

-
摘要: 本文对自然场景文本检测问题及其方法的研究进展进行了综述.首先,论述了自然场景文本的特点、自然场景文本检测技术的研究背景、现状以及主要技术路线.其次,从传统文本检测以及深度学习文本检测的视角出发,梳理、分析并比较了各类自然场景文本检测方法的优缺点,并介绍了端对端文本识别技术.再次,论述了自然场景文本检测技术所面临的挑战,探讨了相应的解决方案.最后,本文列举了测试基准数据集、评估方法,将最具代表性的自然场景文本检测方法的性能进行了比较,本文还展望了本领域的发展趋势.Abstract: In this paper, the research progress of natural scene text detection problems and methods are reviewed. Firstly, the characteristics of natural scene text are introduced, and the text detection technology research background, status and the main technical route are illustrated respectively. Secondly, from the perspective of traditional text detection and deep learning text detection, the merits and demerits of various methods are analyzed, and the technology of end-to-end text recognition is introduced. Then, the challenges of the natural scene text detection technology and the corresponding solutions are discussed. Finally, the benchmark datasets are enumerated, the evaluation methods and the performances of the most representative approaches are fundamentally compared. Furthermore, potential application and development trend in this field are summarized.
-
Key words:
- Text detection /
- scene text /
- deep learning /
- handcraft feature /
- connected component analysis
1) 本文责任编委 刘成林 -


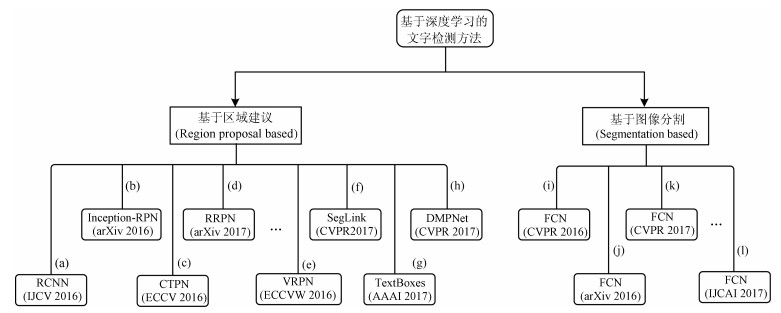
图 9 主要的深度学习文本检测路线与一些代表性方法 ((a)文献[137]方法, 该方法采用CNN与ACF提取文本候选区域; (b)文献[130]方法, 该方法对faster RCNN进行改进, 并提出Inception-RPN方式提取文本候选区域; (c)文献[37]方法, 该方法提出了Connectionist text proposal network检测文本候选区域; (d)文献[138]方法, 该方法提出旋转区域候选网络(RRPN); (e)文献[139]方法, 该方法提出了垂直回归建议网络(VRPN); (f)文献[33]方法, 该方法采用Segment linking方式解决多方向排列的文本检测问题; (g)文献[31]方法, 该方法以SSD作为基础框架, 提出了一个端对端训练文本检测器(TextBoxes); (h)文献[15]方法, 该方法创新性提出采用四边形窗口(非矩形)的方式检测任意方向排列的文本; (i)文献[41]方法, 该方法提出采用Text-block全卷积网络获得文本候选区域; (j)文献[140]方法, 该方法采用FCN综合多信息属性来获得文本候选区域; (k)文献[50]方法, 该方法参考了DenseBox的架构, 采用FCN网络检测任意方向排列的文本; (l)文献[141]方法, 该方法采用深度卷积神经网络(DCNN)来学习文本的高级视觉表示+循环神经网络(RNN)处理文本序列.)
Fig. 9 The main deep learning text detection framework and some representative methods ((a) method[137], the CNN and the ACF are integrated to obtain the text region proposal. (b) method[130], the inception-RPN has been proposed in this work. (c) method[37], the connectionist text proposal network has been proposed in this work. (d) method[138], the RRPN has been proposed in this work. (e) method[139], the VRPN has been proposed in this work. (f) method[33], the segment and linking has been proposed in this work. (g) method[31], the TextBoxes method has been proposed in this work. (h) method[15], the deep matching prior network (DMPNet) with tighter quadrangle has been proposed in this work. (i) method[41], the text-block FCN has been proposed in this work. (j) method[140], the FCN and multi-channel prediction method has been proposed in this work. (k) method[50], the DenseBox framework has been followed and the FCN has been proposed in this work. (l) method[141], the DCNN and the RNN has been adopted in this work.)
表 1 常用自然场景文本检测数据集
Table 1 Widely used natural scene text detection datasets and their download link
数据集 年份 数据集大小 图像数目(训练/测试) 文本数目(训练/测试) 文本种类 文本排列方向 ICDAR$'$03[161] 2003 120.2 MB 509 (258/251) 2 276 (1 110/1 156) 英文 水平方向 ICDAR$'$11[30] 2011 266 MB 484 (229/255) 2 037 (848/1 189) 英文 水平方向 ICDAR$'$13[123] 2013 250 MB 462 (229/233) 1 943 (848/1 095) 英文 水平方向 ICDAR$'$15[32] 2015 131.8 MB 1 500 (1 000/500) 17 548 英文 水平方向 SVT[88] 2010 112 MB 350 (100/250) 904 (257/647) 英文 水平方向 MSRA-TD500[39] 2012 96 MB 500 (300/200) 1 719 (1 068/651) 中文/英文 任意方向 KIST[162] 2010 347.4 MB 3 000 $>5 000$ 英文/韩文 水平方向 OSTD[21] 2011 17.34 MB 89 218 英文 任意方向 NEOCR[163] 2011 1.3 GB 659 5 238 英文 任意方向 USTB-SV1K[164] 2015 36.1 MB 1 000 (500/500) 2 955 英文 任意方向 COCO-Text[58, 165] 2016 - 63 686 173 589 多语种 任意方向 RCTW-17[51] 2017 5.4 GB $>12 000$ (8 034/4 000) - 中文 任意方向 SCUT-CTW1500[135] 2017 842 MB $1 500$ (1 000/500) 10 000 英文 含弧形排列的任意方向  下载: 导出CSV
下载: 导出CSV
表 2 近期主流自然场景文本检测方法性能总结(数据都是原文报道的结果, 带(*)标记的数据是引自相关论文)
Table 2 Performance summary of recent dominant natural scene text detection methods (All results are quoted directly from original papers, except for those marked with (*), which are from a recent related paper.)
