

Data-driven Robust Evaluation Method for Optimal Operating Status and Its Application
-
摘要: 在现代复杂工业生产过程中, 细致而稳健的运行状态评价及非优因素识别对指导工业生产具有十分重要的实际意义.考虑到复杂工业过程难以建立准确的数学模型和实际工业过程数据噪声及离群点污染比较严重的问题, 本文提出一种全潜鲁棒偏M估计的复杂工业过程最优状态的鲁棒评价方法.在建立离线评价模型时, 通过对过程数据主元和残差子空间的进一步分解, 提取出能够反映与原材料、生产消耗和产品质量等因素相关的经济指标的变化信息, 同时采用样本数据加权的方法消除离群点对评价模型的不利影响, 提高算法的鲁棒性; 在线评价时, 针对生产过程中存在不确定性因素, 引入在线数据窗口及相似度分析进行在线评价, 并给出在线评价的准则和流程, 提高评价结果的可靠性, 当评价结果非优时, 通过计算相应变量的贡献率识别非优因素.最后, 通过重介质选煤过程验证了所提方法的有效性.Abstract: In the process of modern complex industrial production, a detailed and robust evaluation method of operation state is of great significance for guiding the production. Considering the difficulty to establish an accurate principle model and the process data which are easily polluted by noise and outliers, this paper proposes a robust optimal evaluation method for complex industrial processes based on total partial robust M-regression. In the off-line modeling stage, by further decomposing the principal and residual subspaces of the process data, the process variation information related to the economic indexes reflecting the factors such as raw materials, production consumption and product quality is extracted, and the adverse effects of the outliers are eliminated by sample data weighting to improve the robustness of the algorithm. In the stage of online evaluation, the online data window and similarity analysis are introduced for the uncertain factors of the production process, and the framework and procedure of online evaluation are given to improve the reliability of the evaluation results. If the evaluation results are not optimal, then the non-optimal factors are identified by calculating the contribution rates of the corresponding variables. Finally, the effectiveness of the proposed method is illustrated by a process of dense medium coal preparation.
-
Key words:
- Complex industrial process /
- data-driven /
- operational status evaluation /
- total partial robust M-regression /
- non-optimal factor
1) 本文责任编委 王卓 -
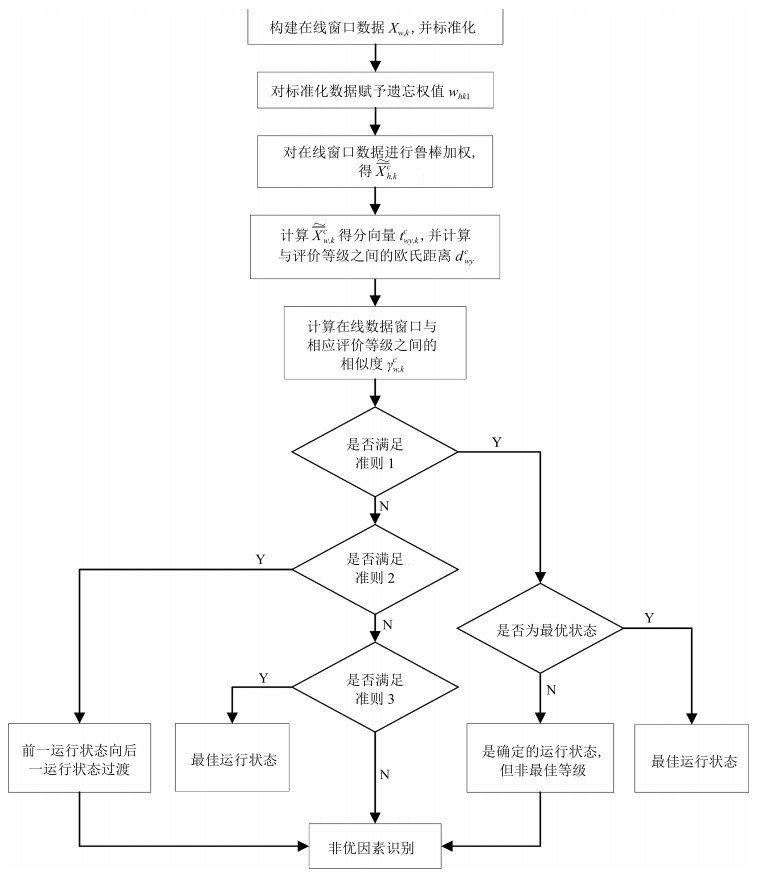
图 1 基于全潜鲁棒偏M估计的复杂工业过程在线运行状态评价流程
Fig. 1 Online operation state evaluation process of complex industrial process based on total partial robust M-regression

图 3 Total-PLS方法的运行状态评价结果
Fig. 3 Evaluation results of the operating state of Total-PLS method
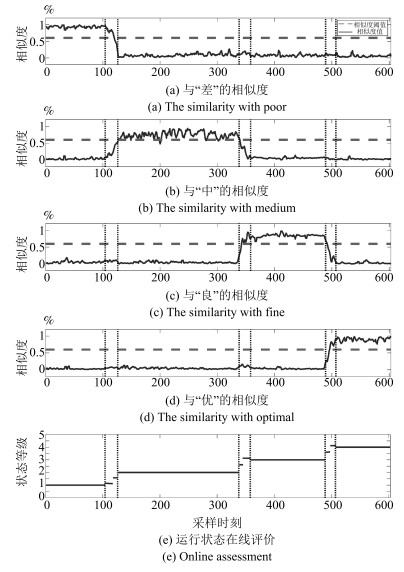
图 4 Total-PRMR方法的运行状态评价结果
Fig. 4 Evaluation results of the operating state of Total-PRMR method

图 5 重介质选煤过程非优因素识别
Fig. 5 Identification of non-optimal factors in the process of dense medium coal preparation
表 1 原煤灰分与状态等级
Table 1 Raw coal ash and state level
原煤灰分化验值(%) 状态等级及过渡过程 6.0$\, \sim\, $6.5 Optimal 6.5$\, \sim\, $6.7 Optimal到Fine过渡 6.7$\, \sim\, $7.2 Fine 7.2$\, \sim\, $7.5 Fine到Medium过渡 7.5$\, \sim\, $8.0 Medium 8.0$\, \sim\, $8.2 Medium到Poor过渡 8.2$\, \sim\, $9.0 Poor  下载: 导出CSV
