

Self-tuning Distributed Fusion Estimation for Systems With Unknown Model Parameters and Fading Measurement Rates
-
摘要: 研究了带未知模型参数和衰减观测率多传感器线性离散随机系统的信息融合估计问题.在模型参数和衰减观测率未知的情形下, 应用递推增广最小二乘(Recursive extend least squares, RELS)算法和加权融合估计算法提出了分布式融合未知模型参数辨识器; 应用相关函数对描述衰减观测现象的随机变量的数学期望和方差进行在线辨识.将辨识后的模型参数、数学期望和方差代入到最优分布式融合状态滤波器中, 获得了相应的自校正融合状态滤波算法.应用动态误差系统分析(Dynamic error system analysis, DESA)方法证明了算法的收敛性.仿真例子验证了算法的有效性.Abstract: This paper is concerned with the information fusion estimation problem for multi-sensor linear discrete-time stochastic systems with unknown model parameters and fading measurement rates. When the model parameters and fading measurement rates are unknown, a distributed weighted fusion identifier for the unknown model parameters is presented based on the recursive extend least squares (RELS) algorithm and weighted fusion estimation algorithm. Both the mathematical expectations and variances of random variables which describe the phenomena of fading measurements are identified by using the correlation functions. The corresponding self-tuning distributed fusion state filtering algorithm is obtained by substituting the identified model parameters, the mathematical expectations and variances into the optimal distributed fusion state filter. The convergence of the proposed algorithms is proven by using a dynamic error system analysis (DESA) method. A simulation example shows the effectiveness of the proposed algorithms.
-
Key words:
- Recursive extend least squares (RELS) /
- correlation function /
- unknown model parameter /
- unknown fading measurement rate /
- self-tuning fusion estimation
-
随着科技的不断进步,现代化工业正发生着翻天覆地的变化, 工厂操作的复杂度急剧增加. 与此同时, 操作过程中测量的变量更加具有复杂性、非线性和巨量性, 而这些测量变量的新性质导致了监测平台操作挑战性不断升级[1]. 在化工过程中, 监测系统产生了大量的实测数据, 对这些数据的有效利用来实现实时监控和故障诊断, 为确保生产设备安全、降低维护成本、提高利润率提供了可靠的保证[2]. 因此, 高效的故障诊断技术正在工业生产的发展中扮演着愈来愈重要的角色.
在化工生产过程中, 需要建立监测平台对整个操作过程进行监控, 并利用监测平台得到的数据进行故障诊断, 从而确保化工产业生产设备安全, 降低维护成本, 提高利润率. 化工过程的故障诊断问题可以看作是对故障数据的分类问题, 其中包括故障特征提取技术、模式识别技术以及故障分类技术. 常见的特征提取方法有: 主元分析法[3] (Principal component analysis, PCA)、偏最小二乘法[4] (Partial least squares, PLS)、核熵分析法[5] (Kernel entropy component analysis, KECA)、独立主元法[6] (Independent component analysis, ICA)等. 然而, 在面向化工的实际应用中, 单纯的多元统计分析并没有取得良好的分类效果. 这是由于化工数据具有很强的非线性, 数据类别复杂、数据量大而且故障特征不易区分的特点[7]. 基于以上问题, Mika等[8]将核函数引入Fisher判别分析算法, 得到了一种新的核Fisher判别法. 该方法在面对复杂的化工过程状态数据时, 能有效地解决因非线性造成的分类困难问题, 因此得到了广泛的应用. 随后, 国内外研究者对该算法进行了深入的研究并提出了许多改进措施. 张曦等[9]提出了基于核Fisher子空间特征提取的汽轮发电机组过程监控和故障诊断新方法, 该方法将原始样本数据从低维非线性空间映射到高维线性空间, 再利用线性Fisher判别分析算法提取原始样本数据的最优特征矢量, 实现了对汽轮发动机组的过程监控. 马立玲等[10]采用Euclidean距离对Fisher判别准则中的类间距做加权, 使得样本数据具有较好的投影效果, 然后通过改进K近邻算法[11]和马氏距离[12-13]算法对数据进行分类, 仿真验证结果表明改进后的核Fisher方法有效改善了因类间距较小而造成的投影数据混叠现象.
然而, 已有的改进核Fisher判别分析方法中, 仍存在以下问题: 1)在投影过程中, 类间距差异较大的类别之间出现投影混叠现象; 2)因为类内比较分散, 数据投影后会出现因类内距不够紧凑而出现的重叠现象; 3)在引入高斯径向基核函数(Radial basis function, RBF)时, 选取非最优的核参数会直接导致故障诊断性能的降低[14]. 为解决以上问题, 本文提出了一种基于马氏距离的改进核Fisher故障诊断方法(MKFD), 该方法采用了区间三分迭代法选取核参数, 利用组平均距离取代质心距离降低运算复杂度并通过加权改进类内的距离, 有效改善了投影效果. 最后, 在田纳西伊—斯特曼过程平台上对该方法进行仿真试验验证, 并与传统的核Fisher诊断方法(Kernel fisher discrimination, KFD)、基于质心距离对类间距进行加权处理的核Fisher判别分析(Centroid kernel fisher discriminate, CKFD)和基于Fisher判别分析的全局—局部保持投影算法(Fisher discriminant global-local preserving projection, FDGLPP)进行了对比. 结果表明, 本文提出的方法不仅提高了运算速度, 同时也有效提高了故障诊断的精度, 具有很高的工程应用价值.
1. 核Fisher判别分析
Fisher判别分析是模式识别中一种非常重要的基于数据降维和分类的方法, 是一种有监督的学习算法[15-17]. 传统的KFD算法在故障诊断领域具有广泛的应用, 但是当面对高维非线性数据时, 其故障诊断的性能大大降低[18]. 核函数的引入能够有效地解决这个问题,使其故障诊断的性能大大提升[19]. 核Fisher算法的基本理论可表述为:
设在P维的原始空间中, 样本点有C类, 样本总数为N, 记为
${{X}} \!=\! \{ {{{X_1}}},{{{X_2}}}, \!{{\cdots}} \!,{{{X_C}}}\}$ , 第$i\;(i = 1,2,\cdots,$ $C)\;$ 个类${\omega _i} \;$ 包含${N_i} \;$ 个样本记作${{{X_i}}} = \{ {{x}}_i^1,{{x}}_i^2, \cdots ,$ ${{x}}_i^{{{{N}}_i}}\},$ 其中, 每一个向量表示的都是列向量. 基于核Fisher判别函数先对原始样本数据进行非线性高维映射${{\phi}} :{{x}} \in {{\rm{R}}^P} \to {{\phi}} ({{x}}) \in {{\rm{H}}^P} ,\;$ 在高维特征空间$H$ 中, 第$i$ 类样本映射后的均值记为${{{m}}_i}, \;$ 所有样本点映射后的均值记为${{m}} . \;$ 可得:$${{{m}}_i} = \frac{1}{{{N_i}}}\sum\limits_{j = 1}^{{N_i}} {{{\phi}} ({{x}}_i^j)} $$ (1) $${{m}} = \frac{1}{N}\sum\limits_{i = 1}^C {\sum\limits_{j = 1}^{{N_i}} {{{\phi}} ({{x}}_i^j)} } $$ (2) 在高维特征空间
$H$ 中, 经过非线性变换后的类内离散度${{S}}_W^\phi$ 和类间的离散度${{S}}_B^\phi$ 分别为:$$ \begin{split} &{{S}}_W^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {\sum\limits_{j = 1}^{{N_i}} {({{\phi}} ({{x}}_i^j) - {{{m}}_i})} } {({{\phi}} ({{x}}_i^j) - {{{m}}_i})^{{\rm{T}}}} \\ & {{S}}_B^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {{N_i}({{{m}}_i} - {{m}})} {({{{m}}_i} - {{m}})^{{\rm{T}}}} \\[-15pt] \end{split} $$ (3) 在特征空间
