

-
摘要: 在无先验信息的情况下, 贝叶斯网络(Bayesian network, BN)结构搜索空间的规模随节点数目增加呈指数级增长, 造成BN结构学习难度急剧增加. 针对该问题, 提出基于双尺度约束模型的BN结构自适应学习算法. 该算法利用最大互信息和条件独立性测试构建大尺度约束模型, 完成BN结构搜索空间的初始化. 在此基础上设计改进遗传算法, 在结构迭代优化过程中引入小尺度约束模型, 实现结构搜索空间小尺度动态缩放. 同时, 在改进遗传算法中构建变异概率自适应调节函数, 以降低结构学习过程陷入局部最优解的概率. 仿真结果表明, 提出的基于双尺度约束模型的BN结构自适应学习算法能够在无先验信息的情况下保证BN结构学习的精度和迭代寻优的收敛速度.Abstract: In the absence of prior information, the size of the search space for Bayesian network (BN) structures grows exponentially with the increasing number of nodes, resulting in the great difficulties of BN structure learning. To solve this problem, BN structure adaptive learning algorithm based on dual-scale constraint model is proposed. The maximum mutual information and conditional independence tests are first used in the proposed algorithm to build a large-scale constraint model, completing the initialization of the search space for BN structures. Based on this, an improved genetic algorithm is presented, introducing a small-scale constraint model during the iteration to realize the dynamic adjustment of the search space. At the same time, an adaptive control function of mutation probability is constructed in order to reduce the probability of getting trapped in a local optimum. The simulation results show that BN structure adaptive learning algorithm based on dual-scale constraint model can guarantee the accuracy of learning BN structure and the convergence speed of the iteration without prior information.
-
Key words:
- Bayesian network /
- structure learning /
- constraint model /
- genetic algorithm
1) 本文责任编委 朱军 -
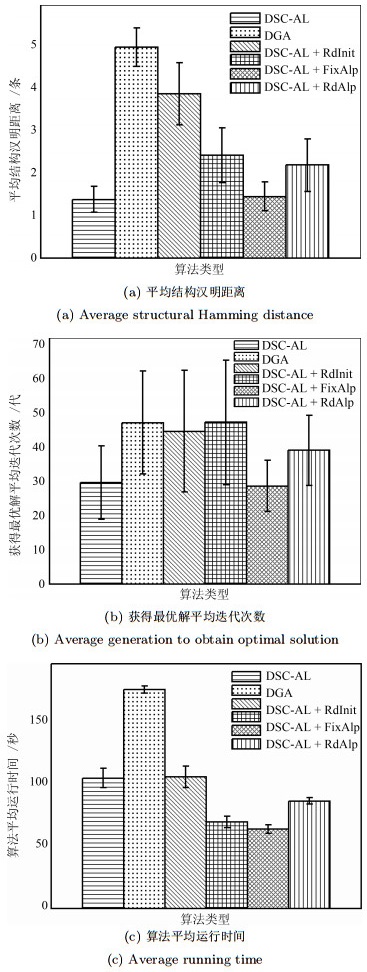
图 6 6种算法在ASIA-1000数据集下的3种性能指标的误差条形图
Fig. 6 Error bar graph of 3 measures for 6 algorithms on ASIA-1000 data set
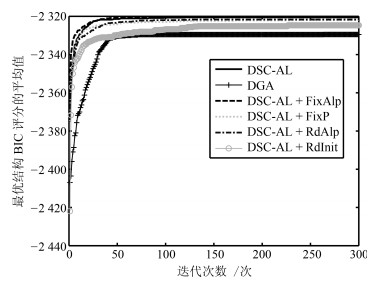
图 7 ASIA-1000下最优结构BIC评分平均值变化曲线
Fig. 7 The curves of BIC scores for optimal structures on ASIA-1000 data set
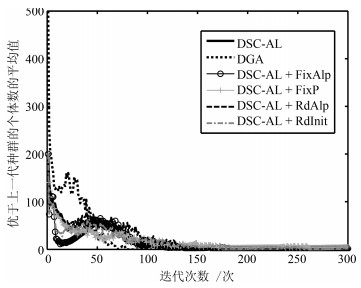
图 8 ASIA-1000下优于上一代种群的个体数平均值变化曲线
Fig. 8 The curves of number of better individuals on ASIA-1000 data set
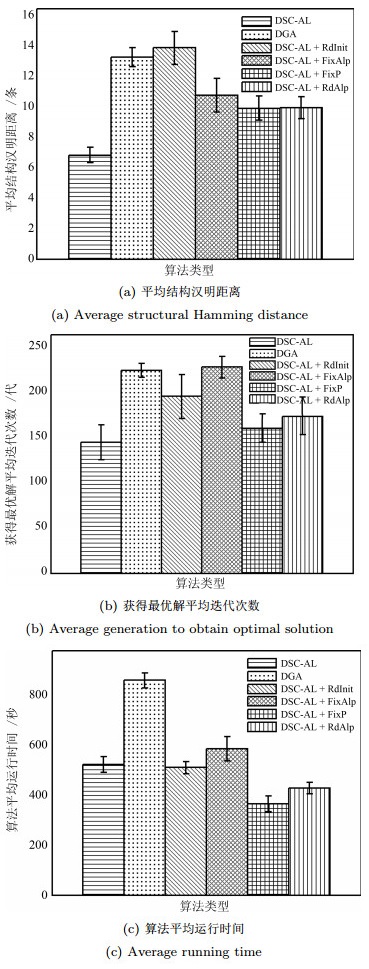
图 9 6种算法在CAR_DIAGNOSIS2-2000数据集下的3种性能指标的误差条形图
Fig. 9 Error bar graph of 3 measures for 6 algorithms on CAR_DIAGNOSIS2-2000 data set

图 10 CAR_DIAGNOSIS2-2000下最优结构BIC评分平均值变化曲线
Fig. 10 The curves of BIC scores for optimal structures on CAR_DIAGNOSIS2-2000 data set
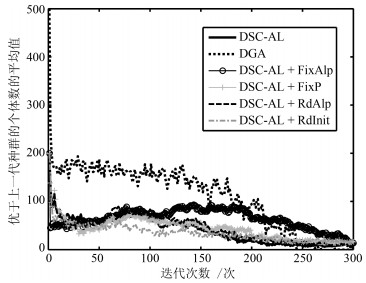
图 11 CAR_DIAGNOSIS2-2000下优于上一代种群的个体数平均值变化曲线
