

Monaural Speech Separation by Means of Convolutive Nonnegative Matrix Partial Co-factorization in Low SNR Condition
-
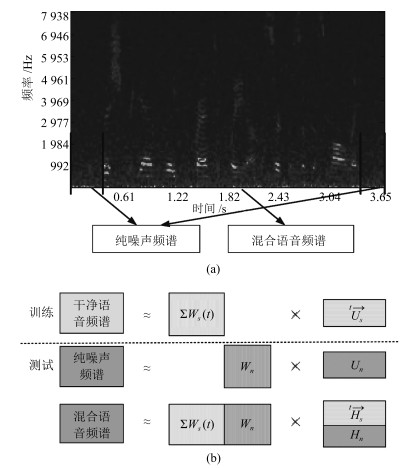
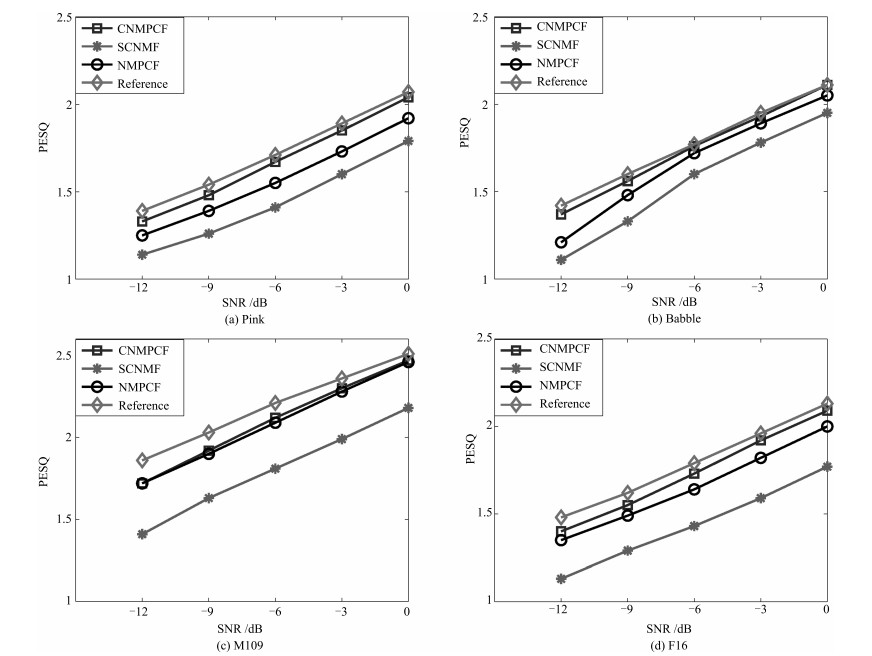
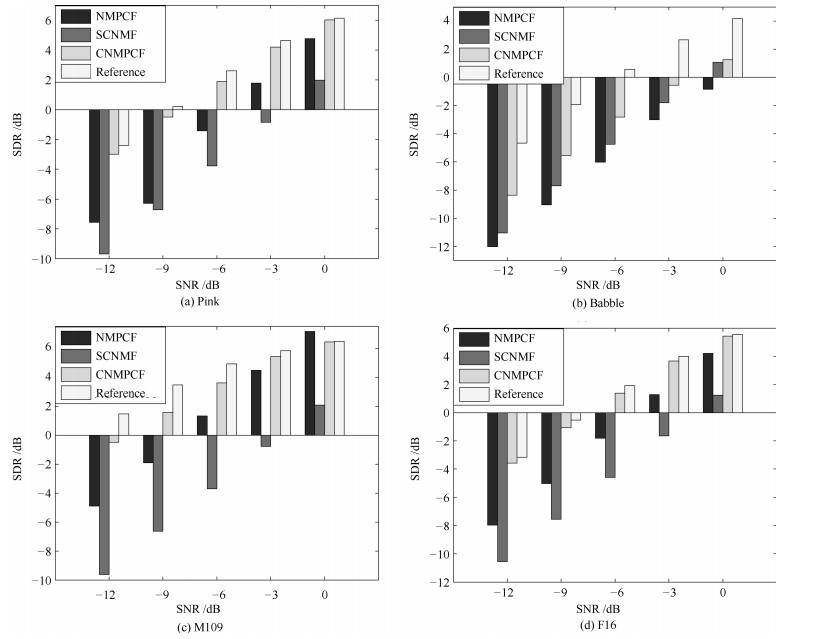
摘要: 非负矩阵部分联合分解(Nonnegative matrix partial co-factorization, NMPCF)将指定源频谱作为边信息参与混合信号频谱的联合分解, 以帮助确定指定源的基向量进而提高信号分离性能.卷积非负矩阵分解(Convolutive nonnegative matrix factorization, CNMF)采用卷积基分解的方法进行矩阵分解, 在单声道语音分离方面取得较好的效果.为了实现强噪声条件下的语音分离, 本文结合以上两种算法的优势, 提出一种基于卷积非负矩阵部分联合分解(Convolutive nonnegative partial matrix co-factorization, CNMPCF)的单声道语音分离算法.本算法首先通过基音检测算法得到混合信号的语音起始点, 再据此确定混合信号中的纯噪声段, 最后将混合信号频谱和噪声频谱进行卷积非负矩阵部分联合分解, 得到语音基矩阵, 进而得到分离的语音频谱和时域信号.实验中, 混合语音信噪比(Signal noise ratio, SNR)选择以-3 dB为间隔从0 dB至-12 dB共5种SNR.实验结果表明, 在不同噪声类型和噪声强度条件下, 本文提出的CNMPCF方法相比于以上两种方法均有不同程度的提高.
-
关键词:
- 卷积非负矩阵分解 /
- 非负矩阵部分联合分解 /
- 语音分离 /
- 强噪声 /
- 单声道
Abstract: Nonnegative matrix partial co-factorization (NMPCF) is a joint matrix decomposition algorithm integrating prior knowledge of specific source to help separate specific source signal from monaural mixtures. Convolutive nonnegative matrix factorization (CNMF), which introduces the concept of a convolutive non-negative basis set during NMF process, opens up an interesting avenue of research in the field of monaural sound separation. On the basis of the above two algorithms, we propose a speech separation algorithm named as convolutive nonnegative matrix