

An Improved Motion Intent Recognition Method for Intelligent Lower Limb Prosthesis Driven by Inertial Motion Capture Data
-
摘要: 为了解决传统意图识别方法使用多模态传感器信号所带来的复杂性以及识别转换模式一般具有滞后性等问题, 本文提出了基于惯性传感器的智能下肢假肢的运动意图实时识别方法.从模式识别的角度看, 在对象空间到模式空间的转换中, 对运动模式尤其是运动转换模式进行了重定义; 在模式采集中, 采用在患侧的运动模式进行转换之前, 采集绑定在健侧的传感器于摆动相前期所产生的时序运动数据, 选择均值、方差等特征统计量和支持向量机分类器对其进行特征选择提取与特征分类的策略, 实现对残疾人运动意图准确、实时地识别.实验结果表明, 本文所提出的方法可以识别出单肢截肢患者在不同地形下的运动意图, 包括平地行走、上楼、下楼、上坡、下坡5种稳态模式, 识别率可达到97.52 %, 并且加入在5种模式之间相互转换的转换模式之后, 识别率可达到95.12 %.本文方法可以极大提高智能下肢假肢的控制性能, 实现智能假肢能根据人的运动意图在多种运动模式之间进行自然、无缝的状态切换.Abstract: In order to overcome the drawbacks of conventional intention recognition methods, including complexities associated with multi-modal sensor signals and lags of transitional state recognition, this paper proposes a real-time motion intent recognition method for intelligent lower limb prosthesis base on inertial sensors. From the perspective of pattern recognition, the motion patterns, especially the motion transformation patterns, are redeflned in the transformation from object space to pattern space. In pattern acquisition, our strategy is that, prior to the movement mode conversion of lower limb prosthesis, motion time-series data generated by the sensors bound to the contralateral side during the early swing phase are collected, and the corresponding statistical features such as mean and variance are extracted. Feature classiflcation is performed by using a support vector machine classifler to achieve the accurate, real-time identiflcation for motion intent of the disabled movement with intelligent lower limb prosthesis. Our proposal is able to recognize various motion intents containing 5 steady states as well as 8 transitional states among the steady states on difierent terrains including level ground, stair ascent, stair descent, ramp