

-
摘要: 维度情感模型通过几个取值连续的维度(如唤醒维、效价维、支配维等)将情感刻画为一个多维信号.与传统的离散情感模型相比,具有表示情感的范围广、能描述情感的演变过程等优点,近年来受到越来越多情感识别研究者的关注.多模态维度情感预测是一项复杂的工程,预测性能受所使用的模态、每个模态的特征提取、信息融合技术、标注人员的标注误差等多方面影响.为了提高多模态维度情感预测的性能,研究者在各个方面都做出了不懈努力.本文综述了维度情感的概念、标注,维度情感预测的性能评价指标以及多模态维度情感预测的研究现状,对比和分析了各种因素对多模态维度情感预测性能的影响,并总结出多模态维度情感预测面临的挑战及发展趋势.Abstract: The dimensional emotion model characterizes emotion as a signal in a multi-dimensional space spanned by several continuously valued dimensions (such as arousal, valence, and dominance). Compared with the discrete emotion model, it has the advantages that it can distinguish subtle difference of emotion, can represent evolution of emotion, etc. So the dimensional emotion model has been paid more and more attention in recent years. Dimensional emotion prediction from multimodal cues is a complex task, the prediction performance is influenced by such as modalities used, features extracted from each modality, information fusion technique, annotation errors. In order to improve multimodal dimensional emotion prediction performance, researchers have made persistent efforts in all aspects. In the paper, concept and annotation of dimensional emotion, performance evaluation criteria of dimensional emotion prediction, and research status of multimodal dimensional emotion prediction are reviewed; influences of various factors on emotion prediction performance are analyzed; challenge and development trend of multimodal dimensional emotion prediction are summarized.1) 本文责任编委 黄庆明
-

图 5 具有不同MSE和CC的效价维的预测与真值的对比图
Fig. 5 Comparison of the prediction and truth values of valence dimension with different MSEs and CCs
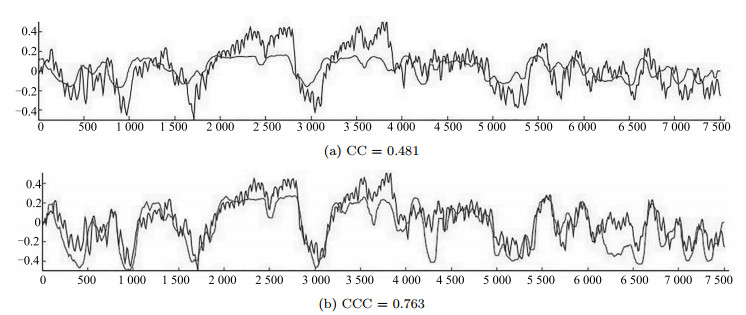
图 6 CC相同的条件下唤醒维的预测与真值的对比图
Fig. 6 Comparison of the prediction and truth values of arousal dimension with the same CC
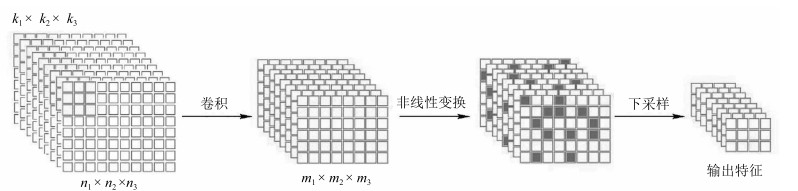
图 7 单层卷积神经网络的三个阶段
Fig. 7 The tree phases of the single layer convolutional neural network
表 1 常用维度情感数据库总结
Table 1 Summary of the frequently used dimensional emotion
数据库 场景 参与者数 模态 情感维度 标注者数 工具/方法 标签范围与类型 SEMAINE Solid SAL 24 Vi + Au A, V, E, D, I 2~8人 FEELtrace [-1, 1]的连续值 RECOLA 远程视频会议 46 Vi + Au + Ph A, V 6人 ANNEMO [-1, 1]的连续值 IEMOCAP 双人对话表演 10 Vi + Au A, V, D 至少2人 SAM系统 1~5的整数值 CreativeIT 双人对话表演 16 Vi + Au A, V, D 3~4人 FEELtrace [-1, 1]的连续值 DEAP 观看音乐视频 32 Vi + Ph A, V, D 1人 SAM系统 [1, 9]的连续值 VAM 电视脱口秀 47 Vi + Au A, V, D 6~34人 SAM系统 [-1, 1]的5点等间隔值 注: Vi —视觉模态, Au —听觉模态, Ph —生理信号, A —唤醒维, V —效价维, E —期望维, D —支配维, I —强度维  下载: 导出CSV
下载: 导出CSV
表 2 维度情感预测文献总结
Table 2 Literature review of the dimensional emotion
文献
(出版日期)模态 特征 特征选择和降维 维度情感预测模型 信息融合方法 回归模型 分类模型 [49] (2008) Au 声学特征 CFS LSTM-RNN CRF - [16] (2009) Au 声学特征 - - HMM - [28] (2010) Vi 头部运动 几何特征 - SVR - - [50] (2010) Vi 步态 几何特征 PCA, KPCA, LDA, GDA - NN - [18] (2010) Au 声音 声学特征 CFS - LSTM-RNN FE 语言 语言特征 [51] (2010) Au 声音 声学特征 - LSTM-RNN - FE 语言 语言特征 [52] (2010) Vi 几何特征 PCA, CFS - BLSTM FE Au 声学特征 [48] (2011) Vi LBP特征 PCA, SPCA SVR - FE + DE Au 声学特征 [53] (2011) Vi 几何特征 - GMM - MO Au 声学特征 [32] (2011) Vi 头部姿势、面部运动单元 CFS SVR - FE-基于串的方法 Au 笑声、叹息声、关键词 [45] (2011) Au 声音 声学特征 CFS SVR - FE 语言 BoCNG特征 [21] (2011) Vi 面部 几何特征 - BLSTM - OA 肩膀 Au 声学特征 [54] (2012) Vi 几何特征 - - EWSC-HMM MO Au 声学特征 [55] (2012) Vi 面部 面部表情 - 身体 几何特征 - 多模态推断系统 MO Au 语言与关键词信息 [56] (2012) Vi 多尺度动态视频特征 新的基于相关的特征选择 核回归 - OA-局部线性回归 Au 声学特征 [57] (2012) Vi 面部 几何特征 - OA-RVM - OA-RVM 肩膀 Au 声学特征 [31] (2013) Vi 基于光流的低级特征 Au 声音 声学特征 CFS BLSTM - FE 语言 BoW特征 [58] (2013) Vi 局部时空特征 - SVR - DE-加权和 Au 声学特征 [59] (2013) Vi 几何特征 CSR CSR - CSR Au 声学特征 [60] (2015) Vi EOH, LBP, LBQ - PLS - DE-线性回归 Au 声学特征 [23] (2015) Vi