

-
摘要: 生成式对抗网络(Generative adversarial networks,GAN)是当前人工智能学界最为重要的研究热点之一.其突出的生成能力不仅可用于生成各类图像和自然语言数据,还启发和推动了各类半监督学习和无监督学习任务的发展.本文概括了GAN的基本思想,并对近年来相关的理论与应用研究进行了梳理,总结了GAN常见的网络结构与训练方法,博弈形式,集成方法,并对一些应用场景进行了介绍.在此基础上,本文对GAN发展的内在逻辑进行了归纳总结.Abstract: Recently, generative adversarial networks (GAN) have become one of the most popular topics in artificial intelligent field. Its outstanding capability of generating realistic samples not only revived the research of generative model, but also inspired the research of semi-supervised learning and unsupervised learning. In this paper, we introduce the basic idea of GAN, and comb its recent development in theory and practice. By concluding its improvements of network structures, optimization methods, the form of the game, the ensemble methods, and its applications, we found the inner logic of its development.
-
-
-
[1] Murphy K P. Machine Learning: A Probabilistic Perspective. Cambridge: MIT Press, 2012. [2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classiflcation with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: ACM, 2012. 1097-1105 [3] Farabet C, Couprie C, Najman L, LeCun Y. Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1915-1929 doi: 10.1109/TPAMI.2012.231 [4] Mikolov T, Deoras A, Povey D, Burget L, Cernocky J. Strategies for training large scale neural network language models. In: Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding. Waikoloa, HI, USA: IEEE, 2011. 196-201 [5] Hinton G, Deng L, Yu D, Dahl G E, Mohamed A R, Jaitly N, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine, 2012, 29(6): 82-97 doi: 10.1109/MSP.2012.2205597 [6] Collobert R, Weston J, Bottou L, Karlen M, Kavukcuoglu K, Kuksa P. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 2011, 12: 2493-2537 http://www.inf.ed.ac.uk/teaching/courses/tnlp/2014/Ryan.pdf [7] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3104-3112 [8] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 doi: 10.1162/neco.2006.18.7.1527 [9] Salakhutdinov R, Hinton G. Deep Boltzmann machines. In: Proceedings of the 12th International Conference on Artiflcial Intelligence and Statistics. Clearwater Beach, Florida, USA: AISTATS, 2009. 448-455 [10] Smolensky P. Information processing in dynamical systems: Foundations of harmony theory. Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Cambridge, MA, USA: MIT Press, 1986. [11] Hinton G E, Zemel R S. Autoencoders, minimum description length and Helmholtz free energy. In: Proceedings of the 6th International Conference on Neural Information Processing Systems. Denver, Colorado, USA: Morgan Kaufmann Publishers Inc., 1994. 3-10 [12] Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. In: Proceedings of the 21st Annual Conference on Neural Information Processing Systems. Vancouver, BC, Canada: MIT Press, 2007. 153-160 [13] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, WardeFarley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [14] Goodfellow I. NIPS 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv: 1701. 00160, 2016 [15] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3): 321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks: The state of the art and beyond. Acta Automatica Sinica, 2017, 43(3): 321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [16] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [17] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533-536 doi: 10.1038/323533a0 [18] Le Cun Y, Boser B, Denker J S, Howard R E, Habbard W, Jackel L D, et al. Handwritten digit recognition with a back-propagation network. In: Proceedings of the 1990 Advances in Neural Information Processing Systems. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1990. 396-404 [19] Lecun Y, Bottou L, Bengio Y, Hafiner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324 doi: 10.1109/5.726791 [20] Hochreiter S. Untersuchungen zu dynamischen neuronalen Netzen[Ph. D. dissertation], Technische Universitt München, München, Germany, 1991 [21] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 1994, 5(2): 157-166 doi: 10.1109/72.279181 [22] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [23] Nair V, Hinton G E. Rectifled linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel: Omni Press, 2010. 