

-
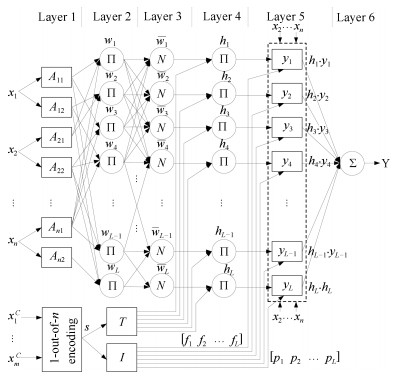
摘要: 现有数据建模方法大多依赖于定量的数值信息,而对于数值与分类混合输入的数据建模问题往往根据分类变量组合建立多个子模型,当有多个分类变量输入时易出现子模型数据分布不均匀、训练耗时长等问题.针对上述问题,提出一种具有混合数据输入的自适应模糊神经推理系统模型,在自适应模糊推理系统的基础上,引入激励强度转移矩阵和结论影响矩阵,采用基于高氏距离的减法聚类辨识模型结构,通过混合学习算法训练模型参数,使数值与分类混合数据对模糊规则的前后件参数同时产生作用,共同影响模型输出.仿真实验分析了分类数据对模型规则后件的作用以及结构辨识算法对模糊规则数的影响,与其他几种混合数据建模方法对比表明本文所提出的模型具有较高的预测精度和计算效率.Abstract: The available data modeling methods mostly depend on quantitative numerical information. But the data modeling with both numerical and categorical data input often has to build multiple sub-models on the basic of combination of categorical variables. It is likely to present unevenly data distribution of sub-models, time-consuming training process and other problems when the multiple categorical variables are input. For the above problems, an adaptive network-based fuzzy inference system with mixed data inputs is proposed. Based on the structure of the adaptive network-based fuzzy inference system, a firing-strength transform matrix and a consequent influence matrix are introduced. The subtractive clustering based on the Gaussian distance is adapted to identify structure of model, and a hybrid learning algorithm is used to train parameters of model. The numerical and categorical data play an important role on the antecedent and consequent parameters of fuzzy rules, and jointly affect the output of model. The simulation experiment analyzes the effect on categorical data to the consequent rules and structure identification to number of fuzzy rules. Comparing with others data modeling with mixed data inputs, the proposed model in this paper has higher prediction accuracy and computational efficiency.1) 本文责任编委 刘艳军
-
表 1 MDI-ANFIS混合学习算法
Table 1 Hybrid learning algorithm of MDI-ANFIS
参数集 算法 Pc, Pi LSE Pt LSE Pp BP  下载: 导出CSV
下载: 导出CSV
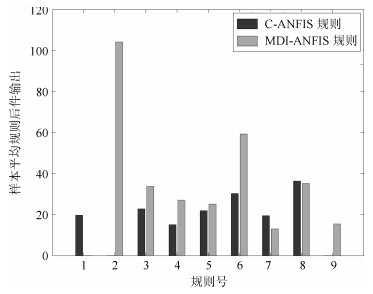
表 2 两种算法的平均规则后件影响和误差
Table 2 Average consequent influences and errors of two algorithms
组号 样本点个数 平均规则后件值 预测误差 C-ANFIS MDI-ANFIS C-ANFIS MDI-ANFIS 1 200 19.659 17.735 2.040 1.519 2 200 18.905 36.270 1.690 1.463 3 200 21.323 27.297 2.980 1.881 4 400 34.202 66.760 3.230 1.604 5 400 14.050 39.905 2.330 2.145 6 400 16.385 35.070 2.510 2.002 7 500 18.901 17.804 3.680 2.194 8 600 21.659 30.857 2.290 2.395 9 600 16.299 22.267 2.800 2.242 10 600 18.426 34.818 3.730 2.187 平均值 410 19.981 32.878 2.728 1.963
下载: 导出CSV
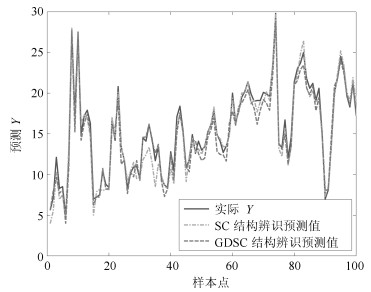
表 3 结构辨识性能对比
Table 3 Performance comparison of structure identification
组号 样本点个数 规则数 预测误差 SC GDSC SC GDSC 1 100 50 13 0.452 0.356 2 100 32 14 0.575 0.466 3 200 37 21 0.517 0.709 4 200 25 14 0.908 0.613 5 300 40 18 0.586 0.690 6 300 34 16 0.661 0.705 7 400 31 16 0.642 0.459 8 400 32 14 0.630 0.747 9 500 30 13 0.788 0.836 10 506 30 14 0.726 0.827 平均值 300 34 15 0.648 0.641
下载: 导出CSV
表 4 UCI数据集模型误差对比
Table 4 Model error comparison on UCI dataset
数据集 样本
个数混合属性
