

A Deep Belief Networks Training Strategy Based on Multi-hidden Layer Gibbs Sampling
-
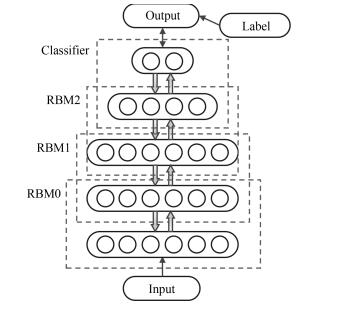
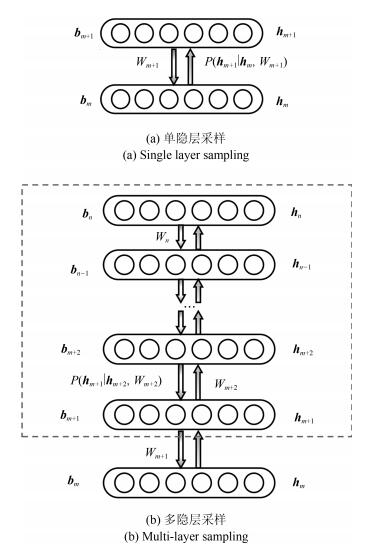
摘要: 深度信念网络(Deep belief network,DBN)作为一类非常重要的概率生成模型,在多个领域都有着广泛的用途.现有深度信念网的训练分为两个阶段,首先是对受限玻尔兹曼机(Restricted Boltzmann machine,RBM)层自底向上逐层进行的贪婪预训练,使得每层的重构误差最小,这个阶段是无监督的;随后再对整体的权值使用有监督的反向传播方法进行精调.本文提出了一种新的DBN训练方法,通过多隐层的Gibbs采样,将局部RBM层组合,并在原有的逐层预训练和整体精调之间进行额外的预训练,有效地提高了DBN的精度.本文同时比较了多种隐层的组合方式,在MNIST和ShapeSet以及Cifar10数据集上的实验表明,使用两两嵌套组合方式比传统的方法错误率更低.新的训练方法可以在更少的神经元上获得比以往的训练方法更好的准确度,有着更高的算法效率.Abstract: Deep belief network (DBN) is a very important probabilistic generative model that can be used in many areas. The current training approach of DBN involves two phases. The first is a fully unsupervised pre-training process, which is a down-top and layer-by-layer one to train the restricted Boltzmann machine (RBM) layers, making the reconstruction error of each layer minimal. The second is a supervised stage which uses the back propagation to fine-tune the entire parameters of the model. In this paper, a new training strategy for DBN is proposed. Between the current two training phases, this paper introduces another training strategy to combine multiple local RBMs into an overall probability model for multi hidden layer Gibbs sampling, which effectively improves the accuracy of DBN. This paper has compared a variety of combinations of RBM layers, experiments on the MNIST, ShapeSet and Cifar10 dataset show that our method outperforms the existing training algorithms for DBN. The new algorithm can achieve better accuracy with fewer neurons, also achieves higher algorithm efficiency.1) 本文责任编委 王占山
-
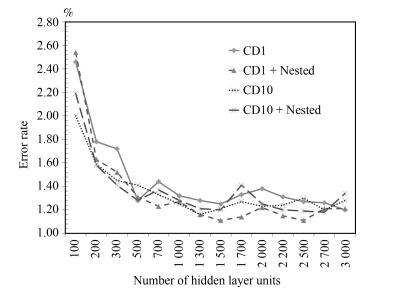
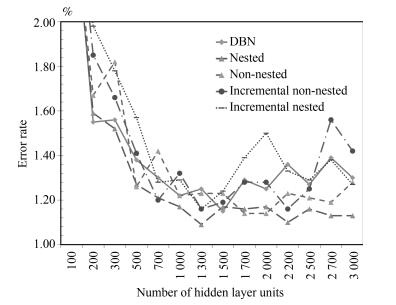
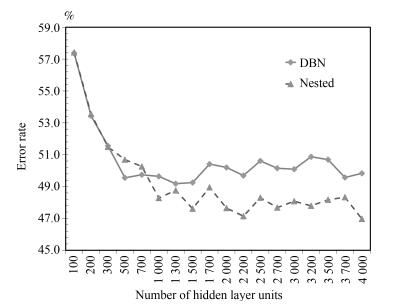
图 8 3隐层模型CD1、CD10错误率对比
Fig. 8 The error rate comparison with CD1 and CD10 on 3 hidden layers model
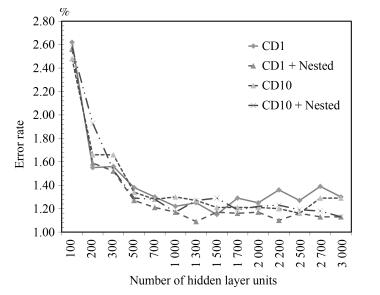
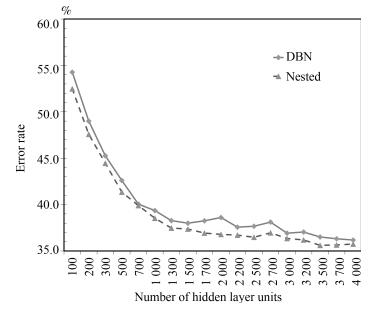
图 9 4隐层模型CD1、CD10错误率对比
Fig. 9 The error rate comparison with CD1 and CD10 on 4 hidden layers model
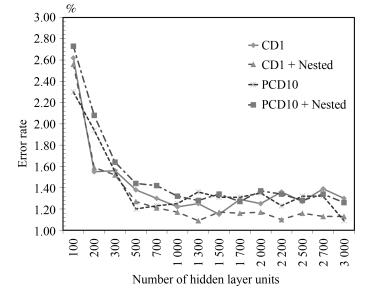
图 10 4隐层模型CD1、PCD错误率对比
Fig. 10 The error rate comparison with CD1 and PCD on 4 hidden layers model
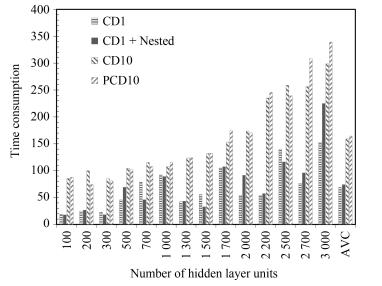
图 11 4隐层模型上各种算法训练耗时对比
Fig. 11 The training time consumption comparison on 4 hidden layers model
-
[1] Bengio Y. Learning deep architectures for AI. Foundations & Trends in Machine Learning, 2009, 2(1):1-127 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1206.5538 [2] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786):504-507 doi: 10.1126/science.1127647 [3] Lee H, Grosse R, Ranganath R, Ng A Y. Unsupervised learning of hierarchical representations with convolutional deep belief networks. Communications of the ACM, 2011, 54(10):95-103 doi: 10.1145/2001269 [4] Goh H, Thome N, Cord M, Lim J H. Learning deep hierarchical visual feature coding. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(12):2212-2225 doi: 10.1109/TNNLS.2014.2307532 [5] Mohamed A R, Dahl G E, Hinton G. Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1):14-22 doi: 10.1109/TASL.2011.2109382 [6] Sarikaya R, Hinton G E, Deoras A. Application of deep belief networks for natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(4):778-784 doi: 10.1109/TASLP.2014.2303296 [7] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃.深度学习在控制领域的研究现状与展望.