807-814 [24] Srivastava N, Hinton G E, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: A simple way to prevent neural networks from overfltting. Journal of Machine Learning Research, 2014, 15(1): 1929-1958 [25] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv: 1412. 6980, 2014 [26] Chellapilla K, Puri S, Simard P. High performance convolutional neural networks for document processing. In: Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition. La Baule, France: Suvisoft, 2006. [27] Lacey G, Taylor G W, Areibi S. Deep learning on FPGAs: Past, present, and future. arXiv preprint arXiv: 1602. 04283, 2016 [28] Jouppi N P, Young C, Patil N, Patterson D, Agrawal G, Bajwa R, et al. In-datacenter performance analysis of a tensor processing unit. In: Proceedings of the 44th Annual International Symposium on Computer Architecture. Toronto, ON, Canada: ACM, 2017. 1-12 [29] Dean J, Corrado G S, Monga R, Chen K, Devin M, Le Q V, et al. Large scale distributed deep networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012. 1223-1231 [30] Bergstra J, Bastien F, Breuleux O, Lamblin P, Pascanu R, Delalleau O, et al. Theano: Deep learning on GPUs with python. Journal of Machine Learning Research, 2011, 1: 1-48 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.678.1889 [31] Collobert R, Kavukcuoglu K, Farabet C. Torch7: A Matlab-like environment for machine learning. In: BigLearn, NIPS Workshop. Martigny, Switzerland: Idiap Research Institute, 2011 [32] Paszke A, Gross S, Chintala S, Chanan G. PyTorch: Tensors and dynamic neural networks in Python with strong GPU acceleration[Online], available: http://pytorch.org/, April 31, 2018 [33] Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z F, Citro C, et al. TensorFlow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv: 1603. 04467, 2016 [34] Li F F, Deng J. ImageNet: Where are we going? and where have we been?. In: Presented at the 2017 Conference on Computer Vision and Pattern Recognition[Online], available: https://www.youtube.com/watch?v=jYvBmJo7qjc, April 31, 2018 [35] Hastie T, Tibshirani R, Friedman J. Unsupervised learning. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York, NY, USA: Springer, 2009. 485-585 [36] Bengio Y. Learning deep architectures for AI. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127 http://www.docin.com/p-1661610042.html [37] Werbos P J. Learning how the world works: Speciflcations for predictive networks in robots and brains. In: Proceedings of IEEE International Conference on Systems, Man and Cybernetics. New York, NY, USA: IEEE, 1987. [38] Opper M, Archambeau C. The variational Gaussian approximation revisited. Neural Computation, 2009, 21(3): 786-792 doi: 10.1162/neco.2008.08-07-592 [39] Kingma D P, Welling M. Auto-encoding variational Bayes. arXiv preprint arXiv: 1312. 6114, 2013 [40] Arjovsky M, Bottou L. Towards principled methods for training generative adversarial networks. arXiv preprint arXiv: 1701. 04862, 2017 [41] Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X. Improved techniques for training GANs. arXiv preprint arXiv: 1606. 03498, 2016 [42] Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. arXiv preprint arXiv: 1706. 08500, 2017 [43] Miyato T, Kataoka T, Koyama M, Yoshida Y. Spectral normalization for generative adversarial networks. arXiv preprint arXiv: 1802. 05957, 2018 [44] Papineni K, Roukos S, Ward T, Zhu W J. BLEU: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, PA, USA: ACL, 2002. 311-318 [45] Lucic M, Kurach K, Michalski M, Gelly S, Bousquet O. Are GANs created equal? A large-scale study. arXiv preprint arXiv: 1711. 10337, 2017 [46] Theis L, van den Oord A, Bethge M. A note on the evaluation of generative models. arXiv preprint arXiv: 1511. 01844, 2015 [47] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv: 1511. 06434, 2015 [48] Zeiler M D, Taylor G W, Fergus R. Adaptive deconvolutional networks for mid and high level feature learning. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 2018-2025 [49] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411. 1784, 2014 [50] Odena A, Olah C, Shlens J. Conditional image synthesis with auxiliary classifler GANs. arXiv preprint arXiv: 1610. 09585, 2016 [51] Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 2172-2180 [52] Larsen A B L, Sonderby S K, Larochelle H, Winther O. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv: 1512. 