

Finite-time Containment Control of Second-order Multi-agent Systems With Mismatched Disturbances
-
摘要: 针对多自主体系统群集运动问题,本文研究了带有不匹配干扰的二阶系统有限时间包容控制.运用现代控制理论,设计了非线性观测器,对系统未知状态和干扰进行估计.在状态估计的基础上,构建了基于干扰观测器的多自主体系统的协同控制算法.应用代数图论和齐次性理论等方法,分析了二阶多自主体系统有限时间包容控制.数据仿真中应用基于观测器的包容控制算法,使得系统的运动状态最终都收敛到由多个领导者所围成的目标区域中,验证了本文结果的有效性.Abstract: In this paper, a finite-time containment control algorithm is studied for the second-order multi-agent systems with mismatched disturbances. By applying the modern control theory, a nonlinear observer is designed to estimate the unknown states and disturbances of the systems. On the basis of the state estimation, a cooperative control algorithm based on disturbance observers for multi-agent systems is constructed. By applying the algebraic graph theory and homogeneous theory, the finite-time containment control of the second-order multi-agent systems is analyzed. The validity of containment control algorithm based on the disturbance observer is verified in simulation examples, where the motion states of the system eventually converge to the target area surrounded by multiple leaders.
-
Key words:
- Containment control /
- finite time /
- mismatched disturbances /
- multiple leaders
-
近年来, 多自主体系统控制成为复杂系统领域的热点研究问题.基于生物学启发的多自主体系统协调控制在多机器人协同工作、交通车辆控制和无人机的编队控制等领域有着广泛的应用, 促进着多自主体系统研究的快速发展.
模仿具有领导者的自然界中的群集运动, 多自主体系统的跟随者动态追随领导者的运动状态来实现群集系统的协同控制[1-3].包容控制的本质是一组跟随者通过所设计的网络通信控制协议最终收敛到由多个领导者所围成的几何区域(凸包)中.文献[4]研究了一般线性时变离散时间多自主体系统的包容控制问题, 并基于轨迹分析的方法证明控制算法的有效性.文献[5]讨论了一阶和二阶多自主体系统的包容控制问题, 并证明在事件触发情况下具有时间延迟的动态系统可以实现包容控制.文献[6]讨论了非线性高阶多自主体系统的包容控制问题, 提出了一种分布式自适应非线性协议, 并证明此协议同样适用于只有一个动态领导者的Leader-follower一致性问题.文献[7]研究了带有传输噪声的多自主体系统的包容控制问题, 并得到在动态切换拓扑和随机切换拓扑下均方包容控制的充分条件.文献[8]研究了在有向网络拓扑下具有固定时延的多个静态或动态领导者的多自主体系统包容控制问题, 并得到了可以使一阶多自主体系统实现包容控制的充分条件.从以上文献可知, 虽然都可以实现系统的包容控制, 但是没有考虑在有限时间内多自主体系统的状态一致性.事实上, 在工业生产中更需要在有限时间内使系统实现一致, 因为不仅可以提高收敛速率, 而且可以使闭环系统提高抑制干扰的能力.文献[9]研究了有向网络拓扑下, 时延多自主体系统的运动一致性, 得到了保证系统一致性的控制增益与时延上界之间的关系.文献[10]研究了二阶随机多自主体系统有限时间一致性问题, 并提出了分布式控制算法, 使所有自主体在无向拓扑的情况下有限时间一致收敛.文献[11]研究了一般线性多自主体系统的分布式有限时间包容控制问题, 并证明了在有向通信拓扑情况下跟随者在有限时间内可以收敛到领导者所围成的凸包中.文献[12]研究了异构多自主体系统有限时间一致性问题, 并得到线性和非线性系统在有领导者和无领导者的情况下达到有限时间一致性的充分条件.
在实际应用中, 多自主体系统通常会受到各种干扰的影响, 干扰的存在会影响系统的运动状态, 所以研究干扰对系统所产生的影响是很有必要的.文献[13]研究了带有外部干扰的多自主体系统的包容控制问题, 并提出状态反馈和输出反馈控制协议, 设计外部干扰观测器使得系统实现包容控制.文献[14]研究了带有外部干扰的二阶多自主体系统的一致性, 设计了干扰观测器来估计干扰系统所产生的干扰.对于固定和切换拓扑, 可以实现在复合控制器下具有干扰的多自主体系统的渐近一致.文献[15]在多自主体系统带有未知的外部干扰情况下, 提出了一种分布式状态观测器, 可观测各个自主体的未知状态和所受干扰, 并提出了可使系统达到一致性的控制算法.文献[16]基于自主体的不同特性, 提出了非均匀分数阶多自主体系统, 并且研究了具有通信时延的非均匀分数阶多自主体系统的分布式包容控制问题.文献[17]研究了带有干扰的连续时间多自主体系统的有限时间一致性问题.文献[18]讨论了带有干扰的有领导者和无领导者的多自主体系统有限时间一致性问题, 并基于有限时间控制技术, 设计了一种分布式控制算法, 证明在受到干扰的情况下, 系统可达到状态一致.前面的研究成果仅仅考虑匹配干扰(干扰与控制输入在系统的同一通道中)对系统的影响, 然而在多自主体系统中也存在不匹配干扰(干扰与控制输入在系统的不同通道中), 例如多液压机械臂系统和多导弹系统等.多液压机械臂的电液伺服作动器中, 模型参数摄动、环境干扰力矩等干扰直接影响活塞杆和机械臂的运动, 而不是通过控制电压通道, 属于不匹配干扰.在多导弹系统中, 导弹所受到的风等环境干扰属于不匹配干扰.不匹配干扰以异于匹配干扰的方式对系统性能产生影响, 已有的抑制匹配干扰的控制方法无法有效地处理不匹配干扰对系统性能的影响.因此, 研究带有不匹配干扰的多智能体系统的抗干扰控制意义重大, 但是, 现有文献对具有不匹配干扰的多自主体系统的有限时间包容控制研究鲜有报道.
本文研究由多个领导者引导的具有不匹配干扰的二阶多自主体系统的有限时间包容控制问题.本文的创新点是在多智能体系统受到不匹配干扰影响的情况下, 提出了有限时间的非线性包容控制算法, 研究具有不匹配干扰的多自主体系统的群集运动.