(N, C)预测误差 误差降低率 ANFIS N-ANFIS F-ANFIS S-MLP C-ANFIS MDI-ANFIS ANFIS N-ANFIS F-ANFIS S-MLP C-ANFIS Abalone 4 177 7, 1 2.608 1.842 1.997 3.985 2.632 1.951 0.336 -0.056 0.023 1.04 0.349 Boston
Housing506 11, 2 0.779 0.631 0.657 7.096 0.824 0.638 0.221 -0.011 0.029 10.1 0.291 Auto
MPG398 4, 3 2.072 0.912 0.871 6.969 0.963 0.605 2.42 0.507 0.439 10.5 0.591 Servo 167 2, 2 1.012 0.060 0.051 3.119 0.362 0.025 39.4 1.40 1.04 123 13.4 TAE 151 1, 4 2.972 0.196 0.385 0.849 0.192 0.225 12.2 -0.128 0.711 2.77 -0.146 Zoo 101 1, 15 1.276 0.062 0.059 2.542 0.126 0.072 16.7 -0.138 -0.181 34.3 0.750 Heart
Disease303 6, 7 0.255 0.073 0.062 1.483 0.108 0.086 1.96 -0.151 -0.279 16.2 0.255 平均值 - - 1.568 0.539 0.583 3.720 0.744 0.515 10.462 0.203 0.255 28.273 2.213
下载: 导出CSV
-
[1] Alexander F J, Hoisie A, Szalay A. Big data. Computing in Science & Engineering, 2011, 13(6):10-13 http://d.old.wanfangdata.com.cn/Periodical/dlxtzdh201601001 [2] Provost F, Fawcett T. Data science and its relationship to big data and data-driven decision making. Big Data, 2013, 1(1):51-59 https://www.ncbi.nlm.nih.gov/pubmed/27447038 [3] Wu X D, Zhu X Q, Wu G Q, Ding W. Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1):97-107 doi: 10.1109/TKDE.2013.109 [4] 陈晋音, 何辉豪.基于密度的聚类中心自动确定的混合属性数据聚类算法研究.自动化学报, 2015, 41(10):1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtmlChen Jin-Yin, He Hui-Hao. Research on density-based clustering algorithm for mixed data with determine cluster centers automatically. Acta Automatica Sinica, 2015, 41(10):1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtml [5] Jacobs R A, Jordan M I, Nowlan S J, Hinton G E. Adaptive mixtures of local experts. Neural Computation, 1991, 3(1):79-87 doi: 10.1162-neco.1991.3.1.79/ [6] Lee K W, Lee T. Design of neural networks for multi-value regression. In:Proceedings of the 2001 International Joint Conference on Neural Networks. Washington DC, USA:IEEE, 2001. 93-98 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_0705.1309 [7] Brouwer R K. A feed-forward network for input that is both categorical and quantitative. Neural Networks, 2002, 15(7):881-890 doi: 10.1016/S0893-6080(02)00090-4 [8] Brouwer R K. A hybrid neural network for input that is both categorical and quantitative. International Journal of Intelligent Systems, 2004, 19(10):979-1001 doi: 10.1002/int.20032 [9] Rey-del-Castillo P, Cardeñosa J. Fuzzy min-max neural networks for categorical data:application to missing data imputation. Neural Computing and Applications, 2012, 21(6):1349-1362 doi: 10.1007/s00521-011-0574-x [10] Hsu C C. Generalizing self-organizing map for categorical data. IEEE Transactions on Neural Networks, 2006, 17(2):294-304 doi: 10.1109/TNN.2005.863415 [11] 张宇献, 彭辉灯, 王建辉.基于异构值差度量的SOM混合属性数据聚类算法.