方法 年份 数据集 精度(P) 召回率(R) 综合评价指标(f) 检测耗时(s) 方法亮点 Lucas[161] 2003 ICDAR'03 0.55 0.46 0.50 8.7 ICDAR'03竞赛冠军 Hinnerk Becker[170] 2005 ICDAR'03 0.62 0.67 0.62 14.4 ICDAR'05竞赛冠军 Yao[39] 2012 ICDAR'03 0.69 0.66 0.67 - 提出MSRA-TD500数据集, 检测任意方向文本 Epshtein[34] 2010 ICDAR'03 0.73 0.60 0.66 - 首次提出笔画宽度变换文本检测方法 SFT-TCD[72] 2013 ICDAR'03 0.81 0.74 0.72 - 提出笔画特征变换 Neumann[60] 2010 ICDAR'03 0.59 0.55 0.57 - 首次提出MSER文本检测方法 Kim[30] 2011 ICDAR'11 0.83 0.63 0.71 - ICDAR'11竞赛冠军 SFT-TCD[72] 2013 ICDAR'11 0.82 0.75 0.73 - 提出笔画特征变换 Yin[164] 2015 ICDAR'11 0.84 0.66 0.74 - 提出自适应聚类文本检测 Zhang[87] 2015 ICDAR'11 0.84 0.76 0.80 - 提出文本行上下结构相似的文本检测 Yin[14] 2014 ICDAR'11 0.86 0.68 0.76 - 提出基于MSER文本检测 Gupta[148] 2016 ICDAR'11 0.92 0.75 0.82 - 首次提出大规模合成场景文本数据集 Liao[31] 2017 ICDAR'11 0.89 0.82 0.86 0.73 提出端对段卷积神经网络 USTB TexStar[123] 2013 ICDAR'13 0.89 0.67 0.76 - ICDAR'13竞赛冠军 Yin[164] 2015 ICDAR'13 0.84 0.65 0.73 - 提出自适应聚类文本检测 Zhang[87] 2015 ICDAR'13 0.88 0.74 0.80 - 提出文本行上下结构相似的文本检测 Zhu[64] 2016 ICDAR'13 0.86 0.74 0.80 - 提出场景上下文检测文本 Zhang[41] 2016 ICDAR'13 0.88 0.78 0.83 - 首次提出基于FCN检测任意方向文本 Gupta[148] 2016 ICDAR'13 0.92 0.76 0.83 - 首次提出大规模合成场景文本数据集 Huang[42] 2016 ICDAR'13 0.88 0.72 0.79 - 提出基于视觉注意的文本检测方法 Liao[31] 2017 ICDAR'13 0.88 0.83 0.85 0.73 提出端对段卷积神经网络 Shi[33] 2017 ICDAR'13 0.88 0.83 0.85 20.6 提出改进版的SSD文本检测器 Stradvision-2[32] 2015 ICDAR'15 0.78 0.37 0.50 - ICDAR'15竞赛冠军 Zhang[41] 2016 ICDAR'15 0.71 0.43 0.54 2.1 首次提出基于FCN检测任意方向文本 Zheng[49] 2017 ICDAR'15 0.62 0.40 0.48 - 提出文本行熵方法 Liu[15] 2017 ICDAR'15 0.73 0.68 0.71 - 提出DMPNet文本检测网络 Shi[33] 2017 ICDAR'15 0.73 0.77 0.75 - 提出改进版的SSD文本检测器 Zhou[50] 2017 ICDAR'15 0.83 0.78 0.81 提出基于FCN与NMS简单高效的文本框架 Yao[39] 2012 MSRA-TD500 0.63 0.63 0.60 7.2 提出MSRA-TD500数据集, 检测任意方向文本 Zhang[41] 2016 MSRA-TD500 0.83 0.67 0.74 - 首次提出基于FCN检测任意方向文本 Huang[42] 2016 MSRA-TD500 0.74 0.68 0.71 - 提出基于视觉注意的文本检测方法 Shivakumara[171] 2017 MSRA-TD500 0.68 0.54 0.60 - 提出基于分形(Fractals)文本检测 Kang[63] 2014 MSRA-TD500 0.71 0.62 0.66 - 提出高阶关联聚类文本检测 Yin[14] 2014 MSRA-TD500 0.71 0.61 0.66 0.8 提出基于MSER文本检测 Yin[164] 2015 MSRA-TD500 0.81 0.63 0.71 1.4 提出自适应聚类文本检测 Zhou[50] 2017 MSRA-TD500 0.87 0.67 0.76 提出基于FCN与NMS简单高效的文本框架 Shi[33] 2017 MSRA-TD500 0.86 0.70 0.77 8.9 提出改进版的SSD文本检测器 Yi[21] 2011 OSTD 0.71 0.62 0.62 17.8 提出组件分析文本检测 Yao[39] 2012 OSTD 0.77 0.73 0.74 - 提出MSRA-TD500数据集, 检测任意方向文本 Yin[164] 2015 USTB-SV1K 0.45$^{*}$ 0.45$^{*}$ 0.45$^{*}$ - 提出基于MSER文本检测 Yao[164] 2015 USTB-SV1K 0.46$^{*}$ 0.44$^{*}$ 0.45$^{*}$ - 提出统一的文本检测与识别框架 Yin[164] 2015 USTB-SV1K 0.50 0.45 0.48 - 提出自适应聚类文本检测 Neumann[59] 2012 SVT 0.19 0.33 0.26 - 提出端对端的文本检测与识别方法 Zhu[64] 2016 SVT 0.41 0.34 0.37 - 提出场景上下文检测文本 Gupta[148] 2016 SVT 0.26 0.27 0.27 - 首次提出大规模合成场景文本数据集 SnooperText[172] 2014 SVT 0.36 0.54 0.43 - 提出自顶向下与自底向上的检测策略 Yin[164] 2015 NEOCR 0.41 0.25 0.31 - 提出自适应聚类文本检测 Yao[104] 2014 COCO-Text 0.3 0.27 0.33 - 提出Strokelet文本区域描述方法 Zhou[50] 2017 COCO-Text 0.50 0.32 0.40 - 提出FCN与NMS简单高效的文本框架 Jin[173] 2011 KAIST 0.85 0.90 - - 提出Touchline文本检测方法 Foo and Bar[51] 2017 RCTW-17 0.74 0.59 0.66 - RCTW-17竞赛冠军 NLPR PAL[51] 2017 RCTW-17 0.77 0.57 0.66 - RCTW-17竞赛亚军
下载: 导出CSV
-
[1] González Á, Bergasa L M, Yebes J J. Text detection and recognition on traffic panels from street-level imagery using visual appearance. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(1):228-238 doi: 10.1109/TITS.2013.2277662 [2] Zhou W G, Li H Q, Lu Y J, Tian Q. Principal visual word discovery for automatic license plate detection. IEEE Transactions on Image Processing, 2012, 21(9):4269-4279 doi: 10.1109/TIP.2012.2199506 [3] Greenhalgh J, Mirmehdi M. Recognizing text-based traffic signs. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(3):1360-1369 doi: 10.1109/TITS.2014.2363167 [4] Ezaki N, Kiyota K, Minh B T, Bulacu M, Schomaker L. Improved text-detection methods for a camera-based text reading system for blind persons. In: Proceedings of the 8th International Conference on Document Analysis and Recognition. Seoul, South Korea: IEEE, 2005. 257-261 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1575549 [5] Ezaki N, Bulacu M, Schomaker L. Text detection from natural scene images: towards a system for visually impaired persons. In: Proceedings of the 17th International Conference on Pattern Recognition. Cambridge, UK: IEEE, 2004. 683-686 http://ieeexplore.ieee.org/iel5/9258/29386/01334351.pdf [6] Jung K, Kim K I, Jain A K. Text information extraction in images and video:a survey. Pattern Recognition, 2004, 37(5):977-997 doi: 10.1016/j.patcog.2003.10.012 [7] Hedgpeth T, Black J A Jr, Panchanathan S. A demonstration of the icare portable reader. In: Proceedings of the 8th International ACM SIGACCESS Conference on Computers and Accessibility. Portland, Oregon, USA: ACM, 2006. 279-280 http://dl.acm.org/citation.cfm?id=1169054 [8] Goto H, Tanaka M. Text-tracking wearable camera system for the blind. In: Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain: IEEE, 2009. 141-145 https://dl.acm.org/citation.cfm?id=1635351 [9] Shilkrot R, Huber J, Liu C, Maes P, Nanayakkara S C. FingerReader: a wearable device to support text reading on the go. In: Proceedings of the CHI'14 Extended Abstracts on Human Factors in Computing Systems. Toronto, Ontario, Canada: ACM, 2014. 2359-2364 http://dl.acm.org/citation.cfm?id=2559206.2581220&coll=DL&dl=GUIDE&CFID=428893675&CFTOKEN=97791852 [10] Google goggles[Online], available: http://www.google.com/mobile/goggles/#text, January 10, 2015 [11] Bai X, Shi B G, Zhang C Q, Cai X, Qi L. Text/non-text image classification in the wild with convolutional neural networks. Pattern Recognition, 2017, 66:437-446 doi: 10.1016/j.patcog.2016.12.005 [12] Shi B G, Bai X, Yao C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11):2298-2304 doi: 10.1109/TPAMI.2016.2646371 [13] Pan Y F, Hou X W, Liu C L. A hybrid approach to detect and localize texts in natural scene images. IEEE Transactions on Image Processing, 2011, 20(3):800-813 doi: 10.1109/TIP.2010.2070803 [14] Yin X C, Yin X W, Huang K Z, Hao H W. Robust text detection in natural scene images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5):970-983 doi: 10.1109/TPAMI.2013.182 [15] Liu Y L, Jin L W. Deep matching prior network: toward tighter multi-oriented text detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 3454-3461 doi: 10.1109/CVPR.2017.368 [16] He P, Huang W L, Qiao Y, Loy C C, Tang X O. Reading scene text in deep convolutional sequences. In: Proceedings of the 13th AAAI Conference on Artificial Intelligence. Phoenix, Arizona, USA: AAAI Press, 2016. 