

Retinal Vessel Segmentation Based on Conditional Deep Convolutional Generative Adversarial Networks
-
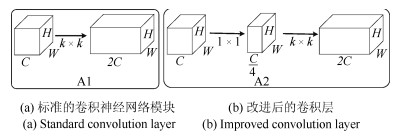
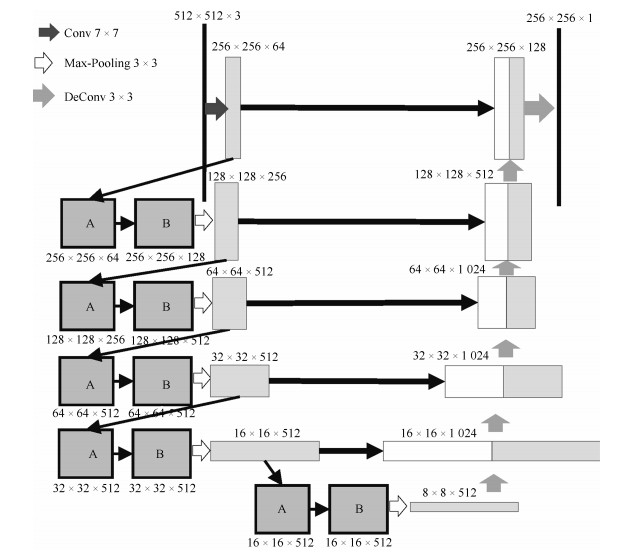
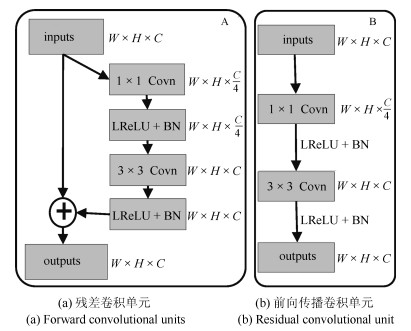
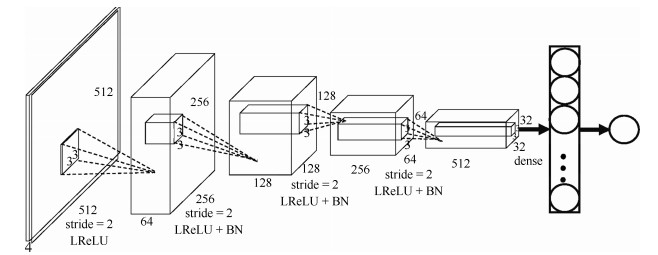
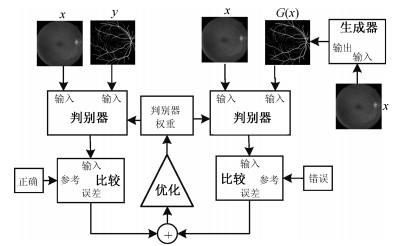
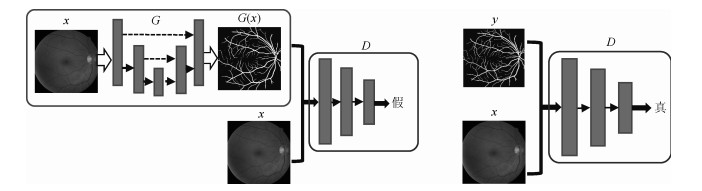
摘要: 视网膜血管的分割帮助医生对眼底疾病进行诊断有着重要的意义.但现有方法对视网膜血管的分割存在着各种问题, 例如对血管分割不足, 抗噪声干扰能力弱, 对病灶敏感等.针对现有血管分割方法的缺陷, 本文提出使用条件深度卷积生成对抗网络的方法对视网膜血管进行分割.我们主要对生成器的网络结构进行了改进,在卷积层引入残差模块进行差值学习使得网络结构对输出的改变变得敏感, 从而更好地对生成器的权重进行调整.为了降低参数数目和计算, 在使用大卷积核之前使用小卷积核对输入特征图的通道数进行减半处理.通过使用U型网络的思想将卷积层的输出与反卷积层的输出进行连接从而避免低级信息共享.通过在DRIVE和STARE数据集上对本文的方法进行了验证, 其分割准确率分别为96.08 %、97.71 %, 灵敏性分别达到了82.74 %、85.34 %, $F$度量分别达到了82.08 %和85.02 %, 灵敏度比R2U-Net的灵敏度分别高了4.82 %, 2.4 %.Abstract: The segmentation of retinal vessels is of significance for doctors to diagnose the fundus diseases. However, existing methods have various problems in the segmentation of the retinal vessels, such as insufficient segmentation of retinal vessels, weak anti-noise interference ability, and sensitivity to lesions, etc. Aiming to the shortcomings of existed methods, this paper proposes the use of conditional deep convolutional generative adversarial networks to segment the retinal vessels. We mainly improve the network structure of the generator. The introduction of the residual module at the convolutional layer for residual learning makes the network structure sensitive to changes in the output, as to better adjust the weight of the generator. In order to reduce the number of parameters and calculations, using a small convolution kernel to halve the number of channels in the input signature before using a large convolution kernel. By used the idea of a U-net to connect the output of the convolutional layer with the output of the deconvolution layer to avoid low-level information sharing. By verifying the method on the DRIVE and STARE datasets, the segmentation accuracy rate is 96.08 % and 97.71 %, the sensitivity reaches 82.74 % and 85.34 %, respectively, and the $F$-measure reaches 82.08 % and 85.02 %, respectively. The sensitivity is 4.82 % and 2.4 % higher than that of R2U-Net.
-
Key words:
- Generative adversarial network (GAN) /
- residual networks /