$H$ 中, Fisher判别准则为:$${{J}}({{{w}_\phi} }) = \max \dfrac{{{{{{w}}}}_{{\phi}} ^{\rm{{T}}}{{S}}_B^{{\phi}} {{{w}}_{{\phi}} }}}{{{{{{w}}}}_{{\phi}} ^{{\rm{T}}}{{S}}_W^{{\phi}} {{{w}}_{{\phi}} }}}$$ (4) 式中:
${{{w}}_{{\phi}} }$ 为任一非零列向量. Fisher判别准则就是要通过优化式(4), 找到最优特征矢量. 由核函数的特点可知, 非线性映射会导致式中的${{{w}}_\phi }$ 无法被直接计算. 此时最优判别矢量${{{w}}_{{\phi}} }$ 可由${{\phi}} ({{{x}}_1{{}),\phi}} ({{{x}}_2}), \cdots ,$ ${{\phi}} ({{{x}}_N})$ 进行线性表示, 即:$${{{w}}_\phi } = \sum\limits_{k = 1}^N {{\alpha _k}} {{\phi}} ({{{x}}_k}) = {{\phi \alpha}} $$ (5) 式中,
${{\alpha}} = {\left( {{\alpha _1},{\alpha _2}, \cdots ,{\alpha _N}} \right)^{{\rm{T}}}}$ 为一个列向量.$$\begin{split} {{{{w}^{{\rm{T}}}}_\phi }}{{\phi}} ({{{x}}_i}) =& {{{\alpha}} ^{{\rm{T}}}}{{{\phi}} ^{{\rm{T}}}}{{\phi}} ({{{x}}_i})= \\ & {{{\alpha}} ^{{\rm{T}}}}{({{\phi}} ({{{x}}_1}),{{\phi}} ({{{x}}_2}), \cdots ,{{\phi}} ({{{x}}_N}))^{{\rm{T}}}}{{\phi}} ({{{x}}_i}) = \\ &{{{\alpha}} ^{{\rm{T}}}}{(k({{{x}}_1},{{{x}}_i}), \cdots ,k({{{x}}_N},{{{x}}_i}))^{{\rm{T}}}} =\\ &{{{\alpha}} ^{{\rm{T}}}}{{\varphi}} ({{{}}{{x}}_i}) \\[-10pt] \end{split} $$ (6) 式中,
${{\varphi}} ({{{x}}_i}) = {(k({{{x}}_1},{{{x}}_i}), \cdots ,k({{{x}}_N},{{{x}}_i}))^{{\rm{T}}}}.$ 在高维特征空间
$H$ 中, 训练集样本类均值向量与总体样本均值向量分别投影到${{{w}}_{{\phi}} }$ 上有:$$\begin{split} &{{{{w}^{{\rm{T}}}}_\phi }}{{\phi}} ({{{x}}_i}) = {{{\alpha}} ^{{\rm{T}}}}{{{\phi}} ^{\rm{T}}}\frac{1}{{{N_i}}}\sum\limits_{j = 1}^{{N_i}} {{{\phi }}({{x}}_i^j)} = {{{\alpha}} ^{{\rm{T}}}}{{{\mu}} _i} \\ & {{{{w}^{{\rm{T}}}}_\phi }}{{\phi}} ({{{x}}_0}) = {{{\alpha}} ^{{\rm{T}}}}{{{\phi}} ^{{\rm{T}}}}\frac{1}{N}\sum\limits_{g = 1}^N {{{\phi}} ({{{x}}_g})} = {{{\alpha}} ^{{\rm{T}}}}{{{\mu}} _0} \\[-15pt] \end{split} $$ (7) 式中:
$$ \begin{split} {{{\mu}} _i} =\,& \frac{1}{{{N_i}}}\left(\sum\limits_{j = 1}^{{N_i}} {{{\phi}}^{{\rm{T}}} {{({{{x}}_1})}}{{\phi}} ({{x}}_i^j),} \cdots ,\sum\limits_{j = 1}^{{N_i}} {{{\phi}}^{{\rm{T}}} {{({{{x}}_N})}}{{\phi}} ({{x}}_i^j)} \right) =\\ &\frac{1}{{{N_i}}}\left(\sum\limits_{j = 1}^{{N_i}} {{{k}}({{{x}}_1},{{x}}_i^j)} , \cdots ,\sum\limits_{j = 1}^{{N_i}} {k({{{x}}_N},{{x}}_i^j)} \right) \\[-20pt] \end{split} $$ (8) $$\begin{split} {{{\mu}} _0} =\,& \frac{1}{N}\left(\sum\limits_{g = 1}^N {{{\phi}} ^{{\rm{T}}}{{({{{x}}_1})}}{{\phi}} ({{x}}_g),} \cdots ,\sum\limits_{g = 1}^N {{{\phi}}^{{\rm{T}}} {{({{{x}}_N})}}{{\phi}} ({{x}}_g)} \right) = \\ & \frac{1}{N}\left(\sum\limits_{g = 1}^N {k({{{x}}_1},{{x}}_g)} , \cdots ,\sum\limits_{g = 1}^{{N}} {k({{{x}}_N},{{x}}_g)} \right) \\[-20pt] \end{split} $$ (9) 在高维特征空间
$H$ 中Fisher准则变为:$$J({{ w}_\phi }) = \max \dfrac{{{{w}}_{{\phi}} ^{{\rm{T}}}{{S}}_B^\phi {{{w}}_{{\phi}} }}}{{{{w}}_{{\phi}} ^{{\rm{T}}}{{S}}_W^\phi {{{w}}_{{\phi}} }}} = \max \dfrac{{{{{\alpha}} ^{{\rm{T}}}}{{K}}_B^\phi{{ \alpha}} }}{{{{{\alpha}} ^{{\rm{T}}}}{{K}}_W^\phi {{\alpha}} }}$$ (10) 式中:
${{K}}_W^\phi$ 和${{K}}_B^\phi$ 的表达式为:$$\begin{split} &{{K}}_W^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {\sum\limits_{j = 1}^{{N_i}} {({{\varphi}} ({{{x}}_i^j}) - {{{\mu}} _i})} } {({{\varphi}} ({{{x}}_i^j}) - {{{\mu}} _i})^{{\rm{T}}}} \\ &{{K}}_B^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {{N_i}({{{\mu}} _i} - {{{\mu}} _0})} {({{{\mu}} _i} - {{{\mu}} _0})^{{\rm{T}}}} \end{split} $$ 所以求解核Fisher最佳判别向量
${{{w}}_\phi }$ 的问题就转化为求解式(10)的Fisher判别函数达到最大值时最佳向量${{\alpha}}$ 的问题. 求解${{\alpha}}$ 问题等价于求解广义特征方程:$${{K}}_B^\phi {{\alpha}} = \lambda {{K}}_W^\phi {{\alpha}} $$ (11) 即Fisher判别准则转化为对
${\left( {{{K}}_W^\phi } \right)^{ - 1}}{{K}}_B^\phi$ 的求解特征值和其所对应的特征向量的问题. 为解决非奇异问题, 将式中${{K}}_W^\phi$ 替换为${{K}}_W^\phi + \mu {{I}} ,\;$ 其中$\mu $ 为非常小的数值, 通常设为${10^{ - 7}},\;$ ${{I}}$ 为单位矩阵[20].2. 基于马氏距离改进的核Fisher故障诊断
核Fisher判别法在故障诊断领域应用广泛, 但是在处理大量非线性数据时, 仍存在一些问题. 第一, 不同类之间的类间距存在较大差异, 会存在数据混叠现象; 第二, 类内距离较分散, 数据投影后不紧凑, 会出现类别重叠现象; 第三, MKFD中RBF核参数的快速选取问题. 针对这些问题, 本文提出了MKFD算法.
2.1 改进核Fisher判别分析
在许多情况下, 数据类别类间距存在很大差异性, 传统的类间距离散度的矩阵为:
$${{S}}_B^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {{N_i}({{{m}}_i} -{{ m}})} {({{{m}}_i} - {{m}})^{{\rm{T}}}}$$ (12) 类间距差异的权重仅依据不同数据类别样本数在总体样本数中所占比进行计算, 但在实际应用中,会出现部分数据类别间距较小,另一部分数据类别间距较大的情况,类间距较小的类信息被间距较大的类信息覆盖的情况, 从而降低故障诊断的性能[21]. 为解决上述问题, 可在原先核Fisher判别中, 保证类内离散度不变, 采用Euclidean距离的函数对类间距进行加权, 重新定义映射后的类间离散度[22]. 重新定义的类间离散度如下:
$$ {{S}}_B^\phi = \dfrac{1}{{{N^2}}}\sum\limits_{i = 1}^{C - 1} {\sum\limits_{j = i + 1}^C {{N_i}} {N_j}W({d_{ij}})({{{m}}_i} - {{m}})} {({{{m}}_i} - {{m}})^{{\rm{T}}}} $$ (13) 式中:
${d_{ij}}$ 表示类$i$ 和类$j$ 的类间距离,${{{m}}_i}$ 和${{m}}$ 分别代表类$i$ 和类$j$ 的平均值, 权重函数${{W}}({d_{ij}})$ 为关于${d_{ij}}$ 的一个函数. 式中:$$\begin{split} &{k_{i1,i2}} = \left\langle {{{\phi}} ({{x}}_i^{i1}),{{\phi}} ({{x}}_i^{i2})} \right\rangle \\ &{k_{j1,j2}} = \left\langle {{{\phi}} ({{x}}_j^{j1}),{{\phi}} ({{x}}_j^{j2})} \right\rangle \\ & {k_{i1,j1}} = \left\langle {{{\phi}} ({{x}}_i^{i1}),{{\phi}} ({{x}}_j^{j1})} \right\rangle \\ \end{split} $$ 此时类间距离
${d_{ij}}$ 选取的是质心距离[23]. 然而质心距离并不能充分利用所有样本的信息, 所以该方法并不具有很好的代表性[24]. 如果把核函数的计算个数作为衡量计算复杂度的标准, 则质心距离的计算复杂度为${{\rm{O}}}(N_i^2 + N_j^2 + {N_i}{N_j})$ . 本文采取组平均距离作为类间距离${d_{ij}}$ :$$\begin{split} {d_{ij}} =\,& \left\| {{{{m}}_i} - {{{m}}_j}} \right\| = \\ & \sqrt {\frac{{\displaystyle\sum\limits_{{x_i}\;\in\; {C_i},{x_j} \;\in\; {C_j}} {({{\phi}} ({{{x}}_i}) \!-\! {{\phi}} ({{{x}}_j})){{({{\phi}} ({{{x}}_i}) \!-\! {{\phi }}({{{x}}_j}))}^{{\rm{T}}}}} }}{{{N_i}{N_j}}}} = \\ & \sqrt {\frac{{\displaystyle\sum\limits_{{x_i} \in {C_i}} {{k_{ii}} \!+\! \displaystyle\sum\limits_{{x_j} \in {C_j}} {{k_{jj}}} \!-\! 2\displaystyle\sum\limits_{xi \in {C_i},{x_j} \in {C_j}} {{k_{ij}}} } }}{{{N_i}{N_j}}}} \\[-20pt] \end{split} $$ (14) 其时间复杂度为
$\rm{O}({N_i} + {N_j} + {N_i}{N_j})$ , 对比发现,采用组平均距离作为类间距离可以在保证精度相差不大的情况下大大提高运算效率. 除此之外, 定义$$ \begin{split} a(i) =\,& \frac{{{d^2}}}{{1 + \displaystyle\sum\limits_{j = 1}^{{N_i}} {{d^*_{ij}}} }} \\ {d^*}_{ij} = \,&\sqrt {({{\phi}} ({{{x}}_{i,j}}) - {{{m}}_i}){{({{\phi}} ({{{x}}_{i,j}}) - {{{m}}_i})}^{{\rm{T}}}}} = \\ &\sqrt {({{\phi}} ({{{x}}_{i,j}}) -{{ \phi}} ( {{\overline{{{x}}}_i}} )){{({{\phi}} ({{{x}}_{i,j}}) -{{ \phi}} ( {{\overline{{{x}}}_i}} ))}^{{\rm{T}}}}} \\ \end{split} $$ (15) 重新定义类内离散度矩阵
$${{S}}_W^\phi = \frac{1}{N}\sum\limits_{i = 1}^C {\sum\limits_{j = 1}^{{N_i}} {a(i)({{\phi}} ({{{x}}_i^j}) - {{{m}}_i})} } {{{(\phi}} ({{{x}}_i^j}) - {{{m}}_i})^{{\rm{T}}}}$$ (16) 式中,
${{K}}_W^\phi$ 和${{K}}_B^\phi$ 的表达式变为:$$\left\{ {\begin{split} & {{{K}}_W^\phi = \frac{{\rm{1}}}{N}\displaystyle\sum\limits_{i = 1}^C {\displaystyle\sum\limits_{j = 1}^{{N_i}} {a(i)({{\varphi}} ({{{x}}_i}) - {{{\mu}} _i})} } {{({{\varphi}} ({{{x}}_i}) - {{{\mu}} _i})}^{{\rm{T}}}}} \\ &{{{\varphi}} ({{{x}}_i}) = {{(k({{{x}}_1},{{{x}}_i}), \cdots ,k({{{x}}_N},{{{x}}_i}))}^{{\rm{T}}}}} \\[-12pt] \end{split}} \right.$$ (17) $$\left\{ {\begin{split} &{{{K}}_B^\phi \!=\! \frac{1}{{{N^2}}}\!\sum\limits_{i = 1}^{C - 1} \!{\sum\limits_{j = i + 1}^C {{N_i}} {N_j}W({d_{ij}})({{{\mu}} _i} \!-\! {{{\mu}} _j})} {{({{{\mu}} _i} \!-\! {{{\mu}} _j})}^{{\rm{T}}}}} \\ &{{{{\mu}} _i} \!=\! \frac{1}{{{N_i}}}{{\left(\sum\limits_{j = 1}^{{N_i}} {k({{{x}}_1},{{x}}_k^i)} , \cdots ,\sum\limits_{j = 1}^{{N_i}} {k({{{x}}_N},{{x}}_k^i)} \right)}^{{\rm{T}}}}} \\[-10pt] \end{split}} \right.$$ (18) 权重函数的表达式为
${{W}}({d_{ij}}) = f({d_{ij}}),$ 定义$f(x) = \dfrac{1}{{{x^{{d}}}}}\;(d \in \rm{N})$ , 即表示权重与类间距离成反比; 对于参数$d,\;$ 通常选取3 ~ 10[25]. 求解${{\alpha}}$ 问题等价于求解广义特征方程:$${\left( {{{K}}_W^\phi } \right)^{ - 1}}{{K}}_B^\phi {{\alpha}} = \lambda {{\alpha}} $$ (19) 此时核Fisher判别准则转化为求解
${\left( {{{K}}_W^\phi } \right)^{ - 1}}\!\!{{K}}_B^\phi$ 的特征值和特征向量的问题.2.2 区间三分法确定高斯径向基(RBF)核参数
在改进的核Fisher判别分析方法中, 核函数及核参数的选取至关重要. 经文献[26]验证, RBF核函数具有良好的分类能力. 在本文中, 选择RBF核函数:
$${{k}}({{x}},{{{x}}_i}) = \exp ( - {\frac{{\left\| {{{x}} - {{{x}}_i}} \right\|}}{{2{\sigma ^2}}}^2})$$ (20) 式中, 核参数
$\sigma $ 的取值对KFD性能的优劣起着至关重要的作用. 目前常用的核参数选取方法有: 交叉验证法[27]、经验选择法、梯度下降法[28]和Bayesian法等.张小云等[29]从理论上证明了在支持向量机(SVM)中采用RBF核函数的性质, 当
$\sigma \to 0$ 时, 不管训练样本个数是多少, 如何标类, 高斯核SVM都能把它们正确的分开, 但对测试集样本的分类准确率差, 容易出现“过拟合”现象. 当$\sigma \to \infty $ 时, 高斯核SVM对所有样本从理论上一视同仁, 认为没有学习推广能力. 基于以上结论, 本文对MKFD中RBF的性质同样进行两种理论假设并进行证明.假设1. 在MKFD中, 当
$\sigma \to 0$ 时, 所有的训练样本都能被正确分类. 但此时的MKFD没有学习推广能力.证明. 在MKFD中, RBF核函数为一个
$N \times N$ 的$\rm{Gram}$ 矩阵$$ {{k}} = \left( {\begin{array}{*{20}{c}} {k({{{x}}_1},{{{x}}_1})}&{k({{{x}}_1},{{{x}}_2})}& \cdots &{k({{{x}}_1},{{{x}}_N})} \\ {k({{{x}}_2},{{{x}}_1})}&{k({{{x}}_2},{{{x}}_2})}& \cdots &{k({{{x}}_2},{{{x}}_N})} \\ \vdots & \vdots & \cdots & \vdots \\ {k({{{x}}_N},{{{x}}_1})}&{k({{{x}}_N},{{{x}}_1})}& \cdots &{k({{{x}}_N},{{{x}}_1})} \end{array}} \right) $$ 当
$\sigma \to 0$ 时, RBF核函数为:$$ {{k}}({{{x}}_i},{{{x}}_j}) = \exp \left( - \frac{{{{\left\| {{{{x}}_i} - {{{x}}_j}} \right\|}^2}}}{{2{\sigma ^2}}}\right) \to \left\{ {\begin{array}{*{20}{c}} {1,{{{x}}_i} = {{{x}}_j}} \\ {0,{{{x}}_i} \ne {{{x}}_j}} \end{array}} \right. $$ 此时, 矩阵
${{k}}$ 变成单位矩阵, 在做特征提取时, 将原问题转化了为求解矩阵(19)所对应的特征值和特征向量. 本文依据TE过程数据做了大量的数据实验, 从结果来看, 当$\sigma \to 0$ 时, 矩阵最大特征值所对应的特征向量中各元素基本相等, 则对于N个训练样本, 判别函数作用后所得到的函数值为:$$T_{csj,i}^* = \sum\limits_{i = 1}^N {{\alpha _0}k({{{x}}_i},{{{x}}_j})} = {\alpha _0}$$ 也就是说, 当
$\sigma $ 取一个很小的数时, MKFD可以将所有的训练集样本正确分类, 但是测试集所映射的函数值几乎相等, 使得测试样本的分类准确率很低, 此时RBF核函数无法分类, MKFD没有学习推广的能力. □假设2. 若在MKFD中
