

-
摘要: 医疗数据共享、防篡改、防泄漏一直是困扰医疗行业的难题.一位患者在转诊时,往往无法提供以往的就诊信息,原因在于国内各医院医疗信息大多数情况下无法共享,而仅能通过病历、检验单等极易丢失的纸质信息来实现一部分医疗信息的共享.同时,患者的医疗信息极易造成泄露,在出现医疗纠纷时所提供的医疗信息也无法保证真实性与公正性.本文设计了一个基于实用拜占庭容错算法(Practical Byzantine fault tolerance,PBFT)的联盟式医疗区块链系统,该系统是一个多节点共同维护与共享的,并且能够防止医疗数据被篡改、泄露的医疗系统,可用来解决这些医疗难题.与现有医疗区块链系统相比,本系统具有一定的优越性与较好的适用性.Abstract: Medical data sharing, anti-tampering, and anti-leakage have always been difficult problems in medical industry. When a patient is on referral, he or she often can not provide information on previous visits. The reason is that many hospitals in China can not share medical information in most cases, and they can only pass the easily lost paper information such as medical records and checklists to achieve part of the medical information sharing. On the other hand, the patient's medical information is easy to leak, and medical information provided in a medical dispute can not be guaranteed in terms of authenticity and impartiality. In this research, an alliance medical blockchain system based on the practical Byzantine fault tolerance algorithm (PBFT) is designed, which is a multi-node maintenance and sharing system, and is able to prevent medical data from being tampered with or leaked. This medical system can be used to solve the above medical problems. Compared with the existing medical blockchain systems, this system has some advantages and good applicability.
-
Key words:
- Medical blockchain /
- medical data /
- consensus algorithm /
- medical information sharing
-
现代过程工业中存在着一类间歇过程[1], 如半导体加工、制药、注塑、发酵等.间歇过程通常具有重复特性, 且对跟踪精度要求较高, 是典型的非连续操作.其控制任务是在每个生产批次内跟踪给定的参考轨迹[2].迭代学习控制(Iterative learning control, ILC)能够利用过去批次的信息进行优化学习, 不断调整控制输入轨迹, 逐步提高跟踪性能, 实现对参考轨迹的高精度跟踪, 因此被广泛应用于间歇过程控制中[3].但是由于ILC是典型的开环控制, 因此不能保证控制系统的时域稳定性, 难以处理实时干扰.模型预测控制(Model predictive control, MPC)作为先进过程控制技术[4], 不仅广泛应用于工业过程的优化控制[5-6], 同时也成功应用于轨迹跟踪控制[7].它通过预测未来的系统状态及输出, 进行滚动时域优化, 能及时处理实时干扰, 保证时域跟踪性能及闭环系统稳定性, 弥补ILC的不足.迭代学习模型预测控制(Model predictive iterative learning control, MPILC)结合了MPC与ILC的优点, 因此成为控制间歇过程的有效方法.
早期的MPILC算法大多基于输入输出模型, 如受控自回归积分滑动平均(CARIMA)模型[8-9], 脉冲响应模型[10].而近年来基于状态空间模型的MPILC算法研究受到了更多关注, 研究对象包括线性定常状态空间模型[11]、带干扰项的状态空间模型[12]以及含不确定性的状态空间模型[13].其控制器设计通常需要进行状态增广以构造二维误差模型.为加强控制器鲁棒性, 很多学者在此基础上提出控制器结构改进算法, 如构造分段优化[14], 改善学习机制[15].
典型的间歇过程通常具有强非线性, 而现有的MPILC算法大都是针对线性系统构造的.文献[14$-$15]将原非线性系统在工作点简单线性化, 文献[10]沿参考轨迹进行线性化.由线性化带来的模型失配问题会在一定程度上影响时域跟踪性能以及迭代学习速度, 这在实际生产上将造成原料浪费以及经济效率下降.近年来许多学者在MPILC研究中通过各种建模手段来近似非线性系统, 包括T-S模糊建模[16]、神经网络建模[17]、数据驱动建模[18]等.但是这些方法需要大量过程数据的支持, 以及极其复杂的调参、学习过程才能建立较为精确的模型.
线性参变(Linear parameter varying, LPV)蕴含技术是处理复杂非线性的有效手段, 已被广泛应用于非线性模型预测中[19].原非线性系统在工作区间的动态特性可以包含在由LPV系统构成的多胞里.因此, 只要保证基于LPV模型的控制系统的稳定, 就能够保证非线性控制系统的稳定[20].由于LPV模型中存在的参数不确定性, 其控制求解一般通过线性矩阵不等式(Linear matrix inequality, LMI)约束下的目标函数优化来实现.
间歇过程的参考轨迹会由于不同的产品规格、生产效率以及外在干扰而发生改变.比如半导体制造中的蚀刻系统必须跟踪不同的操作轨迹来生产不同规格的晶片[21].而一旦参考轨迹发生变化, 经典迭代预测控制需要重新进行初始化, 并经历多个批次的学习来跟踪新轨迹[10], 适应能力较差.近年来许多学者提出改进的自适应ILC算法来解决变参考轨迹跟踪控制问题.文献[21]针对随机系统变轨迹跟踪问题, 提出两种自适应ILC策略, 一是在控制器设计中选择当前批次的输出轨迹与下一批次的参考轨迹的差值作为新的状态变量, 另一种是在每一个批次的末尾利用卡尔曼滤波器重新进行系统辨识; 文献[22]针对离散非线性系统, 设计模糊自适应ILC控制器, 通过不断更新模糊参数来近似变参考轨迹下的系统动态; 文献[23]设计基于数据驱动的自适应ILC控制器, 引入未来批次的参考轨迹作为反馈, 并将过去批次的参考轨迹作为前馈以实现对变参考轨迹的跟踪.这些基于ILC的控制策略通常要求已知所有采样时刻上的参考轨迹变化量, 并且由于算法内缺少预测环节导致了跟踪性能和学习效率的下降.针对该问题, 可将参考轨迹变化量视为迭代域中存在的有界扰动, 构造限制参考轨迹变化量对系统控制性能影响的$H_\infty$约束.这样只要在每个采样时刻的优化中满足此$H_\infty$约束, 就可有效抑制变参考轨迹带来的跟踪误差波动, 且只需已知下一采样时刻的参考轨迹变化量. $H_\infty$控制[24]可与MPILC算法有效结合, 利用预测控制的滚动时域优化提高时域跟踪性能, 从而加快学习速度.
本文提出一种基于LPV模型的鲁棒迭代学习模型预测控制(Robust model predictive iterative learning control, RMPILC)算法, 实现间歇过程对变参考轨迹的跟踪.采用LPV模型描述非线性系统动态特性, 并通过状态增广建立二维误差模型.为保证变参考轨迹下的跟踪性能, 引入$H_\infty$约束条件.将变轨迹跟踪问题转化为LMI约束下的凸优化问题.通过针对数值例子以及CSTR系统的仿真验证了所提出算法的有效性.
1. 模型推导
1.1 非线性系统的LPV蕴含
假设非线性间歇系统由下式表示:
$ \left\{ \begin{array}{l} x(t+1)=f(x(t), u(t))\\ y(t)=g(x(t)) \\ \end{array} \right. $
(1) 其中, $x\in {\bf R}^{n_x}$是状态变量, $u\in{\bf R}^{n_u}$是控制输入, $y\in{\bf R}^{n_y}$为输出变量. $t\in(0, N]$, $N$为批次长度.
假设对任意$x(t)$、$u(t)$ $(t\in{(0, N]})$存在矩阵
$ \aleph(t)\in\Omega(\Im) $
满足
$ \left[\begin{array}{c} x(t+1)\\ y(t) \end{array} \right]=\aleph(t) {\left[\begin{array}{c} x(t)\\ u(t) \end{array} \right]} $
其中, $\Omega(\Im)=co\{A(\theta), B(\theta), C(\theta), {\theta}\in{\Im}\}$为多胞集合, 其中$\theta$为某一有界过程参数, 且存在$l$个非负系数$\theta_q~(q=1, 2, \cdots, l)$满足
$ A(\theta)=\sum\limits_{q=1}^l{{\theta_q}{A_q}}, B(\theta)=\sum\limits_{q=1}^l{{\theta_q}{B_q}}\\ C(\theta)=\sum\limits_{q=1}^l{{\theta_q}{C_q}}, \sum\limits_{q=1}^l{\theta_q}=1\\ $
那么, 非线性系统(1)的动态特性可由LPV系统描述:
$ \begin{cases} x(t+1)=A(\theta)x(t)+B(\theta)u(t)\\ y(t)=C(\theta)x(t)\\ \end{cases} $
(2) 即任何关于LPV系统(2)的性质适用于非线性系统(1).
间歇过程的LPV建模问题已经得到了广泛关注[25].其中, 选择合适的参数至关重要.对于简单非线性系统, 可以通过直接计算非线性项的上下界确定.若被控系统的非线性比较复杂, 可以基于系统平衡点, 采用数学变换的方法获得合适的表达式[26].