下载: 导出CSV
表 2 现有方法(Total-PLS)评价识别准确率
Table 2 The assessment identification accuracy rate of the existing method (Total-PLS based) (%)
相似度阈值 Poor (差) Medium (中) Fine (良) Optimal (优) $\varepsilon \ge 0.{\rm{6}}$ 11 9 55 8 $\varepsilon \ge 0.{\rm{7}}$ 4 5 33 1 $\varepsilon \ge 0.{\rm{8}}$ 1 3 7 0
下载: 导出CSV
表 3 本文方法(Total-PRMR)评价识别准确率(%)
Table 3 The assessment identification accuracy rate of the proposed method (Total-PRMR based) (%)
相似度阈值 Poor (差) Medium (中) Fine (良) Optimal (优) $\varepsilon \ge 0.{\rm{6}}$ 100 100 100 100 $\varepsilon \ge 0.{\rm{7}}$ 93 88 81 94 $\varepsilon \ge 0.{\rm{8}}$ 90 78 72 90
下载: 导出CSV
-
[1] 文成林, 吕菲亚, 包哲静, 刘妹琴.基于数据驱动的微小故障诊断方法综述.自动化学报, 2016, 42(9): 1285-1299 doi: 10.16383/j.aas.2016.c160105Wen Chen-Lin, Lv Fei-Ya, Bao Zhe-Jing, Liu Mei-Qin. A review of data driven-based incipient fault diagnosis. Acta Automatica Sinica, 2016, 42(9): 1285-1299 doi: 10.16383/j.aas.2016.c160105 [2] Yin S, Gao H J, Qiu J B, Kaynak O. Fault detection for nonlinear process with deterministic disturbances: a just-in-time learning based data driven method. IEEE Transactions on Cybernetics, 2017, 47(11): 3649-3657 doi: 10.1109/TCYB.2016.2574754 [3] del Rio-Chanona E A, Zhang D D, Vassiliadis V S. Model-based real-time optimisation of a fed-batch cyanobacterial hydrogen production process using economic model predictive control strategy. Chemical Engineering Science, 2016, 142: 289-298 doi: 10.1016/j.ces.2015.11.043 [4] Rossi F, Copelli S, Colombo A, Pirola C, Manenti F. Online model-based optimization and control for the combined optimal operation and runaway prediction and prevention in (fed-)batch systems. Chemical Engineering Science, 2015, 138: 760-771 doi: 10.1016/j.ces.2015.09.006 [5] Ji H Q, He X, Shang J, Zhou D H. Incipient fault detection with smoothing techniques in statistical process monitoring. Control Engineering Practice, 2017, 62: 11-21 doi: 10.1016/j.conengprac.2017.03.001 [6] Frangos M. Uncertainty quantification for cuttings transport process monitoring while drilling by ensemble Kalman filtering. Journal of Process Control, 2017, 53: 46-56 doi: 10.1016/j.jprocont.2017.02.008 [7] 刘洋, 张国山.基于敏感稀疏主元分析的化工过程监测与故障诊断.控制与决策, 2016, 31(7): 1213-1218 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201607011Liu Yang, Zhang Guo-Shan. Chemical process monitoring and fault diagnosis based on sensitive sparse principal component analysis. Control and Decision, 2016, 31(7): 1213- 1218 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201607011 [8] Zou X Y, Wang F L, Chang Y Q, Zhang B. Process operating performance optimality assessment and non-optimal cause identification under uncertainties. Chemical Engineering Research and Design, 2017, 120: 348-359 doi: 10.1016/j.cherd.2017.02.022 [9] Mosallam A, Medjaher K, Zerhouni N. Component based data-driven prognostics for complex systems: methodology and applications. In: Proceedings of the 1st International Conference on Reliability Systems Engineering (ICRSE). Beijing, China: IEEE, 2015. 