$\sigma \to \infty $ , 此时RBF核函数的分类能力为0, 即它将所有的样本点都归为同一类.证明. 在MKFD中, 当
$\sigma \to \infty$ 时,$\exp \left( \dfrac{{{{\left\| {{{{x}}_{csj}} - {{{x}}_i}} \right\|}^2}}}{{2{\sigma ^2}}}\right)\to1,\forall {{{x}}_{csj}},{{{x}}_i},$ 此时对于$q$ 个测试样本${{{x}}_{csj}},$ 得到的高斯核MKFD的判别函数值为:$$ \begin{split} T_{csj}^* =\,& \sum\limits_{i = 1}^q {\alpha _i^*k({{{x}}_{csj}},{{{x}}_i})} =\\ & \sum\limits_{i = 1}^q {\alpha _i^*\exp \left( - \frac{{{{\left\| {{{{x}}_{csj}} - {{{x}}_i}} \right\|}^2}}}{{2{\sigma ^2}}}\right)} = \sum\limits_{i = 1}^q {\alpha _i^*} \end{split} $$ 从上式的形式来看, 高斯核MKFD所得的判别函数为常函数:
$T_{csj}^* = \displaystyle\sum\nolimits_{i = 1}^q {\alpha _i^*}$ , 将所有类型的的样本点都归结为同一类. □由以上证明说明MKFD的分类能力经历由低到高再到低的过程, MKFD的分类准确率函数
$D(\sigma )$ 相当于一个凸函数, 即我们可以近似认为分类准确率函数$D(\sigma )$ 是关于$\sigma $ 的先增后减的凸函数, 变化曲线近似于图1. 当$D(\sigma )$ 为一个连续凸函数时, 可以利用区间三分法迭代, 求取函数的极值问题.综上, MKFD的分类能力会经历由低变高再变低的过程. 基于这种算法分类能力的规律, 受文献[30]启发本文给出区间三分法的基本步骤为:
1)输入样本数据, 设置分类准确率条件, 选取核参数
$\sigma $ 的范围[min, max] ;2)对区间进行迭代, 首先对区间三等分, 并将这四个等分点记为
${X_1},{X_2},{X_3},{X_4}$ , 分别计算四个$\sigma $ 取值所对应的分类准确率;3)如果四个
$\sigma $ 取值所对应的分类准确率中有一个满足预设的分类准确率条件或者分类准确率不再改变, 终止迭代, 否则用(4)进行判断;4)记四个点中每两点间差商函数
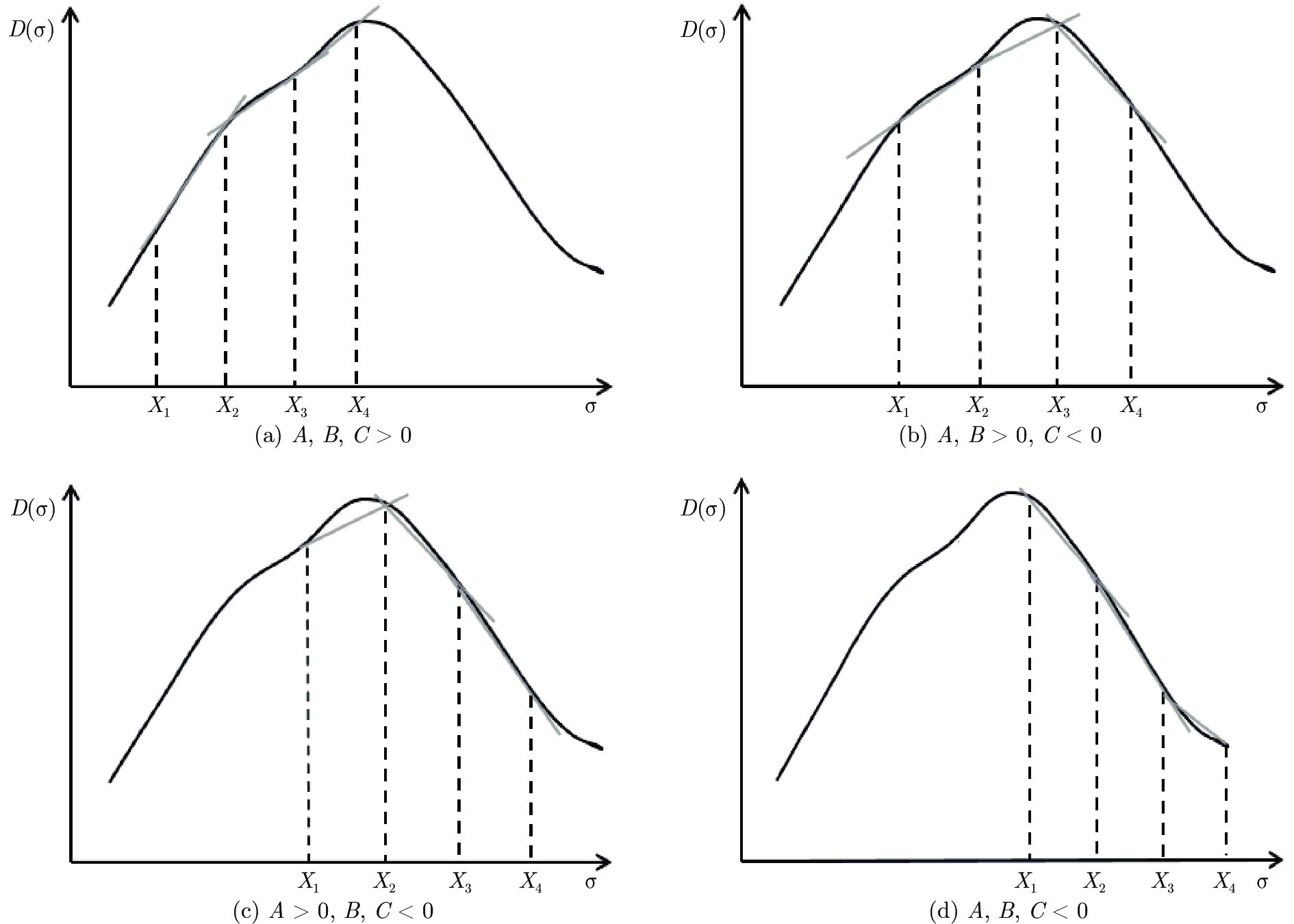
$A,B,C,$ 则$A = $ $ D'({\xi _1}),B = D'({\xi _2}),C = D'({\xi _3}),$ 其中${\xi _1} < {\xi _2} < {\xi _3}.$ 分析A, B, C的符号, 如图2有以下四种;5) a)
$A,B,C > 0,$ 如图2(a)所示, 极值点必定在区间$[{X_2},{X_4}]$ 之间, 返回步骤1). b)$A,B > 0,C < 0,$ 如图2(b)所示, 由零点存在性定理可知极值点必定在区间$[{X_2},{X_4}]$ 之间, 再返回步骤1). c)$A > 0, $ $B,C < 0,$ 如图2(c)所示, 由零点存在性定理可知极值点必定在区间$[{X_1},{X_3}]$ 内, 再返回步骤1), d)$A,B,C < 0,$ 如图2(d)所示, 极值点必定在区间$[{X_1},{X_3}]$ 之间, 返回步骤(1);6)按步骤进行, 直到满足条件, 终止迭代, 得到最优
$\sigma .$ 2.3 基于MKFD的故障诊断算法具体步骤
1)将样本数据分为训练集和测试集. 对数据进行归一化处理, 预处理后的训练集和测试集用
${{{X}}_{xlj}}$ 和${{{X}}_{csj}}$ 表示;2)采用区间迭代法确定RBF核参数, 求出训练集和测试集所对应的核函数集
${{{\varepsilon}} _{xlj}}$ 和${{{\varepsilon}} _{csj}};$ 3)基于MKFD算法, 求得训练集数据核类内离散度矩阵
${{K}}_W^\phi$ 及核类间离散度矩阵${{K}}_B^\phi;$ 4)求解广义特征方程
${{K}}_B^\phi {{\alpha}} = \lambda {{K}}_W^\phi {{\alpha}},$ 对得到方程对应的特征值和特征向量${{\alpha}} _{opt}^*;$ 5)将
${{{\varepsilon}} _{xlj}}$ 和${{{\varepsilon}} _{csj}}$ 两类核数据集向所求得的最优判别向量${{\alpha}} _{opt}^*$ 方向投影, 得到两类数据集最优的核Fisher特征向量${{{{V}}}}_{xlj}^*$ 和${{V}}_{csj}^*;$ 6)计算最优的核Fisher特征向量之间的马氏距离
$D = \left\| {{{V}}_{xlj}^* - {{V}}_{csj}^*} \right\|;$ 7)验证故障类别.
3. 故障诊断试验验证
TE过程[31]是一个基于真实化工生产过程的模型. 它的数据在许多领域被广泛研究和应用, 比如优化控制、过程监控和故障诊断等. 为验证本文所提方法的有效性, 采用TE过程故障数据集进行仿真实验. TE过程故障类型如表1所示. TE过程是一个复杂的非线性大样本尺度系统, 全部过程数据均含有高斯噪声. 本文中,每种故障类型分别选取480组和960组数据作为训练集和测试集,每组数据有52个特征参数. 本文选取的故障类型为: 故障3、4、5和7, 这些故障具有较高的非线性特征.
表 1 故障类型描述Table 1 Description of the selected fault sample setsFault Number Fault description Fault type 3 物料 D 的温度的异变 阶跃 4 反应器冷却水入口温度的异变 阶跃 5 泠凝器冷却水入口温度的异变 阶跃 7 物料 C 压力下降 阶跃 3.1 试验一: 区间三分法寻找最优核参数试验
选取故障3、4、5和7作为故障数据类型, 设置训练集共有样本600个, 每类故障样本有150个; 测试集共有样本320个, 每类故障样本有80个. 对上节选取的实验数据进行交叉验证处理, 首先采用KFD算法可得故障诊断准确率随核参数
$\sigma $ 的变化规律如表2所示. 对表2中的数据绘制折线图, 如图3所示. 从图中可以清晰地看出故障诊断的准确率随着核函数参数不断增大的变化规律: 首先随着参数的增加故障诊断的准确率迅速增加; 当参数达到4后, 分类准确率增长趋势变缓; 当参数超过30以后, 分类准确率随参数的增加而下降. 此时在核参数的选择上采用的是人工经验选择的方法, 效率较低并且有可能会遗漏最优解. 因此, 可以选择区间迭代法的方法取代人工经验选择法来求解最优核参数.表 2 选取不同核参数σ下故障诊断的准确率 (KFD)Table 2 The fault diagnosis accuracy based on different kernel parameter σ(KFD)The value of the parameter σ Test accuracy (%) The value of the parameter σ Test accuracy (%) 0.1 25 30 81.25 0.2 30.31 40 80.94 0.8 50 70 53.13 2 66.88 90 51.56 4 75.63 100 45 8 78.44 160 43.75 10 79.38 180 33.44 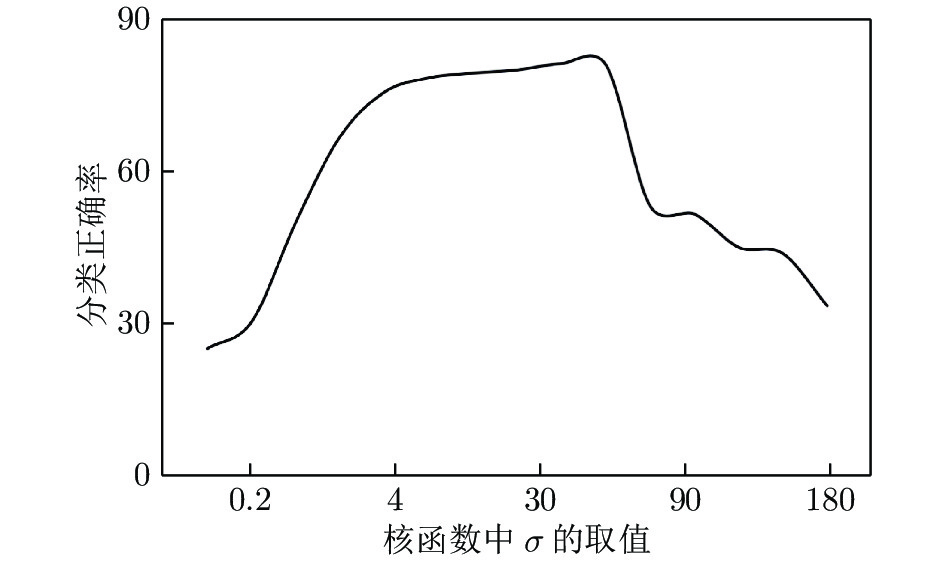 图 3 故障诊断准确率与核参数取值折线图Fig. 3 Line diagram of the fault diagnosis accuracy and kernel parameter
图 3 故障诊断准确率与核参数取值折线图Fig. 3 Line diagram of the fault diagnosis accuracy and kernel parameter采用KFD算法对数据进行处理, 并利用区间三分法迭代求解最优核参数对应的故障诊断的准确率如表3所示. 由表3可知, 当区间迭代六次后,
$\sigma = 30.{\rm{9}} ,\;$ 分类准确率为81.25 %, 且相比第三次迭代中的$\sigma = 30.3,\;$ 分类准确率不再改变, 因此, 可以取$\sigma = 30.{\rm{9}}$ 或$\sigma = 30.3$ 作为最优参数. 通过对比表2可得, 利用区间三分法求解出的最优核参数对应的分类准确率和交叉验证法得到的$\sigma = {\rm{30}}$ 所对应的分类准确率相同, 但是三分法大大提高了运算效率, 并且避免了遗漏最优解的可能.表 3 利用区间三分法求解最优核参数σ对应的故障诊断的准确率 (KFD)Table 3 The accuracy of fault diagnosis of optimal kernel parameter by using the interval three-part method (KFD)迭代次数 对应区间 三分点 1 三分点 2 三分点 3 三分点 4 ${X_1}$ $D({X_1})$ ${X_2}$ $D({X_2})$ ${X_3}$ $D({X_3})$ ${X_3}$ $D({X_4})$ 1 [1, 100] 1 50 % 34 79 % 67 51 % 100 45 % 2 [1, 67] 1 50 % 23 80 % 45 73.8 % 67 51 % 3 [1, 45] 1 50 % 15.7 79.4 % 30.3 81.25 % 45 73.8 % 4 [15.7, 45] 15.7 79.4 % 25.5 80 % 35.2 78.8 % 45 73.8 % 5 [15.7, 35.2] 15.7 79.4 % 22.2 80.3 % 28.7 80.4 % 35.2 78.8 % 6 [22.2, 35.2] 22.2 80.3 % 26.5 80 % 30.9 81.25 % 35.2 78.8 % 同时, 当核参数选取不同值时, 本文对KFD和MKFD两种算法的训练集和测试集的准确率进行了对比, 实验结果如表4所示.
