

-
摘要: 背景消减是计算机视觉和模式识别的关键技术之一.本文提出一种新的背景消减算法,该算法首先利用中值滤波算法进行背景数据的获取,然后基于贝叶斯生成对抗网络进行训练,利用生成对抗网络的特性,有效地对每个像素进行分类,解决了光照渐变和突变、非静止背景以及鬼影的问题.本文采用深度卷积神经网络,来构建贝叶斯生成对抗网络的生成器和判别器.实验结果表明,本文提出的算法性能在绝大多数情况下优于现有其他算法.本文的贡献在于首次将贝叶斯生成对抗网络应用于背景消减,并且取得了良好的实验效果.Abstract: Background subtraction is one of the key techniques in computer vision and pattern recognition. A new background subtraction algorithm is proposed, which firstly uses the median filtering algorithm for extracting background and then trains the network based on Bayesian generative adversarial network. The work uses Bayesian generative adversarial network to classify each pixel effectively, thereby addressing the issues of sudden and slow illumination changes, non-stationary background, and ghost. Deep convolutional neural networks are adopted to construct the generator and the discriminator of Bayesian generative adversarial network. Experiments show that the proposed algorithm results in better performance than others in most cases. The contribution of the work is to apply Bayesian generative adversarial network to background subtraction for the first time and achieve good experimental results.1) 本文责任编委 李力
-
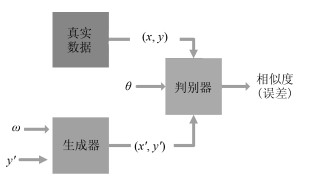
图 2 基于DCGAN的贝叶斯生成对抗网络
Fig. 2 Bayesian generative adversarial networks based on the DCGAN
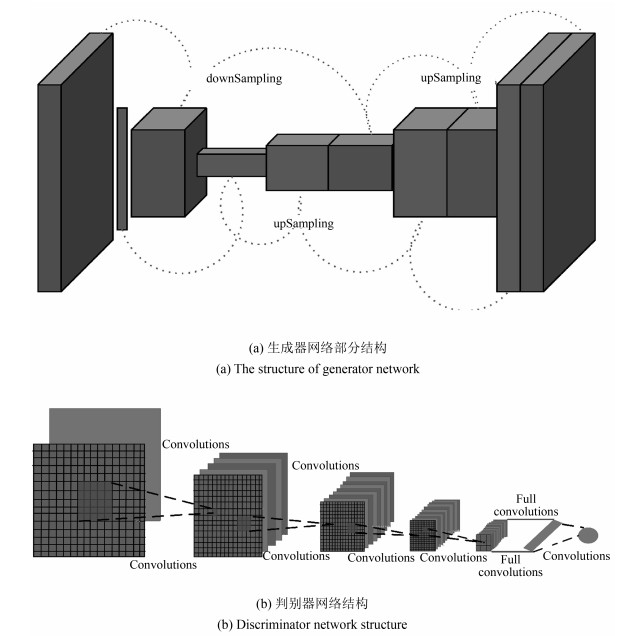
图 4 贝叶斯卷积生成对抗网络结构
Fig. 4 The structure of Bayesian convolutional generative adversarial network
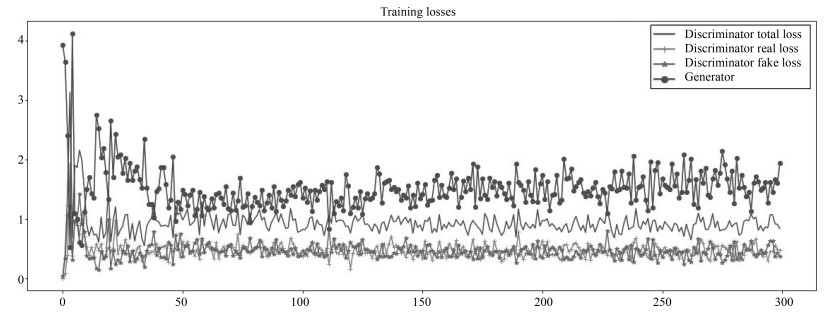
图 5 以office训练时的贝叶斯生成对抗网络损失函数图
Fig. 5 The loss function of the Bayesian generative adversarial networks trained base on the office datasets

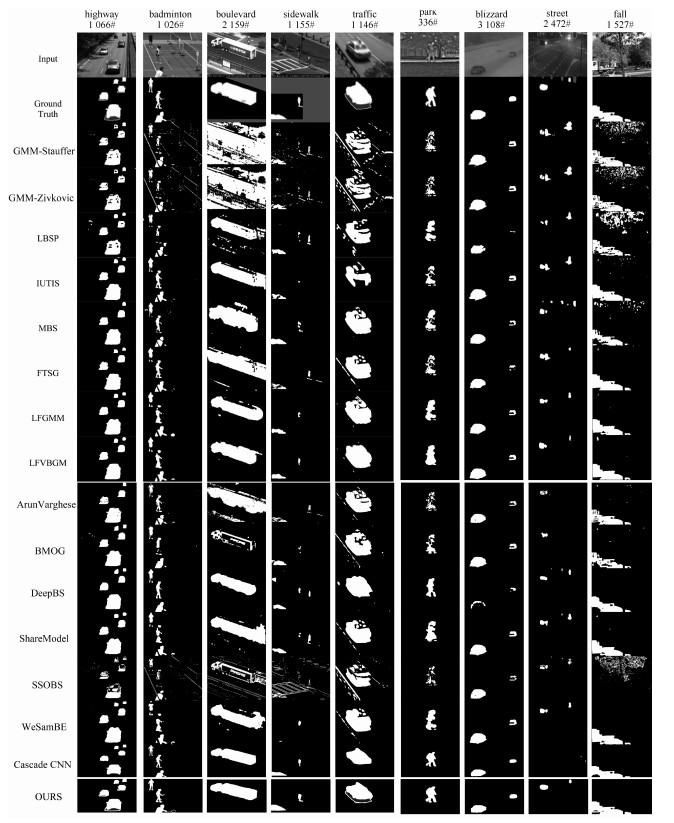
图 6 背景重建与背景减除结果图
Fig. 6 The results of the background reconstruction and background subtraction
表 1 不同检测算法的召回率对比
Table 1 The recall rate of different detection algorithms are compared
Method GMM-Stauffer GMM-Zivkovic LBSP IUTIS MBS FTSG LFGMM LFVBGM Arun Varghese BMOG DeepBS Share Model SSOBS WeSamBE Cascade CNN BSGAN database Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Baseline 81.8 80.9 89.6 97.1 91.6 95.1 94.1 95.2 94.1 85.5 94.2 95.4 49.1 94.5 99.9 99.1 Dynamic background 83.8 80.2 76.7 87.8 76.4 86.9 77.7 88.7 88.7 90.1 85.4 75.9 52.3 67.9 84.8 98.8 Camera jitter 73.3 69.0 67.4 79.2 83.2 77.2 82.4 80.4 78.4 83.6 87.9 79.6 58.1 77.8 91.4 99.1 Shadow 79.6 77.7 87.8 94.8 79.2 92.1 94.2 92.7 74.8 50.9 57.4 71.8 21.6 74.7 96.6 91.4 Inter.ob.motion 51.4 54.7 55.9 69.9 75.3 76.2 81.4 72.0 91.7 85.9 95.8 94.5 50.2 94.0 93.0 98.1 Thermal 56.9 55.4 81.4 78.3 81.6 73.6 81.6 85.0 85.1 52.4 66.3 86.2 30.1 77.2 98.9 95.3 