1.2 增广迭代误差模型
建立相邻迭代次序之间的动态关系, 得到
$ \left\{ \begin{array}{l} \Delta{x_{k}(t+1)}=A(\theta)\Delta{x_{k}(t)}+B(\theta)\Delta{u_{k}(t)}\\ \Delta{y_{k}(t)}=C(\theta)\Delta{x_{k}(t)}\\ \end{array} \right. $
(3) 其中
$ \Delta{x_{k}(t)}=x_{k}(t)-x_{k-1}(t)\\ \Delta{u_{k}(t)}=u_{k}(t)-u_{k-1}(t)\\ \Delta{y_{k}(t)}=y_{k}(t)-y_{k-1}(t) $
定义输出参考轨迹为$y{_k^r}(t)$, 那么跟踪误差可以定义为
$ e_{k}(t)=y{_k^r}(t)-y_{k}(t) $
(4) 将式(4)代入式(3), 得到沿迭代轴的增广迭代误差状态空间模型:
$ \begin{cases} \overline{x}_{k}(t+1)=\overline{A}(\theta) \overline{x}_{k}(t)+\overline{B}(\theta)\Delta{u_{k}(t)} +\Upsilon_{k}(t+1)\\ \overline{y}_{k}(t)=\overline{C}\overline{x}_{k}(t) \end{cases} $
(5) 其中
$ \begin{align*} &\overline{y}_{k}(t)=\Delta{e_{k}(t)},\overline{x}_{k}(t)= \left[\begin{array}{c} \Delta{x_{k}(t)}\\ \Delta{e_{k}(t)} \end{array} \right]\in{\bf R}^{n_x+n_y} \\& \Delta{e_{k}(t)}=e_{k}(t)-e_{k-1}(t),\Delta{y{_k^r}(t)}= y{_k^r}(t)-y{_{k-1}^r}(t) \\& \overline{A}(\theta)=\left[\begin{array}{cc} A(\theta)&0\\ -C(\theta){A}(\theta)&0 \end{array} \right]\\ &\overline{B}(\theta)=\left[\begin{array}{c} B(\theta)\\ -C(\theta){B}(\theta) \end{array} \right] \\& \overline{C}=\left[\begin{array}{cc} 0&I_{n_y\times{n_y}} \end{array} \right],\Upsilon_{k}(t+1)=\left[\begin{array}{c} 0\\ \Delta{y{_k^r}(t+1)} \end{array} \right] \end{align*} $
这里, $\Delta{y{_k^r}}$项代表了参考轨迹变化量.
1.3 二维增广误差模型
由第1.2节可知, 系统(5)的输出$\overline{y}_{k}(t)$为相邻迭代次序跟踪误差的变化量$\Delta{e_{k}(t)}$.则在第$k$次迭代中, 为了将跟踪误差$e_{k}(t)$控制到0, $\overline{y}_{k}(t)$的参考轨迹应为$\overline{y}{_k^r}(t)=-e_{k-1}(t)$.定义:
$ \tilde{e}_{k}(t)=\overline{y}{_k^r}(t)-\overline{y}_k(t) $
(6) 联立式(5)和式(6), 得到同时包含迭代域和时域动态特性的二维增广误差模型
$ \tilde{x}_{k}(t+1)=\tilde{A}(\theta)\tilde{x}_{k}(t)+\tilde{B}(\theta)\delta\Delta{u}_{k}(t)+R_{k}(t+1) $
(7) 其中
$\begin{align*} &\tilde{A}(\theta)=\begin{bmatrix} I_{n_y\times{n_y}}&-\tilde{C}\overline{A}(\theta)\\ 0&\overline{A}(\theta) \end{bmatrix}\nonumber\\&\tilde{B}(\theta)=\begin{bmatrix} -\tilde{C}\overline{B}(\theta)\\ \overline{B}(\theta) \end{bmatrix} \\& \tilde{x}_{k}(t)=\begin{bmatrix} -\tilde{e}_{k}(t)\\ \delta\overline{x}_{k}(t) \end{bmatrix},\delta\Delta{u}_{k}(t)=\Delta{u}_{k}(t)-\Delta{u}_{k}(t-1) \\& \delta\overline{x}_{k}(t)=\overline{x}_{k}(t)-\overline{x}_{k}(t-1) \\& R_{k}(t+1)=\begin{bmatrix} \delta\overline{y}{_k^r}(t+1)-\delta\Delta{y}{_k^r}(t+1)\\ \Upsilon_{k}(t+1)-\Upsilon_{k}(t) \end{bmatrix} \\& \delta\overline{y}{_k^r}(t+1)=\overline{y}{_k^r}(t+1)-\overline{y}{_k^r}(t) \\& \delta\Delta{y}{_k^r}(t+1)=\Delta{y}{_k^r}(t+1)-\Delta{y}{_k^r}(t) \end{align*} $
且满足
注1. $R_{k}(t+1)$包含了参考轨迹变化量, 为已知有界时变量, 与状态变量、控制输入变量均无关, 可以看作迭代域上的有界外部干扰.
注2. 模型(7)与典型的二维Rosser模型[27]不同, 它将在同一个状态方程中建立时域与迭代域上动态关系, 其中$\tilde{x}_{k}(t)$、$\delta\Delta{u}_{k}(t)$以及$R_{k}(t+1)$都是同时包含时域及迭代域信息的二维变量.
因此, 系统(1)的轨迹跟踪问题可以转化为系统(7)的零点跟踪问题.其控制任务包括:
1) 将(7)中的状态$\tilde{x}_{k}(t)$控制到0;
2) 限制参考轨迹变化量$R_{k}(t+1)$对控制性能的影响;
3) 防止控制输入波动过大.
2. RMPILC算法
2.1 问题描述
根据控制任务1)和3), 结合鲁棒$H_\infty$控制, 定义控制性能指标$z_k(t)\in{\bf R}^{n_x+2n_y+n_u}$
$ z_k(t)=C_{\infty}\tilde{x}_{k}(t)+D_{\infty}\delta\Delta{u}_{k}(t) $
(8) 其中
${\small\begin{align*} &C_\infty=\\ &\left[ \begin{array}{ccc} m_1 & & \\ & \ddots & \\ & & m_{n_x+2n_y} \\ \textbf{0}_{n_u\times1} & \cdots & \textbf{0}_{n_u\times1} \\ \end{array} \right]\in {\bf R}^{(n_x+2n_y+n_u)\times{n_x+2n_y}} \\ &D_{\infty}=\\ &\left[ \begin{array}{ccc} \textbf{0}_{(n_x+2n_y)\times1} & \cdots & \textbf{0}_{(n_x+2n_y)\times1} \\ n_1 & & \\ & \ddots & \\ & & n_{n_u} \\ \end{array} \right]\in{\bf R}^{(n_x+2n_y+n_u)\times{n_u}} \end{align*}} $
$m_i~(i=1, 2, \cdots, n_x+2n_y), n_j~(j=1, 2, \cdots, n_u)$为可调权重系数.显然, $C_\infty^{\rm T}{D_\infty}=0$.目标函数可表述为$z_k(t)$的二次型:
$ J{_k^\infty}(t)=\sum\limits_{i=0}^\infty{z_k^{\rm T}(t+i|t){z_k(t+i|t)}} $
(9) 为实现控制任务2), 引入$H_\infty$范数$\|T_{zR}\|{_\infty^2}$ :
$ \|T_{zR}\|{_\infty^2}=\frac{\sum\limits_{i=0}^{\infty}{\|z_k(t+i|t)\|^2}}{\sum\limits_{i=0}^ \infty{\|R_k(t+i+1)\|^2}} $
(10) 设置$H_\infty$性能指标
$ \|T_{zR}\|{_\infty^2}\leq\varepsilon $
(11) 其中, $\varepsilon>0$为给定的$H_\infty$性能上界.不等式(11)表示参考轨迹变化量$R_k(t+1)$对跟踪性能指标$z_k(t)$的影响被限制在由$\varepsilon$定义的范围内.
因此, 满足以上三项控制任务的优化问题可以描述为:
$ \underset{\delta\Delta{u}_{k}(t)}{\min\max} {J{_k^\infty}(t)} $
(12) 满足式(8)和式(12).
2.2 鲁棒稳定状态反馈控制律
定义状态反馈控制律
$ \delta\Delta{u}_{k}(t+i|t)=F_k(t)\tilde{x}_{k}(t+i|t), i\geq 0 $
(13) 其中, $\delta\Delta{u}_{k}(t+i|t)$、$\tilde{x}_{k}(t+i|t)$为当前时刻$t$对未来时刻$t+i$的预测值.
