

-
摘要: 针对局部搜索类改进型非劣分类遗传算法(Nondominated sorting genetic algorithm Ⅱ,NSGAⅡ)计算过程中种群分布不均的问题,提出一种基于均匀分布的NSGAⅡ(NSGAⅡ based on uniform distribution,NSGAⅡ-UID)多目标优化算法.首先,该算法将种群映射到目标函数对应的超平面,并在该平面上进行聚类以增加解的多样性.其次,为了提高解的分布性,将映射平面进行均匀分区.当分段区间不满足分布性条件时,需要激活分布性加强模块.与此同时在计算过程中分段区间可能会出现种群数量不足或无解的状况,为了保证每个区间所选个体数目相同.最后,采用将最优个体进行极限优化变异的方法来获得缺失个体.实验结果显示该算法可以保证种群跳出局部最优且提高收敛速度,并且在解的分布性和收敛性方面均优于文中其他多目标优化算法.
-
关键词:
- 改进型非劣分类遗传算法 /
- 映射 /
- 聚类 /
- 分布性加强 /
- 局部变异
Abstract: Because the population distribution is uneven during the local search process of nondominated sorting genetic algorithm Ⅱ (NSGAⅡ), a multi-objective optimization algorithm for NSGAⅡ based on uniform distribution (NSGAⅡ-UID) is proposed. Firstly, the population which has been clustered is mapped to the hyperplane of the corresponding objective function, then the diversity of population is increased. Secondly, in order to improve the distribution uniformity of the solution, the mapping plane is evenly partitioned. However, when the distribution condition is not satisfied in the corresponding partition, the distribution enhancement module is activated. At the same time the individuals may be insufficient or empty in the piecewise interval during the calculation process, in order to ensure that the number of selected individuals in each interval is the same, the local variation method of the best solution is proposed to get the missing individuals lastly. The experimental results show that the method ensures that the population can jump out the local optimal and the convergence speed can be improved. And the distribution and convergence of this algorithm is superior to the other multi-objective optimization algorithms. -
稀土是由镧系元素, 钪和钇等17种元素组成, 且以共生矿形式存在.稀土元素素有"工业维生素"的美称, 已成为极其重要的战略资源.目前我国稀土萃取分离工艺技术已达到世界先进水平[1], 但稀土工业生产自动化水平普遍较低, 仍停留在"离线分析、手工调整、经验控制"状态, 导致企业生产效率低、资源消耗大、产品质量不稳定, 成为制约稀土工业发展的瓶颈.因此, 部分学者对稀土萃取过程建模与控制进行了大量研究, 并取得了一定成果.公锡泰等[2]在稀土萃取过程的测控敏感点安装在线分析仪, 并在"四出口"萃取生产线上开展自动反馈控制试验, 取得了较好的结果.但在线分析仪因频繁堵塞, 工作人员保养习惯等原因导致难以长时间使用. Giles等[3]提出了基于人工神经网络的稀土萃取控制模型.贾文君等[4]考虑稀土萃取过程的多段动态特性的基础上, 建立了一种具有状态滞后的双线性动态模型.该模型忽略了级间相互作用, 损失了部分动态特性, 难以实现萃取过程流量自动控制, 现场仍采用操作员手动调节模式.黄桂文[5]和Jia等[6]研究了利用稀土离子的特征颜色进行串级萃取工艺控制的可行性, 并总结归纳了萃取剂、料液、洗涤液流量调节的经验公式.
Chai等[7]和杨辉等[8]提出了具有两层体系结构的基于案例推理技术的稀土萃取过程优化控制系统.该方法采用案例推理技术实现上层优化器的功能, 对底层回路值进行预设定, 并利用元素组分含量的离线化验值和预测值对预设定值进行修正, 底层流量回路采用PID控制器实现闭环控制.但是上述方法的优化层只采用了案例推理技术. Yang等[9]提出了稀土萃取过程组分含量分布控制方法, 首先根据每一级建立渐进阶梯式模型, 结合质量平衡模型和监测级组分含量变化趋势, 通过动态补偿萃取剂和洗涤剂流量, 使两端出口产品满足纯度要求, 该方法忽略了较多实际因素, 难以应用于生产实践.针对稀土萃取过程非线性和动态特性, 杨辉等[10]采用自适应神经模糊推理系统(ANFIS)对CePr/Nd萃取过程进行描述, 运用广义预测控制方法(GPC)实现各控制流量的优化控制.文献[11]提出一种稀土萃取过程多模型建模和组分含量预测控制方法, 基于组分含量预测值对CePr/Nd萃取过程中萃取剂和洗涤剂流量进行动态补偿, 以保证两端出口产品的纯度.但一旦工作环境发生变化, 给定参数的PID控制器无法自适应调整, 不能达到最优效果.很明显, 目前还没有较好的稀土萃取过程萃取量和洗涤量控制方法.
针对CePr/Nd稀土萃取过程入矿条件各参数的重要性程度不一致特点, 本文首先提出基于特征属性加权的案例推理预设定模型以实现对萃取剂/洗涤剂的流量预设定, 然后针对镨/钕稀土萃取过程的稀土溶液颜色与组分含量密切相关的特点[12], 利用机器视觉技术获得稀土溶液颜色值, 建立基于LS-SVM的组分含量软测量模型, 在此基础上, 采用基于模糊的智能动态补偿模型补偿萃取剂和洗涤剂流量设定值.
1. 工艺描述与优化控制框架
1.1 工艺描述
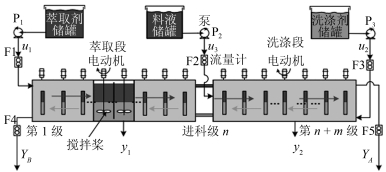
由于分馏萃取可同时得到二个高纯度、高收率的产品, 且单级萃取不能达到有效的分离效果, 因此稀土工业生产普遍采用串级分馏萃取方式(若干级萃取槽串联起来), 使含料水相与有机相多次接触, 并从混合稀土溶液中分离、富集、提取所需具有一定纯度和收率的单一稀土元素. CePr/Nd稀土萃取分离工艺如图 1所示.按照Ce、Pr和Nd分离元素的化学特性, 该萃取过程将Ce和Pr设为难萃组分$ B $, 将Nd设为易萃组分$ A $.在稀土元素Pr和Nd位置间切割, 料液进料为有机相进料方式.整个稀土萃取生产线包括$ {n} $级萃取段和$ m $级洗涤段共$ {n+m} $级萃取槽组成, 每级萃取槽上面溶液为有机相下面溶液为水相.该生产工艺流程第1级萃取槽加入萃取剂$ u_1 $, 第$ {n} $级萃取槽加入料液$ u_3 $; 第$ {n+m} $级萃取槽加入洗涤剂$ u_2 $.由于萃取槽体独特的结构设计和搅拌力的作用, 使得各级萃取槽中有机相从左向右顺向流动、水相从右向左逆向流动.稀土溶液在萃取剂和洗涤剂的作用下经过萃取段和洗涤段各级萃取槽的交换和纯化, 最后从萃取段第1级水相出口得到目标纯度为$ {Y_B} $的难萃$ B $产品, 洗涤段第$ {n+m} $级有机相出口得到目标纯度为$ {Y_A} $的易萃$ A $产品.
1.2 萃取量和洗涤量控制方案分析
该萃取工艺包含料液、萃取剂和洗涤剂等进料, 水相、有机相等出料, 料液指混合稀土溶液, 萃取剂用于控制有机相出口易萃组分的纯度(即组分含量), 洗涤剂(酸液)用于控制水相出口难萃组分的纯度.
CePr/Nd稀土萃取过程的控制目标是指产量、有机相出口易萃稀土元素$ A $纯度和水相出口难萃稀土元素$ B $纯度等指标满足生产要求.稀土萃取过程的入矿条件及扰动量包括萃取流程原料处理量、料液稀土元素配分、皂化度、萃取剂浓度、料液浓度和洗涤剂浓度等工艺参数.其控制变量包括稀土萃取过程添加的萃取剂、洗涤剂、料液等流量值(简称萃取量、洗涤量、料液量).当稀土萃取生产工艺产量指标不变时, 料液的流量设定值一般不作调整, 即料液流量与稀土处理量指标直接关联, 一般不作为工业稀土萃取生产过程的调整量.