Bad weather 71.8 68.6 70.4 74.8 83.4 74.6 82.1 78.8 71.8 76.4 75.2 84.3 58.2 81.7 97.9 93.4 Low frame-rate 58.2 53.0 59.7 82.1 67.7 75.2 85.4 81.4 77.3 63.8 59.2 84.3 53.1 88.4 96.4 86.1 Night videos 52.6 48.0 51.0 56.6 55.4 61.1 65.7 66.1 36.1 64.9 53.2 59.9 44.7 63.7 94.2 91.4 PTZ 64.8 61.1 54.8 66.4 59.7 67.3 83.1 87.8 69.8 76.7 74.6 79.7 68.8 81.5 96.2 96.8 Air turbulence 79.1 77.9 76.1 68.6 60.4 61.1 80.5 81.2 81.2 68.7 79.8 79.1 74.4 71.8 96.1 93.1 Average 68.5 66.0 70.1 77.8 74.0 76.4 82.6 82.7 77.2 72.6 75.4 81.0 51.0 79.4 95.0 94.8  下载: 导出CSV
下载: 导出CSV
表 2 不同检测算法的精确率对比
Table 2 The precision rate of different detection algorithms are compared
Method GMM-Stauffer GMM-Zivkovic LBSP IUTIS MBS FTSG LFGMM LFVBGM Arun Varghese BMOG DeepBS Share Model SSOBS WeSamBE Cascade CNN BSGAN database Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Baseline 84.6 89.9 95.6 93.9 94.3 91.7 93.3 95.0 93.9 81.9 96.6 95.0 94.2 91.7 97.8 98.8 Dynamic background 59.9 62.1 59.2 92.8 86.5 91.3 89.2 90.4 90.4 75.8 90.8 91.9 10.1 89.3 96.7 96.8 Camera jitter 51.3 48.7 83.7 85.2 84.4 76.5 81.2 86.6 86.6 72.9 93.1 83.8 34.1 83.9 96.3 97.5 Shadow 71.6 72.3 87.7 85.8 82.6 85.3 86.5 87.1 83.9 68.2 82.5 75.8 65.3 78.8 78.2 98.8 Inter.ob.motion 66.9 64.4 71.0 81.5 74.2 78.1 65.8 74.9 48.2 53.7 47.4 59.3 36.9 55.3 94.4 90.4 Thermal 86.5 87.1 75.8 89.2 82.7 90.9 83.3 82.8 82.8 90.1 92.6 80.7 72.8 85.6 85.7 87.2 Bad weather 77.0 81.4 86.6 89.6 78.3 92.3 90.9 94.7 94.8 81.5 96.8 85.7 85.1 91.3 95.5 95.9 Low frame-rate 68.9 66.9 65.8 70.0 60.0 65.5 67.4 69.7 64.1 69.5 70.1 68.4 64.4 91.3 82.8 83.8 Night videos 41.3 42.3 44.9 51.3 49.0 49.0 53.4 55.4 65.4 46.1 83.7 58.5 51.5 58.3 88.1 88.0 PTZ 11.9 68.3 20.4 34.7 54.0 28.6 28.4 30.3 47.2 20.9 28.5 31.2 10.2 31.2 87.3 88.6 Air turbulence 42.9 34.9 59.7 92.6 62.0 90.4 78.1 78.4 68.1 76.8 90.8 75.6 9.8 83.7 89.3 89.5 Average 60.3 65.3 68.2 78.8 73.5 76.3 74.3 76.8 75.0 67.0 79.4 73.3 48.6 76.4 90.2 92.3
下载: 导出CSV
表 3 不同检测算法的F-measure
Table 3 F-measure of different detection algorithms
Method GMM-1 GMM-2 LBSP IUTIS MBS FTSG LFGMM LFVBGM Arun Varghese BMOG DeepBS Share Model SSOBS WeSamBE Cascade CNN BSGAN database Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Re (%) Baseline 83.2 85.2 92.5 95.5 92.9 93.4 93.7 95.1 93.9 83.0 95.1 95.2 60.8 93.1 97.8 98.1 Dynamic background 69.9 70.0 66.8 90.2 81.1 89.0 83.1 89.5 89.4 79.3 87.6 82.2 16.1 74.4 96.5 97.6 Camera jitter 60.4 57.1 74.7 82.1 83.8 76.8 81.8 83.4 91.3 74.9 89.9 81.4 41.5 79.7 97.6 98.8 Shadow 75.4 74.9 87.7 90.1 80.9 88.6 90.2 89.8 77.6 52.9 60.9 67.3 30.2 73.9 85.1 97.6 