为表达简洁, 推导过程的书写省略$\theta$.考虑二次型函数$V(\tilde{x})=\tilde{x}^{\rm T}P\tilde{x}$, 可得
$ \begin{align} & V(\tilde{x}_{k}(t+i+1|t))-V(\tilde{x}_{k}(t+i|t))=\nonumber\\&\qquad \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \end{bmatrix}^{\rm T}\times\nonumber\\&\qquad \begin{bmatrix} (\tilde{A}+\tilde{B}F_{k}(t))^{\rm T}P(\tilde{A}+ \tilde{B}F_{k}(t))-P & \ast \\ P(\tilde{A}+\tilde{B}F_{k}(t)) & P \end{bmatrix}\times\nonumber\\&\qquad \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \end{bmatrix} \end{align} $
(14) 将式(14)从$i=0$累加至$i=\infty$, 可得
$\begin{align} &V(\tilde{x}_{k}(\infty|t))\!-\!V(\tilde{x}_{k}(t|t))\!=\! \sum_{i=0}^\infty \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix}^{\rm T}\!\!\times \nonumber\\&\qquad \begin{bmatrix} (\tilde{A}+\tilde{B}F_{k}(t))^{\rm T}P (\tilde{A}+\tilde{B}F_{k}(t))-P & \ast \\ P(\tilde{A}+\tilde{B}F_{k}(t)) & P \\ \end{bmatrix}\times\nonumber\\&\qquad \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix} \end{align} $
(15) 根据控制任务1), $\tilde{x}_k(\infty|t)$应为0, 即$V(\tilde{x}_k(\infty|t)=0$, 则
$ \begin{align} &-V(\tilde{x}_{k}(t|t))=\sum_{i=0}^\infty \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix}^{\rm T}\times\nonumber\\&\qquad \begin{bmatrix} (\tilde{A}+\tilde{B}F_{k}(t))^{\rm T}P(\tilde{A}+\tilde{B}F_{k}(t))-P & \ast \\ P(\tilde{A}+\tilde{B}F_{k}(t)) & P \\ \end{bmatrix}\times\nonumber\\&\qquad \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix} \end{align} $
(16) 由于$C_\infty^{\rm T}{D_\infty}=0$, 因此将式(8)代入式(9)可得
$ \begin{align} J{_k^\infty}(t)=\,&\varepsilon\sum_{i=0}^\infty{R_k^{\rm T}(t+i+1)R_k(t+i+1)}+ \nonumber\\&\sum_{i=0}^\infty \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix}^{\rm T} \begin{bmatrix} C_\infty^{\rm T}C_\infty & \ast \\ 0 & -\varepsilon{I} \\ \end{bmatrix}\times\nonumber\\& \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix} \end{align} $
(17) 联立式(16)和(17), 目标函数(9)有以下形式
$ J{_k^\infty}(t)= V(\tilde{x}_{k}(t|t))+\\ \varepsilon\sum\limits_{i=0}^\infty{R_k^{\rm T}(t+i+1)R_k(t+i+1)}+\\\sum\limits_{i=0}^\infty \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix}^{\rm T}\Phi \begin{bmatrix} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{bmatrix} $
(18) 其中
$ \begin{align*} \Phi=\begin{subarray}{l}\begin{bmatrix} (\tilde{A}+\tilde{B}F_{k}(t))^{\rm T}P(\tilde{A}+\tilde{B}F_{k}(t)) -P+&\ast\\C_\infty^{\rm T}C_\infty+F_k^{\rm T}(t)D_\infty^{\rm T}D_\infty{F_k(t)} & \\ P(\tilde{A}+\tilde{B}F_{k}(t))& P-\varepsilon{I}\\ \end{bmatrix}\end{subarray} \end{align*} $
引理1. 当且仅当$\Phi<0$, 能够满足$H_\infty$性能指标(11).
证明. 在式(14)两端同时加上$z_k^{\rm T}(t+i|t)z_k(t+i|t)-\varepsilon{R_k^{\rm T}(t+i+1)R_k(t+i+1)}$, 可得
$V(\tilde{x}(t+i+1|t))-V(\tilde{x}(t+i|t))=\\ \qquad -\|z_k(t+i|t\|^2+\varepsilon\|R_k(t+i+1)\|^2 +\\ \qquad\left[ \begin{array}{c} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{array} \right]^{\rm T}\Phi\left[ \begin{array}{c} \tilde{x}_{k}(t+i|t) \\ R_{k}(t+i+1) \\ \end{array} \right] $
(19) 若$\Phi<0$, 则有
$V(\tilde{x}_{k}(t+i+1|t))-V(\tilde{x}_{k}(t+i|t))\leq\\ \qquad -\|z_k(t+i|t)\|^2+\varepsilon\|R_k(t+i+1)\|^2 $
(20) 由于$V(\tilde{x}_{k}(\infty|t)=0$, $V(\tilde{x}_{k}(0|0)=0$, 将式(21)从$i=0$到$i=\infty$进行累加, 可得
$ \sum\limits_{i=0}^\infty{\|z_k(t+i|t)\|^2}\leq\varepsilon\sum\limits_{i=0}^\infty{\|R_k(t+i+1)\|^2} $
(21) 式(22)与$H_\infty$约束(12)等价.
在$\Phi<0$的条件下, 可以得到目标函数$J{_k^\infty}(t)$的上界
$ J{_k^\infty}(t)\leq {V(\tilde{x}_{k}(t|t))}+\\ \varepsilon\sum\limits_{i=0}^\infty{R_k^{\rm T}(t+i+1)R_k(t+i+1)} $
(22) 根据式(7)中$R_k(t+1)$的定义可知, $\sum_{i=0}^\infty{R_k^{\rm T}(t+i+1)R_k(t+i+1)}$为有界值.设
$\sum\limits_{i=0}^\infty{R_k^{\rm T}(t+i+1)R_k(t+i+1)}\leq{B_{R_k(t)}^2} \\ V(\tilde{x}_{k}(t|t))\leq\gamma $
(23) 联立式(22)和(23), 得
$ J{_k^\infty}(t)\leq\gamma+\varepsilon{B_{R_k(t)}^2} $
(24) 也就是说$J{_k^\infty}(t)$有上界$\gamma+\varepsilon{B_{R_k(t)}^2}$, 其中只有$\gamma$为变量.因此, 优化问题(12)可以改写为以最小化$\gamma$为优化目标, 以$F_{k}(t)$为优化变量的典型凸优化问题:
$ \underset{F_{k}(t)}{\min\max}{\gamma} $
(25a) 满足
$ V(\tilde{x}_{k}(t|t))\leq\gamma $
(25b) $ \Phi<0 $
(25c) 引理2. 若优化问题(25)在当前时刻可行, 当满足不等式
$ \tilde{x}_{k}^{\rm T}(t|t)P\tilde{x}_{k}(t|t)+\varepsilon{B_{R_k(t)}^2}\leq\gamma $
(26) 时, 由RMPILC算法控制的闭环系统是鲁棒稳定的.
证明. 联立式(14)及条件(26), 可得
$\tilde{x}_{k}^{\rm T}(t+i+1|t)P\tilde{x}_{k}(t+i+1|t)-\\ \qquad \tilde{x}_{k}^{\rm T}(t+i+1|t)P\tilde{x}_{k}(t+i+1|t)\leq\\ \qquad \varepsilon{R_k^{\rm T}(t+i+1)R_k(t+i+1)} $
(27) 将式(28)从$i=0$到$i=p-1~(p\in[1, \infty))$进行累加, 可得
$ \begin{array}{l} \tilde x_k^{\rm{T}}(t + p|t)P{{\tilde x}_k}(t + p|t) \le \tilde x_k^{\rm{T}}(t|t)P{{\tilde x}_k}(t|t) + \\ \varepsilon \sum\limits_{i = 0}^{p - 1} {R_k^{\rm{T}}(t + i + 1){R_k}(t + i + 1)} \end{array} $
(28) 联立式(23)、(26)和(28), 可以推出
$ \tilde{x}_{k}^{\rm T}(t+p|t)P\tilde{x}_{k}(t+p|t)\leq\gamma $
(29) 因此, 对于任意未来时刻$t+p$, 其状态$\tilde{x_k}(t+p|t)$属于不变集$\Omega_{\tilde{x_k}}$:
$ \Omega_{\tilde{x_k}}=\{x|x^{\rm T}\gamma^{-1}Px\leq1\} $
(30) RMPILC控制下的闭环系统是鲁棒稳定的.
注3. 若参考输出保持不变, 即$R_k(t+1)=0$, 那么RMPILC控制下的闭环系统是Lyapunov意义下稳定的.
证明. 根据式(27), 若$R_k(t+1)=0$, 能推出
$ \tilde{x}_{k}^{\rm T}(t+1|t)P\tilde{x}_{k}(t+1|t)\leq\tilde{x}_{k}^{\rm T}(t)P\tilde{x}_{k}(t) $
选择$V_k(t)=\tilde{x}_{k}^{\rm T}(t)P\tilde{x}_{k}(t)$作为Lyapunov函数, 可得到$V_k(t)$随时间衰减.因此, 闭环系统是Lyapunov稳定的.
2.3 LMI求解
为获得满足在鲁棒稳定条件(26)下优化问题(25)的最优解, 将其转化为线性矩阵不等式的形式.