partial co-factorization (CNMPCF) for low signal noise ratio (SNR) monaural speech. Firstly, through a voice detection process exploring fundamental frequency estimation algorithm, we divide a mixture signal into vocal and nonvocal parts, thus those vocal parts are used as test mixture signal while the nonvocal parts (pure noise) participat in the partial joint decomposition. After CNMPCF, we can obtain the separated speech spectrogram. Then, the separated speech signal can reconstructed through Inverse short time fourier transformation. In the experiments, we select 5 SNRs from 0 dB to -12 dB at -3 dB intervals to obtain low SNR mixture speeches. The results demonstrate that the proposed CNMPCF approach has superiority over sparse convolutive nonnegative matrix factorization (SCNMF) and NMPCF under different noise types and noise intensities.-
Key words:
- Convolutive nonnegative matrix factorization (CNMF) /
- nonnegative matrix partial co-factorization (NMPCF) /
- speech separation /
- strong noise /
- monaural speech
-
肺癌是世界范围内发病率和死亡率最高的疾病之一, 占所有癌症病发症的18 %左右[1].美国癌症社区统计显示, 80 %到85 %的肺癌为非小细胞肺癌[2].在该亚型中, 大多数病人会发生淋巴结转移, 在手术中需对转移的淋巴结进行清扫, 现阶段通常以穿刺活检的方式确定淋巴结的转移情况.因此, 以非侵入性的方式确定淋巴结的转移情况对临床治疗具有一定的指导意义[3-5].然而, 基本的诊断方法在无创淋巴结转移的预测上存在很大挑战.
影像组学是针对医学影像的兴起的热门方法, 指通过定量医学影像来描述肿瘤的异质性, 构造大量纹理图像特征, 对临床问题进行分析决策[6-7].利用先进机器学习方法实现的影像组学已经大大提高了肿瘤良恶性的预测准确性[8].研究表明, 通过客观定量的描述影像信息, 并结合临床经验, 对肿瘤进行术前预测及预后分析, 将对临床产生更好的指导价值[9].
