

-
摘要: 双流卷积神经网络能够获取视频局部空间和时间特征的一阶统计信息, 测试阶段将多个视频局部特征的分类器分数平均作为最终的预测. 但是, 一阶统计信息不能充分建模空间和时间特征分布, 测试阶段也未考虑使用多个视频局部特征之间的更高阶统计信息. 针对这两个问题, 本文提出一种基于二阶聚合的视频多阶信息融合方法. 首先, 通过建立二阶双流模型得到视频局部特征的二阶统计信息, 与一阶统计信息形成多阶信息. 其次, 将基于多阶信息的视频局部特征分别进行二阶聚合, 形成高阶视频全局表达. 最后, 采用两种策略融合该表达. 实验表明, 本文方法能够有效提高行为识别精度, 在HMDB51和UCF101数据集上的识别准确率比双流卷积神经网络分别提升了8 % 和2.1 %, 融合改进的密集点轨迹(Improved dense trajectory, IDT) 特征之后, 其性能进一步提升.Abstract: The classical two-stream convolutional neural network (CNN) can capture the flrst-order statistics of the local spatial and temporal features from an input video, while making flnal predictions by averaging the softmax scores of the local video features. However, the flrst-order statistics can not fully characterize the distribution of the spatial and temporal features, while higher-order information inherent in local features is discarded at the test stage. To solve the two problems above, this paper proposes a multi-order information fusion method for human action recognition. To this end, we flrst introduce a novel two-stream CNN model for capturing second-order statistics of the local spatial and temporal features, which, together with the original flrst-order statistics, forms the so-called multi-order information. We perform individually second-order aggregation of these extracted local multi-order information to compute global video representations. Finally, two strategies are proposed to fuse video representations for prediction. The experimental results demonstrate that our proposed method signiflcantly improves recognition accuracy over the original two-stream CNN model, i.e., 8 % and 2.1 % gains on the HMDB51 and UCF101, respectively. The performance of our method is further improved by combining traditional IDT (improved dense trajectory) features.
-
Key words:
- Human action recognition /
- two-stream convolutional neural network /
- multi-order information fusion /
- second-order aggregation
-
人工智能的发展规划已经上升到国家战略层面, 成为建设科技强国和引领未来的重要技术.备受瞩目的AlphaGo [1]就是人工智能和深度学习技术[2-3]相结合的产物, 其中, 局势评估与落棋位置选择是AlphaGo取得成功的关键环节.人工神经网络[4]的深度学习能力, 树搜索以及强化学习技术[5]三者的融合, 确保程序运行中评估的准确性和决策的最优性.最近, 新版程序AlphaGo Zero [6]的出现更被认为是深度强化学习技术的运用典范.
机器学习是人工智能的核心技术, 它是使计算机具有智能的根本途径.作为机器学习领域的重要分支, 强化学习关注机器在与环境的交互中进行智能学习.它研究智能体如何在环境中采取行动, 以最大限度地增加累计奖励或尽量减少惩罚, 其中涉及到最优化思想.事实上, 对于模仿自然和设计自动控制系统的兴趣, 促使人们利用有限资源实现所需的最优性能, 从而使得控制系统达到一定意义下的最优效果.动态规划是一种求解最优化问题的有效计算技术, 通过倒序搜索并利用最优性原理得到最优策略[7-8].然而, 状态和控制维数增大时导致的"维数灾"问题[7], 对于动态系统模型的依赖和倒序搜索与实时控制的矛盾, 极大地限制了该方法的应用范围.虽然如此, 动态规划与强化学习却是密切相关的, 并为理解强化学习思想提供了必要的基础.在强化学习的众多算法中, 有一类自适应评判方法, 它以执行-评判结构为基本框架, 执行组件产生控制行为(或控制律), 评判组件评估该控制行为的价值.自适应评判, 动态规划和神经网络相结合, 产生了用于求得近似最优解的自适应/近似动态规划(Adaptive/approximate dynamic programming, ADP)方法.该方法由Werbos博士首先提出[9-11], 其核心思想是基于自适应评判的优化, 并被认为是实现真正类脑智能的必要途径[11].它的基本结构中有三个组成部分, 即评判模块、模型模块和执行模块, 通常都通过神经网络来实现, 分别执行评估、预测和决策的功能[12-14].应当指出, 同神经网络一样, 模糊逻辑也可以用来提供智能学习能力.在ADP方法体系中, 自适应评判融合强化学习提供学习机制, 动态规划蕴含最优性原理提供理论基础, 神经网络作为函数逼近器提供实现手段.特别地, 它是一种基于数据驱动的方法, 具有在线学习与正序求解的能力.在人工智能、类脑智能、大数据、云计算、物联网等新技术不断涌现的背景下, 具有强大自学习能力的ADP, 符合知识自动化的潮流, 已经成为一种极有发展前景的智能优化技术.
利用ADP方法进行智能优化决策的基础是最优控制设计.关于线性系统的最优调节器设计, 在控制理论和控制工程界已经有很多成熟的方法.然而, 对于一般的非线性系统, 获得Hamilton-Jacobi-Bellman (HJB)方程的解析解并不是一件容易的事情.此类系统的最优控制设计相当困难, 但是却相当重要, 因此引起了人们的广泛重视.其中, 逐次逼近法[15-17]通过寻找HJB方程的近似解来克服这一困难, 并与ADP方法密切相关.简单来说, ADP是一种基于智能学习思想的新兴方法, 可以为复杂动态系统提供有效的优化控制解决方案[9-17].在过去的二十年中, ADP在求解离散时间和连续时间系统的自适应最优控制问题中得到了广泛的应用, 例如文献[18-33].近年来的综述文献和学术专著, 如文献[34-42], 在理论、设计、分析和应用等层面对该领域的研究工作进行了总结.如今, 基于数据驱动的控制设计已经成为控制理论和控制工程领域的研究热点[43-44], ADP能够促进基于数据的决策与优化控制研究, 并有利于人工智能和计算智能技术的发展.
在有关ADP方法的现有结果中, 大多数是在不考虑被控对象不确定性的前提下得到的.但是, 实际中的控制系统总是受着模型不确定性, 外界扰动或其他变化的影响.我们在控制器设计过程中必须考虑这些因素, 以避免闭环系统性能的恶化, 提高被控系统的鲁棒性能.关于不确定系统的鲁棒控制问题, 控制学者们已经取得了很多研究成果, 如文献[45-50]和其中的参考文献.在文献[49-50]中, 作者通过设计标称系统的最优控制器处理鲁棒控制问题.这是在两种控制问题之间建立有效联系的一项重要结果, 但是并没有给出详细的设计步骤, 也很难处理一般的非线性系统.文献[51-52]提出基于HJB方程的非线性系统鲁棒控制器设计方法, 但是求解过程是离线进行的, 而且没有充分讨论闭环系统的稳定性.
近几年来, 利用自适应评判思想进行鲁棒控制设计逐渐成为ADP领域的研究热点之一, 有很多方法陆续被提出, 这里统称为鲁棒自适应评判控制(Robust adaptive critic control).一种基本的做法是进行问题转换, 以建立鲁棒性和最优性之间的密切关系[53-62].在这些文献中, 闭环系统一般满足最终一致有界稳定.这些结果充分表明, ADP方法适用于不确定环境下的复杂非线性系统鲁棒控制设计.由于以前的许多ADP文献并不关注控制器的鲁棒性能, 鲁棒自适应评判控制的出现, 极大地扩大了ADP方法的使用范围.随后, 考虑到在处理系统不确定项方面的共性, 结合ADP和滑模控制技术的自学习优化方法, 为鲁棒自适应评判控制提供了一个新的研究方向[63].另外, 鲁棒ADP方法[64-68], 是该领域的又一重要成果.文献[65]给出了线性和非线性系统鲁棒ADP方法的研究综述.值得一提的是, 鲁棒ADP方法在电力系统中的应用受到了特别关注[64-68].一般而言, 基于鲁棒ADP的控制器不仅能够镇定原始的不确定系统, 而且使得系统在不含有动态不确定性的情况下也能达到最优.总之, 鲁棒自适应评判控制, 包含了关于系统稳定性、收敛性、最优性、鲁棒性的讨论, 在不确定环境下复杂系统的智能学习控制领域扮演着重要角色.本文从一般的自适应评判设计引入主题, 以解决不确定环境下的鲁棒镇定问题为出发点, 着重分析鲁棒自适应评判控制设计的主要方法, 并探讨相关领域的发展趋势.