引理3. 满足约束(25b)、(25c)及鲁棒稳定条件(26)的状态反馈矩阵$F_k(t)$可通过$F_k(t)=YQ^{-1}$计算得到, 其中$Q=\gamma P^{-1}$, $Y$为下述LMI约束下优化问题的解:
$ \underset{Y, Q}{\min}{\gamma} $
(31a) 对所有$q=1, 2, \cdots, l$, 满足
$ \left[ \begin{array}{ccccc} -Q & \ast & \ast & \ast & \ast \\ 0 & -\varepsilon\gamma I & \ast & \ast & \ast \\ \tilde{A}_qQ+\tilde{B}_qY & \gamma I & -Q & \ast & \ast \\ C_\infty Q & 0 & 0 & -\gamma I & \ast \\ D_\infty Y & 0 & 0 & 0 & -\gamma I \\ \end{array} \right] $
(31b) $ \left[ \begin{array}{ccc} 1 & \ast & \ast \\ \varepsilon{B_{R_k(t)}^2}& \gamma\varepsilon{B_{R_k(t)}^2} & \ast \\ \tilde{x}_{k}(t) & 0 & Q \\ \end{array} \right] $
(31c) 证明. 采用Schur补定理[28], 式(25c)等价于
$ \left[ \begin{array}{ccccc} -P & \ast & \ast & \ast & \ast \\ 0 & -\varepsilon I & \ast & \ast & \ast \\ \tilde{A}_qQ+\tilde{B}_qF_k(t) & I & -P^{-1} & \ast & \ast \\ C_\infty & 0 & 0 & -I & \ast \\ D_\infty & 0 & 0 & 0 & -I \\ \end{array} \right] $
(32) 分别左乘右乘diag$\{P^{-1}, I, I, I, I\}$, 得
$ \left[ \begin{array}{ccccc} -P^{-1} & \ast & \ast & \ast & \ast \\ 0 & -\varepsilon I & \ast & \ast & \ast \\ (\tilde{A}_qQ+\tilde{B}_qF_k(t))P^{-1} & I & -P^{-1} & \ast & \ast \\ C_\infty P^{-1} & 0 & 0 & -I & \ast \\ D_\infty P^{-1} & 0 & 0 & 0 & -I \\ \end{array} \right] $
(33) 将$P=\gamma Q^{-1}$, $F_k(t)=YQ^{-1}$代入式(33), 式(31b)可以被推出.
注意式(26)为式(25b)的充分条件, 也就是说只需要要满足式(26), 式(25b)也能被满足.将$P=\gamma Q^{-1}$代入式(27), 利用Schur补定理, 即可得到矩阵不等式(31c).
根据优化得到的$F_k(t)$, 通过下式计算控制输入$u_k(t)$:
$ u_k(t)= \delta\Delta{u_k(t)}+\Delta{u_k(t-1)}+u_{k-1}(t)=\\ F_k(t)\tilde{x}_{k}(t|t)+\Delta{u_k(t-1)}+u_{k-1}(t)=\\ YQ^{-1}\tilde{x}_{k}(t|t)+\Delta{u_k(t-1)}+u_{k-1}(t) $
(34) 其中, $\Delta{u_k(t-1)}$、$u_{k-1}(t)$为当前批次当前时刻的已知量. $\tilde{x}_{k}(t|t)$等于当前状态$\tilde{x}_{k}(t)$.
2.4 控制输入约束
间歇过程中需要考虑的控制输入约束包括$u_k(t)$、$\Delta{u_k(t)}$和$\delta{u_k(t)}$, 通常表述为
$ \left\{ \begin{array}{l} \|u_k(t)\|^2\leq u_h^2\\ \|\Delta u_k(t)\|^2\leq \Delta u_h^2\\ \|\delta u_k(t)\|^2\leq \delta u_h^2 \end{array} \right. $
(35) 推导$u_k(t)$, $\Delta{u_k(t)}$, $\delta{u_k(t)}$与$\delta\Delta{u_k(t)}$的关系
$ \left\{ \begin{array}{l} u_k(t)=\delta\Delta{u_k(t)}+\Delta{u_k(t-1)}+u_{k-1}(t)\\ \Delta u_k(t)=\delta\Delta{u_k(t)}+\Delta{u_k(t-1)}\\ \delta u_k(t)=\delta\Delta{u_k(t)}+\delta{u_{k-1}(t)} \end{array} \right. $
(36) 从式(36)可以看出, $u_k(t)$, $\Delta{u_k(t)}$, $\delta{u_k(t)}$都可以表示成$\delta\Delta{u_k(t)}$与其他已知量的和的形式.将其表述为以下通式
$ u_c=H\delta\Delta{u_k(t)}+u_m $
(37) 其中, $u_c$是被约束量, $u_m$是已知量, $H$是用于选择$\delta\Delta{u_k(t)}$中某一控制输入的向量.
式(35)中的约束条件可以统一表述为
$ \|u_c\|^2\leq\mu^2 $
(38) 其中, $\mu$代表约束上界.
结合式(37), 对不等式(38)进行放缩
$ \begin{align} & \|{{u}_{c}}{{\|}^{2}}=\|H\delta \Delta {{u}_{k}}(t)+{{u}_{m}}{{\|}^{2}}= \\ & \|H\delta \Delta {{u}_{k}}(t){{\|}^{2}}+2{{u}_{m}}H\delta \Delta {{u}_{k}}(t)+ \\ & u_{m}^{2}\le \|HY{{Q}^{-\frac{1}{2}}}{{Q}^{-\frac{1}{2}}}{{{\tilde{x}}}_{k}}(t|t){{\|}^{2}}+ \\ & 2{{u}_{m}}Y{{Q}^{-1}}{{{\tilde{x}}}_{k}}(t|t)+u_{m}^{2}\le \\ & \|HY{{Q}^{-\frac{1}{2}}}{{\|}^{2}}+2{{u}_{m}}Y{{Q}^{-1}}{{{\tilde{x}}}_{k}}(t|t)+u_{m}^{2}= \\ & \|HY{{Q}^{-\frac{1}{2}}}+{{u}_{m}}{{{\tilde{x}}}_{k}}{{(t|t)}^{\text{T}}}{{Q}^{-\frac{1}{2}}}{{\|}^{2}}+u_{m}^{2}- \\ & \|{{u}_{m}}{{Q}^{-\frac{1}{2}}}{{{\tilde{x}}}_{k}}(t|t){{\|}^{2}}= \\ & \|HY{{Q}^{-\frac{1}{2}}}+{{u}_{m}}{{{\tilde{x}}}_{k}}{{(t|t)}^{\text{T}}}{{Q}^{-\frac{1}{2}}}{{\|}^{2}}+ \\ & u_{m}^{2}(1-\beta )\le {{\mu }^{2}} \\ \end{align} $
(39) 其中, $0\leq\beta=\tilde{x}_{k}^{\rm T}(t|t)Q^{-1}\tilde{x}_{k}(t|t)$.由式(29)可知, $\tilde{x}_{k}^{\rm T}(t|t)Q^{-1}\tilde{x}_{k}(t|t)\leq1$.因此$\beta\in[0\;\;\;1]$.则式(39)可以写成以下线性矩阵不等式形式:
$ \begin{equation} \left[ \begin{array}{cc} \mu^2-u_m^2(1-\beta) & \ast \\ Y^{\rm T}H^{\rm T}+u_m\tilde{x}_{k}(t|t) & Q \\ \end{array} \right] \end{equation} $
(40) 因此控制输入约束下的鲁棒迭代预测控制优化问题可以描述为:
$ \underset{Y, Q}{\min}{\gamma} $
(41) 满足式(31b), 式(31c), 式(40).
3. 收敛性分析
MPILC控制系统的收敛性指的是当迭代次数趋近于无穷时, 跟踪误差收敛到零, 即对于任意$t\in[0, N]$, 当$k\rightarrow\infty$时, $e_k(t)\rightarrow0$.文献[29]在$x_{k-1}(N)=x_{k}(0)$的前提下, 证明了经典MPILC算法的收敛性.而近年研究中, 设计附加条件使$\|e_{k+1}(t)\|\leq a\|e_{k}(t)\|~(0<a<1)$成为保证收敛性更为常用的方法[9, 11].在本文提出的RMPILC算法中, 基于包含参考轨迹变化量的LPV模型(7), $\|e_{k+1}(t)\|\leq a\|e_{k}(t)\|$可以转化为有关增广状态$\tilde{x}_{k}(t)=[\tilde{e}_{k}(t)^{\rm T}\delta\overline{x}_k(t)^{\rm T}]^{\rm T}$的约束, 将其加入到实时优化中, 就可以保证原非线性系统在RMPILC控制下沿迭代轴的收敛性.
首先, 提出以下符合实际过程情况的假设:
1) 优化问题(31)在初始时刻可行;
2) 对于$t\in[0, N-1]$, 存在满足约束式(31b), 式(31c), 式(40)的控制序列$u_k(t)$令跟踪误差$e_k(t+1)$等于0;
3) 在$t$时刻, 已知$t+1$时刻的参考轨迹变化量.
定理1. 若在每个采样时刻的优化中, 对于$q=1, 2, \cdots, l$, $j=1, 2, \cdots, n_y$满足LMI约束
$ \left[ \begin{align} & {{a}^{2}}e_{k-1}^{j}{{(t+1)}^{2}}-(1+R_{k}^{\text{T}}(t+1)\times \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ * \\ & {{R}_{k}}(t+1)){{L}_{j}}L_{j}^{\text{T}} \\ & Q{{{\tilde{A}}}_{q}}L_{j}^{\text{T}}+{{Y}^{\text{T}}}\tilde{B}_{q}^{\text{T}}L_{j}^{\text{T}}\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{Q}{1+R_{k}^{\text{T}}(t+1){{R}_{k}}(t+1)} \\ \end{align} \right] $
(42) 那么RMPILC控制下的跟踪误差沿迭代轴收敛到零.其中$e{_{k-1}^j}(t)$表示向量$e_{k-1}(t)$的第$j$个元素, $L_j$是用于选择向量$\tilde{e}_k(t)$第$j$个元素的给定向量.
证明. 在当前时刻$t$, 为保证下一时刻的跟踪误差沿迭代轴收敛, 即$\|e_{k+1}(t)\|\leq a\|e_{k}(t)\|$, 应满足以下不等式条件:
$ |e{_{k}^j}(t+1)|<a|e{_{k-1}^j}(t+1)| $
(43) 其中, $j=1, 2, \cdots, n_y$.