- retinal vessel segmentation /
- conditional models /
- convolutional neural networks (CNNs)
1) 本文责任编委 黄庆明 -
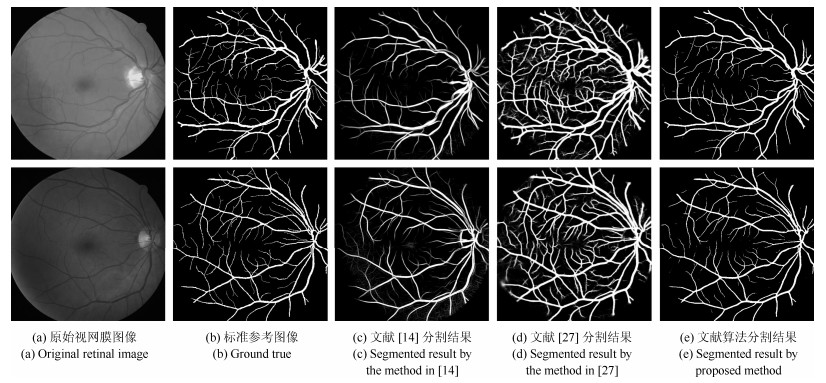
图 10 DRIVE数据库视网膜血管分割结果比较
Fig. 10 Comparisons of segmentation results on DRIVE database
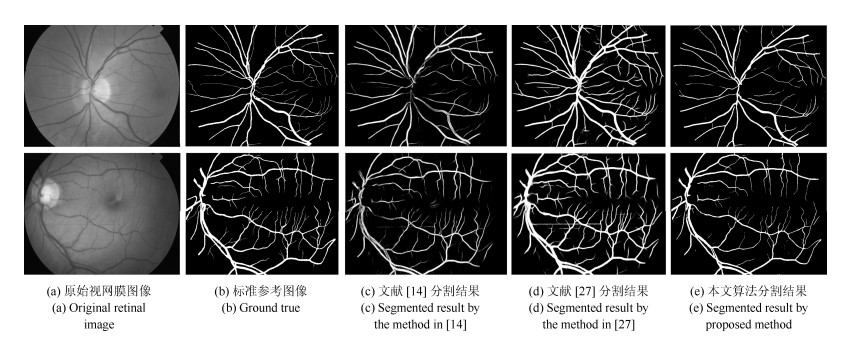
图 11 STARE数据库视网膜血管分割结果比较
Fig. 11 Comparisons of segmentation results on STARE database
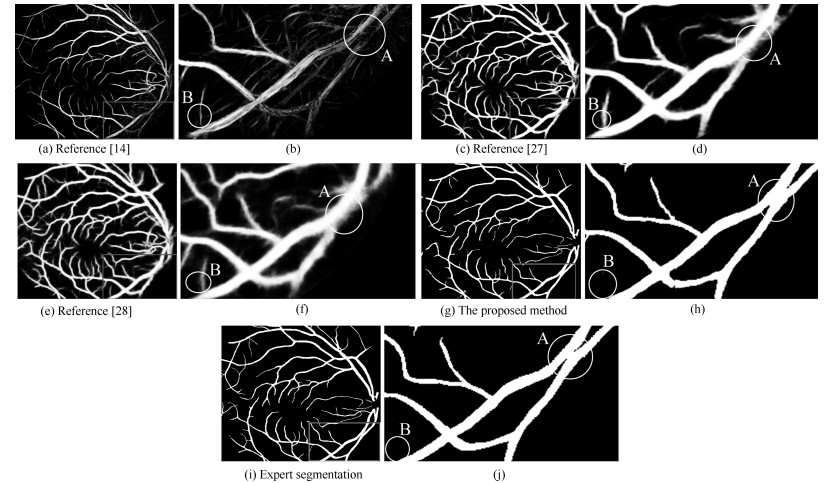
图 12 不同算法的视网膜血管分割局部放大图
Fig. 12 Different methods of partial retinal vessel segmentation

图 13 不同算法的$F$度量性能评价曲线
Fig. 13 Different methods of $F$-measure performance evaluation curve
表 1 模型改进前后分割的结果
Table 1 The segmentation results before and after model improvement
数据集 方法 $F$度量 准确率 DRIVE/STARE U-net 0.8142/0.8373 0.9531/0.9690 GAN+U-net 0.8150/0.8398 0.9583/0.9710 U-net+Residual 0.8149/0.8388 0.9553/0.9700 GAN+U-net+Residual (本文结构) 0.8208/0.8506 0.9608/0.9771  下载: 导出CSV
下载: 导出CSV
表 2 使用瓶颈层前后分割的结果
Table 2 The result of segmentation before and after using the bottleneck layer
数据集 方法 参数 计算量$(GFLOPS)$ $F$度量 准确率 DRIVE/STARE No Bottleneck 19.8 M 183.8 0.8210/0.8504 0.9612/0.9772 Bottleneck 5.2 M 48.5 0.8208/0.8502 0.9608/0.9771
下载: 导出CSV
表 3 DRIVE数据库视网膜血管分割结果
Table 3 Segmentation performance of retinal vessel on the DRIVE database
数据集 方法 年份 $F$度量 灵敏性 特效性 准确率 DRIVE Chen[13] 2014 – 0.7252 0.9798 0.9474 N$^4$-Fields[30] 2014 0.7970 0.8437 0.9743 0.9626 Azzopardi[5] 2015 – 0.7655 0.9704 0.9442 Roychowdhury[12] 2016 – 0.7250 0.9830 0.9520 Liskowsk[14] 2016 – 0.7763 0.9768 0.9495 Qiaoliang Li[12] 2016 – 0.7569 0.9816 0.9527 DRIU[27] 2016 0.6701 0.9696 0.9115 0.9165 HED[28] 2017 0.6400 0.9563 0.9007 0.9054 U-Net[33] 2018 0.8142 0.7537 0.9820 0.9531 Residual U-Net[33] 2018 0.8149 0.7726 0.9820 0.9553 Recurrent U-Net[33] 2018 0.8155 0.7751 0.9816 0.9556 R2U-Net[33] 2018 0.8171 0.7792 0.9813 0.9556 本文方法 2018 0.8208 0.8274 0.9775 0.9608
下载: 导出CSV
表 4 STARE数据库视网膜血管分割结果
Table 4 Segmentation performance of retinal vessel on the STARE database
数据集 方法 年份 $F$度量 灵敏性 特效性 准确率 STARE Marin[31] 2011 – 0.6940 0.9770 0.9520 Fraz[32] 2012 – 0.7548 0.9763 0.9534 Liskowsk[14] 2016 – 0.7867 0.9754 0.9566 Roychowdhury[12] 2016 – 0.7720 0.9730 0.9510 Qiaoliang Li[12] 2016 – 0.7726 0.9844 0.9628 DRIU[27] 2016 0.7385 0.6066 0.9956 0.9499 HED[28] 2017 0.6990 0.5555 0.9955 0.9378 U-Net[33] 2018 0.8373 0.8270 0.9842 0.9690 Residual U-Net[33] 2018 0.8388 0.8203 0.9856 0.9700 Recurrent U-Net[33] 2018 0.8396 0.8108 0.9871 0.9706 R2U-Net[33] 2018 0.8475 0.8298 0.9862 0.9712 本文方法 2018 0.8502 0.8538 0.9878 0.9771