Inter.ob.motion 58.1 59.2 62.6 75.3 74.7 77.1 72.8 73.4 87.1 83.9 89.9 84.6 75.2 86.9 94.1 95.6 Thermal 68.6 67.7 78.5 83.4 82.1 81.3 82.4 83.9 83.3 63.4 75.8 83.1 40.9 79.6 90.7 90.6 Bad weather 74.3 74.5 77.7 81.5 80.8 82.5 86.3 86.0 81.5 78.4 83.0 84.8 68.5 86.1 94.3 95.6 Low frame-rate 63.1 59.1 62.6 75.6 63.6 70.0 75.3 75.1 65.8 61.0 60.1 72.9 46.4 66.0 83.7 85.7 Night videos 46.3 45.0 47.8 53.8 52.0 54.4 58.9 60.3 41.5 49.8 58.4 54.2 44.6 59.3 89.6 90.6 PTZ 20.1 64.5 29.7 45.6 56.7 40.1 42.3 45.1 46.1 23.5 31.3 38.6 13.8 38.4 91.6 93.6 Air turbulence 55.6 48.2 66.9 78.8 61.2 72.9 79.3 79.8 64.5 69.3 84.6 73.4 15.2 75.4 91.8 91.7 Average 61.4 64.1 68.0 77.4 73.6 75.1 76.9 78.3 74.7 65.4 74.2 74.3 41.2 73.9 92.1 93.4
下载: 导出CSV
-
[1] Wang K F, Liu Y Q, Gou C, Wang F Y. A multi-view learning approach to foreground detection for traffic surveillance applications. IEEE Transactions on Vehicular Technology, 2016, 65(6):4144-4158 doi: 10.1109/TVT.2015.2509465 [2] Liu Y Q, Wang K F, Shen D Y. Visual tracking based on dynamic coupled conditional random field model. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(3):822-833 doi: 10.1109/TITS.2015.2488287 [3] 张慧, 王坤峰, 王飞跃.深度学习在目标视觉检测中的应用进展与展望.自动化学报, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtmlZhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtml [4] Stauffer C, Grimson W E L. Adaptive background mixture models for real-time tracking. In: Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Fort Collins, CO, USA: IEEE, 1999. 252 [5] Zivkovic Z. Improved adaptive Gaussian mixture model for background subtraction. In: Proceedings of the 17th International Conference on Pattern Recognition (ICPR). Cambridge, UK: IEEE, 2004. 28-31 [6] St-Charles P L, Bilodeau G A. Improving background subtraction using local binary similarity patterns. In: Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision (WACV). Steamboat Springs, CO, USA: IEEE, 2014. 509-515 [7] Fan J J, Xin Y Z, Dai F L, Hu B, Zhang J Q, Lu Q Y, et al. Distributed multi-camera object tracking with Bayesian Inference. In: Proceedings of the 2011 IEEE International Symposium on Circuits and Systems (ISCAS). Rio de Janeiro, Brazil: IEEE, 2011. 357-360 [8] Yan J H, Wang S F, Xie T X, Yang Y, Wang J Y. Variational Bayesian learning for background subtraction based on local fusion feature. IET Computer Vision, 2016, 10(8):884-893 doi: 10.1049/iet-cvi.2016.0075 [9] Wang Y, Jodoin P M, Porikli F, Konrad J, Benezeth Y, Ishwar P. CDnet 2014: an expanded change detection benchmark dataset. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Columbus, OH, USA: IEEE, 2014. 