本文采用影像组学的方法来解决非小细胞肺癌淋巴结转移预测的问题.通过利用套索逻辑斯特回归(Lasso logistics regression, LLR)[10]模型得出基本的非小细胞肺癌淋巴结的转移预测概率, 并把组学模型的预测概率作为独立的生物标志物, 与患者的临床特征一起构建多元Logistics预测模型并绘制个性化诺模图, 在临床决策中的起重要参考作用.
1. 材料和方法
1.1 病人数据
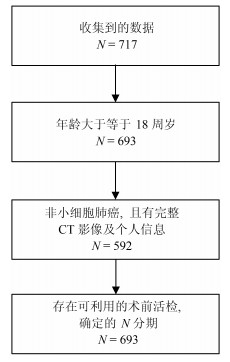
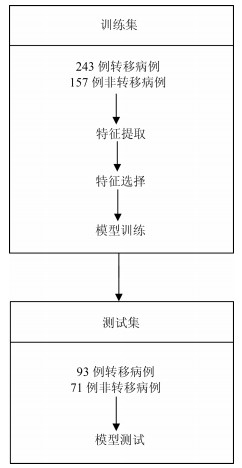
我们收集了广东省人民医院2007年5月至2014年6月期间的717例肺癌病例.这些病人在签署知情同意书后, 自愿提供自己的信息作为研究使用.为了充分利用收集到的数据对非小细胞肺癌淋巴结转移预测, 即对$N1-N3$与$N0$进行有效区分, 我们对收集的数据设置了三个入组标准: 1)年龄大于等于18周岁, 此时的肺部已经发育完全, 消除一定的干扰因素; 2)病理诊断为非小细胞肺癌无其他疾病干扰, 并有完整的CT (Computed tomography)增强图像及个人基本信息; 3)有可利用的术前病理组织活检分级用于确定N分期.经筛选, 共564例病例符合进行肺癌淋巴结转移预测研究的要求(如图 1).
为了得到有价值的结果, 考虑到数据的分配问题, 为了保证客观性, 防止挑数据的现象出现, 在数据分配上, 训练集与测试集将按照时间进行划分, 并以2013年1月为划分点.得到训练集: 400例, 其中, 243例正样本$N1-N3$, 157例负样本$N0$; 测试集: 164例, 其中, 93例正样本, 71例负样本.
1.2 病灶分割
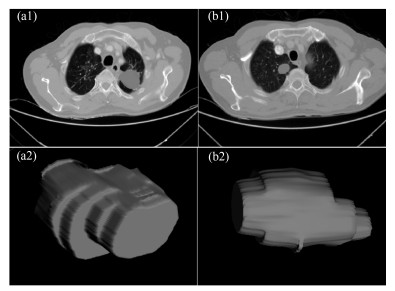
在进行特征提取工作前, 首先要对肿瘤病灶进行分割.医学图像分割的金标准是需要有经验的医生进行手动勾画的结果.但手动分割无法保证每次的分割结果完全一致, 且耗时耗力, 尤其是在数据量很大的情况下.因此, 手动分割不是最理想的做法.在本文中, 使用的自动图像分割算法为基于雪橇的自动区域生长分割算法[11], 该算法首先选定最大切片层的种子点, 这时一般情况下最大切片为中间层的切片, 然后估计肿瘤的大小即直径, 作为一个输入参数, 再自动进行区域生长得到每个切片的肿瘤如图 2(a1), (b1), 之后我们进行雪橇滑动到邻接的上下两个切面, 进行分割, 这样重复上述的区域生长即滑动切片, 最终分割得到多个切片的的肿瘤区域, 我们将肿瘤切面层进行组合, 得到三维肿瘤如图 2(a2), (b2).
1.3 特征的提取与筛选
利用影像组学处理方法, 从分割得到的肿瘤区域中总共提取出386个特征.这些特征可分为四组:三维形状特征, 表面纹理特征, Gabor特征和小波特征[12-13].形状特征通过肿瘤体积、表面积、体积面积比等特征描述肿瘤在空间和平面上的信息.纹理特征通过统计三维不同方向上像素的规律, 通过不同的分布规律来表示肿瘤的异质性. Gabor特征指根据特定方向, 特定尺度筛选出来的纹理信息.
