

-
摘要: 步态识别作为生物特征识别中的一种,具有远距离、非接触和难以模仿等优点.其中视角或行走方向的变化使提取的人体轮廓产生巨大差异,是影响步态识别系统性能的最主要因素之一.本文首先介绍了现有的多角度步态数据库,然后根据特征提取方式的不同,将当前已提出的方法分为三维模型法、视角不变性特征法、映射投影法和深度神经网络法四类,并详细阐述了每一类的原理、特点以及优缺点.最后,结合实际应用指出当前研究的局限性与发展趋势.Abstract: As one of biometric identification methods, gait recognition has many advantages. It is suitable for human identification at a long distance, requiring no contact and hard to imitate. One of the most important factors that affect the performance of gait recognition is that the change of view or the direction of the walk, which makes the human silhouette have a large variation. We first introduce the existing multi-view gait database. Then according to the characteristics of different extraction methods, the current approaches are divided into four kinds:three-dimensional model, view-invariant features, subspace projection as well as deep neural network, and analyses are conducted on their principle, advantages and disadvantages. Finally the limitations of current research and development trend are pointed out.
-
Key words:
- Gait recognition /
- multi-view /
- behavioral characteristics recognition /
- biometrics
-
脊柱类疾病是比较常见的一种疾病, 手术是治疗脊柱类疾病的常见方式.图像引导的脊柱手术能够大大提高手术的成功率, 尤其是3D的图像能够给医生提供包括病人脊椎姿态的丰富信息.然而在术中获取病人的3D影像是十分困难的, 而获得2D的X-ray图像比较容易, 为了在术中给医生呈现病人的3D脊椎信息, 一个可行的方法便是对术前3D图像中的脊椎和术中2D图像中的脊椎进行配准, 从而间接地在术中为医生提供病人脊椎的3D姿态信息.
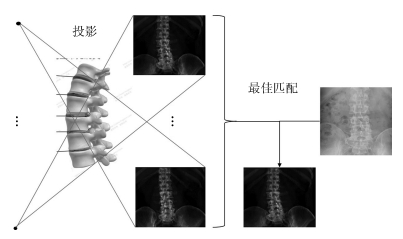
如图 1所示, 传统的2D/3D配准方法是基于搜索的策略, 是将3D图像模拟投影成一系列的2D图像, 将这些模拟投影图像与真实的2D图像进行相似性度量, 找到一个最佳匹配的模拟投影图像, 从而完成配准[1-4].在进行相似性度量时, 早期配准方法如[2, 4-7]是对整幅图像或感兴趣区域进行配准, 这样目标周围的组织也会对配准产生影响.为了避免邻近组织的影响, Pohl等在配准前先对目标进行分割, 使得配准更加的精确[8].在搜索的策略上, 由于投影空间复杂度较高为O(n6), 包括3个平移自由度和3个旋转自由度, 所以计算量巨大, 为了减小计算量, 有许多启发式搜索的方法被提出, 如Zollei等和Kim等使用梯度下降的方法来引导搜索[5-6], Chou等使用回归学习的方法建立灰度残差与投影参数改变量的关系来引导投影参数的搜索方向[9].这些基于启发式搜索的配准方法在一定程度上减小了计算量, 但是依然很难达到实时配准, 并且对初值敏感, 不易收敛.
由于基于搜索策略的配准方法计算量大, 越来越多的研究转向基于机器学习的方法[10-12].基于机器学习的配准方法主要是学习模拟投影图像与投影参数之间的关系, 从而避免搜索的过程, 大大提高了配准的效率.使用投影图像的哪些信息以及如何提取这些信息并建立与投影参数之间的关系是基于机器学习配准方法的一个重要的问题. Cyr等只使用了简单的轮廓信息, 而没有使用内部丰富的结构信息[10].文献[11]中建立了目标的纹理模型, 并学习纹理模型与投影参数之间的关系, 在精度和速度上都有较好的效果, 但是这个工作配准的对象是干扰较小的头部图像, 因此并没有分割的过程.文献[12]中使用标志点的统计分量来回归学习其与投影参数之间的关系, 但是其将分割、标志点定位和统计分量计算作为三个独立的问题进行处理, 且分割直接使用人工设定阈值的方法, 使得整个方法复杂且需要较多的人为干预, 稳定性和实用性欠佳.