自动化学报, 2016, 42(5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtmlDuan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control:the state of the art and prospects. Acta Automatica Sinica, 2016, 42(5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtml [8] Wu F, Wang Z H, Lu W M, Li X, Yang Y, Luo J B, et al. Regularized deep belief network for image attribute detection. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(7):1464-1477 doi: 10.1109/TCSVT.2016.2539604 [9] Wang B Y, Klabjan D. Regularization for unsupervised deep neural nets. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI, 2017. 2681-2687 [10] Goh H, Thome N, Cord M, Lim J H. Top-down regularization of deep belief networks. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: ACM, 2013. 1878-1886 [11] 李飞, 高晓光, 万开方.基于动态Gibbs采样的RBM训练算法研究.自动化学报, 2016, 42(6):931-942 http://www.aas.net.cn/CN/abstract/abstract18884.shtmlLi Fei, Gao Xiao-Guang, Wan Kai-Fang. Research on RBM training algorithm with dynamic Gibbs sampling. Acta Automatica Sinica, 2016, 42(6):931-942 http://www.aas.net.cn/CN/abstract/abstract18884.shtml [12] 乔俊飞, 王功明, 李晓理, 韩红桂, 柴伟.基于自适应学习率的深度信念网设计与应用.自动化学报, 2017, 43(8):1339-1349 http://www.aas.net.cn/CN/abstract/abstract19108.shtmlQiao Jun-Fei, Wang Gong-Ming, Li Xiao-Li, Han Hong-Gui, Chai Wei. Design and application of deep belief network with adaptive learning rate. Acta Automatica Sinica, 2017, 43(8):1339-1349 http://www.aas.net.cn/CN/abstract/abstract19108.shtml [13] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [14] Salakhutdinov R, Murray I. On the quantitative analysis of deep belief networks. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 872-879 [15] Hinton G E. A practical guide to training restricted Boltzmann machines. Neural Networks: Tricks of the Trade. Berlin, Germany: Springer, 2012. 599-619 [16] Salakhutdinov R, Hinton G. Deep Boltzmann machines. In: Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Florida, USA: PMLR, 2009. 1967-2006 [17] Vincent P, Larochelle H, Lajoie I, Bengio Y, Manzagol P A. Stacked denoising autoencoders:learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Research, 2010, 11:3371-3408 https://dl.acm.org/citation.cfm?id=1953039 [18] Nielsen M. Neural Networks and Deep Learning. Determination Press[Online], available: http://neuralnetworksanddeeplearning.com, February 9, 2018. [19] Tieleman T. Training restricted Boltzmann machines using approximations to the likelihood gradient. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 1064-1071 [20] Tieleman T, Hinton G. Using fast weights to improve persistent contrastive divergence. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Quebec, Canada: ACM, 2009. 1033-1040 [21] Abdel-Hamid O, Deng L, Yu D, Jiang H. Deep segmental neural networks for speech recognition. In: Proceedings of the 14th Annual Conference of the International Speech Communication Association. Lyon, France: International Speech and Communication Association, 2013. 1849-1853 [22] Bengio Y, Thibodeau-Laufer É, Alain G, Yosinski J. Deep generative stochastic networks trainable by backprop. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: JMLR, 2014. 226-234 [23] Wang X S, Ma Y T, Cheng Y H. Domain adaptation network based on hypergraph regularized denoising autoencoder. Artificial Intelligence Review, DOI: 10.1007/s10462-017-9576-0 -

 下载:
下载:



计量
- 文章访问数: 2910
- HTML全文浏览量: 428
- PDF下载量: 413
- 被引次数: 0