小波特征是指原图像经过小波变换滤波器后的纹理特征.在模式识别范畴中, 高维特征会增加计算复杂度, 此外, 高维的特征往往存在冗余性, 容易造成模型过拟合.因此, 本位通过特征筛选方法首先对所有特征进行降维处理.
本文采用$L$1正则化Lasso进行特征筛选, 对于简单线性回归模型定义为:
$$ \begin{equation} f(x)=\sum\limits_{j=1}^p {w^jx^j} =w^\mathrm{T}x \end{equation} $$ (1) 其中, $x$表示样本, $w$表示要拟合的参数, $p$表示特征的维数.
要进行参数$w$学习, 应用二次损失来表示目标函数, 即:
$$ \begin{equation} J(w)=\frac{1}{n}\sum\limits_{i=1}^n{(y_i-f(x_i)})^2= \frac{1}{n}\vert\vert\ {{y}-Xw\vert\vert}^2 \end{equation} $$ (2) 其中, $X$是数据矩阵, $X=(x_1 , \cdots, x_n)^\mathrm{T}\in {\bf R}^{n\times p}$, ${y}$是由标签组成的列向量, ${y}=(y_1, \cdots, y_n )^\mathrm{T}$.
式(2)的解析解为:
$$ \begin{equation} \hat{w}=(X^\mathrm{T}X)^{-1}X^\mathrm{T}{y} \end{equation} $$ (3) 然而, 若$p\gg n$, 即特征维数远远大于数据个数, 矩阵$X^\mathrm{T}X$将不是满秩的, 此时无解.
通过Lasso正则化, 得到目标函数:
$$ \begin{equation} J_L(w)=\frac{1}{n} \vert\vert{y}-Xw\vert\vert^2+\lambda\vert\vert w\vert\vert _1 \end{equation} $$ (4) 目标函数最小化等价为:
$$ \begin{equation} \mathop {\min }\limits_w \frac{1}{n} \vert\vert{y}-Xw\vert\vert^2, \, \, \, \, \, \, \, \mathrm{s.t.}\, \, \vert \vert w\vert \vert _1 \le C \end{equation} $$ (5) 为了使部分特征排除, 本文采用$L$1正则方法进行压缩.二维情况下, 在$\mbox{(}w^1, w^2)$平面上可画出目标函数的等高线, 取值范围则为平面上半径为$C$的$L$1范数圆, 等高线与$L$1范数圆的交点为最优解. $L$1范数圆和每个坐标轴相交的地方都有"角''出现, 因此在角的位置将产生稀疏性.而在维数更高的情况下, 等高线与L1范数球的交点除角点之外还可能产生在很多边的轮廓线上, 同样也会产生稀疏性.对于式(5), 本位采用近似梯度下降(Proximal gradient descent)[14]算法进行参数$w$的迭代求解, 所构造的最小化函数为$Jl=\{g(w)+R(w)\}$.在每次迭代中, $Jl(w)$的近似计算方法如下:
$$ \begin{align} J_L (w^t+d)&\approx \tilde {J}_{w^t} (d)=g(w^t)+\nabla g(w^t)^\mathrm{T}d\, +\nonumber\\ &\frac{1} {2d^\mathrm{T}(\frac{I }{ \alpha })d}+R(w^t+d)=\nonumber\\ &g(w^t)+\nabla g(w^t)^\mathrm{T}d+\frac{{d^\mathrm{T}d} } {2\alpha } +\nonumber\\ &R(w^t+d) \end{align} $$ (6) 更新迭代$w^{(t+1)}\leftarrow w^t+\mathrm{argmin}_d \tilde {J}_{(w^t)} (d)$, 由于$R(w)$整体不可导, 因而利用子可导引理得:
$$ \begin{align} w^{(t+1)}&=w^t+\mathop {\mathrm{argmin}} \nabla g(w^t)d^\mathrm{T}d\, +\nonumber\\ &\frac{d^\mathrm{T}d}{2\alpha }+\lambda \vert \vert w^t+d\vert \vert _1=\nonumber\\ &\mathrm{argmin}\frac{1 }{ 2}\vert \vert u-(w^t-\alpha \nabla g(w^t))\vert \vert ^2+\nonumber\\ &\lambda \alpha \vert \vert u\vert \vert _1 \end{align} $$ (7) 其中, $S$是软阈值算子, 定义如下:
$$ \begin{equation} S(a, z)=\left\{\begin{array}{ll} a-z, &a>z \\ a+z, &a<-z \\ 0, &a\in [-z, z] \\ \end{array}\right. \end{equation} $$ (8) 整个迭代求解过程为:
输入.数据$X\in {\bf R}^{n\times p}, {y}\in {\bf R}^n$, 初始化$w^{(0)}$.