稀土萃取生产过程对关键工艺参量稀土元素组分含量缺乏有效的在线检测手段; 且萃取机理复杂、工艺流程长, 难以建立精确的萃取量(洗涤量)与稀土元素组分含量的关系数学模型, 并依据组分含量实现萃取量(洗涤量)优化控制.因此, 实际稀土萃取工业生产过程中工作人员一般根据萃取流程原料处理能力、料液稀土元素配分、皂化度、萃取剂浓度、料液浓度和酸液浓度等入矿条件预先设定萃取量和洗涤量, 然后当入矿条件或扰动量波动导致萃取溶液的元素组分含量变化时, 工作人员再根据CePr/Nd萃取溶液颜色或离线化验值凭借操作经验调整萃取量和洗涤量.例如, 当工况异常导致难萃组分$ B $纯度的化验值或易萃组分$ A $纯度的化验值低于目标值时, 操作人员需根据组分含量化验值调整萃取剂和洗涤剂的流量设定值.但因为萃取工艺流程长、离线化验流程(一班组等隔化验2次)等因素导致化验延时较长, 操作人员难以及时有效地调整萃取量和洗涤量, 导致CePr/Nd萃取工艺生产效率较差.当工况变化频繁时, 操作人员不能及时准确地判断工况和调整萃取量(洗涤量)设定值, 将会使控制系统性能变坏甚至瘫痪, 常常造成故障工况[13-14].
根据稀土萃取工业生产操作实践经验可知, 操作人员首先根据入矿条件预先设定萃取剂和洗涤剂流量值, 在萃取生产过程中再根据稀土元素组分含量的变化对流量设定值动态微调补偿, 使萃取生产稳定运行.由于生产工艺指标稀土元素组分含量与底层控制回路的萃取量和洗涤量设定值密切相关, 它们间的静态、动态特性难以用精确模型描述.为此, 本文结合调节控制和过程运行优化思想, 采用两层结构的实时优化过程模型[15-16], 上层采用非线性专家经验模型优化基础控制回路的萃取量(洗涤量)设定值, 下层通过PID基础控制系统跟踪设定值, 尽可能使过程运行在经济优化状态.由于PID控制能够实时有效地调节萃取剂和洗涤剂流量在给定值上, 因此本文重点研究上层优化结构模型, 该模型首先模拟操作人员专家行为, 采用案例推理方法预设定萃取剂和洗涤剂流量值, 其次, 在萃取生产过程中根据稀土元素组分含量变化采用模糊推理技术对预设定值动态微调补偿, 从而实时优化萃取量和洗涤量设定值.
综上所述, 本文提出一种案例推理静态设定和模糊推理动态补偿相结合的CePr/Nd萃取过程萃取量和洗涤量优化控制方法, 其总体方案结构如图 2所示, 主要包括萃取剂/洗涤剂流量预设定模型、稀土元素组分含量软测量模型及模糊推理智能补偿模型.借鉴人工操作专家行为, 预设定模型采用案例推理方法根据稀土生产入矿条件和生产工艺指标从历史操作案例库中按照一定的匹配原则选择最接近实时工况的流量作为流量预设定值; 然后根据稀土溶液组分含量的变化动态补偿流量预设定值, 包括基于稀土溶液颜色特征的组分含量软测量模型和模糊推理智能补偿模型; 组分含量软测量模型根据机器视觉系统采集到的稀土溶液图像颜色特征软测量稀土溶液的组分含量, 模糊推理智能补偿模型根据软测量模型计算的组分含量与目标组分含量的比较值对预设定的萃取量和洗涤量动态补偿; 最终得到一个满足实时工况要求的萃取剂和洗涤剂流量设定值, 作为底层控制回路的给定值, 由PID控制器实现对萃取剂和洗涤剂流量给定值的跟随控制.此外, 为使各个模型更加准确, 离线检测到的组分含量数据也要作为各个模型数据库更新、校正的参考数据源.
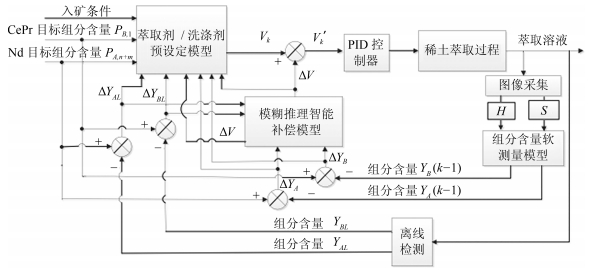 图 2 萃取量和洗涤量优化控制方案Fig. 2 Optimal control scheme for the flow rate of the extractant and the detergent
图 2 萃取量和洗涤量优化控制方案Fig. 2 Optimal control scheme for the flow rate of the extractant and the detergent2. 基于案例推理的药剂量预设定模型
稀土萃取实际生产过程工作人员通常凭借操作经验根据萃取生产流程原料处理量、料液稀土元素配分、皂化度、萃取剂浓度、料液浓度和酸液浓度等入矿条件预先设定萃取剂和洗涤剂流量值.案例推理(Case based reasoning, CBR)是借鉴人类思维方式对问题进行处理的人工智能推理方法, 并从案例中获取专家知识用于解决新问题.基于此, 采用案例推理技术预设定稀土萃取过程萃取剂/洗涤剂的最初值.
基于CBR技术的分类器主要根据已知类别中的历史案例来判断一个新案例属于哪个类.分类精度是评价案例推理技术的一个重要指标, 案例检索、案例重用、案例更新与删除都对分类精度有着重要的影响.由于每个入矿条件的重要程度不一致, 所以利用CBR检索时需要考虑给每个入矿条件属性分配不同的权重, 显然如何确定属性的权重显得尤为重要.此外, 由于实际稀土萃取生产每隔2分钟就要检索案例并产生新的案例, 如果没有合适的案例更新及退出机制, 则案例库中的案例会急剧膨胀, 导致案例检索的精度下降, 因此本文主要针对这两方面问题进行设计.
1) 案例构造
通过对稀土萃取生产过程工艺机理和过程工况数据的分析表明, 稀土料液配分$ {Y_A} $、料液浓度$ {C_F} $、萃取剂浓度$ {C_S} $、洗涤剂浓度$ {C_W} $、料液处理量$ {G} $、产品纯度指标$ {P_{B, 1}} $及$ {P_{A, n+m}} $等入料参数和工艺指标参数直接影响到CePr/Nd萃取过程萃取量和洗涤量的设定值.每条案例都由工况描述和案例解构成, 可以用式(1)表示:
$$ \begin{equation} {\rm{Case}}(X_k, V_k) = {\rm{Case}}((x_{1, k}, \cdots, x_{7, k}), (v_{1, k}, v_{2, k})) \end{equation} $$ (1) 其中, $ {X_k = (x_{1, k}, \cdots, x_{7, k})} $表示第$ {k} $条工况描述, $ {x_{1, k}, \cdots, x_{7, k}} $分别表示稀土料液配比$ {R_F} $、料液浓度$ {C_F} $、萃取剂浓度$ {C_S} $、洗涤剂浓度$ {C_W} $、料液处理量$ {G} $、产品纯度指标$ {P_{B, 1}} $及$ {P_{A, n+m}} $等; $ {V_k = (v_{1, k}, v_{2, k})} $表示第$ {k} $条工况描述所对应的解答, $ {v_{1, k}, v_{2, k}} $分别表示萃取量预设定值$ {V_S} $和洗涤量预设定值$ {V_W} $.
2) 案例检索、匹配与重用
CBR作为一种重要的问题求解范式, 基于"相似问题具有相似解"的认知假设, 通过检索存储于案例库中的相似案例来解决当前的新问题[17].案例检索策略可采用最近邻检索策略, 通过计算目标案例与源案例的特征向量之间的距离衡量二者的相似性, 距离越小说明两案例间的相似度越高. KNN (K-nearest neighbor)检索策略[18]是最近邻检索策略的扩展, 当$ {K = 1} $时就是最近邻策略; 当$ {K>1} $时, 需将历史案例库中的$ {p} $个案例与目标案例的相似度$ {S(X, X_1), \cdots, S(X, X_P)} $从大到小排列, 依次选出相似度最大的$ {K} $个近邻, 并从这$ {K} $个近邻的结果中取出最多的某类结果作为新问题的建议解答.该策略简单有效, 计算方便, 但这种策略对于噪声或者不相关的数据比较敏感, 其解决通常依赖于给案例属性分配不同的权重.因此在利用KNN计算案例之间的相似度之前, 须对工况描述属性的权重进行合理的分配[19].
