

A Compressed Sensing Algorithm Based on Multi-scale Residual Reconstruction Network
-
摘要: 目前压缩感知系统利用少量测量值使用迭代优化算法重构图像.在重构过程中,迭代重构算法需要进行复杂的迭代运算和较长的重构时间.本文提出了多尺度残差网络结构,利用测量值通过网络重构出图像.网络中引入多尺度扩张卷积层用来提取图像中不同尺度的特征,利用这些特征信息重构高质量图像.最后,将网络的输出与测量值进行优化,使得重构图像在测量矩阵上的投影与测量值更加接近.实验结果表明,本文算法在重构质量和重构时间上均有明显优势.Abstract: In recent years, a small number of measurements and iterative optimization algorithms were exploited in compressed sensing to reconstruct images. In the process of reconstruction, most algorithms based on iteration for compressed sensing image reconstruction suffer from the complicatedly iterative computation and time-consuming. In this paper, we propose a novel multi-scale residual reconstruction network (MSRNet), and exploit the measurements to reconstruct images through the network. The multi-scale dilate convolution layer is introduced in the network to extract the feature of different scales in the image, and the feature information could improve the quality of reconstructed image. Finally, we exploit the output of the network and measurements to optimize our algorithm, so as to make the projection of the reconstructed image closer to the measurements. The experimental results show that the MSRNet requires less running time and has better performance in reconstruction quality than other compressed sensing algorithms.
-
Key words:
- Compressive sensing /
- convolution neural network /
- multi-scale convolution /
- dilate convolution
-
图的同构判定在有机化学、计算机科学和人工智能(机器学习或模式识别中常使用图的邻接矩阵特征值来判定两个对象是否为同一个对象)等领域有着重要的应用[1−3]. 上世纪前半叶, 与图同构相关的问题主要围绕图的邻接矩阵特征值及其应用展开[4], 取得若干重要的理论成果和一批应用成果; 其中一个重要的发现是, 两个互不同构的无向图却具有相同的邻接矩阵特征多项式, 即用邻接矩阵特征多项式判定两个无向图是否同构有时会得出错误的结果[4].
上世纪70年代, Karp和Johnson认为图的同构判定问题是少数几个既不能归类为 P 问题也不能归类为 NP 的问题[1, 3]. 此后, 该问题成为理论计算机领域的公开问题并受到广泛重视. 1982年, Luks给出一个当时最好的两图同构判定算法, 其时间复杂度是$\exp ({\text{O(}}\sqrt {n\log n} {\text{)}}$)[5−6] ($ n $为图的顶点数). 此后40多年来, 几百篇这方面的文章得以在不同的学术期刊上发表[1]. 2015年, Babai[6]在Luks算法的基础上, 给出两图同构判定问题的拟多项式算法, 其时间复杂度是$ \exp ({(\log n)^{{\text{O(1)}}}}) $. Babai的工作虽然是一个重要进展, 但图的同构判定问题是否在多项式时间内可解仍然悬而未决[1, 3].
图的同构判定问题的另一研究路径是设计可执行的判定算法, 大致可以分为传统和非传统两类判定算法. 传统判定算法有两类: 1) 针对一些特殊图[7−8] (如树和极大外平面图)的同构判定算法(如Ullman算法和Schmidt算法等[9]). 2) 针对一般简单图的同构判定算法, 如一些放在因特网上用于测试两图是否同构的程序(如Nauty和Saucy等[3, 6]). 非传统判定算法也有两类: 1) 基于遗传算法和神经网络的智能判定算法. 这些算法将图的同构判定问题转化为一类优化求解问题, 但其判定结果并不完全可靠. 2) 基于DNA计算[9]和量子计算的判定算法. 这类算法虽然高效, 但不能回答图的同构判定是 P 问题还是 NP 问题. 无向连通图的距离矩阵是素矩阵(邻接矩阵一般不是素矩阵), 它具有邻接矩阵所没有的独特性质[10]. 文献[10]揭示了简单无向图同构与距离矩阵同构之间的一般关系, 将基于邻接矩阵的同构判定条件推广到距离矩阵, 给出几个适合一般简单无向图的同构判定条件. 这些条件均是充要条件且均具有多项式时间复杂度. 上述成果是近年来图同构研究方面的一个重要进展.
简单无向图的同构关系可由其距离矩阵的同构关系确定, 但复杂无向图却不能. 其根本原因在于: 复杂无向图中的自环和顶点间的重边对顶点间的距离没有影响[10]; 换言之, 自环数或重边数不同的复杂无向图可能具有完全相同的距离矩阵. 因文献[10]所给的判定条件不能用于复杂无向图, 故寻找和发现复杂无向图的同构判定条件既是必须的也是重要的. 本文的主要贡献是: 1) 针对一般复杂无向图的同构判定问题, 给出了基于邻接矩阵之和的特征多项式判定条件. 2) 针对复杂无向连通图的同构判定问题, 给出了基于距离矩阵特征多项式和邻接矩阵特征多项式的同构判定条件. 将该条件用于复杂无向不连通图的各个连通子图, 就可解决复杂无向不连通图的同构判定问题. 上述两个判定条件均是充要条件且均具有多项式时间复杂度. 此外, 当复杂无向图退化为简单无向图时, 上述两个判定条件仍然适用.
1. 相关概念和预备知识
定义1[4, 11−12]. 图$ G $是一个二元组, 记作$ G = \langle V, E \rangle $, 其中:
1) $ V = \{ {v_1},\;{v_2},\; \cdots ,\;{v_n}\left| {\left| V \right| = n,\;{\text{ 1}} \le n < \infty } \right.\} $, $ {v_i} \in V $称为$ G $的顶点, $ V $称为$ G $的顶点集.
2) $ E = \{ {e_1},\;{e_2},\; \cdots ,\;{e_m}\left| {\left| E \right| = m,\;{\text{ 0}} \le m < \infty } \right.\} $, $ {e_j} \in E $称为$ G $的边, $ E $称为$ G $的边集.
3) $ \forall {e_j} \in E $: $ {e_j} $为无向边时, 称$ G $为无向图, $ {e_j} $为有向边时, 称$ G $为有向图.
4) 连接同一顶点的边称为自环, 两顶点间的多条无向边或多条方向相同的有向边称为重边. 既无自环也无重边的图称为简单图, 否则称为复杂图.
在现有文献报道的复杂无向图中, 每个顶点最多有一个自环. 若无特别声明, 本文讨论的均是顶点最多有一个自环的复杂无向图.
定义2[11−13]. 设$ G = \left\langle {V,\;E} \right\rangle $是无向图, $ V = \{ {v_1}, {v_2},\; \cdots ,\;{v_n}\} $. 若$ {v_i} $和$ {v_j} $之间有$ k $ ($ k = 0,\;1,\; \cdots $)条边, 令$ {a_{ij}} = k $; 称由元素$ {a_{ij}} $构成的矩阵$ A({a_{ij}}) \in {{\bf{R}}^{n \times n}} $为无向图$ G $的邻接矩阵.
定义2既适合简单无向图也适合复杂无向图($ {a_{ij}} \in \{ 0,\;1,\;2,\; \cdots \} $). 无向图的邻接矩阵是非负整数对称矩阵.
定义3[14]. 设$ {I_n} \in {{\bf{R}}^{n \times n}} $为单位矩阵, 交换$ {I_n} $的第$ i $行和第$ j $行(或第$ i $列与第$ j $列)所得的矩阵$ P(i,\;j) $称为对换矩阵, 对换矩阵的乘积称为置换矩阵.
引理1[14]. 对换矩阵和置换矩阵具有如下性质:
1) 置换矩阵的乘积仍是置换矩阵;
2) 设$ Q $是置换矩阵, 则$ \det (Q) = \pm 1 $;
3) 设$ Q $是置换矩阵, 则$ {Q^{\text{T}}} $和$ {Q^{ - 1}} $也是置换矩阵, 且$ {Q^{\text{T}}} = {Q^{ - 1}} $;
4) 置换矩阵是正交矩阵;
5) 置换矩阵是幂幺矩阵, 即若$ Q $是置换矩阵, 则$ {Q^m} = {I_n} $, $ m $是某自然数.
由定义3和引理1可知, 对换矩阵和$ {I_n} $也是置换矩阵.
定义4[10]. 设$ A,\;B \in {{\bf{R}}^{n \times n}} $, $ \Omega \subset {{\bf{R}}^{n \times n}} $为全体$ n $阶置换矩阵的集合. 若存在置换矩阵$ Q \in \Omega $, 使得$ A = {Q^{\text{T}}}BQ $, 则称$ A $与$ B $同构, 记作$ A \cong B $; 此外, 称$ {Q^{\text{T}}}BQ $是对$ B $的同构变换.
图的同构问题可以这样表述: 给定两个图, 当忽略图中顶点标号、顶点间相对位置、边的长短和曲直信息时, 问这两个图是否具有相同的结构?
