

A Multiple Extended Target Multi-Bernouli Filter Based on Star-convex Random Hypersurface Model
-
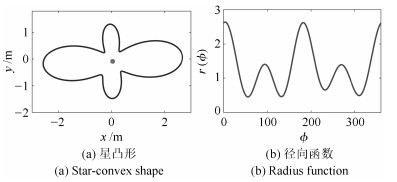
摘要: 针对复杂不确定性环境下具有不规则形状的多扩展目标跟踪问题, 提出了一种基于星凸形随机超曲面模型(Star-convex RHM)的多扩展目标多伯努利滤波算法.首先, 在有限集统计(Finite set statistics, FISST)理论框架下, 采用多伯努利随机有限集(MBer-RFS)和泊松RFS (Possion-RFS)分别描述多扩展目标的状态和观测, 并给出扩展目标势均衡多目标多伯努利(ET-CBMeMBer)滤波器.其次, 利用RHM去描述任意星凸形扩展目标的量测源分布, 提出了容积卡尔曼高斯混合星凸形多扩展目标多伯努利滤波器.此外, 本文给出了一种多扩展目标不规则形状估计性能的评价指标.最后, 通过多扩展目标和具有形状突变的多群目标的跟踪仿真实验验证了本文方法的有效性.Abstract: Considering the tracking of multi-extended target with irregular shape in complicated and uncertain environment, this paper proposes a multi-extended target multi-Bernoulli filtering algorithm based on star-convex random hypersurface model (RHM). First, in the framework of finite set statistics (FISST), the multi-Bernoulli random finite set (MBer-RFS) and Poisson-RFS are used to model multi-extended target state and measurement respectively, and then the extended target cardinality balanced multi-target multi-Bernoulli (ET-CBMeMBer) filter is given. Subsequently, using RHM to represent the measurement source distribution of any star-convex extended target, this paper proposes the cubature Kalman Gaussian mixture Star-convex multi-extended target multi-Bernoulli filter. Besides, this paper also gives a performance metric which can evaluate the irregular shape estimation of multi-extended target. Finally, the effectiveness of the proposed method is verified by the tracking simulations of multi-extended target and multi-group target with sudden shape change.
-
Key words:
- Multiple extended target tracking /
- random hypersurface model /
- multi-Bernoulli filter /
- cubature Kalman
1) 本文责任编委 郭戈 -
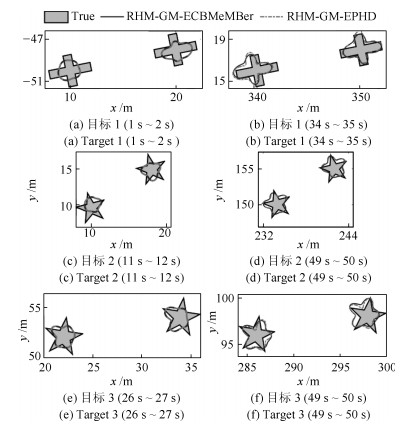
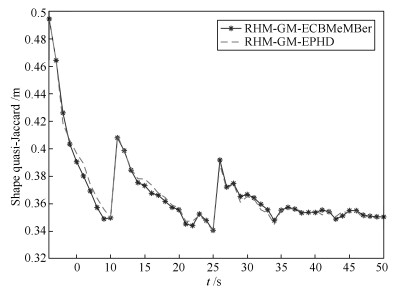
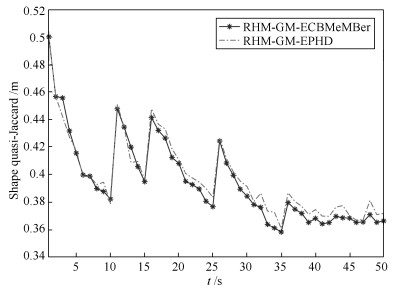
图 6 两种滤波器的形状估计局部放大图
Fig. 6 The partial enlarged effect of the two filters for shape estimation (ET)

图 12 两种滤波器的对群目标的形状估计局部放大图
Fig. 12 The partial enlarged effect of the two filters for shape estimation (GT)
表 1 多目标初始参数
Table 1 Initial parameters of multi-target
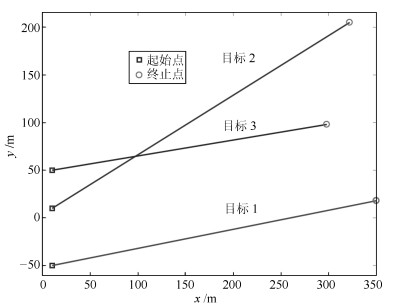
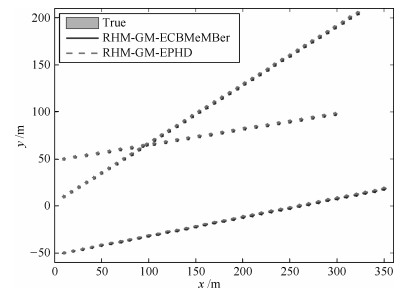
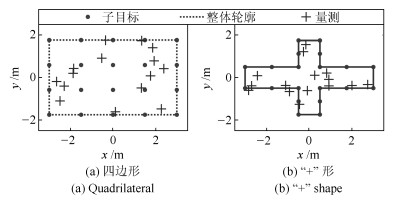
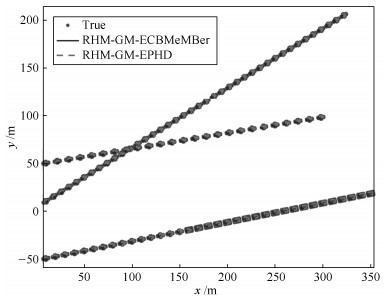
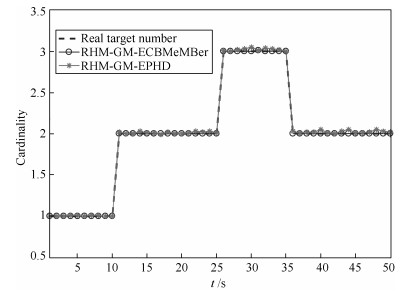
目标 新生时刻(s) 消亡时刻(s) 位置(m) 速度(m/s) 目标1 1 35 $[10, -50]^{\rm T}$ $[10, 2]^{\rm T}$ 目标2 11 50 $[10, 10]^{\rm T}$ $[8, 5]^{\rm T}$ 目标3 26 50 $[10, 50]^{\rm T}$ $[12, 2]^{\rm T}$  下载: 导出CSV
下载: 导出CSV
-