1. 代数图论
设$ G = (V, E, A) $是$ n $个节点的加权无向图, $ V = \{v_1, v_2, \cdots, v_n\} $表示其节点的集合, 其中节点的下标是一个有限集合$ I = \{1, 2, \cdots, n\} $; $ E\subseteq V\times V $表示边的集合, $ e_{ij} = (v_i, v_j) $表示图$ G $的边; $ A = [a_{ij}]\in{\bf R}^{n\times n} $为节点邻接矩阵, 对于$ \forall i\in I $, 都有$ a_{ii} = 0 $; 对于$ e_{ij}\in E $, 都有$ a_{ij} > 0 $, 否则$ a_{ij} = 0 $.节点i的邻居集合定义为$ N_i = \{v_j\in V \mid(v_i, v_j)\in E\} $.令$ D = {\rm diag}\{d_1, d_2, \cdots, d_n\}\in{\bf R}^{n\times n} $为图$ G $的度矩阵, 其中, $ d_i = \sum_{j\neq i}a_{ij} $, $ i = 1, 2, \cdots, n $, 拓扑图$ G $的Laplacian矩阵定义为: $ L = D-A\in {\bf R}^{n\times n} $.如果节点$ v_i $和$ v_j $之间路径存在, 那么则称$ v_i $和$ v_j $之间是可达的, 否则, 称$ v_i $和$ v_j $之间是不可达的.
定义1[19].设集合$X = \{x_1, x_2, \cdots, x_m\}$为实向量空间R$^n$的子集, $X$的凸包定义为$CO(X) = \{ \sum_{i = 1}^m\alpha_ix_i\mid x_i\in X, \alpha_i \geq0, \sum_{i = 1}^m\alpha_i = 1\}$.
定义2[20].考虑如下连续非线性系统:
$ \begin{equation} \dot{\pmb x} = \pmb{f}({\pmb x}), {\pmb x}(0) = {\pmb x}_0\in {\bf R}^n \end{equation} $
(1) 其中连续向量流$ \textbf{f}({\pmb x}) = (f_1({\pmb x}), f_2({\pmb x}), \cdots, f_n({\pmb x}))^{\rm T} $与带有扩张$ {\pmb r} = (r_1, r_2, \cdots, r_n) $, $ r_i > 0 $的度$ \kappa\in\bf{R} $是齐次的, 如果对于任意的$ \varepsilon > 0 $, $ {\pmb x}\in{\bf R}^n $都有
$ \begin{align*} f_i(\varepsilon^{r_1}x_1, \varepsilon^{r_2}x_2, \cdots, \varepsilon^{r_n}x_n) = \varepsilon^{\kappa+r_i}f_i({\pmb x}), \\i = 1, 2, \cdots, n \nonumber \end{align*} $
引理1[21].设系统(1)与带有扩张$(r_1, r_2, \cdots, r_n)$的度$\kappa\in\bf R$是齐次的, 函数$\pmb f({\pmb x})$是连续的, 且${\pmb x} = 0$是它的一个渐近稳定平衡点, 如果齐次度$\kappa < 0$, 则该系统就是有限时间稳定的.
引理2.任意实数$x\geq 0$和$y\geq 0$, 都有$xy\leq x^a/{a}+y^b/{b}$, 其中, $a>1$, $b>1$, 且$1/{a}+{1}/{b} = 1$.
证明.若$xy=0$, 结论显然成立.以下设$x>0$, $y>0$.构造函数$\varphi(y)=x^a/{a}+y^b/{b}-xy$, 得到$\dot{\varphi}(y)=y^{b-1}-x$, 求得唯一驻点$y_0=x^{\frac{1}{b-1}}=x^{a-1}=x^{\frac{a}{b}}$.又因为$\ddot{\varphi}(y)=(b-1)y^{b-2}>0$, 故$\varphi(y)$在$y=y_0$取极小值, 且是最小值.由于$\varphi(y_0)=x^a/{a}+y^b/{b}-x x^{a-1}=x^a-x^a=0$, 故$\varphi(y)\geq\varphi(y_0)=0$, 即$xy\leq x^a/a+y^b/{b}$.
引理3.对于$n$维向量$\pmb\alpha$和$\pmb\beta$, 正定矩阵R, 有$\pmb\alpha^{\rm T}R\pmb\beta\leq\pmb\alpha^{\rm T}R\pmb\alpha/{2}+\pmb\beta^{\rm T}R\pmb\beta/{2}$.
证明.定义$n$维实内积空间中向量内积为$(\pmb{{x}}, \pmb{{y}})=\pmb{{x}}^{\rm T}\pmb{{y}}$, 则向量内积$(\pmb{{x}}-\pmb{{y}}, \pmb{{x}}-\pmb{{y}})\geq0$, 即$(\pmb{{x}}-\pmb{{y}})^{\rm T}(\pmb{{x}}-\pmb{{y}})\geq0$.得到$\pmb{{x}}^{\rm T}\pmb{{x}}+\pmb{{y}}^{\rm T}\pmb{{y}}-2\pmb{{x}}^{\rm T}\pmb{{y}}\geq0$, 令正定矩阵$R=\pmb{{c}}^{\rm T}\pmb{{c}}$, 向量$\pmb{{x}}=\pmb{{c}}\pmb\alpha$, 向量$\pmb{{y}}=\pmb{{c}}\pmb\beta$, 故可得到$\pmb\alpha^{\rm T}R\pmb\beta\leq\pmb\alpha^{\rm T}R\pmb\alpha/{2}+\pmb\beta^{\rm T}R\pmb\beta/{2}$.
2. 具有不匹配干扰的有限时间包容控制
考虑带有不匹配干扰的$n$个跟随者和$m$个领导者的二阶多自主体系统, 假设多自主体系统的动力学方程为:
$ \begin{equation} \begin{cases} \dot{q}_i(t)=p_i(t)+d_{i1}(t)\\ \dot{p}_i(t)=u_i(t)+d_{i2}(t), ~~~~i=1, 2, \cdots, n \end{cases} \end{equation} $
(2a) $ \begin{equation} \begin{cases} \dot{q}_i(t)=p_i(t)\\ \dot{p}_i(t)=0, ~~~~i=n+1, n+2, \cdots, n+m \end{cases} \end{equation} $
(2b) 其中, $q_i(t)$为智能体$i$的位置状态, $u_i(t)$为智能体$i$的控制输入, $p_i(t)$为对应的速度状态, $d_{i1}(t)$、$d_{i2}(t)$分别为不匹配干扰和匹配干扰. $F=\{1, 2, \cdots, n\}$为$n$个跟随者智能体集合, $K=\{n+1, n+2, \cdots, n+m\}$为$m$个动态领导者集合.