为了更好地分割目标, 本文对脊椎建立了统计形状模型[13-14].统计形状模型最早应用于人脸分割上, 文献[15-16]将统计形状模型应用在医学影像的分割上, 得到了不错的效果.统计形状模型除了分割目标外, 还能提取形状分量、灰度分量、标志点位置等信息, 相比文献[12]中将这三个步骤作为三个独立的问题进行处理, 统计形状模型具有更高的稳定性和实用性.文献[11]中使用了灰度信息建立了纹理模型, 但是2D/3D配准是跨模态的, 灰度信息易受到模态的影响, 而形状信息并不会受到模态的影响, 因此本文采用形状信息建立与投影角度的关系, 即姿态模型.
另一方面, 可以证明6个投影参数, 在选择合理的投影方式下, 其中4个投影参数的效果可以等效为一个仿射变换, 有了标志点的位置, 可以通过几何的方法直接计算出这个仿射变换, 因此姿态模型只需要建立两个投影参数与形状分量的关系.
基于以上考虑, 本文提出了一个结合几何与学习的2D/3D脊椎配准方法, 该方法使用统计形状模型对目标脊椎进行分割并提取形状信息, 在一个本文构建的新的投影方式下, 两个参数通过学习求解, 其余4个投影参数通过几何求解.
本文的主要贡献如下:通过学习的方法建立投影图像与投影参数之间的关系, 构建了一个新的投影变换方式, 使用几何和学习相结合的方法计算投影参数.故而, 本文的方法实时性好, 准确性高, 鲁棒性好.
1. 方法
1.1 总体流程
如图 2所示, 本方法主要包括三个部分.第一部分为建立统计形状模型, 在术前使用训练集的CT图像投影生成2D的DRR (Digitally reconstructed radiograph)图像, 并和X-ray图像一起建立统计形状模型AAM (Active appearance model); 第二部分为建立姿态模型, 在术前对病人的CT图像进行DRR投影, 使用AAM模型分割DRR图像中目标脊椎, 并得到形状参数, 然后建立投影参数与形状参数之间的关系; 第三部分为配准, 在术中, 使用AAM模型对X-ray图像的目标脊椎进行分割, 并得到形状参数, 再使用姿态模型通过形状参数直接得到投影参数, 从而完成配准.
1.2 建立统计形状模型
统计形状模型广泛地应用在医学影像分割当中, 常用的统计形状模型包括ASM (Active shape model)[13]和AAM[14], 其中ASM只对形状信息进行建模, 而AAM不仅对形状信息进行建模同时也对灰度信息进行建模, 因此具有更好的分割性能, 因此本文采用AAM来建立统计形状模型.
本文将3D的CT图像投影成2D的DRR图像, 并对2D的DRR图像和X-ray图像进行AAM建模.为了可以使用同一个统计形状模型来对DRR图像和X-ray进行标志点的定位, 本文将DRR图像和X-ray图像放在一起建立一个统一的AAM模型.
为了提取建立AAM模型所需的标志点, 如图 3所示, 本文对每个样本使用人工提取的方法提取所需的标志点, 并使用普氏分析(Procrustes analysis)[17]将提取的标志点映射到一个共同的坐标系下, 使得每个样本标志点的重心为原点, 并消除平移、放缩、旋转对不同样本标志点的影响.
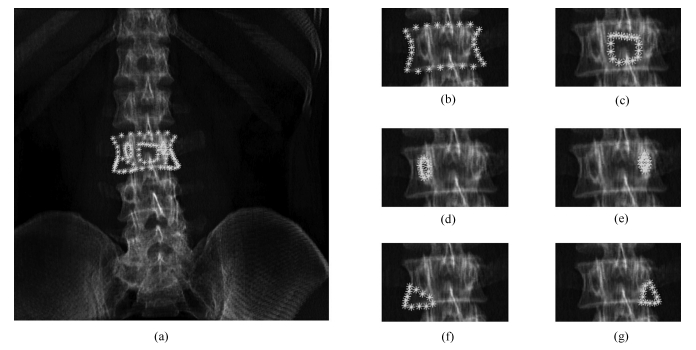 图 3 提取标志点(我们对每幅图像手动提取93个标志点, 所有标志点总体分为6个部分: (a)为所有的标志点, (b)、(c)、(d)、(e)、(f)、(g)为6个部分每个部分的标志点, 其中(b)为椎体轮廓, (c)为中央灰度凹陷, (d)和(e)接近于生理结构的椎弓根, (f)和(g)为椎体左右下切角)Fig. 3 Extract landmarks (We manually extract 93 landmarks for each image, all landmarks are divided into 6 parts, in which (a) contains all landmarks, while (b), (c), (d), (e), (f), (g) contain one of 6 parts, among them, (b) is vertebral body contour, (c) is the central gray depression, (d) and (e) are close to the pedicle of the physiological structure, and (f) and (g) are the left and right bottom of the vertebral body.)