定义5[4, 12−13]. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_2} = $ $ \langle {V_2}, {E_{\text{2}}} \rangle $是两个图. 若存在一个从$ {V_1} $到$ {V_2} $的一一映射$ g $: $ \forall {v_i},\;{v_j} \in {V_1} $, $ {v_i} $至$ {v_j} $有$ k $条边, 当且仅当$ g({v_i}), g({v_j}) \in {V_2} $, 且$ g({v_i}) $至$ g({v_j}) $也有$ k $条边, 则称$ {G_1} $和$ {G_2} $同构, 记作$ {G_1} \cong {G_2} $.
定义5既适合简单图也适合复杂图($ k \in \{ 0, 1,\;2,\; \cdots \} $).
引理2[10−11]. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_2} = $$ \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个图, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n $, $ A $与$ B $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, 则$ {G_1} \cong {G_2} $的充要条件是存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ A = {Q^{\text{T}}}BQ $.
引理2适合一切无向和有向图. 由定义4和引理2可知, 两图同构与该两图的邻接矩阵同构等价.
定义6[4, 10−13]. 设$ G = \left\langle {V,\;E} \right\rangle $是无向图, $ V = \{ {v_1},\;{v_2},\; \cdots ,\;{v_n}\} $, $ E = \{ {e_1},\;{e_2},\; \cdots ,\;{e_m}\} $: 1) $ G $中顶点与边的交替序列$ W = {v_1}{e_1}{v_2}{e_2} \cdots {v_k}{e_k}{v_{k + 1}} $ ($ k \le n - 1 $)称为$ G $的链, 各边互异的链称为迹, 各顶点互异的链称为路, 当$ W $是路时, $ W $中的边数$ k $称为$ W $的长度, 记作$ k = \left| W \right| $; 2) 设$ {v_i} $和$ {v_j} $是$ V $中任意两个顶点, 当$ {v_i} $和$ {v_j} $之间有$ s $条路$ {W_s}{\text{ }} $时, 称$ d({v_i},\;{v_j}) = $$ \min \{ {k_p} = \left| {{W_p}} \right|\left| {1 \le p \le s} \right.\} $为$ {v_i} $和$ {v_j} $之间的距离; 若$ {v_i} $和$ {v_j} $之间无路($ G $不连通), 约定$ d({v_i},\;{v_j}) = \infty $.
定义7[10, 13]. 设$ G = \left\langle {V,\;E} \right\rangle $是无向图, $ V = \{ {v_1}, {v_2},\; \cdots ,\;{v_n}\} $, $ {d_{ij}} = d({v_i},\;{v_j}) $表示顶点$ {v_i} $和$ {v_j} $($ 1 \le i, j \le n $)之间的距离: 当$ i = j $时, 令$ {d_{ii}} = 0 $; 当$ i \ne j $且$ d({v_i},\;{v_j}) = k $ ($ d({v_i},\;{v_j}) = \infty $)时, 令$ {d_{ij}} = k $$ ({d_{ij}} = \infty ) $, 其中$ k \ge 1 $为正整数, 称由元素$ {d_{ij}} $构成的矩阵$ D({d_{ij}}) \in {{\bf{R}}^{n \times n}} $为无向图$ G $的距离矩阵.
由定义6和定义7可知: 1) 复杂无向图中的自环和顶点间的重边对顶点间的距离没有影响; 2) 当$ G $是无向连通图时, 距离矩阵$ D $是对角线元素均为零而其他元素均为正整数的对称矩阵.
定义8[12−13]. 设$ {G_n} = \left\langle {V,\;E} \right\rangle $是简单无向图, $ V = \{ {v_1},\;{v_2},\; \cdots ,\;{v_n}\} $, $ n \ge 2 $, 若$ \forall i \ne j $, $ {v_i} $和$ {v_j} $之间恰有一条边, 则称$ {G_n} $为无向完全图, 其邻接矩阵记为$ {A_n} $.
由定义2和定义8可知, $ {A_n} $的对角线元素均为0而其他元素均为1. 设$ {G_n} $的距离矩阵为$ {D_n} $, 由定义7可知, $ {D_n} = {A_n} $, 即$ {A_n} $既是$ {G_n} $的邻接矩阵又是$ {G_n} $的距离矩阵.
定义9. 设$ { T} \subset {{\bf{R}}^{n \times n}} $$ (n \ge 2) $表示全体$ n $阶正交矩阵的集合; $ {\Omega ^ - } = \{ - S\left| {S \in \Omega } \right.\} $表示全体$ n $阶负置换矩阵的集合; $ \Phi = \Omega \cup {\Omega ^ - } $表示全体$ n $阶置换矩阵和全体$ n $阶负置换矩阵的并集; $ \Theta = { T} - \Phi $表示$ { T} $中除$ \Phi $之外全体$ n $阶正交矩阵的集合.
由定义9和正交矩阵的性质可知: $ \Theta \cap \Phi = \emptyset $($ \emptyset $为空集), $ \Theta \cup \Phi = { T} $; $ \forall {Q_1},\;{Q_2} \in \Phi $, $ {Q_1}{Q_2} \in \Phi $; $ \forall Q \in \Phi $, $ \forall P \in \Theta $, $ QP,\;{\text{ }}PQ \in \Theta $; $ \forall P \in \Theta $, $ \forall E \in \Phi $, $ \forall Q \in { T} $且$ Q \ne E{P^{\text{T}}} $, $ QP,\;{\text{ }}PQ \in \Theta $.
2. 复杂无向图的同构判定方法
为简便计, $ \forall A \in {{\bf{R}}^{n \times n}} $$ (n \ge 2) $, 本文用$ {f_\lambda }(A) $表示$ A $的特征多项式 $ \det (\lambda {I_n} - A) $, 即$ {f_\lambda }(A) = \det (\lambda {I_n} - A) $.
推论1. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_{\text{2}}} = \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个无向图, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n $, $ A $与$ B $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, 若$ {f_\lambda }(A) \ne {f_\lambda }(B) $, 则$ {G_1} $和$ {G_2} $不同构.
证明. 设$ {f_\lambda }(A) \ne {f_\lambda }(B) $时, $ {G_1} \cong {G_2} $. 由引理2可知, 当$ {G_1} \cong {G_2} $时, 存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ A = {Q^{\text{T}}}BQ $. 由此, $ {f_\lambda }(A) = $ $ {f_\lambda }({Q^{\text{T}}}BQ) = {f_\lambda }(B) $, 与假设相矛盾. 故$ {f_\lambda }(A) \ne {f_\lambda }(B) $时, $ {G_1} $和$ {G_2} $不同构.
□ 推论1既适合简单无向图也适合复杂无向图. 需要强调的是, 即使$ {f_\lambda }(A) = {f_\lambda }(B) $, 也不能保证$ {G_1} $和$ {G_2} $同构. 邻接矩阵特征多项式相等仅是两个无向图同构的必要条件[10, 15].
设$ A({a_{ij}}) \in {{\bf{R}}^{n \times n}} $$ (n \ge 2) $是对称矩阵: 若$ {a_{ij}} $全是正整数, 则称$ A $为正整数对称矩阵; 若$ {a_{ij}} $为零或正整数, 则称$ A $为非负整数对称矩阵.
引理3[10]. 设$ A \in {{\bf{R}}^{n \times n}} $$ (n \ge 2) $是对角线元素均为1而其他元素均为正整数的对称矩阵, 则$ \forall P \in \Theta $, $ {P^{\text{T}}}AP $不是正整数对称矩阵.
引理4[14]. 设$ A \in {{\bf{R}}^{n \times n}} $, 则$ A $为正交矩阵的充要条件是存在正交矩阵$ P \in { T} $, 使得
$$ {P^{\text{T}}}AP = {P^{ - 1}}AP = \left[ {\begin{array}{*{20}{c}} {{I_s}}&{}&{} \\ {}&{ - {I_t}}&{} \\ {}&{}&{{H_\theta }} \end{array}} \right] = {P_\theta } $$ 其中, $ {I_s} $与$ I_{t} $分别是$ s $阶和$ t $阶单位矩阵,
$$ {H_\theta } = \left[ {\begin{array}{*{20}{c}} {\left[ {\begin{array}{*{20}{c}} {\cos {\theta _1}}&{\sin {\theta _1}} \\ { - \sin {\theta _1}}&{\cos {\theta _1}} \end{array}} \right]}&{}&{} \\ {}& \ddots &{} \\ {}&{}&{\left[ {\begin{array}{*{20}{c}} {\cos {\theta _k}}&{\sin {\theta _k}} \\ { - \sin {\theta _k}}&{\cos {\theta _k}} \end{array}} \right]} \end{array}} \right] $$ $ s + t + 2k = n $, $ {\theta _j} \in {\bf{R}} $$ (1 \le j \le k) $为实数.
由正交矩阵的定义可知, $ {P_\theta } $和$ {H_\theta } $均是正交矩阵.
定理1. 设$ A \in {{\bf{R}}^{n \times n}} $$ (n \ge 2) $是对角线元素为0或1而其他元素均为正整数的对称矩阵, 则$ \forall P \in \Theta $, $ {P^{\text{T}}}AP $既不是正整数对称矩阵也不是非负整数对称矩阵.