Fig. 11 The curves of number of better individuals on CAR_DIAGNOSIS2-2000 data set
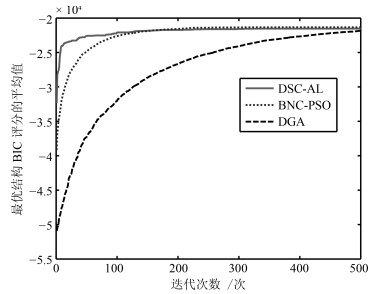
图 12 ALARM-2000下最优结构BIC评分平均值变化曲线
Fig. 12 The curves of BIC scores for optimal structures on ALARM-2000 data set
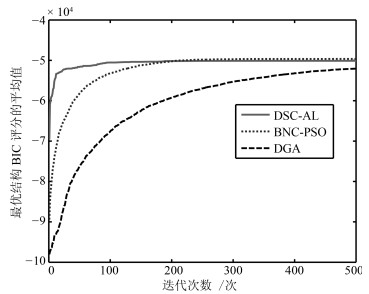
图 13 ALARM-5000下最优结构BIC评分平均值变化曲线
Fig. 13 The curves of BIC scores for optimal structures on ALARM-5000 data set
表 1 ASIA模型下不同算法结果对比
Table 1 Comparisons of different methods on ASIA network
数据集 算法 IBIC BIC SHD RT BG ASIA-1 000 (−2 325.3) DSC-AL −2 375.1 (3.6570) −2 320.5 (2.1782) 1.3667 (0.7184) 103.4270 (17.5317) 29.6667 (25.1812) DGA −2 406.9 (15.1353) −2 329.5 (6.8571) 4.9333 (1.2576) 173.9571 (7.9109) 47.2333 (42.1775) K2 / −2 342.1 (14.0940) 7.5667 (2.1284) / / DSC-AL + RdInit −2 421.9 (19.5248) −2 324.7 (4.7155) 3.8333 (2.0186) 104.3722 (23.3174) 44.7000 (49.7165) DSC-AL + FixAlp −2 372.3 (0.2821) −2 320.2 (1.7524) 1.4333 (0.9353) 62.6387 (9.6306) 28.6333 (20.8450) DSC-AL + RdAlp −2 374.4 (2.7308) −2 321.7 (3.3730) 2.1667 (1.7237) 85.2060 (7.6515) 39.1000 (28.7250) DSC-AL + FixP −2 374.8 (2.9988) −2 322.0 (3.2387) 2.4000 (1.7927) 68.6206 (12.4026) 47.2667 (51.1205)  下载: 导出CSV
下载: 导出CSV
表 2 CAR DIAGNOSIS2模型下不同算法结果对比
Table 2 Comparisons of different methods on CAR DIAGNOSIS2 network
数据集 算法 IBIC BIC SHD RT BG CAR DIAGNOSIS2-2000 (−11 922) DSC-AL −13 865 (186.3612) −11 774 (43.2254) 6.8000 (1.1861) 520.6599 (74.8401) 144.0667 (45.2601) DGA −15 546 (271.5482) −11 795 (51.1551) 13.2000 (1.7301) 856.7351 (85.2662) 222.7667 (21.2630) K2 / −12 111 (198.0365) 23.5667 (5.4752) / / DSC-AL + RdInit −15 661 (415.5809) −12 034 (181.5865) 13.8333 (3.0181) 508.8949 (67.7425) 194.5000 (67.9111) DSC-AL + FixAlp −13 557 (87.5065) −11 745 (22.6139) 10.7000 (3.0867) 583.9935 (9.6306) 226.6667 (33.6988) DSC-AL + RdAlp −13 883 (177.8057) −11 820 (37.1534) 9.9000 (2.0060) 426.4885 (63.1594) 172.5667 (57.0485) DSC-AL + FixP −13 860 (143.4086) −11 825 (41.7158) 9.8667 (2.2242) 364.3424 (90.1956) 159.2667 (42.1303)
下载: 导出CSV
表 3 ALARM模型下不同算法结果对比
Table 3 Comparisons of different methods on ALARM network
数据集 算法 SHD RT BG ALARM-2000 (−20 294) DSC-AL 15.1000 (2.7669) 2 898.8 (267.3125) 225.8000 (95.5671) DGA 33.5000 (3.5071) 2 910.5 (122.4261) 498.1667 (1.4720) BNC-PSO 25.3333 (5.5000) 2 689.1 (153.1974) 267.7778 (63.5227) ALARM-5000 (−48 724) DSC-AL 13.5000 (0.9718) 2 322.7 (106.2002) 203.4000 (85.6364) DGA 28.6667 (1.2111) 2 435.5 (239.3540) 498.3333 (3.1411) BNC-PSO 16.3000 (3.6833) 1616.3 (473.0926) 315.9000 (98.0583)