根据工况描述$ {X_k = (x_{1, k}, \cdots, x_{7, k})} $进行案例检索和匹配, 由入矿条件对稀土萃取过程的影响程度, 设定权重为$ {w_i\; (i = 1, \cdots, 7)} $.在检索过程中, 由入矿条件和工艺指标计算所有案例与该工况输入条件的相似度, 检索出满足设定阈值的所有案例.
假设案例库中共有$ {n} $条案例, 其工况描述为$ {X_k = (x_{1, k}, \cdots, x_{7, k})} $, 对应案例解为$ {V_k = (v_{1, k}, v_{2, k})} $.设目标工况为$ {X = (x_{1}, \cdots, x_{7})} $, 其对应的案例解为$ {V = (v_{1}, v_{2})} $.定义单个工况输入条件$ {X_k} $和$ {X} $间的相似度函数为:
$$ \begin{align} S(X, X_k) = &1-\left(\sum\limits_{i = 1}^m {{w_i}({x_i-x_{i, k})^2}}\right)^{\frac{1}{2}}, \\& k = 1, 2, \cdots, n \end{align} $$ (2) 其中, $ {w_i} $是第$ {i} $个特征属性的权重, 满足$ {\sum\nolimits_{i = 1}^m{w_i = 1}} $.将案例库中与新工况输入条件的相似度$ {S(X, X_k)} $大于或等于阈值的所有历史案例都检测出来作为候选案例.
假设系统检索出大于相似度阈值的$ {l\; (l<n)} $个候选案例, 其相似度值分别为$ {s_1, \cdots, s_l} $, 对应的案例解为$ {V_k = (v_{1, k}, v_{2, k})\; (k = 1, \cdots, l)} $, 则当前新工况的案例解按下式计算:
$$ \begin{equation} \left\{ \begin{array}{l} v_1 = \dfrac{\sum\limits_{k = 1}^l{s_k}\times{v_{1, k}}}{\sum\limits_{k = 1}^l{s_k}}\\ v_2 = \dfrac{\sum\limits_{k = 1}^l{s_k}\times{v_{2, k}}}{\sum\limits_{k = 1}^l{s_k}} \end{array} \right. \end{equation} $$ (3) 属性权重优化的方法较多[20-21], 由于萃取工艺生产过程的复杂多样性, 本文采用内省学习方法调整式(2)的属性权重, 根据两个案例相同属性的描述值, 需将案例属性分为匹配属性和不匹配属性, 给出其定义[22].
定义1. 设历史案例库中的两案例$ C_I = (X_I;Y_I) $和$ {C_{II} = (X_{II};Y_{II})} $, 其中, $ X_I = (x_{1, I}, x_{2, I}, \cdots, $ $ x_{m, I}) $, $ X_{II} = (x_{1, II}, x_{2, II}, \cdots, $ $ x_{m, II}) $, 若满足$ 0\leq $ $ \mid\! x_{i, I}-x_{i, II}\!\mid\leq \xi_{\rm match} $, 则称案例$ {C_I} $与案例$ {C_{II}} $的第$ {i} $个属性为匹配属性, 否则, 称为不匹配属性.其中, $ {\xi_{\rm match}} $为判断属性是否匹配的阈值, 表示两个案例同一属性的接近程度.
基于内省学习原理, 采用如下权重学习策略规则.
规则1. 存在一条案例分类成功时, 匹配属性的权重增加, 同时不匹配属性的权重减少:当检索到的案例$ A $具有和目标案例$ C $相同的类别时(分类成功), 增大案例$ A $中与案例$ C $匹配的属性的权重, 同时减小案例$ A $中与案例$ C $不匹配的属性的权重.如此, $ A $与$ C $的相似度将增大, 保证在求解案例$ C $时, 相似案例$ A $更有可能被检索到.
规则2. 存在一条案例分类失败时, 匹配属性的权重减少, 不匹配属性的权重增加:当检索到的案例$ B $具有和目标案例$ C $不同的类别时(分类失败), 减小案例$ B $中与案例$ C $匹配的属性的权重, 同时增大案例$ B $中与案例$ C $不匹配的属性的权重.如此, $ B $与$ C $的距离增大($ B $被"推离" $ C $), 保证在求解案例$ C $时, 案例$ B $不易被检索到.
根据上述定义和规则, 考虑稀土入矿条件和参数属性对案例属性权重的影响, 对属性权重调整如下.
权重增加:
$$ \begin{equation} w_i(t+1) = w_i(t)+\frac{\triangle_i}{m}, \quad w_i(t+1)\geq0 \end{equation} $$ (4) 权重减少:
$$ \begin{equation} w_i(t+1) = w_i(t)-\frac{\triangle_i}{m}, \quad w_i(t+1)\geq0 \end{equation} $$ (5) 其中, $ {w_i(t)} $是第$ {i} $个属性第$ {t} $次迭代的权重; $ {w_i(t+1)} $是第$ {i} $个属性第$ {t+1} $次迭代的权重; $ {\triangle_i/m} $决定权重的变化量, $ {m} $是案例属性的个数, 对于不同的分类问题, 如果属性个数不同, 即使$ {\triangle_i} $相同,权重的变化量也不相同.但是对于同一个案例库而言, $ {m} $是固定不变的, 因此权重的变化主要与$ {\triangle_i} $有关, 为实现属性权重有效调整, 且保证属性权重调整值不会超过属性权重之和, $ {\triangle_i} $在$ {(0, m)} $区间内取值, 并且需满足式(4)和式(5)更新后的权重不小于零.
当一条案例所有属性的权重都被调整之后, 为保证所有属性的权重之和为1, 需进行归一化操作:
$$ \begin{equation} w_i(t+1)' = \frac{w_i(t+1)}{\sum\limits_{i = 1}^m w_i(t+1)} \end{equation} $$ (6) 其中, $ {w_i(t+1)'} $是第$ {i} $个属性第$ {t+1} $次迭代的最终权重.
3) 案例修正、存储和删除
经案例推理得到的案例结果与新工况不相匹配时, 则需应用其他领域相关知识对案例结果进行人工修正, 或更改参数和检索规则, 使得修正后的案例解(各回路流量设定值)与新工况相匹配.如果根据当前的工况描述没有被正确地分类成案例, 则说明当前案例库中没有该工况的案例, 则需要把当前的工况及案例加入案例库.如果根据当前的工况描述被正确地分类了, 但是其相似度太小, 则说明分类信息不完善, 则需要重新更新该类工况的案例, 并使得该类工况案例的相似度小于$ {\sigma[0, 1]}$并保存.
很明显, 案例推理的案例库随生产工况变化不断增加, 不但增加了检索的难度, 而且降低检索的精确度.所以, 伴随着检索案例的增加, 同时应该删除一些已经不适合新工况的案例.
假定每一个新的案例被保存时都被赋予一个初始遗忘因子, 根据内省学习原理, 其遗忘值的更新如下[23]:
$$ \begin{equation} F_i(t+1) = F_i(t)+\beta\times{r_i}\times{F_i(0)} \end{equation} $$ (7) 其中, $ {\beta} $为遗忘增强因子; $ {r_i} $为奖励函数, 当检索案例与新案例一致时为$ -1, $否则为1. $ {F_i(0)} $为案例的初始遗忘值, $ {F_i(t)} $为案例当前迭代的遗忘值, $ {F_i(t+1)} $为案例当前迭代后的遗忘值.很明显, 当检索案例每次都能成功地匹配当前工况时, 则遗忘值不断减少.当检索案例每次不能成功地匹配当前工况时, 则遗忘值不断增加, 当$ {F_i(t+1) > \varsigma} $时, 该案例需要删除.
3. 基于稀土溶液颜色的智能补偿模型
通常情况下, 采用基于案例推理的预设定模型可得到一个相对合理的萃取剂和洗涤剂流量预设定值, 但该模型没有考虑到实时外界干扰导致的工况变化.当稀土萃取生产过程遇扰动使工况变化时, 难以保证生产指标满足工艺要求.实际铈镨/钕萃取工业生产过程中, 工作人员周期性地根据溶液颜色或组分含量化验值等调整萃取剂和洗涤剂流量差值, 使得生产指标满足工艺要求.本质上, 领域专家或工作人员是根据稀土元素组分含量变化差和变化率调节药剂量流量, 因此, 基于铈镨/钕溶液颜色能够表征其组分含量, 本文采用基于稀土溶液颜色的在线补偿模型, 该模型主要包括基于稀土溶液颜色的组分含量软测量模型和基于模糊推理的智能补偿模型.
