

Illumination-Inversion and Rotation Invariant Texture Representation Based on Local Complement and Derivative Pattern
-
摘要: 针对现有局部二值模式(Local binary pattern, LBP) 算法对光照反转变化敏感和特征描述力不足的问题, 本文提出一种基于局部补数-导数模式(Local complement and derivative pattern, LCDP) 的纹理表达方法. 其中, 局部补数模式(Local complement pattern, LCP) 用于编码原始图像空间中的近邻差分符号信息, 局部导数模式(Local derivative pattern, LDP) 用于编码不同尺度下(一阶和二阶) 高斯导数空间中的近邻差分幅值信息, 二者对光照反转和图像旋转均具有鲁棒性. 为实现对差分符号和差分幅值的联合统计, 同时维持特征的紧致性, 进一步提出基于均值采样的联合编码方案. 最后, 对联合编码的结果进行多尺度直方图特征表达. 实验表明, 该方法能够有效提高线性和非线性光照反转条件下纹理图像的分类精度.Abstract: The existing local binary pattern (LBP) based algorithms are sensitive to inverse illumination changes and have limited ability for feature description. In view of this, a method for texture representation is proposed based on local complement and derivative pattern (LCDP). In LCDP, local complement pattern (LCP) encodes the signs of neighbor difierences in original image space whereas local derivative pattern (LDP) encodes the magnitudes of neighbor difierences in (the flrst and the second order) Gaussian derivative space at difierent scales. Both LCP and LDP are robust to inverse illuminations and image rotation. Furthermore, a joint encoding scheme based on mean sampling is proposed. This is used to establish the joint statistics of difierence signs and difierence magnitudes while remaining compact features. Finally, the texture descriptor is obtained by constructing multi-scale histograms of jointly encoded features. Experiments demonstrate that the proposed method can efiectively improve the classiflcation accuracy of texture images under both linear and nonlinear inverse illumination conditions.
-
Key words:
- Texture classiflcation /
- feature extraction /
- illumination changes /
- local binary pattern (LBP)
-
纹理是一种重要的视觉特征, 它反映了像素灰度的空间分布规律, 传达了物体的表面结构信息. 提取有效的纹理特征是图像处理和计算机视觉领域研究的基础问题, 在纹理分类[1-3]、纹理分割[4]、场景识别[5]、图像匹配[6]等视觉任务中扮演重要角色. 由于图像内在的纹理结构呈现多样化以及外部成像条件的不可预知性(如旋转、光照、尺度和视角等变化), 提取对各种图像变化具有不变性的纹理特征是一个富有挑战性的问题.
近几十年来, 学者们提出了一系列的纹理特征提取方法, 包括灰度共生矩阵[7]、马尔科夫随机场[8]、Gabor滤波[9]和小波变换[10]等. Ojala等[2]提出了局部二值模式(Local binary pattern, LBP), 该方法通过编码像素差分的符号信息来建立直方图特征, 具有计算复杂度低、对光照和旋转变化鲁棒等优点. 受其启发, 研究者们提出了许多LBP的衍生算法[11-12]. 例如, 在提高抗噪性能方面, Tan等[13]提出了局部三值模式(Local ternary pattern, LTP)将局部差分符号量化为三值模式以降低噪声对像素差分编码值的影响. Song等[14]利用局部差分模板提出了抗噪的局部对比度模式(Local contrast pattern, LCP). Liu等[15]基于局部平均的思想提出了对噪声鲁棒的BRINT (Binary rotation invariant and noise tolerant)描述符. 在提高特征鉴别力方面, 研究者们提出了完整的LBP (Completed LBP, CLBP)[16]、完整的局部二值计数(Completed local binary count, CLBC)[17]和基于变换域的方法, 包括局部Gabor二值模式[9]、局部编码变换特征直方图(Locally encoded transform feature histogram, LETRIST)[18]和局部空频模式联合编码(Joint coding of local space-frequency pattern, jcLSFP)[19].
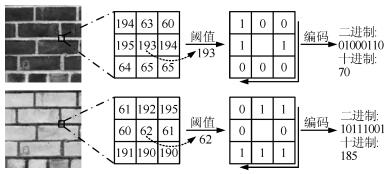
尽管上述LBP的衍生算法获得了一定成功, 但是它们对图像的光照反转变化十分敏感. 光照反转现象是由反射、曝光、前景或者背景变化等引起的图像灰度值相对大小的改变[20-23]. 图 1显示了真实生活场景中存在的光照反转现象. 可以看到, 不同于普通的光照变化, 光照反转使得原先图像中明亮的区域变得暗淡, 反之亦然. 由于LBP编码局部像素对的差分符号信息, 即以中心像素为门限将近邻像素量化为包含"0"和"1"比特的二值模式, 光照反转时LBP将产生完全不同的编码值(见图 2), 这会严重影响LBP及其衍生算法在分类和识别等任务中的性能.
针对上述问题, Nguyen等[20]提出了非冗余的LBP (Non-redundant LBP, NRLBP), 通过寻找LBP二进制码与其反码的最小值来解决对象检测中前景和背景灰度值相对变化的问题. Jun等[21]提出了局部梯度模式(Local gradient pattern, LGP), 通过编码局部差分的幅值来解决光照反转不变性. 类似地, He等[22]提出了梯度LBP (Gradient LBP, GLBP) 来解决纹理分类中的光照反转问题. 为实现旋转不变性, 该方法通过遍历所有方向的特征直方图来寻求最小的匹配距离, 因此计算复杂度比较高. Song等[23]提出了排序的LGP (Sorted LGP, SLGP), 在编码梯度信息的同时还利用主导灰度序来编码中心像素. 在上述4种方法中, NRLBP和LGP没有考虑旋转不变性, LGP、GLBP和SLGP仅考虑了像素差分的幅值信息, 忽略了重要的差分符号信息, 而且这4种方法均表现出有限的特征描述力.
