

-
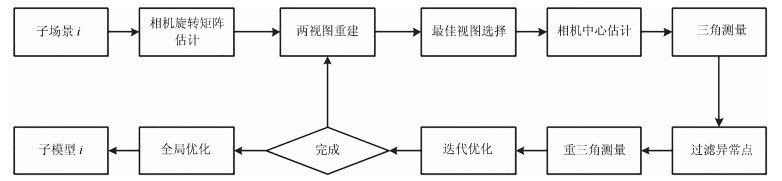
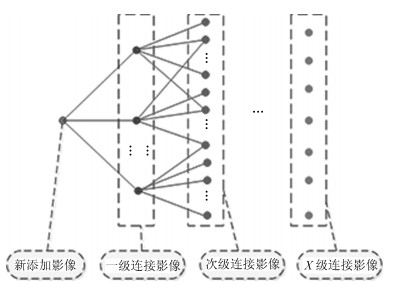
摘要: 针对大范围三维重建, 重建效率较低和重建稳定性、精度差等问题, 提出了一种基于场景图分割的大范围混合式多视图三维重建方法.该方法首先使用多层次加权核K均值算法进行场景图分割; 然后,分别对每个子场景图进行混合式重建, 生成对应的子模型, 通过场景图分割、混合式重建和局部优化等方法提高重建效率、降低计算资源消耗, 并综合采用强化的最佳影像选择标准、稳健的三角测量方法和迭代优化等策略, 提高重建精度和稳健性; 最后, 对所有子模型进行合并, 完成大范围三维重建.分别使用互联网收集数据和无人机航拍数据进行了验证, 并与1DSFM、HSFM算法在计算精度和计算效率等方面进行了比较.实验结果表明, 本文算法大大提高了计算效率、计算精度, 能充分保证重建模型的完整性, 并具备单机大范围场景三维重建能力.Abstract: To solve the problem of low computational efficiency and poor stability of large scale 3D reconstruction, a novel hybrid scheme of large scale reconstruction was proposed. Scene graph was partitioned by multi-level weighted kernel K-means algorithm at first; then sub-scenes were reconstructed by hybrid reconstruction producing sub-models, in which improved optimal image selection criteria, robust triangulation methods and iterative optimization strategies were adopted, and the computational efficiency was improved by using strategies of scene graph part, hybrid reconstruction and partial bundle adjustment (BA); Finally, All sub-models were merged into the final reconstruction result. Experiments were performed using images collected from the internet and UAV aerial images respectively, and comparison was made with 1DSFM and HSFM in terms of computation accuracy and computation efficiency. Experimental results demonstrate the proposed algorithm greatly improves computational efficiency and computational accuracy, fully ensures the integrity of the reconstructed scene and is able to reconstruct large scale scene in single computer.
-
Key words:
- Machine vision /
- 3D reconstruction /
- scene graph partition /
- kernel K-means /
- iterative optimization /
- hybrid reconstruction
-
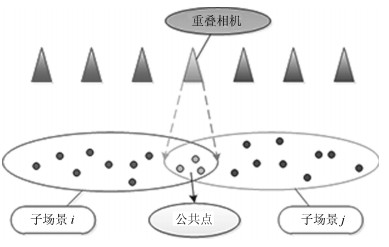
在大数据时代, 数据通常会被分布式地存储在多个节点上, 例如传感器网络[1-3]和分布式数据库[4]中等, 其中每个节点只拥有部分数据. 考虑到单个节点的存储容量有限以及保护数据隐私或安全的需求[5-6], 通常无法将所有数据都发送给一个中心节点, 然后利用集中式的方法处理这些数据, 因此开发高效的算法对分布式存储的数据进行挖掘已成为当前一个重要的研究方向[7-12].
变分贝叶斯(Variational Bayesian, VB)推断[13]是一种功能强大的数据挖掘技术, 被广泛用于解决实际问题, 如识别文档主题[14-15], 对数据进行聚类和密度估计[16]以及预测未知数据[17]等. 近年来, 研究者们已提出很多分布式的VB算法[3, 18-20], 然而在大多数这些算法的每步迭代中, 都需要基于整个数据集更新全局参数, 这不仅会导致算法计算代价大、效率低, 还会导致算法可扩展性差, 难以扩展到在线学习或者流数据处理的情况.
随机变分推断(Stochastic variational inference, SVI)[15]的提出使得贝叶斯推断方法在处理海量数据时具有更高的效率和可扩展性. 它借用了随机优化的方法, 根据基于子样本的噪声自然梯度来优化目标函数, 大大减小了每步迭代时所需的存储量和计算量. 目前已有一些研究者将其扩展为分布式版本, 以提高分布式数据的处理效率以及将其应用于分布式数据流的处理[21]. 具体地, 文献[22]提出了一种有中心的异步分布式SVI算法, 该算法中的中心节点负责收发全局参数, 其余节点并行地更新全局参数. 值得一提的是, 这类有中心的算法往往会存在鲁棒性差, 链路负载不平衡, 数据安全性差等缺点. 在文献[11]中, 交替方向乘子方法(Alternating direction method of multipliers, ADMM)[23]被用来构造两种无中心的分布式SVI算法, 克服了有中心的算法的缺点, 但它们存在每步迭代中全局参数本地更新所需的计算代价大以及不适用于异步网络的缺点.
本文以SVI为核心, 借用多智能体一致优化问题中的扩散方法[24], 发展了一种新的无中心的分布式SVI算法, 并针对异步网络提出了一种适应机制. 在所提出的算法中, 我们利用自然梯度法进行全局参数的本地更新, 并选择对称双随机矩阵作为节点间参数融合的系数矩阵, 减小了本地更新的计算代价. 最后, 我们在伯努利混合模型(Bernoulli mixture model, BMM)和隐含狄利克雷分布(Latent Dirichlet allocation, LDA)上验证了所提出的算法的可行性, 实验结果显示所提出的算法在发现聚类模式, 对初始参数依耐性以及跳出局部最优等方面甚至优于集中式SVI算法, 这是以往分布式VB算法所没有表现出来的.
本文其余部分安排如下: 第1节介绍集中式SVI算法; 第2节介绍本文所提出的分布式SVI算法并给出了一种针对异步网络的适应机制; 第3节展示在BMM和LDA模型上的实验结果; 第4节对本文工作进行总结.
1. 随机变分推断
1.1 模型介绍
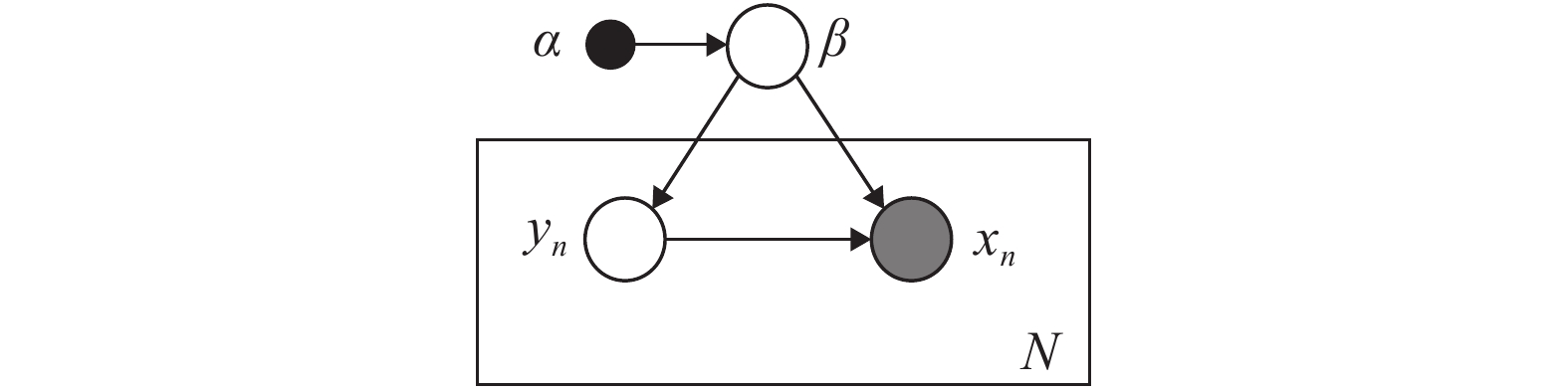
SVI基本模型包含以下这些量: 数据集
${{x}} = \{ {{{x}}_1}, \cdots ,{{{x}}_N}\},$ 局部隐藏变量${{y}} = \{ {{{y}}_1}, \cdots ,{{{y}}_N}\},$ 全局隐藏变量${\beta }$ 以及模型参数${\alpha }.$ 模型的概率图如图1所示, 其中黑色圆圈代表固定参数, 灰色圆圈代表数据集, 白色圆圈代表隐藏变量, 箭头描述了它们之间的依赖关系. 具体地,${\alpha }$ 直接影响${\beta },$ ${\beta }$ 直接影响局部变量对$({{{x}}_n},{{{y}}_n}).$ 我们假设全局隐藏变量${\beta }$ 的先验分布属于指数族分布且具有如下形式:$$p({{\beta} };{{\alpha} }) \propto \exp \left( {{{{\alpha }}^{\rm{T}}}{{u}}({{\beta }}) - A({{\alpha }})} \right)$$ (1) 其中,