1-7 [10] Jia X D, Zhao M, Di Y, Yang Q B, Lee J. Assessment of data suitability for machine prognosis using maximum mean discrepancy. IEEE Transactions on Industrial Electronics, 2018, 65(7): 5872-5881 doi: 10.1109/TIE.2017.2777383 [11] Li N P, Lei Y G, Guo L, Yan T, Lin J. Remaining useful life prediction based on a general expression of stochastic process models. IEEE Transactions on Industrial Electronics, 2017, 64(7): 5709-5718 doi: 10.1109/TIE.2017.2677334 [12] Lei Y G, Li N P, Guo L, Li N B, Yan T, Lin J. Machinery health prognostics: a systematic review from data acquisition to RUL prediction. Mechanical Systems and Signal Processing, 2018, 104: 799-834 doi: 10.1016/j.ymssp.2017.11.016 [13] 齐良才, 李宏光.基于数据驱动的控制器性能多属性评价方法.华东理工大学学报(自然科学版), 2014, 40(2): 244-249 doi: 10.3969/j.issn.1006-3080.2014.02.019Qi Liang-Cai, Li Hong-Guang. A data-driven approach to multi-attribute assessment of controller performance. Journal of East China University of Science and Technology (Natural Science Edition), 2014, 40(2): 244-249 doi: 10.3969/j.issn.1006-3080.2014.02.019 [14] 颜湘武, 李艳艳, 张合川, 王丽娜.基于变权分析方法的电动汽车充电设备性能综合评价.湖南大学学报(自然科学版), 2014, 41(5): 86-93 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=hndxxb201405014Yan Xiang-Wu, Li Yan-Yan, Zhang He-Chuan, Wang Li-Na. Comprehensive evaluation of EV charging equipment performance base on variable weights analysis method. Journal of Hunan University (Natural Sciences), 2014, 41(5): 86-93 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=hndxxb201405014 [15] Melhem M, Ananou B, Ouladsine M, Pinaton J. Regression methods for predicting the product's quality in the semiconductor manufacturing process. IFAC-PapersOnline, 2016, 49(12): 83-88 doi: 10.1016/j.ifacol.2016.07.554 [16] de Souza M F Z, Reis Y, Almeida A B, Lima I, de Souza A C Z. Load margin assessment of systems with distributed generation with the help of a neuro-fuzzy method. IET Renewable Power Generation, 2015, 9(4): 331-339 doi: 10.1049/iet-rpg.2014.0090 [17] Shirali G A, Mohammadfam I, Ebrahimipour V. A new method for quantitative assessment of resilience engineering by PCA and NT approach: a case study in a process industry. Reliability Engineering and System Safety, 2013, 119: 88-94 doi: 10.1016/j.ress.2013.05.003 [18] 廖瑞金, 王谦, 骆思佳, 廖玉祥, 孙才新.基于模糊综合评判的电力变压器运行状态评估模型.电力系统自动化, 2008, 32(3): 70-75 doi: 10.3321/j.issn:1000-1026.2008.03.017Liao Rui-Jin, Wang Qian, Luo Si-Jia, Liao Yu-Xiang, Sun Cai-Xin. Condition assessment model for power transformer in service based on fuzzy synthetic evaluation. Automation of Electric Power Systems, 2008, 32(3): 70-75 doi: 10.3321/j.issn:1000-1026.2008.03.017 [19] 张琨, 沈海波, 张宏, 蒋黎明, 衷宜.