输出.参数$w^\ast ={\rm argmin}_w\textstyle{1 \over n}\vert \vert Xw-{y}\vert \vert ^2+\\ \lambda \vert\vert w\vert \vert _1 $.
1) 初始化循环次数$t = 0$;
2) 计算梯度$\nabla g=X^\mathrm{T}(Xw-{y})$;
3) 选择一个步长大小$\alpha ^t$;
4) 更新$w\leftarrow S(w-\alpha ^tg, \alpha ^t\lambda )$;
5) 判断是否收敛或者达到最大迭代次数, 未收敛$t\leftarrow t+1$, 并循环2)$\sim$5)步.
通过上述迭代计算, 最终得到最优参数, 而参数大小位于软区间中的, 将被置为零, 即被稀疏掉.
1.4 建立淋巴结转移影像组学标签与预测模型
本文使用LLR对组学特征进行降维并建模, 并使用10折交叉验证, 提高模型的泛化能力, 流程如图 3所示.
将本文使用的影像组学模型的预测概率(Radscore)作为独立的生物标志物, 并与临床指标中显著的特征结合构建多元Logistics模型, 绘制个性化预测的诺模图, 最后通过校正曲线来观察预测模型的偏移情况.
2. 结果
2.1 数据单因素分析结果
我们分别在训练集和验证集上计算各个临床指标与淋巴结转移的单因素P值, 计算方式为卡方检验, 结果见表 1, 发现吸烟与否和EGFR (Epidermal growth factor receptor)基因突变状态与淋巴结转移显著相关.
表 1 训练集和测试集病人的基本情况Table 1 Basic information of patients in the training set and test set基本项 训练集($N=400$) $P$值 测试集($N=164$) $P$值 性别 男 144 (36 %) 0.896 78 (47.6 %) 0.585 女 256 (64 %) 86 (52.4 %) 吸烟 是 126 (31.5 %) 0.030* 45 (27.4 %) 0.081 否 274 (68.5 %) 119 (72.6 %) EGFR 缺失 36 (9 %) 4 (2.4 %) 突变 138 (34.5 %) $ < $0.001* 67 (40.9 %) 0.112 正常 226 (56.5 %) 93 (56.7 %) 2.2 淋巴结转移影像组学标签
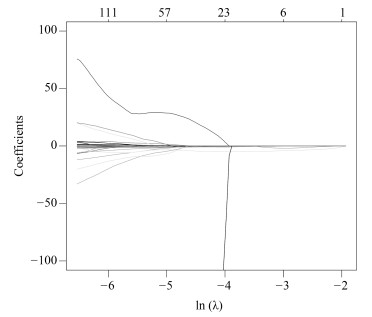
影像组学得分是每个病人最后通过模型预测后的输出值, 随着特征数的动态变化, 模型输出的AUC (Area under curve)值也随之变化, 如图 4所示, 使用R语言的Glmnet库可获得模型的参数$\lambda $的变化图.图中直观显示了参数$\lambda $的变化对模型性能的影响, 这次实验中模型选择了3个变量.如图 5所示, 横坐标表示$\lambda $的变化, 纵坐标表示变量的系数变化, 当$\lambda $逐渐变大时, 变量的系数逐渐减少为零, 表示变量选择的过程, 当$\lambda $越大表示模型的压缩程度越大.
 图 4 $\lambda $与变量数目对应走势Fig. 4 The trend of the parameters and the number of variables
图 4 $\lambda $与变量数目对应走势Fig. 4 The trend of the parameters and the number of variables通过套索回归方法, 自动的将变量压缩为3个, 其性能从图 4中也可发现, 模型的AUC值为最佳, 最终的特征如表 2所示. $V0$为截距项; $V179$为横向小波分解90度共生矩阵Contrast特征; $V230$为横向小波分解90度共生矩阵Entropy特征.