ascent and ramp descent. Experimental results show the recognition accuracy can reach at 97.52 % and 95.12 % on those patterns from steady states and transitional states, respectively. The proposed method can greatly improve the control performance of intelligent lower limb prostheses, and can achieve the natural and seamless state switch of the intelligent prosthesis movement according to the intention of the human movement.
-
Key words:
- Motion intent recognition /
- inertial sensors /
- pattern space /
- transitional state /
- swing phase
1) 本文责任编委 陈积明 -
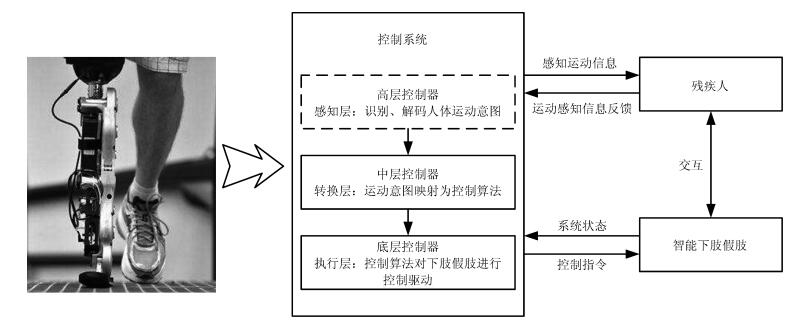
图 1 智能下肢假肢中的分层策略
Fig. 1 Hierarchical control strategy of robotic lower-limb prostheses
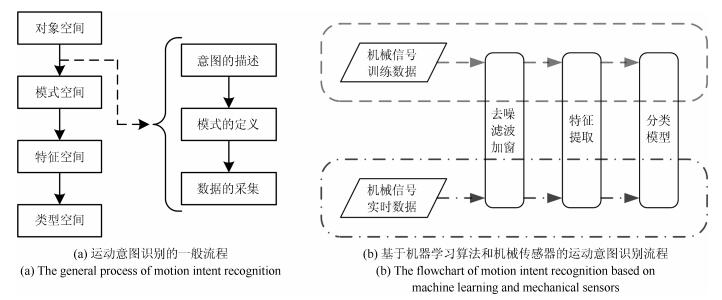
图 2 基于机械传感器的人体运动意图识别方法
Fig. 2 Method of motion intent recognition based on mechanical sensors
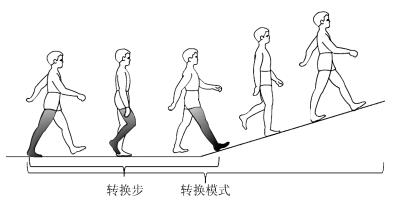
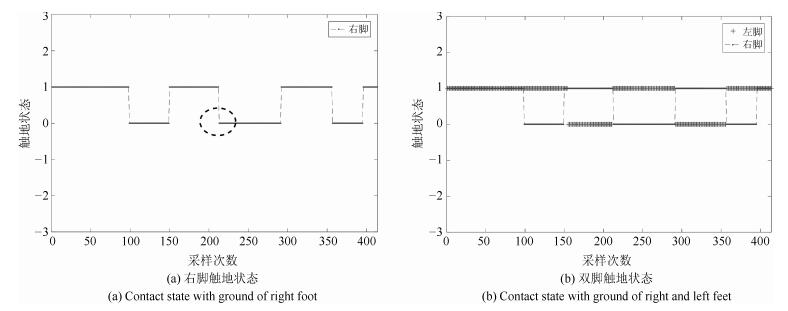
图 6 转换模式与转换步(平地行走—上坡)
Fig. 6 Transitional state and transitional step (level ground to up ramp)
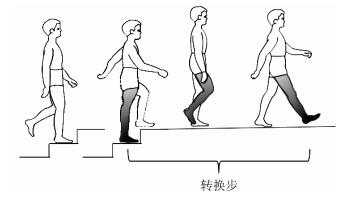
图 7 转换模式与转换步(上楼—平地行走)
Fig. 7 Transitional state and transitional step (up stair to level ground)
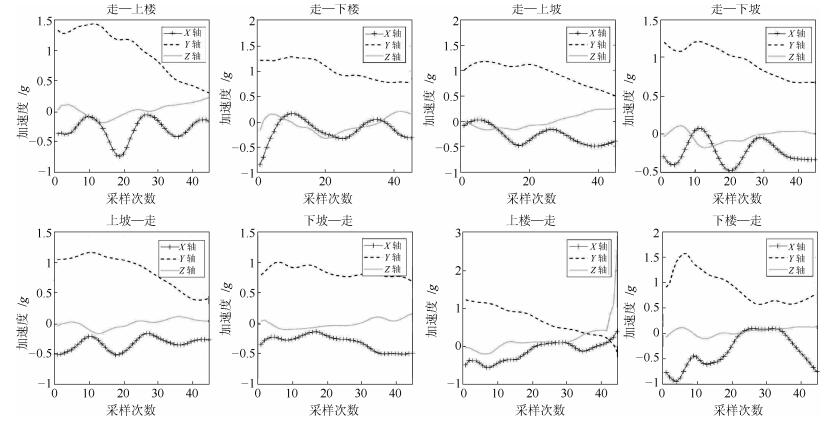
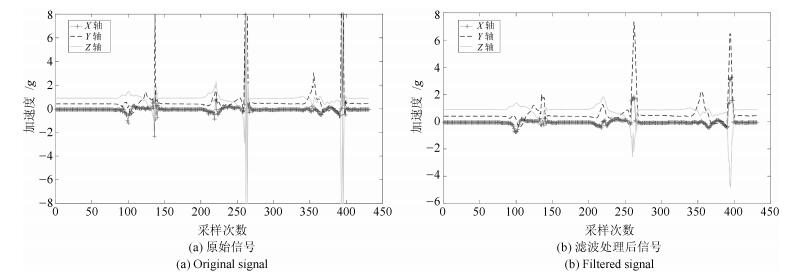
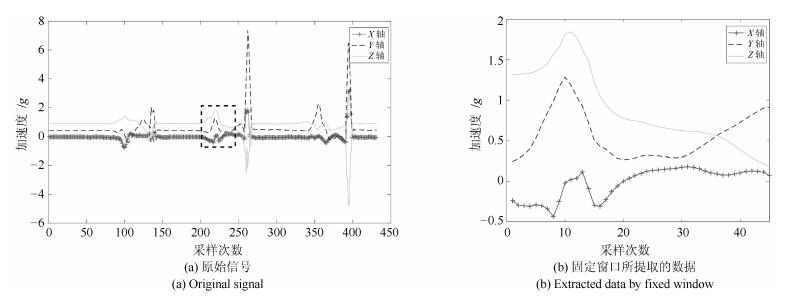
图 11 转换模式样本的加速度信号(大腿处传感器数据)
Fig. 11 Acceleration signals of transitional state (data of sensor placed on thigh)
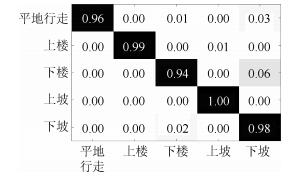
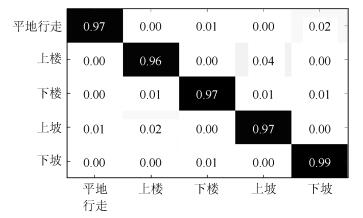
图 16 传感器置于患侧时5种稳态模式的混淆矩阵
Fig. 16 Confusion matrix of steady states when sensors placed at affected side
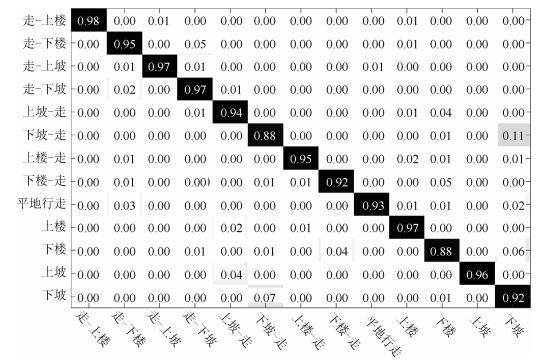
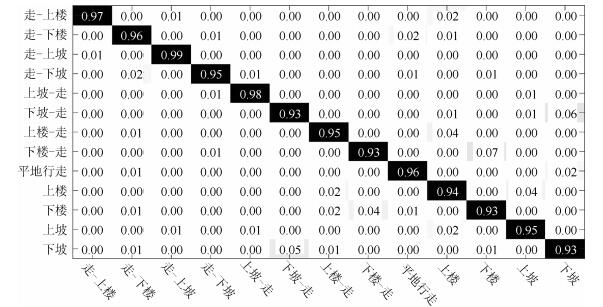
图 17 传感器置于患侧时13种运动模式的混淆矩阵
Fig. 17 Confusion matrix of 13 motion states classes when sensors placed at affected side
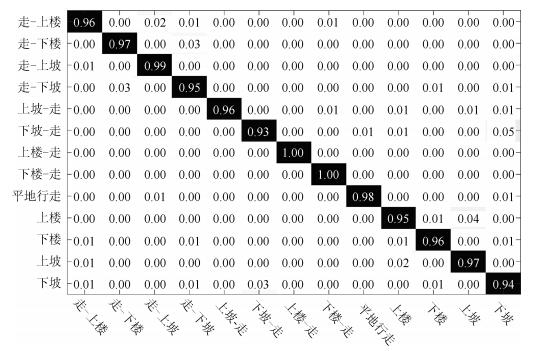
图 18 正常组13种运动模式的混淆矩阵
