

Monaural Speech Separation by Means of Convolutive Nonnegative Matrix Partial Co-factorization in Low SNR Condition
-
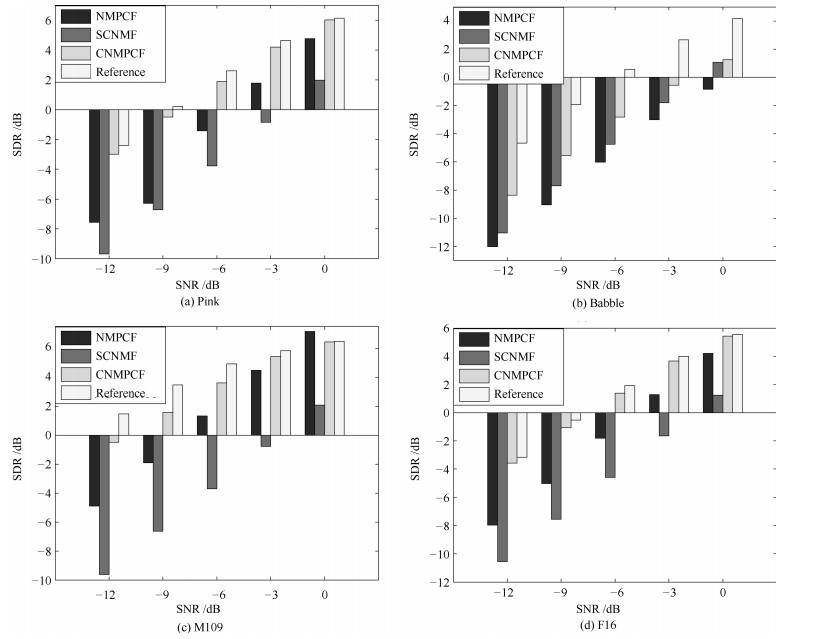
摘要: 非负矩阵部分联合分解(Nonnegative matrix partial co-factorization, NMPCF)将指定源频谱作为边信息参与混合信号频谱的联合分解, 以帮助确定指定源的基向量进而提高信号分离性能.卷积非负矩阵分解(Convolutive nonnegative matrix factorization, CNMF)采用卷积基分解的方法进行矩阵分解, 在单声道语音分离方面取得较好的效果.为了实现强噪声条件下的语音分离, 本文结合以上两种算法的优势, 提出一种基于卷积非负矩阵部分联合分解(Convolutive nonnegative partial matrix co-factorization, CNMPCF)的单声道语音分离算法.本算法首先通过基音检测算法得到混合信号的语音起始点, 再据此确定混合信号中的纯噪声段, 最后将混合信号频谱和噪声频谱进行卷积非负矩阵部分联合分解, 得到语音基矩阵, 进而得到分离的语音频谱和时域信号.实验中, 混合语音信噪比(Signal noise ratio, SNR)选择以-3 dB为间隔从0 dB至-12 dB共5种SNR.实验结果表明, 在不同噪声类型和噪声强度条件下, 本文提出的CNMPCF方法相比于以上两种方法均有不同程度的提高.