证明. 当$ A $的对角线元素全为1时, 由引理3可知, $ \forall P \in \Theta $, $ {P^{\text{T}}}AP $不是正整数对称矩阵. 当$ A $的对角线元素全为0时, 设$ B = A + {I_n} $. 由引理3可知, $ \forall P \in \Theta $, $ {P^{\text{T}}}BP $不是正整数对称矩阵. 因$ {P^{\text{T}}}BP = {P^{\text{T}}}AP + {I_n} $, 故$ \forall P \in \Theta $, $ {P^{\text{T}}}AP $不是非负整数对称矩阵. 当$ A $的对角线元素不全为0也不全为1时, 以下用归纳法证明: $ \forall P \in \Theta $, $ {P^{\text{T}}}AP $不是非负整数对称矩阵.
当$ n = 2 $时, 设
$$ A = \left[ {\begin{array}{*{20}{c}} {{\delta _1}}&a \\ a&{{\delta _2}} \end{array}} \right] ,\; P = \left[ {\begin{array}{*{20}{c}} {\cos \theta }&{\sin \theta } \\ { - \sin \theta }&{\cos \theta } \end{array}} \right] $$ 其中, $ {\delta _1},\;{\delta _2} \in \{ 0,\;1\} $, $ {\delta _1} + {\delta _2} = 1 $, $ a \ge 1 $为正整数, $ \theta \in {\bf{R}} $. 设$ {\vartheta _1} = \sin 2\theta $, $ {\vartheta _2} = \cos 2\theta $, $ C = {P^{\text{T}}}AP $, 可得
$$ C = \left[ {\begin{array}{*{20}{c}} {{{\sin }^2}\theta + {\delta _1}{\vartheta _2} - a{\vartheta _1}}&{({\delta _1} - 0.5){\vartheta _1} + a{\vartheta _2}} \\ {({\delta _1} - 0.5){\vartheta _1} + a{\vartheta _2}}&{{{\cos }^2}\theta - {\delta _1}{\vartheta _2} + a{\vartheta _1}} \end{array}} \right] $$ 当$ \theta \ne \pm k\pi $$ (k = 0,\;1,\;2,\; \cdots ) $时, $ P \in \Theta $, $ C $不是非负整数对称矩阵($ C $的元素中有负数或小数). 当$ P \in \Theta $时, 由定义9和引理4可知, 对一切2阶正交矩阵$ E \in \Phi $, $ Z \in {\rm T} $且$ Z \ne E{P^{ - 1}} $, 则: 1) $ {J_1} = ZP \in \Theta $, $ {J_2} = PZ \in \Theta $, $ {J_3} = {Z^{\text{T}}}PZ \in \Theta $; 2) $ J_1^{\text{T}}A{J_1} $, $ J_2^{\text{T}}A{J_2} $, $ J_3^{\text{T}}A{J_3} $均不是非负整数对称矩阵. 由此, 对一切2阶正交矩阵$ J \in \Theta $, $ {J^{\text{T}}}AJ $不是非负整数对称矩阵.
当$ n = 3 $时, 设
$$ A = \left[ {\begin{array}{*{20}{c}} {{\delta _1}}&{{a_1}}&{{a_2}} \\ {{a_1}}&{{\delta _2}}&{{a_3}} \\ {{a_2}}&{{a_3}}&{{\delta _3}} \end{array}} \right] ,\; P = \left[ {\begin{array}{*{20}{c}} \delta &0&0 \\ 0&{\cos \theta }&{\sin \theta } \\ 0&{ - \sin \theta }&{\cos \theta } \end{array}} \right] $$ 其中, $ {\delta _1},\;{\delta _2},\;{\delta _3} \in \{ 0,\;1\} $, $ 1 \le {\delta _1} + {\delta _2} + {\delta _3} \le 2 $, $ {a_i} \ge 1 $ $ (1 \le i \le 3) $为正整数, $ \delta = \pm 1 $, $ \theta \in {\bf{R}} $. 设$ {\vartheta _1} = \sin 2\theta $, $ {\vartheta _2} = \cos 2\theta $, $ \alpha (\theta ) = {a_1}\cos \theta - {a_2}\sin \theta $, $ \beta (\theta ) = {a_1}\sin \theta $ $ +{a_2}\cos \theta $, $ \eta = {\delta _2} - {\delta _3} $, $ \mu (\theta ) = \eta {\sin ^2}\theta $, $ C = {P^{\mathrm{T}}}AP $, 可得
$$ C = \left[ {\begin{array}{*{20}{c}} {{\delta _1}}&{\delta \alpha (\theta )}&{\delta \beta (\theta )} \\ {\delta \alpha (\theta )}&{{\delta _2} - \mu (\theta ) - {a_3}{\vartheta _1}}&{0.5\eta {\vartheta _1} + {a_3}{\vartheta _2}} \\ {\delta \beta (\theta )}&{0.5\eta {\vartheta _1} + {a_3}{\vartheta _2}}&{{\delta _3} + \mu (\theta ) + {a_3}{\vartheta _1}} \end{array}} \right] $$ 当$ \delta = 1 $且 $ \theta \ne \pm 2l\pi $$ (l = 0,\;1,\;2,\; \cdots ) $, 或者$ \delta = - 1 $且$ \theta \ne \pm h\pi $ ($ h $为奇数)时, $ P \in \Theta $, $ C $不是非负整数对称矩阵. 类似$ n = 2 $时的分析可得, 对一切3阶正交矩阵$ J \in \Theta $, $ {J^{\text{T}}}AJ $不是非负整数对称矩阵.
当$ n \ge 4 $时, 设
$$ A = \left[ {\begin{array}{*{20}{c}} {{A_{11}}}&{{A_{12}}}&{{A_{13}}} \\ {A_{12}^{\text{T}}}&{{A_{22}}}&{{A_{23}}} \\ {A_{13}^{\text{T}}}&{A_{23}^{\text{T}}}&{{A_{33}}} \end{array}} \right] ,\; {P_\theta } = \left[ {\begin{array}{*{20}{c}} {{I_s}}&{}&{} \\ {}&{ - {I_t}}&{} \\ {}&{}&{{H_\theta }} \end{array}} \right] $$ 其中, $ {A_{11}} \in {{\bf{R}}^{s \times s}} $、$ {A_{22}} \in {{\bf{R}}^{t \times t}} $和$ {A_{33}} \in {{\bf{R}}^{2k \times 2k}} $均是对角线元素为0或1而其他元素全是正整数的分块对称矩阵; $ {A_{12}} $, $ {A_{13}} $, $ {A_{23}} $均是分块正整数矩阵; $ A $的对角线元素之和满足$ 1 \le \sum\nolimits_i {{a_{ii}}} \le n - 1 $; $ {H_\theta } $为形如引理4中的矩阵, $ s + t + 2k = n $, $ {\theta _j} \in {\bf{R}} $$ (1 \le j \le k) $为实数. 由此,
$$ P_\theta ^{\text{T}}A{P_\theta } = \left[ {\begin{array}{*{20}{c}} {{A_{11}}}&{ - {A_{12}}}&{{A_{13}}{H_\theta }} \\ { - A_{12}^{\text{T}}}&{{A_{22}}}&{ - {A_{23}}{H_\theta }} \\ {H_\theta ^{\text{T}}A_{13}^{\text{T}}}&{ - H_\theta ^{\text{T}}A_{23}^{\text{T}}}&{H_\theta ^{\text{T}}{A_{33}}{H_\theta }} \end{array}} \right] $$ 1) 当$ s = n $, 或$ 1 \le s < n $, $ t = 0 $且所有的$ {\theta _j} = \pm 2l\pi $$ (l = 0,\;1,\;2,\; \cdots ) $, 或$ s = t = 0 $且所有的$ {\theta _j} = \pm 2l\pi $$ (l = 0,\;1,\;2,\; \cdots ) $时, $ {P_\theta } = {I_n} \in \Omega $.
2) 当$ t = n $, 或$ 1 \le t < n $, $ s = 0 $且所有的$ {\theta _j} = \pm h\pi $($ h $为奇数), 或$ t = s = 0 $且所有的$ {\theta _j} = \pm h\pi $($ h $为奇数)时, $ {P_\theta } = - {I_n} \in \Phi $.
3) 当$ s,\;t,\;k $和$ {\theta _j} $$ (1 \le j \le k) $的取值不是上述两种情况时, $ {P_\theta } \in \Theta $, $ P_\theta ^{\text{T}}A{P_\theta } $不是非负整数对称矩阵.
当$ P \in \Theta $时, 由定义9和引理4可知, 对一切$ n \ge 4 $阶正交矩阵$ E \in \Phi $, $ Z \in {T} $且$ Z \ne E{P^{ - 1}} $, 则: a) $ {J_1} = ZP \in \Theta $, $ {J_2} = PZ \in \Theta $, $ {J_3} = {Z^{\text{T}}}PZ \in \Theta $; b) $ J_1^{\text{T}}A{J_1} $, $ J_2^{\text{T}}A{J_2} $, $ J_3^{\text{T}}A{J_3} $均不是非负整数对称矩阵. 由此, 对一切$ n \ge 4 $阶正交矩阵$ J \in \Theta $, $ {J^{\text{T}}}AJ $不是非负整数对称矩阵.
