

An Algorithm of Semantic Similarity Between Words Based on Word Single-meaning Embedding Model
-
摘要: 针对基于词向量的词语语义相似度计算方法在多义词、非邻域词和同义词三类情况计算准确性差的问题, 提出了一种基于词义向量模型的词语语义相似度算法.与现有词向量模型不同, 在词义向量模型中多义词按不同词义被分成多个单义词, 每个向量分别与词语的一个词义唯一对应.我们首先借助同义词词林中先验的词义分类信息, 对语料库中不同上下文的多义词进行词义消歧; 然后基于词义消歧后的文本训练词义向量模型, 实现了现有词向量模型无法完成的精确词义表达; 最后对两个比较词进行词义分解和同义词扩展, 并基于词义向量模型和同义词词林综合计算词语之间的语义相似度.实验结果表明本文算法能够显著提升以上三类情况的语义相似度计算精度.Abstract: We propose a novel algorithm of semantic similarity between words, based on our word single-meaning embedding model, to address the issue of existing word-embedding-based approaches that have low computation accuracy in polysemous words, nonadjacent words and synonyms. Differently from the existing word embedding models, each polysemous word is decomposed into a series of monosemous words in our model, and there is a one-to-one correspondence between a word meaning and a vector. First of all, the word sense disambiguation (WSD) of polysemous words in different contexts of the corpus is achieved with the help of the prior classification information contained in Tongyici Cilin. Then, the word single-meaning embeddings are learned from the processed corpus and realize the precise expression for each word meaning, and as far as we know, no existing word embedding model could complete this task. At last, two test words are decomposed into marked monosemous words according to the number of meaning and expanded with synonyms, and then semantic relatedness between words is computed based on the word single-meaning embedding model and Tongyici Cilin. The experimental results showed our method can significantly improve the computation accuracy of polysemous words, nonadjacent words and synonyms.
-
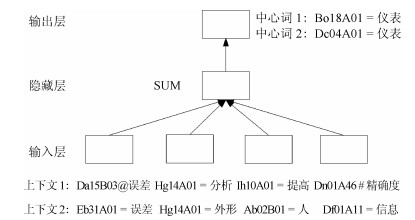
图 2 训练词义向量的神经网络结构
Fig. 2 The architecture of neural network to learn word single-meaning embeddings
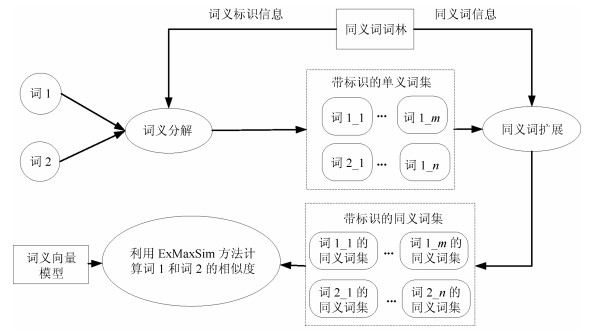
图 3 基于词义向量的词语语义相似度计算过程
Fig. 3 The computing process of similarity between words based on word single-meaning embedding model
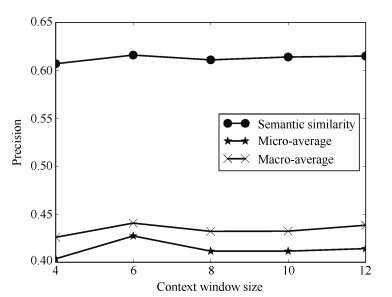
图 4 词义消歧精度和语义相似度精度与上下文窗口的关系
Fig. 4 The precisions of WSD and semantic similarity at different context window sizes
表 1 同义词词林的编码格式
Table 1 The coding format of the Tongyici Cilin
位数 1 2 3 4 5 6 7 8 符号 D a 1 5 B 0 2 = \ # \@ 性质 大类 中类 小类 词群 原子词群 层级 第1层 第2层 第3层 第4层 第5层  下载: 导出CSV
下载: 导出CSV
表 2 CBOW词向量模型中与"仪表"最相似的10个词
Table 2 Top 10 most similar words to the polyseme in the CBOW word embedding model
仪表 相似度 压力表 0.671 控制系统 0.666 电子设备 0.655 控制技术 0.650 电子式 0.647 液压 0.641 主动式 0.639 飞控 0.638 机械式 0.637 仪表板 0.635
下载: 导出CSV
表 3 词义向量模型中与"仪表"两个词义最相似的10个词
Table 3 Top 10 most similar words to the different meanings of the polyseme in WSME
Dc04A01 =仪表 相似度 Bo18A01 =仪表 相似度 风流倜傥 0.700 控制系统 0.697 De04B02 =才情 0.679 电子设备 0.684 Ee31A01 =儒雅 0.669 电子系统 0.674 貌美 0.667 Bo18A16#压力表 0.662 De04A04 =才思 0.663 转速表 0.653 Ee31A01 =雍容 0.662 Bo25B01 =方向盘 0.652 Ee10B01 =旷达 0.659 Bo18A17#高度计 0.652 Eb30B01 =其貌不扬 0.659 Fa05B03 =液压 0.650 Dk02B02#才学 0.653 Dc01C16#机械式 0.644 De04A02 =天资 0.647 仪表板 0.643
下载: 导出CSV
表 4 词义消歧精度对比
Table 4 Evaluation results of WSD
比较算法 $P_{mir} $ (%) $P_{mar} $ (%) 基于HowNet义原向量的方法[23] 36.35 40.19 本文算法 42.74 44.08