Fig. 18 Confusion matrix of 13 motion states classes with simulation of normal subjects
表 1 基于机械传感器的人体运动意图识别研究
Table 1 Research on motion intent recognition based on mechanical sensors
文献 机械传感器类型 机械信号特征 分类器 模式种类 识别精度 Liu等[10] (2017) 加速度计、陀螺仪、压力传感器 组内相关系数 HMM 5 95.8% Young等[11] (2014) 加速度计、陀螺仪、压力传感器 均值、标准差、最大值、最小值 LDA 13 93.9% Young等[12] (2014) 惯性测量单元、压力传感器等 均值、标准差、最大值、最小值 DBN 5 94.7% Zheng等[14] (2017) 加速度计、陀螺仪、压力传感器 均值、标准差、绝对值等 SVM+QDA 8 94.9% Young等[16] (2016) 惯性测量单元、压力传感器 均值、标准差、最大值、最小值 DBN 13 90.0% Chen等[17] (2015) 惯性测量单元、压力传感器 均值、标准差、最大值等 LDA+QDA 6 90.0%  下载: 导出CSV
下载: 导出CSV
表 2 13种不同运动模式
Table 2 13 classes of motion states
编号 行为模式 行为模式描述 1 走—上楼 平地行走到上楼转换 2 走—下楼 平地行走到下楼转换 3 走—上坡 平地行走到上坡转换 4 走—下坡 平地行走到下坡转换 5 上坡—走 上坡到平地行走转换 6 下坡—走 下坡到平地行走转换 7 上楼—走 上楼到平地行走转换 8 下楼—走 下楼到平地行走转换 9 行走 平地行走 10 上楼 稳步上台阶 11 下楼 稳步下台阶 12 上坡 稳步上坡 13 下坡 稳步下坡
下载: 导出CSV
表 3 运动模式及迈步顺序
Table 3 Motions and step sequence
运动模式 迈步顺序具体描述 5种稳态模式 健侧—模拟患侧—健侧—模拟患侧 走—上楼 健侧(平地行走)—模拟患侧(平地行走)—健侧(平地行走向上楼转换)—模拟患侧(平地行走向上楼转换) 走—下楼 健侧(平地行走)—模拟患侧(平地行走)—健侧(平地行走向下楼转换)—模拟患侧(平地行走向下楼转换) 走—上坡 健侧(平地行走)—模拟患侧(平地行走)—健侧(平地行走向上坡转换)—模拟患侧(平地行走向上坡转换) 走—下坡 健侧(平地行走)—模拟患侧(平地行走)—健侧(平地行走向下坡转换)—模拟患侧(平地行走向下坡转换) 上楼—走 模拟患侧(上楼)—健侧(上楼)—模拟患侧(上楼向平地行走转换)—健侧(上楼向平地行走转换) 下楼—走 模拟患侧(下楼)—健侧(下楼)—模拟患侧(下楼向平地行走转换)—健侧(下楼向平地行走转换) 上坡—走 健侧(上坡)—模拟患侧(上坡)—健侧(上坡向平地行走转换)—模拟患侧(上坡向平地行走转换) 下坡—走 健侧(下坡)—模拟患侧(下坡)—健侧(下坡向平地行走转换)—模拟患侧下坡向平地行走转换)
下载: 导出CSV
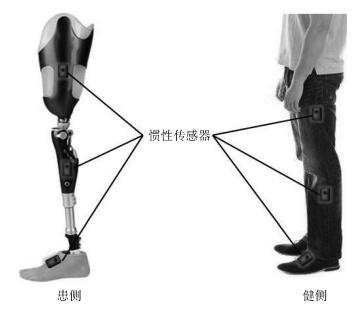
表 4 传感器置于患侧时的迈步顺序
Table 4 Step sequence of the situation where sensors placed at affected side
运动模式 迈步顺序具体描述 走—上楼 模拟患侧(平地行走)—健侧(平地行走)—模拟患侧(平地行走向上楼转换)—健侧(平地行走向上楼转换) 走—下楼 模拟患侧(平地行走)—健侧(平地行走)—模拟患侧(平地行走向下楼转换)—健侧(平地行走向下楼转换) 走—上坡 模拟患侧(平地行走)—健侧(平地行走)—模拟患侧(平地行走向上坡转换)—健侧(平地行走向上坡转换) 走—下坡 模拟患侧(平地行走)—健侧(平地行走)—模拟患侧(平地行走向下坡转换)—健侧(平地行走向下坡转换) 上楼—走 健侧(上楼)—模拟患侧(上楼)—健侧(上楼向平地行走转换)—模拟患侧(上楼向平地行走转换) 下楼—走 健侧(下楼)—模拟患侧(下楼)—健侧(下楼向平地行走转换)—模拟患侧(下楼向平地行走转换) 上坡—走 模拟患侧(上坡)—健侧(上坡)—模拟患侧(上坡向平地行走转换)—健侧(上坡向平地行走转换) 下坡—走 模拟患侧(下坡)—健侧(下坡)—模拟患侧(下坡向平地行走转换)—健侧(下坡向平地行走转换)