基于以上观察, 本文从一个新的角度去解决LBP特征的光照反转不变性, 同时提高特征的描述力. 首先, 提出两种互补性的、对光照反转和图像旋转鲁棒的纹理算子: 局部补数模式(Local complement pattern, LCP)和局部导数模式(Local derivative pattern, LDP). 前者用于编码原始图像空间中的近邻差分符号信息, 后者用于编码不同尺度下(一阶和二阶)高斯导数空间中的近邻差分幅值信息. 然后, 提出基于均值采样的联合编码方案, 其目的是提高特征的表达力, 同时维持特征的紧致性. 最后, 对联合编码的特征进行多尺度的直方图表达, 获得纹理图像描述符, 即局部补数-导数模式(Local complement and derivative pattern, LCDP)特征. 实验表明, 本文方法能够很好地解决纹理分类任务中的光照反转和图像旋转问题, 并在线性和非线性光照反转条件下取得了很高的分类精度.
1. 本文方法
图 3显示了本文方法构建LCDP描述符的框架. 首先, 对图像进行多尺度的一阶和二阶高斯导数滤波, 分别计算梯度的幅值响应图和LOG (Laplacian of Gaussian)滤波的幅值响应图. 然后, 基于均值采样策略对原始图像进行LCP编码, 对两类幅值响应图进行LDP编码. 最后, 对LCP和LDP的编码值进行联合统计, 建立多尺度的直方图特征表达.
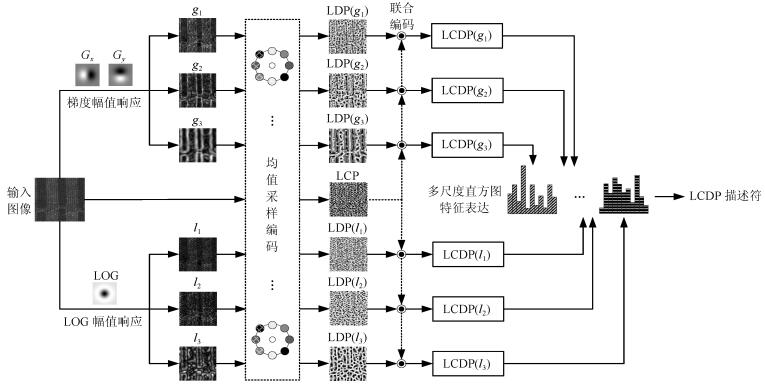 图 3 本文方法构建LCDP描述符的框架Fig. 3 The framework of the proposed method to construct LCDP descriptor
图 3 本文方法构建LCDP描述符的框架Fig. 3 The framework of the proposed method to construct LCDP descriptor1.1 局部补数模式(LCP)
LBP[2]算子直接编码近邻像素差分的符号信息, 是描述纹理结构的有力工具. 给定一幅图像$ I $, 利用LBP算子可以计算对应每个中心像素的具有旋转不变性的码值:
$$ \begin{equation} LBP_{r, P}^{riu2} = \begin{cases}\sum\limits_{p = 0}^{P-1}s(x_{r, p}-x_c), &\rm{ U(LBP_{r, P})\leq2 }\\P+1, &\rm{其他}\end{cases} \end{equation} $$ (1) $$ \begin{align} U(LBP_{r, P}) = \, &\big|s(x_{r, P-1}-x_c)-s(x_{r, 0}-x_c)\big|+\\& \sum\limits_{p = 1}^{P-1}\big|s(x_{r, p}-x_c)-s(x_{r, p-1}-x_c)\big| \end{align} $$ (2) 其中, 上标"$ ri $"表示旋转不变性, "$ u2 $"表示均匀测度$ U\leq2 $, $ x_c $表示当前中心像素的灰度值, $ x_{r, p} $表示均匀分布在半径为$ r $的圆周上的第$ p\, (p = 1, \cdots, P) $个近邻采样点的灰度值(不在图像网格上的点通过内插得到), $ s $为符号函数:
$$ \begin{equation} s(z) = \begin{cases}1, &z\geq0\\0, &\rm{其他} \end{cases} \end{equation} $$ (3) 然而如前文所述, LBP对光照反转十分敏感. 针对此问题, 本文在NRLBP的基础上借鉴"$ riu2 $"的编码思想, 提出一种兼具光照反转和旋转不变性的局部补数模式LCP, 其定义如下:
$$ \begin{align} &LCP_{r, P}^{riu2} = \\ &\begin{cases}{\min}\left\{LBP_{r, P}^{riu2}, P\!- \!LBP_{r, P}^{riu2}\right\}, &\rm{ \!U(LBP_{r, P})\!\leq\!2\! }\\\dfrac{P}{2}+1\!, \! &\rm{其他}\end{cases} \end{align} $$ (4) LCP的编码原理如下: 对于式(1)中的均匀模式(即$ U\leq2 $), 光照反转后仍为均匀模式, 而且光照反转前后的$ LBP_{r, P}^{riu2} $码值互为补数(即码值之和为$ P $), 因此可以通过寻找$ LBP_{r, P}^{riu2} $码与其补数的最小值实现光照反转不变编码; 对于式(1)中的非均匀模式(即$ U>2 $), 光照反转后仍为非均匀模式, 因此可以将所有非均匀模式编码为一个码值. 例如, 由采样配置$ (r, P) = (1, 8) $得到某均匀模式$ (00011000)_2 $, 该模式在光照反转后变为$ (11100111)_2 $, 对应的旋转不变的编码值由2变为6, LCP算子选择最小值2作为最终的编码值; 对于某非均匀模式$ (00110001)_2 $, 该模式在光照反转后变为非均匀模式$ (11001110)_2 $, LCP算子将这两种非均匀模式都编码为5, 从而实现光照反转和旋转不变性.