下载: 导出CSV
表 5 WSME与Emb + TC方法的对比
Table 5 The comparison result of WSME and Emb + TC
比较算法 wordsim-240 wordsim-297 CBOW 51.47 62.72 Emb + TC ($k = 0.3$) 30.87 45.69 Emb + TC ($k = 0.5$) 33.04 47.57 Emb + TC ($k = 0.7$) 39.18 53.34 WSME 61.45 64.09
下载: 导出CSV
表 7 wordsim-401数据集上的Spearman系数对比
Table 7 The Spearman correlation evaluated on wordsim-401
比较算法 polysemous-wordsim-401 Guo等[20] 55.4 WSME 56.9
下载: 导出CSV
表 8 多义词语义相似度计算结果
Table 8 The semantic-similarity result of polysemous words
词1 词2 人的评分 CBOW FastText WSME 自然 人 0.661 0.104 0.168 0.443 书 图书馆 0.772 0.253 0.409 0.425 钱 金融 0.775 0.080 0.022 0.362
下载: 导出CSV
表 9 非邻域词语义相似度计算结果
Table 9 The semantic-similarity result of nonadjacent words
词1 词2 人的评分 CBOW FastText WSME 旅行 宾馆 0.800 0.003 0.096 0.226 医生 责任 0.882 0.057 0.142 0.160 医院 基础设施 0.528 0.036 0.053 0.129
下载: 导出CSV
表 10 同义词相似度计算结果
词1 词2 CBOW FastText WSME 西红柿 番茄 0.473 0.697 1.000 西红柿 黄瓜 0.508 0.682 0.568 番茄 黄瓜 0.436 0.530 0.568
下载: 导出CSV
-
[1] 李文清, 孙新, 张常有, 冯烨.一种本体概念的语义相似度计算方法.自动化学报, 2012, 38(2): 229-235 doi: 10.3724/SP.J.1004.2012.00229Li Wen-Qing, Sun Xin, Zhang Chang-You, Feng Ye. A semantic similarity measure between ontological concepts. Acta Automatica Sinica, 2012, 38(2): 229-235 doi: 10.3724/SP.J.1004.2012.00229 [2] Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space[Online], available: https://arxiv.org/abs/1301.3781, September 7, 2013 [3] Mikolov T, Sutskever I, Chen K, Corrado G, Dean J. Distributed representations of words and phrases and their compositionality. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2013. 3111-3119 [4] Banu A, Fatima S S, Khan K U R. A new ontology-based semantic similarity measure for concept's subsumed by multiple super concepts. International Journal of Web Applications, 2014, 6(1): 14-22 http://www.zentralblatt-math.org/ioport/en/?q=an%3A11259130 [5] Meng L L, Gu J Z, Zhou Z L. A new model of information content based on concept's topology for measuring semantic similarity in WordNet. International Journal of Grid and Distributed Computing, 2012, 5(3): 81-94 http://www.researchgate.net/publication/313393650_A_new_model_of_information_content_based_on_concept's_topology_for_measuring_semantic_similarity_in_WordNet [6] Seddiqui M H, Aono M. Metric of intrinsic information content for measuring semantic similarity in an ontology. In: Proceedings of the 7th Asia-Pacific Conference on Conceptual Modelling. Brisbane, Australia: Australian Computer Society, Inc., 2010. 89-96 [7] Sánchez D, Batet M, Isern D. Ontology-based information content computation. Knowledge-Based Systems, 2011, 24(2): 297-303 doi: 10.1016/j.knosys.2010.10.001 [8] Sánchez D, Batet M, Isern D, Valls A. Ontology-based semantic similarity: A new feature-based approach. Expert Systems with Applications, 2012, 39(8): 7718-7728 http://cn.bing.com/academic/profile?id=472c6e95b9ca6007ac7cbc7cbcd3436c&encoded=0&v=paper_preview&mkt=zh-cn [9] Zadeh P D H, Reformat M Z. Feature-based similarity assessment in ontology using fuzzy set theory. In: Proceedings of the 2012 IEEE International Conference on Fuzzy Systems. Brisbane, Australia: IEEE, 2012. 