在本文中, ${\bf R}$代表所有实数集. ${\bf R}^n$表示由所有$n$-维实向量组成的欧氏空间. ${{\bf R}}^{n\times m}$是所有$n\times m$实矩阵组成的空间. $\|\cdot\|$表示在${ \bf R}^n$上的向量范数或者在${{\bf R}}^{n\times m}$上的矩阵范数. $I_{n}$代表$n \times n$维单位矩阵. $\lambda_{\max}(\cdot)$和$\lambda_{\min}(\cdot)$分别表示矩阵的最大和最小特征值. $\text{diag}\{a_{1}, a_{2}, \cdots, a_{n}\}$表示由各元素构成的对角矩阵.令$\Omega$是${{\bf R}}^{n}$的一个紧集, 而$\Omega_{u}$是${\bf R}^m$的一个紧集, 并且$\mathcal{A}(\Omega)$是$\Omega$上所有容许控制律(定义见文献[16-17, 22, 28])的集合. $\rho$是效用函数中对应于不确定项的参数. $\mathcal{L}_{2}[0, \infty)$表示函数空间, 其中元素的Lebesgue积分有界. $\varrho$是$\mathcal{L}_{2}$-增益性能水平. $i$是策略学习算法中的迭代指标, $j$是事件触发机制下的采样时刻. ${\bf N} = \{0, 1, 2, \cdots\}$表示所有非负整数的集合. "${\rm T}$"代表转置操作且$\nabla (\cdot):=\partial (\cdot)/\partial x$是梯度操作符.
1. 基于学习的自适应评判控制设计
本部分包括基本的问题描述与设计思路, 神经网络实现与系统稳定性分析, 以及关于改进自适应评判学习机制的讨论.
1.1 问题描述与设计思路
考虑一类控制输入具有仿射形式的连续时间非线性系统
$$ \begin{align} \label{Eq55004} \dot{x}(t)=f(x(t))+g(x(t))u(t) \end{align} $$ (1) 其中, $x(t)\in \Omega \subset{\bf R}^n$是状态向量, $u(t) \in \Omega_{u} \subset {\bf R}^m$是控制向量.系统函数$f(\cdot)$和$g(\cdot)$可微且$f(0)=0$.令在$t=0$时的初始状态为$x(0)=x_{0}$, 且$x=0$是被控系统的一个平衡点.假设系统函数$f(x)$在属于${\bf R}^n$并且包含原点的集合$\Omega$上是Lipschitz连续的.一般地, 我们假设非线性动态系统(1)能控.
针对有限时域上的无折扣最优控制问题, 令
$$ \begin{align}\label{Eq55013} U(x(t), u(t))=Q(x(t))+u^{\rm T}(t)Ru(t) \end{align} $$ (2) 表示效用函数, 其中$Q(x) \geq 0$为标量函数, $R =R^{\rm T} > 0$为$m$-维方阵, 并且定义代价函数为
$$ \begin{align} \label{Eq55005} J(x(t), u(t))=\int_{t}^{\infty}U(x(\tau), u(\tau))\text{d}\tau \end{align} $$ (3) 为了描述简洁, 文中的代价函数$J(x(t), u(t))$可被写成$J(x(t))$或$J(x)$.我们通常关心的代价函数是从$t=0$开始, 因此记做$J(x(0))=J(x_{0})$.如果考虑含有折扣因子$\gamma$ ($\gamma \geq 0$)的情形, 代价函数通常为
$$ \begin{align} \label{Eq68002} J(x(t), u)=\int_{t}^{\infty}{\rm e}^{-\gamma(\tau-t)}U(x(\tau), u(\tau))\text{d}\tau \end{align} $$ (4) 这里的指数折扣项${\rm e}^{-\gamma(\tau-t)}$与研究离散时间系统最优控制时常用的折扣因子(如文献[18])有着类似的功能.
在最优控制问题中, 我们通过设计最优反馈控制律$u(x)$, 使得代价函数(3)达到最小.对于任意一个容许控制律$u(x)\in \mathcal{A}(\Omega)$, 若代价函数(3)连续可微, 则非线性Lyapunov方程为
$$ \begin{align} \label{Eq55023} 0 = U(x, u(x))+(\nabla J(x))^{\rm T}[f(x)+g(x)u(x)] \end{align} $$ (5) 且$J(0)=0$.如果考虑折扣因子的影响, 该方程变为
$$ \begin{align} \label{EQ68003} 0 = U(x, u)-\gamma J(x)+(\nabla J(x))^{\rm T}(f+gu) \end{align} $$ (6) 定义系统(1)的Hamiltonian为
$$ \begin{align} H(x, &\ u(x), \nabla J(x))= U(x, u(x))+\nonumber\\&\ (\nabla J(x))^{\rm T} [f(x)+g(x)u(x)] \end{align} $$ (7) 利用Bellman最优性原理, 最优代价函数
$$ \begin{align}\label{Eq55011} J^{*}(x)= \min\limits_{u \in \mathcal{A}(\Omega)}\int_{t}^{\infty}U(x(\tau), u(\tau))\text{d}\tau \end{align} $$ (8) 满足HJB方程$\min_{u \in \mathcal{A}(\Omega)}H(x, u(x), \nabla J^{*}(x))=0$.基于最优控制理论, 最优状态反馈控制律为
$$ \begin{align} \label{Eq55006} u^{*}(x) =-\frac{1}{2}R^{-1}g^{\rm T}(x) \nabla J^{*}(x) \end{align} $$ (9) 使用最优控制表达式(9), HJB方程转化为如下形式
$$ \begin{align} \label{Eq55007} 0= &\ U(x, u^{*}(x))+(\nabla J^{*}(x))^{\rm T}[f(x)+g(x)u^{*}(x)]=\nonumber\\&H(x, u^{*}(x), \nabla J^{*}(x)) \end{align} $$ (10) 其中, $J^{*}(0)=0$.需要指出, 为了简洁与一致, 本文对于效用函数$U$, 代价函数$J$, 以及Hamiltonian函数$H$等符号的使用, 针对不同问题不做明显区分, 具体意义在相应的问题描述中可以得知.
如果已知最优代价函数的值, 最优控制律就可以直接求得, 也就是说方程(10)是可解的.然而, 实际情况并非如此.因为很难得到连续时间HJB方程(10)的解析解, 所以获取一般非线性系统的最优控制律(9)并不容易.这就激发人们进行迭代算法的研究, 如提出经典的策略迭代.首先, 构造代价函数序列$\{J^{(i)}(x)\}$和控制序列$\{u^{(i)}(x)\}$, 然后, 从一个初始容许控制律开始进行逐次迭代.策略迭代算法包括基于式(5)的策略评估和基于式(9)的策略更新[5], 而且能够最终收敛到最优代价函数和最优控制律, 即当$i \to \infty$时, $J^{(i)}(x)\to J^{*}(x)$且$u^{(i)}(x)\to u^{*}(x)$.这种收敛性证明已经在文献[17]和里面的参考文献中给出.尽管如此, 得到Lyapunov方程的精确解仍然是困难的.于是, 人们提出一类近似方法来克服这一难题[34-39, 41-42].这就促使基于ADP方法的神经控制设计的产生与发展.除此之外, 上述迭代过程往往依赖系统的动态信息$f(x)$和$g(x)$.事实上, 近年来出现的一些方法已经放松了这一要求, 如积分策略迭代算法[28]、神经网络辨识方法[55]和探测信号方法[66], 而且关于这一主题的研究还在进一步深入.这也符合数据驱动控制与学习系统设计的发展趋势.
1.2 神经网络实现与稳定性分析
在自适应评判设计中, 往往需要构建不同类型的神经网络.虽然具体实施过程中可能涉及多种模块, 比如模型网络[18]和执行网络[18, 22], 但是, 评判网络是最重要的模块.不同的模块配置反映控制器设计者的不同目标.其中, 具有单一评判网络结构的处理方法, 主要强调设计过程的简易性[53, 56].