假设1.在系统(2a)中, 干扰$d_{i1}(t)$二阶可微, $d_{i2}(t)$一阶可微, 且$\ddot{d}_{i1}(t)$和$\dot{d}_{i2}(t)$是Lipschitz连续的.
注1.实际工程应用中, 有很多种干扰满足假设1, 例如, 常值干扰和谐波干扰等.本文中的干扰不仅可以连续可微, 也可以分段可微.
定义3.图$G$的Laplacian矩阵为L, , 其中跟随者的Laplacian矩阵${L} _F$为$n$阶矩阵, ${L}_{Fk}$为$n\times m$阶矩阵.
令$x_i(t)=q_i(t)$, $v_i(t)=p_i(t)+d_{i1}(t)$, $d_i(t)=\dot{d}_{i1}(t)+d_{i2}(t)$, 则系统(2)可以转化为系统(3).
$ \begin{equation} \begin{cases} \dot{x}_i(t)=v_i(t)\\ \dot{v}_i(t)=u_i(t)+d_{i}(t), \quad i=1, 2, \cdots, n \end{cases} \end{equation} $
(3a) $ \begin{equation} \begin{cases} \dot{x}_i(t)=v_i(t)\\ \dot{v}_i(t)=0, \quad i=n+1, n+2, \cdots, n+m \end{cases} \end{equation} $
(3b) 可见, 系统(2)与系统(3)具有相同的动态特性.
引理4[22].如果系统(3a)中干扰$d_i(t)$是一阶可微的, 且$\dot{d}_i$(t)是Lipschitz连续的, Lipschitz常数$\beta$已知, 针对系统(3a)设计如下非线性观测器:
$ \begin{equation} \begin{cases} \dot{\widehat{x}}_i=h_0=\widehat{v}_i-\lambda_0\beta^{\frac{1}{3}}{\rm sig}^{\frac{2}{3}}(\widehat{x}_i-x_i)\\ \dot{\widehat{v}}_i=h_1=u_i+\widehat{d}_i-\lambda_1\beta^{\frac{1}{2}}{\rm sig}^{\frac{1}{2}}(\widehat{v}_i-h_0)\\ \dot{\widehat{d}}_i=-\lambda_2\beta {\rm sgn}(u_i+\widehat{d}_i-h_1) \nonumber \end{cases} \end{equation} $
其中增益$\lambda_0>0$, $\lambda_1>0$, $\lambda_2>0$, $\widehat{x}_i$, $\widehat{v}_i$, $\widehat{d}_i$分别是$x_i$, $v_i$, $d_i$的估计值, 则该观测器是有限时间收敛的.设${\rm sig}^\alpha(x)=|x|^\alpha {\rm sgn}(x)$, 其中, ${\rm sgn}(\cdot)$表示标准的符号函数, 即当$x>0$时, ${\rm sgn}(x)=1$; 当$x=0$时, ${\rm sgn}(x)=0$; 当$x < 0$时, ${\rm sgn}(x)=-1$.
设智能个体之间信息交互度量函数为:
$ \begin{equation} \ u_{i1}(t)=l_1{\rm sig}\left[\sum\limits_{j\in N_i}a_{ij}(x_j-x_i)\right]^{\alpha_1} \end{equation} $
(4) 其中, $a_{ij}$表示智能体$i$和$j$的连接权值, $0 < \alpha_1 < 1$, $l_1>0$.
引理5[23].假设具有多个领导者的二阶系统(3) $n$个跟随者的通信拓扑为无向图, 则Laplacian矩阵中的$L_F$为正定矩阵, $-L_F^{-1}L_{Fk}$为非负矩阵且每行元素和为1.
引理6.令$\pmb X _F=[x_1, x_2, \cdots, x_n]^{\rm T}$, $\pmb X_k=[x_{n+1}, \cdots, x_{n+m}]^{\rm T}$, 若有$\pmb X _F\rightarrow -L_F^{-1}L_{Fk}\pmb X_k$, 则网络化系统可以实现包容控制.
证明.由引理5可知, $-L_F^{-1}L_{Fk}$为非负矩阵且每行元素和为1, 满足定义1中的条件, 且$\pmb X_k=[x_{n+1}, \cdots, x_{n+m}]^{\rm T}$, 则$-L_F^{-1}L_{Fk}\pmb X_k$位于领导者围成的凸包内.因此, 若有$\pmb X _F\rightarrow-L_F^{-1}L_{Fk}\pmb X_k$, 那么网络化系统就可以实现包容控制.
令$\overline{{\pmb X}} _F=\pmb X _F+L_F^{-1}L_{Fk}\pmb X_k$, $\overline{{\pmb V}} _F=\pmb V _F+ L_F^{-1}L_{Fk}\pmb V_k$, $\dot{\overline{{\pmb X}}} _F=\pmb V _F$, $\pmb u_1=[u_{11}, u_{21}, \cdots, u_{n1}]^{\rm T}$, 其中, $\pmb X _F=[x_1, x_2, \cdots, x_n]^{\rm T}$, $\pmb X_k=[x_{n+1}, \cdots, x_{n+m}]^{\rm T}$, $\pmb V _F=[v_1, v_2, \cdots, v_n]^{\rm T}$, $\pmb V_k=[v_{n+1}, \cdots, v_{n+m}]^{\rm T}$, 则式(4)可以简单变化为:
$ \begin{align*} \ \pmb u_1= &l_1{\rm sig}[-(L_F \pmb X _F+L_{Fk}\pmb X_k)]^{\alpha_1}= \\ & l_1{\rm sig}[-L_F(\pmb X _F+L_F^{-1}L_{Fk}\pmb X_k)]^{\alpha_1}= \\ & l_1{\rm sig}[-(L_F \overline{{\pmb X}} _F)]^{\alpha_1} \end{align*} $
(5) 令$\pmb w=L_F\overline{{\pmb X}} _F$, 则式(5)变为
$ \begin{equation} \ \pmb u_1=-l_1{\rm sig}(\pmb w)^{\alpha_1} \end{equation} $
(6) 定理1.由$n$个跟随者和$m$个领导者构成具有不匹配干扰的二阶多自主系统(2)满足假设1, 当$n$个跟随者组成的网络拓扑图是无向连通的, 至少有一个跟随者能够感应到领导者的信息, 可以设计一个控制器, 使得二阶多自主体系统(2)在有限时间内实现包容控制.
