

-
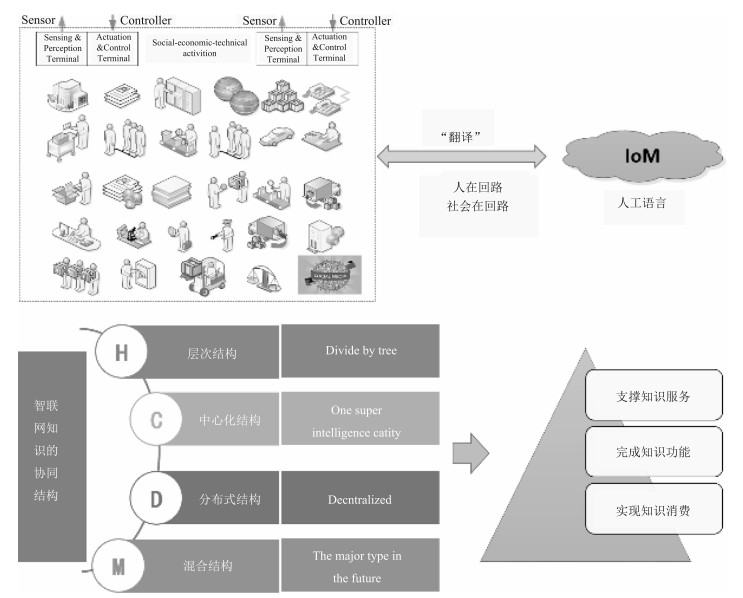
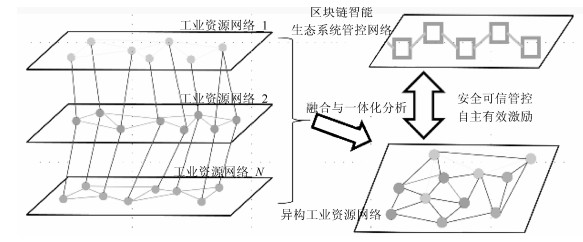
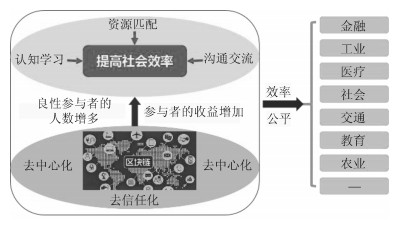
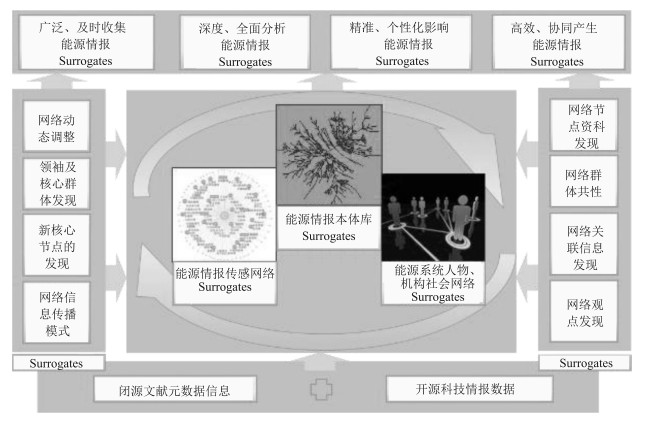
摘要: 本文首先阐述了工业网联技术的演化过程,重点讨论了工业智联网产生的技术和时代背景.然后探讨了工业智联网的基本概念、内涵与应用领域.本文详细介绍了工业智联网的关键技术,包括数字虚拟工业技术、新一代知识工程技术、工业资源异构复杂网络管控技术、区块链智能、社会计算、边缘计算等,及其技术平台架构.最后我们以智能工业新模式和工业系统价值挖掘为示例,举例说明工业智联网的应用模式.Abstract: This article illustrates the concept, technology and applications of industrial internet of minds (ⅡoM). The evolutionary process of inter-connected industrial technology is introduced with emphasis on the background for ⅡoM's emergence. The basic concepts of ⅡoM are explained in details, including digital virtual industrial technology, new-generation knowledge engineering, complex heterogeneous industrial resource networks, blockchain intelligence, social computing, edge computing, etc. Two exemplar applications in intelligent industries and system value mining are used for demonstrating the applicable scenarios of ⅡoM, followed by conclusion remarks.1) 本文责任编委 刘德荣
-

图 1 工业网联技术的演进过程
Fig. 1 The evolutionary process of inter-connected industrial technology
-
[1] P. C. Evans, M. Annunziata. Industrial Internet: Pushing the Boundaries of Minds and Machines[Online], available: https://www.ge.com/docs/chapters/IndustrialInternet.pdf, June 15, 2017. [2] Wikipedia. Kevin Ashton[Online], available: https://en.wikipedia.org/wiki/KevinAshton, September 20, 2017. [3] GE Digital. Everything You Need to Know About the Industrial Internet of Things[Online], available: https://www.ge.com/digital/blog/everything-you-need-knowabout-industrial-internet-things, December 8, 2017. [4] W. Ruh. Why GE Digital Is Positioned To Lead The Industrial Internet Of Things[Online], available: https://www.ge.com/reports/ge-digital-positionedlead-industrial-internet-things-2/, December 19, 2017. [5] 王飞跃, 张俊.智联网:概念、问题和平台.自动化学报, 2017, 43(12):2061-2070 http://www.aas.net.cn/CN/abstract/abstract19181.shtmlWang Fei-Yue, Zhang Jun. Internet of minds:the concept, issues and platforms. Acta Automatica Sinica, 2017, 43(12):2061-2070 http://www.aas.net.cn/CN/abstract/abstract19181.shtml [6] 王飞跃.天命唯新:迈向知识自动化-《自动化学报》创刊50周年专刊序.自动化学报, 2013, 39(11):1741-1743 http://www.aas.net.cn/CN/abstract/abstract18213.shtmlWang Fei-Yue. The destiny:towards knowledge automation-preface of the special issue for the 50th anniversary of Acta Automatica Sinica. Acta Automatica Sinica, 2013, 39(11):1741-1743 http://www.aas.net.cn/CN/abstract/abstract18213.shtml [7] 王飞跃.机器人的未来发展:从工业自动化到知识自动化.科技导报, 2015, 33(21):39-44 http://d.old.wanfangdata.com.cn/Periodical/jqr200105021Wang Fei-Yue. On future development of robotics:from industrial automation to knowledge automation. Science & Technology Review, 2015, 33(21):39-44 http://d.old.wanfangdata.com.cn/Periodical/jqr200105021 [8] Li L, Lin Y L, Zheng N N, Wang F Y. Parallel learning:a perspective and a framework. IEEE/CAA Journal of Automatica Sinica, 2017, 4(3):389-395 doi: 10.1109/JAS.2017.7510493 [9] Wang F Y, Zhang J J, Wang X. Parallel intelligence:toward lifelong and eternal developmental AI and learning in cyber-physical-social spaces. Frontiers of Computer Science, 2018, 12(3):401-405 doi: 10.1007/s11704-018-7903-5 [10] Giacobini M, Brabazon A, Cagnoni S, Di Caro G A, Drechsler R, Ekart A, et al. Applications of Evolutionary Computing. Berlin Heidelberg:Springer-Verlag, 2001. 