综上可得, $ \forall n \ge 2 $, $ \forall P \in \Theta $, $ {P^{\text{T}}}AP $不是非负整数对称矩阵.
□ 此外, 不难证明, $ \forall n \ge 2 $, $ \forall Q \in \Phi $, $ {Q^{\text{T}}}AQ $是非负整数对称矩阵.
使用定义8中的符号$ {A_n} $和引理2, 可以得到如下推论.
推论2. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_2} = \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个无向图, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n \ge 2 $, $ A $与$ B $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, 则$ {G_1} \cong {G_2} $的充要条件是存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ A + {A_n} = {Q^{\text{T}}}(B + {A_n})Q $.
证明. 设$ A + {A_n} = {Q^{\text{T}}}(B + {A_n})Q $. 由定义3和引理1可知, 置换矩阵$ Q \in \Omega $$ (Q \ne {I_n}) $可表示为$ m $ ($ m \ge 2 $为正整数)个对换矩阵$ P({i_s},\;{j_s}) = {P_s} $的乘积, 即$ Q = P({i_1},\;{j_1}) \cdots P({i_m},\;{j_m}) = {P_1} \cdots {P_m}$. 此外, 不难验证, 任给对换矩阵$ {P_s} $, $ P_s^{\text{T}}{A_n}{P_s} = {A_n} $. 由此可得: $ {Q^{\text{T}}}{A_n}Q = P_m^{\text{T}} \cdots P_1^{\text{T}}{A_n}{P_1} \cdots {P_m} = {A_n} $; $ A\; + {A_n} = $$ {Q^{\text{T}}}(B + {A_n})Q = {Q^{\text{T}}}BQ + {A_n} $; $ A = {Q^{\text{T}}}BQ $. 再由引理2可得, $ {G_1} \cong {G_2} $.
设$ {G_1} \cong {G_2} $. 由引理2可知, 存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ A = {Q^{\text{T}}}BQ $. 由上述充分性证明可知, $ \forall Q \in \Omega $, $ {A_n} = {Q^{\text{T}}}{A_n}Q $. 由此, $ A + {A_n} = {Q^{\text{T}}}(B + {A_n})Q $.
□ 容易理解, 推论2适合一切无向图.
引理5[14]. 设$ C,\;B \in {{\bf{R}}^{n \times n}} $是对称矩阵, 则$ {f_\lambda }(C) = {f_\lambda }(B) $的充要条件是存在$ n $阶正交矩阵$ P \in {T} $, 使得$ C = {P^{\text{T}}}BP $.
基于前面的分析和准备, 下面给出两个无向图的同构判定条件.
定理2. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_2} = \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个无向图, 每个顶点最多有一个自环, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n \ge 2 $, $ {A_1} $与$ {A_2} $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, 则$ {G_1} \cong {G_2} $的充要条件是$ {f_\lambda }({A_1} + {A_n}) = {f_\lambda }({A_2} + {A_n}) $.
证明. 设$ {f_\lambda }({A_1} + {A_n}) = {f_\lambda }({A_2} + {A_n}) $. 给$ {G_1} $和$ {G_2} $中的每两个顶点之间加一条边, 可以得到两个新的无向图$ {\hat G_1} $和$ {\hat G_2} $, 其邻接矩阵分别是$ {A_1} + {A_n} $和$ {A_2} + {A_n} $. 因$ {G_1} $和$ {G_2} $的顶点最多有一个自环, 由定义2可知, $ {A_1} $和$ {A_2} $的对角线元素为0或1 (可以全为0, 也可全为1); 再由定义8可知, $ {A_1} + {A_n} $和$ {A_2} + {A_n} $均是对角线元素为0或1而其他元素均是正整数的对称矩阵, 即$ {A_1} + {A_n} $和$ {A_2} + {A_n} $均是非负整数对称矩阵. 由引理5可知, 当$ {f_\lambda }({A_1} + {A_n}) = {f_\lambda }({A_2} + {A_n}) $时, 存在正交矩阵$ Q \in { T} $, 使得$ {A_1} \;+ {A_n} = {Q^{\text{T}}}({A_2} + {A_n})Q $. 由定理1可知, $ Q \notin \Theta $; 否则, $ {A_1} + {A_n} $将不是非负整数矩阵. 因$ Q \in { T} = \Phi \cup \Theta $且$ Q \notin \Theta $, 故$ Q \in \Phi $. 由此, 存在$ Q \in \Omega $ (或$ - Q \in \Omega $), 使得$ {A_1} + {A_n} = {Q^{\text{T}}}({A_2} + {A_n})Q $; 再由推论2可知, $ {G_1} \cong {G_2} $.
设$ {G_1} \cong {G_2} $. 因$ {G_1} \cong {G_2} $, 故存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ {A_1} = {Q^{\text{T}}}{A_2}Q $. 由推论2的证明结果可知, $ {A_n} = {Q^{\text{T}}}{A_n}Q $. 由此, $ {A_1} + {A_n} = $$ {Q^{\text{T}}}({A_2} + {A_n})Q $, $ {f_\lambda }({A_1} + {A_n}) = {f_\lambda }({A_2} + {A_n}) $.
□ 需要说明的是: 1) 定理2既适合复杂无向图也适合简单无向图, 既适合连通无向图也适合不连通无向图; 一言以蔽之, 定理2适合一切无向图. 2) 因求解特征多项式$ {f_\lambda }(A) $的算法复杂度是$ {\mathrm{O}}({n^3}) $[16−17], 故使用定理2判定两个无向图是否同构的算法复杂度是$ 2{\mathrm{O}}({n^3}) $.
引理6[10]. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_{\text{2}}} = \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个简单无向连通图, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n \ge {\text{2}} $, $ {D_1} $与$ {D_2} $分别是$ {G_1} $和$ {G_2} $的距离矩阵, 则$ {G_1} \cong {G_2} $的充要条件是$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $.
引理7[18]. 设$ C,\;B \in {{\bf{R}}^{n \times n}} $为对称矩阵, 对一切$ 1 \le i \le n $, $ {\lambda _i}(C) $为$ C $的特征值, $ {\lambda _i}(B) $为$ B $的特征值, 则$ \min {\lambda _i}(B) + {\lambda _i}(C) \le {\lambda _i}(C + B) $$ \le {\lambda _i}(C) \;+ \max {\lambda _i}(B) $.
设$ G = \left\langle {V,\;E} \right\rangle $是复杂无向连通图, $ V = \{ {v_1}, {v_2},\; \cdots ,\;{v_n}\} $, $ n \ge 2 $: 1) 除去$ G $中顶点上的自环和邻接顶点间的重边(邻接顶点间仅保留一条边), 可以得到一个简单无向连通图$ {G_1} $(称$ {G_1} $为$ G $的主图). 2) $ \forall i \ne j $, 若$ {v_i} $和$ {v_j} $邻接, 除去$ {v_i} $和$ {v_j} $之间的一条边, 其他保持不变, 可以得到另一个无向图$ {G_2} $(称$ {G_2} $为$ G $的附图). 3) 设$ A $为$ G $的邻接矩阵, $ {A_1} $和$ {A_2} $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, $ D $为$ G $的距离矩阵. 由上述假设可知, $ A = {A_1} + {A_2} $. 因复杂无向图中的自环和顶点间的重边对距离没有影响, 由定义6和定义7可知, $ D $既是$ G $也是$ {G_1} $的距离矩阵.
基于以上的叙述和讨论, 本文给出两个复杂无向图同构的另一个判定条件.
定理3. 设$ {G_{\text{1}}} = \left\langle {{V_{\text{1}}},\;{E_{\text{1}}}} \right\rangle $和$ {G_{\text{2}}} = $$ \left\langle {{V_{\text{2}}},\;{E_{\text{2}}}} \right\rangle $是两个复杂无向连通图, 每个顶点最多有一个自环, $ \left| {{V_1}} \right| = \left| {{V_2}} \right| = n \ge {\text{2}} $, $ {A_1} $与$ {A_2} $分别是$ {G_1} $和$ {G_2} $的邻接矩阵, $ {D_1} $与$ {D_2} $分别是$ {G_1} $和$ {G_2} $的距离矩阵. 则$ {G_1} \cong {G_2} $的充要条件是$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $且$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $.