图 3 提取标志点(我们对每幅图像手动提取93个标志点, 所有标志点总体分为6个部分: (a)为所有的标志点, (b)、(c)、(d)、(e)、(f)、(g)为6个部分每个部分的标志点, 其中(b)为椎体轮廓, (c)为中央灰度凹陷, (d)和(e)接近于生理结构的椎弓根, (f)和(g)为椎体左右下切角)Fig. 3 Extract landmarks (We manually extract 93 landmarks for each image, all landmarks are divided into 6 parts, in which (a) contains all landmarks, while (b), (c), (d), (e), (f), (g) contain one of 6 parts, among them, (b) is vertebral body contour, (c) is the central gray depression, (d) and (e) are close to the pedicle of the physiological structure, and (f) and (g) are the left and right bottom of the vertebral body.)1.2.1 形状模型
本文对映射到共同坐标系下的标志点使用PCA (Principal component analysis)得到形状模型(见文献[13]), 每个样本的特征点$x({x_1},{x_2}, \cdots ,{x_n})$可以表示为
$ x = \overline x + {P_s}{b_s} $
(1) 这里是$\overline x $平均形状, $P_s$是对标志点使用PCA得到的一组标准正交基, $b_s$是形状模型参数.
1.2.2 表观模型
我们把对所有的样本进行变形, 使得其特征点变形到平均形状上(使用三角算法)[18].我们把经过形状标准化的图像, 在其形状模型所覆盖的区域进行采样, 并对采样点进行归一化使其均值为0, 方差为1, 以消除亮度的影响, 从而得到$g$.对$g$我们使用PCA得到表观模型[14], 则$g$可以表示为
$ g = \bar g + {P_g}{b_g} $
(2) 这里$\bar{g}$是平均灰度, $P_g$是灰度模型的标准正交基, $b_g$是灰度模型参数.
1.2.3 联合模型
我们将形状模型参数和灰度模型参数串联起来建立一个联合模型.由于形状模型和灰度模型具有不同的量纲, 因此我们对形状模型加一个系数以统一量纲.
$ b = \left[ {\begin{array}{*{20}{c}} {{W_s}{b_s}}\\ {{b_g}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{W_s}P_s^{\rm{T}}(x - \bar x)}\\ {P_g^{\rm{T}}(g - \bar g)} \end{array}} \right] $
(3) 其中, $W_s$是一个对角阵来平衡形状模型和灰度模型参数的量纲(见文献[14]).
为了进一步挖掘形状模型和灰度模型之间相关性, 我们对串联的形状模型和灰度模型参数使用PCA得到联合模型(见文献[14]), 由于形状模型参数和灰度模型参数的均值为0, 所以$b$均值为0, 则有:
$ \hat{b}=Qc $
(4) $Q$是表征模型正交基, $c$是表征模型参数:这样我们可以更直接地使用$c$来表达形状和灰度
$ \hat{x}=\bar{x}+P_s W_s Q_s c, \quad\hat{g}=\bar{g}+P_g Q_g c $
(5) 其中
$ Q= \begin{bmatrix} Q_s\\ Q_g \end{bmatrix} $
(6) 1.2.4 分割模型
建立了形状和灰度的联合统计模型之后, 使用该统计模型对目标进行分割, 分割使用迭代的策略.为了使得分割迭代修正的过程更加高效, 分割模型使用了学习的方法, 使用一个线性模型去学习灰度的偏差与联合统计模型参数的偏移量之间的关系:
$ \delta c=A\delta I $
(7) 为了得到A, 在模型的参数上人为增加一个偏移量$\delta{c}$, 计算增加了偏移量之后图像灰度的变化$\delta I$, 使用多元线性回归来拟合$A$.为了拟合平移$t_x$、$t_y$、旋转$\theta$和尺度$s$的变化带来的变化, 在模型参数上增加额外的4个参数($s_x, s_y, t_x, t_y$), 其中$s_x=s \cos (\theta)$, $s_y=s \sin (\theta)$.同时将原图像的灰度$I$标准化后进行采样得到纹理$g$, 则偏移关系变为
$ \delta c=A\delta g $
(8) 其中
$ \delta g=g_s -g_m $
(9) $g_s$为原图像纹理, ${g}_m$为模型的当前迭代联合统计模型的纹理.