基于式(4), 我们建立一个频率直方图来表示纹理图像, 即
$$ \begin{equation} H_{LCP}(v) = \sum\limits_{x = 1}^{w}\sum\limits_{y = 1}^{h}\delta\left(LCP_{r, P}^{riu2}(x, y), v\right) \end{equation} $$ (5) 其中, $ w $和$ h $分别表示图像的长度和宽度, $ v $ $ (v = 0, \cdots, {P}/{2}+1) $为LCP的模式标签, $ \delta $函数定义为
$$ \begin{equation} \delta(i, j) = \begin{cases}1, &i = j\\0, &i\neq j \end{cases} \end{equation} $$ (6) 上述LCP特征直方图的维度为$ ({P}/{2}+2) $.
1.2 局部导数模式(LDP)
LCP通过编码像素差分的符号信息实现光照反转不变性, 但是没有考虑像素差分的幅值信息, 其特征描述力不足. LGP[21]、GLBP[22]和SLGP[23]利用了像素差分的幅值信息, 但是它们仅考虑了点对像素之间的一阶差分幅值信息, 缺乏深度的像素交互和更为高阶的差分幅值编码. 为此, 本文引入一阶和二阶高斯导数滤波来刻画丰富的纹理结构信息, 并利用LBP算子编码图像滤波后的差分幅值信息, 上述操作称为局部导数模式(LDP)算子.
给定输入图像$ I $, 首先定义像素$ (x, y) $处的二维高斯函数为
$$ \begin{equation} G(x, y) = \frac{1}{2\pi \sigma^2}\rm{exp}\left(-\frac{x^2+y^2}{2 \sigma^2}\right) \end{equation} $$ (7) 然后, 计算基于一阶高斯导数滤波的梯度幅值响应
$$ \begin{equation} g(x, y) = \sqrt{(I\ast G_x)^2+(I\ast G_y)^2} \end{equation} $$ (8) 和基于二阶高斯导数滤波(LOG滤波)的幅值响应
$$ \begin{equation} l(x, y) = |I\ast \rm{LOG}| = \left|I\ast (G_{xx}+G_{yy})\right| \end{equation} $$ (9) 其中, $ G_x $、$ G_{xx} $和$ G_y $、$ G_{yy} $分别是沿$ x $和$ y $方向的一阶、二阶高斯导数, $ \ast $表示卷积操作, $ \sigma $是滤波尺度. 为捕获多尺度的纹理信息, 本文使用三尺度的高斯导数滤波: $ \sigma_1 = 1 $, $ \sigma_2 = 2 $, $ \sigma_3 = 4 $[18-19, 24], 由此得到三幅梯度幅值响应图($ g_1 $、$ g_2 $和$ g_3 $)以及三幅LOG滤波幅值响应图($ l_1 $、$ l_2 $和$ l_3 $). 为获得局部的亮度不变性, 本文对滤波模板(包括$ G_x $、$ G_y $和LOG)进行零均值处理. 根据可控滤波[25]和极值滤波理论[18], 可知式(8)和式(9)具有旋转不变性.
最后, 应用旋转不变的LBP算子分别编码梯度幅值图和LOG幅值响应图:
$$ \begin{align} &LDP_{r, P}^{riu2}(\phi) = \\ &\begin{cases}\sum\limits_{p = 0}^{P-1}s\big(\phi(x_{r, p})\!-\!\phi(x_{c})\big), &\rm{ U\big(LDP_{r, P}( \mathsf{ ϕ})\leq2\big) }\\P+1, &\rm{其他}\end{cases} \end{align} $$ (10) 其中, $ \phi $表示滤波响应图($ \phi = g_i $或者$ l_i $; $ i = 1, 2, 3 $), 其他参数的定义与式(1)类似. 参照式(5), 我们可以建立一个频率直方图$ H_{LDP}(\phi) $来表示纹理图像, 其特征维度为$ (P+2) $.
现证明LDP算子对线性的光照反转变换模型$ I^{\prime} = a\times I+b $ $ (a<0) $[22-23]具有鲁棒性. 由式(10)可知:
$$ \begin{align} s\big(\phi(x^{\prime}_{r, p})\!-\!\phi(x^{\prime}_{c})\big)\! = \, &s\big(|a|\!\times\!\phi(x_{r, p})\!-\!|a|\!\times\!\phi(x_{c})\big) = \\ &s\big(\phi(x_{r, p})-\phi(x_{c})\big) \end{align} $$ (11) 可以看出, 因子$ b $由式(8)和式(9)中的一阶和二阶高斯导数消除, 因子$ a $由符号函数$ s $消除, 因此线性光照变换前后的LDP编码值保持不变. 实验表明, 本文方法对非线性的光照反转变换也具有鲁棒性.
1.3 基于均值采样的联合编码
联合图像的多种信息能够提高特征的表达力[16-18]. 由于LCP和LDP特征分别刻画了局部的差分符号和差分幅值信息, 二者具有互补性, 本文对LCP和LDP进行联合编码. 在联合编码之前, 需要考虑编码后特征的维度. 利用大的采样半径和多的采样点数可以捕获更为宏观的较大尺度上的纹理结构信息, 然而特征的维度也会急剧增加. 为捕获宏观的纹理结构信息、实现对LCP和LDP的联合编码, 同时降低描述符的特征维度, 本文采用基于均值采样[15, 26]的联合编码策略. 具体操作如下.
首先, 对中心像素的近邻点进行圆周性采样, 获得$ P = 8r $个初始采样点. 然后, 将这$ P $个初始采样点按顺序平均分成8组, 每组对应一个新的采样点, 其灰度值为该组内初始采样点的平均灰度值. 图 4为均值采样的示意图, 该过程可描述为
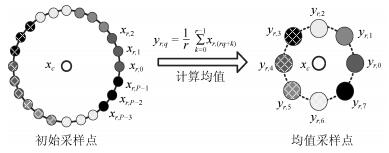 图 4 均值采样示意图$ (r, P) = (3, 24) $Fig. 4 The diagram of mean sampling with $ (r, P) = (3, 24) $
图 4 均值采样示意图$ (r, P) = (3, 24) $Fig. 4 The diagram of mean sampling with $ (r, P) = (3, 24) $$$ \begin{equation} y_{r, q} = \frac{1}{r}\sum\limits_{k = 0}^{r-1}x_{r, (rq+k)} \end{equation} $$ (12) 式中, $ r $为圆形采样邻域的半径, $ x_{r, (\cdot)} $为初始采样点的灰度值, $ y_{r, q} $为新采样点的灰度值($ q = 0, 1, \cdots, 7 $).