-
关键词:
- 卷积非负矩阵分解 /
- 非负矩阵部分联合分解 /
- 语音分离 /
- 强噪声 /
- 单声道
Abstract: Nonnegative matrix partial co-factorization (NMPCF) is a joint matrix decomposition algorithm integrating prior knowledge of specific source to help separate specific source signal from monaural mixtures. Convolutive nonnegative matrix factorization (CNMF), which introduces the concept of a convolutive non-negative basis set during NMF process, opens up an interesting avenue of research in the field of monaural sound separation. On the basis of the above two algorithms, we propose a speech separation algorithm named as convolutive nonnegative matrix partial co-factorization (CNMPCF) for low signal noise ratio (SNR) monaural speech. Firstly, through a voice detection process exploring fundamental frequency estimation algorithm, we divide a mixture signal into vocal and nonvocal parts, thus those vocal parts are used as test mixture signal while the nonvocal parts (pure noise) participat in the partial joint decomposition. After CNMPCF, we can obtain the separated speech spectrogram. Then, the separated speech signal can reconstructed through Inverse short time fourier transformation. In the experiments, we select 5 SNRs from 0 dB to -12 dB at -3 dB intervals to obtain low SNR mixture speeches. The results demonstrate that the proposed CNMPCF approach has superiority over sparse convolutive nonnegative matrix factorization (SCNMF) and NMPCF under different noise types and noise intensities.-
Key words:
- Convolutive nonnegative matrix factorization (CNMF) /
- nonnegative matrix partial co-factorization (NMPCF) /
- speech separation /
- strong noise /
- monaural speech
1) 本文责任编委 党建武 -

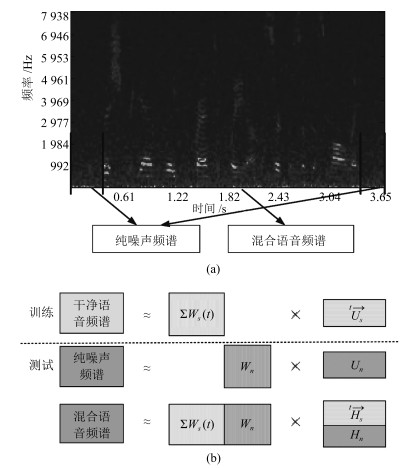
图 1 干净语音频谱经过CNMF分解后提取出的基向量
Fig. 1 The basis extracted from the clean speech spectrum after CNMF decomposition
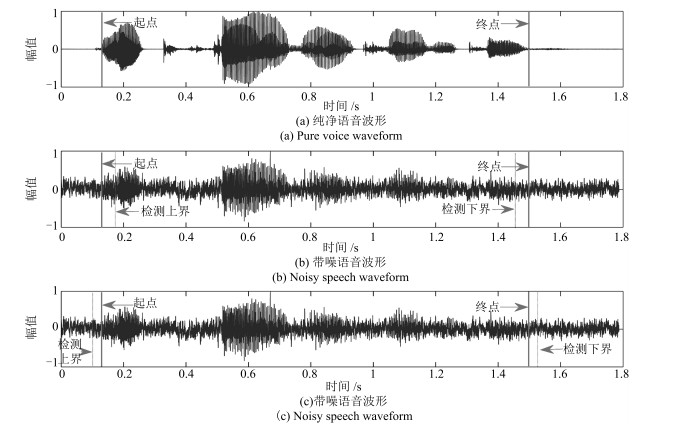
图 3 语音起点、终点(边界)检测示意图
Fig. 3 The illustration of start end points (boundary) detection of a speech
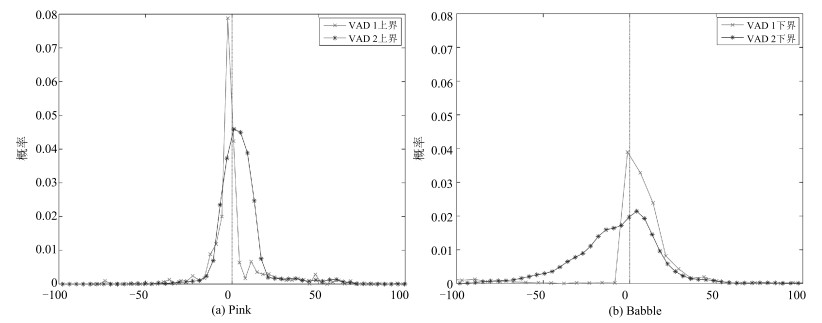
图 4 -12 dB混合信号的语音上界、下界检测偏差概率分布
Fig. 4 The probability distribution of detection deviation of upper and lower bounds in -12 dB mixture speech
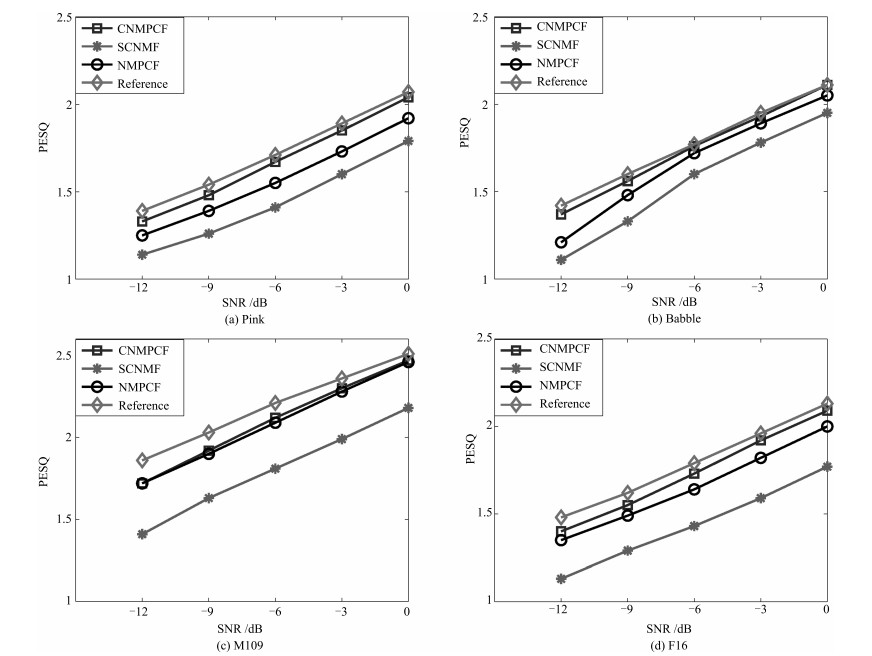
表 1 5种信噪比下, 不同方法的主观听音得分平均值
Table 1 The subjective listening score of different methods at five different input SNR levels
SNR (dB) NMPCF SCNMF CNMPCF -12 1.06 1.08 1.20 -9 1.37 1.46 1.62 -6 1.76 1.95 2.08 -3 2.20 2.29 2.42 0 2.74 2.59 3.05  下载: 导出CSV
下载: 导出CSV
-