表 2 Lasso选择得到的参数Table 2 Parameters selected by LassoLasso选择的参数 含义 数值 $P$值 $V0$ 截距项 2.079115 $V179$ 横向小波分解90度共生矩阵Contrast特征(Contrast_2_90) 0.0000087 < 0.001*** $V230$ 横向小波分解90度共生矩阵Entropy特征(Entropy_3_180) $-$3.573315 < 0.001*** $V591$ 表面积与体积的比例(Surface to volume ratio) $-$1.411426 < 0.001*** $V591$为表面积与体积的比例; 将三个组学特征与$N$分期进行单因素分析, 其$P$值都是小于0.05, 表示与淋巴结转移有显著相关性.根据Lasso选择后的三个变量建立Logistics模型并计算出Rad-score, 详见式(9).并且同时建立SVM (Support vector machine)模型.
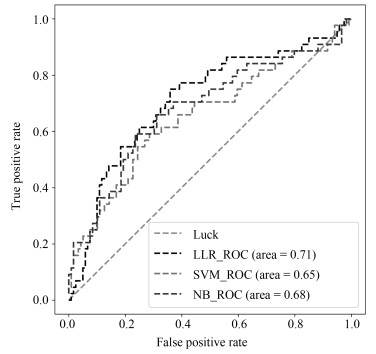
NB (Naive Bayesian)模型, 进行训练与预测, LLR模型训练集AUC为0.710, 测试集为0.712, 表现较优; 如表 3所示.将实验中使用的三个机器学习模型的结果进行对比, 可以发现, LLR的实验结果是最好的.
表 3 不同方法对比结果Table 3 Comparison results of different methods方法 训练集(AUC) 测试集(AUC) 召回率 LLR 0.710 0.712 0.75 SVM 0.698 0.654 0.75 NB 0.718 0.681 0.74 $$ \begin{equation} \begin{aligned} &\text{Rad-score}=2.328373+{\rm Contrast}\_2\_90\times\\ &\qquad 0.0000106 -{\rm entropy}\_3\_180\times 3.838207 +\\ &\qquad\text{Maximum 3D diameter}\times 0.0000002 -\\ &\qquad\text{Surface to volume ratio}\times 1.897416 \\ \end{aligned} \end{equation} $$ (9) 2.3 诺模图个性化预测模型
为了体现诺模图的临床意义, 融合Rad-score, 吸烟情况和EGFR基因因素等有意义的变量进行分析, 绘制出个性化预测的诺模图, 如图 7所示.为了给每个病人在最后得到一个得分, 需要将其对应变量的得分进行相加, 然后在概率线找到对应得分的概率, 从而实现非小细胞肺癌淋巴结转移的个性化预测.我们通过一致性指数(Concordance index, $C$-index)对模型进行了衡量, 其对应的$C$-index为0.724.
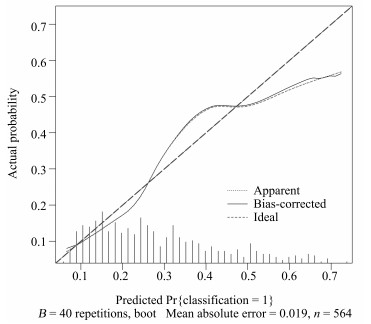
本文中使用校正曲线来验证诺模图的预测效果, 如图 8所示, 由校正曲线可以看出, 预测结果基本上没有偏离真实标签的结果, 表现良好, 因此, 该模型具有可靠的预测性能[15].
3. 结论
在构建非小细胞肺癌淋巴结转移的预测模型中, 使用LLR筛选组学特征并构建组学标签, 并与显著的临床特征构建多元Logistics模型, 绘制个性化预测的诺模图.其中LLR模型在训练集上的AUC值为0.710, 在测试集上的AUC值为0.712, 利用多元Logistics模型绘制个性化预测的诺模图, 得到模型表现能力$C$-index为0.724 (95 % CI: 0.678 $\sim$ 0.770), 并且在校正曲线上表现良好, 所以个性化预测的诺模图在临床决策上可起重要参考意义.[16].