表 4 KFD算法和MKFD算法中不同核参数的故障诊断结果Table 4 The fault diagnosis with different kernel parameters in KFD algorithm and MKFD algorithmThe value of the
parameter σ in KFDTrain
accuracy (%)Test
accuracy (%)The value of the
parameter σ in MKFDTrain
accuracy (%)Test
accuracy (%)0.1 100 25 0.1 100 25 1 100 50 1 100 50 10 99.8 79.4 4 100 76.9 30 99.8 81.3 8 100 99.69 60 70.5 44.7 12 99.9 92.5 90 27.7 25.3 16 99.9 80.6 分析表4可知, 两种算法的分类能力都是由低到高再到低的过程. 在KFD算法中, 当参数
$\sigma $ 取0.1和取1的时候训练集的准确率在100 %, 但是测试集的准确率却只在25 %和50 %; 相对应的, 在MKFD算法中, 参数$\sigma $ 取0.1和取1时也是同样的情况, 这与我们之前的理论证明一致, 即: 当$\sigma $ 趋近于0时, 核Fisher判别分析方法会出现严重的过拟合现象.为充分验证采用区间三分法的MKFD算法的适用性, 本文增加了2个仿真算例. 选用UCI机器学习数据库中Ionosphere和Breast cancer分类数据来做实验验证, Ionosphere数据集包含351个样本, 34个特征向量, 分为“good”和“bad”两个数据类别, 其中“good”类别含有126个样本, “bad”类别含有225个样本; Breast cancer数据集包含638个样本, 9个特征向量, 分为“benign”和“malignant”两个数据类别, 其中“benign”类别包含444个样本, “malignant”类别包含239个样本. 本算例中选取类别各80个作为样本的训练集和测试集, 仿真结果见表5和图4.
表 5 选取不同核参数σ下故障诊断的准确率(按照区间三分法做纵向表)Table 5 The fault diagnosis accuracy based on different kernel parameters σ (Make the longitudinal table according to the interval three-part method)Ionosphere Breast cancer The value of the parameter σ Test accuracy (%) The value of the parameter σ Test accuracy (%) 1 78.9 1 31.7 34 91.6 149 95.1 49 92 223 94.9 56 92.4 248 95.4 59 92.8 297 95.4 63 92.8 334 95.4 67 92.4 346 95.4 68 92 445 94.6 78 90.8 667 94 100 86.1 1000 93.2 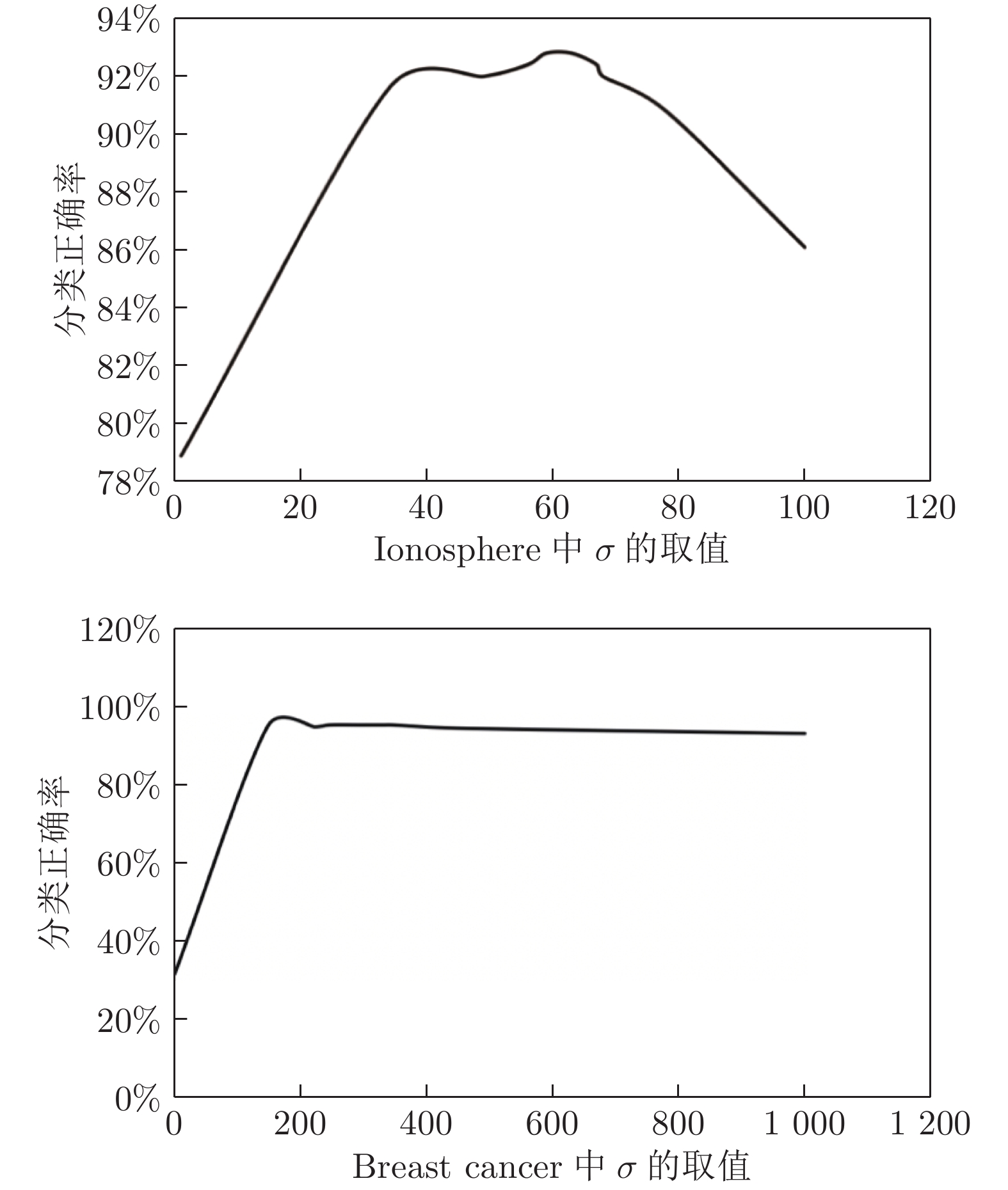 图 4 故障诊断准确率与核参数取值折线图Fig. 4 Line diagram of the fault diagnosis accuracy and kernel parameter
图 4 故障诊断准确率与核参数取值折线图Fig. 4 Line diagram of the fault diagnosis accuracy and kernel parameter按照仿真结果来看, 采用区间三分法的MKFD算法仍适用于UCI机器学习数据库中Ionosphere和Breast cancer分类数据, 其分类能力是由低变高再变低的过程, 对于Ionosphere和Breast cancer分类数据, 其分类准确率分别达到92.8 %和95.4 %. 也可以充分说明该算法的有效性和适用性.
3.2 试验二: 数据诊断效率试验
为了进一步验证本文算法的优越性, 本节对四种故障诊断方法在运算效率上进行对比, 这四种方法分别为: KFD、CKFD、FDGLPP[32]和MKFD. 目前在化工故障领域, 基于全局—局部保持投影算法备受关注, 这种算法不仅考虑数据的全局结构信息也考虑了数据的局部近邻结构信息, 在对数据进行特征提取时, 能大大降低信息量的损失. 将这几种算法与本文算法进行仿真对比, 实验验证结果见表6和表7.
表 6 区间三分法迭代求解最优核参数σ (MKFD)Table 6 The iterative solution of the optimal kernel parameters σ using interval partition method迭代次数 对应区间 三分点 1 三分点 2 三分点 3 三分点 4 ${X_1}$ $D({X_1})$ ${X_2}$ $D({X_2})$ ${X_3}$ $D({X_3})$ ${X_3}$ $D({X_4})$ 1 [1, 100] 1 50.9 % 34 60.6 % 67 57.5 % 100 58.1 % 2 [1, 67] 1 50.9 % 23 76.6 % 45 58.1 % 67 57.5 % 3 [1, 45] 1 50 % 15.7 96.3 % 30.3 63.8 % 45 58.1 % 4 [1, 30.3] 1 50 % 10.8 99.69 % 20.5 84.69 % 30.3 63.8 % 5 [1, 20.5] 1 50 % 7.5 99.38 % 14 97.81 % 20.5 84.69 % 6 [1, 14] 1 50 % 5.3 81.56 % 9.7 99.69 % 14 97.81 % 表 7 交叉验证法选取不同核参数σ下故障诊断的准确率(FDGLPP)Table 7 The fault diagnosis accuracy based on different kernel parameters σ by cross validation methodThe value of the
parameter σTest
accuracy (%)The value of the
parameter σTest
accuracy (%)The value of the
parameter σTest
accuracy (%)0.1 25 0.5 68.13 3 55.31 1 52.19 5 75.31 6 79.38 50 28.44 25 25.0 9 99.69 100 41.25 50 28.44 12 25.0 500 39.06 75 34.69 15 55.94 1000 38.75 95 40.0 18 25.0 本文将MKFD算法和FDGLPP算法进行对比, 我们已知MKFD算法故障诊断准确率随核参数σ的变化规律, 所以通过区间三分法迭代寻找最优核参数, 在第4步迭代时就可以找到最优σ, 此时故障诊断率达99.69 %; 而FDGLPP算法, 在选取最优核参数时, 需要通过交叉验证法得到, 损耗时间较长, 故MKFD算法能有效提升找到最优核参数的效率.