证明. 设$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $且$ {f_\lambda }({A_1}) = $$ {f_\lambda }({A_2}) $. 另设$ {G_{11}} $与$ {G_{12}} $分别是$ {G_1} $的主图和附图, $ {A_{11}} $与$ {A_{12}} $$ ({A_{12}} \ne 0) $分别是$ {G_{11}} $和$ {G_{12}} $的邻接矩阵; $ {G_{21}} $与$ {G_{22}} $分别是$ {G_2} $的主图和附图, $ {A_{21}} $与$ {A_{22}} $$ ({A_{22}} \ne 0) $分别是$ {G_{21}} $和$ {G_{22}} $的邻接矩阵. 由此, 可得: $ {A_1} = {A_{11}} + {A_{12}} $, $ {A_2} = {A_{21}} + {A_{22}} $; $ {D_1} $既是$ {G_1} $也是$ {G_{11}} $的距离矩阵, $ {D_2} $既是$ {G_2} $也是$ {G_{21}} $的距离矩阵. 由引理6可知, 当$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $时, $ {G_{11}} \cong {G_{21}} $; 再由引理2可知, 存在$ Q \in \Omega $, 使得$ {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $. 因$ {A_1} $和$ {A_2} $均是实对称矩阵, 且$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $, 由引理5可知, 存在$ n $阶正交矩阵$ P \in { T} $, 使得$ {A_1} = {P^{\text{T}}}{A_2}P $, 即$ {A_{11}} + {A_{12}} = {P^{\text{T}}}{A_{21}}P + {P^{\text{T}}}{A_{22}}P $. 综上可知, 当$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $且$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $时
$$ {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $$ (1) 且
$$ {A_{11}} + {A_{12}} = {P^{\text{T}}}{A_{21}}P + {P^{\text{T}}}{A_{22}}P$$ (2) 设$ {A_{12}} = {P^{\text{T}}}{A_{22}}P $, 由式(1)和式(2)可得, $ {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $, $ {A_{11}} = {P^{\text{T}}}{A_{21}}P $, 由此, $ P = Q $. 另由式(2)可得, $ {A_{11}} = {P^{\text{T}}}{A_{21}}P + {P^{\text{T}}}{A_{22}}P - {A_{12}} $.
1) 设$ {H_1} = {P^{\text{T}}}{A_{21}}P $, $ {H_2} = {P^{\text{T}}}{A_{22}}P - {A_{12}} $, 则
$${A_{11}} = {H_1} + {H_2} $$ (3) 因$ {H_1} $和$ {H_2} $均是实对称矩阵且$ \lambda ({H_1}) = \lambda ({A_{21}}) $. 由式(3)和引理7可得
$$ \begin{split} & \min {\lambda _i}({H_2}) + {\lambda _i}({A_{21}}) \le {\lambda _i}({A_{11}}) \le\\& \qquad{\lambda _i}({A_{21}}) +\max {\lambda _i}({H_2}) \end{split} $$ (4) 2) 设$ {A_{12}} \ne {P^{\text{T}}}{A_{22}}P $, 则$ {H_2} \ne 0 $. 因$ {H_2} $是对称矩阵, 故当$ {H_2} \ne 0 $时, $ \lambda ({H_2}) \ne 0 $. 设$ \min {\lambda _i}({H_2}) = \max {\lambda _i}({H_2}) = h $, 由式(4)可得, $ {\lambda _i}({A_{11}}) = {\lambda _i}({A_{21}}) \;+ h $. 若$ \lambda ({A_{11}}) = \lambda ({A_{21}}) $, 则$ h = 0 $, $ \lambda ({H_2}) = 0 $, $ {A_{12}} = {P^{\text{T}}}{A_{22}}P $, 与假设矛盾; 若$ \lambda ({A_{11}}) \ne \lambda ({A_{21}}) $, 则与式(1)矛盾. 设$ {\lambda _i}({A_{11}}) \le $$ {\lambda _i}({A_{21}}) + \max {\lambda _i}({H_2})\; ({\lambda _i}({A_{11}}) \ge {\lambda _i}({A_{21}}) + \min {\lambda _i}({H_2})) $, 若$ \lambda ({A_{11}}) \ne \lambda ({A_{21}}) $, 则与$ {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $矛盾; 若$ \lambda ({A_{11}}) = \lambda ({A_{21}}) $, 则由引理5可得, $ {A_{11}} = {P^{\text{T}}}{A_{21}}P $$ (P \in { T}) $. 由此, ${A_{11}} = {P^{\text{T}}}{A_{21}}P,\; {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $, $ P = Q $. 而当$ P = Q $时, 由式(1)和式(2)可得, $ {A_{12}} = {P^{\text{T}}}{A_{22}}P $, 与$ {A_{12}} \ne {P^{\text{T}}}{A_{22}}P $的假设矛盾. 总之, $ {A_{12}} \ne {P^{\text{T}}}{A_{22}}P $的假设不成立.
综上可知: 当$ {A_{12}} = {P^{\text{T}}}{A_{22}}P $时, $ P = Q $; 由式(2)可得$ {A_1} = {Q^{\text{T}}}{A_2}Q $, 再由引理2可得, $ {G_1} \cong {G_2} $.
设$ {G_1} \cong {G_2} $. 由引理2可知, 存在$ n $阶置换矩阵$ Q \in \Omega $, 使得$ {A_1} = {Q^{\text{T}}}{A_2}Q $. 因$ {G_1} $和$ {G_2} $均是复杂无向连通图, 如充分性证明可设, $ {A_1} = {A_{11}} + {A_{12}} $, $ {A_2} = {A_{21}} + {A_{22}} $, 由此, $ {A_{11}} + {A_{12}} = {Q^{\text{T}}}({A_{21}} + {A_{22}})Q $. 因$ Q $是正交矩阵, 故$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $. 设$ {A_{11}} \ne {Q^{\text{T}}}{A_{21}}Q $, 则简单无向连通图$ {G_{11}} $和$ {G_{21}} $不同构, 进而可得$ {G_1} $和$ {G_2} $不同构, 与假设矛盾. 当$ {A_{11}} = {Q^{\text{T}}}{A_{21}}Q $时, 由引理2可知, $ {G_{11}} \cong {G_{21}} $; 再由引理6可得, $ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $. 综上, 当$ {G_1} \cong {G_2} $时, $ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $且$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $.
□ 比较引理6和定理3可知, 简单无向连通图的同构条件不同于复杂无向连通图的同构条件.
由定理3的证明过程可知, 当定理3中的$ {G_1} $和$ {G_2} $均是简单无向连通图时, $ {G_1} = {G_{11}} $, $ {G_2} = {G_{21}} $, $ {A_{12}} = {A_{22}} = 0 $, $ {A_1} = {A_{11}} $, $ {A_2} = {A_{21}} $. 由引理6可知: 当$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $时, $ {G_1} \cong {G_2} $; 再由引理2可知, 存在$ Q \in \Omega $, 使得$ {A_1} = {Q^{\text{T}}}{A_2}Q $, 进而可得$ {f_\lambda }({A_1}) = {f_\lambda }({A_2}) $. 由此, 当$ {G_1} $和$ {G_2} $均是简单无向连通图时, 定理3中的条件可简化为$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $; 定理3退化为引理6. 这表明定理3也适合简单无向连通图.
因为求解距离矩阵$ D $的算法复杂度是$ {\mathrm{O}}({n^3}) $[12−13], 求解特征多项式的算法复杂度是$ {\mathrm{O}}({n^3}) $[16−17], 故定理3判定条件的算法复杂度是$ 4{\mathrm{O}}({n^3}) $.
设$ {G_1} $和$ {G_2} $是两个复杂无向不连通图且分别由$ m $个连通子图$ {G_{ij}} $$ (i = 1,\;2;{\text{ }}1 \le j \le m) $组成, $ {G_1} $与$ {G_2} $同构是指$ {G_1} $中的连通子图$ {G_{1j}} $与$ {G_2} $中的连通子图$ {G_{2j}} $一一对应同构. 不难理解, 将定理3用于复杂无向不连通图的各个连通子图, 就可解决复杂无向不连通图的同构判定问题.
比较定理2和定理3可知: 1) 定理2适合一切无向图, 而定理3仅适合复杂无向连通图; 2) 若将定理2限定在复杂无向连通图上, 则定理2与定理3等价; 3) 就一般复杂无向图的同构判定问题而言, 定理2比定理3具有更低的算法复杂度, 因此也更便于实际应用.
1) $ {G_1} $和$ {G_2} $均是复杂无向连通图. 设$ {G_1} $和$ {G_2} $的邻接矩阵分别是$ {A_{11}} $和$ {A_{12}} $, 距离矩阵分别是$ {D_1} $和$ {D_2} $. 按图中顶点标号, 经计算可得
$$ {A_{11}} = \left[ {\begin{array}{*{20}{c}} 1&1&1 \\ 1&1&1 \\ 1&1&1 \end{array}} \right] ,\; {A_{12}} = \left[ {\begin{array}{*{20}{c}} 1&1&1 \\ 1&0&2 \\ 1&2&0 \end{array}} \right] $$ $$ {D_1} = {D_2} = \left[ {\begin{array}{*{20}{c}} 0&1&1 \\ 1&0&1 \\ 1&1&0 \end{array}} \right] $$ $$ {f_\lambda }({A_{11}} + {A_3}) = {\lambda ^3} - 3{\lambda ^2} - 9\lambda - 5\qquad\qquad $$ $$ {f_\lambda }({A_{12}} + {A_3}) = {\lambda ^3} - {\lambda ^2} - 17\lambda - 15 \qquad\quad\;\;$$ $$ {f_\lambda }({A_{11}}) = {\lambda ^3} - 3{\lambda ^2}, {f_\lambda }({A_{12}}) = {\lambda ^3} - {\lambda ^2} - 6\lambda$$ 其中, $ {A_3} $是3顶点无向完全图的邻接矩阵.