下载: 导出CSV
-
[1] Mohammadfam I, Ghasemi F, Kalatpour O, Moghimbeigi A. Constructing a Bayesian network model for improving safety behavior of employees at workplaces. Applied Ergonomics, 2017, 58: 35-47 doi: 10.1016/j.apergo.2016.05.006 [2] Zarei E, Azadeh A, Khakzad N, Aliabadi M M, Mohammadfam I. Dynamic safety assessment of natural gas stations using Bayesian network. Journal of Hazardous Materials, 2017, 321: 830-840 doi: 10.1016/j.jhazmat.2016.09.074 [3] Landis W G, Ayre K K, Johns A F, Summers H M, Stinson J, Harris M J, et al. The multiple stressor ecological risk assessment for the mercury-contaminated South River and upper Shenandoah River using the Bayesian network-relative risk model. Integrated Environmental Assessment and Management, 2017, 13(1): 85-99 doi: 10.1002/ieam.1758 [4] 王静云, 刘三阳, 朱明敏. 基于条件独立测试的链图结构学习算法. 电子学报, 2017, 45(10): 2443-2448 doi: 10.3969/j.issn.0372-2112.2017.10.019Wang Jing-Yun, Liu San-Yang, Zhu Ming-Min. Structure learning of chain graphs using the conditional independence tests. Acta Electronica Sinica, 2017, 45(10): 2443-2448 doi: 10.3969/j.issn.0372-2112.2017.10.019 [5] Madsen A L, Jensen F, Salmerón A, Langseth H, Nielsen T D. A parallel algorithm for Bayesian network structure learning from large data sets. Knowledge-Based Systems, 2017, 117: 46-55 doi: 10.1016/j.knosys.2016.07.031 [6] Villanueva E, Maciel C D. Efficient methods for learning Bayesian network super-structures. Neurocomputing, 2014, 123: 3-12 doi: 10.1016/j.neucom.2012.10.035 [7] 邸若海, 高晓光, 郭志高. 小数据集BN建模方法及其在威胁评估中的应用. 电子学报, 2016, 44(6): 1504-1511 doi: 10.3969/j.issn.0372-2112.2016.06.035Di Ruo-Hai, Gao Xiao-Guang, Guo Zhi-Gao. The modeling method with Bayesian networks and its application in the threat assessment under small data sets. Acta Electronica Sinica, 2016, 44(6): 1504-1511 doi: 10.3969/j.issn.0372-2112.2016.06.035 [8] 邸若海, 高晓光, 郭志高. 基于改进BIC评分的贝叶斯网络结构学习. 系统工程与电子技术, 2017, 39(2): 437-444 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201702031.htmDi Ruo-Hai, Gao Xiao-Guang, Guo Zhi-Gao. Bayesian networks structure learning based on improved BIC scoring. System Engineering and Electronics, 2017, 39(2): 437-444 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201702031.htm [9] Adabor E S, Acquaah-Mensah