LBP-TOP, LGBP-TOP, PHOG-TOP, HOG, 时空几何特征 - 随机森林 - DE-平均 Au 声学特征 Ph 生理特征 [61] (2015) Vi LGBP-TOP, 时空几何特征 - SVM, RVM - OA Au 声学特征 Ph 时间和频域特征 [62] (2015) Vi LGBP-TOP, LPQ-TOP, 时空几何特征 - DBLSTM - DE-DBLSTM Au 声学特征 Ph 时间和频域特征 [63] (2015) Vi LGBP-TOP, 时空几何特征 PCA LSTM - FE, DE-线性回归 Au 声学特征 Ph 时间和频域特征 [64] (2016) Au 声学特征 - DBLSTM - DE-ELM [65] (2016) Au 加强后的声学特征 - SVR - - [66] (2016) Vi LBP特征 CFS DNN-SKF - FE Au 声学特征 词汇 词汇特征 [67] (2016) Vi CNN特征 - LSTM - DE-Kalman滤波 Au 声学特征 Ph 时间和频域特征 [68] (2016) Au CNN特征 - LSTM - - [69] (2016) Vi LGBP-TOP, 几何特征, CNN特征 PCA LSTM - DE-LSTM Au 声学特征 Ph 时间和频域特征 [20] (2017) Ph 通过SAE进行抽象的传统特征 - Bayesian模型 - FE-分层的特征融合网络 注: 若文中使用多种方法进行对比分析, 这里只列出性能最好的一种方法. Vi — 视觉模态, Au — 听觉模态, Ph — 生理信号, FE — 特征层 融合, DE — 决定层融合 (决定层融合使用的具体方法), MO — 模型层融合, OA — 输出相关融合
下载: 导出CSV
表 3 连续维度情感预测对比总结
Table 3 Comparison and summary of continuous dimensional emotion prediction
文献 数据库 模态 情感维度 特征 回归模型 融合方法 延时弥补
(Y/N)延时弥补
(Y/N)最好平均预测性能 CC CCC [78]
(基准)AVEC 2012 Vi A, V, E, D Vi LBP SVR - N N 0.09 - Vi+Au Au 声学特征 FE N N 0.11 - [58] AVEC 2012 Vi A, V, E, D Vi 局部时空特征 SVR - N N 0.41 - Vi+Au Au 声学特征 DE-加权和 N N 0.42 - [79]
(基准)AVEC 2014 Vi A, V, D Vi LGBP-TOP SVR - N N 0.20 - Vi+Au Au 声学特征 DE-加权和 N N 0.36 - [22]
(基准)AVEC 2015 Vi A, V Vi LGBP-TOP+时空几何特征 SVR - N N 0.29 0.20 Vi+Au+Ph Au 声学特征 DE-线性回归 N N 0.42 0.41 Ph 时间和频域特性 [47]
(基准)AVEC 2016 Vi A, V Vi LGBP-TOP+时空几何特征 SVR - N N - 0.40 Vi+Au+Ph Au 声学特征 DE-线性回归 Y N - 0.66 Ph 时间和频域特性 [55] AVEC 2012 Vi+Au A, V, E, D Vi 面部表情+身体语言 多模态模糊推断系统 MO N N 0.43 - Au 语句和关键词信息 [56] AVEC 2012 Vi+Au A, V, E, D Vi 多尺度动态视频特征 核回归 OA-局部线性回归 Y Y 0.46 - Au 声学特征 [61] AVEC 2015 Vi+Au+Ph A, V Vi LGBP-TOP+时空几何特征 SVM, RVM OA-Regression Y Y - 0.66 Au 声学特征 Ph 时间和频域特性 [62] AVEC 2015 Vi+Au+Ph A, V Vi LGBP-TOP+LPQ-TOP+时空几何特征 DBLSTM DE-DBLSTM Y N 0.68 0.68 Au 声学特征 Ph 时间和频域特性 注: Vi —视觉模态, Au —听觉模态, Ph —生理信号, A —唤醒维, V —效价维, E —期望维, D —支配维, FE —特征层融合, DE —决定层融合(决定层融合使用的具体方法), MO —模型层融合, OA —输出相关融合
下载: 导出CSV
表 4 维度情感分类对比总结
Table 4 Comparison and summary of dimensional emotion
文献 数据库 模态 情感维度 特征 识别模型 信息融合方法 最好平均性能(%) WA UA [83] (基准) AVEC 2011 音频 A, V, E, D 声学特征 SVM - 45.05 51.95 [31] AVEC 2011 音频 A, V, E, D 声学特征 LSTM - 65.2 58.5 [54] SEMAINE 音频+视频 A, V 视频 几何特征 EWSC-HMM 模型层融合 - 78.1 音频 声学特征 [80] SEMAINE 音频+视频 A, V 视频 几何特征 2H-SC-HMM 模型层融合 - 87.5 音频 声学特征 注: A —唤醒维, V —效价维, E —期望维, D —支配维, UA —未加权准确性, WA —加权准确性
下载: 导出CSV
-
[1] 刘烨, 付秋芳, 傅小兰.认知与情绪的交互作用.科学通报, 2009, 54(18):2783-2796 http://d.old.wanfangdata.com.cn/Periodical/xlkx200603052Liu Ye, Fu Qiu-Fang, Fu Xiao-Lan. The interaction between cognition and emotion. Chinese Science Bulletin, 2009, 54(22):4102-4116 http://d.old.wanfangdata.com.cn/Periodical/xlkx200603052 [2] D'Mello S K, Kory J. A review and meta-analysis of multimodal affect detection systems. ACM Computing Surveys, 2015, 47(3):Article No. 43 http://dl.acm.org/citation.cfm?id=2682899 [3] Zeng Z H, Pantic M, Roisman G I, Huang T S. A survey of affect recognition methods:audio, visual, and spontaneous expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(1):39-58 doi: 10.1109/TPAMI.2008.52 [4] Poria S, Cambria E, Bajpai R, Hussain A. A review of affective computing:from unimodal analysis to multimodal fusion. Information Fusion, 2017, 37:98-125 doi: 10.1016/j.inffus.2017.02.003 [5] 乐国安, 董颖红.情绪的基本结构:争论、应用及其前瞻.