根据式(5)有
$ e{_{k}^j}(t)=e{_{k-1}^j}(t)+\Delta{e_k(t)} $
(44) 联立式(5)和(6)得
$ \Delta{e{_{k}^j}(t+1)}=-e{_{k}^j}(t+1)-\tilde{e}{_{k}^j}(t+1) $
(45) 联立式(43)、(44)和(45)可以得到
$ |\tilde{e}{_{k}^j}(t+1)|<a|e{_{k-1}^j}(t+1)| $
(46) 为不等式(43)的充分条件. (46)可以转化为系统(7)的状态约束:
$ \tilde{x}_k^{\rm T}(t+1)L_j^{\rm T}L_j\tilde{x}_k(t+1)<a^2e{_{k}^j}(t+1)^2 v $
(47) 为了得到式(47)的LMI表述, 进行以下推导[30]:
$\begin{align} &\tilde{x}_k^{\rm T}(t+1)L_j^{\rm T}L_j \tilde{x}_k(t+1) < a^2e{_{k-1}^j}(t+1)^2=\nonumber\\ &\qquad((\tilde{A}+\tilde{B}F_{k}(t)) \tilde{x}_k(t)+R_k(t+1))^{\rm T}L_j^{\rm T}L_j\times\nonumber\\ &\qquad((\tilde{A}+\tilde{B}F_{k}(t)) \tilde{x}_k(t)+R_k(t+1))=\nonumber\\ &\qquad\left[ \begin{array}{c} Q^{-\frac{1}{2}}\tilde{x}_k(t) \\ R_k(t+1)\\ \end{array} \right]^{\rm T} \left[ \begin{array}{c} Q^{\frac{1}{2}}(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]L_j^{\rm T}L_j\times\nonumber\\&\qquad \left[ \begin{array}{c} Q^{\frac{1}{2}}(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]^{\rm T}\left[ \begin{array}{c} Q^{-\frac{1}{2}}\tilde{x}_k(t) \\ R_k(t+1)\\ \end{array} \right] < \nonumber\\ &\qquad(1+R_k(t+1))^{\rm T}R_k(t+1)))\times\nonumber\\ &\qquad\lambda_{\max}\Bigg(L_j\left[ \begin{array}{c} Q(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]^{\rm T}\left[ \begin{array}{cc} Q^{-1} & 0 \\ 0 & I \\ \end{array} \right]\nonumber\\ &\qquad\left[ \begin{array}{c} Q(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]L_j^{\rm T}\Bigg) \end{align} $
(48) 联立式(47)和式(48)可得
$\begin{align} &a^2e{_{k-1}^j}(t+1)^2-\left(1+R_k^{\rm T}(t+1)R_k(t+1)\right) \times\nonumber\\& \qquad\Bigg(L_j\left[ \begin{array}{c} Q(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]^{\rm T}\left[ \begin{array}{cc} Q^{-1} & 0 \\ 0 & I \\ \end{array} \right]\times\nonumber\\&\qquad\left[ \begin{array}{c} Q(\tilde{A}+\tilde{B}F_{k}(t))^{\rm T} \\ I \\ \end{array} \right]L_j^{\rm T}\Bigg)>0 \end{align} $
(49) 根据Schur补定理, 式(49)等价于式(42).因此, 如果在每次优化中满足LMI (42), 那么有$|e{_{k}^j}(t+1)|<a|e{_{k-1}^j}(t+1)|$, 即$\|e_{k+1}(t)\|\leq a\|e_{k}(t)\|$.所以, 对于任意$t\in[0, N]$, 当$k\rightarrow\infty$时, $e_k(t)\rightarrow0$.
4. 仿真研究
本节设计两组仿真实验以验证所提出的RMPILC在处理变轨迹跟踪问题方面的有效性.仿真1针对非线性数值系统, 侧重于对算法的理论分析和验证; 仿真2针对典型的间歇CSTR系统, 侧重于对RMPILC的实际应用效果检验.为进行对比, 同时设计经典MPILC算法的仿真实验, 其预测模型为:
$ {\pmb e}_k(t+m|t)={\pmb e}_k(t|t)-{G}^m(t)\Delta{\pmb u}{_k^m}(t) $
(50) 其中, $m$代表预测时域和控制时域大小, ${\pmb e}_k\in {\bf R}^{(n_y\times N)\times1}$,
$ \Delta{\pmb u}{_k^m}(t)=\left[ \begin{array}{ccc} \Delta u_k^{\rm T}(t) & \cdots & \Delta u_k^{\rm T}(t+m-1) \\ \end{array} \right]^{\rm T} $
$ {G}=\left[ \begin{array}{cccc} g_{1,0} & 0 & \cdots & 0 \\ g_{2,0} & g_{2,1} & \cdots & 0 \\ \vdots & \vdots & \ddots & 0 \\ \underbrace{g_{N,0}}_{G(0)} & \underbrace{\cdots}_{G(1)} & \cdots & \underbrace{g_{N,N-1}}_{G(N-1)} \\ \end{array} \right] $
$ {G}^m(t)=\left[ \begin{array}{ccc} G(t) & \cdots & G(t+m-1) \\ \end{array} \right] $
$g_{i, j}\in {\bf R}^{n_y(i)\times n_u(j)}$为$j$时刻施加的单位脉冲信号输入在$i$时刻的脉冲响应矩阵.通常矩阵${G}$可以通过沿参考轨迹进行线性化得到.经典MPILC算法的目标函数为:
$ J{_{\rm MPILC}^k}(t)=\frac{1}{2}\left\{\|{\pmb e}_k(t+m|t)\|_{Q_1}+\|\Delta{\pmb u}{_k^m}\|_{R_1}\right\} $
(51) 其中, $Q_1$和$R_1$为权重系数矩阵.
4.1 仿真1
考虑如下非线性数值系统
$ \begin{equation} \left\{ \begin{array}{l} x(t+1)=\left[ \begin{array}{cc} 0.5 & 0.125 \\ 0.125 & -0.65+0.15\sin{x_1} \\ \end{array} \right]\cdot\\ \qquad\qquad x(t)+\left[ \begin{array}{c} 0.01 \\ 0.07 \\ \end{array} \right] \\ y(t)=\left[ \begin{array}{cc} 1 & 0 \\ \end{array} \right] x(t) \\ \end{array} \right. \end{equation} $
(52) 控制输入约束为
$ \|u_k(t)\|^2\leq8^2, \|\Delta u_k(t)\|^2\leq0.6^2, \|\delta u_k(t)\|^2\leq1^2 $
(53) 由于$-1\leq\sin{x_1}\leq1$恒成立, 选择$\theta_1=\frac{\sin{x_1}-(-1)}{1-(-1)}$, $\theta_1=\frac{1-\sin{x_1}}{1-(-1)}$, 非线性系统(52)就可以被如式(2)的LPV模型包含, 其中$l=2$,
$ A_1=\left[ \begin{array}{cc} 0.5 & 0.125 \\ 0.125 & -0.5 \\ \end{array} \right],\quad A_2=\left[ \begin{array}{cc} 0.5 & 0.125 \\ 0.125 & -0.8 \\ \end{array} \right] $
根据式(7), 可以得到
$\begin{align*} &\tilde{A}_1=\left[ \begin{array}{cccc} 1 & 0.5 & 0.125 & 0 \\ 0 & 0.5 & 0.125 & 0 \\ 0 & -0.125 & -0.5 & 0 \\ 0 & -0.5 & -0.125 & 0 \\ \end{array} \right]\\&\tilde{A}_2=\left[ \begin{array}{cccc} 1 & 0.5 & 0.125 & 0 \\ 0 & 0.5 & 0.125 & 0 \\ 0 & -0.125 & -0.8 & 0 \\ 0 & -0.5 & -0.125 & 0 \\ \end{array} \right] \end{align*} $
仿真设置两种参考轨迹如图 1所示.第1批次到第4批次的目标参考轨迹为$y_{r_1}$; 从第5批次开始, 目标参考轨迹变为$y_{r_2}$.仿真时间为10分钟, 采样时间为0.025分钟.
批次长度为400.第1批次的控制输入为零向量. $H_\infty$性能上界$\varepsilon$设为10.初始状态为$x(0)=[0, 0]^{\rm T}$.收敛条件(42)作为每次优化的约束, 保证跟踪误差的收敛性, 其中$a=0.9$.权重矩阵取为
$\begin{align*} &C_\infty=\left[ \begin{array}{c} {\rm diag}\{1,0,0,0\} \\ \textbf{0}_{1\times4} \\ \end{array} \right]\\&D_\infty=\left[ \begin{array}{cccc} 0 & 0 & 0 & 0.0002 \\ \end{array} \right]^{\rm T} \end{align*} $
在每个采样时刻, 通过求解约束(42)下的LMI优化问题(41)得到变量$Y$, $Q$, 继而通过式$F_k(t)=YQ^{-1}$计算当前时刻的状态反馈矩阵$F_k(t)$.仿真分析中选择参考轨迹转折点第61个采样时刻来比较变轨迹前后的状态反馈矩阵变化, 其结果如表 1所示. 图 2和3为RMPILC的跟踪曲线及对应的控制输入曲线.