证明.构造控制器
$ \begin{equation} \ \pmb u(t)=\pmb u_1(t)+\pmb u_2(t)-\widehat{\pmb d}(t) \end{equation} $
(7) 其中, $\pmb u_2(t)=-l_2{\rm sig}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2}$, $\cdots, \widehat{d}_n(t))^{\rm T}$, $\alpha_2={2\alpha_1}/{(1+\alpha_1)}$, $l_2>0$. ${\widehat {\mathit{\boldsymbol{\overline V}} }_F}$, $\widehat{\pmb d}$分别为$\overline{{\pmb V}} _F$, $\pmb d$的估计值.其中, $\overline{{\pmb V}} _F=[\overline{{v}}_1(t), \overline{{v}}_2(t), $ $\cdots, \overline{{v}}_n(t)]^{\rm T}$, $\pmb d(t)=[d_1(t), d_2(t), \cdots, d_n(t)]^{\rm T}$, 它们可由观测器(8)得到:
$ \begin{equation} \begin{cases} \dot{\widehat{\pmb w}}=\pmb z_0=\widehat{\overline{{\pmb V}}} _F-\lambda_0 \beta^{\frac{1}{3}}{\rm sig}^{\frac{2}{3}}(\widehat{\pmb w}-\pmb w)\\ \dot{\widehat{\overline{{\pmb V}}}} _F=\pmb z_1=\pmb u+\widehat{\pmb d}- \lambda_1\beta^{\frac{1}{2}}{\rm sig}^{\frac{1}{2}} ({\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\pmb z_0)\\ \dot{\widehat{\pmb d}}=-\lambda_2\beta {\rm sgn}(\pmb u+\widehat{\pmb d}-\pmb z_1) \end{cases} \end{equation} $
(8) 其中, $\beta$是$\dot{\pmb d}$的Lipschitz常数, $\lambda_0$, $\lambda_1$, $\lambda_2$分别是观测器的增益.所以控制器为:
$ \begin{equation} {\pmb u}=-l_1{\rm sig}(\pmb w)^{\alpha_1}-l_2{\rm sig}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2}-\widehat{\pmb d} \end{equation} $
(9) 定义观测误差$\pmb e_1=\pmb w-\widehat{\pmb w}$, ${\pmb e}_2=\overline{{\pmb V}} _F-{\widehat {\mathit{\boldsymbol{\overline V}} }_F}$, ${\pmb e}_3={\pmb d}-\widehat{\pmb d}$, 可得到观测误差系统:
$ \begin{equation} \begin{cases} \dot{\pmb e_1}=L_F\overline{{\pmb V}} _F-{\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\lambda_0\beta^{\frac{1}{3}}{\rm sig}^{\frac{2}{3}}(\pmb e_1)\\ \dot{\pmb e_2}=\pmb e_3-\lambda_1\beta^{\frac{1}{2}}{\rm sig}^{\frac{1}{2}}(L_F\overline{{\pmb V}} _F-{\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\dot{\pmb e}_1)\\ \dot{\pmb e_3}=-\lambda_2\beta {\rm sgn}(\pmb e_3-\dot{\pmb e}_2)+\dot{\pmb d} \end{cases} \end{equation} $
(10) 由引理4可知, 存在大于0的增益$\lambda_0$, $\lambda_1$, $\lambda_2$, 使得观测器误差系统(10)有限时间稳定, 即存在一个时间常数$T$, 使得$\pmb e_1(t)=\pmb e_2(t)=\pmb e_3(t)=0$, $\forall t\geq T$.
闭环系统(3), (8), (9)的有限时间稳定性分析可以分为两个部分:一方面, 存在时间$T$, 当$t\in(0, T]$时, $\overline{{\pmb X}} _F$和$\overline{{\pmb V}} _F$是否是有界的; 另一方面, $t>T$时, 闭环系统(3), (9)在有限时间内是否收敛.注意到, 当$t\in(0, T]$时, $|\overline{{\pmb V}} _F-{\widehat {\mathit{\boldsymbol{\overline V}} }_F}|$有界, 因此${\widehat {\mathit{\boldsymbol{\overline V}} }_F}$的有界性等价于$\overline{{\pmb V}} _F$的有界性.