1-698 [11] Dong M X, Ranjan R, Zomaya A Y, Lin M. Guest editorial on advances in tools and techniques for enabling cyberphysical-social systems-Part Ⅰ. IEEE Transactions on Computational Social Systems, 2015, 2(3):38-40 doi: 10.1109/TCSS.2016.2527158 [12] 王飞跃.软件定义的系统与知识自动化:从牛顿到默顿的平行升华.自动化学报, 2015, 41(1):1-8 doi: 10.3969/j.issn.1003-8930.2015.01.001Wang Fei-Yue. Software-defined systems and knowledge automation:a parallel paradigm shift from Newton to Merton. Acta Automatica Sinica, 2015, 41(1):1-8 doi: 10.3969/j.issn.1003-8930.2015.01.001 [13] 王飞跃, 孙奇, 江国进, 谭珂, 张俊, 侯家琛, 等.核能5.0:智能时代的核电工业新形态与体系架构.自动化学报, 2018, 44(5):922-934 http://www.aas.net.cn/CN/abstract/abstract19283.shtmlWang Fei-Yue, Sun Qi, Jiang Guo-Jin, Tan Ke, Zhang Jun, Hou Jia-Chen, et al. Nuclear energy 5.0:new formation and system architecture of nuclear power industry in the new IT era. Acta Automatica Sinica, 2018, 44(5):922-934 http://www.aas.net.cn/CN/abstract/abstract19283.shtml [14] 张俊, 高文忠, 张应晨, 郑心湖, 杨柳青, 郝君, 等.运行于区块链上的智能分布式电力能源系统:需求、概念、方法以及展望.自动化学报, 2017, 43(9):1544-1554 http://www.aas.net.cn/CN/abstract/abstract19130.shtmlZhang Jun, Gao Wen-Zhong, Zhang Ying-Chen, Zheng XinHu, Yang Liu-Qing, Hao Jun, et al. Blockchain based intelligent distributed electrical energy systems:needs, concepts, approaches and vision. Acta Automatica Sinica, 2017, 43(9):1544-1554 http://www.aas.net.cn/CN/abstract/abstract19130.shtml [15] 平健, 陈思捷, 张宁, 严正, 姚良忠.基于智能合约的配电网去中心化交易机制.中国电机工程学报, 2017, 37(13):3682-3690 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=ZGDC201713004&dbname=CJFD&dbcode=CJFQPing Jian, Chen Si-Jie, Zhang Ning, Yan Zheng, Yao LiangZhong. Decentralized transactive mechanism in distribution network based on smart contract. Proceedings of the CSEE, 2017, 37(13):3682-3690 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=ZGDC201713004&dbname=CJFD&dbcode=CJFQ [16] Zhang J, Wang F Y, Chen S Y. Token economics in energy systems: concept, functionality and applications. eprint arXiv: 1808.01261, 2018. http://econpapers.repec.org/RePEc:arx:papers:1808.01261 [17] Klitgaard T, Reddy R. Lowering electricity prices through deregulation. Current Issues in Economics and Finance, 2000, 6(14):1-6 https://www.mendeley.com/research-papers/lowering-electricity-prices-through-deregulation/ [18] 胡凯, 白晓敏, 高灵超, 董爱强.智能合约的形式化验证方法.信息安全研究, 2016, 2(12):1080-1089 http://d.old.wanfangdata.com.cn/Periodical/xxaqyj201612003Hu Kai, Bai Xiao-Min, Gao Ling-Chao, Dong Ai-Qiang. Formal verification method of smart contract. Journal of Information Securyity Research, 2016, 2(12):1080-1089 http://d.old.wanfangdata.com.cn/Periodical/xxaqyj201612003 [19] 袁勇, 王飞跃.