南开学报(哲学社会科学版), 2013, (1):140-150 http://d.old.wanfangdata.com.cn/Periodical/yejy-jykx201305009Yue Guo-An, Dong Ying-Hong. On the categorical and dimensional approaches of the theories of the basic structure of emotions. Nankai Journal (Literature and Social Science Edition), 2013, (1):140-150 http://d.old.wanfangdata.com.cn/Periodical/yejy-jykx201305009 [6] Arifin S, Cheung P Y K. Affective level video segmentation by utilizing the pleasure-arousal-dominance information. IEEE Transactions on Multimedia, 2008, 10(7):1325-1341 doi: 10.1109/TMM.2008.2004911 [7] Cowie R, Douglas-Cowie E, Savvidou S, McMahon E, Sawey M, Schröder M. "FEELTRACE": an instrument for recording perceived emotion in real time. In: Proceedings of the 2000 ISCA Tutorial and Research Workshop on Speech and Emotion. Northern Ireland: ISCA, 2000. 19-24 [8] 韩文静, 李海峰, 阮华斌, 马琳.语音情感识别研究进展综述.软件学报, 2014, 25(1):37-50 http://d.old.wanfangdata.com.cn/Periodical/rjxb201401004Han Wen-Jing, Li Hai-Feng, Ruan Hua-Bin, Ma Lin. Review on speech emotion recognition. Journal of Software, 2014, 25(1):37-50 http://d.old.wanfangdata.com.cn/Periodical/rjxb201401004 [9] Gunes H, Schuller B. Categorical and dimensional affect analysis in continuous input:current trends and future directions. Image and Vision Computing, 2013, 31(2):120-136 doi: 10.1016/j.imavis.2012.06.016 [10] Fontaine J R J, Scherer K R, Roesch E B, Eiisworth P C. The world of emotions is not two-dimensional. Psychological Science, 2007, 18(12):1050-1057 doi: 10.1111/j.1467-9280.2007.02024.x [11] 邹吉林, 张小聪, 张环, 于靓, 周仁来.超越效价和唤醒-情绪的动机维度模型述评.心理科学进展, 2011, 19(9):1339-1346 http://d.old.wanfangdata.com.cn/Conference/8110806Zou Ji-Lin, Zhang Xiao-Cong, Zhang Huan, Yu Liang, Zhou Ren-Lai. Beyond dichotomy of valence and arousal:review of the motivational dimensional model of affect. Advances in Psychological Science, 2011, 19(9):1339-1346 http://d.old.wanfangdata.com.cn/Conference/8110806 [12] Morris J D. Observations:SAM:the self-assessment manikin-an efficient cross-cultural measurement of emotional response. Journal of Advertising Research, 1995, 35:63-68 http://d.old.wanfangdata.com.cn/Periodical/kjkxxb201702001 [13] Koelstra S, Muhl C, Soleymani M, Lee J S, Yazdani A, Ebrahimi T, et al. DEAP:a database for emotion analysis using physiological signals. IEEE Transactions on Affective Computing, 2012, 3(1):18-31 doi: 10.1109/T-AFFC.2011.15 [14] Busso C, Bulut M, Lee C C, Kazemzadeh A, Mower E, Kim S, et al. IEMOCAP:interactive emotional dyadic motion capture database. Language Resources and Evaluation, 2008, 42(4):335-359 doi: 10.1007/s10579-008-9076-6 [15] Ringeval F, Sonderegger A, Sauer J, Lalanne D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai, China: IEEE, 2013. 1-8 http://www.mendeley.com/catalog/introducing-recola-multimodal-corpus-remote-collaborative-affective-interactions/ [16] Schuller B, Vlasenko B, Eyben F, Rigoll G, Wendemuth A. Acoustic emotion recognition: a benchmark comparison of performances. In: Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition and Understanding. Merano, Italy: IEEE, 2009. 552-557 http://www.mendeley.com/catalog/acoustic-emotion-recognition-benchmark-comparison-performances/ [17] Tarasov A, Delany S J. Benchmarking classification models for emotion recognition in natural speech: a multi-corporal study. In: Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops. Santa Barbara, CA, USA: IEEE, 2011. 841-846 http://www.mendeley.com/catalog/benchmarking-classification-models-emotion-recognition-natural-speech-multicorporal-study/ [18] Wöllmer M, Schuller B, Eyben F, Rigoll G. Combining long short-term memory and dynamic Bayesian networks for incremental emotion-sensitive artificial listening. IEEE Journal of Selected Topics in Signal Processing, 2010, 4(5):867-881 doi: 10.1109/JSTSP.2010.2057200 [19] Espinosa H P, García C A R, Pineda L V. Features selection for primitives estimation on emotional speech. In: Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing. Dallas, TX, USA: IEEE, 2010. 