首先证明当$t\in(0, T]$时, $\overline{{\pmb X}} _F$和$\overline{{\pmb V}} _F$的有界性.选取Lyapunov函数$Q=\frac{l_1}{1+\alpha_1}|\pmb w|^{1+\alpha_1}+\frac{1}{2}{\widehat {\mathit{\boldsymbol{\overline V}} }_F^{\rm T}}L_F{\widehat {\mathit{\boldsymbol{\overline V}} }_F}$, 对其进行求导:
$ \begin{align*} \label{abc} \dot{Q}= &l_1|\pmb w|^{\alpha_1}\cdot|\dot{\pmb w}|+ {\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F \dot{\widehat{\overline{{\pmb V}}}} _F= \\ &l_1|\pmb w|^{\alpha_1}\cdot {\rm sgn}(\pmb w)\cdot\dot{\pmb w}+\\ &{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F(-l_1{\rm sig}^{\alpha_1} (\pmb w)-l_2{\rm sig}^{\alpha_2}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})-\\ &\lambda_1\beta^\frac{1}{2}{\rm sig}^{\frac{1}{2}} ({\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\pmb z_0))= \\ &l_1{\rm sig}^{\alpha_1}(\pmb w^{\rm T})\cdot L_F(\pmb e_2+ {\widehat {\mathit{\boldsymbol{\overline V}} }_F})-\\ &l_1{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F{\rm sig}^{\alpha_1}(\pmb w)-l_2{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F{\rm sig}^{\alpha_2}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})-\\ & {\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F\lambda_1\beta^\frac{1}{2}{\rm sig}^{\frac{1}{2}} ({\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\pmb z_0)=\end{align*} $
$ \begin{align*} &l_1{\rm sig}^{\alpha_1}(\pmb w^{\rm T})\cdot L_F\pmb e_2-l_2 {\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F{\rm sig}^{\alpha_2}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})- \\ &{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F\lambda_1\beta^{\frac{1}{2}}{\rm sig}^{\frac{1}{2}} ({\widehat {\mathit{\boldsymbol{\overline V}} }_F}-\pmb z_0)\leq\\ &\frac{l_1\alpha_1}{1+\alpha_1}|\pmb w|^{1+\alpha_1}+ \frac{l_1}{1+\alpha_1}|L_F\pmb e_2|^{1+\alpha_1}-\\ &l_2|{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}|{\rm sgn}({\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T})L_F{\rm sgn}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})| {\widehat {\mathit{\boldsymbol{\overline V}} }_F}|^{\alpha_2}-\\ &{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F\lambda_1\beta^{\frac{1}{2}}{\rm sig}^{\frac{1}{2}} (\lambda_0\beta^{\frac{1}{3}}{\rm sig}^{\frac{2}{3}}(\widehat{\pmb w}-\pmb w)) \nonumber \end{align*} $
上式的最后不等式推理应用了引理2.由于
$ \begin{equation} |{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}|{\rm sgn}({\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T})L_F{\rm sgn}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})|{\widehat {\mathit{\boldsymbol{\overline V}} }_F}|^{\alpha_2}\geq\lambda_{\rm min}(L_F)|{\widehat {\mathit{\boldsymbol{\overline V}} }_F}|^{1+\alpha_2} \nonumber \end{equation} $
应用引理3可得:
$ \begin{array}{l} \dot{Q}\leq \frac{l_1\alpha_1}{1+\alpha_1}|\pmb w|^{1+\alpha_1}+ \frac{l_1}{1+\alpha_1}|L_F\pmb e_2|^{1+\alpha_1}- \\ \lambda_{\rm min}(L_F)l_2|\mathit{\boldsymbol{\overline V}} _F|^{1+\alpha_2}+\\ \mathit{\boldsymbol{\overline V}} _F^{\rm T}L_F\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}} (1+\pmb e_1))\leq \\ \frac{l_1\alpha_1}{1+\alpha_1}|\pmb w|^{1+\alpha_1}+\frac{l_1} {1+\alpha_1}|L_F\pmb e_2|^{1+\alpha_1}-\\ \lambda_{\rm min}(L_F)l_2|\mathit{\boldsymbol{\overline V}} _F|^{1+\alpha_2}+ \frac{1}{2}\mathit{\boldsymbol{\overline V}} _F^{\rm T}L_F\mathit{\boldsymbol{\overline V}} _F+\\ \frac{1}{2}[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}} (1+\pmb e_1))]^{\rm T}\times\\ L_F[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}}(1+\pmb e_1))] \leq Q+ \\ \frac{l_1}{1+\alpha_1}|L_F \pmb e_2^{\rm max}|^{1+\alpha_1}- \lambda_{\rm min}(L_F)l_2|\mathit{\boldsymbol{\overline V}} _F|^{1+\alpha_2}+ \\ \frac{1}{2}[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}} (1+\pmb e_1^{\rm max}))]^{\rm T}\times\\ L_F[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}} (1+\pmb e_1^{\rm max}))]\leq \\ Q+\frac{l_1}{1+\alpha_1}|L_F\pmb e_2^{\rm max}|^{1+\alpha_1}+ \\ \frac{1}{2}[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0 \beta^{\frac{1}{3}}(1+\pmb e_1^{\rm max}))]^{\rm T}\times\\ L_F[\lambda_1\beta^{\frac{1}{2}}(1+\lambda_0\beta^{\frac{1}{3}} (1+\pmb e_1^{\rm max}))] \end{array} $
其中, $\pmb e_1^{\rm max}$、$\pmb e_2^{\rm max}$分别是$\pmb e_1$、$\pmb e_2$的上界, 由引理4可知, 存在时间$T$, 在$t\in(0, T]$时, $\pmb e_1$、$\pmb e_2$、$\pmb e_3$是有限时间收敛的.由上式可知, $\pmb w$和${\widehat {\mathit{\boldsymbol{\overline V}} }_F}$是有界的, 即$\overline{{\pmb X}} _F$和$\overline{{\pmb V}} _F$是有界的.
再证明全局有限时间稳定, 当$t>T$时, $\pmb e_1(t)=\pmb e_2(t)=\pmb e_3(t)=0$, 则控制器(9)变为$\overline{{u}}_i(t)=l_1{\rm sig}[\sum_{j\in N_i}a_{ij}(x_j-x_i)]^{\alpha_1}-l_2{\rm sig}(\widehat{\overline{{v}}}_i)^{\alpha_2}$, 所以系统(3)变为:
$ \begin{equation} \begin{cases} \dot{x}_i(t)=v_i(t)\\ \dot{v}_i(t)=\overline{{u}}_i(t), \quad i=1, 2, \cdots, n \end{cases} \end{equation} $
(11a) $ \begin{equation} \begin{cases} \dot{x}_i(t)=v_i(t)\\ \dot{v}_i(t)=0, \quad i=n+1, n+2, \cdots, n+m \end{cases} \end{equation} $
(11b) 选取与第一步相同的Lyapunov函数$Q$, 求导后得:
$ \begin{align*} \dot{Q}= &-l_2{\widehat {\mathit{\boldsymbol{\overline V}} }_F}^{\rm T}L_F{\rm sig}^{\alpha_2}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})\leq\\ &-\lambda_{\rm min}(L_F)l_2|\widehat{\overline{{\pmb V}}} _F|^{1+\alpha_2}\leq0 \nonumber \end{align*} $
当$\dot{Q}\equiv0$时, 有${\widehat {\mathit{\boldsymbol{\overline V}} }_F}=0$, 因此$\dot{\widehat{\overline{{\pmb V}}}} _F=0$.而$\dot{\widehat{\overline{{\pmb V}}}} _F=-l_1{\rm sig}(\pmb w)^{\alpha_1}-l_2{\rm sig}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2}$, $\pmb w=L_F\overline{{\pmb X}} _F$, 当$\dot{\widehat{\overline{{\pmb V}}}} _F=0$时, 有$\pmb w=0$, 即$\overline{{\pmb X}} _F=0$.由LaSalle$'$s不变集原理可知, $\overline{{\pmb X}} _F$、$\overline{{\pmb V}} _F$全局渐近收敛到0.由$\lim_{t\rightarrow\infty}\overline{{\pmb X}} _F(t)=0$, 可以得到$\pmb X _F\rightarrow-L_F^{-1}L_{Fk}\pmb X_k$.再由$\pmb e_2=\overline{{\pmb V}} _F-{\widehat {\mathit{\boldsymbol{\overline V}} }_F}$, $\pmb e_2=0$, $\lim_{t\rightarrow\infty}{\widehat {\mathit{\boldsymbol{\overline V}} }_F}(t)=0$, 可得$\lim_{t\rightarrow\infty}\overline{{\pmb V}} _F(t)=0$, 即$\pmb V _F\rightarrow-L_F^{-1}L_{Fk}\pmb V_k$.所以由引理6可知, 系统(2)实现了包容控制.