3501-3508 http://www.mendeley.com/catalog/reading-scene-text-deep-convolutional-sequences/ [17] Ye Q X, Jiao J B, Huang J, Yu H. Text detection and restoration in natural scene images. Journal of Visual Communication and Image Representation, 2007, 18(6):504-513 doi: 10.1016/j.jvcir.2007.07.003 [18] Shi C Z, Wang C H, Xiao B H, Zhang Y, Gao S. Scene text detection using graph model built upon maximally stable extremal regions. Pattern Recognition Letters, 2013, 34(2):107-116 doi: 10.1016/j.patrec.2012.09.019 [19] Huang W L, Qiao Y, Tang X O. Robust scene text detection with convolution neural network induced MSER trees. In: Proceedings of the 13th European Conference on Computer Vision. Cham, Switzerland: Springer, 2014. 497-511 doi: 10.1007/978-3-319-10593-2_33 [20] Li Y, Jia W J, Shen C H, van den Hengel A. Characterness:an indicator of text in the wild. IEEE Transactions on Image Processing, 2014, 23(4):1666-1677 doi: 10.1109/TIP.2014.2302896 [21] Yi C C, Tian Y L. Text string detection from natural scenes by structure-based partition and grouping. IEEE Transactions on Image Processing, 2011, 20(9):2594-2605 doi: 10.1109/TIP.2011.2126586 [22] Ye Q X, Doermann D. Text detection and recognition in imagery:a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(7):1480-1500 doi: 10.1109/TPAMI.2014.2366765 [23] Zhang H G, Zhao K L, Song Y Z, Guo J. Text extraction from natural scene image:a survey. Neurocomputing, 2013, 122:310-323 doi: 10.1016/j.neucom.2013.05.037 [24] Zhu Y Y, Yao C, Bai X. Scene text detection and recognition:recent advances and future trends. Frontiers of Computer Science, 2016, 10(1):19-36 doi: 10.1007/s11704-015-4488-0 [25] Yin X C, Zuo Z Y, Tian S, Liu C L. Text detection, tracking and recognition in video:a comprehensive survey. IEEE Transactions on Image Processing, 2016, 25(6):2752-2773 doi: 10.1109/TIP.2016.2554321 [26] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊.深度学习在手写汉字识别中的应用综述, 自动化学报, 2016, 42(8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtmlJin Lian-Wen, Zhong Zhuo-Yao, Yang Zhao, Yang Wei-Xin, Xie Ze-Cheng, Sun Jun. Applications of deep learning for handwritten Chinese character recognition:a review. Acta Automatica Sinica, 2016, 42(8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtml [27] Ohya J, Shio A, Akamatsu S. Recognizing characters in scene images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994, 16(2):214-220 doi: 10.1109/34.273729 [28] Zhong Y, Karu K, Jain A K. Locating text in complex color images. Pattern Recognition, 1995, 28(10):1523-1535 doi: 10.1016/0031-3203(95)00030-4 [29] Lee C M, Kankanhalli A. Automatic extraction of characters in complex scene images. International Journal of Pattern Recognition and Artificial Intelligence, 1995, 9(1):67-82 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=d3a27e8256cc71ff249eb4debc893f5a [30] Shahab A, Shafait F, Dengel A. ICDAR 2011 robust reading competition challenge 2: reading text in scene images. In: Proceedings of the 2011 International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 1491-1496 http://ieeexplore.ieee.org/document/6065556 [31] Liao M H, Shi B G, Bai X, Wang X G, Liu W Y. Textboxes: a fast text detector with a single deep neural network. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, CA, USA: AAAI, 2017. 4161-4167 http://mc.eistar.net/UpLoadFiles/Papers/TextBoxes-AAAI17-draft.pdf [32] Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, et al. ICDAR 2015 competition on robust reading. In: Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis, Tunisia: IEEE, 2015. 1156-1160 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/icdar-2015-competition-on-robust-reading-2O0ncmuPQ2 [33] Shi B G, Bai X, Belongie S. Detecting oriented text in natural images by linking segments. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 3482-3490 http://arxiv.org/abs/1703.06520 [34] Epshtein B, Ofek E, Wexler Y. Detecting text in natural scenes with stroke width transform. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 2963-2970 http://www.mendeley.com/catalog/detecting-text-natural-scenes-stroke-width-transform/ [35] Wang R M, Sang N, Gao C X. Text detection approach based on confidence map and context information. Neurocomputing, 2015, 157:153-165 doi: 10.1016/j.neucom.2015.01.023 [36] Yi C C, Tian Y L. Text extraction from scene images by character appearance and structure modeling. Computer Vision and Image Understanding, 2013, 117(2):182-194 doi: 10.1016/j.cviu.2012.11.002 [37] Tian Z, Huang W L, He T, He P, Qiao Y. Detecting text in natural image with connectionist text proposal network. In: Proceedings of the 14th European Conference on Computer Vision. Cham, Switzerland: Springer, 2016. 56-72 doi: 10.1007/978-3-319-46484-8_4 [38] Shivakumara P, Phan T Q, Tan C L. A Laplacian approach to multi-oriented text detection in video. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(2):412-419 doi: 10.1109/TPAMI.2010.166 [39] Yao C, Bai X, Liu W Y, Ma Y, Tu Z W. Detecting texts of arbitrary orientations in natural images. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 1083-1090 http://www.mendeley.com/catalog/detecting-texts-arbitrary-orientations-natural-images/ [40] Yao C, Zhang X, Bai X, Liu W Y, Ma Y, Tu Z W. Rotation-invariant features for multi-oriented text detection in natural images. PLoS One, 2013, 8(8):e70173 doi: 10.1371/journal.pone.0070173 [41] Zhang Z, Zhang C Q, Shen W, Yao C, Liu W Y, Bai X. Multi-oriented text detection with fully convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 4159-4167 http://adsabs.harvard.edu/abs/2016arXiv160404018Z [42] Huang W Y, He D F, Yang X, Zhou Z H, Kifer D, Giles C L. Detecting arbitrary oriented text in the wild with a visual attention model. In: Proceedings of the 2016 ACM on Multimedia Conference. Amsterdam, The Netherlands: ACM, 2016. 551-555 http://dl.acm.org/citation.cfm?doid=2964284.2967282 [43] Raza A, Siddiqi I, Djeddi C, Ennaji A. Multilingual artificial text detection using a cascade of transforms. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, D.C., USA: IEEE, 2013. 309-313 https://dl.acm.org/citation.cfm?id=2549575 [44] Ren X H, Zhou Y, He J H, Chen K, Yang X K, Sun J. A convolutional neural network based Chinese text detection algorithm via text structure modeling. IEEE Transactions on Multimedia, 2017, 19(3):506-518 doi: 10.1109/TMM.2016.2625259 [45] 颜建强.图像视频复杂场景中文字检测识别方法研究[博士学位论文], 西安电子科技大学, 中国, 2014Yan Jian-Qiang. Text Detection and Recognition in Complex Scene of Image and Video[Ph.D. dissertation], Xidian University, China, 2014 [46] Wang T, Wu D J, Coates A, Ng A Y. End-to-end text recognition with convolutional neural networks. In: Proceedings of the 21st International Conference on Pattern Recognition. Tsukuba, Japan: IEEE, 2012. 