基于灰色关联分析的复杂网络节点重要性综合评价方法.南京理工大学学报(自然科学版), 2012, 36(4): 579-586 doi: 10.3969/j.issn.1005-9830.2012.04.005Zhang Kun, Shen Hai-Bo, Zhang Hong, Jiang Li-Ming, Zhong Yi. Synthesis evaluation method for node importance in complex networks based on grey relational analysis. Journal of Najing University of Science and Technology (Natural Science), 2012, 36(4): 579-586 doi: 10.3969/j.issn.1005-9830.2012.04.005 [20] 罗毅, 周创立, 刘向杰.多层次灰色关联分析法在火电机组运行评价中的应用.中国电机工程学报, 2012, 32(17): 97-103 http://d.old.wanfangdata.com.cn/Periodical/zgdjgcxb201217017Luo Yi, Zhou Chuang-Li, Liu Xiang-Jie. Application of the multi-level grey relational analysis method in operation assessment of thermal power units. Proceedings of the CSEE, 2012, 32(17): 97-103 http://d.old.wanfangdata.com.cn/Periodical/zgdjgcxb201217017 [21] 吴奇.基于过程数据的重介质选煤过程运行状态评价方法研究[硕士学位论文], 中国矿业大学, 中国, 2016.Wu Qi. Research on Heavy Medium Coal Preparation Process Operating Performance Assessment Method Based on Process Data [Master thesis], China University of Mining and Technology, China, 2016. [22] Vo H X, Durlofsky L J. Data assimilation and uncertainty assessment for complex geological models using a new PCA-based parameterization. Computational Geosciences, 2015, 19(4): 747-767 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ff4f0203f92e1fea0e3632f325d8e91c [23] Liu Y, Wang F L, Chang Y Q. Operating optimality assessment and cause identification for nonlinear industrial processes. Chemical Engineering Research and Design, 2017, 117: 472-487 doi: 10.1016/j.cherd.2016.11.001 [24] 刘炎, 常玉清, 王福利.基于Fisher判别分析的过程运行状态在线评价.控制与决策, 2014, 29(9): 1655-1660 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201409021Liu Yan, Chang Yu-Qing, Wang Fu-Li. Online assessment of process operating performance based on Fisher discriminant analysis. Control and Decision, 2014, 29(9): 1655-1660 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201409021 [25] Liu Y, Chang Y Q, Wang F L. Online process operating performance assessment and nonoptimal cause identification for industrial processes. Journal of Process Control, 2014, 24(10): 1548-1555 doi: 10.1016/j.jprocont.2014.08.001 [26] Paalanen P, Kamarainen J K, Ilonen J, Kälviäinen H. Feature representation and discrimination based on Gaussian mixture model probability densities-practices and algorithms. Pattern Recognition, 2006, 39(7): 1346-1358 doi: 10.1016/j.patcog.2006.01.005 [27] Ye L B, Liu Y M, Fei Z S, Liang J. Online probabilistic assessment of operating performance based on safety and optimality indices for multimode industrial processes. Industrial and Engineering Chemistry Research, 2009, 48(24): 10912- 10923 doi: 10.1021/ie801870g [28] Zou X Y, Wang F L, Chang Y Q, Zhao L P, Zheng W. Two-level multi-block operating performance