通过分析表8可知: CKFD、FDGLPP和MKFD三种算法分别在σ = 8, 10, 9时, 故障诊断准确率达到最高值. 此时可以发现, FDGLPP算法和MKFD算法的准确率都高达99%以上, 但是FDGLPP算法运行的时间是MKFD算法运行效率的两倍之多, 这也可以看出MKFD算法在运行效率上的优越性. 这两个实验通过对比可以发现, 本文的算法在提升运算效率的同时并没有以损失准确率为代价, 这有效证明了本文算法的优越性.
表 8 四种模型的故障诊断结果与运行时间Table 8 Fault diagnosis results and running time of the four modelsModel Optimal value of parameter σ Test accuracy (%) Test time (s) KFD 30 81.25 3.90072 CKFD 8 97.81 4.14769 FDGLPP 10 99.69 9.30612 MKFD 9 99.69 3.86806 3.3 试验三: 数据混叠的故障诊断试验
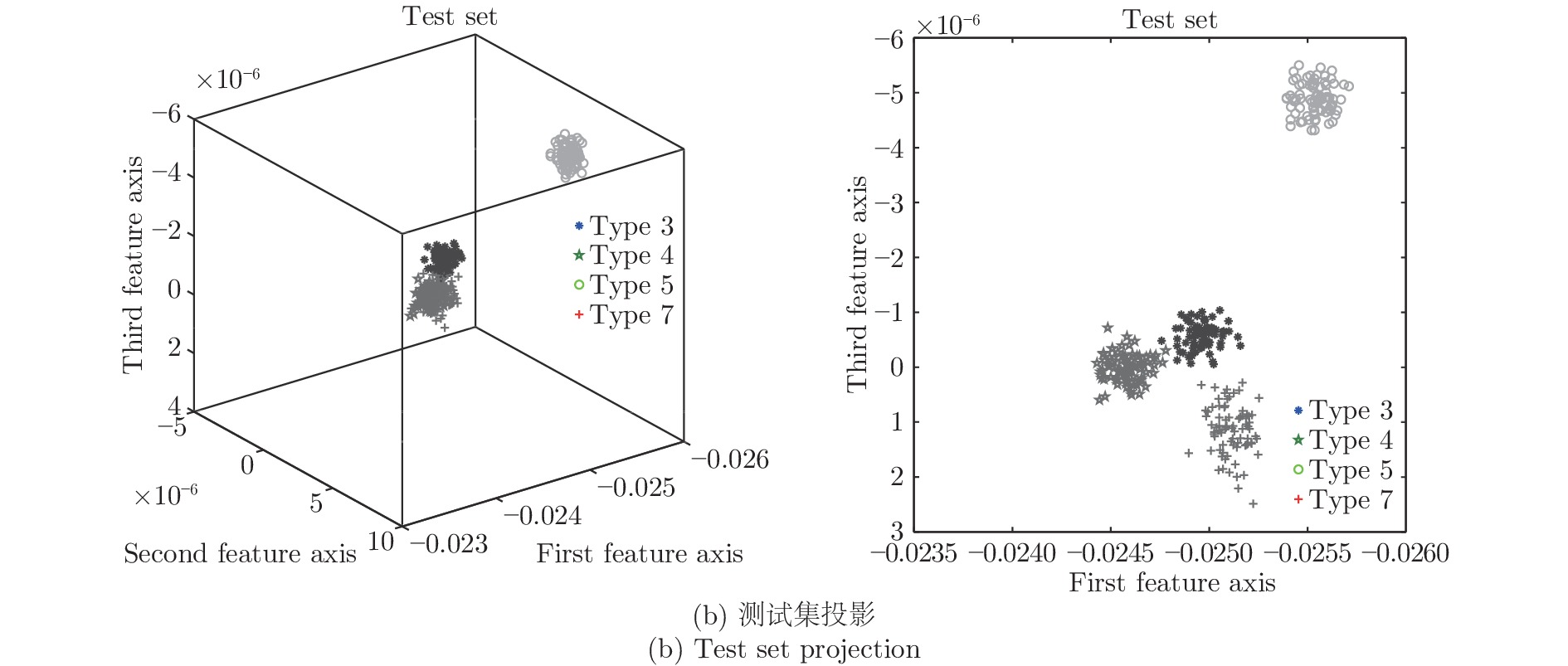
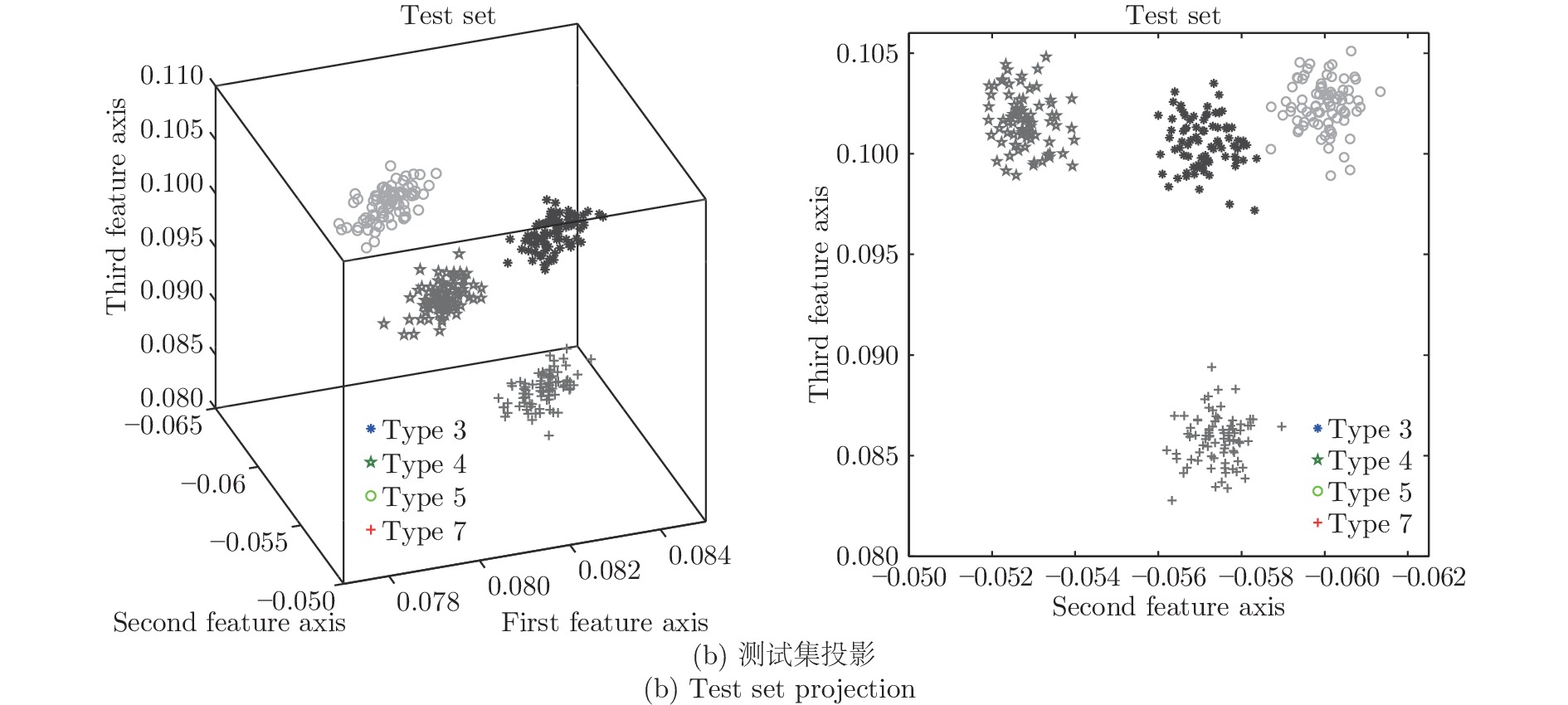
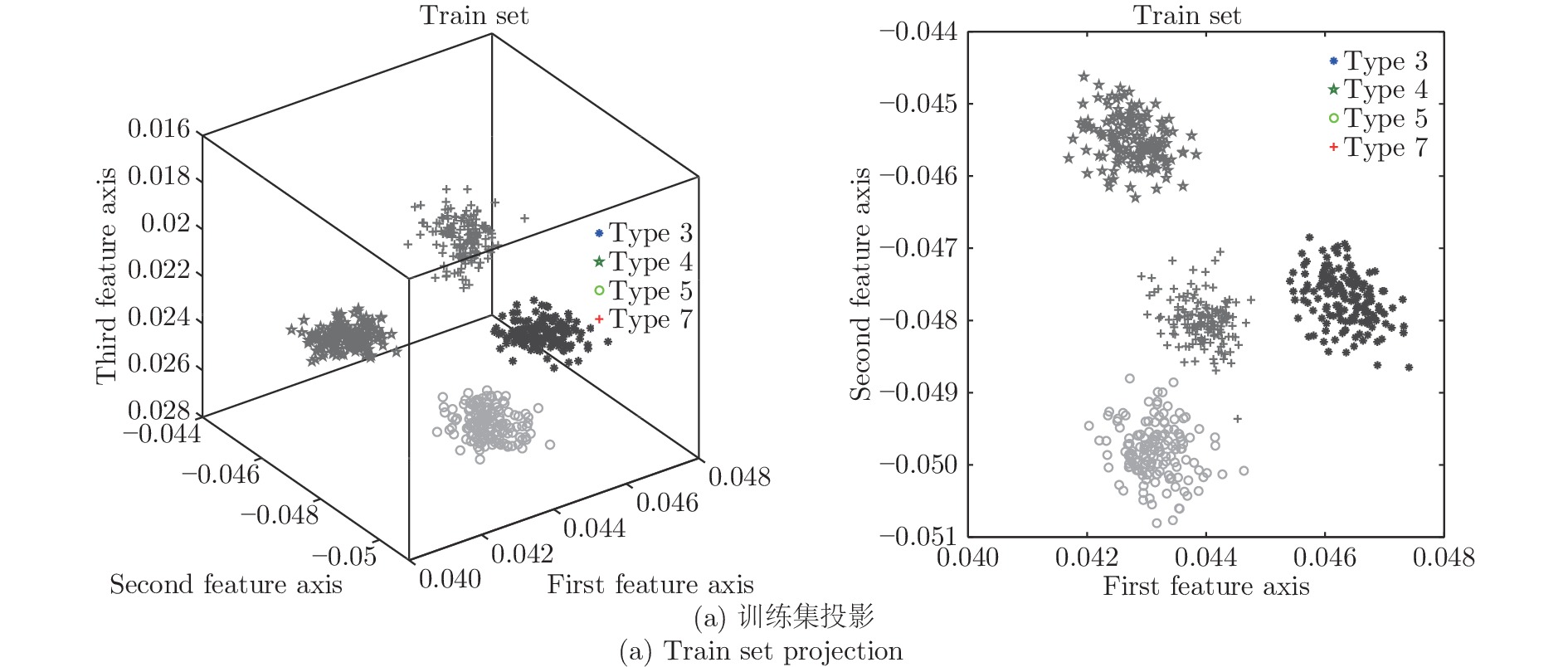
分别应用KFD、CKFD、FDGLPP以及MKFD四种算法对训练集和测试集样本进行特征投影, 并用马氏距离对样本进行故障分类, 特征投影结果如图5、图6、图7和图8, 这四组图分别是在四种算法处理下, 训练集和测试集在三维主特征轴及二维主特征轴上的投影.