09300, 2015 [53] Warde-Farley D, Bengio Y. Improving generative adversarial networks with denoising feature matching. In: International Conference on Learning Representations. 2017 [54] Nguyen A, Clune J, Bengio Y, Dosovitskiy A, Yosinski J. Plug & play generative networks: Conditional iterative generation of images in latent space. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 3510-3520 [55] Rosca M, Lakshminarayanan B, Warde-Farley D, Mohamed S. Variational Approaches for auto-encoding generative adversarial networks. arXiv preprint arXiv: 1706. 04987, 2017 [56] Wu J J, Zhang C K, Xue T F, Freeman B, Tenenbaum J. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 82-90 [57] Iofie S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: PMLR, 2015. 448-456 [58] Salimans T, Kingma D P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 901-909 [59] Xiang S T, Li H. On the efiects of batch and weight normalization in generative adversarial networks. arXiv preprint arXiv: 1704. 03971, 2017 [60] Dietterich T G. Ensemble methods in machine learning. Multiple Classifler Systems. Berlin, Heidelberg, Germany: Springer, 2000. 1-15 [61] Zhou Z H, Wu J X, Tang W. Ensembling neural networks: Many could be better than all. Artiflcial Intelligence, 2002, 137(1): 239-263 https://core.ac.uk/download/pdf/82151182.pdf [62] Tolstikhin I, Gelly S, Bousquet O, Simon-Gabriel C J, Schölkopf B. AdaGAN: Boosting generative models. arXiv preprint arXiv: 1701. 02386, 2017 [63] Huang X, Li Y X, Poursaeed O, Hopcroft J, Belongie S. Stacked generative adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. [64] Denton E, Chintala S, Szlam A, Fergus R. Deep generative image models using a Laplacian pyramid of adversarial networks. In: Proceedings of the 29th Annual Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates, Inc., 2015. 1486-1494 [65] Karras T, Aila T, Laine S, Lehtinen J. Progressive Growing of GANs for improved quality, stability, and variation. arXiv preprint arXiv: 1710. 10196, 2017 [66] Liu M Y, Tuzel O. Coupled generative adversarial networks. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 469-477 [67] Ghosh A, Kulharia V, Namboodiri V, Torr P H S, Dokania P K. Multi-agent diverse generative adversarial networks. arXiv preprint arXiv: 1704. 02906, 2017 [68] Mescheder L, Nowozin S, Geiger A. The Numerics of GANs. arXiv preprint arXiv: 1705. 10461, 2017 [69] Sutton R S, McAllester D A, Singh S P, Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Proceedings of the 12th International Conference on Neural Information Processing Systems. Denver, CO, USA: MIT Press, 1999. 1057-1063 [70] Grondman I, Busoniu L, Lopes G A D, Babuska R. A survey of actor-critic reinforcement learning: Standard and natural policy gradients. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2012, 42(6): 1291-1307 doi: 10.1109/TSMCC.2012.2218595 [71] Pfau D, Vinyals O. Connecting generative adversarial networks and actor-critic methods. arXiv preprint arXiv: 1610. 01945, 2016 [72] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge, UK: MIT Press, 1998. [73] Goodfellow I. AMA (Ask Me Anything) about the GANs (Generative Adversarial Nets) paper[Online], available: https://fermatslibrary.com/arxivcomments?url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdf, April 31, 2018 [74] Williams R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 1992, 8(3-4): 229-256 doi: 10.1007/BF00992696 [75] Yu L T, Zhang W N, Wang J, Yu Y. SeqGAN: Sequence generative adversarial nets with policy gradient. arXiv preprint arXiv: 1609. 05473, 2016 [76] Fedus W, Goodfellow I, Dai A M. MaskGAN: Better text generation via fllling in the. arXiv preprint arXiv: 1801. 07736, 2018 [77] Ganin Y, Kulkarni T, Babuschkin I, Eslami S M A, Vinyals O. Synthesizing programs for images using reinforced adversarial learning. arXiv preprint arXiv: 1804. 01118, 2018 [78] Goodfellow I J. On distinguishability criteria for estimating generative models. arXiv preprint arXiv: 1412. 6515, 2014 [79] Arora S, Ge R, Liang Y Y, Ma T Y, Zhang Y. Generalization and equilibrium in generative adversarial nets (GANs). arXiv preprint arXiv: 1703. 00573, 2017 [80] Qi G J. Loss-sensitive generative adversarial networks on Lipschitz densities. arXiv preprint arXiv: 1701. 06264, 2017 [81] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. arXiv preprint arXiv: 1701. 