下载: 导出CSV
-
[1] Zhang B, Zhang L, Zhang L, Karray F. Retinal vessel extraction by matched filter with first-order derivative of Gaussian. Computers in Biology and Medicine, 2010, 40(4): 438-445 doi: 10.1016/j.compbiomed.2010.02.008 [2] Jiang X Y, Mojon D. Adaptive local thresholding by verification-based multithreshold probing with application to vessel detection in retinal images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(1): 131-137 doi: 10.1109/TPAMI.2003.1159954 [3] Zana F, Klein J C. Segmentation of vessel-like patterns using mathematical morphology and curvature evaluation. IEEE Transactions on Image Processing, 2001, 10(7): 1010-1019 doi: 10.1109/83.931095 [4] Mehrotra A, Tripathi S, Singh K K, Khandelwal P. Blood vessel extraction for retinal images using morphological operator and KCN clustering. In: Proceedings of the 2014 IEEE International Advance Computing Conference. Gurgaon, India: IEEE, 2014. 1142-1146 [5] Azzopardi G, Strisciuglio N, Vento M, Petkov N. Trainable COSFIRE filters for vessel delineation with application to retinal images. Medical Image Analysis, 2015, 19(1): 46-57 doi: 10.1016/j.media.2014.08.002 [6] Wang Y F, Ji G R, Lin P, Trucco E. Retinal vessel segmentation using multiwavelet kernels and multiscale hierarchical decomposition. Pattern Recognition, 2013, 46(8): 2117-2133 doi: 10.1016/j.patcog.2012.12.014 [7] Guo Z L, Lin P, Ji G R, Wang Y F. Retinal vessel segmentation using a finite element based binary level set method. Inverse Problems and Imaging, 2014, 8(2): 459-473 doi: 10.3934/ipi.2014.8.459 [8] Tolias Y A, Panas S M. A fuzzy vessel tracking algorithm for retinal images based on fuzzy clustering. IEEE Transactions on Medical Imaging, 1998, 17(2): 263-273 doi: 10.1109/42.700738 [9] 王晓红, 赵于前, 廖苗, 邹北骥.基于多尺度2D Gabor小波的视网膜血管自动分割.自动化学报, 2015, 41(5): 970-980 doi: 10.16383/j.aas.2015.c140185Wang Xiao-Hong, Zhao Yu-Qian, Liao Miao, Zou Bei-Ji. Automatic segmentation for retinal vessel based on multi-scale 2D Gabor wavelet. Acta Automatica Sinica, 2015, 41(5): 970-980 doi: 10.16383/j.aas.2015.c140185 [10] 梁礼明, 黄朝林, 石霏, 吴健, 江弘九, 陈新建.