5138-5141 http://www.mendeley.com/research/features-selection-primitives-estimation-emotional-speech/ [20] Yin Z, Zhao M Y, Wang Y X, Yang J D, Zhang J H. Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Computer Methods and Programs in Biomedicine, 2017, 140:93-110 doi: 10.1016/j.cmpb.2016.12.005 [21] Nicolaou M A, Gunes H, Pantic M. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. IEEE Transactions on Affective Computing, 2011, 2(2):92-105 doi: 10.1109/T-AFFC.2011.9 [22] Ringeval F, Schuller B, Valstar M, Jaiswal S, Marchi E, Lalanne D, et al. AV+EC 2015: the first affect recognition challenge bridging across audio, video, and physiological data. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge. Brisbane, Australia: ACM, 2015. 3-8 doi: 10.1145/2808196.2811642 [23] Kächele M, Schels M, Thiam P, Schwenker F. Fusion mappings for multimodal affect recognition. In: Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence. Cape Town, South Africa: IEEE, 2015. 307-313 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/fusion-mappings-for-multimodal-affect-recognition-oJNU0tN0pn [24] 孙晓, 潘汀, 任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtmlSun Xiao, Pan Ting, Ren Fu-Ji. Facial expression recognition using ROI-KNN deep convolutional neural networks. Acta Automatica Sinica, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtml [25] 徐峰, 张军平.人脸微表情识别综述.自动化学报, 2017, 43(3):333-348 http://www.aas.net.cn/CN/abstract/abstract19013.shtmlXu Feng, Zhang Jun-Ping. Facial microexpression recognition:a survey. Acta Automatica Sinica, 2017, 43(3):333-348 http://www.aas.net.cn/CN/abstract/abstract19013.shtml [26] Ekman P. Universal facial expressions of emotion. California Mental Health Research Digest, 1970, 8(4):151-158 http://d.old.wanfangdata.com.cn/OAPaper/oai_pubmedcentral.nih.gov_3358835 [27] Kleinsmith A, Bianchi-Berthouze N. Affective body expression perception and recognition:a survey. IEEE Transactions on Affective Computing, 2013, 4(1):15-33 doi: 10.1109/T-AFFC.2012.16 [28] Gunes H, Pantic M. Dimensional emotion prediction from spontaneous head gestures for interaction with sensitive artificial listeners. In: Proceeding of the 10th International Conference on Intelligent Virtual Agents. Berlin, Heidelberg, Germany: Springer-Verlag, 2010. 371-377 doi: 10.1007%2F978-3-642-15892-6_39 [29] Metallinou A, Yang Z J, Lee C C, Busso C, Carnicke S, Narayanan S. The USC CreativeIT database of multimodal dyadic interactions:from speech and full body motion capture to continuous emotional annotations. Language Resources and Evaluation, 2016, 50(3):497-521 doi: 10.1007/s10579-015-9300-0 [30] 王科, 夏睿.情感词典自动构建方法综述.自动化学报, 2016, 42(4):495-511 http://www.aas.net.cn/CN/abstract/abstract18838.shtmlWang Ke, Xia Rui. A survey on automatical construction methods of sentiment lexicons. Acta Automatica Sinica, 2016, 42(4):495-511 http://www.aas.net.cn/CN/abstract/abstract18838.shtml [31] Wöllmer M, Kaiser M, Eyben F, Schuller B, Rigoll G. LSTM-Modeling of continuous emotions in an audiovisual affect recognition framework. Image and Vision Computing, 2013, 31(2):153-163 http://dl.acm.org/citation.cfm?id=2438270 [32] Eyben F, Wöllmer M, Valstar M F, Gunes H, Schuller B, Pantic M. String-based audiovisual fusion of behavioural events for the assessment of dimensional affect. In: Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops. Santa Barbara, CA, USA: IEEE, 2011. 