表 1 $F_k(t)$优化值Table 1 Optimized feedback control law批次($k$) $F_k(61)$ 2 [$-$46.7539 $-$24.0899 $-$5.0529 0.0000] 3 [$-$42.9654 $-$25.0475 $-$3.7597 0.0000] 4 [$-$57.4573 $-$29.2520 $-$5.4621 $-$0.0000] 5 [$-$16.9782 $-$7.8604 $-$1.2311 $-$0.0000] 6 [$-$37.0429 $-$26.9746 $-$3.0976 0.0000] 7 [$-$41.3123 $-$27.2625 $-$2.9534 $-$0.0000] 8 [$-$54.1913 $-$32.1226 $-$4.9777 0.0000] 在经典MPILC仿真中, 设置$Q_1=I_{400\times400}$, $R_1=0.00015I_{20\times20}$, $m=20$.其跟踪曲线如图 4所示.
比较图 2和图 4, 在参考轨迹保持不变的第1 $\sim$第4批次, RMPILC从第2批次就能够精确跟踪$y_{r_1}$, 而MPILC直到第4批次才能较好地跟踪${y_{r_1}}$.这是因为RMPILC采用了LPV模型来描述原系统的非线性特性, 避免出现模型失配问题, 从而获得了更快的收敛速度; 在参考轨迹变为$y_{r_2}$的第5 $\sim$第8批次, RMPILC能快速跟踪$y_{r_2}$, 而MPILC难以及时适应变参考轨迹, 需要经过几次迭代才能达到较好的跟踪效果.因而, RMPILC采用$H_\infty$控制有效抑制了变参考轨迹的影响.
图 5为RMPILC和经典MPILC控制下各批次跟踪误差均方差(Main square error, MSE)的变化情况. RMPILC控制下MSE沿迭代轴收敛到零, 且在参考轨迹变化的第5批次, 没有明显波动, 保持收敛趋势, 而MPILC控制下MSE出现较大波动.这证明了RMPILC在变参考轨迹下能够保证跟踪误差沿迭代轴收敛.
RMPILC的控制性能与参考轨迹变化程度以及$H_\infty$性能上界$\varepsilon$的大小有较大关系.由式(11)可知, $\varepsilon$越小越有利于增强抗干扰能力.而式(26)表明$\varepsilon$减小将导致可行域的缩小.当可行域缩小到不能包含当前状态时, 优化问题将无解.因此, 在选择$\varepsilon$时, 要根据实际需要权衡变轨迹适应能力和可行性问题.对于系统(52)能够保证可行性的最小$\varepsilon$值为5.8. 图 6为参考轨迹发生变化的第5批次中, RMPILC在$\varepsilon=5.8$、$\varepsilon=10$和$\varepsilon=15$时的跟踪情况, 表明随着$\varepsilon$增大, RMPILC跟踪性能下降. 图 7为$x(0)=[0.01, 0.05]^{\rm T}$, $\varepsilon$分别取值5.8、10和15时不变集$\Omega_{\tilde{x}_k}=\{x|x^{\rm T}Q^{-1}x\leq1\}$在原状态空间的象集.由于不变集的大小能够反映可行域的大小, 因此图 7表明初始可行域随$\varepsilon$减小而缩小.
 图 6 RMPILC控制下第5批次当$\varepsilon=5.8$、$\varepsilon=10$和$\varepsilon=15$时的跟踪曲线Fig. 6 The tracking trajectories in the fifth batch when $\varepsilon=5.8, 10, 15$
图 6 RMPILC控制下第5批次当$\varepsilon=5.8$、$\varepsilon=10$和$\varepsilon=15$时的跟踪曲线Fig. 6 The tracking trajectories in the fifth batch when $\varepsilon=5.8, 10, 15$ 图 7 RMPILC控制下$\varepsilon=5.8$、$\varepsilon=10$和$\varepsilon=15$时的不变集$\Omega_{\tilde{x}_k}$在原状态空间的象集Fig. 7 The image set of $\Omega_{\tilde{x}_k}$ when $\varepsilon=5.8, 10, 15$
图 7 RMPILC控制下$\varepsilon=5.8$、$\varepsilon=10$和$\varepsilon=15$时的不变集$\Omega_{\tilde{x}_k}$在原状态空间的象集Fig. 7 The image set of $\Omega_{\tilde{x}_k}$ when $\varepsilon=5.8, 10, 15$4.2 仿真2: CSTR系统
连续搅拌反应釜系统中进行恒定体积、放热、不可逆化学反应$A\rightarrow B$.其控制任务为重复跟踪给定的反应温度轨迹, 且生成物$B$的产品质量很大程度依赖于跟踪精度.因此, 采用MPILC方法控制CSTR系统能适应其生产过程的重复性, 并且提高产品质量.
CSTR系统具有以下非线性微分方程描述[31]:
$ \left\{ \begin{array}{l} \dot{C}_A=\frac{q}{V}(C_{Af}-C_A)-k_0\exp\left(\frac{-E} {RT}\right)C_A\\ \dot{T}=\frac{q}{V}(T_f-T)+\frac{-\Delta H}{\rho C_p}k_0\exp\left(\frac{-E}{RT}\right)C_A+ \\ \qquad\frac{UA}{V\rho C_p}(T_c-T) \end{array} \right. $
(54) 其中, 反应温度$T$ (K)为被控量, 冷却剂温度$T_c$ (K)为控制输入.其他参数的物理意义和取值见文献[31].
在间歇反应器控制中, 反应温度$T$的参考轨迹可能会由于调整进料浓度$C_A$、启动速度、批次时间长度等发生变化.为了验证RMPILC在适应频繁变化的参考轨迹的能力, 在仿真中设置三种不同的参考轨迹, 如图 8所示, 包括常规轨迹$y_{r_1}$、慢启动轨迹$y_{r_2}$以及快启动轨迹$y_{r_3}$. $y_{r_3}$中$T$上升较快, 有利于提高产量; $y_{r_2}$中$T$上升较慢, 后续反应更加平稳, 易于控制.在实际生产中可以根据不同的生产需求选择不同的参考轨迹.
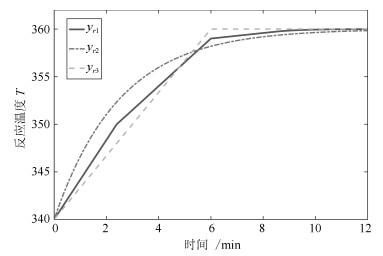 图 8 CSTR反应温度$T$参考轨迹Fig. 8 The reference trajectories of CSTR reaction temperature $T$
图 8 CSTR反应温度$T$参考轨迹Fig. 8 The reference trajectories of CSTR reaction temperature $T$根据文献[32]介绍的替换法, 非线性系统(54)可以表述为如式(2)的LPV模型, 过程如下:
首先, 计算系统(54)的平衡点:
$ \{C{_A^{eq}}, T^{eq}, T{_c^{eq}}\}=\{0.5 {\rm mol} , 350 {\rm K}, 338 {\rm K}\} $
定义状态变量$[x_1, x_2]^{\rm T}=[C_A-C{_A^{eq}}, T-T^{eq}]$, 输入变量$u=T_c-T{_c^{eq}}$, 输出变量$y=x_2$.系统(54)能写成以下的状态方程形式:
$ \left\{ \begin{array}{l} \dot{x}=\left[ \begin{array}{c} \frac{q}{V}(C_{Af}-x_1-C{_A^{eq}})- \\k_0\exp\left(\frac{-E}{R(x_2+T^{eq})}\right) (x_1+C{_A^{eq}}) \\ \frac{q}{V}(T_f-x_2-T^{eq})+ \frac{-\Delta H}{\rho C_P}\times\\k_0\exp\left(\frac{-E} {R(x_2+T^{eq})}\right)\times\\ (x_1+C{_A^{eq}})+ \frac{UA}{V\rho C_p}(T_c-x_2-T^{eq}) \\ \end{array} \right] \\ y=x_2 \end{array} \right. $
(55) 在给定的输出参考轨迹中, 反应温度满足$\underline{T}\leq T\leq\overline{T}$, 也就是$\underline{T}-T^{eq}\leq x_2<\overline{T}-T^{eq}$.设
$ \underline{x}=\underline{T}-T^{eq}, \overline{x}=\overline{T}-T^{eq} $
定义
$ \begin{align} & {{\varphi }_{1}}({{x}_{2}})={{k}_{0}}\exp \left( \frac{-E}{R({{x}_{2}}+{{T}^{eq}})} \right) \\ & {{\varphi }_{2}}({{x}_{2}})={{k}_{0}}(\exp \left( \frac{-E}{R({{x}_{2}}+{{T}^{eq}})} \right)- \\ & \exp \left( \frac{-E}{R{{T}^{eq}}} \right))C_{A}^{eq}\frac{1}{{{x}_{2}}} \\ & {{\nu }_{1}}({{x}_{2}})={{\varphi }_{1}}({{x}_{2}})-\frac{1}{2}({{\varphi }_{1}}({{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{x}}}_{2}})+{{\varphi }_{1}}({{{\bar{x}}}_{2}})) \\ & {{\nu }_{2}}({{x}_{2}})={{\varphi }_{2}}({{x}_{2}})-\frac{1}{2}({{\varphi }_{1}}({{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{x}}}_{2}})+{{\varphi }_{1}}({{{\bar{x}}}_{2}})) \\ \end{align} $
选择LPV模型(2)中的参数$\theta$为
$ \theta_1=\frac{1}{2}\frac{\nu_1(x_2)-\nu_1(\underline{x}_2)} {\nu_1(\overline{x}_2)-\nu_1(\underline{x}_2)}, \theta_2= \frac{1}{2}\frac{\nu_1(\overline{x}_2)-\nu_1(x_2)} {\nu_1(\overline{x}_2)-\nu_1(\underline{x}_2)} \\ \theta_1=\frac{1}{2}\frac{\nu_2(x_2)-\nu_2(\underline{x}_2)} {\nu_2(\overline{x}_2)-\nu_2(\underline{x}_2)}, \theta_2= \frac{1}{2}\frac{\nu_2(\overline{x}_2)-\nu_2(x_2)} {\nu_2(\overline{x}_2)-\nu_2(\underline{x}_2)} $
那么系统(55)可以由如式(2)的LPV模型描述, 其多胞形的各顶点为
$\begin{align*} &A_1=\left[ \begin{array}{cc} 0.8227 & -0.00168 \\ 6.1233 & 0.9367 \\ \end{array} \right]\\& A_2=\left[ \begin{array}{cc} 0.9654 & -0.00182 \\ -0.6759 & 0.9433 \\ \end{array} \right] \\& A_3=\left[ \begin{array}{cc} 0.8895 & -0.00294 \\ 2.9447 & 0.9968 \\ \end{array} \right]\\&A_4=\left[ \begin{array}{cc} 0.8930 & -0.00062 \\ 2.7738 & 0.8864 \\ \end{array} \right]\\& B_1=\left[ \begin{array}{c} -0.000092 \\ 0.1014 \\ \end{array} \right],~ B_2=\left[ \begin{array}{c} -0.000097 \\ 0.1016 \\ \end{array} \right] \\&B_3=\left[ \begin{array}{c} -0.000157 \\ 0.1045 \\ \end{array} \right],~ B_4=\left[ \begin{array}{c} -0.000034 \\ 0.0986 \\ \end{array} \right] \\&C=\left[ \begin{array}{cc} 1 & 0 \\ \end{array} \right] \end{align*} $
仿真基于LPV模型设计控制律, 并将优化得到的控制输入施加都原非线性系统(54)中.