[1] Vo B N, Vo B T, Hoang H G. An efficient implementation of the generalized labeled multi-Bernoulli filter. IEEE Transactions on Signal Processing, 2017, 65(8): 1975-1987 doi: 10.1109/TSP.2016.2641392 [2] Gostar A K, Hoseinnezhad R, Bab-Hadiashar A, et al. Sensor-management for multitarget filters via minimization of posterior dispersion. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(6): 2877-2884 doi: 10.1109/TAES.2017.2718280 [3] Xia Y X, Granström K, Svensson L, Fatemi M. Extended target Poisson Multi-Bernoulli filter. arXiv: 1801.01353, 2018. [4] Cao W, Lan J, Li X R. Extended object tracking and classification using radar and ESM sensor data. IEEE Signal Processing Letters, 2018, 25(1): 90-94 doi: 10.1109/LSP.2017.2757920 [5] Granström K, Baum M, Reuter S. Extended object tracking: introduction, overview, and applications. Journal of Advances in Information Fusion, 2017, 12(2): 139-174 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ026837439/ [6] Sun L F, Lan J, Li X R. Joint tracking and classification of extended object based on support functions. IET Radar, Sonar & Navigation, 2018, 12(7): 685-693 http://cn.bing.com/academic/profile?id=f0ee724952593df098352f581578ff5d&encoded=0&v=paper_preview&mkt=zh-cn [7] Aftab W, De Freitas A, Arvaneh M, Mihaylova L. A Gaussian process approach for extended object tracking with random shapes and for dealing with intractable likelihoods. In: Proceedings of the 22nd International Conference on Digital Signal Processing (DSP). London, UK: IEEE, 2017. 1-5 [8] Beard M, Reuter S, Granström K, Vo B T, Vo B N, Scheel A. Multiple extended target tracking with labeled random finite sets. IEEE Transactions on Signal Processing, 2016, 64(7): 1638-1653 doi: 10.1109/TSP.2015.2505683 [9] Mahler R P S. Advances in Statistical Multisource-Multitarget Information Fusion. Boston, USA: Artech House, 2014. [10] Mahler R P S. Statistical Multisource-Multitarget Information Fusion. Boston, USA: Artech House, Inc., 2007. [11] Mahler R P S. Multitarget Bayes filtering via first-order multitarget moments. IEEE Transactions on Aerospace and Electronic Systems, 2003, 39(4): 1152-1178 doi: 10.1109/TAES.2003.1261119 [12] Mahler R. PHD filters of higher order in target number. IEEE Transactions on Aerospace and Electronic Systems, 2007, 43(4): 1523-1543 doi: 10.1109/TAES.2007.4441756 [13] Vo B T, Vo B N, Cantoni A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Transactions on Signal Processing, 2009, 57(2): 409-423 doi: 10.1109/TSP.2008.2007924 [14] Vo B T, Vo B N, Phung D. Labeled random finite sets and the Bayes multi-target tracking filter. IEEE Transactions