下面分析齐次性系统的有限时间稳定, 对于系统(11), 假设
$ \begin{equation} \begin{cases} \ f_1(\overline{{\pmb X}} _F, \overline{{\pmb V}} _F)=\overline{{\pmb V}} _F\\ \ f_2(\overline{{\pmb X}} _F, \overline{{\pmb V}} _F)=l_1{\rm sig}[-(L_F \overline{{\pmb X}} _F)]^{\alpha_1}-l_2{\rm sig}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2} \nonumber \end{cases} \end{equation} $
取$r_1=2$, $r_2=1+\alpha_1$, $\kappa=\alpha_1-1$, 由定义2可得
$ \begin{equation} \ f_1(\varepsilon^{r_1}\overline{{\pmb X}} _F, \varepsilon^{r_2}\overline{{\pmb V}} _F)=\varepsilon^{r_2}\overline{{\pmb V}} _F=\varepsilon^{\kappa+r_1}f_1(\overline{{\pmb X}} _F, \overline{{\pmb V}} _F) \nonumber \end{equation} $
$ \begin{array}{l} f_2(\varepsilon^{r_1}\mathit{\boldsymbol{\overline X}} _F, \varepsilon^{r_2} \overline{{\pmb V}} _F)=l_1{\rm sig}[-(L_F\varepsilon^{r_1} \mathit{\boldsymbol{\overline X}} _F)]^{\alpha_1}-\\ \qquad l_2{\rm sig} (\varepsilon^{r_2}{\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2}=\\ \qquad\varepsilon^{r_1\alpha_1}[l_1{\rm sig}(-(L_F \mathit{\boldsymbol{\overline X}} _F))^{\alpha_1}]-\\ \qquad \varepsilon^{r_2\alpha_2}l_2{\rm sig}({\widehat {\mathit{\boldsymbol{\overline V}} }_F})^{\alpha_2} \end{array} $
而$\varepsilon^{r_1\alpha_1}=\varepsilon^{r_2\alpha_2}=\varepsilon^{2\alpha_1}$, 所以
$ \begin{align*} & f_2(\varepsilon^{r_1}\overline{{\pmb X}} _F, \varepsilon^{r_2}\overline{{\pmb V}} _F)=\varepsilon^{2\alpha_1}[l_1{\rm sig}(-(L_F \overline{{\pmb X}} _F))^{\alpha_1}-\\ &\qquad l_2{\rm sig} (\widehat{\overline{{\pmb V}}} _F)^{\alpha_2}]=\varepsilon^{\kappa+r_2}f_2(\overline{{\pmb X}} _F, \overline{{\pmb V}} _F) \nonumber \end{align*} $
此多智能体系统与带有扩张$(\underbrace{2, 2, \cdots, 2}_{{n}}, $ $\underbrace{\alpha_1+1, \alpha_1+1, \cdots, \alpha_1+1}_{{n}})$的度$\kappa=\alpha_1-1$是同次的.由引理1可知, 系统(11)是全局有限时间稳定的.因此, 多智能体系统(3)应用控制协议(9)可以实现全局有限时间包容控制, 也就是应用基于观测器的协同控制协议(9), 使二阶多智能体系统(2)在有限时间内实现包容控制.
注2.文献[24]研究了二阶系统的球面编队追踪控制的几何级数增长设计, 将自适应Backstepping技术、几何级数增长和一致性算法结合设计新的观测器, 对自主体在法线方向上的速度, 球面经线方向上的速度和球面纬线方向上的速度进行估计.文献[25]研究了在未知的欧拉规范流场中对编队追踪运动的自适应Backstepping设计, 将自适应Backstepping技术和一致性算法结合提出了一种新的观测器, 可以对未知的流速向量进行估计.以上两种观测器适用于流场中的编队追踪控制, 而本文所使用的观测器针对的是可以在有限时间情况下对带有不匹配干扰的系统的未知状态和干扰进行估计.不同的观测器针对的系统不同, 各有各的优势.
3. 仿真验证
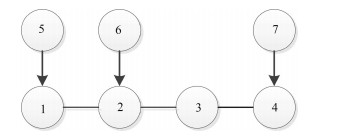
为了验证控制器(9)的控制效果, 本文考虑4个受扰跟随者和3个领导者, 跟随者集合和领导者集合分别为$F=\{1, 2, 3, 4\}$和$K=\{5, 6, 7\}$, 假设多智能体系统的通信拓扑图如图 1所示.
假设拓扑图所有边的权重为1, 图的邻接矩阵为$A=\left[ {{array}{*{20}{c}} 0 & 1 & 0 & 0 & 1 & 0 & 0\\ 1 & 0 & 1 & 0 & 0 & 1 & 0\\ 0 & 1 & 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 {array}} \right]$, 则系统的Laplacian矩阵为.