G K, Oduro F T. SAGA: a hybrid search algorithm for Bayesian network structure learning of transcriptional regulatory networks. Journal of Biomedical Informatics, 2015, 53: 27-35 doi: 10.1016/j.jbi.2014.08.010 [10] Masegosa A R, Moral S. An interactive approach for Bayesian network learning using domain/expert knowledge. International Journal of Approximate Reasoning, 2013, 54(8): 1168-1181 doi: 10.1016/j.ijar.2013.03.009 [11] 高晓光, 叶思懋, 邸若海, 寇振超. 基于融合先验方法的贝叶斯网络结构学习. 系统工程与电子技术, 2018, 40(4): 790-796 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201804012.htmGao Xiao-Guang, Ye Si-Mao, Di Ruo-Hai, Kou Zhen-Chao. Bayesian network structures learning based on approach using incoporate priors method. System Engineering and Electronics, 2018, 40(4): 790-796 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201804012.htm [12] Gasse M, Aussem A, Elghazel H. A hybrid algorithm for Bayesian network structure learning with application to multi-label learning. Expert Systems with Applications, 2014, 41(15): 6755-6772 doi: 10.1016/j.eswa.2014.04.032 [13] 李明, 张韧, 洪梅, 白成祖. 基于信息流改进的贝叶斯网络结构学习算法. 系统工程与电子技术, 2018, 40(6): 1385-1390 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201806028.htmLi Ming, Zhang Ren, Hong Mei, Bai Cheng-Zu. Improved structure learning algorithm of Bayesian network based on information flow. System Engineering and Electronics, 2018, 40(6): 1385-1390 https://www.cnki.com.cn/Article/CJFDTOTAL-XTYD201806028.htm [14] 刘彬, 王海羽, 孙美婷, 刘浩然, 刘永记, 张春兰. 一种通过节点序寻优进行贝叶斯网络结构学习的算法. 电子与信息学报, 2018, 40(5): 1234-1241 https://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201805031.htmLiu Bin, Wang Hai-Yu, Sun Mei-Ting, Liu Hao-Ran, Liu Yong-Ji, Zhang Chun-Lan. Learning Bayesian network structure from node ordering searching optimal. Journal of Electronics and Information Technology, 2018, 40(5): 1234-1241 https://www.cnki.com.cn/Article/CJFDTOTAL-DZYX201805031.htm [15] Wong M L, Leung K S. An efficient data mining method for learning Bayesian networks using an evolutionary algorithm-based hybrid approach. IEEE Transactions on Evolutionary Computation, 2004, 8(4): 378-404 doi: 10.1109/TEVC.2004.830334 [16] 冀俊忠, 张鸿勋, 胡仁兵, 刘椿年. 一种基于独立性测试和蚁群优化的贝叶斯网学习算法. 