在神经网络实现中, 我们考虑通用逼近性质, 将最优代价函数$J^{*}(x)$在紧集$\Omega$上表示为
$$ \begin{align}\label{Eq49002} J^{*}(x)=\omega_{c}^{\rm T}\sigma_{c}(x)+\varepsilon_{c}(x) \end{align} $$ (11) 其中, $\omega_{c}\in {\bf R}^{l_c}$是理想的权值向量, $l_c$是隐含层神经元个数, $\sigma_{c}(x)\in {\bf R}^{l_c}$是激活函数, $\varepsilon_{c}(x)\in {\bf R}$是重构误差.对于一般的非线性情形, 理想权值向量$\omega_{c}$和重构误差$\varepsilon_{c}$是未知的, 但均有界.易知, 最优代价函数的梯度是$\nabla J^{*}(x)=(\nabla \sigma_{c}(x))^{\rm T}\omega_{c}+\nabla \varepsilon_{c}(x) $.由于理想权值是未知的, 我们构建一个评判神经网络
$$ \begin{align} \label{Eq55019}\hat{J}^{*}(x)=\hat{\omega}_{c}^{\rm T}\sigma_{c}(x) \end{align} $$ (12) 来逼近最优代价函数, 其中$\hat{\omega}_{c}\in {\bf R}^{l_c}$表示估计的权值向量.类似地, 梯度向量为$\nabla \hat{J}^{*}(x)=(\nabla \sigma_{c}(x))^{\rm T}\hat{\omega}_{c} $.
需要指出的是, 评判网络的具体结构往往通过实验选择, 并根据工程经验和直觉确定, 需要在控制精度和计算复杂度之间进行权衡[17].
考虑反馈表达式(9)和神经网络表达式(11), 最优控制律可以写成与权值相关的形式
$$ \begin{align} \label{Eq36009} u^*(x) = -\frac{1}{2}R^{-1} g^{\rm T} (x) \big[(\nabla \sigma_{c}(x))^{\rm T} \omega_{c} + \nabla \varepsilon_{c}(x)\big] \end{align} $$ (13) 利用评判网络(12), 近似的最优反馈控制函数为
$$ \begin{align} \label{Eq55008} \hat{u}^*(x)=-\frac{1}{2}R^{-1}g^{\rm T}(x)(\nabla \sigma_{c}(x))^{\rm T}\hat{\omega}_{c} \end{align} $$ (14) 基于神经网络描述, 近似的Hamiltonian为
$$ \begin{align}\label{Eq0221} \hat H (x, &\ \hat{u}^*(x), \nabla \hat{J}^{*}(x)) = U(x, \hat{u}^*(x))+ \nonumber\\ &\ \hat \omega_c^{\rm T}\nabla \sigma_c(x) [f(x)+g(x)\hat{u}^*(x)] \end{align} $$ (15) 根据式(10)和式(15)定义误差量$e_c=\hat H (x, \nabla \hat{J}^{*}(x)) -H(x, \nabla J^{*}(x))$, 也即$e_{c} = \hat H (x, \hat{u}^*(x), \nabla \hat{J}^{*}(x))$成立.为了训练评判网络使得目标函数$E_{c}=0.5e_{c}^{2}$最小化, 一般采用经典的梯度下降法:
$$ \begin{align} \label{Eq55001} \dot{\hat{\omega}}_{c}=-\alpha_{c}\bigg(\frac{\partial E_{c}}{\partial \hat{\omega}_{c}}\bigg) \end{align} $$ (16) 来调整权值向量, 其中, 常数$\alpha_{c}>0$是学习率标量.这里, 通常会引入一个与$l_c$-维向量$\phi = {\partial e_{c}}/{\partial \hat \omega_c} $相关的归一化正项, 以改善学习效果.在引入折扣因子时, 会出现一个与之相关的项$-\gamma\sigma_{c}(x)$, 从而影响梯度下降法的学习过程.进一步地, 定义理想权值与其估计值之间的误差为$\tilde \omega_c= \omega_c-\hat \omega_c$, 则有$\dot{\tilde \omega}_c= -\dot{\hat \omega}_c$, 由此展开可以得到评判网络的权值误差动态.
在自适应评判设计中, 我们旨在确定评判网络的权值参数以近似最优的代价函数.正如传统自适应控制的要求[46], 在自适应评判控制中, 也需要满足一定的持续激励条件.进而, 根据文献[22], 如果近似最优控制律由式(14)给出, 同时评判网络的权值按照式(16)进行训练, 则闭环系统状态向量和评判网络权值误差都将最终一致有界稳定.进一步地, 可以得到:近似最优控制律$\hat{u}^*(x)$能够收敛到其最优值$u^{*}(x)$的一个小邻域内, 而且这个邻域可以通过设定相关参数(如评判网络学习率)使其任意小.
1.3 改进评判网络学习准则
传统的自适应评判控制设计常常依赖初始稳定控制律.但是, 在实际控制工程中, 往往难以获得初始稳定控制律[22, 55, 66-67], 这在一定程度上缩小了ADP方法的应用范围.一般来说, 需要通过试错的办法, 选择一个初始的权值向量来创建一个初始的稳定控制, 然后开始训练过程.否则, 一个不稳定的控制律可能导致闭环系统不稳定.这激励人们努力放宽对于初始条件的限制[26, 54, 69-71].这一重要思想来源于文献[69], 它采用分段函数来减少初始条件和检测稳定性, 但理论证明比较复杂.于是, 我们针对传统的自适应评判框架, 增加一个额外的强化模块, 以改进评判网络学习准则, 实现在线优化调节, 同时能够简化理论分析[58, 72-73].在具体的神经网络实施过程中, 通过选取合适形式的Lyapunov函数$J_{s}(x)$, 例如$J_{s}(x)=0.5x^{\rm T}x$, 可以有助于自适应评判系统学习性能的提高[58, 72-73].文献[73]已经证明在改进学习规则下的闭环系统稳定性.
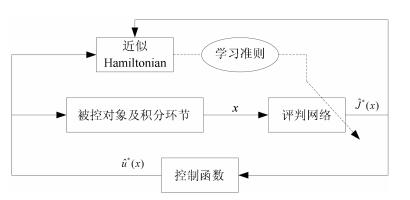
基于学习的自适应评判控制结构图如图 1所示, 其中, 实线表示信号流线, 虚线表示神经网络反向传播路径, 而神经网络的学习准则是关键设计模块.
在下面的几个部分中, 我们将面向动态系统的不确定因素, 以自适应评判思想为基础, 阐述基于智能学习的鲁棒自适应评判控制设计近些年来的主要成果, 包括自学习鲁棒镇定, 自适应轨迹跟踪, 事件驱动鲁棒控制, 以及自适应$H_{\infty}$控制设计等.
2. 鲁棒自适应评判控制设计
这里介绍不确定环境下非线性系统自学习鲁棒控制设计的主要方法, 包括基于最小二乘的问题转换方法[51-52], 基于自适应评判的问题转化方法[53-60], 基于数据的问题转换方法[61-62], 组合滑模控制方法[63]和鲁棒ADP方法[64-68].在文献[53]中, 针对具有匹配不确定项的连续时间非线性系统, 作者提出一种新颖的策略迭代算法实现自学习鲁棒镇定.随后, 该方法被推广应用于处理具有未知动态[55]和输入约束[56]非线性系统的鲁棒控制问题.值得一提的是, 针对离散时间非线性系统, 文献[57]也给出了鲁棒自适应评判控制设计的初步成果.为了改善评判神经网络的学习规则, 文献[58]建立了实现非线性系统自适应优化控制的改进方法, 并进一步研究了非线性系统的鲁棒镇定问题.此外, 文献[59]还研究了具有非匹配形式不确定项的非线性系统鲁棒控制问题.随后, 文献[60]扩展文献[54]中的方法, 研究同时含有匹配不确定项和外部扰动的鲁棒控制设计.另外, 为了讨论鲁棒控制器的最优性, 文献[61]建立新颖的匹配非线性系统数据驱动鲁棒最优控制方法.通过积分强化学习, 文献[62]研究了一类具有控制约束未知非线性系统的鲁棒自适应控制.
从研究对象来看, 针对特殊匹配形式不确定系统的自学习鲁棒镇定是设计基础, 而文献[51-52, 59, 65-68]研究了具有非匹配不确定项的自适应鲁棒控制设计.最近, 针对具有一般形式不确定项的非线性系统, 文献[74]提出基于改进学习规则的鲁棒自适应评判控制方案, 而文献[75]从问题转化的角度进行神经网络控制设计, 研究对象逐渐广义化.
如果在动态系统(1)中引入不确定项, 我们就必须关注所设计控制器的鲁棒性.考虑一类含有不确定项的连续时间非线性系统
$$ \begin{equation} \label{Eq51003} \dot{x}(t)=f(x(t))+g(x(t))[u(t)+d(x(t))] \end{equation} $$ (17) 其中, 表达式$g(x)d(x)$反映了一种和控制矩阵匹配的动态不确定项.通常假设$d(0)=0$, 以保持$x=0$是被控系统的平衡点.又假设表达式$d(x)$是有界的, 即$\|d(x)\| \ \leq d_{M}(x) $, 这里$d_{M}(x)$是一个已知函数且满足$d_{M}(0)=0$.