对训练集和测试集样本采用KFD投影, 得到的投影图如图5所示, 此时核参数取30. 对训练集和测试集样本采用CKFD投影, 得到的投影图如图6所示, 此时核参数取8, 权重函数取3. 对训练集和测试集样本采用FDGLPP投影, 得到的投影图如图7所示, 此时核参数取10. 同样对训练集和测试集样本采用MKFD投影, 得到的投影图如图8所示, 此时核参数取8, 权重函数分别取3和1.
图5可以看出, 通过KFD投影, 得到故障3、4和7的投影信息互相掩盖, 导致分类效果差. 图6所示, 通过CKFD投影, 可以将三者区分开, 增大两者之间的类间距, 使得分类效果明显增强, 可以达到97 %以上, 但是此时CKFD的运算效率明显低于KFD. 在图7中通过FDGLPP投影, 可以将这四类故障区分开, 但是每一类故障投影的类内距离较分散, 在数据量大的情况下, 不利于分类准确. 在图8中通过MKFD投影, 缩小类内间距, 用组平均距离代替质心距离作为改变类间距的权重函数, 此时不仅能提升运算效率, 还可以提升其准确率, 此时的准确率为99.69 %.
综上, 本文提出的MKFD算法, 对于故障样本的投影效果具有很大改善, 提升了故障诊断的精度, 同时, 在MKFD算法中所提出的寻找最优核参数的区间三分法也可以大大提升算法的运行效率.
4. 结论
复杂的化工过程产生了大量的状态数据, 这些数据具有大量、非线性的特点. 引入KFD算法进行特征提取, 可以有效解决数据非线性问题, 提升算法效率. 但KFD算法也有一些缺点, 本文针对故障数据分类效果差及无法快速确定最优核参数这两个缺点, 提出了MKFD算法.
在MKFD算法中, 选用区间三分法来克服核参数的低效选取问题, 该方法不仅可以解决依靠经验选择参数的劣势, 还可以避免遗漏最优解, 可以有效提升核参数的选取效率. 该方法基于TE过程数据做仿真验证, 并与之前常用的交叉验证法做对比, 结果表明: 在最优参数精度范围内, 本文所提方法加快了参数选择速度; 同时, 运用马氏距离对类间和类内距离进行加权, 不仅可以最大限度地分离投影向量的类间距离, 还可以使得其类内距离更紧凑, 显著提升了故障诊断算法的运行效率.
在本文提及的方法中, 数据量大所带来的矩阵非奇异的情况可以进一步深入研究, 除此之外, 并行运算, 实时监控, 提取最大信息量也是需要进一步深入研究的方向.
-
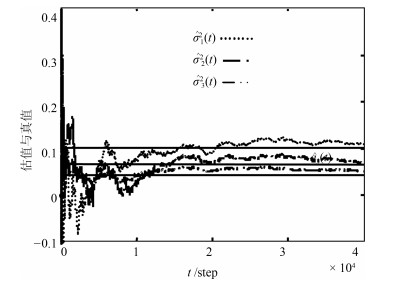
图 4 $\mu_{i}(t)$的数学期望辨识
Fig. 4 Identification of Mathematical expectation of $\mu_{i}(t)$

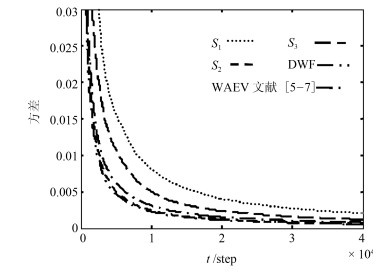
图 8 局部、融合最优与自校正状态分量1的滤波误差方差
Fig. 8 Variance of the first state component of local, fusion optimal and self-tuning filters

图 9 局部、融合最优与自校正状态分量2的滤波误差方差
Fig. 9 Variance of the second state component of local, fusion optimal and self-tuning filters
-
[1] Anderson B D O, Moore J B. Optimal Filtering. Englewood Cliffs, NJ: Prentice-Hall, 1979. [2] 邓自立, 李春波.按对角阵加权自校正信息融合Kalman预报器及其收敛性分析.自动化学报, 2007, 33(2): 156-163 doi: 10.1360/aas-007-0156Deng Zi-Li, Li Chun-Bo. Self-tuning information fusion Kalman predictor weighted by diagonal matrices and its convergence analysis. Acta Automatica Sinica, 2007, 33(2): 156-163 doi: 10.1360/aas-007-0156 [3] Gao Y, Jia W J, Sun X J, Deng Z L. Self-tuning multisensor weighted measurement fusion Kalman filter. IEEE Transactions on Aerospace and Electronic Systems, 2009, 45(1): 179-191 doi: 10.1109/TAES.2009.4805272 [4] Dou Y F, Sun S L, Ran C J. Self-tuning full-order wmf Kalman filter for multisensor descriptor systems. IET Control Theory & Applications, 2017, 11(3): 359-368 [5] Ran C J, Gu L, Deng Z L. Self-tuning centralized fusion Kalman filter for multisensor systems with companion form and its convergence. In: Proceedings of 8th IEEE International Confewence on Control and Automation. Xiamen, China: IEEE, 2010. 645-650 [6] 陶贵丽, 邓自立.含未知参数的自校正融合Kalman滤波器及其收敛性.自动化学报, 2012, 38(1): 109-119 doi: 10.3724/SP.J.1004.2012.00109Tao Gui-Li, Deng Zi-Li. Self-tuning fusion Kalman filter with unknown parameters and its convergence. Acta Automatica Sinica, 2012, 38(1): 109-119 doi: 10.3724/SP.J.1004.2012.00109 [7] Ran C J, Deng Z L. Self-tuning weighted measurement fusion Kalman filtering algorithm. Computational Statistics & Data Analysis, 2012, 56 (6): 2112-2128 [8] 游科友, 谢立华, 网络控制系统的最新研究综述, 自动化学报, 2013, 39(2): 101-118 doi: 10.3724/SP.J.1004.2013.00101You Ke-You, Xie Li-Hua. Survey of recent progress in networked control systems. Acta Automatica Sinica, 2013, 39(2): 101-118 doi: 10.3724/SP.J.1004.2013.00101 [9] Sun S L, Xie L H, Xiao W D, Yeng C S. Optimal linear estimation for systems with multiple packet dropouts. Automatica, 2008, 44(5): 1333-1342 doi: 10.1016/j.automatica.2007.09.023 [10] Ma J, Sun S L. Information fusion estimators for systems with multiple sensors of different packet dropout rates. Information Fusion, 2011, 12(3): 213-222 doi: 10.1016/j.inffus.2010.11.003 [11] Nahi N E. Optimal recursive estimation with uncertain observation. IEEE Transactions on Information Theory, 1969, 15(4): 457-462 doi: 10.1109/TIT.1969.1054329 [12] 孙书利.具有一步随机滞后和多丢包的网络系统的最优线性估计.自动化学报, 2012, 38(3): 349-356 doi: 10.3724/SP.J.1004.2012.00349Sun Shu-Li. Optimal linear estimation for networked systems with one-step random delays and multiple packet dropouts. Acta Automatica Sinica, 2012, 38(3): 349-356 doi: 10.3724/SP.J.1004.2012.00349 [13] 李娜, 马静, 孙书利.带多丢包和滞后随机不确定系统的最优线性估计.自动化学报, 2015, 41(3): 611-619 doi: 10.16383/j.aas.2015.c140484Li Na, Ma Jing, Sun Shu-Li. Optimal linear estimation for stochastic uncertain systems with multiple packet dropouts and delays. Acta Automatica Sinica, 2015, 41(3): 611-619 doi: 10.16383/j.aas.2015.c140484 [14] Wang S Y, Fang H J, Tian X G. Minimum variance estimation for linear uncertain systems with one-step correlated noises and incomplete measurements. Digital Signal Processing, 2016, 49(C): 126-136 [15] R Caballero Águila, A Hermoso Carazo, J Linares Pérez. Fusion estimation using measured outputs with random parameter matrices subject to random delays and packet dropouts. Signal Processing, 2016, 127(C): 12-23 [16] R Caballero Águila, A Hermoso Carazo, J Linares Pérez. Distributed fusion filters from uncertain measured outputs in sensor networks with random packet losses. Information Fusion, 2017, 34: 70-79 doi: 10.1016/j.inffus.2016.06.008 [17] Zhang W A, Yu L, Feng G. Optimal linear estimation for networked systems with communication constraints. Automatica, 2011, 47(9): 1992-2000 doi: 10.1016/j.automatica.2011.05.020 [18] Sun S L, Tian T, Lin H L. State estimators for systems with random parameter matrices, stochastic nonlinearities, fading measurements and correlated noises. Information Sciences, 2017, s397-398: 118-136 [19] Hu J, Wang Z D, Gao H J. Recursive filtering with random parameter matrices, multiple fading measurements and correlated noises. Automatica, 2013, 19(11): 3440-3448 [20] Subhrakanti Dey, Alex S Leong, Jamie S Evans. Kalman filtering with faded measurements. Automatica, 2009, 45(10): 2223-2233 doi: 10.1016/j.automatica.2009.06.025 [21] Sun S L, Peng F F, Lin H L. Distributed asynchronous fusion estimator for stochastic uncertain systems with multiple sensors of different fading measurement rates. IEEE Transactions on Signal Processing, 2018, 66(3): 641-653 doi: 10.1109/TSP.2017.2770102 [22] Lin H L, Sun S L. Optimal sequential fusion estimation with stochastic parameter perturbations, fading measurements, and correlated noises. IEEE Transactions on Signal Processing, 2018, 66(13): 3571-3583 doi: 10.1109/TSP.2018.2831642 [23] Sun S L, Deng Z L. Multi-sensor optimal information fusion Kalman filter. Automatica, 2004, 40(6): 1017-1023 doi: 10.1016/j.automatica.2004.01.014 [24] 邓自立.信息融合估计理论及其应用.北京:科学出版社, 2012.Deng Zi-Li. Information Fusion Estimation Theory and Applications. Beijing: Science Press, 2012. 期刊类型引用(5)