自动化学报, 2009, 35(3): 281-288 doi: 10.3724/SP.J.1004.2009.00281Ji Jun-Zhong, Zhang Hong-Xun, Hu Ren-Bing, Liu Chun-Nian. A Bayesian network learning algorithm based on independence test and ant colony optimization. Acta Automatica Sinica, 2009, 35(3): 281-288 doi: 10.3724/SP.J.1004.2009.00281 [17] Li B H, Liu S Y, Li Z G. Improved algorithm based on mutual information for learning Bayesian network structures in the space of equivalence classes. Multimedia Tools and Applications, 2012, 60(1): 129-137 doi: 10.1007/s11042-011-0801-6 [18] Lee J, Chung W, Kim E. Structure learning of Bayesian networks using dual genetic algorithm. IEICE Transactions on Information and Systems, 2008, 91(1): 32-43 http://dl.acm.org/citation.cfm?id=1522665 [19] Gheisari S, Meybodi M R. BNC-PSO: Structure learning of Bayesian networks by particle swarm optimization. Information Sciences, 2016, 348: 272-289 doi: 10.1016/j.ins.2016.01.090 [20] Cooper G F, Herskovits E. A Bayesian method for the induction of probabilistic networks from data. Machine Learning, 1992, 9(4): 309-347 http://dl.acm.org/citation.cfm?id=145259 [21] Robinson, R W. Counting unlabeled acyclic digraphs. In Proceedings of the 5th Australian Conference on Combinatorial Mathematics, Melbourne, Australia: Springer, 1976. 28-43 [22] de Campos L M, Castellano J G. Bayesian network learning algorithms using structural restrictions. International Journal of Approximate Reasoning, 2007, 45(2): 233-254 doi: 10.1016/j.ijar.2006.06.009 [23] 刘建伟, 黎海恩, 罗雄麟. 概率图模型学习技术研究进展. 自动化学报, 2014, 40(6): 1025-1044 doi: 10.3724/SP.J.1004.2014.01025Liu Jian-Wei, Li Hai-En, Luo Xiong-Lin. Learning technique of probabilistic graphical models: a review. Acta Automatica Sinica, 2014, 40(6): 1025-1044 doi: 10.3724/SP.J.1004.2014.01025 [24] 汪春峰, 张永红. 基于无约束优化和遗传算法的贝叶斯网络结构学习方法. 控制与决策, 2013, 28(4): 618-622 https://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201304027.htmWang Chun-Feng, Zhang Yong-Hong. Bayesian network structure learning based on unconstrained optimization and genetic algorithm. Control and Decision, 2013, 28(4): 618-622 https://www.cnki.com.cn/Article/CJFDTOTAL-KZYC201304027.htm [25] Larrañaga P, Karshenas H, Bielza C, et al. A review on evolutionary algorithms in Bayesian network learning and inference tasks. Information Sciences, 2013, 233: 109-125 doi: 10.1016/j.ins.2012.12.051 [26] Omara F A, Arafa M M. Genetic algorithms for task scheduling problem. Journal of Parallel and Distributed Computing, 2010, 70(1): 13-22 doi: 10.1016/j.jpdc.2009.09.009 -

 下载:
下载:


计量
- 文章访问数: 813
- HTML全文浏览量: 414
- PDF下载量: 143
- 被引次数: 0