下载: 导出CSV
表 5 正常组的迈步顺序
Table 5 Step sequence of the situation with simulation of normal subjects
运动模式 迈步顺序具体描述 5种稳态模式 健侧(左)—健侧(右)—健侧(左)—健侧(右) 走—上楼左侧 (平地行走)—右侧(平地行走)—左侧(平地行走向上楼转换)—右侧(平地行走向上楼转换) 走—下楼左侧 (平地行走)—右侧(平地行走)—左侧(平地行走向下楼转换)—右侧(平地行走向下楼转换) 走—上坡左侧 (平地行走)—右侧(平地行走)—左侧(平地行走向上坡转换)—右侧(平地行走向上坡转换) 走—下坡左侧 (平地行走)—右侧(平地行走)—左侧(平地行走向下坡转换)—右侧(平地行走向下坡转换) 上楼—走右侧 (上楼)—左侧(上楼)—右侧(上楼向平地行走转换)—左侧(上楼向平地行走转换) 下楼—走右侧 (下楼)—左侧(下楼)—右侧(下楼向平地行走转换)—左侧(下楼向平地行走转换) 上坡—走左侧 (上坡)—右侧(上坡)—左侧(上坡向平地行走转换)—右侧(上坡向平地行走转换) 下坡—走左侧 (下坡)—右侧(下坡)—左侧(下坡向平地行走转换)—右侧(下坡向平地行走转换)
下载: 导出CSV
表 6 方法与实验结果对比
Table 6 Comparison of the methods and experimental results
文献 传感器类型/数量 传感器位置 机械信号特征 分类器 运动模式种类 识别精度 稳态 转换 Liu等[10] (2017) 1个加速度计、1个陀螺仪、2个压力传感器 患侧 组内相关系数 HMM 5 / 95.8% Young等[11] (2014) 3个加速度计、3个陀螺仪、1个压力传感器 患侧 均值、标准差、最大值、最小值 LDA 5 8 (下一模式已发生, 有滞后性) 93.9% Young等[12] (2014) 1个惯性测量单元、1个压力传感器等 患侧 均值、标准差、最大值、最小值 DBN 5 / 94.7% Zheng等[14] (2017) 2个加速度计、2个陀螺仪、1个压力传感器 患侧 均值、标准差、绝对值等 SVM+QDA / 8 (下一模式已发生, 有滞后性) 94.9% Young等[16] (2016) 1个惯性测量单元、1个压力传感器 患侧 均值、标准差、最大值、最小值 DBN 5 8 (下一模式已发生, 有滞后性) 90.0% Chen等[17] (2015) 2个惯性测量单元、1个压力传感器 患侧 均值、标准差、最大值等 LDA+QDA 6 / 90.0% 本文方法 3个惯性测量单元 健侧 均值、方差、 SVM 5 / 97.52% 最大值与最小值 5 8 (下一模式未发生, 无滞后性) 95.12%
下载: 导出CSV
-
[1] 中国残疾人联合会.第二次全国残疾人抽样调查主要数据公报. 2006 [2] 喻洪流, 关慎远, 钱省三, 赵展.膝上假肢的智能控制方法.中国康复医学杂志, 2008, 23(2): 145-147 doi: 10.3969/j.issn.1001-1242.2008.02.021 [3] 王启宁, 郑恩昊, 陈保君, 麦金耿.面向人机融合的智能动力下肢假肢研究现状与挑战.自动化学报, 2016, 42(12): 1780-1793 doi: 10.16383/j.aas.2016.y000007Wang Q N, Zheng E H, Chen B J, Mai J G. Recent progress and challenges of robotic lower-limb prostheses for humanrobot integration. Acta Automatica Sinica, 2016, 42(12): 1780-1793 doi: 10.16383/j.aas.2016.y000007 [4] Nazarpour K, Sharafat A R, Firoozabadi S M. Application of higher order statistics to surface electromyogram signal classiflcation. IEEE Transactions on Biomedical Engineering, 2007, 54(10): 1762-1769 doi: 10.1109/TBME.2007.894829 [5] 丁其川, 熊安斌, 赵新刚, 韩建达.