-

图 1 干净语音频谱经过CNMF分解后提取出的基向量
Fig. 1 The basis extracted from the clean speech spectrum after CNMF decomposition
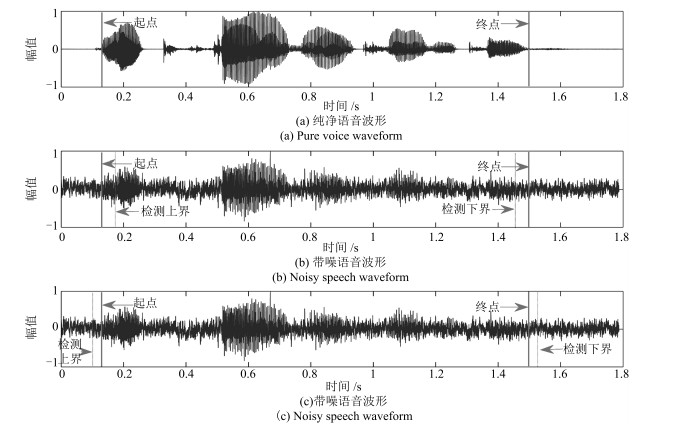
图 3 语音起点、终点(边界)检测示意图
Fig. 3 The illustration of start end points (boundary) detection of a speech
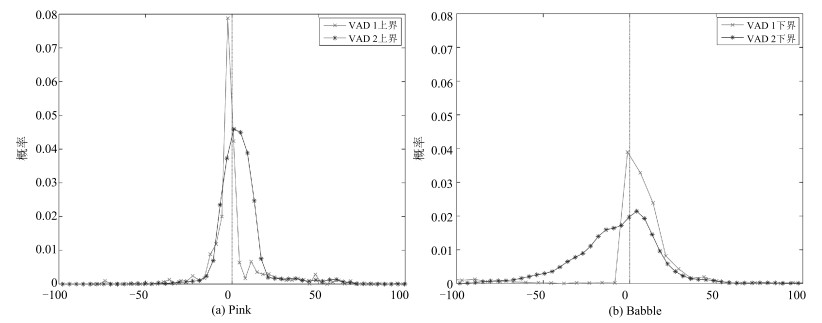
图 4 -12 dB混合信号的语音上界、下界检测偏差概率分布
Fig. 4 The probability distribution of detection deviation of upper and lower bounds in -12 dB mixture speech
表 1 5种信噪比下, 不同方法的主观听音得分平均值
Table 1 The subjective listening score of different methods at five different input SNR levels
SNR (dB) NMPCF SCNMF CNMPCF -12 1.06 1.08 1.20 -9 1.37 1.46 1.62 -6 1.76 1.95 2.08 -3 2.20 2.29 2.42 0 2.74 2.59 3.05  下载: 导出CSV
下载: 导出CSV
-
[1] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Deep learning for monaural speech separation. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Florence: IEEE, 2014. 1562-1566 [2] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12): 2136-2147 doi: 10.1109/TASLP.2015.2468583 [3] 刘文举, 聂帅, 梁山, 张学良.基于深度学习语音分离技术的研究现状与进展.自动化学报, 2016, 42(6): 819-833 doi: 10.16383/j.aas.2016.c150734Liu Wen-Ju, Nie Shuai, Liang Shan, Zhang Xue-Liang. Deep learning based speech separation technology and its developments. Acta Automatica Sinica, 2016, 42(6): 819-833 doi: 10.16383/j.aas.2016.c150734 [4] Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401(6755): 788 -791 doi: 10.1038/44565 [5] Wang D L, Brown G J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Piscataway: IEEE Press, 2006. [6] 韩伟, 张雄伟, 闵刚, 张启业.基于感知掩蔽深度神经网络的单通道语音增强方法.自动化学报, 2017, 43(2): 248-258 doi: 10.16383/j.aas.2017.c150719Han Wei, Zhang Xiong-Wei, Min Gang, Zhang Qi-Ye. A single-channel speech enhancement approach based on perceptual masking deep neural network. Acta Automatica Sinica, 2017, 43(2): 248-258 doi: 10.16383/j.aas.2017.c150719 [7] 袁文浩, 孙文珠, 夏斌, 欧世峰.利用深度卷积神经网络提高未知噪声下的语音增强性能.自动化学报, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001Yuan Wen-Hao, Sun Wen-Zhu, Xia Bin, Ou Shi-Feng. Improving speech enhancement in unseen noise using deep convolutional neural network. Acta Automatica Sinica, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001 [8] Smaragdis P. Convolutive speech bases and their application to supervised speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(1): 1-12 doi: 10.1109/TASL.2006.876726 [9] O'Grady P D, Pearlmutter B A. Discovering speech phones using convolutive non-negative matrix factorisation with a sparseness constraint. Neurocomputing, 2008, 72(1-3): 88 -101 doi: 10.1016/j.neucom.2008.01.033 [10] Sun M, Li Y N, Gemmeke J F, Zhang X W. Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback--Leibler divergence. IEEE Transactions on Audio, Speech, and Language Processing, 2015, 23(7): 1233-1242 doi: 10.1109/TASLP.2015.2427520 [11] Kim M, Yoo J, Kang K, Choi S. Blind rhythmic source separation: Nonnegativity and repeatability. In: Proceedings of the 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing. Dallas: IEEE, 2010. 