

-
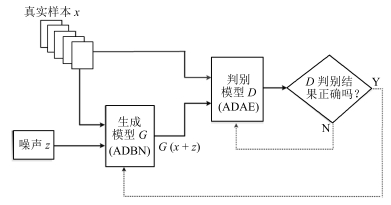
摘要: 生成式对抗网络(Generative adversarial network,GAN)是目前人工智能领域的一个研究热点,引起了众多学者的关注.针对现有GAN生成模型效率低下和判别模型的梯度消失问题,本文提出一种基于重构误差的能量函数意义下的生成式对抗网络模型(Energy reconstruction error GAN,E-REGAN).首先,将自适应深度信念网络(Adaptive deep belief network,ADBN)作为生成模型,来快速学习给定样本数据的概率分布并进一步生成相似的样本数据.其次,将自适应深度自编码器(Adaptive deep autoencoder,ADAE)的重构误差(Reconstruction error,RE)作为一个表征判别模型性能的能量函数,能量越小表示GAN学习优化过程越趋近纳什均衡的平衡点,否则反之.同时,通过反推法给出了E-REGAN的稳定性分析.最后在MNIST和CIFAR-10标准数据集上的实验结果表明,相较于现有的类似模型,E-REGAN在学习速度和数据生成能力两方面均有较大提高.Abstract: Generative adversarial network (GAN) has become a hot research in artificial intelligence, and has received much attention from scholars. In view of low efficiency of generative model and gradient disappearance of discriminative model, a GAN based on energy function (E-REGAN) is proposed in this paper, in which reconstruction error (RE) acts as the energy function. Firstly, an adaptive deep belief network (ADBN) is presented as the generative model, which is used to fast learn the probability distribution of given sample data and further generate new data with similar probability distribution. Secondly, the RE in adaptive deep auto-encoder (ADAE) acts as an energy function evaluating the performance of discriminative model; the smaller energy function, the closer to Nash equilibrium the learning optimization process of GAN will be, and vice versa. Meanwhile, the stability analysis of the proposed E-REGAN is given using the inverse inference method. Finally, the simulation results from MNIST and CIFAR-10 benchmark dataset experiments show that, compared with the existing similar models, the proposed E-REGAN achieves significant improvement in learning rate and data generation capability.1) 本文责任编委 王坤峰
-
表 1 MNIST数据集测试中ADBN的固有参数
Table 1 Fixed parameters of ADBN on MNIST dataset
$\eta_0$ $\tau$ $t$ $u$ $v$ $\lambda$ $\gamma $ 0.1 200 2 1.5 0.7 0.02 0.01 $ \eta _0 $表示学习率的初始值  下载: 导出CSV
下载: 导出CSV
表 3 CIFAR-10数据集测试中ADBN的固有参数
Table 3 Fixed parameters of ADBN on CIFAR-10 dataset
$\eta_0$ $\tau$ $t$ $u$ $v$ $\lambda$ $\gamma $ 0.1 300 2 1.7 0.5 0.05 0.02 $ \eta _0 $表示学习率的初始值.
下载: 导出CSV
表 4 CIFAR-10数据集实验结果对比
Table 4 Result comparison on CIFAR-10 dataset
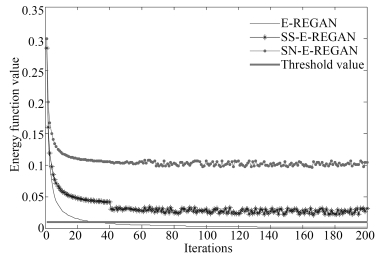
方法 能量函数 测试误差 平均运行时间(s) 均值 方差 均值 方差 E-REGAN 0.0048 0.0831 0.0160 0.0831 65.38 SS-E-REGAN 0.0473 2.2406 0.0431 2.2406 65.75 SN-E-REGAN 0.2097 2.8119 0.0633 2.8119 67.92 标准GAN – – 0.0802 1.9227 90.68 LS-GAN[27] – – 0.0358 0.1076 78.24 LR-GAN[28] – – 0.0263 0.1547 84.36 Bayesian GAN[29] – – 0.0386 0.2037 86.19 粗体表示最优值.
下载: 导出CSV
-
[1] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [2] Makhzani A, Shlens J, Jaitly N, Goodfellow I, Frey B. Adversarial autoencoders. arXiv preprint arXiv: 1511. 05644, 2015. [3] Mao X D, Li Q, Xie H R, Lau R Y K, Wang Z, Smolley S P. Least squares generative adversarial networks. arXiv preprint ArXiv: 1611. 04076, 2016. [4] Durugkar I, Gemp I, Mahadevan S. Generative multi-adversarial networks. arXiv preprint arXiv: 1611. 01673, 2016. [5] Huang X, Li Y X, Poursaeed O, Hopcroft J, Belongie1 S. Stacked generative adversarial networks. arXiv preprint arXiv: 1612. 04357, 2016. [6] Saito M, Matsumoto E, Saito S. Temporal generative adversarial nets with singular value clipping. In: Proceedings of the 2017 IEEE Conference on Computer Vision. Venice, Italy: ICCV, 2017. 2849-2858 [7] Che T, Li Y R, Zhang R X, Hjelm R D, Li W J, Song Y Q, etal. Maximum-likelihood augmented discrete generative adversarial networks. arXiv preprint arXiv: 1702. 07983, 2017. [8] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [9] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. arXiv preprint arXiv: 1701. 07875, 2017. [10] Donahue J, Krähenbühl P, Darrell T. Adversarial feature learning. arXiv preprint arXiv: 1605. 09782, 2016. [11] LeCun Y, Huang F. Loss functions for discriminative training of energy-based models. In: Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics. Barbados: AIS, 2005. 206-213 [12] 乔俊飞, 潘广源, 韩红桂.一种连续型深度信念网的设计与应用.