基于表面肌电的运动意图识别方法研究及应用综述.自动化学报, 2016, 42(1): 13-25 doi: 10.16383/j.aas.2016.c140563Ding Qi-Chuan, Xiong An-Bin, Zhao Xin-Gang, Han JianDa. A review on researches and applications of sEMG-based motion intent recognition methods. Acta Automatica Sinica, 2016, 42(1): 13-25 doi: 10.16383/j.aas.2016.c140563 [6] Huang H, Kuiken T A, Lipschutz R D. A strategy for identifying locomotion modes using surface electromyography. IEEE Transactions on Biomedical Engineering, 2009, 56(1): 65-73 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=601e630258ef23b5e57afcbf6afa9beb [7] 佟丽娜, 侯增广, 彭亮, 王卫群, 陈翼雄, 谭民.基于多路sEMG时序分析的人体运动模式识别方法.自动化学报, 2014, 40(5): 810-821 doi: 10.3724/SP.J.1004.2014.00810Tong Li-Na, Hou Zeng-Guang, Peng Liang, Wang Wei-Qun, Chen Yi-Xiong, Tan Min. Multi-channel sEMG time series analysis based human motion recognition method. Acta Automatica Sinica, 2014, 40(5): 810-821 doi: 10.3724/SP.J.1004.2014.00810 [8] Hargrove L J, Simon A M, Lipschutz R, Finucane S B, Kuiken T A. Non-weight-bearing neural control of a powered transfemoral prosthesis. Journal of Neuro Engineering and Rehabilitation, 2013, 10(1), Article No. 62 [9] Young A J, Hargrove L J, Kuiken T A. Improving myoelectric pattern recognition robustness to electrode shift by changing interelectrode distance and electrode conflguration. IEEE Transactions on Biomedical Engineering, 2012, 59(3): 645-652 https://www.infona.pl/resource/bwmeta1.element.ieee-art-000006092466 [10] Liu Z J, Lin W, Geng Y L, Yang P. Intent pattern recognition of lower-limb motion based on mechanical sensors. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 651-660 doi: 10.1109/JAS.2017.7510619 [11] Young A J, Simon A M, Hargrove L J. A training method for locomotion mode prediction using powered lower limb prostheses. IEEE Transactions on Neural Systems & Rehabilitation Engineering, 2014, 22(3): 671-677 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=c2fbe368d73a6e8d9b87fdb13a9ce181 [12] Young A J, Simon A M, Fey N P, Hargrove L J. Intent recognition in a powered lower limb prosthesis using time history information. Annals of Biomedical Engineering, 2014, 42(3): 631-641 doi: 10.1007/s10439-013-0909-0 [13] Yuan K B, Wang Q N, Wang L. Fuzzy-logic-based terrain identiflcation with multisensor fusion for transtibial amputees. IEEE/ASME Transactions on Mechatronics, 2015, 20(2): 618-630 doi: 10.1109/TMECH.2014.2309708 [14] Zheng E H, Wang Q N. Noncontact capacitive sensing-based locomotion transition recognition for amputees with robotic transtibial prostheses. IEEE Transactions on Neural Systems & Rehabilitation Engineering, 2017, 25(2): 161-170 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f5b927bc507853addb3a694973e9bf93 [15] Preece S J, Goulermas J Y, Kenney L P, Howard D. A comparison of feature extraction methods for the classiflcation of dynamic activities from accelerometer data. IEEE Transactions on Biomedical Engineering, 2009, 56(3): 871-879 http://usir.salford.ac.uk/id/eprint/12578/6/2009_TBE_Comparison%20of%20feature%20extraction.pdf [16] Young A J, Hargrove L J. A classiflcation method for userindependent intent recognition for transfemoral amputees using powered lower limb prostheses. IEEE Transactions on Neural Systems & Rehabilitation Engineering, 2016, 24(2): 217-225 https://ieeexplore.ieee.org/document/7061495/ [17] Chen B J, Zheng E H, Wang Q N, Wang L. A new strategy for