2006-2009 [12] Yoo J, Kim M, Kang K, Choi S. Nonnegative matrix partial co-factorization for drum source separation. In: Proceedings of the 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing. Dallas: IEEE, 2010. 1942-1945 [13] Kim M, Yoo J, Kang K, Choi S. Nonnegative matrix partial co-factorization for spectral and temporal drum source separation. IEEE Journal of Selected Topics in Signal Processing, 2011, 5(6): 1192-1204 doi: 10.1109/JSTSP.2011.2158803 [14] Hu Y, Liu G Z. Separation of singing voice using nonnegative matrix partial co-factorization for singer identification. IEEE Transactions on Audio, Speech, and Language Processing, 2015, 23(4): 643-653 doi: 10.1109/TASLP.2015.2396681 [15] 路成, 田猛, 周健, 王华彬, 陶亮. L1/2稀疏约束卷积非负矩阵分解的单通道语音增强方法.声学学报, 2017, 42(3): 377-384 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=shengxxb201703015Lu Cheng, Tian Meng, Zhou Jian, Wang Hua-Bin, Tao Liang. A single-channel speech enhancement approach using convolutive non-negative matrix factorization with L1/2 sparse constraint. Acta Acustica, 2017, 42(3): 377-384 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=shengxxb201703015 [16] Natarajan B K. Sparse approximate solutions to linear systems. SIAM Journal on Computing, 1995, 24(2): 227-234 doi: 10.1137/S0097539792240406 [17] Candés E J, Li X D, Ma Y, Wright J. Robust principal component analysis? Journal of the ACM, 2009, 58(3): Article No. 11. http://d.old.wanfangdata.com.cn/Periodical/cjce200405015 [18] Boersma P. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. Proceedings of the Institute of Phonetic Sciences, 1993, 17: 97-110 2013. 704-708 http://www.cs.northwestern.edu/~pardo/courses/eecs352/papers/pitch%20tracking%20-%20boersma.pdf [19] Rix A W, Beerends J G, Hollier M P, Hekstra A P. Perceptual evaluation of speech quality (PESQ) --- a new method for speech quality assessment of telephone networks and codecs. In: Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Salt Lake City: IEEE, 2001. 749-752 [20] Vincent E, Gribonval R, Fevotte C. Performance measurement in blind audio source separation. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4): 1462-1469 doi: 10.1109/TSA.2005.858005 [21] Li Y P, Woodruff J, Wang D L. Monaural musical sound separation based on pitch and common amplitude modulation. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17(7): 1361-1371 doi: 10.1109/TASL.2009.2020886 [22] van Segbroeck M. A robust frontend for VAD: Exploiting contextual, discriminative and spectral cues of human voice. In: Proceedings of the 2013 Interspeech. Lyon: Interspeech, 2013. -

 下载:
下载:


计量
- 文章访问数: 1349
- HTML全文浏览量: 136
- PDF下载量: 155
- 被引次数: 0