3304-3308 http://citeseerx.ist.psu.edu/viewdoc/similar?doi=10.1.1.252.8930&type=cc [47] Sun L, Huo Q, Jia W, Chen K. Robust text detection in natural scene images by generalized color-enhanced contrasting extremal region and neural networks. In: Proceedings of the 22th International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014. 2715-2720 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/robust-text-detection-in-natural-scene-images-by-generalized-color-LsMesHoFfD [48] Jaderberg M, Vedaldi A, Zisserman A. Deep features for text spotting. In: Proceedings of the 13th European Conference on Computer Vision. Cham, Switzerland: Springer, 2014. 512-528 doi: 10.1007/978-3-319-10593-2_34 [49] Zheng Y, Li Q, Liu J, Liu H P, Li G, Zhang S W. A cascaded method for text detection in natural scene images. Neurocomputing, 2017, 238:307-315 doi: 10.1016/j.neucom.2017.01.066 [50] Zhou X Y, Yao C, Wen H, Wang Y Z, Zhou S C, He W R, et al. East: an efficient and accurate scene text detector. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 2642-2651 http://arxiv.org/abs/1704.03155 [51] Shi B G, Yao C, Liao M H, Yang M K, Xu P, Cui L Y, et al. ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). arXiv preprint arXiv: 1708.09585, 2017 http://arxiv.org/abs/1708.09585 [52] Lienhart R W, Stuber F. Automatic text recognition in digital videos. In: Proceedings Volume 2666, Image and Video Processing IV. San Jose, CA, USA: SPIE, 1996. 180-188 http://www.mysciencework.com/publication/show/automatic-text-recognition-in-digital-videos [53] Busta M, Neumann L, Matas J. FASText: efficient unconstrained scene text detector. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1206-1214 http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7410500&navigation=1 [54] Liu X Q, Samarabandu J. Multiscale edge-based text extraction from complex images. In: Proceedings of the 2006 IEEE International Conference on Multimedia and Expo. Toronto, Ont. Canada: IEEE, 2006. 1721-1724 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=4036951 [55] Liu C M, Wang C H, Dai R W. Text detection in images based on unsupervised classification of edge-based features. In: Proceedings of the 8th International Conference on Document Analysis and Recognition. Seoul, South Korea: IEEE, 2005. 610-614 http://www.mendeley.com/research/text-detection-images-based-unsupervised-classification-edgebased-features/ [56] Jamil A, Siddiqi I, Arif F, Raza A. Edge-based features for localization of artificial urdu text in video images. In: Proceedings of the 11th International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 1120-1124 http://dl.acm.org/citation.cfm?id=2067443 [57] Yu C, Song Y H, Meng Q, Zhang Y L, Liu Y. Text detection and recognition in natural scene with edge analysis. IET Computer Vision, 2015, 9(4):603-613 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=1465ad94d5f239976226cb94596f5651 [58] Veit A, Matera T, Neumann L, Matas J, Belongie S. COCO-text: dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv: 1601.07140, 2016 http://arxiv.org/abs/1601.07140 [59] Neumann L, Matas J. Real-time scene text localization and recognition. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 3538-3545 http://dl.acm.org/citation.cfm?id=2355095 [60] Neumann L, Matas J. A method for text localization and recognition in real-world images. In: Proceedings of the 10the Asian Conference on Computer Vision. Berlin, Heidelberg, Germany: Springer, 2010. 770-783 doi: 10.1007%2F978-3-642-19318-7_60 [61] González A, Bergasa L M, Yebes J, Bronte S. Text location in complex images. In: Proceedings of the 21st International Conference on Pattern Recognition. Tsukuba, Japan: IEEE, 2012. 617-620 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/text-location-in-complex-images-cQaWqeDZiu [62] Gómez L, Karatzas D. MSER-based real-time text detection and tracking. In: Proceedings of the 22th International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014. 3110-3115 http://www.ingentaconnect.com/content/klu/44/2014/00000023/00000003/art00015 [63] Kang L, Li Y, Doermann D. Orientation robust text line detection in natural images. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 4034-041 http://www.mendeley.com/research/orientation-robust-text-line-detection-natural-images/ [64] Zhu A N, Gao R W, Uchida S. Could scene context be beneficial for scene text detection. Pattern Recognition, 2016, 58:204-251 doi: 10.1016/j.patcog.2016.04.011 [65] Sun L, Huo Q. An improved component tree based approach to user-intention guided text extraction from natural scene images. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, DC, USA: IEEE, 2013. 383-387 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/an-improved-component-tree-based-approach-to-user-intention-guided-f0HzXdQiA4 [66] Mancas-Thillou C, Gosselin B. Color text extraction with selective metric-based clustering. Computer Vision and Image Understanding, 2007, 107(1-2):97-107 doi: 10.1016/j.cviu.2006.11.010 [67] Lai A N, Park K, Kumar M, Lee G. Korean text extraction by local color quantization and k-means clustering in natural scene. In: Proceedings of the 1st Asian Conference on Intelligent Information and Database Systems. Dong Hoi, Vietnam: IEEE, 2009. 138-143 http://www.mendeley.com/research/korean-text-extraction-local-color-quantization-kmeans-clustering-natural-scene/ [68] Garg R, Hassan E, Chaudhury S, Gopal M. A CRF based scheme for overlapping multi-colored text graphics separation. In: Proceedings of the 11th International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 1215-1219 http://dl.acm.org/citation.cfm?id=2067500 [69] Zhou G, Liu Y H, Tian Z Q, Su Y Q. A new hybrid method to detect text in natural scene. In: Proceedings of the 18th IEEE International Conference on Image Processing. Brussels, Belgium: IEEE, 2011. 2605-2608 http://ieeexplore.ieee.org/document/6116199/ [70] Mosleh A, Bouguila N, Hamza A B. Image text detection using a bandlet-based edge detector and stroke width transform. In: Proceedings of the British Machine Vision Conference. BMVA Press, 2012. 63.1-63.12 [71] Karthikeyan S, Jagadeesh V, Manjunath B S. Learning bottom-up text attention maps for text detection using stroke width transform. In: Proceedings of the 20th IEEE International Conference on Image Processing. Melbourne, VIC, Australia: IEEE, 2013. 3312-3316 http://ieeexplore.ieee.org/document/6738682/ [72] Huang W L, Lin Z, Yang J C, Wang J. Text localization in natural images using stroke feature transform and text covariance descriptors. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 1241-1248 http://www.mendeley.com/catalog/text-localization-natural-images-using-stroke-feature-transform-text-covariance-descriptors/ [73] Milyaev S, Barinova O, Novikova T, Kohli P, Lempitsky V. Image binarization for end-to-end text understanding in natural images. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, DC, USA: IEEE, 2013. 128-132 http://ieeexplore.ieee.org/document/6628598/ [74] Wang R M, Sang N, Gao C X. Scene text identification by leveraging mid-level patches and context information. IEEE Signal Processing Letters, 2015, 22(7):963-967 doi: 10.1109/LSP.2014.2379625 [75] Wei Y W, Zhang Z J, Shen W, Zeng D, Fang M, Zhou S F. Text detection in scene images based on exhaustive segmentation. Signal Processing:Image Communication, 2017, 50:1-8 doi: 10.1016/j.image.2016.10.003 [76] 姚聪.自然图像中文字检测与识别研究[博士学位论文], 华中科技大学, 中国, 2014Yao Cong. Research on text detection and recognition in natural images[Ph.D. dissertation], Huazhong University of Science and Technology, China, 2014 [77] Chen H Z, Tsai S S, Schroth G, Chen D M, Grzeszczuk R, Girod B. Robust text detection in natural images with edge-enhanced maximally stable extremal regions. In: Proceedings of the 18th IEEE International Conference on Image Processing. Brussels, Belgium: IEEE, 2011. 2609-2612 [78] Koo H I, Kim D H. Scene text detection via connected component clustering and nontext filtering. IEEE Transactions on Image Processing, 2013, 22(6):2296-2305 doi: 10.1109/TIP.2013.2249082 [79] He T, Huang W L, Qiao Y, Yao J. Text-attentional convolutional neural network for scene text detection. IEEE Transactions on Image Processing, 2016, 25(6):2529-2541 doi: 10.1109/TIP.2016.2547588 [80] Li Y, Shen C H, Jia W J, van den Hengel A. Leveraging surrounding context for scene text detection. In: Proceedings of the 20th IEEE International Conference on Image Processing. Melbourne, VIC, Australia: IEEE, 2013. 2264-2268 http://hdl.handle.net/2440/83151 [81] González Á, Bergasa L M. A text reading algorithm for natural images. Image and Vision Computing, 2013, 31(3):255-274 http://dl.acm.org/citation.cfm?id=2450876 [82] Sun L, Huo Q. A component-tree based method for user-intention guided text extraction. In: Proceedings of the 21st International Conference on Pattern Recognition. Tsukuba, Japan: IEEE, 2012. 633-636 [83] Sun L, Huo Q, Jia W, Chen K. A robust approach for text detection from natural scene images. Pattern Recognition, 2015, 48(9):2906-2920 doi: 10.1016/j.patcog.2015.04.002 [84] Louloudis G, Gatos B, Pratikakis I, Halatsis C. Text line detection in handwritten documents. Pattern Recognition, 2008, 41(12):3758-3772 doi: 10.1016/j.patcog.2008.05.011 [85] Rabaev I, Biller O, El-Sana J, Kedem K, Dinstein I. Text line detection in corrupted and damaged historical manuscripts. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, D.C., USA: IEEE, 2013. 812-816 [86] van Beusekom J, Shafait F, Breuel T M. Combined orientation and skew detection using geometric text-line modeling. International Journal on Document Analysis and Recognition, 2010, 13(2):79-92 doi: 10.1007/s10032-009-0109-5 [87] Zhang Z, Shen W, Yao C, Bai X. Symmetry-based text line detection in natural scenes. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 2558-2567 http://www.mendeley.com/research/symmetrybased-text-line-detection-natural-scenes-1/ [88] Wang K, Belongie S. Word spotting in the wild. In: Proceedings of the 11th European Conference on Computer Vision. Berlin, Heidelberg, Germany: Springer, 2010. 591-604 Word spotting in the wild. [89] Hanif S M, Prevost L, Negri P A. A cascade detector for text detection in natural scene images. In: Proceedings of the 19th International Conference on Pattern Recognition. Tampa, FL, USA: IEEE, 2008. 1-4 https://www.mendeley.com/catalogue/cascade-detector-text-detection-natural-scene-images/ [90] Mishra A, Alahari K, Jawahar C V. Top-down and bottom-up cues for scene text recognition. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 2687-2694 [91] Wang K, Babenko B, Belongie S. End-to-end scene text recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1457-1464 http://www.mendeley.com/catalog/end-end-scene-text-recognition/ [92] Tian S X, Pan Y F, Huang C, Lu S J, Yu K, Tan C L. Text flow: a unified text detection system in natural scene images. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4651-4659 http://adsabs.harvard.edu/cgi-bin/nph-data_query?bibcode=2016arXiv160406877T&db_key=PRE&link_type=PREPRINT [93] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA: IEEE, 2001. I-511-I-518 http://www.mendeley.com/research/colonialism-homosexuality-review/ [94] Lienhart R, Kuranov A, Pisarevsky V. Empirical analysis of detection cascades of boosted classifiers for rapid object detection. In: Proceedings of DAGM 25th Pattern Recognition. Berlin, Heidelberg, Germany: Springer, 2003. 297-304 http://www.springerlink.com/content/wyp0xr0wmtmyy4rk [95] Viola P, Jones M J. Robust real-time face detection. International Journal of Computer Vision, 2004, 57(2):137-154 doi: 10.1023/B:VISI.0000013087.49260.fb [96] Lee J J, Lee P H, Lee S W, Yuille A, Koch C. Adaboost for text detection in natural scene. In: Proceedings of the 2011 International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 429-434 http://www.mendeley.com/catalog/adaboost-text-detection-natural-scene/ [97] Chen X R, Yuille A L. Detecting and reading text in natural scenes. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE, 2004. Ⅱ-366-Ⅱ-373 [98] Hanif S M, Prevost L. Text detection and localization in complex scene images using constrained AdaBoost algorithm. In: Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain: IEEE, 2009. 1-5 http://ieeexplore.ieee.org/document/5277813/ [99] Shivakumara P, Huang W H, Phan T Q, Tan C L. Accurate video text detection through classification of low and high contrast images. Pattern Recognition, 2010, 43(6):2165-2185 doi: 10.1016/j.patcog.2010.01.009 [100] Kim W, Kim C. A new approach for overlay text detection and extraction from complex video scene. IEEE Transactions on Image Processing, 2009, 18(2):401-411 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=e3ac5ac111cb0857964d7f0481835a38 [101] Wei Y C, Lin C H. A robust video text detection approach using SVM. Expert Systems with Applications, 2012, 39(12):10832-10840 doi: 10.1016/j.eswa.2012.03.010 [102] Anthimopoulos M, Gatos B, Pratikakis I. A two-stage scheme for text detection in video images. Image and Vision Computing, 2010, 28(9):1413-1426 doi: 10.1016/j.imavis.2010.03.004 [103] Fabrizio J, Marcotegui B, Cord M. Text detection in street level images. Pattern Analysis and Applications, 2013, 16(4):519-533 doi: 10.1007/s10044-013-0329-7 [104] Yao C, Bai X, Shi B G, Liu W Y. Strokelets: a learned multi-scale representation for scene text recognition. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 4042-4049 https://dl.acm.org/citation.cfm?id=2679850 [105] Su B L, Lu S J, Tian S X, Lim J H, Tan C L. Character recognition in natural scenes using convolutional co-occurrence HOG. In: Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014. 2926-2931 http://www.mendeley.com/catalog/character-recognition-natural-scenes-using-convolutional-cooccurrence-hog/ [106] Tian S X, Lu S J, Su B L, Tan C L. Scene text recognition using co-occurrence of histogram of oriented gradients. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, D.C., USA: IEEE, 2013. 912-916 http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6628751 [107] Minetto R, Thome N, Cord M, Leite N J, Stolfi J. T-HOG:an effective gradient-based descriptor for single line text regions. Pattern Recognition, 2013, 46(3):1078-1090 doi: 10.1016/j.patcog.2012.10.009 [108] Yan J Q, Li J, Gao X B. Chinese text location under complex background using Gabor filter and SVM. Neurocomputing, 2011, 74(17):2998-3008 doi: 10.1016/j.neucom.2011.04.031 [109] Leon M, Vilaplana V, Gasull A, Marques F. Caption text extraction for indexing purposes using a hierarchical region-based image model. In: Proceedings of the 16th IEEE International Conference on Image Processing. Cairo, Egypt: IEEE, 2009. 1869-1872 http://dl.acm.org/citation.cfm?id=1819242 [110] Ye Q X, Huang Q M, Gao W, Zhao D B. Fast and robust text detection in images and video frames. Image and Vision Computing, 2005, 23(6):565-576 doi: 10.1016/j.imavis.2005.01.004 [111] Kim K I, Jung K, Kim J H. Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(12):1631-1639 doi: 10.1109/TPAMI.2003.1251157 [112] Nguyen C D, Ardabilian M, Chen L M. Robust car license plate localization using a novel texture descriptor. In: Proceedings of the 6th IEEE International Conference on Advanced Video and Signal Based Surveillance. Genova, Italy: IEEE, 2009. 523-528 http://www.mendeley.com/research/robust-car-license-plate-localization-using-novel-texture-descriptor/ [113] Chen D T, Bourlard H, Thiran J P. Text identification in complex background using SVM. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA: IEEE, 2001. Ⅱ-621-Ⅱ-626 http://www.mendeley.com/research/text-identification-complex-background-using-svm/ [114] Lee C Y, Bhardwaj A, Di W, Jagadeesh V, Piramuthu R. Region-based discriminative feature pooling for scene text recognition. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 4050-4057 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/region-based-discriminative-feature-pooling-for-scene-text-recognition-Gg8429ugyA [115] Chen X R, Yuille A L. Detecting and reading text in natural scenes. In: Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC, USA: IEEE, 2004. Ⅱ-366-Ⅱ-373 http://ieeexplore.ieee.org/iel5/9183/29134/01315187.pdf [116] Yin X W, Yin X C, Hao H W, Iqbal K. Effective text localization in natural scene images with MSER, geometry-based grouping and AdaBoost. In: Proceedings of the 21st IEEE International Conference on Pattern Recognition. Tsukuba, Japan: IEEE, 2012. 725-728 http://www.mendeley.com/catalog/effective-text-localization-natural-scene-images-mser-geometrybased-grouping-adaboost/ [117] Shi C Z, Wang C H, Xiao B H, Gao S, Hu J L. End-to-end scene text recognition using tree-structured models. Pattern Recognition, 2014, 47(9):2853-2866 doi: 10.1016/j.patcog.2014.03.023 [118] Zhang Y, Wang C H, Xiao B H, Shi C Z. A new method for text verification based on random forests. In: Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition. Washington, DC, USA: IEEE, 2012. 109-113 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/a-new-method-for-text-verification-based-on-random-forests-dAM2VSzy0U [119] Xu H L, Su F. A robust hierarchical detection method for scene text based on convolutional neural networks. In: Proceedings of the 2015 IEEE International Conference on Multimedia and Expo. Turin, Italy: IEEE, 2015. 1-6 [120] Li H P, Doermann D, Kia O. Automatic text detection and tracking in digital video. IEEE Transactions on Image Processing, 2000, 9(1):147-156 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=aa6f95a5f67a6c39e7babbde7d125ec7 [121] Shi C Z, Wang C H, Xiao B H, Zhang Y, Gao S, Zhang Z. Scene text recognition using part-based tree-structured character detections. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE, 2013. 2961-2968 http://www.mendeley.com/catalog/scene-text-recognition-using-partbased-treestructured-character-detection/ [122] Karatzas, D, Mestre S R, Mas J, Nourbakhsh F, Roy P P. ICDAR 2011 Robust Reading Competition-Challenge 1: Reading Text in Born-Digital Images (Web and Email). In: Proceedings of the International Conference on Document Analysis and Recognition. Beijing, China: IEEE, 2011. 1485-1490 http://ieeexplore.ieee.org/document/6065555/ [123] Karatzas D, Shafait F, Uchida S, Iwamura M, i Bigorda L G, Mestre S R, et al. ICDAR 2013 robust reading competition. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, D.C., USA: IEEE, 2013. 1484-1493 http://dl.acm.org/citation.cfm?id=2549400.2549448 [124] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [125] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [126] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786):504-507 doi: 10.1126/science.1127647 [127] Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [128] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8):1735-1780 doi: 10.1162/neco.1997.9.8.1735 [129] Simard P Y, Steinkraus D, Platt J C. Best practices for convolutional neural networks applied to visual document analysis. In: Proceedings of the 7th International Conference on Document Analysis and Recognition. Washington, DC, USA: IEEE, 2003. 