3.1 组分含量软测量模型
稀土元素独特的电子层结构可使稀土离子具有丰富的发射光谱. CePr/Nd萃取生产工艺的易萃组分和难萃组分分别显现紫色和绿色颜色特征, 且颜色深浅与稀土离子溶度有关.由于难萃稀土组分含量和易萃稀土组分含量之和为1, 所以一般情况下只需要知道其中一个即可.将采集的稀土溶液颜色图像在HSI颜色空间下提取出H、S、I颜色特征分量.颜色H分量和S分量与组分含量的相关性分析如图 3所示, 图 3(a)为二维图, 图 3(b)为三维图.从图 3中可知, 溶液图像颜色与组分含量关系具有一定的规律, 且为非线性关系, 可表示如下[24]:
$$ \begin{equation} y = f(C_h, C_s) \end{equation} $$ (8)  图 3 颜色分量H、S特征值和组分含量相关性分析Fig. 3 Correlation between color feature and component content
图 3 颜色分量H、S特征值和组分含量相关性分析Fig. 3 Correlation between color feature and component content其中, $ {y} $表示组分含量, $ C_h $、$ C_s $分别表示HSI颜色空间的H和S分量.该非线性关系可采用非线性回归、神经网络等建模.由于最小二乘支持向量机(LS-SVM) 在求解二次规划问题时遇到的稀疏性及运算复杂问题时简化了采用二次规划求解优化问题的方式, 对小样本建模效果较好[25].因此, 式(8)采用LS-SVM建模.
LS-SVM算法的最小化目标函数为[26]:
$$ \begin{align} & \min\;J = \frac{1}{2}w^{ {\rm{T}}}w+\frac{1}{2}\gamma\sum\limits_{i = 1}^l{e_i^2} \\ & {\rm{s.t.}}\;y_i = w^ {{\rm{T}}}\cdot\varphi(x_i)+b+e_i, \;i = 1, \cdots, l \end{align} $$ (9) 根据式(9), 构造其拉格朗日函数为:
$$ \begin{equation} L = J-\sum\limits_{i = 1}^l \alpha_i[w^ {{\rm{T}}}\cdot\varphi(x_i)+b+e_i-y_i] \end{equation} $$ (10) 其中, $ {\alpha_i} $为拉格朗日乘子, 根据KTT条件得:
$$ \begin{equation} \begin{cases} \dfrac{\partial L}{\partial w} = 0 \to {w} = \sum\limits_{i = 1}^l \alpha_i\varphi(x_i)\\ \dfrac{\partial L}{\partial b} = 0 \to \sum\limits_{i = 1}^l \alpha_i = 0 \\ \dfrac{\partial L}{\partial e_i} = 0 \to \alpha_i = \gamma_{e_i}\\ \dfrac{\partial L}{\partial a_i} = 0 \to w^ {\rm{T}}\cdot\varphi(x_i)+b+e_i-y_i = 0\\ \end{cases} \end{equation} $$ (11) 对于$ {i = 1, \cdots, l} $, 消去$ {w} $和$ {e} $, 得到如下线性方程:
$$ \begin{equation} \left[ {\begin{array}{*{20}{c}} {0}&{{\bf{\mathord{\buildrel{\lower3pt\hbox{$ \rightharpoonup$}} \over 1} }}^ {\rm{T}}} \\ {\bf{\mathord{\buildrel{\lower3pt\hbox{$ \rightharpoonup$}} \over 1} }} &{ZZ^ {\rm{T}}+{\gamma^{-1}}I} \\ \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{b}}\\ {{ \alpha}}\\ \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {0}\\ {y}\\ \end{array}} \right] \end{equation} $$ (12) 其中, $ {\bf{\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\rightharpoonup$}} \over 1} }} = [1\cdots1]^ {\rm{T}} $, $ {a = [\alpha_1, \cdots, \alpha_l]^ {\rm{T}}} $, $ {y = [y_1, \cdots, y_l]^ {\rm{T}}} $, $ {Z = [\varphi(x_1), \cdots, \varphi(x_l)]^ {\rm{T}}} $, 令 $ {K(x, x_i) = \varphi(x)^ {\rm{T}}\varphi(x_i)} $, 根据核函数方法, 引入$ {n\times n} $的高斯径向基函数为核函数:
$$ \begin{equation} K(x_i, x_k) = {\rm{exp}}(-\frac{\|x_i-x_k\|}{2\sigma^2}) \end{equation} $$ (13) 则采用支持向量机进行预测的输出为:
$$ \begin{equation} y(x) = \sum\limits_{i = 1}^l a_iK(x, x_i)+b \end{equation} $$ (14) LS-SVM模型的参数$ {a, b} $由式(12)计算, 高斯核函数宽度$ {\sigma} $和误差惩罚系数$ {\gamma} $等由粒子群优化算法计算[27]:
$$ \begin{align} v_{i, d}(t+1) = &wv_{i, d}(t)+c_1r_1(P_{i, d}-x_{i, d}(t))+ \\& c_2r_2(P_{g, d}-x_{i, d}(t)) \end{align} $$ (15) $$ \begin{equation} x_{i, d}(t+1) = x_{i, d}(t)+v_{i, d}(t+1) \end{equation} $$ (16) 其中, $ {x_{i, d}} $, $ {v_{i, d}} $, $ {P_{i, d}} $, $ {P_{g, d}} $分别表示粒子当前位置、当前速度、当前最佳位置和粒子的最佳位置. $ {\beta} $ 称为内部系数, 为[0, 1]间常量; $ {c_1} $和$ {c_2} $为学习速率; $ {r_1} $和$ {r_2} $为[0, 1]随机系数. $ v_{id}\in[-v_{ \rm{max}}, v_{ \rm{max}}], {v_{ \rm{max}}}$ 为最大速率.
3.2 基于模糊推理的流量智能补偿模型
稀土萃取生产过程中, 工作人员根据组分含量的变化量及变化率对当前的流量预设定值进行补偿, 使稀土元素组分含量满足生产指标.工作人员调节药剂量完全依赖于其经验知识, 且调节量是估计值.相比其他智能模型, 模糊推理是以模糊系统理论为基础、专家经验和领域知识为决策依据, 把定性模型转化成定量模型, 且不需要依据萃取机理建立关系模型.因此, 本节采用模糊推理建立萃取量和洗涤量补偿模型.该模型根据稀土元素组分含量软测量值, 补偿萃取量和洗涤量设定值.
通过第3.1节得到的组分含量 ${Y_{B}(k-1)}$ , ${Y_{A}(k-1)} $与目标组分含量$ {P_{B, 1}} $, $ {P_{A, n+m}} $比较, 得到其偏差$ e_s = Y_A(k-1)-P_{A, n+m} $, $ e_w = Y_B(k-1)-P_{B, 1} $及其偏差的变化$ \triangle e_s = Y_A(k-1)-Y_A(k-2) $, $ \triangle e_w = Y_B(k-1)-Y_B(k-2) $作为模糊系统的输入量, 萃取剂和洗涤剂的补偿增量$ {\triangle v_s} $和$ {\triangle v_w} $作为模糊推理系统的输出量.
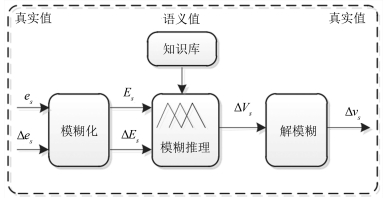
基于模糊推理的智能补偿器如图 4所示, 主要包括模糊化/解模糊部分、模糊推理、知识库等; 知识库包括输入输出变量的比例(尺度)因子、隶属度函数和模糊语义控制规则.通常, 萃取剂流量模糊控制器的输入与输出之间的关系可表示为[28-29]:
$$ \begin{equation} \triangle v_s(k) = f(e_s(k), \triangle e_s(k)|\psi) \end{equation} $$ (17) 其中, $ {f(\cdot|\psi)} $表示参数为$ {\psi} $ (如隶属度函数和模糊语义控制规则等)的模糊函数.假定萃取剂补偿量为$ {\triangle v_s(k)} $, 洗涤剂补偿量为$ {\triangle v_w(k)} $, 水相出口分数为$ {f_b'} $, 根据萃取机理模型[30], 可推导出下列公式:
$$ \begin{equation} \triangle v_w(k) = \triangle v_s(k)+f_b' \end{equation} $$ (18) 一般情况只需要模糊推理萃取剂或洗涤剂补偿量即可.