接着, 利用新采样点计算每个像素的LCP和LDP编码值. 由于均值采样后近邻采样点的数目降为8, LCP和LDP的特征维度分别为6和10.
最后, 对LCP和LDP进行联合编码:
$$ \begin{equation} LCDP(g_i)_{r, P}^{riu2} = LCP_{r, P}^{riu2}\!\times\! 10+LDP(g_i)_{r, P}^{riu2} \end{equation} $$ (13) $$ \begin{equation} LCDP(l_i)_{r, P}^{riu2} = LCP_{r, P}^{riu2}\times 10+LDP(l_i)_{r, P}^{riu2} \end{equation} $$ (14) 式中, $ i $代表不同的滤波尺度($ i = 1, 2, 3 $). 参照式(5), 可以建立两个频率直方图$ H_{LCDP(g_i)} $和$ H_{LCDP(l_i)} $, 它们的特征维度均为60.
1.4 多尺度的直方图特征表达
将在三个滤波尺度下计算的直方图$ H_{LCDP(g_i)} $和$ H_{LCDP(l_i)} $级联($ i = 1, 2, 3 $), 得到输入图像$ I $的多尺度的直方图特征表达:
$$ \begin{equation} H_{LCDP} = \left[H_{LCDP(g)}, H_{LCDP(l)}\right] \end{equation} $$ (15) 其中
$$ \begin{equation} H_{LCDP(g)} = \left[H_{LCDP(g_1)}, H_{LCDP(g_2)}, H_{LCDP(g_3)}\right] \end{equation} $$ (16) $$ \begin{equation} H_{LCDP(l)} = \left[H_{LCDP(l_1)}, H_{LCDP(l_2)}, H_{LCDP(l_3)}\right] \end{equation} $$ (17) 本文构建的LCDP描述符的特征维度为360.
2. 实验
为验证本文方法的有效性, 在三个基准数据库Outex[2]、CUReT[27]和KTH-TIPS[28]上进行纹理分类实验, 对比11种纹理特征提取方法: 局部二值模式(LBP)[2]、局部三值模式(LTP)[13]、完整的局部二值模式(CLBP)[16]、完整的局部二值计数(CLBC)[17]、局部编码变换特征直方图(LETRIST)[18]、局部空频模式联合编码(jcLSFP)[19]、非冗余的局部二值模式(NRLBP)[20]、局部梯度模式(LGP)[21]、梯度局部二值模式(GLBP)[22]、排序的局部梯度模式(SLGP)[23]和尺度不变特征变换(SIFT)[29].
2.1 数据库描述与实验建立
对于Outex数据库, 选用TC10和TC12两个子库进行实验. TC10子库用来测试旋转不变性, 包含成像于光照条件"inca"的24类纹理图像, 每类有20幅图像, 分别有9个旋转角度($ 0^\circ $、$ 5^\circ $、$ 10^\circ $、$ 15^\circ $、$ 30^\circ $、$ 45^\circ $、$ 60^\circ $、$ 75^\circ $和$ 90^\circ $). 其中, 旋转角度为$ 0^\circ $的480 (24$ \times $20)幅图像作为训练集, 其余8个旋转角度的3 840 (24$ \times $20$ \times $8)幅图像作为测试集. TC12子库用来测试旋转和光照不变性, 其训练集与TC10相同, 测试集为成像于光照条件"tl84"或者"horizon"的4 320 (24$ \times $20$ \times $9)幅图像. CUReT数据库包含61类纹理, 每类有92幅图像, 分别成像于不同的视角和光照方向. 从每类中随机选取46幅图像作为训练集, 其余的图像作为测试集. KTH-TIPS数据库包含10类纹理, 每类有81幅图像, 分别呈现不同的尺度、光照和姿态变化. 从每类中随机选取40幅图像作为训练集, 其余作为测试集. 由于CUReT和KTH-TIPS数据库没有固定的训练集和测试集划分, 本文进行50次分类实验, 然后计算平均的分类精度.
本文采用$ \chi^2 $距离和最近邻分类器进行纹理分类[2, 16, 23]. 实验前将所有的纹理图像转换为灰度图像并归一化到$ [0, 255] $. 本文利用公开的代码对LBP、LTP、CLBP、CLBC和LGP (原始文献中的LGP不具有旋转不变性)实施流行的基于三尺度$ (r, P) = \{(1, 8), (2, 16), (3, 24)\} $的旋转不变性编码, 其余方法采用原文献中的设置. 对于SIFT, 本文使用Lezibnik[30]提供的代码来提取稠密的SIFT特征, 然后用Bag of Words (BoW)模型表示图像, 视觉单词个数设置为500. 为综合评估不同方法对光照反转变化的鲁棒性, 实验采用两种光照反转模型[22-23]: 1)线性光照反转模型, 即对测试图像进行线性变换$ I^{\prime} = -\lambda\times I+255 $, 系数$ \lambda $是在区间$ (0, 1] $上产生的随机数; 2)非线性光照反转模型, 即对测试图像进行非线性变换$ I^{\prime} = -\sqrt{I}+255 $.
2.2 采样半径与多尺度滤波分析
图 5显示了线性光照反转条件下采样半径$ r $和多尺度滤波对LCDP分类性能的影响. 可以看出, 当$ r = 1 $增大到$ r = 2 $时, 各滤波尺度下LCDP的分类性能均得到明显提升, 这是因为使用较大的采样半径捕获了纹理的宏结构信息; 但是随着$ r $的不断增大, LCDP的分类性能逐渐趋于饱和甚至下降, 这是因为均值采样会因$ r $的增大而平滑掉纹理细节. 在单一滤波尺度下($ \sigma = 1 $、$ \sigma = 2 $或者$ \sigma = 4 $), LCDP的分类性能因数据库和滤波尺度的不同而展现出差异性; 对于多尺度的特征表达, 总体上两尺度的LCDP特征在分类性能上要优于单尺度, 三尺度(即$ \sigma = 1, 2, 4 $)的LCDP特征分类性能最好(尤其是对于存在明显尺度变化的KTH-TIPS数据库). 因此, 本文选择$ r = 5 $, 并采用三尺度的特征表达.