1. Jing SUN,Guangtong XU,Zhu WANG,Teng LONG,Jingliang SUN. Safe flight corridor constrained sequential convex programming for efficient trajectory generation of fixed-wing UAVs. Chinese Journal of Aeronautics. 2025(01): 542-555 .  必应学术
必应学术2. 王祝,张振鹏,张梦通,徐广通. 安全走廊约束的无人机轨迹序列凸优化方法. 系统仿真学报. 2025(01): 134-144 . 百度学术3. 冯子鑫,薛文超,张冉,齐洪胜. 可回收火箭大气层内动力下降的多阶段鲁棒优化制导方法. 自动化学报. 2024(03): 505-517 . 本站查看4. 王子恒,李伊陶,熊兴中. 基于分布式模型预测控制的实时可交互无人机群编队方法. 计算机应用研究. 2024(12): 3600-3606 . 百度学术5. 郑纪彬,杨志伟,杨洋,刘宏伟,张田仓,杨娟. 集群无人机载雷达阵列波束合成. 雷达科学与技术. 2023(01): 24-34+39 . 百度学术其他类型引用(3)
-

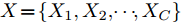
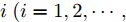
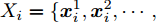
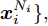
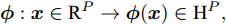
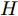

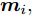
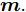
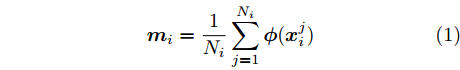
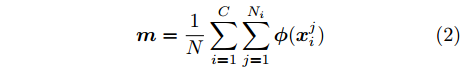
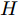
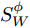
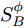
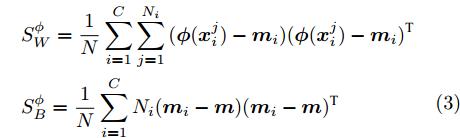
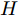
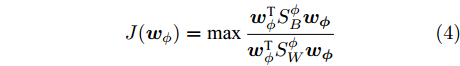
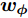
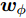
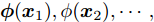
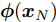
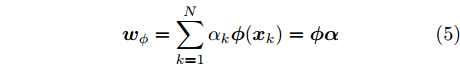
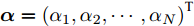
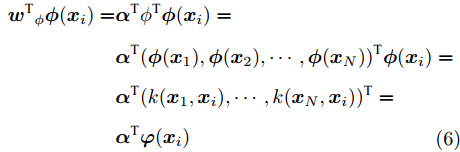
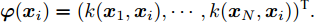
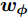
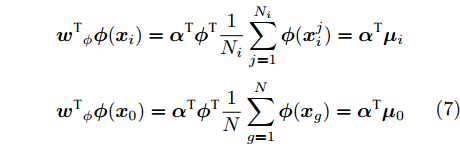
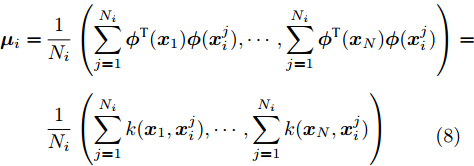
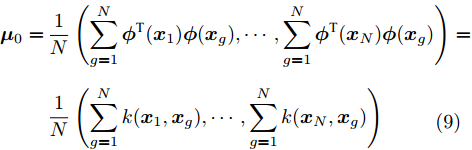
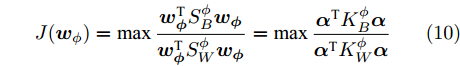
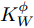
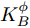
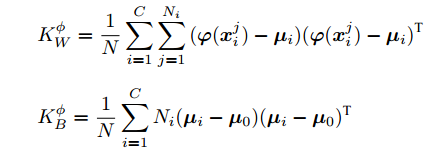
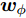
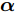
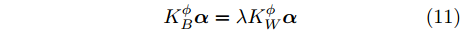
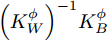
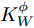
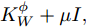
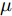
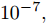
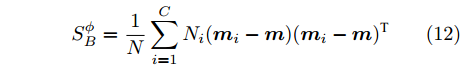
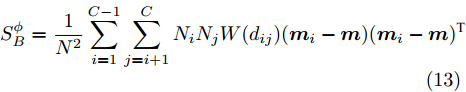
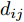

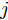
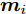
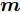
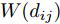
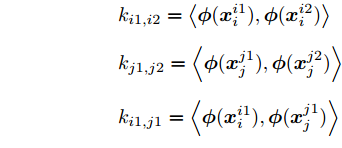
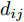
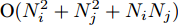
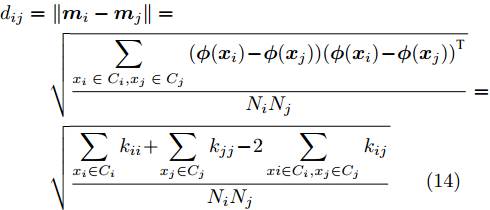
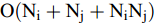
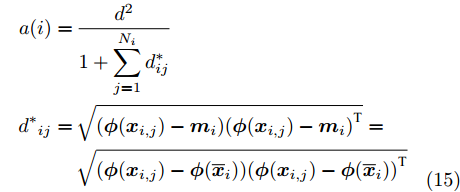
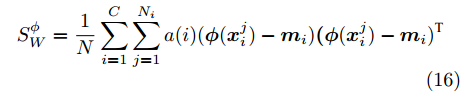
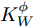
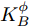
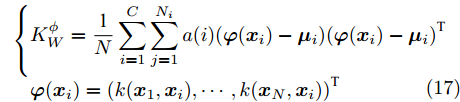
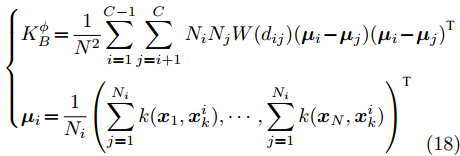
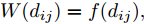
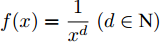
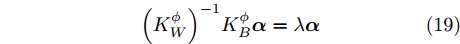
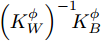
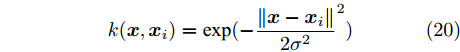

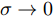
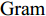
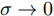
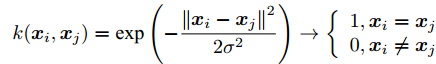
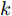
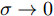
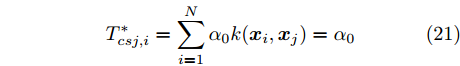


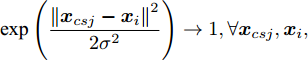
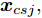
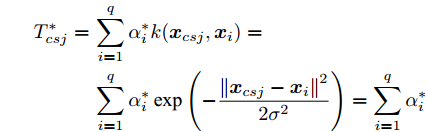
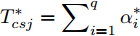
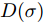
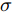
 下载:
下载:
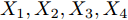
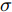
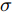
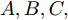
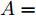
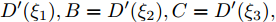
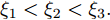
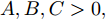
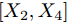
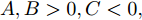
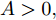
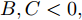
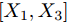
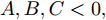
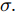
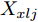
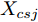
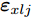
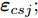
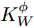
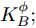
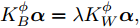
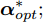
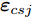
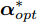
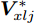
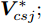
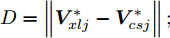
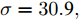
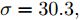
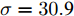
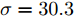
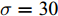





 下载:
下载:
计量
- 文章访问数: 1133
- HTML全文浏览量: 239
- PDF下载量: 172
- 被引次数: 8