958-963 http://www.mendeley.com/catalog/best-practices-convolutional-neural-networks-applied-visual-document-analysis/ [130] Zhong Z Y, Jin L W, Zhang S Y, Feng Z Y. DeepText: a unified framework for text proposal generation and text detection in natural images. arXiv preprint arXiv: 1605.07314, 2016 http://arxiv.org/abs/1605.07314v1 [131] Liao M H, Shi B G, Bai X. Textboxes++: a single-shot oriented scene text detector. arXiv preprint arXiv: 1801.02765, 2018 http://ieeexplore.ieee.org/document/8334248/ [132] He W H, Zhang X Y, Yin F, Liu C L. Deep direct regression for multi-oriented scene text detection. arXiv preprint arXiv: 1703.08289, 2017 http://arxiv.org/abs/1703.08289 [133] Dai Y C, Huang Z, Gao Y T, Xu Y X, Chen K, Guo J, et al. Fused text segmentation networks for multi-oriented scene text detection. arXiv preprint arXiv: 1709.03272, 2017 http://arxiv.org/abs/1709.03272 [134] Jiang Y Y, Zhu X Y, Wang X B, Yang S L, Li W, Wang H, et al. R2CNN: rotational region CNN for orientation robust scene text detection. arXiv preprint arXiv: 1706.09579, 2017 http://arxiv.org/abs/1706.09579 [135] Liu Y L, Jin L W, Zhang S T, Zhang S. Detecting curve text in the wild: new dataset and new solution. arXiv preprint arXiv: 1712.02170, 2017 http://arxiv.org/abs/1712.02170 [136] Zhu Y X, Du J. Sliding line point regression for shape robust scene text detection. arXiv preprint arXiv: 1801.09969, 2018 http://arxiv.org/abs/1801.09969 [137] Jaderberg M, Simonyan K, Vedaldi A, Zisserman A. Reading text in the wild with convolutional neural networks. International Journal of Computer Vision, 2016, 116(1):1-20 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=296ed6181656155f8f0993494adf6aac [138] Ma J Q, Shao W Y, Ye H, Wang L, Wang H, Zheng Y B, et al. Arbitrary-oriented scene text detection via rotation proposals. IEEE Transactions on Multimedia, DOI: 10.1109/TMM.2018.2818020 [139] Xiang D L, Guo Q, Xia Y. Robust text detection with vertically-regressed proposal network. In: Proceedings of the European Conference on Computer Vision. Cham, Switzerland: Springer, 2016. 351-363 doi: 10.1007/978-3-319-46604-0_26 [140] Yao C, Bai X, Sang N, Zhou X Y, Zhou S C, Cao Z M. Scene text detection via holistic, multi-channel prediction. arXiv preprint arXiv: 1606.09002, 2016 http://arxiv.org/abs/1606.09002 [141] Yang X, He D F, Zhou Z H, Kifer D, Giles C L. Learning to read irregular text with attention mechanisms. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia, 2017. 3280-3286 [142] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. In: Proceedings of the International Conference on Neural Information Processing Systems. Istanbul, Turkey, 2015. 91-99 http://dl.acm.org/citation.cfm?id=2969250&preflayout=flat [143] Li H, Wang P, Shen C H. Towards end-to-end text spotting with convolutional recurrent neural networks. arXiv preprint arXiv: 1707.03985, 2017 http://arxiv.org/abs/1707.03985 [144] Liu X B, Liang D, Yan S, Chen D G, Qiao Y, Yan J J. FOTS: fast oriented text spotting with a unified network. arXiv preprint arXiv: 1801.01671, 2018 http://arxiv.org/abs/1801.01671 [145] He T, Huang W L, Qiao Y, Yao J. Accurate text localization in natural image with cascaded convolutional text network. arXiv preprint arXiv: 1603.09423, 2016 http://arxiv.org/abs/1603.09423 [146] Deng D, Liu H F, Li X L, Cai D. PixelLink: detecting scene text via instance segmentation. arXiv preprint arXiv: 1801.01315, 2018 [147] Lyu P, Yao C, Wu W H, Yan S C, Bai X. Multi-oriented scene text detection via corner localization and region segmentation. arXiv preprint arXiv: 1802.08948, 2018 http://arxiv.org/abs/1802.08948 [148] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 2315-2324 http://arxiv.org/abs/1604.06646 [149] Jaderberg M, Simonyan K, Vedaldi A, Zisserman A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv preprint arXiv: 1406.2227, 2014 http://arxiv.org/abs/1406.2227 [150] Hu H, Zhang C Q, Luo Y X, Wang Y Z, Han J Y, Ding E R. WordSup: exploiting word annotations for character based text detection. arXiv preprint arXiv: 1708.06720, 2017 http://arxiv.org/abs/1708.06720 [151] Chen D T, Odobez J M, Bourlard H. Text detection and recognition in images and video frames. Pattern Recognition, 2004, 37(3):595-608 doi: 10.1016/j.patcog.2003.06.001 [152] Neumann L, Matas J. Scene text localization and recognition with oriented stroke detection. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 97-104 http://ieeexplore.ieee.org/document/6751121/ [153] Bissacco A, Cummins M, Netzer Y, Neven H. PhotoOCR: reading text in uncontrolled conditions. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013. 785-792 http://www.mendeley.com/catalog/photoocr-reading-text-uncontrolled-conditions/ [154] Pan Y F, Hou X W, Liu C L. Text localization in natural scene images based on conditional random field. In: Proceedings of the 10th International Conference on Document Analysis and Recognition. Barcelona, Spain: IEEE, 2009. 6-10 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/text-localization-in-natural-scene-images-based-on-conditional-random-ZgoFPu8hH5 [155] Bartz C, Yang H J, Meinel C. STN-OCR: a single neural network for text detection and text recognition. arXiv preprint arXiv: 1707.08831, 2017 http://arxiv.org/abs/1707.08831 [156] Bušta M, Neumann L, Matas J. Deep TextSpotter: an end-to-end trainable scene text localization and recognition framework. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2223-2231 [157] Alsharif O, Pineau J. End-to-end text recognition with hybrid HMM maxout models. arXiv preprint arXiv: 1310.1811, 2013 [158] Yin F, Wu Y C, Zhang X Y, Liu C L. Scene text recognition with sliding convolutional character models. arXiv preprint arXiv: 1709.01727, 2017 http://arxiv.org/abs/1709.01727 [159] Patel Y, Bušta M, Matas J. E2E-MLT-an unconstrained end-to-end method for multi-language scene text. arXiv preprint arXiv: 1801.09919, 2018 http://arxiv.org/abs/1801.09919 [160] Bartz C, Yang H J, Meinel C. SEE: towards semi-supervised end-to-end scene text recognition. arXiv preprint arXiv: 1712.05404, 2017 http://arxiv.org/abs/1712.05404 [161] Lucas S M, Panaretos A, Sosa L, Tang A, Wong S, Young R. ICDAR 2003 robust reading competitions. In: Proceedings of the 7th International Conference on Document Analysis and Recognition. Edinburgh, UK: IEEE, 2003. 682-687 http://libra.msra.cn/Publication/606663/icdar-2003-robust-reading-competitions [162] Lee S, Cho M S, Jung K, Kim J H. Scene text extraction with edge constraint and text collinearity. In: Proceedings of the 20th International Conference on Pattern Recognition. Istanbul, Turkey: IEEE, 2010. 3983-3986 http://www.mendeley.com/catalog/scene-text-extraction-edge-constraint-text-collinearity/ [163] Nagy R, Dicker A, Meyer-Wegener K. NEOCR: a configurable dataset for natural image text recognition. In: Proceedings of the International Workshop on Camera-Based Document Analysis and Recognition. Berlin, Heidelberg, Germany: Springer, 2011. 