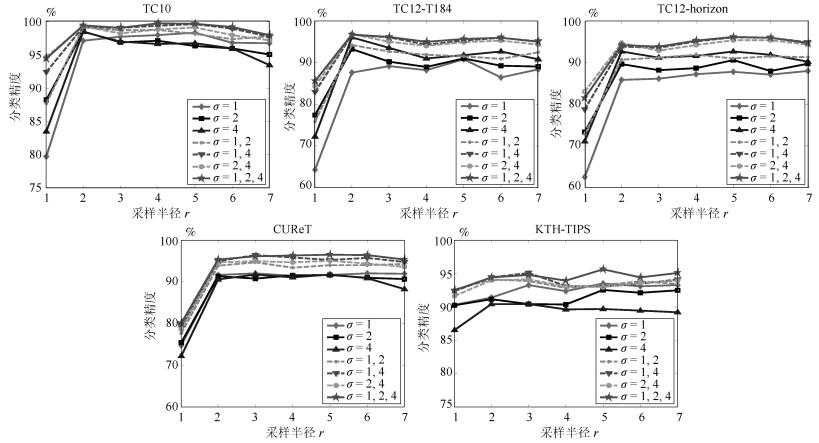 图 5 线性光照反转条件下采样半径和多尺度滤波对LCDP分类性能的影响Fig. 5 The influence of sampling radius and filtering scale on the classification performance of LCDP under linear inverse illumination conditions
图 5 线性光照反转条件下采样半径和多尺度滤波对LCDP分类性能的影响Fig. 5 The influence of sampling radius and filtering scale on the classification performance of LCDP under linear inverse illumination conditions2.3 特征的互补性分析
图 6对比了本文构建的LCP、LDP和LCDP特征在线性光照反转条件下的分类精度. 其中, $ (g) $、$ (l) $和$ (g+l) $分别表示利用梯度幅值响应、LOG滤波幅值响应和二者联合所计算的纹理特征(见图 3). 由图 6可见, LCP的分类精度最低, LDP的分类精度稍好, 联合编码LCP和LDP的LCDP则在所有数据库上都获得了最好的分类性能, 这表明LCP和LDP两种编码方式具有互补性. 从图 6中进一步发现, LDP和LCDP使用$ (g+l) $的分类性能比单独使用$ (g) $或者$ (l) $高, 这表明一阶梯度幅值响应和二阶LOG滤波的幅值响应也具有互补性.
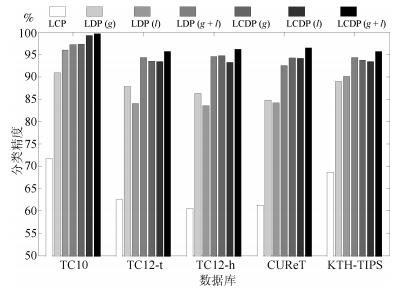 图 6 LCP、LDP和LCDP在线性光照反转条件下的分类精度Fig. 6 Classification accuracies of LCP, LDP and LCDP under linear inverse illumination conditions
图 6 LCP、LDP和LCDP在线性光照反转条件下的分类精度Fig. 6 Classification accuracies of LCP, LDP and LCDP under linear inverse illumination conditions2.4 与其他算法的比较
2.4.1 线性光照反转实验
表 1对比了不同方法在线性光照反转条件下的分类精度, 可以得出以下结论. 1) LBP及其衍生方法LTP、CLBP、CLBC、LETRIST和jcLSFP的分类精度都比较低, 最高的分类精度不超过54.54 %. 这是因为这些方法直接编码了局部差分的符号信息, 对光照反转变化十分敏感. 由于SIFT是梯度方向直方图, 加之光照反转变化会严重影响像素的梯度方向, SIFT在三个纹理数据库上的分类精度最低(最高精度为27.95 %). 2) NRLBP、LGP、GLBP和SLGP通过求补运算和计算局部梯度在一定程度上提高了分类性能. 3)本文改进的LCP在Outex上的分类精度高于NRLBP 15.3 %以上, 说明LCP对图像的旋转变化是鲁棒的. 4)本文提出的LDP在TC12和KTH-TIPS上的分类性能优于现有方法, 联合编码后的LCDP在所有数据库上获得最佳的性能. 因此, 对一阶和二阶差分幅值进行LDP编码能够有效捕获纹理的结构信息, 而且LCP和LDP这两种特征具有互补性. 5)鉴于三个基准数据库自身的特性, 本文方法能够表现出优良的分类性能, 说明该方法对图像的旋转、尺度、视角以及线性光照反转变化都较为鲁棒.