因$ {f_\lambda }({A_{11}} + {A_3}) \ne {f_\lambda }({A_{12}} + {A_3}) $, 由定理2可以判定$ {G_1} $和$ {G_2} $不同构. 因$ {f_\lambda }({D_1}) = {f_\lambda }({D_2}) $, 但$ {f_\lambda }({A_{11}}) \ne {f_\lambda }({A_{12}}) $, 由推论1和定理3均可判定$ {G_1} $和$ {G_2} $不同构.
2) $ {G_3} $和$ {G_4} $均是复杂无向连通图. 设$ {G_3} $的邻接矩阵和距离矩阵分别是$ {A_{31}} $和$ {D_3} $, $ {G_4} $的邻接矩阵和距离矩阵分别是$ {A_{41}} $和$ {D_4} $. 按图中顶点标号, 经计算可得
$$ {A_{31}} = {A_{41}} = \left[ {\begin{array}{*{20}{c}} 1&0&0&0&0&1&1&1 \\ 0&0&0&0&2&0&1&1 \\ 0&0&0&1&0&1&0&1 \\ 0&0&1&0&1&0&1&0 \\ 0&2&0&1&0&1&0&0 \\ 1&0&1&0&1&0&0&0 \\ 1&1&0&1&0&0&0&0 \\ 1&1&1&0&0&0&0&0 \end{array}} \right] $$ $$ {D_3} = {D_4} = \left[ {\begin{array}{*{20}{c}} 0&2&2&2&2&1&1&1 \\ 2&0&2&2&1&2&1&1 \\ 2&2&0&1&2&1&2&1 \\ 2&2&1&0&1&2&1&2 \\ 2&1&2&1&0&1&2&2 \\ 1&2&1&2&1&0&2&2 \\ 1&1&2&1&2&2&0&2 \\ 1&1&1&2&2&2&2&0 \end{array}} \right] $$ 设$ {A_8} $是8顶点无向完全图的邻接矩阵. 因$ {f_\lambda }({A_{31}} + {A_8}) = {f_\lambda }({A_{41}} + {A_8}) $, 由定理2可以判定$ {G_3} \cong {G_4} $. 因$ {f_\lambda }({D_3}) = {f_\lambda }({D_4}) $且$ {f_\lambda }({A_{31}}) = $$ {f_\lambda }({A_{41}}) $, 故由定理3亦可判定$ {G_3} \cong {G_4} $.
3) $ {G_5} $和$ {G_6} $均是复杂无向连通图. 设$ {G_5} $的邻接矩阵和距离矩阵分别是$ {A_{51}} $和$ {D_5} $, $ {G_6} $的邻接矩阵和距离矩阵分别是$ {A_{61}} $和$ {D_6} $. 按图中顶点标号, 经计算可得
$$ {A_{51}} = {A_{61}} = \left[ {\begin{array}{*{20}{c}} 1&0&0&1&1&1 \\ 0&0&0&1&1&1 \\ 0&0&0&1&1&2 \\ 1&1&1&0&0&0 \\ 1&1&1&0&0&0 \\ 1&1&2&0&0&0 \end{array}} \right] $$ $$ {D_5} = {D_6} = \left[ {\begin{array}{*{20}{c}} 0&2&2&1&1&1 \\ 2&0&2&1&1&1 \\ 2&2&0&1&1&1 \\ 1&1&1&0&2&2 \\ 1&1&1&2&0&2 \\ 1&1&1&2&2&0 \end{array}} \right] $$ 设$ {A_6} $是6顶点无向完全图的邻接矩阵. 因$ {f_\lambda }({A_{51}} + {A_6}) = {f_\lambda }({A_{61}} + {A_6}) $, 由定理2可以判定$ {G_5} \cong {G_6} $. 因$ {f_\lambda }({A_{51}}) = {f_\lambda }({A_{61}}) $且$ {f_\lambda }({D_5}) = $$ {f_\lambda }({D_6}) $, 由定理3亦可判定$ {G_5} \cong {G_6} $.
4) $ {G_7} $和$ {G_8} $均是无向树. 设$ {G_7} $和$ {G_8} $的邻接矩阵分别是$ {A_{71}} $和$ {A_{81}} $, 距离矩阵分别是$ {D_7} $和$ {D_8} $. 按图中顶点标号, 经计算可得
$$ {A_{71}} = \left[ {\begin{array}{*{20}{c}} 0&1&1&1&1&0&0&0 \\ 1&0&0&0&0&1&1&1 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&0&0 \\ 0&1&0&0&0&0&0&0 \\ 0&1&0&0&0&0&0&0 \\ 0&1&0&0&0&0&0&0 \end{array}} \right] \; $$ $$ {A_{81}} = \left[ {\begin{array}{*{20}{c}} 0&1&1&1&1&1&0&0 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&0&0 \\ 1&0&0&0&0&0&1&0 \\ 0&0&0&0&0&1&0&1 \\ 0&0&0&0&0&0&1&0 \end{array}} \right] $$ $$ {D_7} = \left[ {\begin{array}{*{20}{c}} 0&1&1&1&1&2&2&2 \\ 1&0&2&2&2&1&1&1 \\ 1&2&0&2&2&3&3&3 \\ 1&2&2&0&2&3&3&3 \\ 1&2&2&2&0&3&3&3 \\ 2&1&3&3&3&0&2&2 \\ 2&1&3&3&3&2&0&2 \\ 2&1&3&3&3&2&2&0 \end{array}} \right] $$ $$ {D_8} = \left[ {\begin{array}{*{20}{c}} 0&1&1&1&1&1&2&3 \\ 1&0&2&2&2&2&3&4 \\ 1&2&0&2&2&2&3&4 \\ 1&2&2&0&2&2&3&4 \\ 1&2&2&2&0&2&3&4 \\ 1&2&2&2&2&0&1&2 \\ 2&3&3&3&3&1&0&1 \\ 3&4&4&4&4&2&1&0 \end{array}} \right] $$ 设$ {A_8} $是8顶点无向完全图的邻接矩阵, 可得$ \det ({A_{71}} + {A_8}) = 17 $, $ \det ({A_{81}} + {A_8}) = 21 $. 由此, $ {f_\lambda }({A_{71}} + {A_8}) \ne {f_\lambda }({A_{81}} + {A_8}) $, 由定理2可以判定$ {G_7} $和$ {G_8} $不同构. 另外, 还可求得: $ {f_\lambda }({A_{71}}) = {f_\lambda }({A_{81}}) = {\lambda ^8} - 7{\lambda ^6} + 9{\lambda ^4} $; $ \det ({D_7}) = $$- 1\,048$, $\det ({D_8}) = 1\,600$. 因$ \det ({D_7}) \ne \det ({D_8}) $, 故$ {f_\lambda }({D_7}) \ne {f_\lambda }({D_8}) $. 由此, $ {f_\lambda }({A_{71}}) = {f_\lambda }({A_{81}}) $, 但$ {f_\lambda }({D_7}) \ne {f_\lambda }({D_8}) $, 由定理3可以判定$ {G_7} $和$ {G_8} $不同构.
3. 结束语
图的同构关系是一种等价关系, 凡与图的结构相关的分类、聚类、识别和学习等问题均与图的同构判定问题有关. 时至今日, 图的同构判定问题仍然具有重要的理论和应用价值.
文献[10]将基于邻接矩阵的同构判定条件(引理2)推广到简单无向图距离矩阵(引理6和引理7), 解决了简单无向图的同构判定问题. 但引理6和引理7不能用于复杂无向图的同构判定, 原因在于复杂无向图的同构关系不能由其距离矩阵唯一确定.
本文的主要思路和贡献可概括为: 1) 证明了对角线元素为0或1而其他元素均为正整数的对称矩阵在非同构正交变换下不再是非负整数对称矩阵(定理1); 利用无向完全图邻接矩阵在矩阵同构变换下保持不变的特性, 给出了引理2的另一种等价表示(推论2); 基于定理1和推论2, 给出了基于邻接矩阵之和的特征多项式判定条件(定理2). 2) 针对复杂无向连通图的同构判定问题, 使用图及邻接矩阵的分解方法, 给出了基于邻接矩阵特征多项式和距离矩阵特征多项式的同构判定条件(定理3). 将该条件用于复杂无向不连通图的各个连通子图, 就可解决复杂无向不连通图的同构判定问题. 定理2和定理3中的判定条件均是充要条件且均具有多项式时间复杂度. 需要再次说明的是: 定理2所给的判定条件具有一般普适性, 即对任意的简单、复杂(每一顶点最多允许有一个自环)、连通和不连通无向图均适用; 定理3既适合复杂无向连通图也适合简单无向连通图.
与文献[10]中的结果相比, 定理2和定理3是无向图同构研究方面的又一重要进展. 定理2和定理3的另一理论价值表明, 无向图的同构判定问题是 P 问题. 需要说明的是, 虽然我们解决了无向图的同构判定问题, 但有向图的同构判定是 P 问题还是 NP 问题仍然没有得到解决.
今后我们将针对有向图的同构判定问题开展研究, 期望得到一些有理论和实用价值的新结果.
