

-
摘要: 针对风电场风功率预测问题, 利用历史风功率、气象数据和测风塔实时数据等相关信息, 提出了带有批特征的混核最小二乘支持向量机(Hybrid kernel least squares support vector machine, HKLSSVM)方法, 建立风电场风功率预测模型.为了增强模型的适应性, 设计改进的差分进化算法对模型参数进行优化, 并利用稀疏选择方法来选取合适的训练样本集, 缩短建模时间, 保证预测模型精度.根据风场风机的地理位置分布情况, 提出批划分的建模策略, 对相近地理位置的风机进行组批, 替代传统风场风功率预测方法.通过风场中实际数据进行测试, 实验结果表明与其他预测方法相比, 本文提出的方法能够提高预测精度和效率, 减少风电波动性对电网的影响, 从而提高电网的安全性和可靠性.
-
关键词:
- 风功率预测 /
- 批特征 /
- 混核最小二乘支持向量机 /
- 差分进化 /
- 稀疏选择
Abstract: For the wind power prediction problem in a wind farm, this paper collects some related data such as historical wind power data, meteorological data, and wind speed data sampled by anemometer tower. Then, a wind power prediction method with batch feature is proposed, which is based on hybrid kernel least squares support vector machine (HKLSSVM). It is used to establish the wind power prediction model in the wind farm. To enhance the model$'$s adaptability, an improved differential evolution algorithm is designed to optimize the model parameters, and a sparse selection method is used to select the appropriate training samples set. Thus, the modeling time is shortened and the prediction model accuracy is guaranteed. According to the location distribution of wind turbines in the wind farm, a modeling strategy based on batch partition is proposed, some wind turbines at similar locations can be clustered by batch strategy, which is used instead of the traditional wind power prediction methods in the wind farm. The proposed model is tested through the real data in the wind farm. Experimental results show that the proposed method can improve the accuracy and efficiency of wind power prediction compared with other prediction methods, and can reduce the effect of the wind fluctuation. Hence it can ensure the safety and reliability of the power grid.-
Key words:
- Wind power prediction /
- batch feature /
- hybrid kernel least squares support vector machine (HKLSSVM) /
- differential evolution (DE) /
- sparse selection
1) 本文责任编委 孙秋野 -
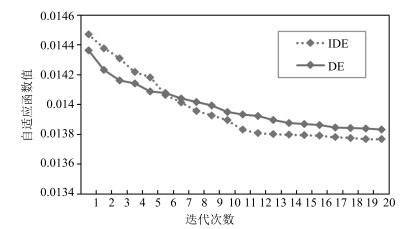
图 3 IDE与DE的风速预测模型收敛比较
Fig. 3 The convergence comparison of wind speed prediction model between IDE and DE
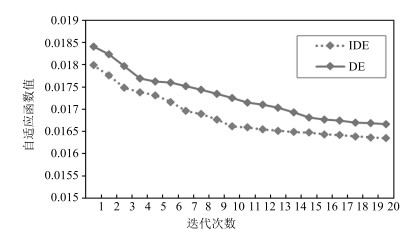
图 4 IDE与DE的风功率预测模型收敛比较
Fig. 4 The convergence comparison of wind power prediction model between IDE and DE
表 1 IDE的参数设置
Table 1 Parameters setting of IDE
参数 ${NP}$ ${M}$ ${g_{\max }}$ $\theta$ $CR$ ${F_1}$ 取值 100 4 20 10 0.7 0.3  下载: 导出CSV
下载: 导出CSV
表 2 BSIDE-HKLSSVM的参数设置范围
Table 2 Parameters setting scope of BSIDE-HKLSSVM
参数 $\lambda$ $\sigma$ $\gamma$ ${d}$ ${a_1}$ 范围 [0.05, 0.1] [1,50] (0, 1 000] [1,10] (0, 0.0001]
下载: 导出CSV
表 3 风场风速预测结果
Table 3 Prediction results of wind speed in the wind farm
方法 RMSE MAXE (m/s) ARE SIDE-HKLSSVM 0.61 2.07 0.07 IDE-HKLSSVM 0.83 2.16 0.10 IDE-LSSVM 1.14 3.17 0.12 SVR 2.14 3.76 0.25 ELM 1.21 2.35 0.13
下载: 导出CSV
表 4 基于BSIDE-HKLSSVM方法的批样机风功率预测结果
Table 4 Prediction results of wind power based on BSIDE-HKLSSVM method for batch turbines
批样机 RMSE MAXE (MW) ARE 9# 0.18 0.63 0.35 18# 0.15 0.61 0.42 31# 0.12 0.46 0.51 37# 0.14 0.50 0.70 52# 0.13 0.53 0.90 59# 0.12 0.63 0.44
下载: 导出CSV
表 5 基于BIDE-HKLSSVM方法的批样机风功率预测结果
Table 5 Prediction results of wind power based on BIDE-HKLSSVM method for batch turbines
批样机 RMSE MAXE (MW) ARE 9# 0.16 0.60 0.32 18# 0.14 0.62 0.36 31# 0.18 0.44 0.92 37# 0.12 0.51 0.50 52# 0.13 0.51 0.94 59# 0.12 0.64 0.41
下载: 导出CSV
表 6 风场风功率预测结果
Table 6 Prediction results of wind power in the wind farm