仪器仪表学报, 2016, 37(11):2555-2562 doi: 10.3969/j.issn.0254-3087.2016.11.019Zhang Yu-Xian, Peng Hui-Deng, Wang Jian-Hui. Self-organizing mapping clustering algorithm based on heterogeneous value difference metric for mixed attribute data. Chinese Journal of Scientific Instrument, 2016, 37(11):2555-2562 doi: 10.3969/j.issn.0254-3087.2016.11.019 [12] Liu M, Dong M Y, Wu C. A new ANFIS for parameter prediction with numeric and categorical inputs. IEEE Transactions on Automation Science and Engineering, 2010, 7(3):645-653 doi: 10.1109/TASE.2010.2045499 [13] Jang J S R. ANFIS:adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics, 1993, 23(3):665-685 doi: 10.1109/21.256541 [14] Abdelrahim E M, Yahagi T. A new transformed input-domain ANFIS for highly nonlinear system modeling and prediction. In:Proceedings of the 2001 Canadian Conference on Electrical and Computer Engineering. Toronto, Canada:IEEE, 2001. 655-660 https://ieeexplore.ieee.org/document/933761 [15] Mar J, Lin F J. An ANFIS controller for the car-following collision prevention system. IEEE Transactions on Vehicular Technology, 2001, 50(4):1106-1113 doi: 10.1109/25.938584 [16] Lima C A M, Coelho A L V, Von Zuben F J. Fuzzy systems design via ensembles of ANFIS. In:Proceedings of the 2002 IEEE International Conference on Fuzzy Systems. Honolulu, USA:IEEE, 2002. 506-511 https://ieeexplore.ieee.org/document/1005042 [17] Paramasivam S, Arumugan R, Umamaheswari B, Vijayan S, Balamurugan S, Venkatesan G. Accurate rotor position estimation for switched reluctance motor using ANFIS. In:Proceedings of the 2001 Conference on Convergent Technologies for the Asia-Pacific Region. Bangalore, India:IEEE, 2003. 1493-1497 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=1273168 [18] Lih W C, Bukkapatnam S T S, Rao P, Chandrasekharan N, Komanduri R. Adaptive neuro-fuzzy inference system modeling of MRR and WIWNU in CMP process with sparse experimental data. IEEE Transactions on Automation Science and Engineering, 2008, 5(1):71-83 doi: 10.1109/TASE.2007.911683 [19] Chiu S L. Fuzzy model identification based on cluster estimation. Journal of Intelligent and Fuzzy Systems:Applications in Engineering and Technology, 1994, 2(3):267-278 https://dl.acm.org/citation.cfm?id=2656640 [20] Tuerhong G, Kim S B. Gower distance-based multivariate control charts for a mixture of continuous and categorical variables. Expert Systems with Applications, 2014, 41(4):1701-1707 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=efe4850a38e280a7baffd18ce342e4e3 [21] 曾珂, 张乃尧, 徐文立.线性T-S模糊系统作为通用逼近器的充分条件.自动化学报, 2001, 27(5):606-612 http://d.old.wanfangdata.com.cn/Periodical/zdhxb200105002Zeng Ke, Zhang Nai-Yao, Xu Wen-Li. Sufficient condition for linear T-S fuzzy systems as universal approximators. Acta Automatica Sinica, 2001, 27(5):606-612 http://d.old.wanfangdata.com.cn/Periodical/zdhxb200105002 [22] 刘慧林, 冯汝鹏, 胡瑞栋, 刘春华.模糊系统作为通用逼近器的10年历程.控制与决策, 2004, 19(4):367-371 doi: 10.3321/j.issn:1001-0920.2004.04.002Liu Hui-Lin, Feng Ru-Peng, Hu Rui-Dong, Liu Chun-Hua. Decennary development of fuzzy systems as universal approximators. Control and Decision, 2004, 19(4):367-371 doi: 10.3321/j.issn:1001-0920.2004.04.002 -

 下载:
下载:



图(7) / 表(4)
计量
- 文章访问数: 2316
- HTML全文浏览量: 344
- PDF下载量: 120
- 被引次数: 0