-

图 1 多尺度残差重构网络(MSRNet), s-Dconv表示扩张卷积, $s$ = 1, 2, 4
Fig. 1 Mult-scale residuce recontruction network, s-Dconv denotes s-dilate convolution, here $s$ = 1, 2 and 4
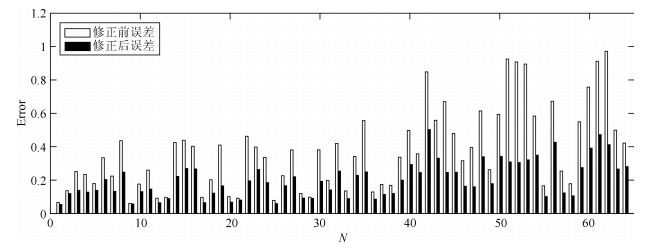
图 4 重构图像块修正前后误差的比较(Barbara图像)
Fig. 4 The comparison of the error of the reconstructed image block before and after refined (Barbara)

图 7 比较几种算法的重构性能(第1行到第3行采样率MR = 0.25, 0.10, 0.04)
Fig. 7 Comparison of reconstruction performance of various algotithms (MR = 0.25, 0.10, 0.04)

图 8 修正前后的重构图像对比(MR = 0.25)
Fig. 8 The comparison of reconstructed images before and after refined (MR = 0.25)
表 1 6幅测试图像在不同算法不同采样率下的PSNR
Table 1 PSNR values in dB for six testing images by different algorithms at different measurement rates
图像 算法 MR = 0.25 MR = 0.10 MR = 0.04 MR = 0.01 w/o BM3D w/BM3D w/o BM3D w/BM3D w/o BM3D w/BM3D w/o BM3D w/BM3D Barbara TVAL3 24.19 24.20 21.88 22.21 18.98 18.98 11.94 11.96 NLR-CS 28.01 28.00 14.80 14.84 11.08 11.56 5.50 5.86 D-AMP 25.08 25.96 21.23 21.23 16.37 16.37 5.48 5.48 ReconNet 23.25 23.52 21.89 22.50 20.38 21.02 18.61 19.08 DR$ ^2 $-Net 25.77 25.99 22.69 22.82 20.70 21.30 18.65 19.10 MSRNet 26.69 26.91 23.04 23.06 21.01 21.28 18.60 18.90 Boats TVAL3 28.81 28.81 23.86 23.86 19.20 19.20 11.86 11.88 NLR-CS 29.11 29.27 14.82 14.86 10.76 11.21 5.38 5.72 D-AMP 29.26 29.26 21.95 21.95 16.01 16.01 5.34 5.34 ReconNet 27.30 27.35 24.15 24.10 21.36 21.62 18.49 18.83 DR$ ^2 $-Net 30.09 30.30 25.58 25.90 22.11 22.50 18.67 18.95 MSRNet 30.74 30.93 26.32 26.50 22.58 22.79 18.65 18.88 Flinstones TVAL3 24.05 24.07 18.88 18.92 14.88 14.91 9.75 9.77 NLR-CS 22.43 22.56 12.18 12.21 8.96 9.29 4.45 4.77 D-AMP 25.02 24.45 16.94 16.82 12.93 13.09 4.33 4.34 ReconNet 22.45 22.59 18.92 19.18 16.30 16.56 13.96 14.08 DR$ ^2 $-Net 26.19 26.77 21.09 21.46 16.93 17.05 14.01 14.18 MSRNet 26.67 26.89 21.72 21.81 17.28 17.40 13.83 14.10 Lena TVAL3 28.67 28.71 24.16 24.18 19.46 19.47 11.87 11.89 NLR-CS 29.39 29.67 15.30 15.33 11.61 11.99 5.95 6.27 D-AMP 28.00 27.41 22.51 22.47 16.52 16.86 5.73 5.96 ReconNet 26.54 26.53 23.83 24.47 21.28 21.82 17.87 18.05 DR$ ^2 $-Net 29.42 29.63 25.39 25.77 22.13 22.73 17.97 18.40 MSRNet 30.21 30.37 26.28 26.41 22.76 23.06 18.06 18.35 Monarch TVAL3 27.77 27.77 21.16 21.16 16.73 16.73 11.09 11.11 NLR-CS 25.91 26.06 14.59 14.67 11.62 11.97 6.38 6.71 D-AMP 26.39 26.55 19.00 19.00 14.57 14.57 6.20 6.20 ReconNet 24.31 25.06 21.10 21.51 18.19 18.32 15.39 15.49 DR$ ^2 $-Net 27.95 28.31 23.10 23.56 18.93 19.23 15.33 15.50 MSRNet 28.90 29.04 23.98 24.17 19.26 19.48 15.41 15.61 Peppers TVAL3 29.62 29.65 22.64 22.65 18.21 18.22 11.35 11.36 NLR-CS 28.89 29.25 14.93 14.99 11.39 11.80 5.77 6.10 D-AMP 29.84 28.58 21.39 21.37 16.13 16.46 5.79 5.85 ReconNet 24.77 25.16 22.15 22.67 19.56 20.00 16.82 16.96 DR$ ^2 $-Net 28.49 29.10 23.73 24.28 20.32 20.78 16.90 17.11 MSRNet 29.51 29.86 24.91 25.18 20.90 21.16 17.10 17.33 平均PSNR TVAL3 27.84 27.87 22.84 22.86 18.39 18.40 11.31 11.34 NLR-CS 28.05 28.19 14.19 14.22 10.58 10.98 5.30 5.62 D-AMP 28.17 27.67 21.14 21.09 15.49 15.67 5.19 5.23 ReconNet 25.54 25.92 22.68 23.23 19.99 20.44 17.27 17.55 DR$ ^2 $-Net 28.66 29.06 24.32 24.71 20.80 21.29 17.44 17.80 MSRNet 29.48 29.67 25.16 25.38 21.41 21.68 17.54 17.82  下载: 导出CSV
下载: 导出CSV
表 2 不同算法下11幅测试图像平均SSIM
Table 2 Mean SSIM values for 11 testing images by different algorithms
算法 MR = 0.01 MR = 0.04 MR = 0.10 MR = 0.25 ReconNet 0.4083 0.5266 0.6416 0.7579 DR$ ^2 $-Net 0.4291 0.5804 0.7174 0.8431 MSRNet 0.4535 0.6167 0.7598 0.8698
下载: 导出CSV
表 3 MSRNet重构图像修正后11幅测试图像的PSNR (dB)和SSIM
Table 3 The PSNR (dB) and SSIM of 11 test images of refined MSRNet reconstruction
图像 MR = 0.25 MR = 0.10 MR = 0.04 PSNR SSIM PSNR SSIM PSNR SSIM Monarch 29.74 0.9189 24.40 0.8078 19.62 0.6400 Parrots 30.13 0.9054 25.15 0.8240 22.06 0.7311 Barbara 27.53 0.8553 23.28 0.6630 21.39 0.5524 Boats 31.63 0.8999 26.73 0.7753 22.86 0.6355 C-man 27.17 0.8433 23.33 0.7400 20.51 0.6378 Fingerprint 28.75 0.9280 23.18 0.7777 18.81 0.5212 Flinstones 27.77 0.8529 22.14 0.7114 17.46 0.4824 Foreman 35.85 0.9297 31.71 0.8740 26.97 0.7939 House 34.15 0.8891 29.55 0.8196 25.60 0.7443 Lena 30.95 0.9019 26.68 0.7965 23.16 0.6882 Peppers 30.67 0.8898 25.43 0.7811 21.28 0.6382 平均值 30.39 0.8922 25.59 0.7791 21.79 0.6423
下载: 导出CSV
表 4 不同卷积方式在图 5的测试集中重构图像的平均PSNR (dB)
Table 4 Mean PSNR in dB for testing set in Fig. 5 by different convolution
卷积形式 MR = 0.01 MR = 0.04 MR = 0.10 MR = 0.25 普通卷积 17.50 21.23 24.79 29.05 扩张卷积 17.54 21.41 25.16 29.48
下载: 导出CSV
表 5 不同卷积方式在BSD500测试集中重构图像平均PSNR (dB)
Table 5 Mean PSNR in dB for BSD500 testing set by different convolution
算法 MR = 0.01 MR = 0.04 MR = 0.10 MR = 0.25 普通卷积 19.34 22.14 24.48 27.78 扩张卷积 19.35 22.25 24.73 27.93
下载: 导出CSV
表 6 重构一幅$ 256 \times 256 $图像的运行时间(s)
Table 6 Time (in seconds) for reconstruction a single $ 256 \times 256 $ image
算法 MR = 0.01 (CPU/GPU) MR = 0.04 (CPU/GPU) MR = 0.10 (CPU/GPU) MR = 0.25 (CPU/GPU) ReconNet 0.5363/0.0107 0.5369/0.0100 0.5366/0.0101 0.5361/0.0105 DR$ ^2 $-Net 1.2039/0.0317 1.2064/0.0317 1.2096/0.0314 1.2176/0.0326 MSRNet 0.4884/0.0121 0.5172/0.0124 0.5152/0.0117 0.5206/0.0126
下载: 导出CSV
表 7 不同算法在BSD500测试集的平均PSNR (dB)和平均SSIM
Table 7 Mean PSNR in dB and SSIM values for BSD500 testing images by different algorithms
模型 MR = 0.01 MR = 0.04 MR = 0.10 MR = 0.25 PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM ReconNet 19.17 0.4247 21.40 0.5149 23.28 0.6121 25.48 0.7241 DR$ ^2 $-Net 19.34 0.4514 21.86 0.5501 24.26 0.6603 27.56 0.7961 MSRNet 19.35 0.4541 22.25 0.5696 24.73 0.6837 27.93 0.8121
下载: 导出CSV
表 8 比较ReconNet、DR$ ^2 $-Net和MSRNet三种算法对高斯噪声的鲁棒性(图 5中11幅测试图像)
Table 8 Comparison of robustness to Gaussian noise among of ReconNet, DR$ ^2 $-Net, MSRNet (11 testing images in Fig. 5)
模型 MR = 0.25 MR = 0.10 $ \sigma $ = 0.01 $ \sigma $ = 0.05 $ \sigma $ = 0.10 $ \sigma $ = 0.25 $ \sigma $ = 0.01 $ \sigma $ = 0.05 $ \sigma $ = 0.10 $ \sigma $ = 0.25 ReconNet 25.44 23.81 20.81 14.15 22.63 21.64 19.54 14.17 DR$ ^2 $-Net 28.49 25.63 21.45 14.32 24.17 22.70 20.04 14.54 MSRNet 29.28 26.50 22.63 18.46 25.06 23.56 21.11 15.46
下载: 导出CSV
表 9 比较ReconNet、DR$ ^2 $-Net和MSRNet三种算法对高斯噪声的鲁棒性(BSD500数据集)
Table 9 Comparison of robustness to Gaussian noise among of ReconNet, DR$ ^2 $-Net, MSRNet (BSD500 dataset)
