. Pattern Recognition, 2009, 42(3): 425-436 doi: 10.1016/j.patcog.2008.08.014 [9] Wolf L, Hassner T, Taigman Y. Descriptor Based Methods in the Wild. In: Proceedings of the 2008 European Conference on Computer Vision. Marseille, 2008. 121-128 [10] Lin T, Zha H B. Riemannian manifold learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(5): 796-809 doi: 10.1109/TPAMI.2007.70735 [11] Sanin A, Sanderson C, Harandi M T, Lovell B C. Spatio-temporal covariance descriptors for action and gesture recognition. In: Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. Clearwater Beach, FL, USA: IEEE, 2013. 103-110 [12] Cabello S, Chambers E W, Erickson J. Multiple source shortest paths in embedded graphs. SIAM Journal on Computing, 2012, 42(4): 1542-1571 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1202.0314 [13] Ueno G, Yasuda K, Iwasaki N. Robust adaptive particle swarm optimization. In: Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics. Waikoloa, HI, USA: IEEE, 2005. 3915-3920 [14] Zhang C M, Xie Y C, Liu D, Wang L. Fast threshold image segmentation based on 2D fuzzy Fisher and random local optimized QPSO. IEEE Transactions on Image Processing, 2017, 26(3): 1355-1362 doi: 10.1109/TIP.2016.2621670 [15] Peng C, Yan J, Duan S K, Zhang S L. Enhancing electronic nose performance based on a novel QPSO-KELM model. Sensors, 2016, 16(4): 520 doi: 10.3390/s16040520 [16] Cevikalp H, Triggs B. Large margin classiflers based on convex class models. In: Proceedings of the 2009 International Conference on Computer Vision. Kyoto, Japan, 2009. 101-108 [17] Tang Z j, Huang Z Q, Zhang X Q, Lao H. Robust image hashing with multidimensional scaling. Signal Processing, 2017, 137(C): 240-250 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=7bf321b76a8474b12a97b9e902156bef [18] Cevikalp H, Triggs B. Face recognition based on imagesets. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 2567-2573 [19] Zhao G Y, Pietikainen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 915-928 doi: 10.1109/TPAMI.2007.1110 [20] Wang Y, Shen X J, Chen H P, Zhai Y J. Dynamic biometric identification from multiple views using the GLBP-TOP method. Bio-Medical Materials and Engineering, 2014, 24(6): 2715-2724 doi: 10.3233/BME-141089 -

 下载:
下载:

计量
- 文章访问数: 1856
- HTML全文浏览量: 598
- PDF下载量: 301
- 被引次数: 0