表 1 不同方法在线性光照反转条件下的分类精度(%)Table 1 Classification accuracies (%) of different methods under linear inverse illumination conditions方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 39.98 39.34 39.63 43.47 47.07 LTP[13] 21.37 37.99 38.91 44.71 54.46 CLBP[16] 24.49 22.12 22.72 34.33 43.15 CLBC[17] 20.20 18.68 18.96 31.02 41.54 LETRIST[18] 32.97 32.37 34.89 43.68 53.75 jcLSFP[19] 33.78 35.49 38.40 49.04 54.54 NRLBP[20] 42.34 42.49 45.26 83.21 87.88 LGP[21] 94.58 78.47 76.65 89.73 88.85 GLBP[22] 93.39 90.43 89.35 88.21 89.12 SLGP[23] 97.79 84.17 83.82 94.87 93.83 SIFT[29] 19.39 14.43 13.75 13.49 27.95 LCP 71.72 62.57 60.56 61.30 68.68 LDP 97.24 94.35 94.58 92.51 94.31 LCDP 99.69 95.63 96.18 96.52 95.68 2.4.2 非线性光照反转实验
表 2对比了不同方法在非线性光照反转条件下的分类结果. 可以看到, 在非线性光照反转条件下, LBP、LTP、CLBP、CLBC、jcLSFP、LETRIST和SIFT的分类精度最高不超过53.07 %, 尤其是LETRIST在Outex和CUReT上的分类精度均低于5 %. NRLBP、LGP、GLBP和SLGP在一定程度上提高了分类性能. 在本文提出的描述符中, LCP在Outex数据库上优于NRLBP, LDP在Outex和KTH-TIPS上都优于现有方法, 联合LCP和LDP后的LCDP在三个数据库上都表现出最佳的分类性能. LCDP对非线性的光照反转变化具有很强的鲁棒性, 这得益于本文方法对局部纹理结构的有力描述和对光照反转与图像旋转的妥善处理.
表 2 不同方法在非线性光照反转条件下的分类精度(%)Table 2 Classification accuracies (%) of different methods under nonlinear inverse illumination conditions方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 40.63 38.91 39.40 43.18 46.93 LTP[13] 36.56 35.32 37.08 43.72 41.66 CLBP[16] 22.99 23.15 23.87 35.59 44.93 CLBC[17] 18.29 18.80 19.75 33.16 42.34 LETRIST[18] 4.17 4.17 4.17 2.30 12.24 jcLSFP[19] 33.88 35.56 37.85 49.45 53.07 NRLBP[20] 42.32 42.94 45.32 69.02 87.73 LGP[21] 91.27 71.08 70.49 85.18 87.49 GLBP[22] 92.79 89.32 88.70 87.90 87.66 SLGP[23] 95.60 75.49 73.63 91.23 90.82 SIFT[29] 11.94 13.61 13.69 17.03 29.88 LCP 71.57 62.19 60.64 61.39 68.51 LDP 96.43 92.77 92.75 90.80 92.05 LCDP 99.61 95.09 95.42 95.81 94.54 2.4.3 无光照反转实验与特征提取时间
表 3对比了不同方法在原始数据库上的分类精度. 可以看到, NRLBP和SIFT因不具有旋转不变性而在Outex数据库上表现较差; 本文方法LCDP在Outex数据库上的分类精度仅次于LETRIST和jcLSFP, 在CUReT和KTH-TIPS数据库上相较于光照反转不变描述符NRLBP、LGP、GLBP和SLGP也有较大的性能提升. 综合对比表 1~表 3的实验结果, 本文方法在原始数据库和光照反转变化条件下均表现出优异的分类性能.
表 3 不同方法在原始数据库上的分类精度(%)Table 3 Classiflcation accuracies (%) of difierent methods on the original databases方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 97.16 88.96 83.96 93.52 92.70 LTP[13] 98.65 92.69 89.86 94.46 94.36 CLBP[16] 99.17 95.23 95.58 96.94 96.50 CLBC[17] 99.04 94.10 95.14 96.78 96.39 LETRIST[18] 100.00 99.81 100.00 98.52 98.80 jcLSFP[19] 100.00 99.77 99.93 98.20 98.72 NRLBP[20] 45.96 48.33 50.95 83.08 87.36 LGP[21] 94.58 78.47 76.65 89.86 89.83 GLBP[22] 93.20 90.37 89.26 88.44 87.63 SLGP[23] 97.79 84.17 83.82 94.83 93.71 SIFT[29] 48.61 52.75 53.18 78.12 93.37 LCP 71.72 62.57 60.56 61.41 68.56 LDP 97.24 94.35 94.58 92.37 94.52 LCDP 99.69 95.63 96.18 96.60 95.49 最后, 对比不同方法的特征提取时间. 实验平台为MATLAB (R2014a), PC配置为Intel Core 3 GHz CPU和8 GB RAM. 表 4给出了不同方法在KTH-TIPS数据库上提取单个图像描述符所需的平均时间. 可以看到, 单一尺度NRLBP的特征提取时间最短; GLBP的特征提取时间最长, 因为它需要遍历所有可能方向的特征直方图来实现旋转不变性; LBP、LTP、SIFT和LCDP等其余方法所需的时间都远少于GLBP. 因此, 本文方法LCDP在保持高分类精度的同时还具有计算高效的优点.
表 4 不同方法在KTH-TIPS数据库上提取单个图像描述符所需的平均时间(秒)Table 4 Average time (second) for different methods to extract one image descriptor on the KTH-TIPS database方法 时间 方法 时间 方法 时间 LBP 0.040 LETRIST 0.052 GLBP 0.914 LTP 0.047 jcLSFP 0.077 SLGP 0.084 CLBP 0.063 NRLBP 0.010 SIFT 0.087 CLBC 0.056 LGP 0.041 LCDP 0.139 3. 结论
针对现有LBP算法对光照反转变化敏感和特征描述力不足的问题, 本文提出一种基于局部补数-导数模式(LCDP)的纹理表达方法. 局部补数模式(LCP)用来编码原始图像空间中的差分符号信息, 局部导数模式(LDP)用来编码一阶和二阶高斯导数空间中的差分幅值信息, 二者具有互补性. 为提高特征的表达力同时维持特征的紧致性, 本文进一步提出基于均值采样的联合编码方案. 最终的纹理描述符是融合多尺度信息的、联合编码差分符号与差分幅值信息的直方图特征表达. 对三个基准数据库Outex、CUReT和KTH-TIPS进行纹理分类, 实验表明该方法能够有效解决线性和非线性变换条件下的光照反转问题, 并对图像的旋转、尺度和视角等变化具有很强的鲁棒性. 本文方法所采用的邻域特征对于非均匀光照变化还存在一定的局限性. 在未来工作中我们将会进一步考虑非均匀光照变化的具体建模和相应的特征提取问题.