模型 MR = 0.25 MR = 0.10 $ \sigma $ = 0.01 $ \sigma $ = 0.05 $ \sigma $ = 0.10 $ \sigma $ = 0.25 $ \sigma $ = 0.01 $ \sigma $ = 0.05 $ \sigma $ = 0.10 $ \sigma $ = 0.25 ReconNet 25.38 22.03 20.72 14.03 23.22 22.06 19.85 14.51 DR$ ^2 $-Net 27.40 24.99 21.32 14.47 24.17 22.74 20.26 14.85 MSRNet 27.78 25.53 22.37 18.38 24.67 23.34 21.22 16.37
下载: 导出CSV
-
[1] Donoho D L. Compressed sensing. IEEE Transactions on Information Theory, 2006, 52(4):1289-1306 doi: 10.1109/TIT.2006.871582 [2] Candes E J, Justin R J, Tao T. Robust uncertainty principles:exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory, 2006, 52(2):489-509 doi: 10.1109/TIT.2005.862083 [3] Candes E J, Wakin M B. An introduction to compressive sampling. IEEE Signal Processing Magazine, 2008, 25(2):21-30 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f038caf0ee508db10a5b5fd193679bc2 [4] 任越美, 张艳宁, 李映.压缩感知及其图像处理应用研究进展与展望.自动化学报, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/abstract/abstract18426.shtmlRen Yue-Mei, Zhang Yan-Ning, Li Ying. Advances and perspective on compressed sensing and application on image processing. Acta Automatica Sinica, 2014, 40(8):1563-1575 http://www.aas.net.cn/CN/abstract/abstract18426.shtml [5] Tropp J A, Gilbert A C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Transactions on Information Theory, 2007, 53(12):4655-4666 doi: 10.1109/TIT.2007.909108 [6] Blumensath T, Davies M E. Iterative hard thresholding for compressed sensing. Applied and Computational Harmonic Analysis, 2009, 27(3):265-274 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_0805.0510 [7] Xiao Y H, Yang J F, Yuan X M. Alternating algorithms for total variation image reconstruction from random projections. Inverse Problems and Imaging, 2012, 6(3):547-563 doi: 10.3934/ipi.2012.6.547 [8] Dong W S, Shi G M, Li X, Zhang L, Wu X L. Image reconstruction with locally adaptive sparsity and nonlocal robust regularization. Signal Processing:Image Communication, 2012, 27(10):1109-1122 doi: 10.1016/j.image.2012.09.003 [9] Eldar Y C, Kuppinger P, Bolcskei H. Block-sparse signals:uncertainty relations and efficient recovery. IEEE Transactions on Signal Processing, 2010, 58(6):3042-3054 doi: 10.1109/TSP.2010.2044837 [10] 练秋生, 陈书贞.基于混合基稀疏图像表示的压缩传感图像重构.自动化学报, 2010, 36(3):385-391 http://www.aas.net.cn/CN/abstract/abstract13678.shtmlLian Qiu-Sheng, Chen Shu-Zhen. Image reconstruction for compressed sensing based on the combined sparse image representation. Acta Automatica Sinica, 2010, 36(3):385-391 http://www.aas.net.cn/CN/abstract/abstract13678.shtml [11] 沈燕飞, 李锦涛, 朱珍民, 张勇东, 代锋.基于非局部相似模型的压缩感知图像恢复算法.自动化学报, 2015, 41(2):261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtmlShen Yan-Fei, Li Jin-Tao, Zhu Zhen-Min, Zhang Yong-Dong, Dai Feng. Image reconstruction algorithm of compressed sensing based on nonlocal similarity model. Acta Automatica Sinica, 2015, 41(2):261-272 http://www.aas.net.cn/CN/abstract/abstract18605.shtml [12] Dong C, Loy C C, He K M, Tang X O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(2):295-307 http://d.old.wanfangdata.com.cn/Periodical/jsjfzsjytxxxb201709007 [13] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA:IEEE, 2015. 3431-3440 [14] Zhang K, Zuo W M, Chen Y J, Meng D Y, Zhang L. Beyond a gaussian denoiser:residual learning of deep CNN for image denoising. IEEE Transactions on Image Processing, 2017, 26(7):3142-3155 doi: 10.1109/TIP.2017.2662206 [15] Mousavi A, Patel A B, Baraniuk R G. A deep learning approach to structured signal recovery. In:Proceedings of the 53rd Annual Allerton Conference on Communication, Control, and Computing. Monticello, IL, USA:IEEE, 2015. 1336-1343 [16] Kulkarni K, Lohit S, Turaga P, Kerviche R, Ashok A. ReconNet:non-iterative reconstruction of images from compressively sensed measurements. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA:IEEE, 2016. 449-458 https://ieeexplore.ieee.org/document/7780424/ [17] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA:IEEE, 2016. 770-778 http://www.oalib.com/paper/4016438 [18] Yao H T, Dai F, Zhang D M, Ma Y K, Zhang S L, Zhang Y D, et al. DR2-Net:deep residual reconstruction network for image compressive sensing[Online], available:https://arxiv.org/pdf/1702.05743.pdf, July 6, 2017. [19] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[Online], available:https://arxiv.org/abs/1511.07122, April 30, 2016. [20] Gan L. Block compressed sensing of natural images. In:Proceedings of the 15th International Conference on Digital Signal Processing. Cardiff, UK:IEEE, 2007. 403-406 [21] Kingma D P, Ba J L. Adam:a method for stochastic optimization. In:Proceedings of the 3rd International Conference for Learning Representations. San Diego, USA:Computer Science, 2014. [22] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Communications of the ACM, 2017, 60(6):84-90 doi: 10.1145/3065386 [23] Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Transactions on Image Processing, 2007, 16(8):2080-2095 doi: 10.1109/TIP.2007.901238 [24] Wu J S, Jiang L Y, Han X, Senhadji L, Shu H Z. Performance evaluation of wavelet scattering network in image texture classification in various color spaces. Journal of Southeast University, 2015, 31(1):46-50 http://cn.bing.com/academic/profile?id=c73d072061e32a8b8d31062f4abad153&encoded=0&v=paper_preview&mkt=zh-cn [25] Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z F, Citro C, et al. TensorFlow:large-scale machine learning on heterogeneous distributed systems[Online], available:http://tensorflow.org, September 19, 2017. [26] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In:Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy:JMLR, 2010. 249-256 [27] Li C B, Yin W T, Jiang H, Zhang Y. An efficient augmented lagrangian method with applications to total variation minimization. Computational Optimization & Applications, 2013, 56(3):507-530 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=252968b97ae188abfb677b3e976d5e15 [28] Dong W S, Shi G M, Li X, Ma Y, Huang F. Compressive sensing via nonlocal low-rank regularization. IEEE Transactions on Image Processing, 2014, 23(8):3618-3632 doi: 10.1109/TIP.2014.2329449 [29] Metzler C A, Maleki A, Baraniuk R G. From denoising to compressed sensing. IEEE Transactions on Information Theory, 2016, 62(9):5117-5144 doi: 10.1109/TIT.2016.2556683 -


 下载:
下载:




计量
- 文章访问数: 2991
- HTML全文浏览量: 930
- PDF下载量: 249
- 被引次数: 0