考虑不确定非线性系统(17), 为了解决鲁棒镇定问题, 需要设计一个控制律$u(x)$, 使得闭环系统在考虑不确定性的情况下稳定.引入一个正数$\rho$并且指定$Q(x)=\rho d_{M}^{2}(x)$, 鲁棒镇定问题能够通过设计系统(1)的最优控制器进行求解.这里, 代价函数仍然为式(3)的形式, 但是效用函数取为
$$ \begin{align} \label{Eq51001} U(x(t), u(t))= \rho d_{M}^{2}(x(t))+u^{\rm T}(t)Ru(t) \end{align} $$ (18) 值得注意的是, 即使采用改进的效用函数, 最优控制函数却保持不变.考虑系统(1)和基于改进效用函数(18)的代价函数(3), Hamiltonian变为
$$ \begin{align} \label{Eq048} H(x, &\ u(x), \nabla J(x))= \rho d_{M}^{2}(x)+u^{\rm T}(x)Ru(x)+\nonumber\\&\ (\nabla J(x))^{\rm T} [f(x) + g(x)u(x)] \end{align} $$ (19) 基于改进的效用函数(18), 并再次使用最优控制律(9), 得到改进的最优控制问题的HJB方程为
$$ \begin{align} \label{Eq51002} 0=&\ \rho d_{M}^{2}(x)+(\nabla J^{*}(x))^{\rm T}f(x)- \nonumber\\ &\ \frac{1}{4}(\nabla J^{*}(x))^{\rm T}g(x)R^{-1}g^{\rm T}(x)\nabla J^{*}(x) \end{align} $$ (20) 且有$J^{*}(0)=0$.
文献[53]和[58]分别给出了应用近似最优控制律(14)时, 被控对象标称部分(1)和原始不确定系统(17)的最终一致有界稳定性.应该特别注意的是, 在使用近似最优控制律时, 得到闭环系统最终一致有界稳定[58], 这不同于采用精确最优控制律时的渐近稳定结论[53].此外, 文献[54-55, 61]也讨论了鲁棒控制器的最优性.这是通过给系统(1)的最优反馈控制律(9)增加适当的反馈增益$\pi$和定义特殊的代价函数得到的, 其中, 引入反馈增益后的控制律为
$$ \begin{align} \label{Eq55016} \bar{u}(x) = \pi u^{*}(x)=-\frac{1}{2}\pi R^{-1}g^{\rm T}(x) \nabla J^{*}(x) \end{align} $$ (21) 关于反馈增益的取值对于闭环系统稳定性的影响, 已在文献[54-55, 61]中给出.总的来说, 我们应该设计标称系统的最优控制律, 然后实现原始系统的鲁棒镇定, 也就是说, 可以利用自适应评判思想和神经网络技术来设计有效的鲁棒最优控制器.
为了减少对于系统模型的依赖, 积分策略迭代算法[32]也被用来求解基于ADP的鲁棒控制问题[61-62].为此, 我们考虑引入受限探测信号$\vartheta(t)$的非线性系统, 如下所示
$$ \begin{equation} \dot{x}(t)=f(x(t))+g(x(t))[u(t)+\vartheta(t)] \end{equation} $$ (22) 在线积分策略迭代算法从$i=0$开始进行, 并且在每一步迭代中同时求解$\{J^{(i)}(x), u^{(i)}(x)\}$.由于在积分方程中没有出现$f(x)$和$g(x)$, 因此建立了不需要动态模型的数据驱动策略学习方法.
在文献[63]中, 具有混合结构的滑模控制器的表达式为$u=u^{\text{a}}+u^{\text{s}}$, 其中, 前一部分$u^{\text{a}}$是基于ADP的控制律, 用来镇定滑模动态并且保证次优性能, 而后者$u^{\text{s}}$是不连续控制策略, 设计目的是减小干扰的影响和保证滑模面的可达性.该方法融合了滑模控制的思想, 并扩展了文献[53, 55-56, 59-60]中的结果.
鲁棒ADP方法[64-68]是对于具有不确定项的线性和非线性系统经典ADP方法的重要延伸, 它综合了现代非线性控制理论的几种工具, 如鲁棒再设计和反推技术以及非线性小增益定理[76]等关键策略.文献[66]考虑如下形式的一类非线性系统
$$ \dot{\varsigma}=\delta_{\varsigma}(\varsigma, x) $$ (23a) $$ \dot{x}=f(x)+g(x)[u+\delta(\varsigma, x)] $$ (23b) 其中, $\varsigma$是状态变量的不可测部分, $\delta_{\varsigma}$和$\delta$是未知局部Lipschitz函数.这里的设计目标是找到一个在线控制律来镇定原始不确定系统, 并且在不考虑动态不确定因素时(即$\delta=0$且没有$\varsigma$-子系统), 使其成为最小化标称系统代价函数的最优控制律.这里, 鲁棒性是针对不确定系统的, 而最优性则是针对标称系统讨论的.此外, 这种方法也扩展到了具有非匹配动态不确定项的非线性系统[66]和大规模的复杂系统[67-68].文献[67]和[68]分别研究分散大规模系统最优控制和关联系统输出反馈控制问题, 这也使得鲁棒ADP技术更加完善.
3. 自学习鲁棒跟踪控制设计
自适应评判技术在最优调节器设计中取得了重要进展之外, 也常常应用于非线性系统的轨迹跟踪控制问题.以往的很多成果主要是针对确定系统的跟踪控制设计, 没有考虑不确定因素, 如文献[25, 29].近年来, 关于不确定环境下的鲁棒轨迹跟踪, 在一些主流刊物上也报道了一些最新成果[77-79].
考虑一类含有不确定项的连续时间非线性系统
$$ \begin{equation} \label{Eq0201} \dot{x}(t)=f(x(t))+g(x(t))u(t)+\Delta f(x(t)) \end{equation} $$ (24) 其中, $x(t)\in \Omega \subset{ {\bf R}}^n$是状态向量并且$u(t)\in {\bf R}^m$是控制向量, $f(\cdot)$和$g(\cdot)$可微且满足$f(0)=0$, $\Delta f(x)$是不确定项且有$\Delta f(0)=0$.这里, 令$x(0)=x_{0}$为初始状态并且假设不确定项$\Delta f(x)$有界, 即$\|\Delta f(x)\| \ \leq \lambda_{f}(x) $, 其中, 已知函数$\lambda_{f}(x)$满足$\lambda_{f}(0)=0$.
为了研究轨迹跟踪问题, 引入一个参考系统
$$ \begin{align} \label{Eq60001} \dot{r}(t)=\varphi(r(t)) \end{align} $$ (25) 其中, $r(t) \in {\bf R}^n$代表有界的目标轨迹且满足$r(0)=r_{0}$.这里假设$\varphi(r(t))$是一个Lipschitz连续函数同时满足$\varphi(0)=0$.定义轨迹跟踪误差为
$$ \begin{align} \label{Eq60002} z(t)=x(t)-r(t) \end{align} $$ (26) 并且初始误差向量为$z(0)=z_{0}=x_{0}-r_{0}$.联立式(24) ~ (26), 我们可以得到跟踪误差动态为
$$ \begin{align} \label{Eq60003} \dot{z}(t) = f(x(t)) - \varphi(r(t)) + g(x(t))u + \Delta f(x(t)) \end{align} $$ (27) 考虑到$x(t)=z(t)+r(t)$, 系统(27)可以改写为
$$ \begin{align} \label{Eq60004} \dot{z}(t)=&\ f(z(t)+r(t))+g(z(t)+r(t))u(t)-\nonumber\\&\ \varphi(r(t))+\Delta f(z(t)+r(t)) \end{align} $$ (28) 这里, 定义增广状态向量$\xi(t)=[z^{\rm T}(t), r^{\rm T}(t)]^{\rm T} \in {\bf R}^{2n} $且$\xi(0)=\xi_0=[z^{\rm T}_{0}, r^{\rm T}_{0}]^{\rm T}$是它的初始条件, 那么, 基于式(25)和(28), 增广系统动态可以简洁描述为
$$ \begin{align} \label{Eq60005} \dot{\xi}(t)=\mathcal{F}(\xi(t))+\mathcal{G}(\xi(t))u(t)+\Delta \mathcal{F}(\xi(t)) \end{align} $$ (29) 其中, $ \mathcal{F}(\cdot)$和$ \mathcal{G}(\cdot)$是新的系统矩阵和控制矩阵, 而$\Delta \mathcal{F}(\xi)$是新的不确定项.它们的具体形式为
$$ \mathcal{F}(\xi(t))=\left[ \begin{array}{c} f(z(t)+r(t))-\varphi(r(t)) \\ \varphi(r(t)) \\ \end{array} \right] $$ (30a) $$ \mathcal{G}(\xi(t))=\left[ \begin{array}{c} g(z(t)+r(t)) \\ 0_{n \times m} \\ \end{array}\right] $$ (30b) $$ \Delta \mathcal{F}(\xi(t))=\left[ \begin{array}{c} \Delta f(z(t)+r(t)) \\ 0_{n \times 1} \\ \end{array} \right] $$ (30c) 由于
$$ \begin{align} \label{Eq60010}\|\Delta \mathcal{F}(\xi)\| =&\ \|\Delta f(z+r)\| =\|\Delta f(x)\| \leq \nonumber\\&\ \lambda_{f}(x) = \lambda_{f}(z+r) := \lambda_{f}(\xi) \end{align} $$ (31) 因此, 新的不确定项仍然是有上界的.