322-329 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.364.3773 [33] 彭聃龄.普通心理学.北京:北京师范大学出版社, 2001.Peng Ran-Ling. General Psychology. Beijing:Beijing Normal University Press, 2001. [34] Calvo R A, D'Mello S. Affect detection:an interdisciplinary review of models, methods, and their applications. IEEE Transactions on Affective Computing, 2010, 1(1):18-37 doi: 10.1109/T-AFFC.2010.1 [35] Mckeown G, Valstar M, Cowie R, Pantic M, Schroder M. The SEMAINE database:annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE Transactions on Affective Computing, 2012, 3(1):5-17 doi: 10.1109/T-AFFC.2011.20 [36] Grimm M, Kroschel K, Narayanan S. The Vera am Mittag German audio-visual emotional speech database. In: Proceedings of the 2008 IEEE International Conference on Multimedia and Expo. Hannover, German: IEEE, 2008. 865-868 http://www.mendeley.com/catalog/vera-mittag-german-audiovisual-emotional-speech-database/ [37] Lades M, Vorbruggen J C, Buhmann J, Lang J, von der Malsburg C, Wurtz R P, et al. Distortion invariant object recognition in the dynamic link architecture. IEEE Transactions on Computers, 1993, 42(3):300-311 doi: 10.1109/12.210173 [38] Ahonen T, Hadid A, Pietikainen M. Face description with local binary patterns:application to face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12):2037-2041 doi: 10.1109/TPAMI.2006.244 [39] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 886-893 http://www.mendeley.com/catalog/histogram-oriented-gradients-human-detection/ [40] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, USA: IEEE, 2001. I-511-I-518 http://www.mendeley.com/research/colonialism-homosexuality-review/ [41] Zhao G Y, Pietikäinen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6):915-28 doi: 10.1109/TPAMI.2007.1110 [42] Jiang B H, Valstar M, Martinez B, Pantic M. A dynamic appearance descriptor approach to facial actions temporal modeling. IEEE Transactions on Cybernetics, 2014, 44(2):161-174 doi: 10.1109/TCYB.2013.2249063 [43] Almaev T R, Valstar M F. Local Gabor binary patterns from three orthogonal planes for automatic facial expression recognition. In: Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction. Geneva, Switzerland: IEEE, 2013. 356-361 http://www.mendeley.com/research/local-gabor-binary-patterns-three-orthogonal-planes-automatic-facial-expression-recognition/ [44] Yang P, Liu Q, Metaxas D N. Boosting coded dynamic features for facial action units and facial expression recognition. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, USA: IEEE, 2007. 1-6 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.581.9566 [45] Schuller B. Recognizing affect from linguistic information in 3D continuous space. IEEE Transactions on Affective Computing, 2011, 2(4):192-205 doi: 10.1109/T-AFFC.2011.17 [46] Jenke R, Peer A, Buss M. Feature extraction and selection for emotion recognition from EEG. IEEE Transactions on Affective Computing, 2014, 5(3):327-339 doi: 10.1109/TAFFC.2014.2339834 [47] Valstar M, Gratch J, Schuller B, Ringeval F, Lalanne D, Torres M T, et al. AVEC 2016: depression, mood, and emotion recognition workshop and challenge. In: Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge. Amsterdam, The Netherlands: ACM, 2016. 3-10 http://www.deepdyve.com/lp/association-for-computing-machinery/avec-2016-depression-mood-and-emotion-recognition-workshop-and-bJsOVdX1yf [48] Sayedelahl A, Araujo R, Kamel M S. Audio-visual feature-decision level fusion for spontaneous emotion estimation in speech conversations. In: Proceedings of the 2013 IEEE International Conference on Multimedia and Expo Workshops. San Jose, CA, USA: IEEE, 2013. 