控制器(9)的参数选取为$l_1=20$, $l_2=20$, $\alpha_1=\frac{1}{2}$, $\alpha_2=\frac{2}{3}$, 观测器(8)的参数选取为$\lambda_0=10$, $\lambda_1=5$, $\lambda_2=5$, $\beta=20$.四个跟随者所受的不匹配干扰和匹配干扰分别选取为:跟随者1的干扰$d_{11}=1$, $d_{12}=2$; 跟随者2的干扰$d_{21}=0.5$, $d_{22}=1$; 跟随者3的干扰$d_{31}=0.5\sin2t$, $d_{32}=2\cos2t$; 跟随者4的干扰$d_{41}=0.5\cos2t$, $d_{42}=2\sin2t$.又因为$d_i=\dot{d}_{i1}+d_{i2}$, 所以四个跟随者最终所受的干扰为:~$d_{1}=2$, $d_{2}=1$, $d_{3}=3\cos2t$, $d_{4}=\sin2t$.假设四个跟随者的初始位置为: $q_1(0)=[2~~0]^{\rm T}$, $q_2(0)=[4~~0]^{\rm T}$, $q_3(0)=[0~~2]^{\rm T}$, $q_4(0)=[0~~4]^{\rm T}$, 初速度为:~$v_1(0)=[2~~6]^{\rm T}$, $v_2(0)=[3~~8]^{\rm T}$, $v_3(0)=[4~~6]^{\rm T}$, $v_4(0)=[5~~5]^{\rm T}$.三个动态领导者的初始位置为:~$q_5(0)=[6~~8]^{\rm T}$, $q_6(0)=[8~~8]^{\rm T}$, $q_7(0)=[8~~6]^{\rm T}$, 初速度为$v_5(0)=[1~~1]^{\rm T}$, $v_6(0)=[1~~1]^{\rm T}$, $v_7(0)=[1~~1]^{\rm T}$.
系统仿真图 2表示二阶多自主体系统跟随者的运动轨迹, 选取了$t=0 \rm s$, $t=5 \rm s$和$t=10 \rm s$三个时间点的三个动态领导者的位置状态, 由图 2可以看出, 四个跟随者的位置在$t=5 \rm s$时已收敛到由三个领导者围成的三角形平面当中, 二阶多自主体系统在基于控制器(9)作用下实现了包容控制.
 图 2 二阶多自主体系统跟随者的运动轨迹Fig. 2 The motion track of followers in the second-order multi-agent systems
图 2 二阶多自主体系统跟随者的运动轨迹Fig. 2 The motion track of followers in the second-order multi-agent systems系统仿真图 3表示观测器(8)对$\pmb w$的估计值, , 由图 3可以看出, $\pmb w$的值在$4 \rm s$左右收敛到零, 即$\overline{{\pmb X}} _F\rightarrow0$.系统仿真图 4表示观测器(8)对$\overline{{\pmb V}} _F$的估计值, 由图 4可以看出, $\overline{{\pmb V}} _F$的值在$4 \rm s$左右收敛到零, 即$\overline{{\pmb V}} _F\rightarrow0$.由以上两个图可以得到系统在有限时间内实现了包容控制.
 图 4 速度$\overline{{V}} _F$的估计值Fig. 4 The estimated value of velocity $\overline{{V}} _F$
图 4 速度$\overline{{V}} _F$的估计值Fig. 4 The estimated value of velocity $\overline{{V}} _F$系统仿真图 5表示观测器(8)对四个跟随者所受干扰的估计值, 由图 5可以看出, 干扰观测器的估计值在有限时间$1 \rm s$左右都渐渐趋近于实际值, 跟随者1的干扰$d_{1}=2$, 跟随者2的干扰$d_{2}=1$, 跟随者3的干扰$d_{3}=3\cos2t$, 跟随者4的干扰$d_{4}=\sin2t$.
系统仿真图 6表示观测器对干扰的观测误差, 由图 6可以看出, 观测器(8)在有限时间内实现对系统所受干扰$\pmb d$的精确估计, 在有限时间$1.2 \rm s$左右趋近于0, 达到了很好的观测效果.
4. 结论
1) 本文研究了带有不匹配干扰的具有多个动态领导者的多自主体系统的有限时间包容控制问题.为了观测不可测的系统状态, 设计了非线性观测器来估计系统不可测状态和干扰.通过使用Lyapunov稳定性理论、代数图论、齐次性理论等方法, 研究了多自主体系统的有限时间包容控制问题, 仿真结果验证了本文所设计的包容控制算法可以使多自主体系统在有限时间内快速收敛.
2) 下一步工作将对具有多源干扰(含不匹配干扰)的多自主体系统进行研究, 对系统中的不匹配干扰放宽要求, 分析高阶多自主体系统的有限时间包容控制问题.
-
图 2 二阶多自主体系统跟随者的运动轨迹
Fig. 2 The motion track of followers in the second-order multi-agent systems
图 4 速度$\overline{{V}} _F$的估计值
Fig. 4 The estimated value of velocity $\overline{{V}} _F$
-
[1] Yoon M G. Consensus of adaptive multi-agent systems. Systems & Control Letters, 2017, 102:9-44 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1109.3838 [2] Yang H Y, Zhu X L, Zhang S Y. Consensus of second-order delayed multi-agent systems with leader-following. European Journal of Control, 2010, 16(2):188-199 doi: 10.3166/ejc.16.188-199 [3] Han F J, Gao L, Yang H Y. Sampling control on collaborative flocking motion of discrete-time system with time-delays. Neurocomputing, 2016, 216:242-249 doi: 10.1016/j.neucom.2016.07.041 [4] Mu X W, Yang Z. Containment control of discrete-time general linear multi-agent systems under dynamic digraph based on trajectory analysis. Neurocomputing, 2016, 171:1655-1660 doi: 10.1016/j.neucom.2015.07.079 [5] Miao G Y, Cao J D, Alsaedi A, Alsaedi F E. Event-triggered containment control for multi-agent systems with constant time delays. Journal of the Franklin Institute, 2017, 354(15):6956-6977 doi: 10.1016/j.jfranklin.2017.08.010 [6] Wang Q, Fu J J, Wang J Z. Fully distributed containment control of high-order multi-agent systems with nonlinear dynamics. Systems & Control Letters, 2017, 99:33-39 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=06e1a4fe9dd39883d60548a372d6df36 [7] 刘帅, 谢立华, 张焕水.带噪声多自主体的均方包容控制.自动化学报, 2013, 39(11):1787-1795 http://www.aas.net.cn/CN/abstract/abstract18218.shtmlLiu Shuai, Xie Li-Hua, Zhang Huan-Shui. Mean square containment control of multi-agent systems with transmission noises. Acta Automatica Sinica, 2013, 39(11):1787-1795 http://www.aas.net.cn/CN/abstract/abstract18218.shtml [8] Li B, Chen Z Q, Liu Z X, Zhang C Y, Zhang Q. Containment control of multi-agent systems with fixed time-delays in fixed directed networks. Neurocomputing, 2016, 173:2069-2075 doi: 10.1016/j.neucom.2015.09.056 [9] 杨洪勇, 郭雷, 张玉玲, 姚秀明.复杂分数阶多自主体系统的运动一致性.