150-163 [164] Yin X C, Pei W Y, Zhang J, Hao H W. Multi-orientation scene text detection with adaptive clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):1930-1937 doi: 10.1109/TPAMI.2014.2388210 [165] Su P. COCO-text explorer. Cornell University CS Department MEng Report, 2016. [166] Wolf C, Jolion J M. Object count/area graphs for the evaluation of object detection and segmentation algorithms. International Journal of Document Analysis and Recognition, 2006, 8(4):280-296 doi: 10.1007/s10032-006-0014-0 [167] Everingham M, Eslami S M, van Gool L, Williams C K I, Winn J, Zisserman A. The pascal visual object classes challenge:a retrospective. International Journal of Computer Vision, 2015, 111(1):98-136 doi: 10.1007/s11263-014-0733-5 [168] Freeman H, Shapira R. Determining the minimum-area encasing rectangle for an arbitrary closed curve. Magazine Communications of the ACM, 1975, 18(7):409-413 doi: 10.1145/360881.360919 [169] Everingham M, van Gool L, Williams C K I, Winn J, Zisserman A. The pascal visual object classes (VOC) challenge. International Journal of Computer Vision, 2010, 88(2):303-338 doi: 10.1007/s11263-009-0275-4 [170] Lucas S M. ICDAR 2005 text locating competition results. In: Proceedings of the 8th International Conference on Document Analysis and Recognition. Seoul, South Korea: IEEE, 2005. 80-84 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=1575514 [171] Shivakumara P, Wu L, Lu T, Tan C L, Blumenstein M, Anami B S. Fractals based multi-oriented text detection system for recognition in mobile video images. Pattern Recognition, 2017, 68:158-174 doi: 10.1016/j.patcog.2017.03.018 [172] Minetto R, Thome N, Cord M, Leite N J, Stolfi J. SnooperText:a text detection system for automatic indexing of urban scenes. Computer Vision and Image Understanding, 2014, 122:92-104 doi: 10.1016/j.cviu.2013.10.004 [173] Jung J, Lee S, Cho M S, Kim J H. Touch TT:scene text extractor using touchscreen interface. ETRI Journal, 2011, 33(1):78-88 doi: 10.4218/etrij.11.1510.0029 [174] Lyu P Y, Liao M H, Yao C, Wu W H, Bai X. Mask TextSpotter: an end-to-end trainable neural network for spotting text with arbitrary shapes. In: Proceedings of the Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 71-88 http://arxiv.org/abs/1807.02242 [175] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2001. I-511-I-518 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=990517 [176] Judd T, Ehinger K, Durand F, Torralba A. Learning to predict where humans look. In: Proceedings of the 12th International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009. 2106-2113 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5459462 [177] Wang H C, Pomplun M. The attraction of visual attention to texts in real-world scenes. Journal of Vision, 2012, 12(6):26 doi: 10.1167/12.6.26 [178] Shahab A, Shafait F, Dengel A, Uchida S. How salient is scene text? In: Proceedings of the 10th IAPR International Workshop on Document Analysis Systems. Washington D.C., USA: IEEE, 2012. 317-321 http://www.mendeley.com/catalog/salient-scene-text/ [179] Karaoglu S, van Gemert J C, Gevers T. Object reading: text recognition for object recognition. In: Proceedings of the 12th European Conference on Computer Vision. Berlin, Heidelberg, Germany: Springer, 2012. 456-465 http://www.springerlink.com/index/R732145575207180.pdf [180] Sun Q Y, Lu Y, Sun S L. A visual attention based approach to text extraction. In: Proceedings of the 20th International Conference on Pattern Recognition. Istanbul, Turkey: IEEE, 2010. 3991-3995 http://www.deepdyve.com/lp/institute-of-electrical-and-electronics-engineers/a-visual-attention-based-approach-to-text-extraction-OiJOVsnbeo [181] Mesquita R G, Mello C A B. Finding text in natural scenes by visual attention? In: Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics. Manchester, UK: IEEE, 2013. 4243-4247 http://ieeexplore.ieee.org/document/6722476/ [182] Gao R W, Uchida S, Shahab A, Shafait F, Frinken V. Visual saliency models for text detection in real world. PLoS One, 2014, 9(12):e114539 doi: 10.1371/journal.pone.0114539 [183] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259 doi: 10.1109/34.730558 [184] He P, Huang W L, He T, Zhu Q L, Qiao Y, Li X L. Single shot text detector with regional attention. arXiv preprint arXiv: 709.0138, 2017 http://arxiv.org/abs/1709.00138 [185] Karaoglu S, Tao R, van Gemert J C, Gevers T. Con-text:text detection for fine-grained object classification. IEEE Transactions on Image Processing, 2017, 26(8):3965-3980 doi: 10.1109/TIP.2017.2707805 [186] Du Y N, Duan G Q, Ai H Z. Context-based text detection in natural scenes. In: Proceedings of the 19th IEEE International Conference on Image Processing. Orlando, FL, USA: IEEE, 2012. 1857-1860 http://ieeexplore.ieee.org/document/6467245/ [187] Pan J Y, Chen Y, Anderson B, Berkhin P, Kanade T. Effectively leveraging visual context to detect texts in natural scenes. In: Proceedings of the 11th Asian Conference on Computer Vision. Daejeon, South Korea, 2012. 1-14 http://www.cs.cmu.edu/~jiyanpan/papers/accv12.pdf [188] Lin L, Qu Y Y, Liao W M. Structure context clues for Chinese text detection. In: Proceedings of the International Conference on Internet Multimedia Computing and Service. Xiamen, China: ACM, 2014. 327 http://dl.acm.org/citation.cfm?id=2632925 [189] He D F, Yang X, Huang W Y, Zhou Z H, Kifer D, Giles C L. Aggregating local context for accurate scene text detection. In: Proceedings of the Asian Conference on Computer Vision. Cham, Switzerland: Springer, 2016. 280-296 doi: 10.1007/978-3-319-54193-8_18 [190] Hauptmann A G, Witbrock M J. Informedia: news-on-demand multimedia information acquisition and retrieval. Intelligent Multimedia Information Retrieval. Cambridge, MA: AAAI Press, 1997. http://dl.acm.org/citation.cfm?id=266279 [191] Smith J R, Chang S F. VisualSEEk: a fully automated content-based image query system. In: Proceedings of the 4th ACM International Conference on Multimedia. Boston, Massachusetts, USA: ACM, 1996. 87-98 http://citeseerx.ist.psu.edu/viewdoc/summary?cid=83307 [192] Bai X, Yang M K, Lyu P, Xu Y C, Luo J B. Integrating scene text and visual appearance for fine-grained image classification. arXiv preprint arXiv: 1704.04613, 2017 http://arxiv.org/abs/1704.04613 [193] Shi B G, Yao C, Zhang C Q, Guo X W, Huang F Y, Bai X. Automatic script identification in the wild. arXiv preprint arXiv: 1505.02982, 2015 [194] Bruce V, Young A. Understanding face recognition. British Journal of Psychology, 1986, 77(3):305-327 doi: 10.1111/bjop.1986.77.issue-3 [195] Kanwisher N, McDermott J, Chun M M. The fusiform face area:a module in human extrastriate cortex specialized for face perception. The Journal of Neuroscience, 1997, 17(11):4302-4311 doi: 10.1523/JNEUROSCI.17-11-04302.1997 -

 下载:
下载:






计量
- 文章访问数: 4204
- HTML全文浏览量: 2092
- PDF下载量: 1597
- 被引次数: 0