融合形状先验的水平集眼底图像血管分割.计算机学报, 2018, 41(7): 1678-1692 https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201807013.htmLiang Li-Ming, Huang Chao-Lin, Shi Fei, Wu Jian, Jiang Hong-Jiu, Chen Xin-Jian. Retinal vessel segmentation using level set combined with shape priori. Chinese Journal of Computers, 2018, 41(7): 1678-1692 https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201807013.htm [11] Roychowdhury S, Koozekanani D D, Parhi K K. Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE Journal of Biomedical and Health Informatics, 2015, 19(3): 1118-1128 [12] Li Q L, Feng B W, Xie L P, Liang P, Zhang H S, Wang T F. A cross-modality learning approach for vessel segmentation in retinal images. IEEE Transactions on Medical Imaging, 2016, 35(1): 109-118 doi: 10.1109/TMI.2015.2457891 [13] Cheng E, Du L, Wu Y, Zhu Y J, Megalooikonomou V, Ling H B. Discriminative vessel segmentation in retinal images by fusing context-aware hybrid features. Machine Vision and Applications, 2014, 25(7): 1779-1792 doi: 10.1007/s00138-014-0638-x [14] Liskowski P, Krawiec K. Segmenting retinal blood vessels with deep neural networks. IEEE Transactions on Medical Imaging, 2016, 35(11): 2369-2380 doi: 10.1109/TMI.2016.2546227 [15] Kingma D P, Welling M. Auto-encoding variational Bayes. arXiv: 1312.6114, 2014 [16] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, WardeFarley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [17] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003Wang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3): 321-332 doi: 10.16383/j.aas.2017.y000003 [18] Hu Y P, Gibson E, Lee L L, Xie W D, Barratt D C, Vercauteren T, et al. Freehand ultrasound image simulation with spatially-conditioned generative adversarial networks. In: Proceedings of Molecular Imaging, Reconstruction and Analysis of Moving Body Organs, and Stroke Imaging and Treatment. Québec, Canada: Springer, 2017. 105-115 [19] Kohl S, Bonekamp D, Schlemmer H P, Yaqubi K, Hohenfellner M, Hadaschik B, et al. Adversarial networks for the detection of aggressive prostate cancer. arXiv: 1702.08014, 2017. [20] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv: 1511.06434, 2015. [21] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. arXiv preprint arXiv: 1505.04597v1, 2015. [22] He K M, Sun J. Convolutional neural networks at constrained time cost. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts: IEEE, 2015. 5353-5360 [23] Pathak D, Krähenbühl P, Donahue J, Darrell T, Efros A A. Context encoders: feature learning by inpainting. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, Nevada: IEEE, 2016. 2536-2544 [24] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv: 1502.03167, 2015. [25] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv: 1411.1784, 2014. [26] Staal J, Abrámoff M D, Niemeijer M, Viergever M A, Van Ginneken B. Ridge-based vessel segmentation in color images of the retina. IEEE Transactions on Medical Imaging, 2004, 23(4): 501-509 doi: 10.1109/TMI.2004.825627 [27] Maninis K K, Pont-Tuset J, Arbeláez P, Van Gool L. Deep retinal image understanding. arXiv preprint arXiv: 1609.01103, 2016. [28] Xie S, Tu Z. Holistically-nested edge detection. International Journal of Computer Vision, 2017, 125(1-3): 3-18 doi: 10.1007/s11263-017-1004-z [29] Soares J V B, Leandro J J G, Cesar R M, Jelinek H F, Cree M J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Transactions on Medical Imaging, 2006, 25(9): 1214-1222 doi: 10.1109/TMI.2006.879967 [30] Ganin Y, Lempitsky V. $N.4$-fields: neural network nearest neighbor fields for image transforms. arXiv preprint arXiv: 1406.6558, 2014. [31] Marin D, Aquino A, Gegundez-Arias M E, Bravo J M. A new supervised method for blood vessel segmentation in retinal images by using gray-level and moment invariants-based features. IEEE Transactions on Medical Imaging, 2011, 30(1): 146-158 doi: 10.1109/TMI.2010.2064333 [32] Fraz M M, Remagnino P, Hoppe A, Uyyanonvara B, Rudnicka A R, Owen C G, et al. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Transactions on Biomedical Engineering, 2012, 59(9): 2538-2548 doi: 10.1109/TBME.2012.2205687 [33] Alom M Z, Hasan M, Yakopcic C, Taha T M, Asari V K. Recurrent residual convolutional neural network based on U-Net (R2U-Net) for medical image segmentation. arXiv preprint arXiv: 1802.06955, 2018. -

 下载:
下载:



计量
- 文章访问数: 1660
- HTML全文浏览量: 448
- PDF下载量: 413
- 被引次数: 0