方法 RMSE MAXE (MW) ARE PAR (%) BSIDE-HKLSSVM 4.57 17.36 0.21 95.4 BIDE-HKLSSVM 4.84 18.86 0.22 95.1 SIDE-HKLSSVM 6.79 21.94 0.22 93.1 IDE-HKLSSVM 7.44 25.98 0.21 92.5 IDE-LSSVM 8.35 26.95 0.26 91.6 STS 8.09 22.01 0.33 91.8 SVR 7.53 27.34 0.22 92.4 ELM 7.93 27.17 0.33 92.0 EE 13.08 36.05 0.33 86.8
下载: 导出CSV
表 7 带有稀疏策略的风场风功率训练模型时间比较
Table 7 Time comparisons of training model with sparsity strategy for the wind power in the wind farm
方法 时间(s) BSIDE-HKLSSVM 382.27 BIDE-HKLSSVM 474.07 SIDE-HKLSSVM 40.71 IDE-HKLSSVM 64.93
下载: 导出CSV
-
[1] MaríL, Nabona N. Renewable energies in medium-term power planning. IEEE Transactions on Power Systems, 2015, 30(1): 88-97 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e8fff6a927f62a4ded3acf054ee093cf [2] 郎劲, 唐立新.考虑风力发电批特征的电力机组调度问题.自动化学报, 2015, 41(7): 1295-1305 doi: 10.16383/j.aas.2015.c140503Lang Jin, Tang Li-Xin. Unit commitment problem for wind turbines power generation with batching characteristics consideration. Acta Automatica Sinica, 2015, 41(7): 1295- 1305 doi: 10.16383/j.aas.2015.c140503 [3] Moeini-Aghtaie M, Farzin H, Fotuhi-Firuzabad M, Amrollahi R. Generalized analytical approach to assess reliability of renewable-based energy hubs. IEEE Transactions on Power Systems, 2017, 32(1): 368-377 http://ieeexplore.ieee.org/document/7457314/ [4] Tascikaraoglu A, Uzunoglu M. A review of combined approaches for prediction of short-term wind speed and power. Renewable and Sustainable Energy Reviews, 2014, 34: 243 -254 doi: 10.1016/j.rser.2014.03.033 [5] Croonenbroeck C, Ambach D. A selection of time series models for short- to medium-term wind power forecasting. Journal of Wind Engineering and Industrial Aerodynamics, 2015, 136: 201-210 doi: 10.1016/j.jweia.2014.11.014 [6] Colak I, Sagiroglu S, Yesilbudak M. Data mining and wind power prediction: A literature review. Renewable Energy, 2012, 46: 241-247 doi: 10.1016/j.renene.2012.02.015 [7] Yuan X H, Tan Q X, Lei X H, Yuan Y B, Wu X T. Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine. Energy, 2017, 129: 122-137 doi: 10.1016/j.energy.2017.04.094 [8] Wan C, Xu Z, Pinson P, Dong Z Y, Wong K P. Probabilistic forecasting of wind power generation using extreme learning machine. IEEE Transactions on Power Systems, 2014, 29(3): 1033-1044 https://ieeexplore.ieee.org/document/6665108/ [9] Qureshi A S, Khan A, Zameer A, Usman A. Wind power prediction using deep neural network based meta regression and transfer learning. Applied Soft Computing, 2017, 58: 742-755 doi: 10.1016/j.asoc.2017.05.031 [10] Pousinho H M I, Mendes V M F, Catalão J P S. A hybrid PSO-ANFIS approach for short-term wind power prediction in Portugal. Energy Conversion and Management, 2011, 52: 397-402 doi: 10.1016/j.enconman.2010.07.015 [11] Haque A U, Mandal P, Meng J L, Srivastava A K, Tseng T L, Senjyu T. A novel hybrid approach based on wavelet transform and fuzzy ARTMAP networks for predicting wind farm power production. IEEE Transactions on Industry Applications, 2013, 49(5): 2253-2261 doi: 10.1109/TIA.2013.2262452 [12] Heinermann J, Kramer O. Machine learning ensembles for wind power prediction. Renewable Energy, 2016, 89: 671- 679 doi: 10.1016/j.renene.2015.11.073 [13] Ye L, Zhao Y N, Zeng C, Zhang C H. Short-term wind power prediction based on spatial model. Renewable Energy, 2017, 101: 1067-1074 doi: 10.1016/j.renene.2016.09.069 [14] 刘强, 秦泗钊.过程工业大数据建模研究展望.自动化学报, 2016, 42(2): 161-171 doi: 10.16383/j.aas.2015.c140503Liu Qiang, Qin S Joe. Perspectives on big data modeling of process industries. Acta Automatica Sinica, 2016, 42(2): 161-171 doi: 10.16383/j.aas.2015.c140503 [15] 陶剑文, 王士同.