${{u}}({\beta })$ 表示自然参数,$A({\alpha })$ 表示归一化函数; 不同局部变量对$({{{x}}_n},{{{y}}_n})$ 之间相互独立且其分布也属于指数族分布, 具体形式如下:$$p({{{x}}_n},{{{y}}_n}|{{\beta} }) \propto \exp \left( {{{u}}^{\rm{T}}{{({\beta })}}f({{{x}}_n},{{{y}}_n})} \right)$$ (2) 其中
$f({{{x}}_n},\ {{{y}}_n})$ 表示自然充分统计量; 此外, 还假设上述两个指数族分布满足共轭条件关系[25], 以使后验分布与先验分布的形式相同. 我们的目标是根据观测到的数据集来估计局部隐藏变量的分布, 即其后验分布$p({{y}},{\beta }|{{x}}).$ 1.2 平均场变分推断
平均场变分推断是一种用一个可以因式分解的变分分布去近似后验分布的方法. 在上一节介绍的模型基础上, 我们可以用变分分布
$q({{y}},{\beta })$ 来近似$p({{y}},{\beta }|{{x}}),$ 并假设该变分分布满足以下条件:$$q({{y}},{\beta }) = q({\beta }{\rm{;}}{\lambda })\prod\limits_n {q({{{y}}_n};{{\phi }_n})} $$ (3) $$q({{\beta }};{{\lambda} }) \propto \exp \left( {{{\lambda }^{\rm{T}}}{{u}}({{\beta} }) - A({{\lambda} })} \right)$$ (4) $$q({{{y}}_n};{{\phi }_n}) \propto \exp \left( {{{\phi }_n^{\rm{T}}}{{u}}({{{y}}_n}) - A({{\phi }_n})} \right)$$ (5) 其中,
${\lambda }$ 和${\phi } = \{ {{\phi }_1},{{\phi }_2}, \cdots ,{{\phi }_N}\}$ 是变分参数. 此时需要最小化$q({{y}},{\beta })$ 和$p({{y}},{\beta }|{{x}})$ 之间的Kullback-Leibler (KL)散度来让$q({{y}},{\beta })$ 逼近$p({{y}},{\beta }|{{x}}),$ 这等价于最大化$$L({\lambda },{\phi }) = {\mathbb{E}_q}\left[ {\ln \frac{{p({\beta };{\alpha })}}{{q({\beta };{\lambda })}}} \right] + \sum\limits_{n = 1}^N {{\mathbb{E}_q}\left[ {\ln \frac{{p({{{x}}_n},{{{y}}_n}|{\beta })}}{{q({{{y}}_n};{{\phi }_n})}}} \right]} $$ (6) 其中,
${\mathbb{E}_q}\left[ \cdot \right]$ 表示在分布$q({{y}},{\beta })$ 下的期望函数,$L({\lambda },{\phi })$ 是对数证据$\ln p({{x}})$ 的一个下界, 被称为Evidence lower bound (ELBO)[15]. 基于$q({{y}},{\beta }))$ 可分解的假设, 最大化$L({\lambda },{\phi })$ 可以利用坐标上升法[26]通过交替更新${\lambda }$ 和${\phi }$ 来实现. 下文讨论的SVI 以上述平均场变分推断方法为基础.如果我们固定
${\phi },$ 则可以把$L({\lambda },{\phi })$ 看成是${\lambda }$ 的函数, 此时需要求解$$L({\lambda }) = \mathop {\max }\limits_{{\phi }} L({\lambda },{\phi })$$ (7) 常用的方法是对其求(欧氏)梯度, 但是用欧氏距离表征不同
${\lambda }$ 之间的远近关系是不合理的, 这是因为${\lambda }$ 为变分参数, 我们所关心的是不同的${\lambda }$ 所刻画的分布$q({{y}},{\beta })$ 之间的差异, 此时可以引入自然梯度[15], 它表示的是函数在黎曼空间上的梯度. 通过对$L({\lambda },{\phi })$ 关于${\phi }$ 求自然梯度, 可以将平均场变分推断推广到随机优化的版本, 即随机变分推断. 具体地, 我们定义如下的随机函数$${L_I}({\lambda }) \!:=\! N\mathop {\max }\limits_{{{\phi }_I}} {\mathbb{E}_q}\!\left[ {\ln \frac{{p({{{x}}_I},{{{y}}_I}|{\beta })}}{{q({{{y}}_I};{{\phi }_I})}}} \right] \!+\! {\mathbb{E}_q}\!\left[ {\ln \frac{{p({\beta };{\alpha })}}{{q({\beta };{\lambda })}}} \right]\!$$ (8) 其中,
$I$ 是均匀取值于$\left\{ {1, \cdots ,N} \right\}$ 的随机变量. 易知${L_I}({\lambda })$ 的期望等于$L({\lambda })$ , 因此每次均匀地选取一个数据点$n$ 时,${L_n}({\lambda })$ 给出了$L({\lambda })$ 的一个无偏估计. 根据随机优化理论, 集中式SVI的过程由下面两步构成:1) 均匀地随机选取一个数据点
$n$ , 并计算当前最优的局部变分参数${\phi }_n^*;$ 2) 通过
$${{\lambda }^{t + 1}} = (1 - {\rho _t}){{\lambda }^t} + {\rho _t}\left( {{\alpha } + N{\mathbb{E}_{{\phi }_n^*}}\left[ {f({{{x}}_n},{{{y}}_n})} \right]} \right)$$ (9) 更新全局变分参数
${\lambda }.$ 上述SVI算法一次迭代只采样一个数据点, 其也可以被直接扩展成一次采样一个数据批量(Batch)的版本, 详见文献[15].
2. 基于扩散方法的分布式SVI算法
2.1 问题描述
我们考虑一个由
$J$ 个节点组成的分布式网络, 其中每个节点$i$ 存储包含${N_i}$ 个数据项的数据集${{{x}}_i} = \{ {{{x}}_{i1}},\cdots,{{{x}}_{i{N_i}}}\},$ 于是整个网络上存储的完整数据集为${{x}} = \{ {{{x}}_1},\cdots,{{{x}}_J}\},$ 总数据项数为$N = \displaystyle\sum\nolimits_i {{N_i}}.$ 假设网络的通讯拓扑是一个无向图$G = (V,E),$ 其中$V = \{ 1,\cdots,J\}$ 是节点集合,$E \subseteq V \times V$ 是边集合,$(i,j) \in E$ 表明信息可以在节点$i$ 和节点$j$ 之间直接传输, 记节点$i$ 的邻居集合为${B_i} = \{ j \in V: (j,i)$ $\in E\}.$ 此外, 我们还假设$G$ 是连通的, 即对$\forall i \ne j,$ 存在至少一条路径连接节点$i$ 和节点$j$ .如果记节点