为了达到被控系统(24)对于参考轨迹(25)鲁棒跟踪的目标, 可以构造一个增广动态系统(29), 并设计一个反馈控制律$u(\xi)$, 在其作用下, 闭环系统对于$\Delta\mathcal{F}(\xi)$是渐近稳定的.文献[78]已经证明:这一问题可以转化为具有适当代价函数的标称增广系统最优控制设计.为此, 考虑增广系统(29)的标称部分
$$ \begin{equation} \label{Eq0203} \dot{\xi}(t)=\mathcal{F}(\xi(t))+\mathcal{G}(\xi(t))u(t) \end{equation} $$ (32) 为了设计控制律$u(\xi)$以最小化代价函数
$$ \begin{equation} \label{Eq0204} J(\xi(t))=\int_{t}^{\infty}\big\{\mathcal{Q}(\xi(\tau))+U(\xi(\tau), u(\tau))\big\}\text{d}\tau \end{equation} $$ (33) 其中, $\mathcal{Q}(\xi) \geq 0$是额外的效用项, 而$U(\xi, u)$是效用函数的主体部分, $U(0, 0)=0$, 并且对于所有的$\xi$和$u$都有$U(\xi, u)\ge 0$成立.这里, 效用函数的主体部分仍然选择经典的二次型形式$U(\xi, u)=\xi^{\rm T}\bar{Q}\xi+u^{\rm T}Ru$, 其中, $\bar{Q}=\text{diag}\{Q, 0_{n \times n}\}$, 而$Q\in{ {\bf R}}^{n\times n}$和$R\in{ {\bf R}}^{m\times m}$同为正定矩阵.值得注意的是, 这里提出的代价函数(33)同时反映了不确定项, 调节项和控制项的信息, 其中, $\mathcal{Q}(\xi)$是和不确定因素密切相关的.
这样一来, 针对标称增广系统和特殊定义的代价函数, 我们就可以定义Lyapunov方程, 通过自适应评判控制设计, 来近似最优代价函数
$$ \begin{equation} \label{Eq0208} J^{*}(\xi(t)) = \min\limits_{u \in \mathcal{A}(\Omega)}\int_{t}^{\infty} \big\{\mathcal{Q}(\xi(\tau)) + U(\xi(\tau), u(\tau))\big\}\text{d}\tau \end{equation} $$ (34) 和最优控制律
$$ \begin{align} \label{Eq0210} u^{*}(\xi)=-\frac{1}{2}R^{-1}\mathcal{G}^{\rm T}(\xi) \nabla J^{*}(\xi) \end{align} $$ (35) 这里的核心问题在于给出额外效用项的具体描述.文献[78]中指出的
$$ \begin{equation}\label{Eq0212} \mathcal{Q}(\xi)=\frac{1}{4}(\nabla J(\xi))^{\rm T}\nabla J(\xi)+\lambda_{f}^{2}(\xi) \end{equation} $$ (36) 就是一种实用的形式.通过这一项, 可以很好地定义整个效用函数和代价函数(33), 进而将鲁棒跟踪控制问题转化为近似求解一个特殊的HJB方程.
4. 事件驱动框架下的鲁棒自适应评判控制
随着网络化技术的快速发展, 越来越多的控制系统需要通过通信媒介进行信号传输, 因此使得网络化系统的通信负担不断加剧.如何减轻这种日益严重的通信负担, 激发人们开展关于事件驱动机制的研究[80-81].在事件驱动机制下, 只有满足一定的条件才能更新执行器, 以保证目标系统的稳定性和控制效果的合理性.将事件驱动机制与自适应评判技术相结合, 不仅可以节省通信负担, 同时可以实现智能优化, 因此受到了广泛关注[82-90].针对非线性连续时间系统, 文献[82]提出一种基于执行-评价框架和神经网络技术的最优自适应事件驱动控制方法, 为事件驱动机制应用于ADP领域打下了基础.
定义一个单调递增的事件触发序列$\{s_{j}\}_{j=0}^{\infty}$, 其中$s_{j}$代表第$j$个连续采样时刻, $j\in{\bf N}$.那么, 在$t \in [s_{j}, s_{j+1})$时, 采样设备的输出用$\hat{x}_{j}=x(s_{j})$表示, 称为采样状态.定义在当前状态和采样状态之间的误差函数为事件驱动误差, 即
$$ \begin{align} \label{Eq100} e_{j}(t)=\hat{x}_{j}-x(t), \forall t \in [s_{j}, s_{j+1}) \end{align} $$ (37) 在事件驱动控制器设计中, 定义合理的驱动条件扮演着重要角色.在$t=s_{j}$时刻, 如果不满足驱动条件就会发生事件触发.在每一个触发时刻, 系统状态经过采样, 将驱动误差$e_{j}(t)$重置为零, 并更新控制信号$u(x(s_{j}))=u(\hat{x}_{j}):=\mu(\hat{x}_{j})$.控制信号$\{\mu(\hat{x}_{j})\}_{j=0}^{\infty}$通过零阶保持器设备的作用变为分段信号, 由此得到控制输入是一个分段的常值函数.
在此基础上, 考虑不确定因素, 文献[87]将事件驱动机制应用于系统(17)的自学习鲁棒控制设计.这时, 代价函数仍然定义为式(3)且效用函数为
$$ \begin{align} \label{Eq55120} U(x, u)= \rho d_{M}^{2}(x)+ x^{\rm T}Qx+u^{\rm T}Ru \end{align} $$ (38) 其中, $Q = Q^{\rm T} >0 $.在传统的时间触发情形下, 利用式(38)的效用函数, HJB方程为
$$ \begin{align} \label{Eq55121} H(x, & u^{*}(x), \nabla J^{*}(x))= \nonumber\\& \rho d_{M}^{2}(x)+x^{\rm T}Qx+ u^{*{\rm T}}(x)Ru^{*}(x)+\nonumber\\& (\nabla J^{*}(x))^{\rm T}[f(x)+g(x)u^{*}(x)] \end{align} $$ (39) 在事件驱动机制下, 控制信号是基于采样状态$\hat{x}_{j}$得到的, 而不是根据实时的状态向量$x(t)$.于是, 传统的最优控制函数(9)变成了如下的事件驱动形式:
$$ \begin{align} \label{Eq103} \mu^{*}(\hat{x}_{j})=-\frac{1}{2}R^{-1}g^{\rm T}(\hat{x}_{j}) \nabla J^{*}(\hat{x}_{j}) \end{align} $$ (40) 其中, $\nabla J^*(\hat x_j)=(\partial J^*(x)/\partial x)|_{x=\hat x_j}$.同理, 事件驱动机制下的HJB方程为
$$ \begin{align} \label{Eq105} H(x, & \mu^{*}(\hat{x}_{j}), \nabla J^{*}(x))= \nonumber\\ & \rho d_{M}^{2}(x)+x^{\rm T}Qx +\mu^{*{\rm T}}(\hat{x}_{j})R\mu^{*}(\hat{x}_{j})+\nonumber\\ & (\nabla J^{*}(x))^{\rm T}[f(x)+g(x)\mu^{*}(\hat{x}_{j})] \end{align} $$ (41) 值得注意的是, 事件驱动HJB方程(41)一般不等于零.但是, 时间驱动HJB方程(39)和事件驱动HJB方程(41)却满足如下的关系
$$ \begin{align}\label{Eq68001} H(x, &\ u^{*}(x), \nabla J^{*}(x)) - H(x, \mu^{*}(\hat{x}_{j}), \nabla J^{*}(x)) = - \nonumber\\ & [u^{*}(x)-\mu^{*}(\hat{x}_{j})]^{\rm T}R[u^{*}(x)-\mu^{*}(\hat{x}_{j})] \end{align} $$ (42) 在事件驱动框架下, $\mu^{*}(\hat{x}_{j})$一般不等于$u^{*}(x)$, 因此, 式(42)通常不为零.