on Signal Processing, 2014, 62(24): 6554-6567 doi: 10.1109/TSP.2014.2364014 [15] Vo B N, Vo B T. An implementation of the multi-sensor generalized labeled multi-Bernoulli filter via Gibbs sampling. In: Proceedings of the 20th International Conference on Information Fusion. Xi'an, China: IEEE, 2017: 1-8 [16] Vo B N, Vo B T, Beard M. Multi-sensor multi-object tracking with the generalized labeled multi-Bernoulli filter. IEEE Transactions on Signal Processing, 2019, 67(23): 5952-5967 doi: 10.1109/TSP.2019.2946023 [17] Hoseinnezhad R, Vo B N, Vo B T, Suter D. Bayesian integration of audio and visual information for multi-target tracking using a CB-MeMBer filter. In: Proceedings of the 2011 International Conference on Acoustics, Speech and Signal Processing (ICASSP). Prague, Czech Republic: IEEE, 2011. 2300-2303 [18] Chong N, Nordholm S, Vo B T, Murray I. Tracking and separation of multiple moving speech sources via cardinality balanced multi-target multi Bernoulli (CBMeMBer) filter and time frequency masking. In: Proceedings of the 2016 International Conference on Control, Automation and Information Sciences (ICCAIS). Ansan, South Korea: IEEE, 2016. 88-93 [19] Hoang H G, Vo B T. Sensor management for multi-target tracking via multi-Bernoulli filtering. Automatica, 2014, 50(4): 1135-1142 doi: 10.1016/j.automatica.2014.02.007 [20] 陈辉, 韩崇昭.机动多目标跟踪中的传感器控制策略的研究.自动化学报, 2016, 42(4): 512-523 doi: 10.16383/j.aas.2016.c150529Chen Hui, Han Chong-Zhao. Sensor control strategy for maneuvering multi-target tracking. Acta Automatica Sinica, 2016, 42(4): 512-523 doi: 10.16383/j.aas.2016.c150529 [21] Gilholm K, Salmond D. Spatial distribution model for tracking extended objects. IEE Proceedings-Radar, Sonar and Navigation, 2005, 152(5): 364-371 doi: 10.1049/ip-rsn:20045114 [22] Gilholm K, Godsill S, Maskell S, Salmond D. Poisson models for extended target and group tracking. In: Proceedings of SPIE 5913, Signal and Data Processing of Small Targets 2005. San Diego, USA: SPIE, 2005. 230-241 [23] Lan J, Li X R. Tracking of extended object or target group using random matrix—Part Ⅱ: irregular object. In: Proceedings of the 15th International Conference on Information Fusion. Singapore: IEEE, 2012. 2185-2192 [24] Lan J, Li X R. Tracking of maneuvering non-ellipsoidal extended object or target group using random matrix. IEEE Transactions on Signal Processing, 2014, 62(9): 2450-2463 doi: 10.1109/TSP.2014.2309561 [25] Feldmann M, Franken D. Tracking of extended objects and group targets using random matrices—a new approach. In: Proceedings of the 11th International Conference on Information Fusion. Cologne, Germany: IEEE, 2008. 