393-400 [10] Martins I, Carvalho P, Corte-Real L, Alba-Castro J L. BMOG: boosted Gaussian mixture model with controlled complexity. In: Pattern Recognition and Image Analysis. Faro, Portugal: Springer, 2017. 50-57 [11] Sehairi K, Chouireb F, Meunier J. Comparative study of motion detection methods for video surveillance systems. Journal of Electronic Imaging, 2017, 26(2):023025 doi: 10.1117/1.JEI.26.2.023025 [12] Chen Y Y, Wang J Q, Lu H Q. Learning sharable models for robust background subtraction. In: Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME). Turin, Italy: IEEE, 2015. 1-6 [13] Jiang S Q, Lu X B. WeSamBE: a weight-sample-based method for background subtraction. IEEE Transactions on Circuits and Systems for Video Technology, https://ieeexplore.ieee.org/document/7938679/ [14] Babaee M, Dinh D T, Rigoll G. A deep convolutional neural network for video sequence background subtraction. Pattern Recognition, 2018, 76:635-649 doi: 10.1016/j.patcog.2017.09.040 [15] Saatchi Y, Wilson A G. Bayesian GAN. arXiv: 1705.09558, 2017 [16] 李力, 林懿伦, 曹东璞, 郑南宁, 王飞跃.平行学习——机器学习的一个新型理论框架.自动化学报, 2017, 43(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtmlLi Li, Lin Yi-Lun, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel learning——a new framework for machine learning. Acta Automatica Sinica, 2017, 43(1):1-8 http://www.aas.net.cn/CN/abstract/abstract18984.shtml [17] Wang F Y, Wang X, Li L X, Li L. Steps toward parallel intelligence. IEEE/CAA Journal of Automatica Sinica, 2016, 3(4):345-348 doi: 10.1109/JAS.2016.7510067 [18] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [19] Wang K F, Gou C, Duan Y J, Lin Y L, Zheng X H, Wang F Y. Generative adversarial networks:introduction and outlook. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4):588-598 doi: 10.1109/JAS.2017.7510583 [20] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial networks. arXiv:1406.2661, 2014 [21] 王坤峰, 鲁越, 王雨桐, 熊子威, 王飞跃.平行图像:图像生成的一个新型理论框架.模式识别与人工智能, 2017, 30(7):577-587 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=mssb201707001&dbname=CJFD&dbcode=CJFQWang Kun-Feng, Lu Yue, Wang Yu-Tong, Xiong Zi-Wei, Wang Fei-Yue. Parallel imaging:a new theoretical framework for image generation. Pattern Recognition and Artificial Intelligence, 2017, 30(7):577-587 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=mssb201707001&dbname=CJFD&dbcode=CJFQ [22] 王坤峰, 苟超, 王飞跃.平行视觉:基于ACP的智能视觉计算方法.