控制输入$T_c$的约束如下:
$ \|T_c\|^2\leq350^2, \|\Delta T_c\|^2\leq5^2, \|\delta T_c\|^2\leq2.5^2 $
(56) 仿真时间为12分钟(min), 采样时间为0.03分钟(min), 批次长度为400.设置初始参考轨迹为$y_{r_1}$, 在第6批次、第7批次分别变为$y_{r_2}$、$y_{r_3}$, 在第8批次变回$y_{r_1}$.批次1的初始控制输入为幅度为330 K的阶跃信号.初始状态为$[C_A, T]^{\rm T}=[0.7 {\rm mol/L}, 340 {\rm K}]^{\rm T}$. $H_\infty$性能上界选为$\varepsilon=20$.权重系数矩阵选取同仿真1.同样地, 收敛条件(42)在每次优化中作为约束$(a=0.9)$, 状态反馈矩阵$F_k(t)$由$F_k(t)=YQ^{-1}$计算得到, 各批次$F_k(200)$的优化值如表 2所示.
表 2 $F_k(t)$优化值Table 2 Optimized feedback control law批次$k$ $F_k(200)$ 2 [-7.8076 -12.6079 -7.9428 -0.0000] 3 [-8.4202 -12.9000 -8.2264 -0.0000] 4 [-7.8744 -12.6839 -7.9521 -0.0000] 5 [-8.9258 -13.1178 -8.4572 -0.0000] 6 [-9.7286 -13.2893 -9.0092 0.0000] 7 [-6.9490 -11.3713 -7.6883 0.0000] 8 [-7.5195 -12.4532 -8.0074 -0.0000] 9 [-7.7803 -12.6691 -7.9535 -0.0000] 在经典MPILC仿真中, 设置$m=10$, $Q_1=I_{400\times400}$, $R_1=I_{10\times10}$. 图 9和图 11为RMPILC和MPILC控制下的跟踪曲线.相应的RMPILC控制输入如图 10所示.可以看出RMPILC从第2批次开始就可以准确跟踪$y_{r_1}$, 且在批次6 $\sim$ 8能够及时跟踪变化轨迹.而MPILC直至批次5才能跟踪上$y_{r_1}$, 且在批次6 $\sim$ 8不能适应参考轨迹变化.因此与经典MPILC相比, 基于LPV模型的RMPILC快速跟踪变参考轨迹, 有利于提高CSTR的生产效率.
 图 9 RMPILC控制下反应温度$T$参考轨迹跟踪曲线Fig. 9 The tracking trajectories for $T$ under RMPILC control
图 9 RMPILC控制下反应温度$T$参考轨迹跟踪曲线Fig. 9 The tracking trajectories for $T$ under RMPILC control 图 10 RMPILC控制下控制输入$T_c$轨迹Fig. 10 The trajectories of control input $T_c$ under RMPILC
图 10 RMPILC控制下控制输入$T_c$轨迹Fig. 10 The trajectories of control input $T_c$ under RMPILC图 12为变轨迹下RMPILC和MPILC仿真中MSE随迭代次数的变化情况.显然, 变参考轨迹下RMPILC的跟踪误差沿迭代轴收敛, 而MPILC的跟踪误差发生较大波动, 会导致产品质量下降.
5. 结束语
本文针对具有重复特性的非线性间歇过程, 提出一种能跟踪变参考轨迹的鲁棒迭代学习模型预测控制.控制器设计基于包含被控系统非线性动态特性的LPV模型, 将LPV模型进行状态增广建立二维迭代误差模型.在鲁棒$H_\infty$预测控制框架下, 设置$H_\infty$性能上界, 并据此构建LMI约束下的目标函数优化问题.分析RMPILC系统的鲁棒稳定性和迭代收敛性, 将其充分条件作为约束加入每个采样时刻的优化中.仿真结果验证了RMPILC在快速跟踪变参考轨迹方面的优势, 表明采用基于LPV模型的RMPILC算法能显著减少迭代学习次数, 提高生产效率.
在实际生产中, 间歇过程的参考轨迹可能会发生剧烈变化.若要保证鲁棒稳定条件和迭代收敛条件, 可能会导致优化问题不可行, 或是可行域太小以至达不到期望的跟踪精度.因此, 未来的研究方向趋向于构建软约束RMPILC算法.在优化中引入松弛变量来放松约束, 允许控制输入在短时间内超出约束以达到扩大可行域的目的[33].基于软约束的RMPILC算法将能够适应剧烈变化的参考轨迹, 提高间歇过程控制的鲁棒性.