07875, 2017 [82] Rachev S T, R M. Duality Theorems For Kantorovich-Rubinstein And Wasserstein Functionals. Warszawa: Instytut Matematyczny Polskiej Akademi Nauk, 1990. [83] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A. Improved training of wasserstein GANs. arXiv preprint arXiv: 1704. 00028, 2017 [84] Zhao J B, Mathieu M, LeCun Y. Energy-based generative adversarial network. arXiv preprint arXiv: 1609. 03126, 2016 [85] Wang R H, Cully A, Chang H J, Demiris Y. MAGAN: Margin adaptation for generative adversarial networks. arXiv preprint arXiv: 1704. 03817, 2017 [86] Iizuka S, Simo-Serra E, Ishikawa H. Globally and locally consistent image completion. ACM Transactions on Graphics, 2017, 36(4): Article No. 107 https://www.cs.siue.edu/~wwhite/CS482/SIGGRAPHPapers/107-0331-iizuka.pdf [87] Li Y J, Liu S F, Yang J M, Yang M H. Generative face completion. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 5892-5900 [88] Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image superresolution using a generative adversarial network. arXiv preprint arXiv: 1609. 04802, 2016 [89] Lotter W, Kreiman G, Cox D. Unsupervised learning of visual structure using predictive generative networks. arXiv preprint arXiv: 1511. 06380, 2015 [90] Lotter W, Kreiman G, Cox D. Deep predictive coding networks for video prediction and unsupervised learning. arXiv preprint arXiv: 1605. 08104, 2016 [91] Kupyn O, Budzan V, Mykhailych M, Mishkin D, Matas J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. arXiv preprint arXiv: 1711. 07064, 2017 [92] Huang J B, Kang S B, Ahuja N, Kopf J. Image completion using planar structure guidance. ACM Transactions on Graphics, 2014, 33(4): Article No. 129 http://www.academia.edu/7162612/Image_Completion_using_Planar_Structure_Guidance [93] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. arXiv preprint arXiv: 1412. 6572, 2014 [94] Papernot N, Carlini N, Goodfellow I, Feinman R, Faghri F, Matyasko A, et al. cleverhans v2. 0. 0: An adversarial machine learning library. arXiv preprint arXiv: 1610. 00768, 2016 [95] Yang C F, Wu Q, Li H, Chen Y R. Generative poisoning attack method against neural networks. arXiv preprint arXiv: 1703. 01340, 2017 [96] Shen S, Jin G, Gao K, Zhang Y. APE-GAN: Adversarial Perturbation Elimination with GAN. arXiv preprint arXiv: 1707. 05474, 2017. [97] Lee H, Han S, Lee J. Generative adversarial trainer: Defense to adversarial perturbations with GAN. arXiv preprint arXiv: 1705. 03387, 2017 [98] Johnson-Roberson M, Barto C, Mehta R, Sridhar S N, Rosaen K, Vasudevan R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? In: Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Singapore: Institute of Electrical and Electronics Engineers Inc., 2017. 746-753 [99] Bousmalis K, Silberman N, Dohan D, Erhan D, Krishnan D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 95-104 [100] Shrivastava A, Pflster T, Tuzel O, Susskind J, Wang W D, Webb R. Learning from simulated and unsupervised images through adversarial training. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 2242-2251 [101] Bousmalis K, Irpan A, Wohlhart P, Bai Y F, Kelcey M, Kalakrishnan M, et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping. arXiv preprint arXiv: 1709. 07857, 2017 [102] Santana E, Hotz G. Learning a driving simulator. arXiv preprint arXiv: 1608. 01230, 2016 [103] Huang V, Ley T, Vlachou-Konchylaki M, Hu W F. Enhanced experience replay generation for efficient reinforcement learning. arXiv preprint arXiv: 1705. 08245, 2017 [104] Wang K F, Gou C, Zheng N N, Rehg J M, Wang F Y. Parallel vision for perception and understanding of complex scenes: Methods, framework, and perspectives. Artiflcial Intelligence Review, 2017, 48(3): 299-329 doi: 10.1007/s10462-017-9569-z [105] Yu Y, Qu W Y, Li N, Guo Z M. Open-category classiflcation by adversarial sample generation. arXiv preprint arXiv: 1705. 08722, 2017 [106] Odena A. Semi-supervised learning with generative adversarial networks. arXiv preprint arXiv: 1606. 01583, 2016 [107] Lamb A M, Goyal A, Zhang Y, Zhang S Z, Courville A, Bengio Y. Professor forcing: A new algorithm for training recurrent networks. In: Proceedings of the 29th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 4601-4609 [108] Johnson J, Gupta A, Fei-Fei L. Image generation from scene graphs. arXiv preprint arXiv: 1804. 01622, 2018 [109] Reed S, Akata Z, Yan X C, Logeswaran L, Schiele B, Lee H. Generative adversarial text to image synthesis. arXiv preprint arXiv: 1605. 