parameter optimization to improve phasedependent locomotion mode recognition. Neurocomputing, 2015, 149(B): 585-593 https://www.sciencedirect.com/science/article/abs/pii/S0925231214010303 [18] Su B Y, Tang Q F, Wang G J, Sheng M. The recognition of human daily actions with wearable motion sensor system. Transactions on Edutainment XII, 2016, 68-77 doi: 10.1007/978-3-662-50544-1_6 [19] 苏本跃, 蒋京, 汤庆丰, 盛敏.基于函数型数据分析方法的人体动态行为识别.自动化学报, 2017, 43(5): 866-876 doi: 10.16383/j.aas.2017.c160120Su Ben-Yue, Jiang Jing, Tang Qing-Feng, Sheng Min. Human dynamic action recognition based on functional data analysis. Acta Automatica Sinica, 2017, 43(5): 866-876 doi: 10.16383/j.aas.2017.c160120 [20] Su B Y, Jiang J, Tang Q F, Sheng M. Human periodic activity recognition based on functional features. In: Proceedings of SIGGRAPH ASIA 2016 Symposium on Education, 2016, Article 6 [21] Su B Y, Tang Q F, Jiang J, Sheng M, Yahya A A, Wang G J. A novel method for short-time human activity recognition based on improved template matching technique. In: Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry, 2016, 1: 233-242 [22] Sheng M, Jiang J, Su B Y, Yahya A A, Wang G J. Shorttime activity recognition with wearable sensors using convolutional neural network. In: Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry, 2016, 1: 413-416 [23] Au S K, Weber J, Herr H. Powered ankle foot prosthesis improves walking metabolic economy. IEEE Transactions on Robotics, 2009, 25(1): 51-66 http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ027911847/ [24] MATLAB中文论坛. MATLAB神经网络30个案例分析.北京: 北京航空航天出版社, 2010. 120-132MATLAB Chinese Forum. MATLAB neural network 30 case analysis. Beijing: Beijing University of Aeronautics and Astronautics Press, 2010. 120-132 -

 下载:
下载:


计量
- 文章访问数: 1965
- HTML全文浏览量: 416
- PDF下载量: 201
- 被引次数: 0