式(17)所示的模糊补偿器需要确定模糊逻辑控制器的参数向量$ {\psi} $, 该参数向量包括模糊化方法、模糊推理方法、解模糊方法和知识库等.由于参数向量$ {\psi} $里面的参数相互作用影响输出控制量, 所以实际工业过程的模糊控制器要满足控制性能并非容易得到, 需要大量的时间和精力调整设计参数.基于模糊系统理论, 参数$ {\psi} $可写成[31]:
$$ \begin{equation} \psi = [k_h, k_g, k_u;a_h, b_h, c_h;a_g, b_g, c_g;a_u, b_u, c_u] \end{equation} $$ (19) 其中, $ {k} $表示模糊控制的比例(尺度)因子, $ {a} $、$ {b} $和$ {c} $表示三角形隶属度函数的参数集, 下标$ {h} $、$ {g} $和$ {u} $分别表示组分含量误差、组分含量变化差和萃取量.
为实现对萃取量和洗涤量预设定值的补偿, 组分含量误差和组分含量变化差须模糊化成语义输入量, 经模糊推理得到的语义输出量须解模糊成实际补偿萃取量和洗涤量.假定组分含量误差的论域$ {e_s} $为$ [-e_{ \rm{smax}}, e_{ \rm{smax}}]$, 组分含量变化差$ {\triangle e_s} $的论域为 $ [-\triangle e_{ \rm{smax}}, \triangle e_{ \rm{smax}}]$, 补偿萃取量$ {\triangle v_s} $的论域为$ [-\triangle e_{ \rm{wmax}}, \triangle e_{ \rm{wmax}}]$. 语义变量 $ {E_s} $的论域为$ {-n, \cdots, 0, \cdots, n} $;语义变量$ {\triangle E_s} $的论域为$ {-m, \cdots, 0, \cdots, m-1, m} $; 语义变量$ {\triangle V_s} $ 的论域为$ {-l, \cdots, 0, \cdots, l-1, l} $ .因此, 比例因子表示为:
$$ \begin{equation} k_g = \frac{n}{e_{ \rm{smax}}}, k_h = \frac{m}{\triangle e_{ \rm{smax}}}, k_u = \frac{\triangle v_{ \rm{smax}}}{l} \end{equation} $$ (20) $ {E_s} $和$ {\triangle E_s} $的论域定义七个模糊集为: "NB", "NM", "NS", "ZE", "PS", "PM", "PB". $ {\triangle V_s} $的论域定义七个模糊集为: "NL", "NB", "NM", "NS", "ZE ", "PS ", "PM ", "PB ", "PL".正如图 5(a)所示, 三角形隶属度函数主要有三个顶点参数$ {a} $、$ {b} $、$ {c} $确定.当两个相邻的隶属度函数确定后, 其交点$ {\lambda} $即确定.在一般情况下, 交点$ {\lambda} $ 应该位于两个隶属度函数中心位置, 能够对输入量快速响应及输入量小范围内变化精确响应.组分含量误差、组分含量变化差和萃取剂补偿量的隶属度函数如图 5(b)、5(c)和(d)所示.
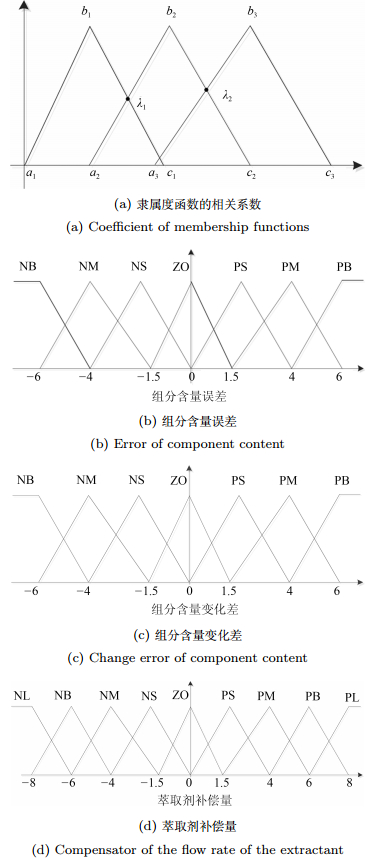 图 5 组分含量误差、组分含量变化差和萃取剂补偿量的隶属度函数Fig. 5 Membership functions of component content, change error of component content and compensator of the flow rate of the extractant
图 5 组分含量误差、组分含量变化差和萃取剂补偿量的隶属度函数Fig. 5 Membership functions of component content, change error of component content and compensator of the flow rate of the extractant根据专家经验和领域知识, 模糊规则表如表 1所示, 利用下面的语义控制规则构建模糊规则:
表 1 语义规则表Table 1 Semantic rules tableNB NM NS ZO PS PM PB \hline NB PL PL PB PM PM PS ZO NM PL PB PM PS PS ZO NS NS PB PM PS PS ZO NS NM ZO PM PM PS ZO NS NM NM PS PM PS ZO NS NS NM NB PM PS ZO NS NS NM NB NL PB ZO NS NM NM NB NL NL $ {R_i} $:如果$ {E_s} $为$ {\Gamma_i(E_s)} $和$ {\triangle E_s} $为$ {\Gamma_i(\triangle E_s)} $则$ {\triangle V_s} $为 $ {\Gamma_i(\triangle V_s)} $.
其中, $ {R_i} $表示$ {{\rm if}\cdots {\rm then}\cdots} $规则, $ \Gamma_i(\cdot)\in $ $ \{{\rm NL, NB, NM, NS, ZO, PS, PM, PB, PL}\} $. $ {NL} $、$ {NB} $等代码为模糊简写符号. $ {E_s} $、$ {\triangle E_s} $ 和$ {\triangle V_s} $ 分别表示组分含量误差、组分含量变化差和萃取量.
由于模糊推理的输出结果为一模糊集, 反映了模糊语义输出变量论域各元素隶属度大小的组合, 为了能够得到萃取剂补偿量的精确答案, 使用重心法解模糊:
$$ \begin{equation} \triangle v_s = \frac{\sum\limits_{i = 1}^n(\Gamma_i(\triangle v_s)\cdot\mu_v(\triangle v_s))}{\sum\limits_{i = 1}^n\mu_v(\triangle v_s)} \end{equation} $$ (21) 其中, $ {n} $指输出论域元素的总数, $ {\Gamma_i(\triangle v_s)} $表示输出论域的元素, 权系数$ {\mu_v(\triangle v_s)} $表示相应的隶属度函数.需要注意的是, $ {\triangle v_s} $需要乘以比例因子$ {k_u} $才能施加于预设定值.
4. 试验结果与分析
为了验证基于LS-SVM的组分含量软测量模型, 以某公司CePr/Nd萃取分离生产过程为对象, 在CePr/Nd萃取生产现场采集350份混合溶液样品, 287份作为训练样本, 63 份作为测试样本.溶液样本经机器视觉和化验两个基本预处理过程, 其提取出混合溶液图像的H、S颜色特征分量一阶矩作为软测量模型的输入变量, 化验后的CePr/Nd组分含量作为模型的输出变量.为了消除变量间由于数量级差异带来的影响, 将输入/输出样本组成的数据集进行归一化处理.在案例推理模型中, 案例阈值设为0.93, $ {\triangle_i} $设为2, 遗忘因子$ {\beta} $设为0.1, $ {\varsigma} $设为2.其案例推理权重属性通过学习策略计算分别为{0.12, 0.11, 0.21, 0.21, 0.11, 0.12, 0.12}. 在LS-SVM 模型中, 通过粒子群优化算法确定核宽度$ {\sigma} $ 为10.37, 惩罚系数(核参数) $ {\gamma} $为0.53, 287组样本数据集训练LS-SVM 模型, 利用63 组测试样本在已经训练好的模型上进行测试, 并与人工化验得到的63组样本所对应的组分含量化验值进行对比分析, 结果如图 6所示.结果表明该软测量模型基本满足要求, 为了说明该方法的有效性, 与RBF、SVM方法比较, 采用均方根误差(反映测量数据偏离真实值的程度)和均方差(反映一个数据集的离散程度)作为评价指标, 计算公式分别为: $ {{\rm RMSE} = \sqrt{\frac{1}{n}\sum\nolimits_{i = 1}^n(\hat{y_i}-y_i)^2}} $ 和 $ {{\rm MSE} = \sqrt{\frac{1}{n}\sum\nolimits_{i = 1}^n(y_i-\bar{y})^2}} $. 结果如表 2所示.本文采用的LS-SVM相比较于RBF和SVM方法效果更好.