[1] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Deep learning for monaural speech separation. In: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech, and Signal Processing. Florence: IEEE, 2014. 1562-1566 [2] Huang P S, Kim M, Hasegawa-Johnson M, Smaragdis P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(12): 2136-2147 doi: 10.1109/TASLP.2015.2468583 [3] 刘文举, 聂帅, 梁山, 张学良.基于深度学习语音分离技术的研究现状与进展.自动化学报, 2016, 42(6): 819-833 doi: 10.16383/j.aas.2016.c150734Liu Wen-Ju, Nie Shuai, Liang Shan, Zhang Xue-Liang. Deep learning based speech separation technology and its developments. Acta Automatica Sinica, 2016, 42(6): 819-833 doi: 10.16383/j.aas.2016.c150734 [4] Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401(6755): 788 -791 doi: 10.1038/44565 [5] Wang D L, Brown G J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Piscataway: IEEE Press, 2006. [6] 韩伟, 张雄伟, 闵刚, 张启业.基于感知掩蔽深度神经网络的单通道语音增强方法.自动化学报, 2017, 43(2): 248-258 doi: 10.16383/j.aas.2017.c150719Han Wei, Zhang Xiong-Wei, Min Gang, Zhang Qi-Ye. A single-channel speech enhancement approach based on perceptual masking deep neural network. Acta Automatica Sinica, 2017, 43(2): 248-258 doi: 10.16383/j.aas.2017.c150719 [7] 袁文浩, 孙文珠, 夏斌, 欧世峰.利用深度卷积神经网络提高未知噪声下的语音增强性能.自动化学报, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001Yuan Wen-Hao, Sun Wen-Zhu, Xia Bin, Ou Shi-Feng. Improving speech enhancement in unseen noise using deep convolutional neural network. Acta Automatica Sinica, 2018, 44(4): 751-759 doi: 10.16383/j.aas.2018.c170001 [8] Smaragdis P. Convolutive speech bases and their application to supervised speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(1): 1-12 doi: 10.1109/TASL.2006.876726 [9] O'Grady P D, Pearlmutter B A. Discovering speech phones using convolutive non-negative matrix factorisation with a sparseness constraint. Neurocomputing, 2008, 72(1-3): 88 -101 doi: 10.1016/j.neucom.2008.01.033 [10] Sun M, Li Y N, Gemmeke J F, Zhang X W. Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback--Leibler divergence. IEEE Transactions on Audio, Speech, and Language Processing, 2015, 23(7): 1233-1242 doi: 10.1109/TASLP.2015.2427520 [11] Kim M, Yoo J, Kang K, Choi S. Blind rhythmic source separation: Nonnegativity and repeatability. In: Proceedings of the 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing. Dallas: IEEE, 2010. 2006-2009 [12] Yoo J, Kim M, Kang K, Choi S. Nonnegative matrix partial co-factorization for drum source separation. In: Proceedings of the 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing. Dallas: IEEE, 2010. 