$i$ 的局部隐藏变量为${{{y}}_i} = $ $\{ {{{y}}_{i1}},\cdots, {{{y}}_{i{N_i}}}\},$ 记对应的局部变分参数为${{\phi }_i} = $ $\{ {{\phi }_{i1}},\cdots,{{\phi }_{i{N_i}}}\},$ 则ELBO可以写为$$L({\lambda },{\phi }) = {\mathbb{E}_q}\left[ {\ln \frac{{p({\beta };{\alpha })}}{{q({\beta };{\lambda })}}} \right] + \sum\limits_{j = 1}^J {{\mathbb{E}_q}\left[ {\ln \frac{{p({{{x}}_j},{{{y}}_j}|{\beta })}}{{q({{{y}}_j};{{\phi }_j})}}} \right]} $$ (10) 2.2 算法设计
我们借用多智能体一致优化问题中的扩散方法来发展分布式SVI算法. 扩散方法的基本思想是交替执行本地更新和节点间参数融合两个步骤, 从而使所有节点的参数收敛到所希望的全局最优值或者局部最优值.
对于节点
$i$ , 如果定义其局部ELBO为$${L_i}({\lambda },{{\phi }_i}) = {\mathbb{E}_q}\left[ {\ln \frac{{p({\beta };{\alpha })}}{{q({\beta };{\lambda })}}} \right] + J{\mathbb{E}_q}\left[ {\ln \frac{{p({{{x}}_i},{{{y}}_i}|{\beta })}}{{q({{{y}}_i};{{\phi }_i})}}} \right]$$ (11) 则显然有
$L({\lambda },{\phi }) = \dfrac{1}{J}\displaystyle\sum\nolimits_i {{L_i}({\lambda },{{\phi }_i})}$ , 因此每个节点$i$ 可以把${L_i}({\lambda },{{\phi }_i})$ 作为优化目标, 进行本地更新. 在本地更新步骤中, 我们分批次训练以提高学习效率. 不失一般性, 将${{{x}}_i}$ 划分成$M$ 个子集${{{x}}_i} = \{ {{x}}_{i1}^b,\cdots, {{x}}_{iM}^b\},$ 对应地,${{{y}}_i} \!=\! \{ {{y}}_{i1}^b,\cdots,{{y}}_{iM}^b\},$ ${{\phi }_i} \!=\! \{ {\phi }_{i1}^b,\cdots, {\phi }_{iM}^b\},$ 定义$$ \begin{split} L_{im}^b({\lambda },{\phi }_{im}^b) =\, & {\mathbb{E}_q}\left[ {\ln \frac{{p({\beta };{\alpha })}}{{q({\beta };{\lambda })}}} \right] +\\ &MJ{\mathbb{E}_q}\left[ {\ln \frac{{p({{x}}_{im}^b,{{y}}_{im}^b|{\beta })}}{{q({{y}}_{im}^b;{\phi }_{im}^b)}}} \right] \end{split}$$ (12) 不难证明
$L_{im}^b({\lambda },{\phi }_{im}^b)$ 是${L_i}({\lambda },{{\phi }_i})$ 的一个无偏估计, 因此可以基于子样本${{x}}_{im}^b$ 更新参数. 令${{\phi }_i}$ 表示节点$i$ 的全局变分参数, 则类似于集中式[2]的情况, 节点$i$ 中第$t$ 次本地更新由下列公式描述:$${\phi }_{im}^{{b^*}} = \arg \mathop {\max }\limits_{{\phi }_{im}^b} L_{im}^b({\lambda }_i^t,{\phi }_{im}^b)$$ (13) $${z}_i^{t + 1} = {\lambda }_i^t + {\rho _{_t}}\tilde \nabla L_{im}^b({\lambda }_i^t,{\phi }_{im}^{{b^ * }})$$ (14) 其中,
$\tilde \nabla L_{im}^b({\lambda },{\phi }_{im}^{b*})\! =\! {\alpha } \!-\! {\lambda } \!+\! MJ\displaystyle\sum\nolimits_{{x_{in}} \in x_{im}^b} {\mathbb{E}_q}[ f({{x}}_{in}^{}, {{y}}_{in}^{}) ]$ 表示$L_{im}^b({\lambda },{\phi }_{im}^{b*})$ 关于${\lambda }$ 的自然梯度,$\tilde \nabla $ 为自然梯度符号. 我们选择随时间衰减形式的学习率${\rho _t} = {(t + \tau )^{ - \kappa }},$ 其中$\kappa \in [0.5,1],$ $\tau \geq 0,$ 这样一来根据随机优化理论[15], 可以保证基于噪声自然梯度的更新式(14)可以使得全局变分参数收敛到${L_i}({\lambda },{{\phi }_i})$ 的一个局部最优值.注意本地更新只能使每个节点的全局变分参数独立地收敛到各自的局部ELBO的局部最优值, 我们还要保证每个节点学得的全局变分参数收敛到一致, 即
$||{{\lambda }_i} - {{\lambda }_j}|| \to 0,$ $\forall i \ne j.$ 由于我们已经假设拓扑图是连通的, 因此只要使$||{{\lambda }_i} - {{\lambda }_j}|| \to 0,$ $\forall (i,j) \in E$ 就可以保证所有节点的全局变分参数都收敛到一致. 为此, 根据扩散方法, 我们在每次本地更新之后, 将每个节点的当前全局变分参数发送给其邻居节点, 然后将当前的全局变分参数与从邻居节点接受到的全局变分参数进行融合. 上述过程可以由下面公式描述:$${\lambda }_i^{t + 1} = \sum\limits_{j \in {B_i} \cup \{ i\} } {{p_{ji}}{z}_j^{t + 1}} $$ (15) 其中,
${p_{ij}}$ 是融合系数, 我们采用如下的定义$$ {p}_{ij}=\left\{ \begin{array}{l} \dfrac{1}{\mathrm{max}(|{B}_{i}|,|{B}_{j}|)}\;\;,i\in {B}_{j}\\ 0,\qquad\qquad\qquad\;\; i\ne j ,\;i\notin {B}_{j}\\ 1-{\displaystyle \sum _{l=1,l\ne i}^{J}{p}_{il}},\;\;\quad i=j,\;i\notin {B}_{j} \end{array} \right. $$ (16) 事实上, 如上定义的
$[{p_{ij}}]$ 是一个对称随机矩阵. 当迭代次数很大的时候,${\rho _t}$ 变得很小, 则有${z}_i^{t + 1} \approx {\lambda }_i^t,$ 分布式SVI算法退化成由式(15)描述的平均一致性协同过程, 所以${\lambda }_i^t$ 将收敛到所有节点初始参数值的平均值. 这样使得训练结果不会对任何节点的数据分布有偏向性.2.3 针对异步网络的适应机制
上节所述的分布式SVI算法默认是同步执行的, 即所有节点在每个迭代步同步地执行本地更新和参数融合两个步骤. 但是所有节点同步执行需要使用时间同步协议去估计和补偿时序偏移, 这会带来额外的通信负载. 此外, 执行快的节点需要等待执行慢的节点, 这会大大降低算法的执行速度. 为此我们设计了一种机制使所提出的分布式SVI算法适应异步通信网络. 具体地, 每个节点额外开辟一块存储区域将邻居节点发送过来的
${\lambda }_i^t$ 存储起来. 在每个参数融合步中, 如果在等待一定的时间后收到了来自邻居节点发送过来的${\lambda }_i^t$ , 则更新存储区域中的${\lambda }_i^t$ 的值, 然后, 用更新后的${\lambda }_i^t$ 进行本地参数更新; 否则, 直接用存储区域的${\lambda }_i^t$ 值进行本地参数更新. 这样一来, 既可以使所提出的分布式算法以异步方式执行, 又尽可能地保证了算法的性能.3. 实验