自动化学报, 2016, 42(10):1490-1500 http://www.aas.net.cn/CN/abstract/abstract18936.shtmlWang Kun-Feng, Gou Chao, Wang Fei-Yue. Parallel vision:an ACP-based approach to intelligent vision computing. Acta Automatica Sinica, 2016, 42(10):1490-1500 http://www.aas.net.cn/CN/abstract/abstract18936.shtml [23] Wang K F, Gou C, Zheng N N, Rehg J M, Wang F Y. Parallel vision for perception and understanding of complex scenes:methods, framework, and perspectives. Artificial Intelligence Review, 2017, 48(3):299-329 doi: 10.1007/s10462-017-9569-z [24] Laugraud B, Piérard S, Braham M, Van Droogenbroeck M. Simple median-based method for stationary background generation using background subtraction algorithms. In: New Trends in Image Analysis and Processing. Italy: Springer, 2015. 477-484 [25] Braham M, van Droogenbroeck M. Deep background subtraction with scene-specific convolutional neural networks. In: Proceedings of the 2016 International Conference on Systems, Signals and Image Processing. Bratislava, Slovakia: IEEE, 2016. 1-4 [26] Zhao J, Meng D Y. FastMMD:ensemble of circular discrepancy for efficient two-sample test. Neural Computation, 2015, 27(6):1345-1372 doi: 10.1162/NECO_a_00732 [27] Gangeh M J, Sadeghi-Naini A, Diu M, Tadayyon H, Kamel M S, Czarnota G J. Categorizing extent of tumor cell death response to cancer therapy using quantitative ultrasound spectroscopy and maximum mean discrepancy. IEEE Transactions on Medical Imaging, 2014, 33(6):1390-1400 doi: 10.1109/TMI.2014.2312254 [28] He K M, Sun J. Convolutional neural networks at constrained time cost. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 5353-5360 [29] Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X. Improved techniques for training GANs. arXiv: 1606.03498, 2016 [30] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A. Improved training of Wasserstein GANs. arXiv: 1704.00028, 2017 [31] Varghese A, Sreelekha G. Sample-based integrated background subtraction and shadow detection. IPSJ Transactions on Computer Vision and Applications, 2017, 9:25 doi: 10.1186/s41074-017-0036-1 [32] Wang Y, Luo Z M, Jodoin P M. Interactive deep learning method for segmenting moving objects. Pattern Recognition Letters, 2017, 96:66-75 doi: 10.1016/j.patrec.2016.09.014 [33] 白天翔, 王帅, 沈震, 曹东璞, 郑南宁, 王飞跃.平行机器人与平行无人系统:框架、结构、过程、平台及其应用.自动化学报, 2017, 43(2):161-175 http://www.aas.net.cn/CN/abstract/abstract18998.shtmlBai Tian-Xiang, Wang Shuai, Shen Zhen, Cao Dong-Pu, Zheng Nan-Ning, Wang Fei-Yue. Parallel robotics and parallel unmanned systems:framework, structure, process, platform and applications. Acta Automatica Sinica, 2017, 43(2):161-175 http://www.aas.net.cn/CN/abstract/abstract18998.shtml -

 下载:
下载:



计量
- 文章访问数: 3636
- HTML全文浏览量: 754
- PDF下载量: 1699
- 被引次数: 0