1-6 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/audio-visual-feature-decision-level-fusion-for-spontaneous-emotion-qFjpwOTK0Y [49] Wöllmer M, Eyben F, Reiter S, Schuller B, Cox C, Douglas-Cowie E, et al. Abandoning emotion classes-towards continuous emotion recognition with modelling of long-range dependencies. In: Proceedings of the 2008 Interspeech. Brisbane, Australia: DBLP, 2008. 597-600 [50] Karg M, Kuhnlenz K, Buss M. Recognition of affect based on gait patterns. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2010, 40(4):1050-1061 doi: 10.1109/TSMCB.2010.2044040 [51] Eyben F, Wöllmer M, Graves A, Schuller B, Douglas-Cowie E, Cowie R. On-line emotion recognition in a 3-D activation-valence-time continuum using acoustic and linguistic cues. Journal on Multimodal User Interfaces, 2010, 3(1-2):7-19 doi: 10.1007/s12193-009-0032-6 [52] Wöllmer M, Metallinou A, Eyben F, Schuller B, Narayanan S. Context-sensitive multimodal emotion recognition from speech and facial expression using bidirectional LSTM modeling. In: Proceedings of the 11th Annual Conference of the International Speech Communication Association. Makuhari, Chiba, Japan: DBLP, 2010. 2362-2365 [53] Metallinou A, Katsamanis A, Wang Y, Narayanan S. Tracking changes in continuous emotion states using body language and prosodic cues. In: Proceedings of the 2011 IEEE International Conference on Acoustics, Speech, and Signal Processing. Prague, Czech: IEEE, 2011. 2288-2291 http://www.mendeley.com/catalog/tracking-changes-continuous-emotion-states-using-body-language-prosodic-cues/ [54] Lin J C, Wu C H, Wei W L. Error weighted semi-coupled hidden Markov model for audio-visual emotion recognition. IEEE Transactions on Multimedia, 2012, 14(1):142-156 doi: 10.1109/TMM.2011.2171334 [55] Soladié C, Salam H, Pelachaud C, Stoiber N, Séguier R. A multimodal fuzzy inference system using a continuous facial expression representation for emotion detection. In: Proceedings of the 14th ACM International Conference on Multimodal Interaction. Santa Monica, California, USA: ACM, 2012. 493-500 http://www.mendeley.com/research/multimodal-fuzzy-inference-system-using-continuous-facial-expression-representation-emotion-detectio/ [56] Nicolle J, Rapp V, Bailly K, Prevost L, Chetouani M. Robust continuous prediction of human emotions using multiscale dynamic cues. In: Proceedings of the 14th ACM International Conference on Multimodal Interaction. Santa Monica, California, USA: ACM, 2012: 501-508 http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.433.2139 [57] Nicolaou M A, Gunes H, Pantic M. Output-associative RVM regression for dimensional and continuous emotion prediction. In: Proceedings of the 2012 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops. Santa Barbara, CA, USA: IEEE, 2012. 16-23 http://www.mendeley.com/catalog/outputassociative-rvm-regression-dimensional-continuous-emotion-prediction/ [58] Song Y, Morency L P, Davis R. Learning a sparse codebook of facial and body microexpressions for emotion recognition. In: Proceedings of the 15th ACM on International Conference on Multimodal Interaction. Sydney, Australia: ACM, 2013. 237-244 http://www.mendeley.com/research/learning-sparse-codebook-facial-body-microexpressions-emotion-recognition/ [59] Nicolaou M A, Zafeiriou S, Pantic M. Correlated-spaces regression for learning continuous emotion dimensions. In: Proceedings of the 21st ACM International Conference on Multimedia. Barcelona, Spain: ACM, 2013. 