这一节我们将所提出的分布式SVI算法(我们称之为异步分布式SVI)应用于BMM模型和LDA主题模型, 并在不同的数据集上测试其性能. 并且将其与集中式SVI算法和dSVB算法[3]进行对比, 其中dSVB算法被我们以同样的方式扩展成随机的版本以方便比较.
3.1 伯努利混合模型
我们考虑具有
$K$ 个成分的混合多变量伯努利模型. 该模型的全局隐藏变量包括: 每个成分$k$ 的全局隐藏变量${{\beta }_k}$ , 其维度等于数据维度, 每个维度的值表示该维度的数据值属于“0”的概率, 以及成分的混合概率${\pi } = \{ {\pi _1},\cdots,{\pi _K}\},$ 其中隐藏变量的先验分布形式如下:$$p({\pi }) = Dir({\pi };{\alpha })$$ (17) $$p({{y}_{in}}|{\pi }) = \prod\limits_{k = 1}^K {{\pi _k}^{{y_{ink}}}} $$ (18) $$p({\beta }) = \prod\limits_{k = 1}^K {p({{\beta }_k})} \propto \prod\limits_{k = 1}^K {\prod\limits_{d = 1}^D {\beta _{kd}^{a - 1}{{(1 - {\beta _{kd}})}^{b - 1}}} } $$ (19) 其中,
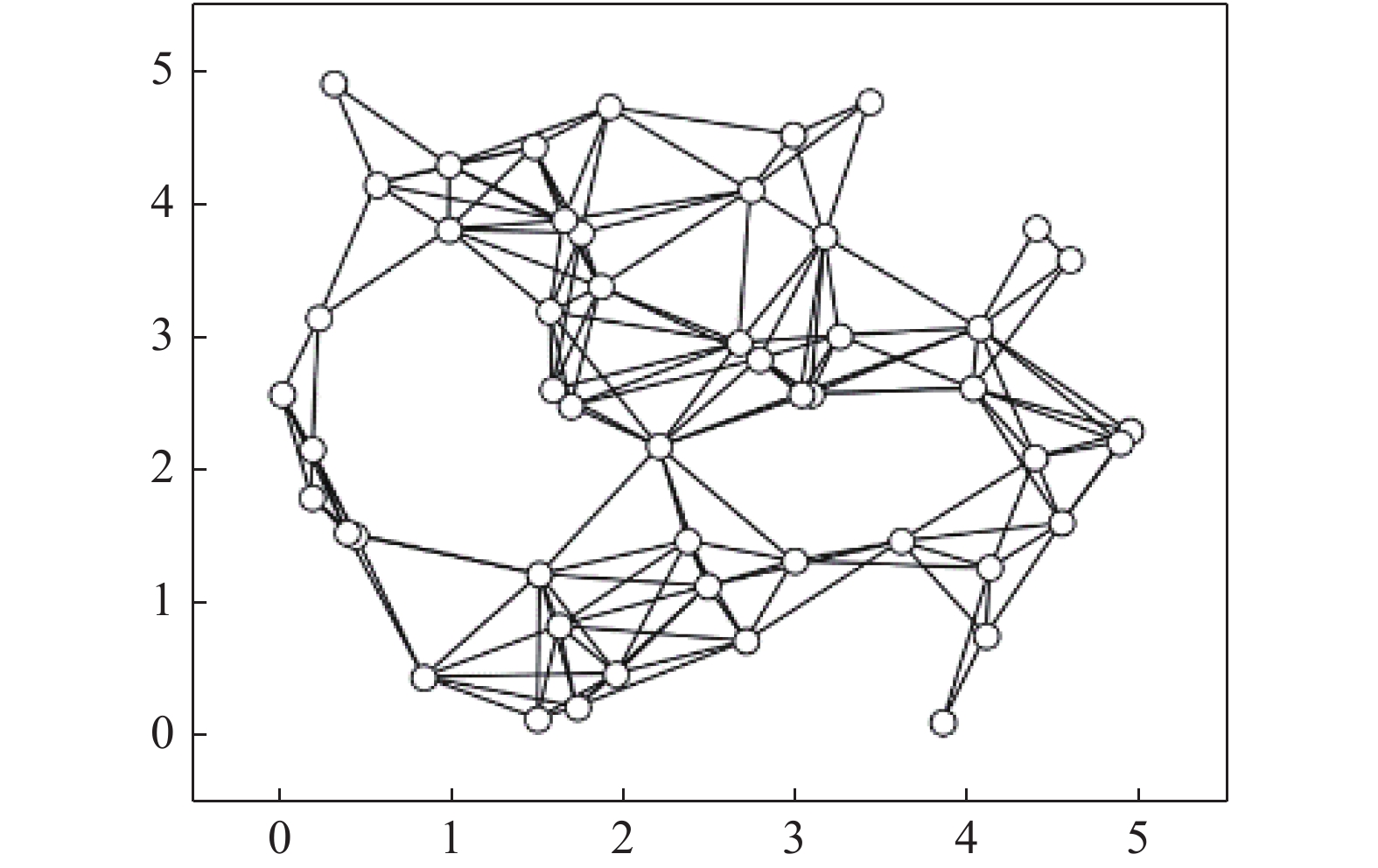
${\alpha } = {[\alpha ]^K},$ $a$ 和$b$ 是固定的超参数, 在BMM模型上的实验中, 我们均设置$\alpha = a = b = 1.$ 我们将混合多变量伯努利模型应用到MNIST数据集上. 在预处理中, 每张图的每个像素根据其像素值被设为0或者1, 然后每张图被展开成28 × 28 = 784维的向量. 我们随机生成包含50个节点, 166条边的无向连通网络, 其拓扑结构如图2所示, 并将训练数据平均分给50个节点, 每个节点包含1 200条数据(整个MNIST训练集包含60 000条数据). 实验中, 设置
$K = 40$ , 并设置全局隐藏变量的先验分布为均匀分布.图3展示了所提出的异步分布式SVI算法在
$\kappa = 0.5,$ $\tau = 10$ 下, 每份数据分6个批次训练200个epoch得到的聚类中心 (由每个成分$k$ 的全局隐藏变量${{\beta }_k}$ 的期望所定义的向量对应的图片) 和相同设置下集中式SVI算法得到的聚类中心. 由图3可知, 异步分布式SVI算法可以充分找到所有潜在的聚类模式, 而集中式SVI则往往不能充分找出所有的聚类模式. 图 3 异步分布式SVI算法和集中式SVI算法得到的聚类中心Fig. 3 Cluster centers obtained by the asynchronous distributed SVI and the centralized SVI
图 3 异步分布式SVI算法和集中式SVI算法得到的聚类中心Fig. 3 Cluster centers obtained by the asynchronous distributed SVI and the centralized SVI在相同设置下多次运行三种算法得到的所有节点估计的ELBO的平均值以及相校平均值的偏差演化曲线如图4所示, 可以看到异步分布式SVI算法相比集中式SVI算法能够收敛到更好的值, 并且多次运行得到的结果之间的误差更小, 表现更加稳定. 此外, 异步执行的方式破坏了dSVB算法的收敛性, 而异步分布式SVI算法对异步网络具有良好的适应性.
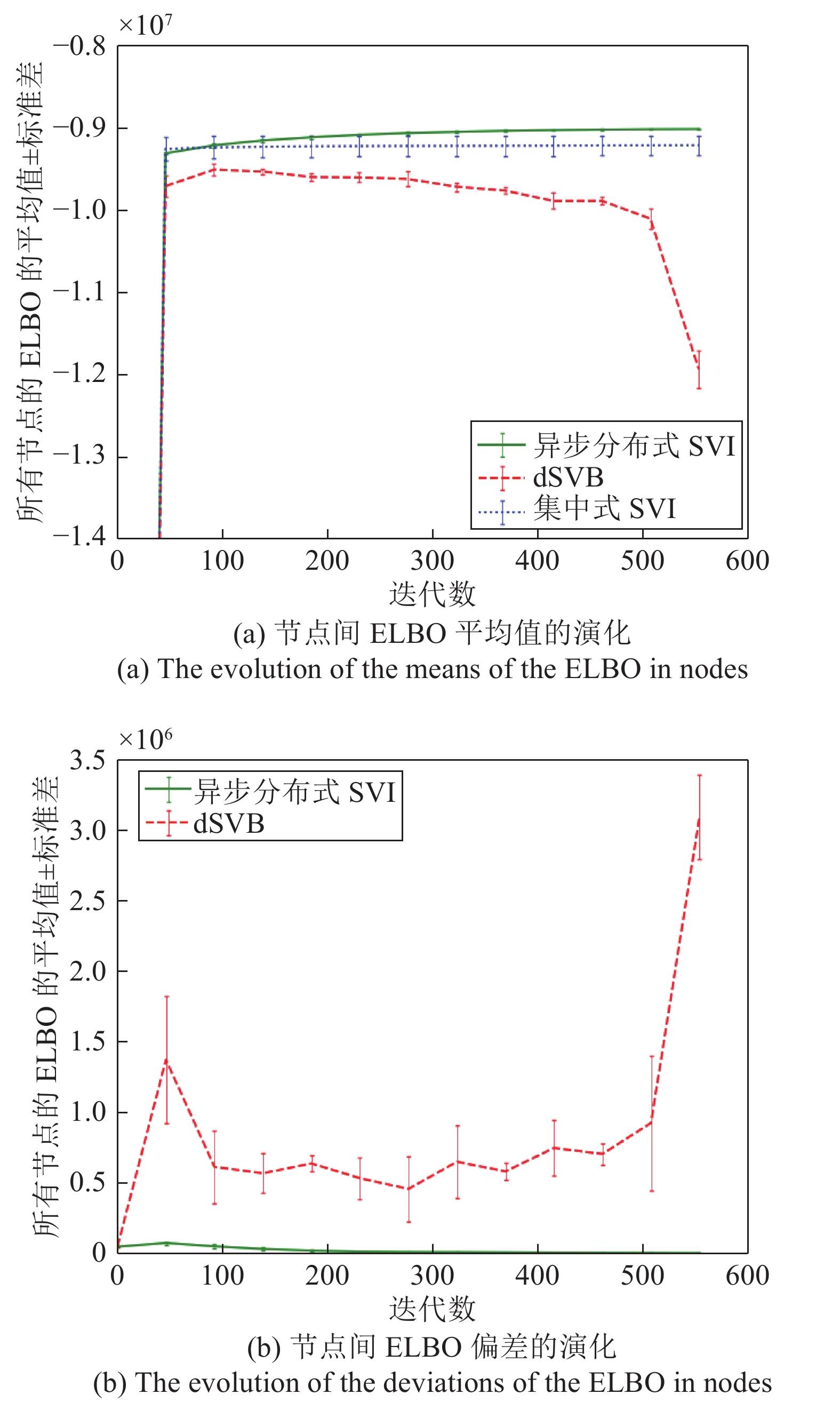 图 4 异步分布式SVI算法、dSVB算法、集中式SVI算法的ELBO的平均值和偏差演化Fig. 4 The evolution of the means and deviations of the ELBO for the asynchronous distributed SVI, the dSVB, and the centralized SVI
图 4 异步分布式SVI算法、dSVB算法、集中式SVI算法的ELBO的平均值和偏差演化Fig. 4 The evolution of the means and deviations of the ELBO for the asynchronous distributed SVI, the dSVB, and the centralized SVI为了研究超参数
$\kappa $ 和$\tau $ 对所提出的分布式SVI算法表现的影响, 我们在$(\kappa = 0.5,\tau = 1),$ $(\kappa = 0.5, \tau \!=\! 10),$ $(\kappa \!=\! 0.5,$ $\tau \!=\! 100),$ $(\kappa \!=\! 0.75,\tau \!=\! 10),$ $(\kappa = 1, \tau = 10)$ 几组参数下进行实验, 所得到的所有节点ELBO的平均值的演化曲线见图5, 可以看到在不同的$(\kappa ,\tau )$ 设置下所提出的异步分布式SVI均优于集中式SVI.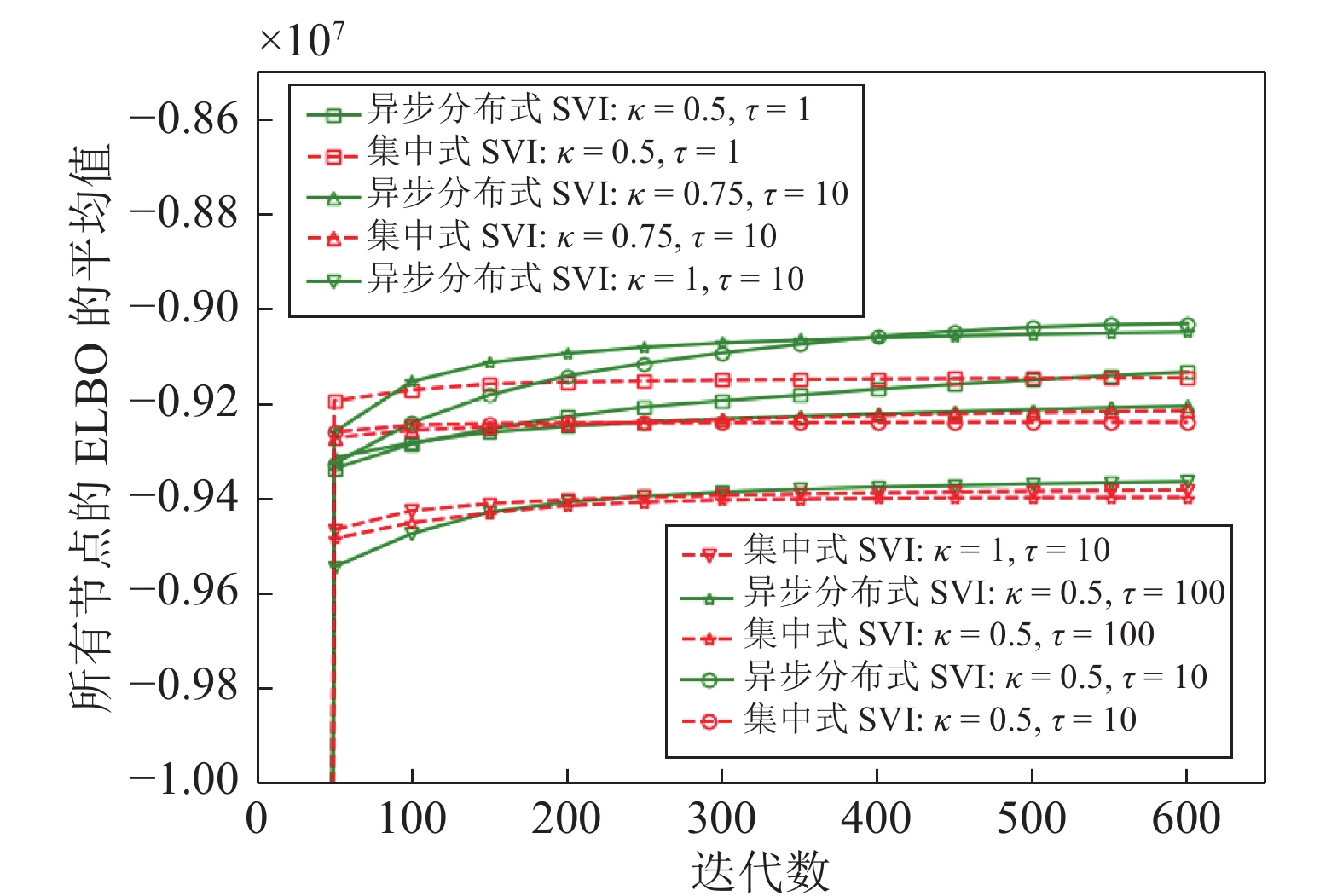 图 5 不同
图 5 不同$(\kappa ,\tau )$ 设置下异步分布式SVI和集中式SVI的ELBO的平均值演化Fig. 5 The evolution of the means of the ELBO for the asynchronous distributed SVI and the centralized SVI under different settings of$(\kappa ,\tau )$ 3.2 LDA主题模型
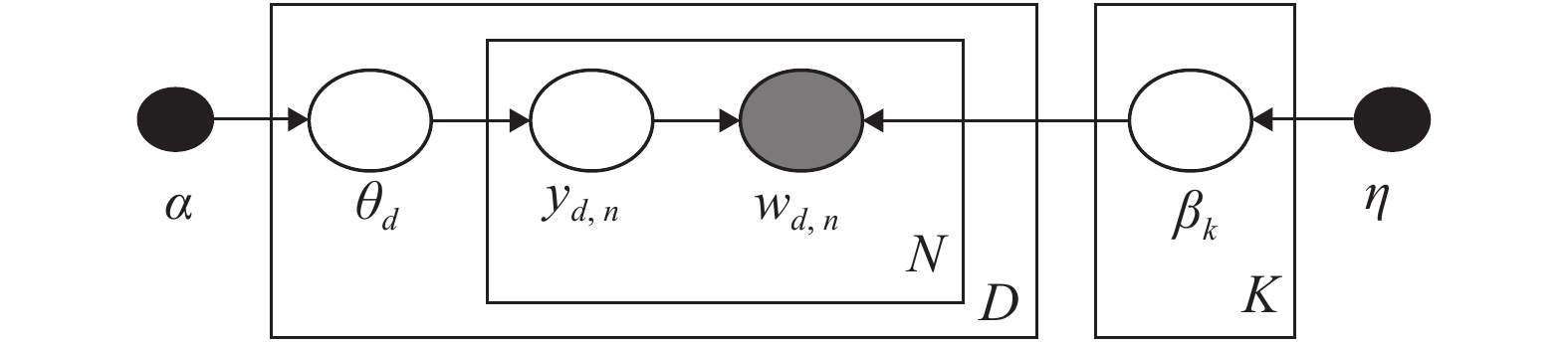
LDA主题模型是文档集的概率模型, 它使用隐藏变量对重复出现的单词使用模式进行编码, 由于这些模式在主题上趋于一致, 因此被称为“主题模型”. 其已经被应用于很多领域, 例如构建大型文档库的主题导航或者辅助文档分类. LDA模型的贝叶斯网络结构如图6所示, 其中变量的说明见表1.
表 1 LDA模型变量Table 1 Variables in LDA model变量 $\alpha $ $\eta $ $K$ $D$ $N$ ${\theta _d}$ ${y_{d,n}}$ ${w_{d,n}}$ ${\beta _k}$ 类型 固定参数 固定参数 固定参数 输入参数 输入参数 局部隐藏变量 局部隐藏变量 单词向量 全局隐藏变量 描述> 主题数 文档数 单词数 决定文档的主题分布 单词所属的主题 决定主题的单词分布 分布 $Dir({\theta _d}|\alpha )$ $Mult({y_{d,n}}|{\theta _d})$ $Mult({w_{d,n}}|{\beta _k},{y_{d,n}})$ $Dir({\beta _k}|\eta )$ 我们首先在New York Times和Wikipedia两个数据集上验证异步分布式算法在LDA模型上的性能. 首先我们生成一个包含5个节点7条边的网络, 将每个数据集的文档随机分配给各个节点. 在实验中我们设置
$K = 5,$ 并以文档集的生成概率的对数$\ln p(w) = \displaystyle\sum\nolimits_d {\sum\nolimits_n {\ln p({w_{d,n}}|{\beta _k},{y_{d,n}})} }$ 作为评价指标.图7展示了在