1942-1945 [13] Kim M, Yoo J, Kang K, Choi S. Nonnegative matrix partial co-factorization for spectral and temporal drum source separation. IEEE Journal of Selected Topics in Signal Processing, 2011, 5(6): 1192-1204 doi: 10.1109/JSTSP.2011.2158803 [14] Hu Y, Liu G Z. Separation of singing voice using nonnegative matrix partial co-factorization for singer identification. IEEE Transactions on Audio, Speech, and Language Processing, 2015, 23(4): 643-653 doi: 10.1109/TASLP.2015.2396681 [15] 路成, 田猛, 周健, 王华彬, 陶亮. L1/2稀疏约束卷积非负矩阵分解的单通道语音增强方法.声学学报, 2017, 42(3): 377-384 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=shengxxb201703015Lu Cheng, Tian Meng, Zhou Jian, Wang Hua-Bin, Tao Liang. A single-channel speech enhancement approach using convolutive non-negative matrix factorization with L1/2 sparse constraint. Acta Acustica, 2017, 42(3): 377-384 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=shengxxb201703015 [16] Natarajan B K. Sparse approximate solutions to linear systems. SIAM Journal on Computing, 1995, 24(2): 227-234 doi: 10.1137/S0097539792240406 [17] Candés E J, Li X D, Ma Y, Wright J. Robust principal component analysis? Journal of the ACM, 2009, 58(3): Article No. 11. http://d.old.wanfangdata.com.cn/Periodical/cjce200405015 [18] Boersma P. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. Proceedings of the Institute of Phonetic Sciences, 1993, 17: 97-110 2013. 704-708 http://www.cs.northwestern.edu/~pardo/courses/eecs352/papers/pitch%20tracking%20-%20boersma.pdf [19] Rix A W, Beerends J G, Hollier M P, Hekstra A P. Perceptual evaluation of speech quality (PESQ) --- a new method for speech quality assessment of telephone networks and codecs. In: Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Salt Lake City: IEEE, 2001. 749-752 [20] Vincent E, Gribonval R, Fevotte C. Performance measurement in blind audio source separation. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4): 1462-1469 doi: 10.1109/TSA.2005.858005 [21] Li Y P, Woodruff J, Wang D L. Monaural musical sound separation based on pitch and common amplitude modulation. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17(7): 1361-1371 doi: 10.1109/TASL.2009.2020886 [22] van Segbroeck M. A robust frontend for VAD: Exploiting contextual, discriminative and spectral cues of human voice. In: Proceedings of the 2013 Interspeech. Lyon: Interspeech, 2013. -

 下载:
下载:


计量
- 文章访问数: 1563
- HTML全文浏览量: 180
- PDF下载量: 159
- 被引次数: 0