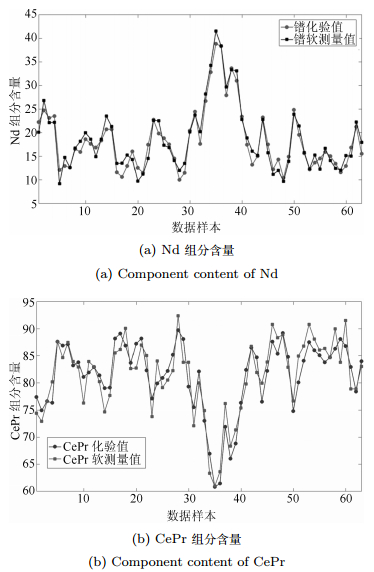 图 6 基于溶液颜色的组分含量软测量与化验值比较Fig. 6 Component content by soft sensing based on color feature of rare earth solution and lab test表 2 不同方法建模结果的性能比较Table 2 Performance comparison of different models
图 6 基于溶液颜色的组分含量软测量与化验值比较Fig. 6 Component content by soft sensing based on color feature of rare earth solution and lab test表 2 不同方法建模结果的性能比较Table 2 Performance comparison of different modelsNd (%) CePr (%) $ {\rm Method} $ $ {\rm RMSE} $ $ {\rm MSE} $ $ {\rm RMSE} $ $ {\rm MSE} $ $ {\rm RBF} $ 0.5829 0.623 0.6243 0.6109 $ {\rm SVM} $ 0.6021 0.528 0.5820 0.652 $ {\rm LSSVM} $ 0.5012 0.4891 0.5391 0.509 模糊药剂量补偿模块主要确定特征参数$ {\psi} $的值, 即$ \psi = [k_h, k_g, k_u; a_h, b_h, c_h; a_g, b_g, c_g; $ $ a_u, b_u, c_u] $.根据工艺试验, Nd组分含量误差的论域为$ [-3, 3] $, 其预定值为0, 因此$ \triangle h $的论域为 $ [-3, 3] $, 则$ {k_h = 3/6 = 0.5} $. Nd组分含量变化率的论域为$ [-0.18, 0.18], $其预定值为0, 因此$ {\triangle g} $的论域为$ [-0.18, 0.18] $, 则$ {k_g = 0.18/6 = 0.03} $.萃取量范围为 [3ml/min, 5ml/min] 且其预定值为4ml/min, 则$ {\triangle u} $的论域[$ -\rm{ml}/min, 1ml/min]$, 则$ {k_u = 8/1 = 8} $. $ {\triangle h} $, $ {\triangle g} $和$ {\triangle u} $隶属度函数的特征参数如表 3所示.工业现场工艺实验可知水出口分数$ {f_b' = 0.9298} $.
表 3 使用特征参数的隶属度函数Table 3 Membership functions of the fuzzy logic controller using characteristic parametersNd组分含量误差 Nd组分含量变化率 萃取补偿量 NO. $ {a_h} $ $ {b_h} $ $ {c_h} $ $ {a_g} $ $ {b_g} $ $ {c_g} $ $ {a_u} $ $ {b_u} $ $ {c_u} $ 1 -8 -6 -4 -8 -6 -4 -10 -8 -6 2 -6 -4 -1.5 -6 -4 -1.5 -8 -6 -4 3 -4 -1.5 0 -4 -1.5 0 -6 -4 -1.5 4 -1.5 0 1.5 -1.5 0 1.5 -1.5 0 1.5 5 0 1.5 4 0 1.5 4 -4 -1.5 0 6 1.5 4 6 1.5 4 6 0 1.5 4 7 4 6 8 4 6 8 1, 5 4 6 8 $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ 4 6 8 9 $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ $ {\times} $ 6 8 10 采用人工方法、单独采用案例推理预设定模型与本文方法的控制效果相比较如何?为此, 结合图 1所示的铈镨/钕稀土萃取过程, 将图 2所提出的本文方法与人工设定方法、基于案例推理的单模型方法进行对比试验.三组萃取工艺生产流程来自于同一料液, 一组生产流程采用本文的智能设定方法; 另一组萃取生产流程采用人工设定方法; 第三组采用基于案例推理的单模型设定方法.三组萃取生产过程的料液相同, 萃取生产过程条件相同.每隔2小时记录萃取量和洗涤量、图像分析的组分含量及其对应的离线化验的组分含量, 各得到60组运行数据, 统计结果如图 7所示.由于图像采集安装在萃取段第20级, 在该级萃取槽中镨的组分含量应该在[26, 30]范围内, CePr的组分含量在[70, 74]范围内.
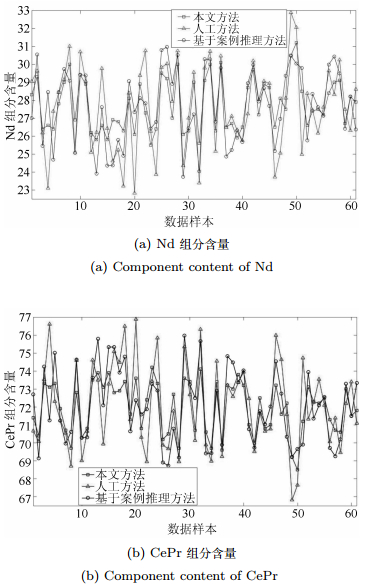 图 7 人工方法、单模型方法与本文方法的组分含量Fig. 7 Component content obtained by manual method、CBR based method and the proposed method
图 7 人工方法、单模型方法与本文方法的组分含量Fig. 7 Component content obtained by manual method、CBR based method and the proposed method图 7方法1采用本文提出智能设定方法对其设定, 方法2表示人工方法设定, 方法3表示仅采用基于案例推理的单模型设定方法进行设定.图 8为三种方法的药剂量变化情况.图 7和图 8反映了组分含量的变化及相应的萃取剂和洗涤剂流量变化情况.在61个样本点里, 当组分含量变化时, 其对应的萃取剂和洗涤剂流量也就相应地变化, 并反映到了下一个组分含量上面.由图 7可看出, 方法2的人工调节随意性较大, 调节时喜欢采用一步到位法, 导致组分含量波动较大.方法3的组分含量波动较大, 并且不满足要求的数据点较多, 其原因在于通过案例推理模型计算萃取量, 但没有利用反馈补偿机制.采用方法1的组分含量波动较小, 满足要求的数据点较多.通过计算, 单独采用预设定模型时精矿品位合格率为73.78%, 采用人工方法的合格率为75.4%, 而采用本文方法时的合格率为83.5%.这说明经过智能动态补偿模型的补偿作用, 所提方法克服了工况变化带来的扰动, 弥补了人工方法、基于案例推理的单模型设定方法的不足.
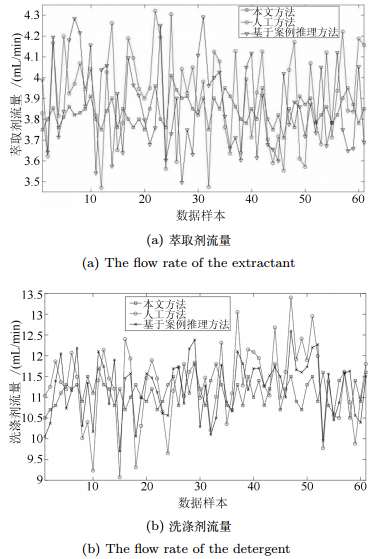 图 8 人工方法、案例推理方法与本文方法的萃取量Fig. 8 Flow rate of the extractant and the detergent consumed by manual method、CBR based method and the proposed method
图 8 人工方法、案例推理方法与本文方法的萃取量Fig. 8 Flow rate of the extractant and the detergent consumed by manual method、CBR based method and the proposed method在稀土萃取工业生产领域, 除了生产指标, 萃取量和洗涤量消耗也是萃取生产厂家最为关注的指标之一, 与工厂绩效密切相关.为评估本文方法的有效性, 比较人工设定、单模型方法及智能优化设定的生产指标和萃取量和洗涤量消耗量等.图 8显示本文方法的萃取量和洗涤量波动比另外两种方法要小, 说明药剂量控制相对比较平缓; 而且, 如表 4所示, 本文方法的萃取量和洗涤量消耗比另外两种方法要少.结果表明, 比起另外两种方法, 本文方法的三个模型为紧密联系的有机整体, 能够实现更好的萃取剂和洗涤剂流量控制, 并达到了降低药剂量消耗的目的.