1-8 [26] Feldmann M, Fränken D, Koch W. Tracking of extended objects and group targets using random matrices. IEEE Transactions on Signal Processing, 2011, 59(4): 1409-1420 doi: 10.1109/TSP.2010.2101064 [27] Orguner U. A variational measurement update for extended target tracking with random matrices. IEEE Transactions on Signal Processing, 2012, 60(7): 3827-3834 doi: 10.1109/TSP.2012.2192927 [28] Baum M, Hanebeck U D. Extended object tracking with random hypersurface models. IEEE Transactions on Aerospace and Electronic Systems, 2014, 50(1): 149-159 doi: 10.1109/TAES.2013.120107 [29] Baum M, Hanebeck U D. Shape tracking of extended objects and group targets with star-convex RHMs. In: Proceedings of the 14th International Conference on Information Fusion. Chicago, USA: IEEE, 2011. 338-345 [30] Zea A, Faion F, Baum M, Hanebeck U D. Level-set random hypersurface models for tracking nonconvex extended objects. IEEE Transactions on Aerospace and Electronic Systems, 2016, 52(6): 2990-3007 doi: 10.1109/TAES.2016.130704 [31] Yao G, Dani A. Image moment-based random hypersurface model for extended object tracking. In: Proceedings of the 20th International Conference on Information Fusion. Xi'an, China: IEEE, 2017. 1-7 [32] Han Y L, Zhu H Y, Han C. A Gaussian-mixture PHD filter based on random hypersurface model for multiple extended targets. In: Proceedings of the 16th International Conference on Information Fusion. Istanbul, Turkey: IEEE, 2013. 1752-1759 [33] Ünsalan C, Erçil A. Conversions between parametric and implicit forms using polar/spherical coordinate representations. Computer Vision and Image Understanding, 2001, 81(1): 1-25 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e8862acbb2ed9a24a7854026578db0ff [34] Zhang G H, Lian F, Han C Z. CBMeMBer filters for nonstandard targets, Ⅰ: extended targets. In: Proceedings of the 17th International Conference on Information Fusion. Salamanca, Spain: IEEE, 2014. 1-6 [35] Arasaratnam I, Haykin S, Hurd T R. Cubature Kalman filtering for continuous-discrete systems: theory and simulations. IEEE Transactions on Signal Processing, 2010, 58(10): 4977-4993 doi: 10.1109/TSP.2010.2056923 [36] Schuhmacher D, Vo B T, Vo B N. A consistent metric for performance evaluation of multi-object filters. IEEE Transactions on Signal Processing, 2008, 56(8): 3447-3457 doi: 10.1109/TSP.2008.920469 -

 下载:
下载:
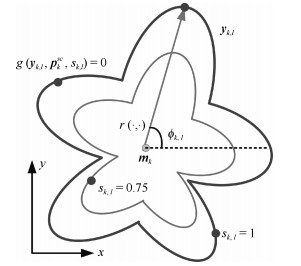





图(15) / 表(1)
计量
- 文章访问数: 3154
- HTML全文浏览量: 361
- PDF下载量: 248
- 被引次数: 0