-
图 3 本文方法构建LCDP描述符的框架
Fig. 3 The framework of the proposed method to construct LCDP descriptor
图 4 均值采样示意图$ (r, P) = (3, 24) $
Fig. 4 The diagram of mean sampling with $ (r, P) = (3, 24) $
图 5 线性光照反转条件下采样半径和多尺度滤波对LCDP分类性能的影响
Fig. 5 The influence of sampling radius and filtering scale on the classification performance of LCDP under linear inverse illumination conditions
图 6 LCP、LDP和LCDP在线性光照反转条件下的分类精度
Fig. 6 Classification accuracies of LCP, LDP and LCDP under linear inverse illumination conditions
表 1 不同方法在线性光照反转条件下的分类精度(%)
Table 1 Classification accuracies (%) of different methods under linear inverse illumination conditions
方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 39.98 39.34 39.63 43.47 47.07 LTP[13] 21.37 37.99 38.91 44.71 54.46 CLBP[16] 24.49 22.12 22.72 34.33 43.15 CLBC[17] 20.20 18.68 18.96 31.02 41.54 LETRIST[18] 32.97 32.37 34.89 43.68 53.75 jcLSFP[19] 33.78 35.49 38.40 49.04 54.54 NRLBP[20] 42.34 42.49 45.26 83.21 87.88 LGP[21] 94.58 78.47 76.65 89.73 88.85 GLBP[22] 93.39 90.43 89.35 88.21 89.12 SLGP[23] 97.79 84.17 83.82 94.87 93.83 SIFT[29] 19.39 14.43 13.75 13.49 27.95 LCP 71.72 62.57 60.56 61.30 68.68 LDP 97.24 94.35 94.58 92.51 94.31 LCDP 99.69 95.63 96.18 96.52 95.68  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在非线性光照反转条件下的分类精度(%)
Table 2 Classification accuracies (%) of different methods under nonlinear inverse illumination conditions
方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 40.63 38.91 39.40 43.18 46.93 LTP[13] 36.56 35.32 37.08 43.72 41.66 CLBP[16] 22.99 23.15 23.87 35.59 44.93 CLBC[17] 18.29 18.80 19.75 33.16 42.34 LETRIST[18] 4.17 4.17 4.17 2.30 12.24 jcLSFP[19] 33.88 35.56 37.85 49.45 53.07 NRLBP[20] 42.32 42.94 45.32 69.02 87.73 LGP[21] 91.27 71.08 70.49 85.18 87.49 GLBP[22] 92.79 89.32 88.70 87.90 87.66 SLGP[23] 95.60 75.49 73.63 91.23 90.82 SIFT[29] 11.94 13.61 13.69 17.03 29.88 LCP 71.57 62.19 60.64 61.39 68.51 LDP 96.43 92.77 92.75 90.80 92.05 LCDP 99.61 95.09 95.42 95.81 94.54
下载: 导出CSV
表 3 不同方法在原始数据库上的分类精度(%)
Table 3 Classiflcation accuracies (%) of difierent methods on the original databases
方法 Outex CUReT KTH-TIPS TC10 TC12 tl84 horizon LBP[2] 97.16 88.96 83.96 93.52 92.70 LTP[13] 98.65 92.69 89.86 94.46 94.36 CLBP[16] 99.17 95.23 95.58 96.94 96.50 CLBC[17] 99.04 94.10 95.14 96.78 96.39 LETRIST[18] 100.00 99.81 100.00 98.52 98.80 jcLSFP[19] 100.00 99.77 99.93 98.20 98.72 NRLBP[20] 45.96 48.33 50.95 83.08 87.36 LGP[21] 94.58 78.47 76.65 89.86 89.83 GLBP[22] 93.20 90.37 89.26 88.44 87.63 SLGP[23] 97.79 84.17 83.82 94.83 93.71 SIFT[29] 48.61 52.75 53.18 78.12 93.37 LCP 71.72 62.57 60.56 61.41 68.56 LDP 97.24 94.35 94.58 92.37 94.52 LCDP 99.69 95.63 96.18 96.60 95.49
下载: 导出CSV
表 4 不同方法在KTH-TIPS数据库上提取单个图像描述符所需的平均时间(秒)
Table 4 Average time (second) for different methods to extract one image descriptor on the KTH-TIPS database
方法 时间 方法 时间 方法 时间 LBP 0.040 LETRIST 0.052 GLBP 0.914 LTP 0.047 jcLSFP 0.077 SLGP 0.084 CLBP 0.063 NRLBP 0.010 SIFT 0.087 CLBC 0.056 LGP 0.041 LCDP 0.139
下载: 导出CSV
-
[1] 刘丽, 赵凌君, 郭承玉, 王亮, 汤俊. 图像纹理分类方法研究进展和展望. 自动化学报, 2018, 44(4): 584-607 doi: 10.16383/j.aas.2018.c160452Liu Li, Zhao Ling-Jun, Guo Cheng-Yu, Wang Liang, Tang Jun. Texture classification: state-of-the-art methods and prospects. Acta Automatica Sinica, 2018, 44(4): 584-607 doi: 10.16383/j.aas.2018.c160452 [2] Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987 doi: 10.1109/TPAMI.2002.1017623 [3] 何楚, 尹莎, 许连玉, 廖紫纤. 基于局部重要性采样的SAR图像纹理特征提取方法. 自动化学报, 2014, 40(2): 316-326 doi: 10.3724/SP.J.1004.2014.00316He Chu, Yin Sha, Xu Lian-Yu, Liao Zi-Xian. Feature extraction of SAR image based on local important sampling binary encoding. Acta Automatica Sinica, 2014, 40(2): 316-326 doi: 10.3724/SP.J.1004.2014.00316 [4] Liu X, Wang D. Image and texture segmentation using local spectral histograms. IEEE Transactions on Image Processing, 2006, 15(10): 3066-3077 doi: 10.1109/TIP.2006.877511 [5] Song T C, Li H L. WaveLBP based hierarchical features for image classification. Pattern Recognition Letters, 2013, 34(12): 1323-1328 doi: 10.1016/j.patrec.2013.04.020 [6] Song T C, Li H L. Local polar DCT features for image description. IEEE Signal Processing Letters, 2013, 20(1): 59-62 doi: 10.1109/LSP.2012.2229273 [7] Haralick R M, Shanmugam K, Dinstein I. Textural features for image classification. IEEE Transactions on Systems Man and Cybernetics, 1973, SMC-3(6): 610-621 doi: 10.1109/TSMC.1973.4309314 [8] Cross G R, Jain A K. Markov random field texture models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1983, 5(1): 25-39 [9] Zhang W C, Shan S G, Gao W, Chen X L. Local Gabor binary pattern histogram sequence (LGBPHS): a novel non-statistical model for face representation and recognition. In: Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China: IEEE, 2005. 