表 4 萃取量和洗涤量消耗统计表(升)Table 4 Sum of the extractant and detergent comsumend by three methods (L)人工方法 案例推理方法 本文方法 洗涤量 82.67 82.29 81.54 萃取量 28.63 28.26 27.54 5. 结论
萃取生产过程具有机理复杂、非线性、时滞大等特点, 难以建立精确的萃取量和洗涤量优化控制模型, 当前稀土生产企业采用主观性强的人工设定方式, 易造成工艺指标波动较大.本文根据稀土溶液颜色与组分含量密切相关的特点, 提出了一种基于案例推理静态设定和机器视觉动态补偿的萃取量和洗涤量优化控制方法.首先根据案例推理确定萃取剂/洗涤剂预设定值, 然后根据软测量组分含量和目标组分含量的差值采用模糊推理方法智能补偿萃取量预设定值, 实现了萃取生产过程萃取溶液组分含量的优化控制, 试验表明该方法能够实现较好的生产指标及经济效益.
-
表 1 测试函数参数
Table 1 Paramter setting of the test function
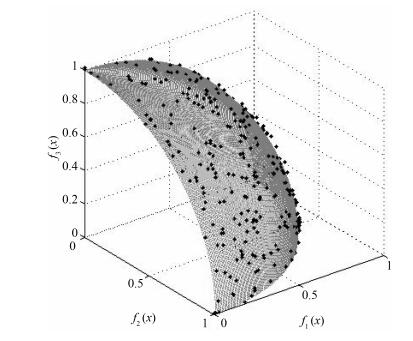
函数 pareto前沿特征 维度 种群规模 变量 目标 ZDT1 凸 30 2 1 000 ZDT2 凹 30 2 1 000 ZDT3 凸且非连续 30 2 536 ZDT4 凸 30 2 1 000 ZDT6 凹 10 2 420 DTLZ2 凹 10 3 5 000 DTLZ7 多峰且非连续 20 3 4 700  下载: 导出CSV
下载: 导出CSV
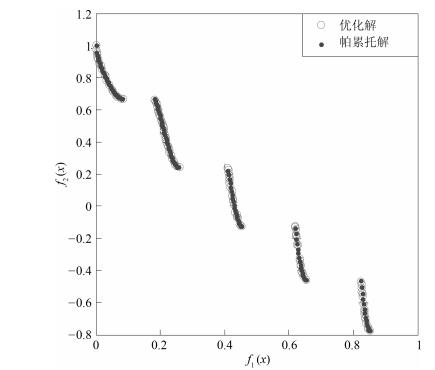
表 2 NSGAII-UID与其他局部搜索算法的ZDT和DTLZ系列实验IGD结果
Table 2 ZDT and DTLZ series performance IGD comparison of different algorithms
算法 NSGAII-UID NSGAII-DLS[13] NSGAII[18] AMOPSO[11] MODE[16] ZDT1 最大值 6.526E-03 9.728E-03 6.466E-03 6.153E-03 4.94E-02 最小值 2.528E-03 4.259E-03 5.367E-03 3.562E-03 4.04E-03 平均值 3.229E-03 6.427E-03 5.755E-03 4.009E-03 4.54E-03 标准差 6.700E-05 3.090E-04 3.390E-04 5.700E-05 2.58E-04 ZDT2 最大值 2.732E-03 7.036E-03 5.806E-03 2.493E-03 3.12E-02 最小值 1.126E-03 4.226E-03 5.134E-03 1.539E-03 3.79E-03 平均值 1.854E-03 5.026E-03 5.355E-03 1.983E-03 4.31E-04 标准差 4.970E-05 1.950E-04 2.020E-04 5.200E-05 2.64E-03 ZDT3 最大值 9.236E-03 9.123E-03 6.105E-03 9.160E-03 1.48E-02 最小值 2.526E-03 5.228E-03 5.447E-03 2.752E-03 3.01E-03 平均值 4.016E-03 6.326E-03 5.834E-03 3.982E-03 6.24E-03 标准差 3.623E-03 2.013E-04 2.020E-04 3.623E-03 7.13E-05 ZDT4 最大值 4.237E-03 4.659E-03 1.117E-01 5.845E-03 8.144E-02 最小值 9.926E-04 4.123E-03 4.623E-03 1.851E-03 3.145E-03 平均值 3.256E-03 4.326E-03 1.655E-02 4.147E-03 1.021E-02 标准差 3.160E-04 1.065E-02 3.174E-02 2.980E-04 2.145E-02 ZDT6 最大值 4.735E-03 5.321E-03 1.498E-02 2.110E-04 1.024E-02 最小值 8.669E-04 2.768E-03 1.119E-02 9.310E-05 6.119E-03 平均值 1.126E-03 3.412E-03 1.286E-02 1.754E-04 8.155E-03 标准差 1.075E-04 9.875E-04 1.004E-03 8.600E-05 4.121E-03 DTLZ2 最大值 2.065E-02 1.2334E-01 2.74E-01 9.991E-02 1.221E-01 最小值 8.431E-02 2.435E-02 7.831E-02 2.180E-02 6.152E-02 平均值 6.271E-02 1.026E-01 1.059E-01 6.595E-02 9.251E-02 标准差 6.241E-04 6.345E-03 8.383E-03 7.241E-04 9.251E-03 DTLZ7 最大值 1.015E-02 1.068E-02 3.208E-02 1.552E-02 4.97E-02 最小值 3.109E-03 3.259E-03 6.14E-03 6.055E-03 7.02E-03 平均值 1.206E-02 1.365E-02 1.799E-02 1.215E-02 2.87E-02 标准差 9.324E-04 1.013E-03 1.294E-03 8.600E-04 2.01E-03
下载: 导出CSV
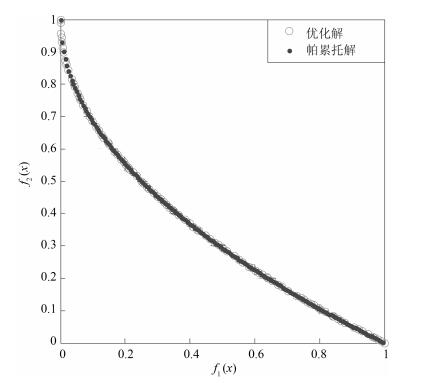
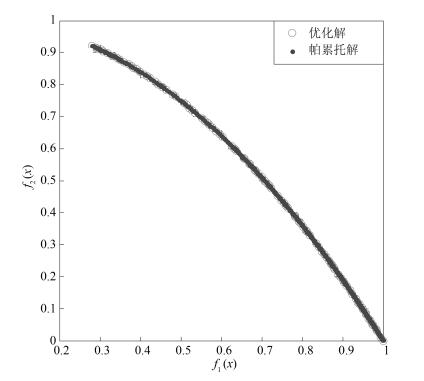
表 3 NSGAII-UID与其他局部搜索算法的ZDT和DTLZ系列实验SP结果
Table 3 ZDT series performance SP comparison of different algorithms
算法 NSGAII-UID NSGAII[18] AMOPSO[11] cdMOPSO[15] MODE[16] ZDT1 最大值 1.067E-02 7.538E-02 2.907E-02 1.023E-01 1.01E-01 最小值 8.687E-03 4.340E-02 1.512E-02 7.732E-02 4.06E-02 平均值 9.764E-03 5.830E-02 2.551E-02 8.561E-02 5.21E-02 标准差 5.712E-04 9.385E-03 6.710E-04 1.425E-02 1.43E-02 ZDT2 最大值 9.671E-03 8.287E-03 3.336E-02 2.377E-02 2.25E-02 最小值 7.248E-03 6.015E-03 1.999E-02 1.012E-02 1.01E-02 平均值 6.795E-03 7.241E-03 2.257E-02 1.097E-02 1.06E-02 标准差 7.918E-04 7.410E-04 3.245E-03 6.420E-04 4.02E-04 ZDT3 最大值 1.095E-01 1.066E-01 9.957E-02 8.745E-01 7.63E-01 最小值 7.264E-02 8.157E-02 6.489E-02 1.036E-01 1.40E-01 平均值 8.738E-02 9.222E-02 7.025E-02 3.568E-01 3.64E-01 标准差 8.276E-03 8.415E-03 7.171E-03 2.247E-01 2.14E-01 ZDT4 最大值 9.173E-03 4.425E-02 2.954E-02 3.010E-01 6.251E-02 最小值 7.968E-03 3.139E-02 2.130E-02 1.369E-01 3.103E-02 平均值 8.624E-03 3.838E-02 2.654E-02 2.046E-01 3.210E-02 标准差 6.5316E-04 3.837E-03 4.998E-04 9.556E-02 3.914E-3 ZDT6 最大值 8.734E-03 1.013E-02 4.742E-02 4.021E-02 1.214E-02 最小值 6.974E-03 6.851E-03 3.218E-02 1.240E-02 3.899E-03 平均值 7.598E-03 8.266E-03 3.651E-02 3.457E-02 9.145E-03 标准差 9.648E-04 9.180E-04 1.363E-03 3.884E-03 3.251E-04 DTLZ2 最大值 4.598E-02 7.314E-01 3.553E-01 5.897E-01 7.516E-01 最小值 8.431E-02 2.145E-02 7.569E-02 9.32E-02 3.145E-02 平均值 6.271E-02 4.162E-01 2.399E-01 3.562E-01 4.021E-01 标准差 8.381E-04 3.655E-02 9.732E-03 1.772E-02 4.215E-02 DTLZ7 最大值 6.983E-01 7.466E-01 7.564E-01 9.307E-01 9.31E-01 最小值 4.027E-02 6.32E-02 4.491E-02 1.347E-01 1.35E-01 平均值 9.921E-02 4.191E-01 3.758E-01 5.972E-01 5.97E-01 标准差 8.169E-03 7.961E-03 7.593E-03 2.133E-01 2.45E-01
下载: 导出CSV
表 4 NSGAII-UID与其他局部搜索算法的函数计算次数结果
Table 4 Function calculation comparison of different algorithms
下载: 导出CSV
-