1.3 建立姿态模型
由于病人的CT图像可以在术前得到, 所以可以在术前从病人的CT图像中尽可能地获取信息以辅助术中的配准, 提高术中的配准速度和精度.
本节通过对病人术前CT图像投影生成一系列DRR图像, 并使用AAM模型对目标脊椎进行分割得到其统计模型参数, 从这个参数中得到目标脊椎的形状分量和灰度分量.
为了避免配准搜索的过程, 本节建立了姿态模型, 即脊椎和投影参数之间的关系.由于DRR图像和X-ray图像属于不同的模态, 其灰度信息有一定的差异, 因此用DRR图像的灰度信息建立的姿态模型直接应用于X-ray图像并不合适.考虑到脊椎的形状信息不但受模态的影响小而且与投影参数也有较强的相关性, 所以本文使用形状信息来建立姿态模型.
在投影生成DRR图像时, 如果让CT以一些特定的方式变换, 4个投影参数的作用可以等效为一个仿射变换.这就意味着部分投影参数可被几何变换代替.本文构建了一种新的投影变换, 如图 4所示, ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示方向, $w$轴沿径向方法指向背离圆心的方向.
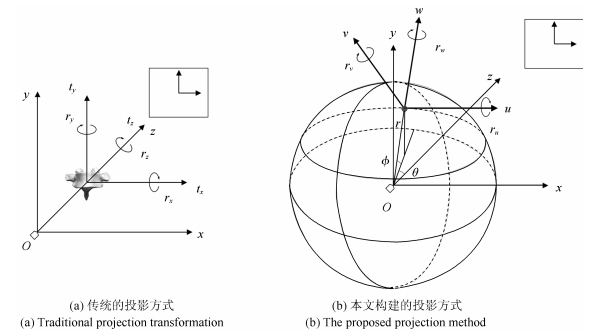 图 4 投影变换((a)图是传统的投影方式, ($x, y, z$)为世界坐标系, ($t_x, t_y, t_z$)是三个平移参数($r_x, r_y, r_z$)为三个旋转参数. (b)图是本文构建的投影方式, ($x, y, z$)为世界坐标系, ($x'O'y'$)为投影平面坐标系, 此坐标系沿世界坐标系$z$轴向投影与($xOy$)重合. ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示所示方向, $w$轴沿径向方法指向背离圆心的方向.)Fig. 4 Projection transformation ((a) is traditional projection transformation, and ($x, y, z$)is world coordinate system, and ($t_x, t_y, t_z$) are three translation parameters, while ($r_x, r_y, r_z$) are three rotation parameters. b) is the proposed projection method. ($x, y, z$) is the world coordinate system, and $x'O'y'$) is the coordinate system of projective plane. This coordinate system coincides with the axial projection of $z$ in the world coordinate system ($xOy$). ($r, \theta, \phi$) are parameters for the spherical coordinate system. ($u, v, w$) is pose projection coordinates of object, and it coact with spherical coordinates as the (b) shows.)
图 4 投影变换((a)图是传统的投影方式, ($x, y, z$)为世界坐标系, ($t_x, t_y, t_z$)是三个平移参数($r_x, r_y, r_z$)为三个旋转参数. (b)图是本文构建的投影方式, ($x, y, z$)为世界坐标系, ($x'O'y'$)为投影平面坐标系, 此坐标系沿世界坐标系$z$轴向投影与($xOy$)重合. ($r, \theta, \phi$)为球形坐标系的参数. ($u, v, w$)为投影对象自身姿态坐标系, 此姿态坐标系与球形坐标系联动, 姿态坐标系的$u$轴平行于球坐标系的纬线切线指向如图 4(b)中所示方向, $v$轴平行于球坐标系的经线指向如图 4(b)中所示所示方向, $w$轴沿径向方法指向背离圆心的方向.)Fig. 4 Projection transformation ((a) is traditional projection transformation, and ($x, y, z$)is world coordinate system, and ($t_x, t_y, t_z$) are three translation parameters, while ($r_x, r_y, r_z$) are three rotation parameters. b) is the proposed projection method. ($x, y, z$) is the world coordinate system, and $x'O'y'$) is the coordinate system of projective plane. This coordinate system coincides with the axial projection of $z$ in the world coordinate system ($xOy$). ($r, \theta, \phi$) are parameters for the spherical coordinate system. ($u, v, w$) is pose projection coordinates of object, and it coact with spherical coordinates as the (b) shows.)为了使问题更加简化且清晰, 本文在对CT投影之前, 先将目标脊椎的中心移动到初始投影位置.对于新的投影方式, 投影过程可以表示为
$ I={ P}({T}(I_{3{\rm D}};r_u, r_v, r_w, r, \theta, \phi )) $
(10) 其中, $I_{3{\rm D}}$为3D图像, $T$为本文构建的三维空间变换, $P$为DRR投影, $I$为投影生成的2D的DRR图像.