自动化学报, 2014, 40(3):489-496 http://www.aas.net.cn/CN/abstract/abstract18314.shtmlYang Hong-Yong, Guo Lei, Zhang Yu-Ling, Yao Xiu-Ming. Movement consensus of complex fractional-order multi-agent systems. Acta Automatica Sinica, 2014, 40(3):489-496 http://www.aas.net.cn/CN/abstract/abstract18314.shtml [10] Zhao L, Jia Y M. Finite-time consensus for second-order stochastic multi-agent systems with nonlinear dynamics. Applied Mathematics & Computation, 2015, 270:278-290 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=cefa2995a45a4a4093c3ccbf7ea28728 [11] Fu J J, Wang J Z. Robust finite-time containment control of general linear multi-agent systems under directed communication graphs. Journal of the Franklin Institute, 2016, 353(12):2670-2689 doi: 10.1016/j.jfranklin.2016.05.015 [12] 朱亚锟, 关新平, 罗小元.线性和非线性动态异构多自主体系统的有限时间一致性.自动化学报, 2014, 40(11):2618-2624 http://www.aas.net.cn/CN/abstract/abstract18539.shtmlZhu Ya-Kun, Guan Xin-Ping, Luo Xiao-Yuan. Finite-time consensus of heterogeneous multi-agent systems with linear and nonlinear dynamics. Acta Automatica Sinica, 2014, 40(11):2618-2624 http://www.aas.net.cn/CN/abstract/abstract18539.shtml [13] Xu C J, Zheng Y, Su H S, Zeng H B. Containment for linear multi-agent systems with exogenous disturbances. Neurocomputing, 2015, 160:206-212 doi: 10.1016/j.neucom.2015.02.008 [14] Yang H Y, Zhang Z X, Zhang S Y. Consensus of second-order multi-agent systems with exogenous disturbances. International Journal of Robust & Nonlinear Control, 2011, 21(9):945-956 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201701011 [15] Cao W J, Zhang J H, Ren W. Leader-follower consensus of linear multi-agent systems with unknown external disturbances. Systems & Control Letters, 2015, 82:64-70 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=b8c72268432876460cf59b5011bcd99d [16] Yang H Y, Han F J, Zhao M, Zhang S N, Yue J. Distributed containment control of heterogeneous fractional-order multi-agent systems with communication delays. Open Physics, 2017, 15(1):509-516 doi: 10.1515/phys-2017-0058 [17] Sun F L, Zhu W, Li Y F, Liu F. Finite-time consensus problem of multi-agent systems with disturbance. Journal of the Franklin Institute, 2016, 353(12):2576-2587 doi: 10.1016/j.jfranklin.2016.04.016 [18] Li S H, Du H B, Lin X Z. Finite-time consensus algorithm for multi-agent systems with double-integrator dynamics. Automatica, 2011, 47(8):1706-1712 doi: 10.1016/j.automatica.2011.02.045 [19] Cheng Y Y, Du H B, He Y G, Jia R T. Robust finite-time synchronization of coupled harmonic oscillations with external disturbance. Journal of the Franklin Institute, 2015, 352(10):4366-4381 doi: 10.1016/j.jfranklin.2015.06.006 [20] Cao Y C, Ren W. Containment control with multiple stationary or dynamic leaders under a directed interaction graph. In: Proceedings of the 48th IEEE Conference on Decision and Control and 28th Chinese Control Conference. Shanghai, China: IEEE, 2009. 3014-3019 [21] Rosier L. Homogeneous Lyapunov function for homogeneous continuous vector field. Systems and Control Letters, 1992, 19(4):467-473 doi: 10.1016-0167-6911(92)90078-7/ [22] Bhat S P, Bernstein D S. Finite-time stability of homogeneous systems. In: Proceedings of the 1997 American Control Conference. Albuquerque, NM: IEEE, 1997. 2513-2514 [23] Meng Z Y, Ren W, You Z. Distributed finite-time attitude containment control for multiple rigid bodies. Automatica, 2010, 46(12):2092-2099 doi: 10.1016/j.automatica.2010.09.005 [24] Chen Y Y, Wang Z Z, Zhang Y, Liu C L, Wang Q. A geometric extension design for spherical formation tracking control of second-order agents in unknown spatiotemporal flowfields. Nonlinear Dynamics, 2017, 88(2):1173-1186 doi: 10.1007/s11071-016-3303-2 [25] Chen Y Y, Zhang Y, Wang Z Z. An adaptive backstepping design for formation tracking motion in an unknown Eulerian specification flowfield. Journal of the Franklin Institute, 2017, 354(14):6217-6233 doi: 10.1016/j.jfranklin.2017.07.020 期刊类型引用(6)
1. 薛奇,白宇鑫,侯瑞欣. 带有领导者的多智能体有限时间编队控制. 山西师范大学学报(自然科学版). 2024(03): 39-45 .  百度学术
百度学术2. 马俊达,谭冲,范佳佳. 基于齐次系统理论的多船有限时间饱和包容控制. 哈尔滨工程大学学报. 2023(10): 1779-1787 . 百度学术3. 寇立伟,项基. 基于输出反馈线性化的多移动机器人目标包围控制. 自动化学报. 2022(05): 1285-1291 . 本站查看4. 孙玉娇,杨洪勇,于美妍. 基于领航者的多机器人系统编队控制研究. 鲁东大学学报(自然科学版). 2020(01): 35-39+97 . 百度学术5. 杨怡泽,杨洪勇,刘凡,李玉玲,刘远山. 具有干扰的多领航者系统群集运动的快速收敛. 计算机应用研究. 2020(04): 1030-1033+1042 . 百度学术6. 崔艳,薛奇. 二阶多智能体系统的有限时间包容一致性控制. 电光与控制. 2020(12): 26-31+73 . 百度学术其他类型引用(9)
-

 下载:
下载:



 下载:
下载:
计量
- 文章访问数: 1337
- HTML全文浏览量: 327
- PDF下载量: 155
- 被引次数: 15