05396, 2016 [110] Zhu J Y, Krähenbühl P, Shechtman E, Efros A A. Generative visual manipulation on the natural image manifold. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 597-613 [111] Brock A, Lim T, Ritchie J M, Weston N. Neural photo editing with introspective adversarial networks. arXiv preprint arXiv: 1609. 07093, 2016 [112] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv: 1611. 07004, 2016 [113] Wang T C, Liu M Y, Zhu J Y, Tao A, Kautz J, Catanzaro B. High-resolution image synthesis and semantic manipulation with conditional GANs. arXiv preprint arXiv: 1711. 11585, 2017 [114] He D, Xia Y, Qin T, Wang L W, Yu N H, Liu T Y, et al. Dual learning for machine translation. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 820-828 [115] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-toimage translation using cycle-consistent adversarial networks. arXiv preprint arXiv: 1703. 10593, 2017 [116] Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style. arXiv preprint arXiv: 1508. 06576, 2015 [117] Ho J, Ermon S. Generative adversarial imitation learning. arXiv preprint arXiv: 1606. 03476, 2016 [118] Ng A Y, Russell S J. Algorithms for inverse reinforcement learning. In: Proceedings of the 17th International Conference on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2000. 663-670 [119] Ziebart B D, Maas A L, Bagnell J A, Dey A K. Maximum Entropy Inverse Reinforcement Learning. In: Proceedings of the 23rd National Conference on Artiflcial Intelligence. Chicago, Illinois: AAAI, 2008. 1433-1438 [120] Ratlifi N D, Silver D, Bagnell J A. Learning to search: Functional gradient techniques for imitation learning. Autonomous Robots, 2009, 27(1): 25-53 doi: 10.1007/s10514-009-9121-3 [121] Kuefler A, Morton J, Wheeler T, Kochenderfer M. Imitating driver behavior with generative adversarial networks. In: Proceedings of the 2017 IEEE Intelligent Vehicles Symposium. Los Angeles, CA, USA: IEEE, 2017 [122] Wang Z Y, Merel J, Reed S, Wayne G, de Freitas N, Heess N. Robust imitation of diverse behaviors. arXiv preprint arXiv: 1707. 02747, 2017 [123] Wang J, Yu L T, Zhang W N, Gong Y, Xu Y H, Wang B Y, et al. IRGAN: A minimax game for unifying generative and discriminative information retrieval models. In: Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. Shinjuku, Tokyo, Japan: ACM, 2017. 515-524 [124] Frakes, W B, Baeza-Yates R, (Eds. ). Information Retrieval: Data Structures And Algorithms (Vol. 331). Englewood Clifis, New Jersey: prentice Hall, 1992. [125] Hu W W, Tan Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv preprint arXiv: 1702. 05983, 2017 [126] Gupta A, Zou J. Feedback GAN (FBGAN) for DNA: A novel feedback-loop architecture for optimizing protein functions. arXiv preprint arXiv: 1804. 01694, 2018 [127] Wang H W, Wang J, Wang J L, Zhao M, Zhang W N, Zhang F Z, et al. GraphGAN: Graph representation learning with generative adversarial nets. arXiv preprint arXiv: 1711. 08267, 2017 [128] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550(7676): 354-359 doi: 10.1038/nature24270 [129] Wang F Y, Zhang J J, Zheng X H, Wang X, Yuan Y, Dai X X, et al. Where does AlphaGo go: From church-turing thesis to AlphaGo thesis and beyond. IEEE/CAA Journal of Automatica Sinica, 2016, 3(2): 113-120 doi: 10.1109/JAS.2016.7471613 [130] Li L, Lin Y L, Zheng N N, Wang F Y. Parallel learning: A perspective and a framework. IEEE/CAA Journal of Automatica Sinica, 2017, 4(3): 389-395 doi: 10.1109/JAS.2017.7510493 [131] Lin Y L, Li L, Dai X Y, Zheng N N, Wang F Y. Master general parking skill via deep learning. In: Proceedings of the 2017 IEEE Intelligent Vehicles Symposium. Los Angeles, CA, USA: IEEE, 2017. [132] Wang F Y, Zheng N N, Cao D P, Martinez C M, Li L, Liu T. Parallel driving in CPSS: A unifled approach for transport automation and vehicle intelligence. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 577-587 doi: 10.1109/JAS.2017.7510598 [133] 王飞跃.生成式对抗网络的研究进展与展望.中国计算机学会通讯, 2017, 13(11): 58-62 https://www.researchgate.net/profile/Fei_Yue_Wang/publication/320827081_shengchengshiduikangwangluoGAN_deyanjiujinzhanyuzhanwang/links/59fc140ca6fdcca1f2931a80/shengchengshiduikangwangluoGAN-deyanjiujinzhanyuzhanwang.pdf -

 下载:
下载:








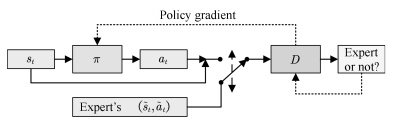


图(19)
计量
- 文章访问数: 5224
- HTML全文浏览量: 1240
- PDF下载量: 4568
- 被引次数: 0