786-791 [10] Yalavarthi A, Veeraswamy K, Sheela K A. Content based image retrieval using enhanced Gabor wavelet transform. In: Proceedings of the 2017 International Conference on Computer, Communications and Electronics. Jaipur, Rajasthan India: IEEE, 2017. 339-343 [11] 宋克臣, 颜云辉, 陈文辉, 张旭. 局部二值模式方法研究与展望. 自动化学报, 2013, 39(6): 730-744 doi: 10.3724/SP.J.1004.2013.00730Song Ke-Chen, Yan Yun-Hui, Chen Wen-Hui, Zhang Xu. Research and perspective on local binary pattern. Acta Automatica Sinica, 2013, 39(6): 730-744 doi: 10.3724/SP.J.1004.2013.00730 [12] Liu L, Fieguth P, Guo Y L, Wang X G, Pietikainen M. Local binary features for texture classification: taxonomy and experimental study. Pattern Recognition, 2017, 62: 135-160 doi: 10.1016/j.patcog.2016.08.032 [13] Tan X, Triggs B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Transactions on Image Processing, 2010, 19(6): 1635-1650 doi: 10.1109/TIP.2010.2042645 [14] Song T C, Li H L, Meng F M, Wu Q B, Luo B, Zeng B, Gabbouj M. Noise-Robust texture description using local contrast patterns via global measures. IEEE Signal Processing Letters, 2014, 21(1): 93-96 doi: 10.1109/LSP.2013.2293335 [15] Liu L, Long Y L, Fieguth P W, Lao S Y, Zhao G Y. BRINT: binary rotation invariant and noise tolerant texture classification. IEEE Transactions on Image Processing, 2014, 23(7): 3071-3084 doi: 10.1109/TIP.2014.2325777 [16] Guo Z H, Zhang L, Zhang D. A completed modeling of local binary pattern operator for texture classification. IEEE Transactions on Image Processing, 2010, 19(6): 1657-1663 doi: 10.1109/TIP.2010.2044957 [17] Zhao Y, Huang D S, Jia W. Completed local binary count for rotation invariant texture classification. IEEE Transactions on Image Processing, 2012, 21(10): 4492-4497 doi: 10.1109/TIP.2012.2204271 [18] Song T C, Li H L, Meng F M, Wu Q B, Cai J F. LETRIST: locally encoded transform feature histogram for rotation-invariant texture classification. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(7): 1565-1579 doi: 10.1109/TCSVT.2017.2671899 [19] Song T C, Li H L, Meng F M, Wu Q B, Luo B. Exploring space-frequency co-occurrences via local quantized patterns for texture representation. Pattern Recognition, 2015, 48(8): 2621-2632 doi: 10.1016/j.patcog.2015.03.003 [20] Nguyen D T, Zong Z M, Ogunbona P, Li W Q. Object detection using non-redundant local binary patterns. In: Proceedings of the 2010 IEEE International Conference on Image Processing. Hong Kong, China: IEEE, 2010. 4609-4612 [21] Jun B, Choi I, Kim D. Local transform features and hybridization for accurate face and human detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(6): 1423-1436 doi: 10.1109/TPAMI.2012.219 [22] He Y G, Sang N. Robust illumination invariant texture classification using gradient local binary patterns. In: Proceedings of the 2011 International Workshop on Multi-Platform/Multi-Sensor Remote Sensing and Mapping. Xiamen, China: IEEE, 2011. 1-6 [23] Song T C, Xin L L, Gao C Q, Zhang G, Zhang T Q. Grayscale-Inversion and rotation invariant texture description using sorted local gradient pattern. IEEE Signal Processing Letters, 2018, 25(5): 625-629 doi: 10.1109/LSP.2018.2809607 [24] Zhang J, Zhao H, Liang J. Continuous rotation invariant local descriptors for texton dictionary-based texture classification. Computer Vision and Image Understanding, 2013, 117(1): 56-75 doi: 10.1016/j.cviu.2012.10.004 [25] Freeman W T, Adelson E H. The design and use of steerable filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1991, 13(9): 891-906 doi: 10.1109/34.93808 [26] Liao S C, Zhu X X, Lei Z, Zhang L, Li S Z. Learning multi-scale block local binary patterns for face recognition. In: Proceedings of the 2007 International Conference on Biometrics. Seoul, Korea: Springer, 2007. 828-837 [27] Dana K J, Nayar S K, Ginneken B V, Nayar S K, Koenderink J J. Reflectance and texture of real-world surfaces. ACM Transactions on Graphics, 1999, 18(1): 1-34 doi: 10.1145/300776.300778 [28] Hayman E, Caputo B, Fritz M, Eklundh J. On the significance of real-world conditions for material classification. In: Proceedings of the 8th European Conference on Computer Vision. Prague, Czech Republic: Springer, 2004. 3024: 253-266 [29] Lowe D G. Distinctive image features from scale-Invariant Keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [30] Lazebnik S, Schmid C, Ponce J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: Proceedings of the 2006 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2006. 2169-2178 -

 下载:
下载:

计量
- 文章访问数: 944
- HTML全文浏览量: 181
- PDF下载量: 115
- 被引次数: 0