文献[82]提出的事件驱动最优控制方法为将其扩展到鲁棒控制设计提供了可能.在设计合理的阈值条件下, 文献[87-90]给出了实现不确定非线性系统鲁棒镇定的驱动条件, 建立了事件驱动框架下的鲁棒自适应评判控制理论与方法, 同时也进行了避免发生Zeno行为[80-81]的理论分析.
不论是基于智能学习的鲁棒自适应评判控制, 还是鲁棒跟踪, 或者是事件驱动鲁棒镇定设计, 在进行适当的问题转化之后, 都包括两个主要步骤: 1)对于标称系统的智能评判学习; 2)对于不确定系统的鲁棒控制实现.例如, 对于事件驱动鲁棒自适应评判控制, 这一过程的简易框图如图 2所示, 其中, 阶段Ⅰ是智能评判学习过程, 阶段Ⅱ是利用最终的权值进行鲁棒控制实现, 正项$e_T$和$\hat{e}_T$代表不同阶段的阈值, 对于驱动机制的实施具有重要作用.
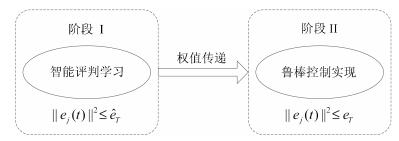 图 2 事件驱动鲁棒自适应评判控制设计过程图Fig. 2 The design procedure of event-triggered robust adaptive critic control
图 2 事件驱动鲁棒自适应评判控制设计过程图Fig. 2 The design procedure of event-triggered robust adaptive critic control5. 基于学习的自适应$\pmb H_{\bf\infty}$控制设计
如前文所述, 未知参数和外部扰动的广泛存在, 使得设计具有鲁棒特性的控制器变得非常重要.经典的$H_{\infty}$控制针对包含外部扰动和不确定项的动态系统, 构建考虑最坏情形的控制律.根据极大极小最优性原理, $H_{\infty}$控制问题通常被描述为二人零和微分博弈.为了得到在最坏情况下使得代价函数最小化的控制器, 需要寻找对应于Hamilton-Jacobi-Isaacs (HJI)方程的Nash均衡解.然而, 对于一般的非线性系统, 获得HJI方程的解析解是不容易的, 这如同求解非线性最优控制问题HJB方程时遇到的困难.近些年来, ADP思想已被广泛应用于求解$H_{\infty}$控制问题.与自适应最优调节设计类似, 这里称作自适应$H_{\infty}$控制设计, 如文献[91-96]和其中的参考文献.
考虑一类含有外部扰动的连续时间非线性系统
$$ \dot{x}(t)=f(x(t))+g(x(t))u(t)+h(x(t))v(t) $$ (43a) $$ \zeta(t)=y(x(t)) $$ (43b) 其中, $v(t)\in {\bf R}^q$是满足$v(t) \in \mathcal{L}_{2}[0, \infty)$的扰动向量, $\zeta(t)=y(x(t))\in {\bf R}^p$是目标输出, 并且$h(\cdot)$是可微的.
在非线性$H_{\infty}$控制设计中, 通常需要找到一个反馈控制律$u(x)$, 使得闭环系统渐近稳定且具有不大于$\varrho$的$\mathcal{L}_{2}$-增益, 即
$$ \begin{align}\label{Eq36001} \int_{0}^{\infty} \big[\|y(x(\tau))\|^{2}+& u^{\rm T}(\tau)Ru(\tau)\big]\text{d}\tau \leq \nonumber\\& \varrho^{2}\int_{0}^{\infty}v^{\rm T}(\tau)Pv(\tau)\text{d}\tau \end{align} $$ (44) 其中, $\|y(x(t))\|^{2}=x^{\rm T}(t)Qx(t)$, $Q$, $R$, $P$是具有合适维数的对称正定有界矩阵.值得一提的是, $H_{\infty}$控制问题的解是零和博弈理论的鞍点并由一对控制律$(u^{*}, v^{*})$表示, 其中, $u^{*}$和$v^{*}$分别称为最优控制律和最坏情况下的扰动函数.
$$ \begin{align}U(x, u, v)= x^{\rm T}Qx+u^{\rm T}Ru-\varrho^{2}v^{\rm T}Pv\end{align} $$ (45) 并且定义代价函数为
$$ \begin{align} \label{Eq003} J(x(t), u, v)=\int_{t}^{\infty}U(x(\tau), u(\tau), v(\tau))\text{d}\tau \end{align} $$ (46) 我们的目标是找到鞍点解$(u^{*}, v^{*})$, 使得Nash条件
$$ \begin{align} J^{*}(x_{0}) = \min\limits_{u}\max\limits_{v}J(x_{0}, u, v) = \max\limits_{v}\min\limits_{u}J(x_{0}, u, v) \end{align} $$ (47) 成立, 其中, $J^{*}(x_{0})$代表最优代价.对于容许控制$u \in \mathcal{A}(\Omega)$, 如果相关的代价函数(46)是连续可微的, 那么非线性Lyapunov方程为
$$ \begin{align} %\label{Eq005} 0 = U(x, u, v)+(\nabla J(x))^{\rm T}(f+gu+hv) \end{align} $$ (48) 其中, $J(0)=0$.定义被控系统的Hamiltonian为
$$ \begin{align} H(x, &\ u, v, \nabla J(x))= U(x, u, v)+\nonumber\\&\ (\nabla J(x))^{\rm T} (f+gu+hv) \end{align} $$ (49) 利用文献[95]中的结论, 最优控制律和最坏情形的扰动函数分别为
$$ u^{*}(x)=-\frac{1}{2}R^{-1}g^{\rm T}(x) \nabla J^{*}(x) $$ (50a) $$ v^{*}(x)=\frac{1}{2\varrho^{2}}P^{-1}h^{\rm T}(x) \nabla J^{*}(x) $$ (50b) 于是, 此类问题的HJI方程为下面的形式:
$$ \begin{align} \label{Eq010} 0= & U(x, u^{*}, v^{*})+(\nabla J^{*}(x))^{\rm T} (f+gu^{*}+hv^{*})=\nonumber\\ &H(x, u^{*}, v^{*}, \nabla J^{*}(x)) \end{align} $$ (51) 其中, $J^{*}(0)=0$.利用自适应评判进行$H_{\infty}$控制设计的核心就是构建并训练评判网络, 以近似求解非线性的HJI方程(51).最近, 在事件驱动机制下的自适应$H_{\infty}$控制设计也得到了人们的关注[97-99], 基本的设计框图如图 3所示, 其中的主要组件包括被控对象及积分环节, 评判神经网络, 通信网络媒介, 采样设备组件, 以及零阶保持组件.图 3中的符号$\hat{x}_{j}$是通过网络媒介并由采样设备处理后的事件驱动状态向量, $\hat{J}(\hat{x}_{j})$是评判网络的输出量, $\mu(\hat{x}_{j})$和$v(x)$分别是控制函数和扰动函数输出, 与近似Hamiltonian相关的$e_c$是训练评判网络的基本误差量.值得关注的是, 文献[97]提出基于更新准则的评判网络学习机制, 即
$$ \begin{align} \label{Eq0223}\dot{\hat{\omega}}_{c}=&-\alpha_{c}\frac{\phi}{(1+\phi^{\rm T}\phi)^{2}}e_{c}+\frac{1}{2}\alpha_{s}\bigg[\nabla \sigma_{c}(\hat{x}_{j})g(\hat{x}_{j})\times \nonumber\\&\ g^{\rm T}(x)-\frac{1}{\varrho^{2}}\nabla \sigma_{c}(x)h(x)h^{\rm T}(x)\bigg]\nabla J_{s}(x) \end{align} $$ (52)  图 3 事件驱动自适应$H_{\infty}$控制结构图Fig. 3 Structure of event-triggered adaptive $H_{\infty}$ control
图 3 事件驱动自适应$H_{\infty}$控制结构图Fig. 3 Structure of event-triggered adaptive $H_{\infty}$ control这样, 在基本学习率$\alpha_{c}$和附加调整因子$\alpha_{s}>0$的共同作用下, 控制设计者可以根据实际情况建立更加有效的控制器, 而减缓初始条件限制更具实用意义.