773-776 http://www.mendeley.com/research/correlatedspaces-regression-learning-continuous-emotion-dimensions/ [60] Gaus Y F A, Meng H Y, Jan A, Zhang F, Turabzadeh S. Automatic affective dimension recognition from naturalistic facial expressions based on wavelet filtering and PLS regression. In: Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Ljubljana, Yugoslavia: IEEE, 2015. 1-6 http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7284859 [61] Huang Z, Dang T, Cummins N, Stasak B, Le P, Sethu V, et al. An investigation of annotation delay compensation and output-associative fusion for multimodal continuous emotion prediction. In: Proceedings of the 2015 International Workshop on Audio/Visual Emotion Challenge. New York, USA: ACM, 2015. 41-48 doi: 10.1145/2808196.2811640 [62] He L, Jiang D M, Yang L, Pei E C, Wu P, Sahli H. Multimodal affective dimension prediction using deep bidirectional long short-term memory recurrent neural networks. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge. Brisbane, Australia: ACM, 2015. 73-80 [63] Chen S Z, Jin Q. Multi-modal dimensional emotion recognition using recurrent neural network. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge. Brisbane, Australia: ACM, 2015. 49-56 http://dl.acm.org/citation.cfm?id=2811638 [64] Li X X, Xianyu H, Tian J S, Chen W X, Meng F H, Xu M X, et al. A deep bidirectional long short-term memory based multi-scale approach for music dynamic emotion prediction. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech, and Signal Processing. Shanghai, China: IEEE, 2016. 544-548 http://ieeexplore.ieee.org/document/7471734/ [65] Zhang Z X, Ringeval F, Han J, Deng J, Marchi E, Schuller B. Facing realism in spontaneous emotion recognition from speech: feature enhancement by autoencoder with LSTM neural networks. In: Proceedings of the 2016 Conference of the International Speech Communication Association. San Francisco, USA: ISCA, 2016. 3593-3597 [66] Pei E C, Xia X H, Yang L, Jiang D M, Sahli H. Deep neural network and switching Kalman filter based continuous affect recognition. In: Proceedings of the 2016 IEEE International Conference on Multimedia and Expo Workshops. Seattle, WA, USA: IEEE, 2016. 1-6 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/deep-neural-network-and-switching-kalman-filter-based-continuous-Gi0nak0reF [67] Brady K, Gwon Y, Khorrami P, Godoy E, Campbell W, Dagli C, et al. Multi-modal audio, video and physiological sensor learning for continuous emotion prediction. In: Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge. Amsterdam, The Netherlands: ACM, 2016. 97-104 http://experts.illinois.edu/en/publications/multi-modal-audio-video-and-physiological-sensor-learning-for-con [68] Trigeorgis G, Ringeval F, Brueckner R, Marchi E, Nicolaou M A, Schuller B, et al. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 5200-5204 http://ieeexplore.ieee.org/document/7472669/ [69] Chao L L, Tao J H, Yang M H, Li Y, Wen Z Q. Long short term memory recurrent neural network based multimodal dimensional emotion recognition. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge. Brisbane, Australia: ACM, 2015. 65-72 http://www.deepdyve.com/lp/association-for-computing-machinery/long-short-term-memory-recurrent-neural-network-based-multimodal-PD8TcEBEm5 [70] Sariyanidi E, Gunes H, Cavallaro A. Automatic analysis of facial affect:a survey of registration, representation, and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(6):1113-1133 doi: 10.1109/TPAMI.2014.2366127 [71] Lecun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [72] 尹宝才, 王文通, 王立春.深度学习研究综述.