$\alpha = 0.2,$ $\eta = 0.2,$ $\kappa = 0.5,$ $\tau = 10,$ 训练epoch取40, 分布式算法中每个节点的批大小取10, 集中式算法的批大小取50的设置下, 异步分布式SVI, 集中式SVI和dSVB以异步方式分别在两个数据集上运行多次得到的$\ln p(w)$ 的演化曲线, 可见异步分布式SVI算法表现优于另外两种算法. 不同参数设置下异步分布式SVI和集中式SVI在New York Times数据集上收敛时的$\ln p(w)$ 见表2, 可见不同设置下异步分布式SVI的表现均优于集中式SVI.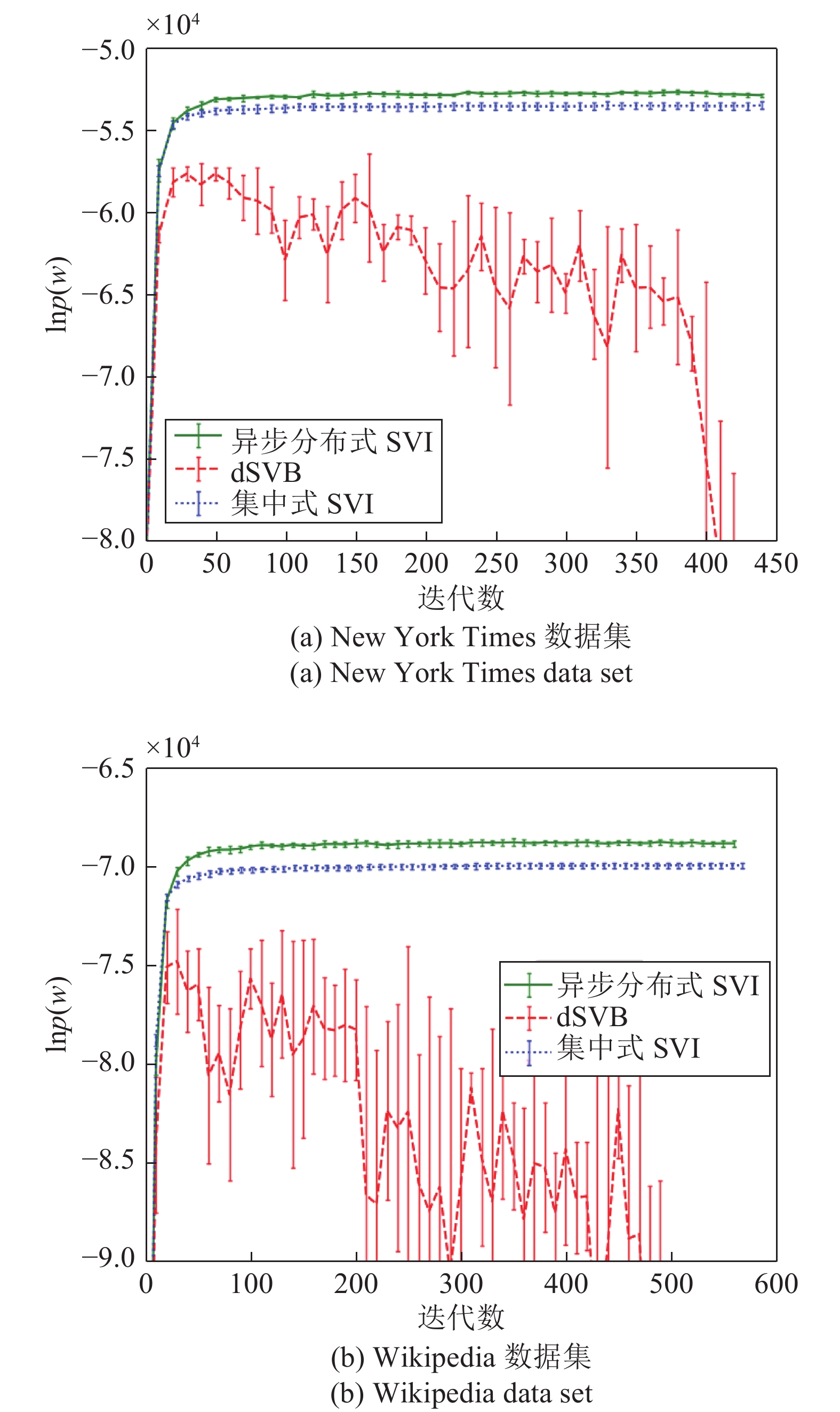 图 7 异步分布式SVI、集中式SVI和dSVB在两个数据集上的表现Fig. 7 Performance of the asynchronous distributed SVI, the centralized SVI, and the dSVB on the two data sets表 2 不同参数设置下异步分布式SVI和集中式SVI收敛的值Table 2 The convergent values of the asynchronous distributed SVI and the centralized SVI under different parameter settings
图 7 异步分布式SVI、集中式SVI和dSVB在两个数据集上的表现Fig. 7 Performance of the asynchronous distributed SVI, the centralized SVI, and the dSVB on the two data sets表 2 不同参数设置下异步分布式SVI和集中式SVI收敛的值Table 2 The convergent values of the asynchronous distributed SVI and the centralized SVI under different parameter settings参数设置 $\begin{gathered} \alpha = \eta = 0.4 \\ \kappa = 0.5,\tau = 1 \\ \end{gathered} $ $\begin{gathered} \alpha = \eta = 0.8 \\ \kappa = 0.5,\tau = 1 \\ \end{gathered} $ $\begin{gathered} \alpha = \eta = 0.4 \\ \kappa = 0.7,\tau = 10 \\ \end{gathered} $ $\begin{gathered} \alpha = \eta = 0.8 \\ \kappa = 0.7,\tau = 10 \\ \end{gathered} $ $\begin{gathered} \alpha = \eta = 0.4 \\ \kappa = 1,\tau = 100 \\ \end{gathered} $ $\begin{gathered} \alpha = \eta = 0.8 \\ \kappa = 1,\tau = 100 \\ \end{gathered} $ 异步分布式SVI —53791.33 —55554.12 —54350.50 —56212.30 —57003.45 —57567.67 集中式SVI —54198.30 —56327.50 —54776.18 —56721.87 —57805.78 —58191.39 然后我们在复旦大学中文文本分类数据集上测试所提出的异步分布式SVI算法. 该数据集来自复旦大学计算机信息与技术系国际数据库中心自然语言处理小组, 其由分属20个类别的9 804篇文档构成, 其中20个类别的标签分别为Art、Literature、 Education、Philosophy、History、Space、Energy、Electronics、Communication、Computer、Mine、Transport、Environment、Agriculture、Economy、Law、Medical、Military、Politics和Sports. 在预处理步骤中, 我们首先去除了文本中的数字和英文并用语言技术平台(Language technology plantform, LTP)的分词模型对文本进行分词处理. 为了减小训练的数据量, 我们只读取每个类别的前100篇文档进行训练. 图8展示了在
$K = 20,$ $\alpha = 0.2,$ $\eta = 0.2,$ $\kappa = 0.5,$ $\tau = 10,$ 分布式算法Batch size(批大小)取2, 集中式算法batch size取100的设置下, 异步分布式SVI和集中式SVI分别在复旦大学中文文本分类数据集上运行多次得到的$\ln p(w)$ 的演化曲线, 可以看到异步分布式SVI收敛速度慢于集中式SVI, 但是最终得到的$\ln p(w)$ 值优于集中式SVI.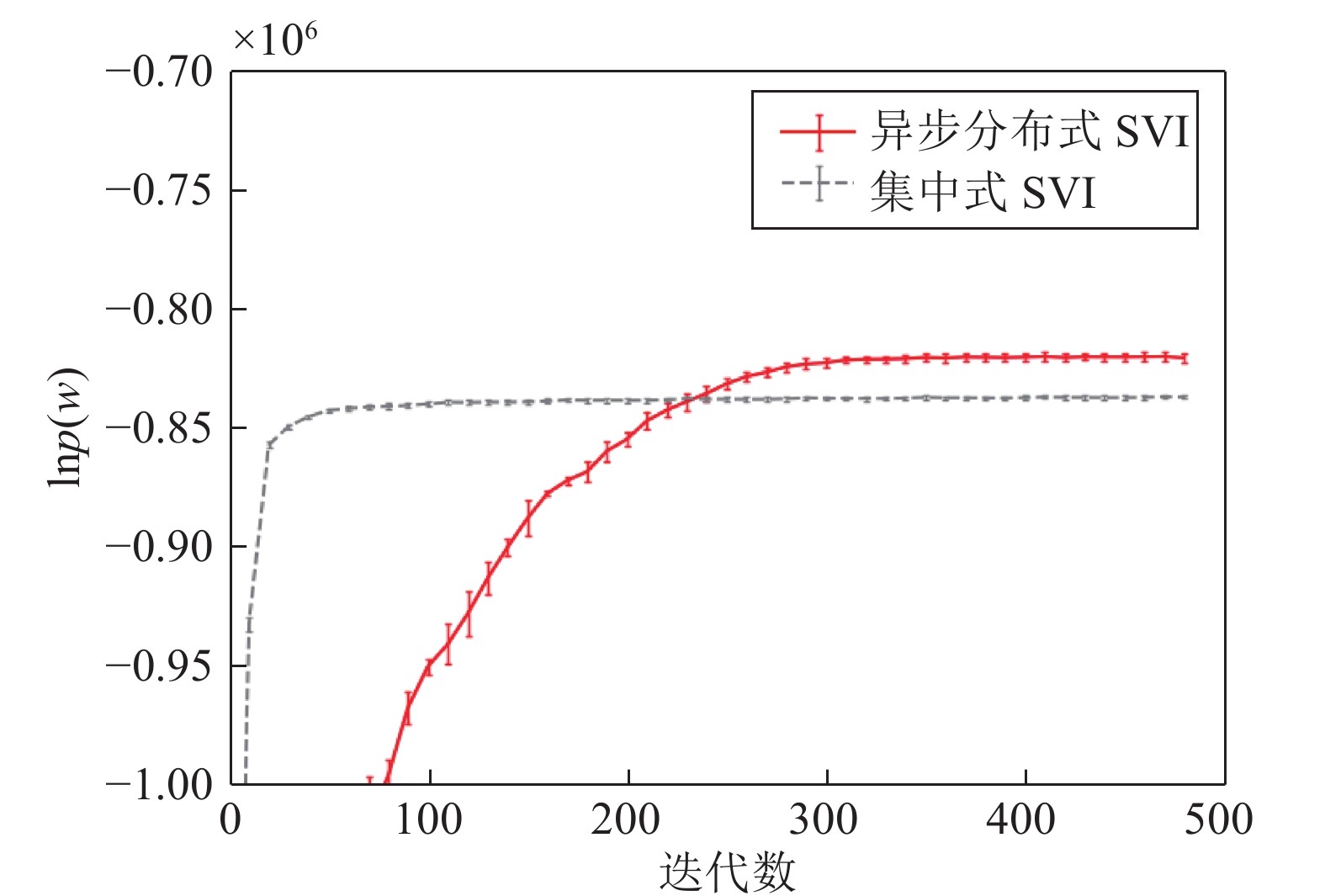 图 8 异步分布式SVI和集中式SVI在复旦大学中文文本分类数据集上的表现Fig. 8 Performance of the asynchronous distributed SVI and the centralized SVI on the Chinese text classification data set of Fudan University
图 8 异步分布式SVI和集中式SVI在复旦大学中文文本分类数据集上的表现Fig. 8 Performance of the asynchronous distributed SVI and the centralized SVI on the Chinese text classification data set of Fudan University图9展示了在表3所示的超参数组合设置下异步分布式SVI和集中式SVI在复旦大学中文文本分类数据集上训练100个epoch得到的
$\ln p(w)$ 的值的对比, 其中横坐标为集中式SVI得到的$\ln p(w)$ 的值, 纵坐标为对应超参数设置下异步分布式SVI得到的$\ln p(w)$ 的值. 可以看到大部分数据点都位于左上方, 表明大部分情况下异步分布式SVI都优于集中式SVI. 并且注意到当batch size取1时异步分布式SVI表现最差, 在$(\kappa = 0.5,\tau = 1, {\rm{batch size}} = 1)$ 的设置下其表现不如集中式SVI. 我们认为这是由于当batch size太小时, 分布式SVI的收敛速度过慢造成的.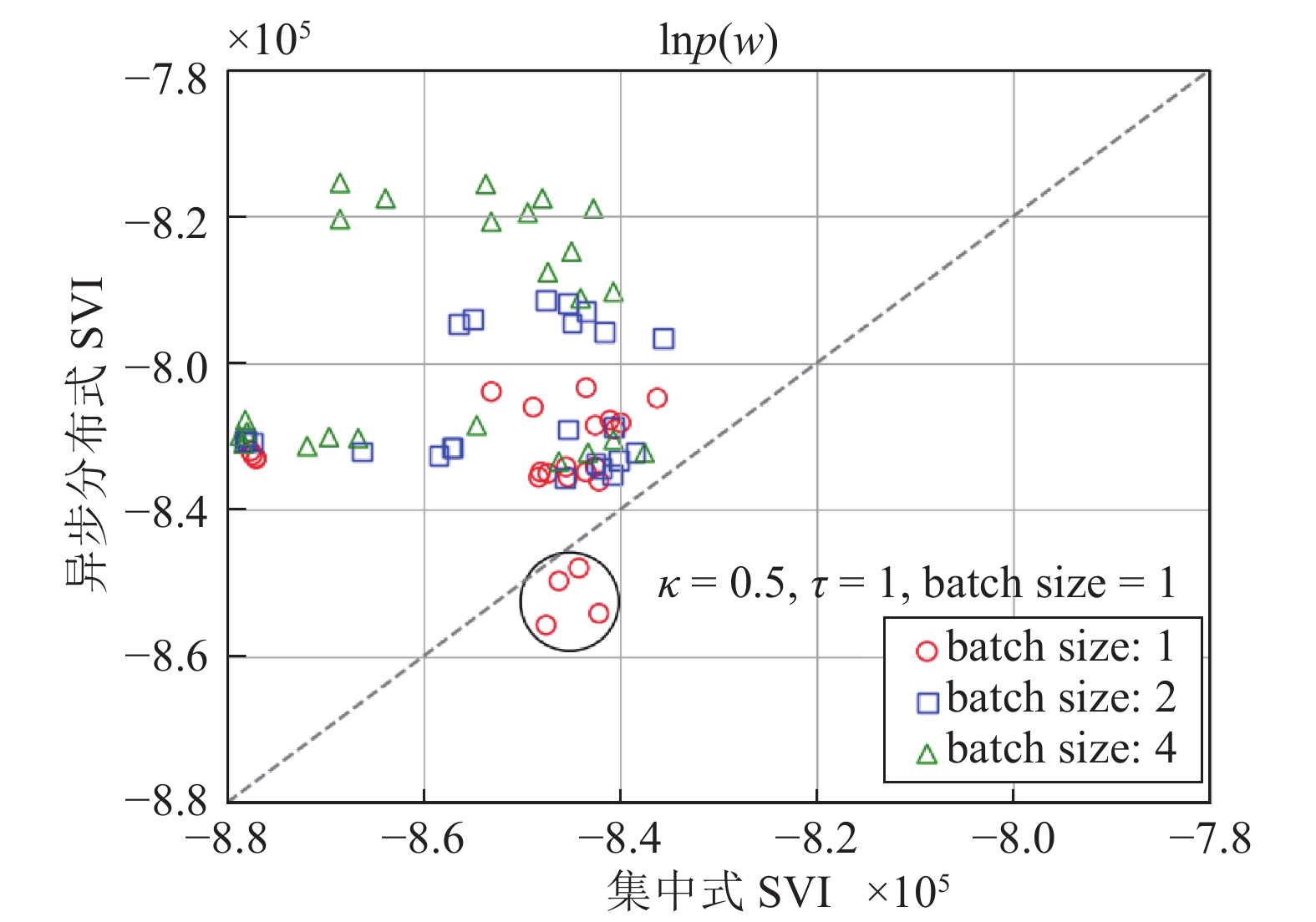 图 9 不同超参数设置下异步分布式SVI和集中式SVI在复旦大学中文文本分类数据集上表现Fig. 9 Performance of the asynchronous distributed SVI and the centralized SVI on the Chinese text classification data set of Fudan University under different hyperparameter settings表 3 超参数取值表Table 3 The values of hyperparameters
图 9 不同超参数设置下异步分布式SVI和集中式SVI在复旦大学中文文本分类数据集上表现Fig. 9 Performance of the asynchronous distributed SVI and the centralized SVI on the Chinese text classification data set of Fudan University under different hyperparameter settings表 3 超参数取值表Table 3 The values of hyperparameters$\kappa $ $\tau $ batch size $\alpha $ $\eta $ 0.5 1 1 0.1 0.1 1.0 10 2 0.2 0.2 — 100 4 — — 4. 结论
本文针对无中心的分布式网络, 基于扩散方法提出了一种新颖的分布式SVI算法, 其中采用自然梯度法进行本地更新以及采用对称双随机矩阵作为信息融合系数, 并且为其设计了一种针对异步网络的适应机制. 然后将其应用于BMM和LDA主题模型. 在不同数据集上的实验均表明所提出的算法确实适用于异步分布式网络, 而且其在发现聚类模式和对抗浅的局部最优方面的表现优于集中式SVI算法.
-