考虑到不确定因素和外部扰动的广泛存在, 利用ADP这一智能学习技术, 构建鲁棒自适应评判系统, 实现复杂非线性系统的自学习鲁棒控制与自适应$H_{\infty}$控制, 具有重要的理论与实际意义.鲁棒自适应评判控制理论与方法, 仍然是相关领域的研究热点, 更多富有意义的成果将不断涌现.
6. 总结与展望
由于在解决复杂系统智能控制和决策问题方面的优势, 基于智能学习的自适应评判控制设计已经有许多成功的应用.复杂的工业系统, 如电力与能源系统[23, 31, 64-68, 85, 100-105], 机械系统[13-14, 26, 58, 60, 66, 78, 106], 智能交通系统[107-108]是最常见的应用领域.文献[103]提出针对频率控制问题的自适应评判设计方法, 以实现智能电网的频率稳定.文献[105]建立一种基于天气分类的新型电能自适应优化方法, 能够有效管理电能流动, 平衡电网负载, 而且实施错峰用电可以减少居民的电费支出.文献[106]针对运载工业中常用的吊车系统, 设计有效的自适应优化控制方案.文献[107]和[108]则分别给出ADP方法在交通信号控制和车联网技术方面的研究成果, 为建立智能交通系统提供了一定的方法保障.除此之外, 很多学者仍然在开展大量具有实际应用背景的研究工作, 以期取得更加显著的经济和社会效益.
尽管在自适应评判控制及鲁棒镇定设计方面, 已经有很多优秀的成果, 但是仍然需要进一步研究策略学习算法的收敛性和被控系统的稳定性以及最优性与鲁棒性等各种基础问题.例如, 克服神经网络逼近的缺点, 实现全局最优镇定就值得进一步研究.如何进一步降低策略学习算法对于初始条件的依赖也是很有意义的主题.关于离散时间系统的鲁棒自适应评判控制, 也期待有更多的研究成果出现, 以完善复杂动态系统的智能化设计体系.结合抽象动态规划[109]理论进行自适应评判设计也是一个有趣的方向.另外, 强化学习系统的一个重要特性是可以高效利用数据资源.如何更加有效地利用数据信息来建立更为先进的数据驱动控制方法是非常关键的.在这一主题上, 迭代神经动态规划算法[20-21], 积分强化学习技术[32], 计算控制方法[43]和并行学习算法[98]都是有意义的尝试.特别地, 将深度学习与ADP及强化学习相结合产生的深度强化学习, 不仅已经在AlphaGo Zero [6]中取得了重大成功, 还将有助于我们构建更多的智能系统并实现更高水平的类脑智能.深度强化学习能够直接基于图像的输入来输出控制信号, 同时具备深度学习的感知能力和强化学习的决策优点[2].这种机制使得人工智能与人类的思维模式非常接近, 因此, 迫切需要深入地研究其在自适应评判设计中的应用.同时, 在考虑不确定因素和鲁棒性能的情况下, 如何得到含有高效数据驱动和智能学习组件的鲁棒最优控制策略, 也需要进一步研究.此外, 对于网络化系统, 充分考虑通信因素是很有必要的.需要深入讨论事件驱动机制的实施办法, 不局限于针对控制函数.如何将基于数据的方法与事件驱动机制相结合, 进行混合数据-事件驱动控制也是很有意义的.这样不仅可以高效利用数据资源, 而且可以显著降低通信负担, 实现有效的混合驱动控制, 进而可以推广研究混合驱动的鲁棒轨迹跟踪和$H_{\infty}$控制设计.最后, 需要将现有的结果扩展到多智能体系统, 以实现网络化系统的分布式协同优化.所以, 在不确定环境下, 基于自适应评判的分布式设计与分散控制设计是处理复杂系统智能控制与管理问题的另一个很有发展前景的方向.
近年来, 脑科学与类脑智能的研究已经引起各国学者的极大兴趣.越来越多的证据表明, 最优性在理解大脑智能的研究中具有重要作用.考虑以在线方式实现对具有不确定性和未知动态的复杂系统进行最优决策和智能控制这一宗旨, ADP可以为智能系统和类脑智能研究做出相当大的贡献.正如其创始人Werbos博士指出的, ADP很可能是实现真正意义类脑智能的关键方法[110].因此, 为降低计算量和通信负担的近似动态规划解决方案, 包括保证稳定性、收敛性、最优性和鲁棒性的研究仍然需要大批学者的努力, 其中, 基于智能学习的鲁棒自适应评判控制设计也一定能够取得更大的进展.
-

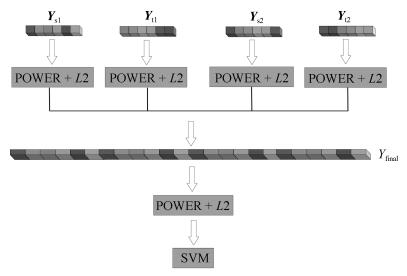
图 1 基于二阶聚合的多阶信息融合方法流程图
Fig. 1 The flow chart of multi-order information fusion based on second-order aggregation
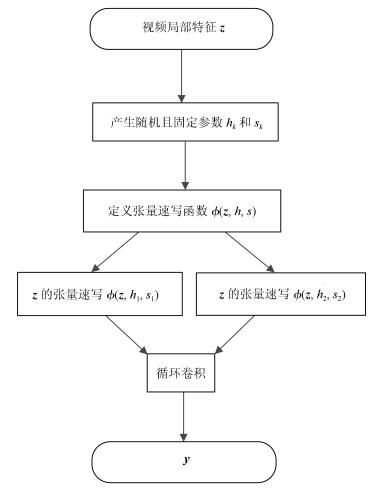
图 2 视频局部特征z进行压缩双线性池化操作流程图
Fig. 2 The flow chart of compact bilinear pooling of one local video feature z
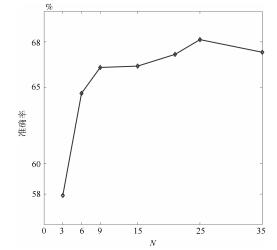
图 5 HMDB51上对视频序列中均匀采样帧数目$N$的评估
Fig. 5 Evaluation of the number $N$ of the frames uniformly sampled from the video on HMDB51
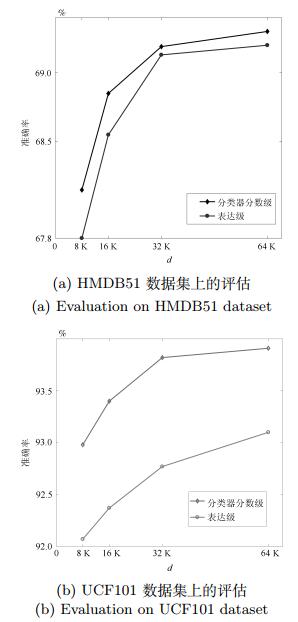
图 6 HMDB51和UCF101数据集在不同视频全局表达维度d下对表达级融合策略和分类器分数级融合策略的评估
Fig. 6 Evaluation of representation level fusion strategy and class score level fusion strategy under the difierent dimension of the video representation on HMDB51 and UCF101 dataset
表 1 一阶、二阶空间和时间流网络在UCF101和HMDB51上准确率的比较
Table 1 Comparisons of first-order spatial and temporal network with second-order spatial and temporal network on UCF101 and HMDB51
 下载: 导出CSV
下载: 导出CSV
表 2 UCF101和HMDB51上多阶信息融合有效性评估
Table 2 Evaluation of the efiectiveness of multi-order information fusion on UCF101 and HMDB51
一阶空间流 一阶时间流 二阶空间流 二阶时间流 UCF101 (%) HMDB51 (%) √ √ 91.70 61.20 √ √ 92.90 65.17 √ √ 91.34 61.63 √ √ 92.67 63.50 √ √ √ 92.50 65.18 √ √ √ 92.96 66.14 √ √ √ 91.78 60.60 √ √ √ 91.12 58.71 √ √ √ √ 92.75 64.74
下载: 导出CSV
表 3 UCF101和HMDB51上基于二阶聚合的视频不同多阶信息融合评估
Table 3 Evaluation of fusing difierent multi-order information of the video based on second-order aggregation on UCF101 and HMDB51
一阶空间信息 一阶时间信息 二阶空间信息 二阶时间信息 UCF101 (%) HMDB51 (%) √ √ 89.28 64.24 √ √ 87.57 59.56 √ √ 92.58 65.93 √ √ 92.07 64.10 √ √ √ 92.68 68.02 √ √ √ 92.60 67.45 √ √ √ 88.64 61.44 √ √ √ 92.55 64.88 √ √ √ √ 92.98 68.15
下载: 导出CSV
表 4 不同融合方法测试时间比较
Table 4 Test speed comparison of different fusion methods
方法 测试方式 时间(s/视频) 一阶双流网络融合(基线)[9] 10-crop 9.670 二阶双流网络融合 10-crop 10.459 一阶+二阶双流网络融合 10-crop 20.129 多阶信息二阶聚合 1-crop 6.412
下载: 导出CSV
表 5 基于双流卷积神经网络架构的行为识别方法比较
Table 5 Comparison of difierent human action recognition arthogram based on two-stream convolutional network
方法 网络架构 UCF101 (%) HMDB51 (%) Two-stream[6] VGG-M $88.0$ $59.4$ Two-stream 3D卷积+ 3D池化[7] VGG-16 $92.5$ $66.4$ Two-stream[9] ResNet-50 $91.7$ $61.2$ ST-ResNet*[8] ResNet-50 $93.4$ $66.4$ ST-multiplier network[9] ResNet-50 (空间), ResNet-152 (时间) $94.2$ $68.9$ Two-Stream fusion + IDT[7] VGG-16 $93.5$ $69.2$ ST-ResNet + IDT[8] ResNet-50 $94.6$ $70.3$ ST-multiplier + IDT[9] ResNet-50 (空间), ResNet-152 (时间) $94.9$ $72.2$ 本文方法 ResNet-50 93.8 69.2 本文方法+联合训练[8] ResNet-50 94.1 70.7 本文方法+ IDT ResNet-50 94.6 74.4
下载: 导出CSV
-