optimality assessment for plant-wide processes. The Canadian Journal of Chemical Engineering, DOI: 10.1002/cjce.23159, 2018. [29] Liu Y, Wang F L, Chang Y Q, Ma R C. Operating optimality assessment and nonoptimal cause identification for non-Gaussian multimode processes with transitions. Chemical Engineering Science, 2015, 137: 106-118 doi: 10.1016/j.ces.2015.06.016 [30] Liu Y, Wang F L, Chang Y Q. Operating optimality assessment based on optimality related variations and nonoptimal cause identification for industrial processes. Journal of Process Control, 2016, 39: 11-20 doi: 10.1016/j.jprocont.2015.12.008 [31] Zhou D H, Li G, Qin S J. Total projection to latent structures for process monitoring. AIChE Journal, 2010, 56(1): 168-178 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f04d2e43492464d020b4fc1e4c9d8979 [32] 贾润达, 毛志忠, 王福利.基于核偏鲁棒M-回归的间歇反应过程混合模型辨识.高校化学工程学报, 2014, 28(1): 115-122 doi: 10.3969/j.issn.1003-9015.2014.01.018Jia Run-Da, Mao Zhi-Zhong, Wang Fu-Li. Identification of hybrid models for batch reaction processes based on kernel partial robust M-regression. Journal of Chemical Engineering of Chinese Universities, 2014, 28(1): 115-122 doi: 10.3969/j.issn.1003-9015.2014.01.018 [33] Chu F, Ma X P, Wang F L, Jia R D. Novel robust approach for constructing Mamdani-type fuzzy system based on PRM and subtractive clustering algorithm. Journal of Central South University, 2015, 22(7): 2620-2628 doi: 10.1007/s11771-015-2792-3 [34] Jia R D, Mao Z Z, Chang Y Q, Zhang S N. Kernel partial robust M-regression as a flexible robust nonlinear modeling technique. Chemometrics and Intelligent Laboratory Systems, 2010, 100(2): 91-98 doi: 10.1016-j.chemolab.2009.11.005/ [35] 赵春祥, 叶桂森.重介质选煤过程控制模型及控制算法的研究.煤炭学报, 2000, 25(z1): 196-200 doi: 10.3321/j.issn:0253-9993.2000.z1.044Zhao Chun-Xiang, Ye Gui-Sen. Study of heavy medium coal preparation process control model and control algorithm. Journal of China Coal Society, 2000, 25(z1): 196-200 doi: 10.3321/j.issn:0253-9993.2000.z1.044 [36] Peng K X, Zhang K, Li G, Zhou D H. Contribution rate plot for nonlinear quality-related fault diagnosis with application to the hot strip mill process. Control Engineering Practice, 2013, 21(4): 360-369 doi: 10.1016/j.conengprac.2012.11.013 [37] 曹珍贯.重介选煤过程中重介质的密度预测控制研究[博士学位论文], 中国矿业大学, 中国, 2014.Cao Zhen-Guan. Study of Prediction Control on Heavy Medium Density in the Process of Coal Preparation [Ph. D. dissertation], China University of Mining and Technology, China, 2014. [38] Chu F, Wu Q, Dai W, Ma X P, Wang F L. Latent variable techniques based operating performance assessment for the dense medium coal preparation process. In: Proceedings of the 35th Chinese Control Conference (CCC). Chengdu, China: IEEE, 2016. 9821-9826 -

 下载:
下载:


计量
- 文章访问数: 5460
- HTML全文浏览量: 1510
- PDF下载量: 418
- 被引次数: 0