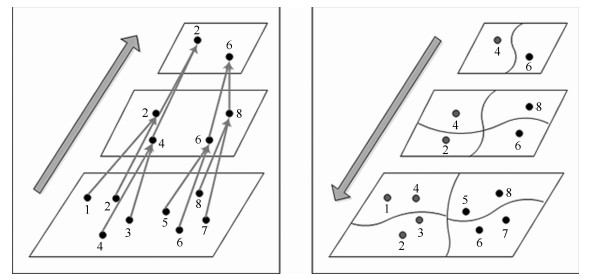
图 7 大雁塔场景图分割重建结果(上:分割后子场景图; 中:子场景图相机地面投影; 下:子场景图重建结果)
Fig. 7 Reconstruction results of DAYANTA based on scene graph partition (up: sub-scene graph; middle: camera ground projection in sub-scene graph; below: reconstruction result of sub-scene graph)

图 8 场景图分割重建结果(上:分割后子场景图; 下:子场景图重建结果)
Fig. 8 Reconstruction results of Rome Forum based on scene graph partition (up: sub-scene graph; below: reconstruction result of sub-scene graph)

图 10 航测数据集(西安大雁塔、大连市区、某城市市区)三维重建结果
Fig. 10 3D reconstruction result of aerial images (Da-Yan Tower in Xi$'$an, Dalian City, and A City Center)