-
表 1 Medical chain与现有医疗区块链对比
Table 1 Medical chain vs. existing medical blockchain
系统 基于区块链 共识机制 算法类型 支付报酬 需要节点数 算力需求 投票权比重设定 MDSM 是 改进DPOS POX 否 121个 小 是 MedRec 是 POW POX 是 多 大 否 ModelChain 是 POI POX 是 多 大 否 Medical chain 是 改进PBFT BFT 否 少, 至少4个 小 否  下载: 导出CSV
下载: 导出CSV
表 2 医疗信息化问题与Medical chain应对方式
Table 2 Medical informatization issues and medical chain's solutions
类型 面临问题 应对方式 隐私与安全 恶意攻击医疗数据保护不可抵赖性 将访问控制信息和每次的操作都加入到区块链中, 并且采用非对称加密机制, 能够保证患者的隐私不会受到威胁, 并且无法抵赖 患者参与度 患者难以获取自己的数据每到一家医院需要重新办理就诊卡, 流程繁琐 患者可以在一个平台上查看自己在各家医院的就诊记录, 并且可以隐藏自己相关的医疗信息来保护自己的隐私 数据访问性 医疗研究人员获取医疗数据困难患者获取自己在各医院的就诊记录困难医生获取患者之前的医疗信息困难 采用匿名形式以及访问控制来保证相关研究人员在得到授权后, 可以访问部分医疗信息, 患者可以查看到自己所有的医疗记录, 医生在患者授权下可以访问患者之前的医疗信息 医疗纠纷 在医院与患者发生医疗纠纷时, 医院与患者提供的证据难以确保其真实性 通过数字签名将相关医疗信息及其修改记录存储在区块链中, 确保证据的不可抵赖与真实性
下载: 导出CSV
-
[1] 蔡维德, 郁莲, 王荣, 刘娜, 邓恩艳.基于区块链的应用系统开发方法研究.软件学报, 2017, 28(6):1474-1487 http://d.old.wanfangdata.com.cn/Periodical/rjxb201706010Tsai Wei-Tek, Yu Lian, Wang Rong, Liu Na, Deng En-Yan. Blockchain application development techniques. Journal of Software, 2017, 28(6):1474-1487 http://d.old.wanfangdata.com.cn/Periodical/rjxb201706010 [2] Nakamoto S. Bitcoin: a peer-to-peer electronic cash system[Online], available: https://bitcoin.org/bitcoin.pdf, August 19, 2018 [3] 袁勇, 王飞跃.区块链技术发展现状与展望.自动化学报, 2016, 42(4):481-494 http://www.aas.net.cn/CN/Y2016/V42/I4/481Yuan Yong, Wang Fei-Yue. Blockchain:the state of the art and future trends. Acta Automatica Sinica, 2016, 42(4):481 -494 http://www.aas.net.cn/CN/Y2016/V42/I4/481 [4] Lamport L, Shostak R, Pease M. The Byzantine generals problem. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982, 4(3):382-401 doi: 10.1145/357172.357176 [5] 韩璇, 刘亚敏.区块链技术中的共识机制研究.信息网络安全, 2017, (9):147-152 doi: 10.3969/j.issn.1671-1122.2017.09.034Han Xuan, Liu Ya-Min. Research on the consensus mechanisms of blockchain technology. Netinfo Security, 2017, (9):147-152 doi: 10.3969/j.issn.1671-1122.2017.09.034 [6] Bitshares.org. Delegated proof-of-stake consensus[Online], available: https://bitshares.org/technology/delegated-proof-of-stake-consensus/, July 10, 2018 [7] Castro M, Liskov B. Practical Byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems (TOCS), 2002, 20(4):398-461 doi: 10.1145/571637.571640 [8] 薛腾飞, 傅群超, 王枞, 王新宴.基于区块链的医疗数据共享模型研究.自动化学报, 2017, 43(9):1555-1562 http://www.aas.net.cn/CN/abstract/abstract19131.shtmlXue Teng-Fei, Fu Qun-Chao, Wang Cong, Wang Xin-Yan. A medical data sharing model via blockchain. Acta Automatica Sinica, 2017, 43(9):1555-1562 http://www.aas.net.cn/CN/abstract/abstract19131.shtml [9] Wood G. Ethereum: a secure decentralised generalised transaction ledger[Online], available: http://gavwood.com/paper.pdf, August 19, 2018 [10] Azaria A, Ekblaw A, Vieira T, Lippman A. MedRec: using blockchain for medical data access and permission management. In: Proceedings of the 2nd International Conference on Open and Big Data (OBD). Vienna, Austria: IEEE, 2016.25-30 [11] Ivan D. Moving toward a blockchain-based method for the secure storage of patient records[Online], available: https://www.healthit.gov/sites/default/files/9-16-drew_ivan_20160804_blockchain_for_healthcare_final.pdf, August 19, 2018 [12] Shrier A A, Chang A, Diakun-thibault N, et al. Blockchain and health IT: algorithms, privacy, and data[Online], available: http://www.truevaluemetrics.org/DBpdfs/Technology/Blockchain/1-78-blockchainandhealthitalgorithmsprivacydata_whitepaper.pdf, August 19, 2018 [13] Kuo T T, Hsu C N, Ohno-Machado L. ModelChain: decentralized privacy-preserving healthcare predictive modeling framework on private blockchain networks[Online], available: https://www.healthit.gov/sites/default/files/10-30-ucsd-dbmi-onc-blockchain-challenge.pdf, August 19, 2018 [14] Witchey N. Healthcare Transaction Validation Via Block-chain Proof-of-Work, Systems and Methods, WIPO Patent Application WO/2015/175722, November 2015. [15] Rivest R. The MD5 message-digest algorithm. RFC, 1992, 473(10):492 http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_f659b1885fb8206e9d53960c7f2f1fec [16] Eastlake D 3rd, Hansen T. US secure hash algorithms (SHA and HMAC-SHA)[Online], available: https://www.rfc-ed-itor.org/rfc/pdfrfc/rfc4634.txt.pdf, August 19, 2018 [17] Merkle R C. A digital signature based on a conventional encryption function. In: Proceedings of the 1987 Conference on the Theory and Applications of Cryptographic Techniques. Heidelberg, Berlin, Germany: Springer, 1987.369-378 [18] Rivest R L, Shamir A, Adleman L M. Cryptographic Communications System and Method, USA Patent 4405829, September 1983. [19] Kravitz D W. Digital Signature Algorithm, USA Patent 5231668, July 1993. [20] Johnson D, Menezes A, Vanstone S. The elliptic curve digital signature algorithm (ECDSA). International Journal of Information Security, 2001, 1(1):36-63 http://d.old.wanfangdata.com.cn/OAPaper/oai_pubmedcentral.nih.gov_3821297 [21] 张明德, 刘伟. PKI/CA与数字证书技术大全.北京:电子工业出版社, 2015.22-25Zhang Ming-De, Liu Wei. PKI/CA and Digital Certificate Technology. Beijing:Publishing House of Electronics Industry, 2015.22-25 [22] Josefsson S. The base16, base32, and base64 data encodings[Online], available: https://www.rfc-editor.org/rfc/pdfrfc/rfc4648.txt.pdf, August 19, 2018 [23] 董建成.我国医院信息系统现状及原因分析.中华医院管理杂志, 2003, 19(4):228-230 doi: 10.3760/j.issn:1000-6672.2003.04.014Dong Jian-Cheng. Analysis of status and causes of hospital information system in China. Chinese Journal of Hospital Administration, 2003, 19(4):228-230 doi: 10.3760/j.issn:1000-6672.2003.04.014 [24] National Health Commission of the People's Republic of China. Electronic medical record basic architecture and data standards (Trial)[Online], available: http://www.moh.gov.cn/mohbgt/s6718/200912/45414.shtml, August 19, 2018 [25] Goda K. Storage area network. Encyclopedia of Database Systems. Boston, MA, USA:Springer, 2009.335-336 [26] Castro M, Liskov B. A Correctness Proof for a Practical Byzantine-Fault-Tolerant Replication Algorithm. Massachusetts Institute of Technology, Cambridge, MA, USA, 1999. [27] 结城浩[著], 周自恒[译].图解密码技术.第2版.北京: 人民邮电出版社, 2016.Yuki H[Author], Zhou Zi-Heng[Translator]. Graphical Cryptography. Beijing: The People's Posts and Telecommunications Press, 2016. [28] Galperin S, Malpani A, Adams C, Ankney R, Santesson S, Myers M. X.509 Internet Public Key Infrastructure Online Certificate Status Protocol-OCSP, RFC 6960, 1999. [29] 李凤华, 苏铓, 史国振, 马建峰.访问控制模型研究进展及发展趋势.电子学报, 2012, 40(4):805-813 doi: 10.3969/j.issn.0372-2112.2012.04.030Li Feng-Hua, Su Mang, Shi Guo-Zhen, Ma Jian-Feng. Research status and development trends of access control model. Acta Electronica Sinica, 2012, 40(4):805-813 doi: 10.3969/j.issn.0372-2112.2012.04.030 [30] Szabo N. Formalizing and securing relationships on public networks. First Monday, 1997, 2(9):1-21 [31] Etherscan.io. Ethereum network HashRate growth chart[Online], available: https://etherscan.io/chart/hashrate, August 19, 2018 [32] Bitcoin cash charts[Online], available: https://charts.bitcoin.com/chart/hash-rate, August 19, 2018 [33] Etherscan.io. Ethereum block difficulty growth chart[Online], available: https://etherscan.io/chart/difficulty, August 19, 2018 [34] Wang S, Jiang X Q, Wu Y, Cui L J, Cheng S, Ohno-Machado L. EXpectation propagation LOgistic REgRession (EXPLORER):distributed privacy-preserving online model learning. Journal of Biomedical Informatics, 2013, 46(3):480-496 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0231223213/ [35] Yan F, Sundaram S, Vishwanathan S V N, Qi Y. Distributed autonomous online learning:regrets and intrinsic privacy-preserving properties. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(11):2483-2493 doi: 10.1109/TKDE.2012.191 期刊类型引用(9)
1. 李帷韬,童倩倩,王殿辉,吴高昌. 基于深层卷积随机配置网络的电熔镁炉工况识别方法研究. 自动化学报. 2024(03): 527-543 .  本站查看
本站查看2. 仇翔,蒋文泽,吴麒,张宝康,葛其运. 基于专家知识与监测数据联合驱动的高压开关柜状态评估. 高技术通讯. 2024(07): 776-786 . 百度学术3. 茹鑫鑫,高晓光,王阳阳. 基于模糊约束的贝叶斯网络参数学习. 系统工程与电子技术. 2023(02): 444-452 . 百度学术4. 刘金平,匡亚彬,赵爽爽,杨广益. 长短滑窗慢特征分析与时序关联规则挖掘的过渡过程识别. 智能系统学报. 2023(03): 589-603 . 百度学术5. 刘炎,熊雨露,褚菲,王福利. 基于多源异构信息自适应融合的镁砂熔炼过程运行状态评价. 仪器仪表学报. 2023(09): 322-337 . 百度学术6. 刘渝. 融合语言特征和神经网络的英语机器翻译研究. 自动化与仪器仪表. 2022(05): 142-145 . 百度学术7. 潘晓杰,张文朝,徐友平,杨俊炜,党杰,周濛. 基于暂态能量不平衡的输电网络风险评估模型. 可再生能源. 2022(05): 690-695 . 百度学术8. 王姝,关展旭,王晶,孙晓辉. 基于迁移学习的贝叶斯网络参数学习方法. 东北大学学报(自然科学版). 2021(04): 509-515 . 百度学术9. 常玉清,康孝云,王福利,赵炜炜. 基于贝叶斯网络的磨煤机过程异常工况诊断模型实时更新方法. 仪器仪表学报. 2021(08): 52-61 . 百度学术其他类型引用(12)
-


 下载:
下载:












计量
- 文章访问数: 3350
- HTML全文浏览量: 640
- PDF下载量: 411
- 被引次数: 21