[1] Schaffer J D. Multiple objective optimization with vector evaluated genetic algorithms. In: Proceedings of the 1st International Conference on Genetic Algorithms. Hillsdale, NJ, USA: L. Erlbaum Associates, Inc., 1985. 93-100 [2] Fonseca C M, Fleming P J. Genetic algorithms for multiobjective optimization: Formulation, discussion and generalization. In: Proceedings of the 5th International Conference. San Mateo, CA: Morgan Kauffman Publishers, 1993. 416-423 [3] Srinivas N, Deb K. Muiltiobjective optimization using nondominated sorting in genetic algorithms. Evolutionary Computation, 1994, 2(3):221-248 doi: 10.1162/evco.1994.2.3.221 [4] Deb K, Agrawal S, Pratap A, Meyarivan T. A fast elitist non-dominated sorting genetic algorithm for multi-objective optimization: NSGA-Ⅱ. In: Proceedings of the 6th International Conference on Parallel Problem Solving from Nature. Berlin, Heidelberg: Springer, 2000. 849-858 [5] Ahmadi A. Memory-based adaptive partitioning (MAP) of search space for the enhancement of convergence in Pareto-based multi-objective evolutionary algorithms. Applied Soft Computing, 2016, 41:400-417 doi: 10.1016/j.asoc.2016.01.029 [6] Goldberg D E, Richardson J. Genetic algorithms with sharing for multimodal function optimization. In: Proceedings of the 2nd International Conference on Genetic Algorithms. Hillsdale, NJ, USA: L. Erlbaum Associates, Inc., 1987. 41-49 [7] 朱学军, 陈彤, 薛量, 李峻.多个体参与交叉的Pareto多目标遗传算法.电子学报, 2001, 29(1):106-109 doi: 10.3321/j.issn:0372-2112.2001.01.029Zhu Xue-Jun, Chen Tong, Xue Liang, Li Jun. Pareto multiobjective genetic algorithm with multiple individual participation. Acta Electronica Sinica, 2001, 29(1):106-109 doi: 10.3321/j.issn:0372-2112.2001.01.029 [8] Corne D W, Knowles J D, Oates M J. The Pareto envelope-based selection algorithm for multiobjective optimization. In: Proceedings of the International Conference on Parallel Problem Solving from Nature. Berlin, Germany: Springer-Verlag, 2000. 839-848 [9] Knowles J, Corne D. Properties of an adaptive archiving algorithm for storing nondominated vectors. IEEE Transactions on Evolutionary Computation, 2003, 7(2):100-116 doi: 10.1109/TEVC.2003.810755 [10] Morse J N. Reducing the size of the nondominated set:pruning by clustering. Computers & Operations Research, 1980, 7(1-2):55-66 [11] Han H G, Lu W, Qiao J F. An adaptive multiobjective particle swarm optimization based on multiple adaptive methods. IEEE Transactions on Cybernetics, 2017, 47(9):2754-2767 doi: 10.1109/TCYB.2017.2692385 [12] 栗三一, 李文静, 乔俊飞.一种基于密度的局部搜索NSGA2算法.控制与决策, 2018, 33(1):60-66 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201801007Li San-Yi, Li Wen-Jing, Qiao Jun-Fei. A local search strategy based on density for NSGA2 algorithm. Control and Decision, 2018, 33(1):60-66 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201801007 [13] Sindhya K, Miettinen K, Deb K. A hybrid framework for evolutionary multi-objective optimization. IEEE Transactions on Evolutionary Computation, 2013, 17(4):495-511 doi: 10.1109/TEVC.2012.2204403 [14] Yang S X. Genetic algorithms with memory- and elitism-based immigrants in dynamic environments. Evolutionary Computation, 2008, 16(3):385-416 doi: 10.1162/evco.2008.16.3.385 [15] Helwig S, Branke J, Mostaghim S. Experimental analysis of bound handling techniques in particle swarm optimization. IEEE Transactions on Evolutionary Computation, 2013, 17(2):259-271 doi: 10.1109/TEVC.2012.2189404 [16] Basu M. Economic environmental dispatch using multi-objective differential evolution. Applied Soft Computing, 2011, 11(2):2845-2853 doi: 10.1016/j.asoc.2010.11.014 [17] Kim H, Liou M S. Adaptive directional local search strategy for hybrid evolutionary multiobjective optimization. Applied Soft Computing, 2014, 19:290-311 doi: 10.1016/j.asoc.2014.02.019 [18] Deb K, Pratap A, Agarwal S, Meyarivan T. A fast and elitist multiobjective genetic algorithm:NSGA-Ⅱ. IEEE Transactions on Evolutionary Computation, 2002, 6(2):182-197 doi: 10.1109/4235.996017 [19] Sindhya K, Miettinen K, Deb K. A hybrid framework for evolutionary multi-objective optimization. IEEE Transactions on Evolutionary Computation, 2013, 17(4):495-511 doi: 10.1109/TEVC.2012.2204403 期刊类型引用(6)
1. 邵雨晴,张红娟,高妍. 电动汽车混合储能系统双判据多模式功率分配策略. 现代电力. 2025(01): 176-182 .  百度学术
百度学术2. 李敏,李琤,鲁业安. 基于工况预测的两挡纯电动汽车换挡策略研究. 机械设计与制造. 2025(03): 18-22 . 百度学术3. 付主木,朱龙龙,陶发展,李梦杨. 基于Stackelberg博弈的燃料电池混合动力汽车跟车能量管理. 河南科技大学学报(自然科学版). 2024(04): 1-9+115 . 百度学术4. 付主木,龚慧贤,宋书中,陶发展,孙昊琛. 燃料电池电动汽车改进深度强化学习能量管理. 河南科技大学学报(自然科学版). 2023(04): 41-48+6 . 百度学术5. 申永鹏,袁小芳,赵素娜,孟步敏,王耀南. 智能网联电动汽车节能优化控制研究进展与展望. 自动化学报. 2023(12): 2437-2456 . 本站查看6. 万欣,荀径,WU Guoyuan,赵子枞. 基于MPC的混合动力汽车能量管理策略. 北京交通大学学报. 2022(05): 149-158 . 百度学术其他类型引用(10)
-

 下载:
下载:

计量
- 文章访问数: 2748
- HTML全文浏览量: 450
- PDF下载量: 509
- 被引次数: 16