图 11 稀疏重建结果(左:嵩山, 右: Quad)
Fig. 11 Sparse reconstruction results (left: Songshan; right: Quad)

图 12 嵩山地区部分区域特征点与重投影点分布图(×表示特征点位置, +表示重投影点位置)
Fig. 12 Distribution of feature points and re-projection points in the Songshan areas (×: feature points, +: re-projection points)
表 1 合并前后重建结果对比
Table 1 Comparison of reconstruction results before and after merging
数据集 子场景序号 合并前 合并后 $N_R$ $A_{RE}$ $N_R$ $A_{RE}$ 大雁塔 1 296 0.416 1 045 0.455 2 323 0.463 3 268 0.451 4 253 0.437 Rome Forum 1 470 0.577 1 475 0.572 2 386 0.556 3 355 0.583 4 431 0.572 表中, $N_R$为重建影像数目; $A_{RE}$表示重投影误差, 单位(pixel).  下载: 导出CSV
下载: 导出CSV
表 2 1DSFM、HSFM与本文算法的不同数据集三维重建结果对比
Table 2 Comparison of 3D reconstruction result of different dataset using 1DSFM, HSFM and Ours
数据集 1DSFM HSFM Ours 名称 $N_D$ $N_R$ $T_{A}$ $A_{RE}$ $N_R$ $T_{A}$ $A_{RE}$ $N_R$ $T_{A}$ $A_{RE}$ 龙泉寺 443 406 25.386 0.841 417 19.661 0.717 413 16.815 0.711 Yorkminster 3 368 1 176 93.910 0.736 1 472 64.726 0.628 1 712 65.803 0.607 Piccadilly 7 351 6 445 476.781 1.194 6 791 269.561 0.865 6 979 231.794 0.822 Trafalgar 15 683 9 384 765.685 1.173 11 943 481.857 0.837 12 741 438.443 0.816 西安大雁塔 1 045 1 043 58.357 0.617 1 045 31.637 0.510 1 045 26.946 0.455 大连市区 4 900 4 900 327.625 1.397 4 900 231.394 1.478 4 900 197.872 1.353 某城市市区 15 750 NA NA NA 15 745 845.632 1.359 15 750 785.451 1.211 表中, $N_D$为数据集中的影像数目; $N_R$为重建影像数目; $T_{A}$表示重建时间, 单位(min); $A_{RE}$表示重投影误差, 单位(pixel).
下载: 导出CSV
表 3 嵩山地区部分误差结果
Table 3 Partial error result of the Songshan area
序号 $\Delta X$ $\Delta Y$ $\Delta Z$ RMS 1 0.2727 0.2337 0.2512 0.4383 2 0.1222 0.1053 0.1597 0.3370 3 0.1725 0.3045 0.3623 0.5037 4 0.2045 0.3643 0.5239 0.6703 5 0.1380 0.1419 0.4578 0.4987
下载: 导出CSV
表 4 Quad数据集部分误差结果
Table 4 Partial error result of Quad dataset
序号 $\Delta X$ $\Delta Y$ $\Delta Z$ RMS 1 0.2727 0.2337 0.2512 0.4383 2 0.1222 0.1053 0.1597 0.3370 3 0.1725 0.3045 0.3623 0.5037 4 0.2045 0.3643 0.5239 0.6703 5 0.1380 0.1419 0.4578 0.4987
下载: 导出CSV
-
[1] 王雪, Shi Jian-Bo, Park Hyun-Soo, 王庆.基于运动目标三维轨迹重建的视频序列同步算法.自动化学报, 2017, 43(10): 1759-1772 doi: 10.16383/j.aas.2017.c160584Wang Xue, Shi Jian-Bo, Park Hyun-Soo, Wang Qing. Synchronization of Video Sequences Through 3D Trajectory Reconstruction. Acta Automatica Sinica, 2017, 43(10): 1759-1772 doi: 10.16383/j.aas.2017.c160584 [2] Cui H, Gao X, Shen S. HSfM: hybrid structure-from-motion. In: Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition. IEEE, 2017. 2393-2402 [3] Wu C. Towards linear-time incremental structure from motion. In: Proceedings of In3D Vision-3DV 2013, 2013 International Conference. IEEE, 2013. 127-134 [4] Schonberger J L, Frahm J M. Structure-from-motion revisited. In: Proceedings of the IEEE Computer Vision and Pattern Recognition. IEEE, 2016. 4104-4113 [5] Toldo R, Gherardi R, Farenzena M, Fusiello A. Hierarchical structure-and-motion recovery from uncalibrated images. Computer Vision and Image Understanding, 2015, 140: 127-143 doi: 10.1016/j.cviu.2015.05.011 [6] 宋征玺, 张明环.基于分块聚类特征匹配的无人机航拍三维场景重建.西北工业大学学报, 2016, 34(4): 731-737 http://d.old.wanfangdata.com.cn/Periodical/xbgydxxb201604028Song Zheng-Xi, Zhang Ming-Huan. 3D Reconstruction on Unmanned Aerial Video by Using Patch Clustering Matching Method. Journal of Northwestern Polytechnical University, 2016, 34(4): 731-737 http://d.old.wanfangdata.com.cn/Periodical/xbgydxxb201604028 [7] Cefalu A, Haala N, Fritsch D. Hierarchical structure from motion combining global image orientation and structureless bundle adjustment. International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, 2017, 42: 535 [8] Agarwal S, Furukawa Y, Snavely N. Building Rome in a day. Communications of the ACM, 2011, 54(10): 105-112 doi: 10.1145/2001269.2001293 [9] Heinly J, Schonberger J L, Dunn E. Reconstructing the world in six days. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3287-3295 [10] 王伟, 高伟, 朱海, 胡占义.快速鲁棒的城市场景分段平面重建.自动化学报, 2017, 43(4): 674-684 doi: 10.16383/j.aas.2017.c160261Wang Wei, Gao Wei, Zhu Hai, Hu Zhan-Yi. Rapid and robust piecewise planar reconstruction of urban scenes. Acta Automatica Sinica, 2017, 43(4): 674-684 doi: 10.16383/j.aas.2017.c160261 [11] Özyeşil O, Voroninski V, Basri R, Singer A. A survey of structure from motion. Acta Numerica. 2017, 26: 305-64 doi: 10.1017/S096249291700006X [12] Simone B, Ciocca G, Marelli D. Evaluating the performance of structure from motion pipelines. Journal of Imaging, 2018, 4(8): 98 doi: 10.3390/jimaging4080098 [13] Cui H, Shen S, Gao W, Hu Z. Efficient large-scale structure from motion by fusing auxiliary imaging information. IEEE Transactions on Image Processing. 2015, 24(11): 3561-3573 doi: 10.1109/TIP.2015.2449557 [14] Zhu S, Shen T, Zhou L, Zhang R, Wang J, Fang T, Quan L. Accurate, scalable and parallel structure from motion[Ph. D. dissertation], Hong Kong University of Science and Technology, China, 2017 [15] Yang Y, Chang MC, Wen L, Tu P, Qi H, Lyu S. Efficient large-scale photometric reconstruction using Divide-Recon-Fuse 3D Structure from Motion. In: Proceedings of the 13th IEEE International Conference on Advanced Video and Signal Based Surveillance. IEEE, 2016. 180-186 [16] Wilson K, Snavely N. Robust global translations with 1dsfm. In: Proceedings of the 2014 European Conference on Computer Vision, Cham: Springer, 2014. 61-75 [17] Govindu V M. Lie-algebraic averaging for globally consistent motion estimation. In: Proceedings of the 2004 Computer Vision and Pattern Recognition, IEEE, 2004. 684-691 [18] Martinec D, Pajdla T. Robust rotation and translation estimation in multiview reconstruction. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2007. 1-8 [19] Jensen S H, Del Bue A, Doest M E, Aanæs H. A Benchmark and Evaluation of Non-Rigid Structure from Motion. arXiv preprint arXiv: 1801.08388, 2018. [20] Chatterjee A, Madhav Govindu V. Efficient and robust large-scale rotation averaging. In: Proceedings of the 2013 IEEE International Conference on Computer Vision, IEEE, 2013. 521-528 [21] Jiang N, Cui Z, Tan P. A global linear method for camera pose registration. In: Proceedings of the 2013 IEEE International Conference on Computer Vision, IEEE, 2013. 481-488 [22] 郭复胜, 高伟.基于辅助信息的无人机图像批处理三维重建方法.自动化学报, 2013, 39(6): 834-845 doi: 10.3724/SP.J.1004.2013.00834Guo Fu-Sheng, Gao Wei. Batch reconstruction from UAV images with prior information. Acta Automatica Sinica, 2013, 39(6): 834-845 doi: 10.3724/SP.J.1004.2013.00834 [23] Arie-Nachimson M, Kovalsky S Z, Kemelmacher-Shlizerman I, Singer A, Basri R. Global motion estimation from point matches. In: Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, IEEE, 2012. 81-88 [24] Crandall D, Owens A, Snavely N, Huttenlocher D. Discrete-continuous optimization for large-scale structure from motion. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2011. 3001-3008 [25] Cui Z. Global Structure-from-Motion and Its Application[Ph. D. dissertation], Applied Sciences: School of Computing Science, 2017 [26] Havlena M, Torii A, Pajdla T. Efficient structure from motion by graph optimization. In: Proceedings of the European Conference on Computer Vision, Berlin: Springer, 2010. 100-113 [27] Bhowmick B, Patra S, Chatterjee A, Govindu VM, Banerjee S. Divide and conquer: efficient large-scale structure from motion using graph partitioning. In: Proceedings of the Asian Conference on Computer Vision, Cham: Springer, 2014. 273-287 [28] Agudo A, Moreno-Noguer F. A scalable, efficient, and accurate solution to non-rigid structure from motion. Computer Vision and Image Understanding, 2018, 167: 121-133 doi: 10.1016/j.cviu.2018.01.002 [29] Dhillon I S, Guan Y, Kulis B. Weighted graph cuts without eigenvectors a multilevel approach. IEEE transactions on pattern analysis and machine intelligence, 2007, 29(11): 1-14 doi: 10.1109/TPAMI.2007.4302753 [30] Karami E, Prasad S, Shehata M. Image matching using SIFT, SURF, BRIEF and ORB: performance comparison for distorted images. arXiv preprint arXiv: 1710.02726, 2017. [31] Li X, Larson M, Hanjalic A. Pairwise geometric matching for large-scale object retrieval. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2015. 5153-5161 [32] Sweeney C, Sattler T, Hollerer T, Turk M, Pollefeys M. Optimizing the viewing graph for structure-from-motion. In: Proceedings of the 2015 IEEE International Conference on Computer Vision, IEEE, 2015. 801-809 [33] 韦盛斌, 王少卿, 周常河, 刘昆, 范鑫.用于三维重建的点云单应性迭代最近点配准算法.光学学报, 2015, 35(5): 244-250 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gxxb201505033Wei Sheng-Bin, Wang Shao-Qing, Zhou Chang-He, Liu Kun, Fan Xin. An iterative closest point algorithm based on biunique correspondence of point clouds for 3D reconstruction. Acta Optica Sinica, 2015, 35(5): 244-250 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gxxb201505033 [34] Agarwal S, Mierle K. Ceres Solver: Tutorial & Reference. Google Inc, 2012, 2:72. [35] Hartley R, Aftab K, Trumpf J. $L_1$ rotation averaging using the Weiszfeld algorithm. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2011. 3041-3048 [36] Zhang Q, Chin T J. Coresets for Triangulation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=8dc54afc7e357efa504f48233844295f [37] Shah R, Chari V, Narayanan PJ. A Unified View-Graph Selection Framework for Structure from Motion. arXiv preprint arXiv: 1708.01125, 2017. [38] National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences. datasets for 3D reconstruction[Online], available: http://vision.ia.ac.cn/data, January 3, 2018 期刊类型引用(18)
1. 李互刚,李刚,孙伟,王斌. 基于半监督特征融合算法的配电网施工场景非定标三维重建方法. 微型电脑应用. 2025(01): 180-182+192 .  百度学术
百度学术2. 曹学伟,袁杰,梁荣光. 基于特征点云配准的SLAM重建深度优化方法. 计算机工程与设计. 2025(03): 657-664 . 百度学术3. 任晓辰,邱春婷. 三维交互式场景虚拟现实建模仿真研究. 计算机仿真. 2024(01): 217-221 . 百度学术4. 高宇,朱立忠,刘韵婷,刘晓玉. 基于门控循环深度范围预测网络的多视角重建. 电子测量技术. 2024(01): 118-124 . 百度学术5. 陈豹,王品贺,董秋雷. 利用全局仿射模型进行卫星图像快速三维重建. 遥感学报. 2024(06): 1576-1587 . 百度学术6. 王雪茹,曹立佳. 面向倾斜摄影的实景模型融合技术与应用展望. 电子测量技术. 2024(10): 34-47 . 百度学术7. 刘韵婷,高宇,戴佳霖,谭明晓. 融合ECA注意力层和轻量正则化的多视图三维重建. 电子测量与仪器学报. 2024(07): 179-186 . 百度学术8. 王岩,张婷婷,王飞,刘振东. 一种基于深度图改进的分块密集匹配方法. 测绘通报. 2023(02): 78-83 . 百度学术9. 刘彪,顾邦军. 融合超像素分割技术的虚拟成像细节重建研究. 计算机仿真. 2023(04): 190-194 . 百度学术10. 耿国华,贺小伟,王美丽,袁庆曙,尹国军,许阳,潘志庚. 元宇宙下的智慧博物馆研究进展. 中国图象图形学报. 2023(06): 1567-1584 . 百度学术11. 李雷,徐浩,吴素萍. 基于DDPG的三维重建模糊概率点推理. 自动化学报. 2022(04): 1105-1118 . 本站查看12. 王震,盖孟,许恒硕. 基于虚拟现实技术的三维场景图像表面重建算法. 吉林大学学报(工学版). 2022(07): 1620-1625 . 百度学术13. 郁钱,路金晓,柏基权,范洪辉. 基于深度学习的三维物体重建方法研究综述. 江苏理工学院学报. 2022(04): 31-41 . 百度学术14. 马大勇,李安卓,王虎群,徐昕. VR技术下多感官人机交互三维重建仿真. 计算机仿真. 2022(10): 205-208+213 . 百度学术15. 康文慧. 虚拟数字艺术背景下动漫虚拟场景设计方法. 德州学院学报. 2022(06): 46-51 . 百度学术16. 张俊,田慧敏. 一种基于边指针搜索及区域划分的三角剖分算法. 自动化学报. 2021(01): 100-107 . 本站查看17. 张香玉,金晖. VR环境下基于特征并行匹配的多视图三维重建. 计算机仿真. 2021(05): 307-311 . 百度学术18. 王楠. 面向移动终端的交互式三维场景模拟重建研究. 现代电子技术. 2021(21): 160-164 . 百度学术其他类型引用(12)
-