区块链技术发展现状与展望.自动化学报, 2016, 42(4):481-494 http://www.aas.net.cn/CN/abstract/abstract18837.shtmlYuan Yong, Wang Fei-Yue. Blockchain:the state of the art and future trends. Acta Automatica Sinica, 2016, 42(4):481-494 http://www.aas.net.cn/CN/abstract/abstract18837.shtml [20] Wang F Y. Social computing:concepts, contents, and methods. International Journal of Intelligent Control and Systems, 2004, 9(2):91-96 http://d.old.wanfangdata.com.cn/Periodical/zgtsgxb201203013 [21] 王飞跃.社会计算的意义及其展望.中国计算机学会通讯, 2006, 2(2):8-17Wang Fei-Yue. The significance of social computing and its prospects. Communications of CCF, 2006, 2(2):8-17 [22] 王飞跃.人工社会、计算实验、平行系统一关于复杂社会经济系统计算研究的讨论.复杂系统与复杂性科学, 2004, 1(4):25-35 doi: 10.3969/j.issn.1672-3813.2004.04.002Wang Fei-Yue. Artificial societies, computational experiments, and systems:a discussion on computational theory of complex social-economic systems. Complex Systems and Complexity Science, 2004, 1(4):25-35 doi: 10.3969/j.issn.1672-3813.2004.04.002 [23] Wang F Y. Toward a paradigm shift in social computing:the ACP approach. IEEE Intelligent Systems, 2007, 22(5):65-67 doi: 10.1109/MIS.2007.4338496 [24] Lazer D, Pentland A, Adamic L, Aral S, Barabasi A-L, Brewer D, et al. Social science:computational social science. Science, 2009, 323(5915):721-723 doi: 10.1126/science.1167742 [25] Schuler D. Social computing. Communications of the ACM, 1994, 37(1):28-29 doi: 10.1145/175222.175223 [26] Yang Q, Zhou Z H, Mao W J, Li W, Liu N N. Social learning. IEEE Intelligent Systems, 2010, 25(4):9-11 doi: 10.1109/MIS.2010.103 [27] Leskovec J, Huttenlocher D, Kleinberg J. Predicting positive and negative links in online social networks. In: Proceedings of the 19th International Conferences on World Wide Web. Raleigh, North Carolina: ACM, 2010. 641-650 http://www.mendeley.com/catalog/predicting-positive-negative-links-online-social-networks/ [28] Satyanarayanan M. The emergence of edge computing. Computer, 2017, 50(1):30-39 doi: 10.1109/MC.2017.9 [29] Shi W S, Cao J, Zhang Q, Li Y Z, Xu L Y. Edge computing:vision and challenges. IEEE Internet of Things Journal, 2016, 3(5):637-646 doi: 10.1109/JIOT.2016.2579198 [30] Shi W S, Dustdar S. The promise of edge computing. Computer, 2016, 49(5):78-81 doi: 10.1109/MC.2016.145 [31] 施巍松, 孙辉, 曹杰, 张权, 刘伟.边缘计算:万物互联时代新型计算模型.计算机研究与发展, 2017, 54(5):907-924 http://d.old.wanfangdata.com.cn/Periodical/zdhbl201709030Shi Wei-Song, Sun Hui, Cao Jie, Zhang Quan, Liu Wei. Edge computing-an emerging computing model for the internet of everything era. Journal of Computer Research and Development, 2017, 54(5):907-924 http://d.old.wanfangdata.com.cn/Periodical/zdhbl201709030 [32] Edge Computing Consortium. White Paper of Edge Computing Consortium[Online], available: http://www.ecconsortium.net/Uploads/file/20161208/1481181867831374.pdf, June 15, 2017. -

 下载:
下载:



图(12)
计量
- 文章访问数: 4217
- HTML全文浏览量: 589
- PDF下载量: 1636
- 被引次数: 0