北京工业大学学报, 2015, 41(1):48-59 http://d.old.wanfangdata.com.cn/Periodical/jsjyyyj201208002Yin Bao-Cai, Wang Wen-Tong, Wang Li-Chun. Review of deep learning. Journal of Beijing University of Technology, 2015, 41(1):48-59 http://d.old.wanfangdata.com.cn/Periodical/jsjyyyj201208002 [73] Zheng W Q, Yu J S, Zou Y X. An experimental study of speech emotion recognition based on deep convolutional neural networks. In: Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction. Xi'an, China: IEEE, 2015. 827-831 http://ieeexplore.ieee.org/document/7344669/ [74] Poria S, Chaturvedi I, Cambria E, Hussain A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In: Proceedings of the 16th IEEE International Conference on Data Mining. Barcelona, Spain: IEEE, 2016. 439-448 http://ieeexplore.ieee.org/document/7837868 [75] Weninger F, Ringeval F, Marchi E, Schuller B. Discriminatively trained recurrent neural networks for continuous dimensional emotion recognition from audio. In: Proceedings of the 25th International Joint Conference on Artificial Intelligence. New York, USA: AAAI Press, 2016. 2196-2202 http://www.sewaproject.eu/files/338a1be0-486e-43ae-c09f-4e88236e62df.pdf [76] Banda N, Engelbrecht A, Robinson P. Continuous emotion recognition using a particle swarm optimized NARX neural network. In: Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction. Xi'an, China: IEEE, 2015. 380-386 http://ieeexplore.ieee.org/document/7344599/ [77] Glodek M, Tschechne S, Layher G, Schels M, Brosch T, Scherer S, et al. Multiple classifier systems for the classification of audio-visual emotional states. In: Proceedings of the 2011 International Conference on Affective Computing and Intelligent Interaction. Berlin, Heidelberg, German: Springer-Verlag, 2011. 359-368 http://www.springerlink.com/content/77345u71p6x76pg3/ [78] Schuller B, Valstar M, Cowie R, Pantic M. AVEC 2012: the continuous audio/visual emotion challenge-an introduction. In: Proceedings of the 14th ACM International Conference on Multimodal Interaction. Santa Monica, California, USA: ACM, 2012. 361-362 http://www.mendeley.com/research/avec-2012-continuous-audiovisual-emotion-challenge/ [79] Valstar M, Schuller B, Smith K, Almaev T, Eyben F, Krajewski J, et al. AVEC 2014: 3D dimensional affect and depression recognition challenge. In: Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge. Orlando, Florida, USA: ACM, 2014. 3-10 http://dl.acm.org/citation.cfm?id=2661807 [80] Wu C H, Lin J C, Wei W L. Two-level hierarchical alignment for semi-coupled HMM-based audiovisual emotion recognition with temporal course. IEEE Transactions on Multimedia, 2013, 15(8):1880-1895 doi: 10.1109/TMM.2013.2269314 [81] Mariooryad S, Busso C. Correcting time-continuous emotional labels by modeling the reaction lag of evaluators. IEEE Transactions on Affective Computing, 2015, 6(2):97-108 doi: 10.1109/TAFFC.2014.2334294 [82] Mariooryad S, Busso C. Analysis and compensation of the reaction lag of evaluators in continuous emotional annotations. In: Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction. Geneva, Switzerland: IEEE, 2013. 85-90 http://dl.acm.org/citation.cfm?id=2544966 [83] Schuller B, Valstar M, Eyben F, McKeown G, Cowie R, Pantic M. AVEC 2011-the first international audio/visual emotion challenge. In: Proceedings of the 2011 International Conference on Affective Computing and Intelligent Interaction. Berlin, German: Springer-Verlag, 2011. 415-424 AVEC 2011-the first international audio/visual emotion challenge. -

 下载:
下载:



计量
- 文章访问数: 5224
- HTML全文浏览量: 2301
- PDF下载量: 1250
- 被引次数: 0