1-7 [10] Li M, Lang B, Wang J M. Compound concept semantic similarity calculation based on ontology and concept constitution features. In: Proceedings of the 27th International Conference on Tools with Artificial Intelligence (ICTAI). Vietri sul Mare, Italy: IEEE, 2015. 226-233 [11] Gao J B, Zhang B W, Chen X H. A WordNet-based semantic similarity measurement combining edge-counting and information content theory. Engineering Applications of Artificial Intelligence, 2015, 39: 80-88 doi: 10.1016/j.engappai.2014.11.009 [12] 田久乐, 赵蔚.基于同义词词林的词语相似度计算方法.吉林大学学报(信息科学版), 2010, 28(6): 602-608 doi: 10.3969/j.issn.1671-5896.2010.06.011Tian Jiu-Le, Zhao Wei. Words similarity algorithm based on Tongyici Cilin in semantic web adaptive learning system. Journal of Jilin University (Information Science Edition), 2010, 28(6): 602-608 doi: 10.3969/j.issn.1671-5896.2010.06.011 [13] Pennington J, Socher R, Mannin C D. GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014. 1532-1542 [14] Socher R, Bauer J, Manning C D, Ng A Y. Parsing with compositional vector grammars. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013. 455-465 [15] Chen X X, Xu L, Liu Z Y, Sun M S, Luan H B. Joint learning of character and word embeddings. In: Proceedings of the 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AIAA, 2015. 1236-1242 [16] Bojanowski P, Grave E, Joulin A, Mikolov T. Enriching word vectors with subword information[Online], available: https://arxiv.org/abs/1607.04606, June 19, 2017 [17] Joulin A, Grave E, Bojanowski P, Mikolov T. Bag of tricks for efficient text classification[Online], available: https://arxiv.org/abs/1607.01759, August 9, 2016 [18] Niu Y L, Xie R B, Liu Z Y, Sun M S. Improved word representation learning with sememes. In: Proceeding of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017. 2049-2058 [19] Huang E H, Socher R, Manning C D, Ng A Y. Improving word representations via global context and multiple word prototypes. In: Proceeding of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju Island, Korea: Association for Computational Linguistics, 2012. 873-882 [20] Guo J, Che W X, Wang H F, Liu T. Learning sense-specific word embeddings by exploiting bilingual resources. In: Proceedings of the 25th International Conference on Computational Linguistics: Technical Papers. Dublin, Ireland: COLING, 2014. 497-507 [21] 鹿文鹏, 黄河燕, 吴昊.基于领域知识的图模型词义消歧方法.自动化学报, 2014, 40(12): 2836-2850 doi: 10.3724/SP.J.1004.2014.02836Lu Wen-Peng, Huang He-Yan, Wu Hao. Word sense disambiguation with graph model based on domain knowledge. Acta Automatica Sinica, 2014, 40(12): 2836-2850 doi: 10.3724/SP.J.1004.2014.02836 [22] Chen X X, Liu Z Y, Sun M S. A unified model for word sense representation and disambiguation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014. 1025-1035 [23] 唐共波, 于东, 荀恩东.基于知网义原词向量表示的无监督词义消歧方法.中文信息学报, 2015, 29(6): 23-29 doi: 10.3969/j.issn.1003-0077.2015.06.004Tang Gong-Bo, Yu Dong, Xun En-Dong. An unsupervised word sense disambiguation method based on sememe vector in HowNet. Journal of Chinese Information Processing, 2015, 29(6): 23-29 doi: 10.3969/j.issn.1003-0077.2015.06.004 -

 下载:
下载:

计量
- 文章访问数: 1849
- HTML全文浏览量: 416
- PDF下载量: 239
- 被引次数: 0