领域适应核支持向量机.自动化学报, 2012, 38(5): 797-811 doi: 10.3724/SP.J.1004.2012.00797Tao Jian-Wen, Wang Shi-Tong. Kernel support vector machine for domain adaptation. Acta Automatica Sinica, 2012, 38(5): 797-811 doi: 10.3724/SP.J.1004.2012.00797 [16] 石勇, 李佩佳, 汪华东. L2损失大规模线性非平行支持向量顺序回归模型.自动化学报, 2019, 45(3): 505-517 doi: 10.16383/j.aas.2018.c170438Shi Yong, Li Pei-Jia, Wang Hua-Dong. L2-Loss large-scale linear nonparallel support vector ordinal regression. Acta Automatica Sinica, 2019, 45(3): 505-517 doi: 10.16383/j.aas.2018.c170438 [17] 高明哲, 许爱强, 唐小峰, 张伟.基于多核多分类相关向量机的模拟电路故障诊断方法.自动化学报, 2019, 45(2): 434-444 doi: 10.16383/j.aas.2017.c160779Gao Ming-Zhe, Xu Ai-Qiang, Tang Xiao-Feng, Zhang Wei. Analog circuit diagnostics method based on multi-kernel learning multiclass relevance vector machine. Acta Automatica Sinica, 2019, 45(2): 434-444 doi: 10.16383/j.aas.2017.c160779 [18] 张凯军, 梁循.一种改进的显性多核支持向量机.自动化学报, 2014, 40(10): 2288-2294 doi: 10.3724/SP.J.1004.2014.02288Zhang Kai-Jun, Liang Xun. An improved domain multiple kernel support vector machine. Acta Automatica Sinica, 2014, 40(10): 2288-2294 doi: 10.3724/SP.J.1004.2014.02288 [19] Ouyang T H, Zha X M, Qin L, Xiong Y, Xia T. Wind power prediction method based on regime of switching kernel functions. Journal of Wind Engineering and Industrial Aerodynamics, 2016, 153: 26-33 doi: 10.1016/j.jweia.2016.03.005 [20] Ouyang T H, Zha X M, Qin L. A combined multivariate model for wind power prediction. Energy Conversion and Management, 2017, 144: 361-373 doi: 10.1016/j.enconman.2017.04.077 [21] Khosravi A, Koury R N N, Machado L, Pabon J J G. Prediction of wind speed and wind direction using artificial neural network, support vector regression and adaptive neuro-fuzzy inference system. Sustainable Energy Technologies and Assessments, 2018, 25: 146-160 doi: 10.1016/j.seta.2018.01.001 [22] Yuan X H, Chen C, Yuan Y B, Huang Y H, Tan Q X. Short-term wind power prediction based on LSSVM-GSA model. Energy Conversion and Management, 2015, 101: 393-401 doi: 10.1016/j.enconman.2015.05.065 [23] Zhang L L, Li M S, Ji T Y, Wu Q H. Short-term wind power prediction based on intrinsic time-scale decomposition and LS-SVM. In: Proceedings of the 2016 IEEE Innovative Smart Grid Technologies- Asia (ISGT-Asia). Melbourne, Australia: IEEE, 2016. 41-45 [24] Vapnik V N. The Nature of Statistical Learning Theory. New York: Springer Verlag, 1995. [25] Liu C, Tang L X, Liu J Y, Tang Z H. A dynamic analytics method based on multistage modeling for a BOF steelmaking process. IEEE Transactions on Automation Science and Engineering, 2019, 16(3): 1097-1109 doi: 10.1109/TASE.2018.2865414 [26] Storn R, Price K. Differential Evolution-A Simple and Efficient Adaptive Scheme for Global Optimization over Continuous Spaces, Technical Report TR-95-012, International Computer Science Institute, Berkeley, USA, 1995. [27] Suykens J A K, van Gestel T, de Brabanter J, de Moor B, Vandewalle J. Least Squares Support Vector Machines. Singapore: World Scientific, 2003. [28] Drucker H, Burges C J, Kaufman L, Smola A J, Vapnik V. Support vector regression machines. In: Proceedings of the 1997 Advances in Neural Information Processing Systems. Denver, CO, USA: NIPS, 1997. 155-161 [29] Huang G B, Zhou H M, Ding X J, Zhang R. Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2012, 42(2): 513-529 doi: 10.1109/TSMCB.2011.2168604 -

 下载:
下载:

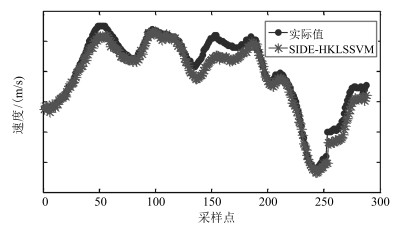

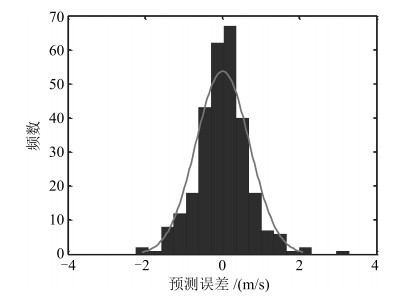

计量
- 文章访问数: 1419
- HTML全文浏览量: 138
- PDF下载量: 166
- 被引次数: 0