[1] 朱煜, 赵江坤, 王逸宁, 郑兵兵. 基于深度学习的人体行为识别算法综述. 自动化学报, 2016, 42(6): 848-857 doi: 10.16383/j.aas.2016.c150710Zhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6): 848-857 doi: 10.16383/j.aas.2016.c150710 [2] 苏本跃, 蒋京, 汤庆丰, 盛敏. 基于函数型数据分析方法的人体动态行为识别. 自动化学报, 2017, 43(6): 866-876 doi: 10.16383/j.aas.2017.c160120Su Ben-Yue, Jiang Jing, Tang Qing-Feng, Sheng Min. Human dynamic action recognition based on functional data analysis. Acta Automatica Sinica, 2017, 43(6): 866-876 doi: 10.16383/j.aas.2017.c160120 [3] 周风余, 尹建芹, 杨阳, 张海婷, 袁宪锋. 基于时序深度置信网络的在线人体动作识别. 自动化学报, 2016, 42(7): 1030-1039 doi: 10.16383/j.aas.2016.c150629Zhou Feng-Yu, Yin Jian-Qin, Yang Yang, Zhang Hai-Ting, Yuan Xian-Feng. Online recognition of human actions based on temporal deep belief neural network. Acta Automatica Sinica, 2016, 43(6): 1030-1039 doi: 10.16383/j.aas.2016.c150629 [4] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS Foundation, Inc., 2012. 1097-1105 [5] Wang H, Schmid C. Action recognition with improved trajectories. In: Proceedings of the 14th International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 3551-3558 [6] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS Foundation, Inc., 2014. 568-576 [7] Feichtenhofer C, Pinz A, Zisserman A. Convolutional two-stream network fusion for video action recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1933-1941 [8] Feichtenhofer C, Pinz A, Wildes R P. Spatiotemporal residual networks for video action recognition. In: Proceedings of the 29th International Conference on Neural Information Processing Systems. Barcelona, ES, Spain: NIPS Foundation, Inc., 2016. 3468-3476 [9] Feichtenhofer C, Pinz A, Wildes R P. Spatiotemporal multiplier networks for video action recognition. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 7445-7454 [10] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770-778 [11] Wang Y B, Long M S, Wang J M, Yu S P. Spatiotemporal pyramid network for video action recognition. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 2097-2106 [12] Wang L M, Xiong Y J, Wang Z, Qiao Y, Lin D H, Tang X D, et al. Temporal segment networks: Towards good practices for deep action recognition. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 20-36 [13] Hu J, Zheng W, Lai J, Zhang J G. Jointly learning heterogeneous features for RGB-D activity recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 2017, 39(11): 2186-2200 doi: 10.1109/TPAMI.2016.2640292 [14] Shahroudy A, Ng T, Gong Y H, Wang G. Deep multimodal feature analysis for action recognition in RGB+D videos. IEEE Transactions on Pattern Analysis and Machine Intelligence 2018, 40(5): 1045-1058 doi: 10.1109/TPAMI.2017.2691321 [15] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2014, 115(3): 211- 252 doi: 10.1007/s11263-015-0816-y [16] Lin T Y, Roychowdhury A, Maji S. Bilinear CNN models for fine-grained visual recognition. In: Proceedings of the 15th International Conference on Computer Vision. Santiago, USA: IEEE, 2015. 1449-1457 [17] Lin T Y, Roychowdhury A, Maji S. Bilinear convolutional neural networks for fine-grained visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1309-1322 doi: 10.1109/TPAMI.2017.2723400 [18] Li P H, Xie J T, Wang Q L, Zuo W M. Is second-order information helpful for large-scale visual recognition? In: Proceedings of the 16th International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2089-2097 [19] Li P H, Xie J T, Wang Q L, Gao Z L. Towards faster training of global covariance pooling networks by iterative matrix square root normalization. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018. 947-955 [20] Gao Y, Beijbom O, Zhang N, Darrell T. Compact bilinear pooling. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 317-326 [21] Charikar M, Chen K, Farach-Colton M. Finding frequent items in data streams. In: Proceedings of the 2002 International Colloquium on Automata, Languages, and Programming. Malaga, ES, Spain: Springer, 2002. 693-703 [22] Soomro K, Zamir A R, Shah M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv: 1212. 0402, 2012. 1-7 [23] Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T. HMDB: A large video database for human motion recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, ES, Spain: IEEE, 2011. 2556- 2563 [24] MatConvNet: CNNs for MATLAB: Source Code [Onlilne], available: http://www.vlfeat.org/matconvnet, November 7, 2018 [25] Peng X J, Wang L M, Wang X X, Qiao Y. Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Computer Vision and Image Understanding, 2016, 150: 109-125 doi: 10.1016/j.cviu.2016.03.013 期刊类型引用(8)
1. 刘文璇,钟忺,徐晓玉,周卓,江奎,王正,白翔. 空—地多视角行为识别的判别信息增量学习方法. 中国图象图形学报. 2025(01): 130-147 .  百度学术
百度学术2. 苏本跃,郭梦娟,朱邦国,盛敏. 顺序主导和方向驱动下基于点边特征的人体动作识别方法. 控制与决策. 2024(09): 3090-3098 . 百度学术3. 乔迤,曲毅. 基于自适应融合权重的人体行为识别方法. 计算机工程与设计. 2023(03): 845-851 . 百度学术4. 沈加炜,陆一鸣,陈晓艺,钱美玲,陆卫忠. 基于深度学习的人体行为检测方法研究综述. 计算机与现代化. 2023(09): 1-9 . 百度学术5. 曾明如,熊嘉豪,祝琴. 基于T-Fusion的TFP3D人体行为识别算法. 计算机集成制造系统. 2023(12): 4032-4039 . 百度学术6. 凌永标,毛峰,杨岚岚,邱兴卫,张志锐,张杰. 基于混合注意力网络的安全工器具检测. 计算机技术与发展. 2022(06): 209-214 . 百度学术7. 张海超,张闯. 融合注意力的轻量级行为识别网络研究. 电子测量与仪器学报. 2022(05): 173-179 . 百度学术8. 杨观赐,李杨,赵乐,刘赛赛,何玲,刘丹. 基于传感器数据的用户行为识别方法综述. 包装工程. 2021(18): 94-102+133+11 . 百度学术其他类型引用(19)
-

 下载:
下载:

计量
- 文章访问数: 1319
- HTML全文浏览量: 428
- PDF下载量: 380
- 被引次数: 27