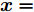
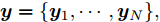
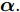
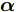
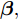
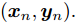
 下载:
下载:
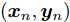
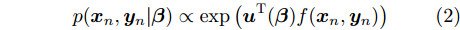
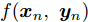
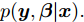
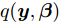
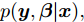
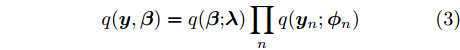
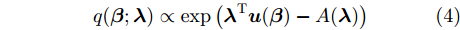
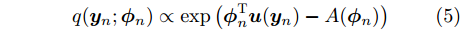
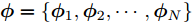
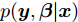
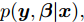
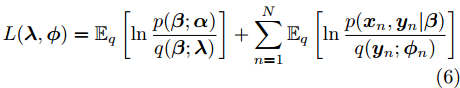
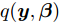
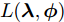
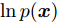
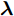
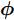
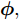
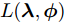
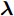
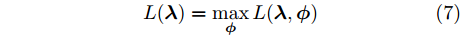
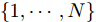
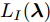
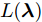
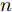
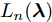
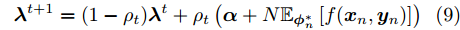


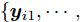
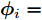
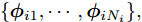
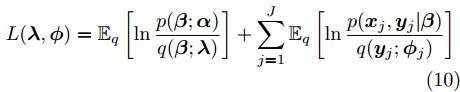

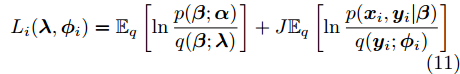
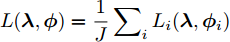

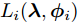
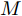
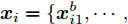
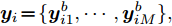
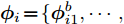
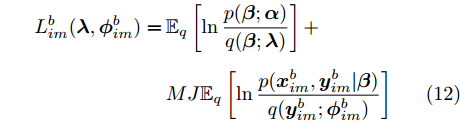
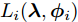
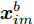
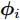

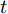
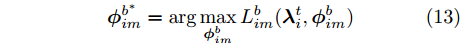
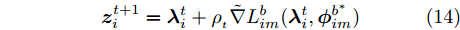
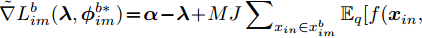
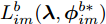
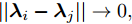
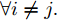
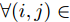
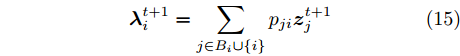
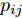
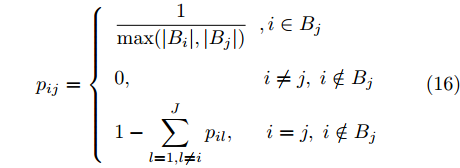
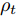
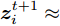
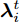
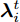
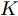
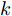
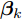
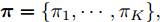
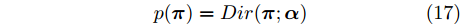
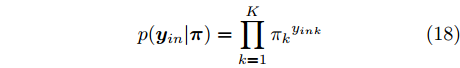
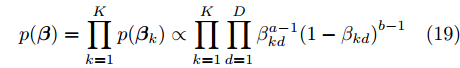
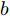

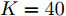
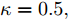
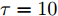
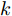
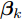
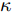

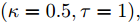
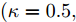
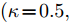

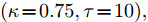
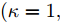
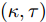
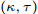
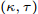
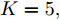
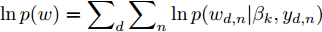
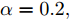
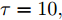
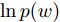
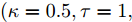



计量
- 文章访问数: 4191
- HTML全文浏览量: 1831
- PDF下载量: 296
- 被引次数: 30