自动化学报, 2015, 41(12):2138-2146 http://www.aas.net.cn/CN/abstract/abstract18786.shtmlQiao Jun-Fei, Pan Guang-Yuan, Han Hong-Gui. Design and application of continuous deep belief network. Acta Automatica Sinica, 2015, 41(12):2138-2146 http://www.aas.net.cn/CN/abstract/abstract18786.shtml [13] 乔俊飞, 王功明, 李晓理, 韩红桂, 柴伟.基于自适应学习率的深度信念网设计与应用.自动化学报, 2017, 43(8):1339-1349 http://www.aas.net.cn/CN/abstract/abstract19108.shtmlQiao Jun-Fei, Wang Gong-Ming, Li Xiao-Li, Han Hong-Gui, Chai Wei. Design and application of deep belief network with adaptive learning rate. Acta Automatica Sinica, 2017, 43(8):1339-1349 http://www.aas.net.cn/CN/abstract/abstract19108.shtml [14] Lopes N, Ribeiro B. Towards adaptive learning with improved convergence of deep belief networks on graphics processing units. Pattern Recognition, 2014, 47(1):114-127 doi: 10.1016/j.patcog.2013.06.029 [15] 王功明, 李文静, 乔俊飞.基于PLSR自适应深度信念网络的出水总磷预测.化工学报, 2017, 68(5):1987-1997 http://www.doc88.com/p-6922879556285.htmlWang Gong-Ming, Li Wen-Jing, Qiao Jun-Fei. Prediction of effluent total phosphorus using PLSR-based adaptive deep belief network. CIESC Journal, 2017, 68(5):1987-1997 http://www.doc88.com/p-6922879556285.html [16] Hinton G E. Training products of experts by minimizing contrastive divergence. Neural Computation, 2002, 14(8):1771-1800 doi: 10.1162/089976602760128018 [17] Le Roux N, Bengio Y. Representational power of restricted boltzmann machines and deep belief networks. Neural Computation, 2008, 20(6):1631-1649 doi: 10.1162/neco.2008.04-07-510 [18] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [19] Alain G, Bengio Y. What regularized auto-encoders learn from the data-generating distribution. The Journal of Machine Learning Research, 2014, 15(1):3563-3593 http://jmlr.csail.mit.edu/papers/volume15/alain14a/alain14a.pdf [20] Chan P P K, Lin Z, Hu X, Tsang E C C, Yeung D S. Sensitivity based robust learning for stacked autoencoder against evasion attack. Neurocomputing, 2017, 267:572-580 doi: 10.1016/j.neucom.2017.06.032 [21] Huang G B, Chen L, Siew C K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Transactions on Neural Networks, 2006, 17(4):879-892 doi: 10.1109/TNN.2006.875977 [22] Leung F H F, Lam H K, Ling S H, Tam P K S. Tuning of the structure and parameters of a neural network using an improved genetic algorithm. IEEE Transactions on Neural networks, 2003, 14(1):79-88 doi: 10.1109/TNN.2002.804317 [23] de la Rosa E, Yu W. Randomized algorithms for nonlinear system identification with deep learning modification. Information Sciences, 2016, 364-365:197-212 doi: 10.1016/j.ins.2015.09.048 [24] Zhao J B, Mathieu M, LeCun Y. Energy-based generative adversarial network. arXiv preprint arXiv: 1609. 03126, 2016. [25] Larochelle H, Bengio Y, Louradour J, Lamblin P. Exploring strategies for training deep neural networks. The Journal of Machine Learning Research, 2009, 10:1-40 http://www.cs.toronto.edu/~larocheh/publications/jmlr-larochelle09a.pdf [26] Wang Y, Wang X G, Liu W Y. Unsupervised local deep feature for image recognition. Information Sciences, 2016, 351:67-75 doi: 10.1016/j.ins.2016.02.044 [27] Qi G J. Loss-sensitive generative adversarial networks on lipschitz densities. arXiv preprint arXiv: 1701. 06264, 2017. [28] Yang J W, Kannan A, Batra D, Parikh D. LR-GAN: layered recursive generative adversarial networks for image generation. arXiv preprint arXiv: 1703. 01560, 2017. [29] Saatchi Y, Wilson A. Bayesian GAN. arXiv preprint arXiv: 1705. 09558, 2017. [30] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv: 1207. 0580, 2012. [31] Xu B, Wang N Y, Chen T Q, Li M. Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv: 1505. 00853, 2015. [32] Goroshin R, Bruna J, Tompson J, Eigen D, LeCun Y. Unsupervised learning of spatiotemporally coherent metrics. In: Proceedings of the 2015 IEEE Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4086-4093 [33] Metz L, Poole B, Pfau D, Sohl-Dickstein J. Unrolled generative adversarial networks. arXiv preprint arXiv: 1611. 02163, 2016. [34] Springenberg J T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv preprint arXiv: 1511. 06390, 2015. -

 下载:
下载:










图(16) / 表(4)
计量
- 文章访问数: 2626
- HTML全文浏览量: 662
- PDF下载量: 1265
- 被引次数: 0