由于我们获得X-ray图像生成时, 投影对象距离光源的大致距离$r_0$, 因此可以将$r_0$作为投影的基准值, 实际投影的距离可以表示为$r_0+\delta r$, 这样投影过程可以表示为
$ I={P}({T}(I_{3{\rm D}};r_u, r_v, r_w, r_0 +\delta r, \theta, \phi)) $
(11) 由于$\delta r\ll r_0$, 因此我们可以近似认为$\delta r$的改变所引起的投影图像的变化为一个放缩变换(证明详见附录A).
令
$ I_a={P}({T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0)) $
(12) $ I_c={P}({T}(I_{\rm CT};r_u, r_v, r_w, r_0 +\delta r, \theta, \phi )) $
(13) $x^a$为$I^a$某点的坐标, $x^c$为$I^c$中$x^a$的对应点的坐标, 我们把二维的投影坐标系下的坐标点增广表示在三维的世界坐标系中则有$x^A={bmatrix} x^a\\ {h} {bmatrix}$, $x^C={bmatrix} x^c\\ {h} {bmatrix}$. $h$是光源到投影平面原点的距离.则有(证明过程详见附录A)
$ x^C=kRSx^A $
(14) 其中, $k$为一个系数使得等式右边的第三维为$h$, 且
$ S= \begin{bmatrix} s & 0 & 0\\ 0 & s & 0\\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0\\ - \sin r_w & \cos r_w & 0\\ 0 & 0 & 1 \end{bmatrix} $
(15) $ s=\frac{r_0}{(r_0+\Delta r)} $
(16) 其中
$ R= \begin{bmatrix} \cos \theta & 0 & \sin \theta\\ - \sin \theta & \sin \phi & \cos \theta \cos \phi\\ \sin \theta \sin \phi & \cos \phi & - \cos \theta \sin \phi \end{bmatrix} $
(17) $r_u$和$r_v$是空间的旋转参数, 表示的是脊椎的空间姿态, 我们称之为姿态参数, $r_w, \delta r, \theta, \phi$可以使用一个几何变换代替, 我们称之为几何参数.具有相同姿态参数的DRR图像之间可以使用几何变换(齐次空间下)相互转换, 这就意味着对相同的姿态参数只需要投影生成一张DRR图像, 其他相同姿态参数的DRR图像可以通过几何变换的方法得到.这样需要进行DRR投影的参数空间就可以从O($n^6$)减少为O($n^2$).对于图像上的标志点, 同样可以使用线性变换得到, 需要定位标志点位置的图像空间也可以从O($n^6$)减少为O($n^2$), 这样显著的减少了定位标志点的工作量.
为了学习姿态参数与目标脊椎形状参数之间的关系, 对CT图像生成$n$幅DRR图像.对于$n$幅生成的投影图像, 使用AAM分割目标脊椎并获得$n$组形状参数${\pmb B}=(b_1, b_2, \cdots, b_n)$, 每个投影图像对应的姿态参数为
$ \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} = \begin{bmatrix} r_{u1} & r_{u2} & \cdots & r_{un} \\ r_{v1} & r_{v2} & \cdots & r_{vn} \end{bmatrix} $
本文使用一个线性模型$M$去学习形状参数与姿态参数之间的关系,
$ \begin{equation} \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} =M{\pmb B} \end{equation} $
(18) $ \begin{equation} M= \begin{bmatrix} \pmb {R_u} \\ \pmb {R_v} \end{bmatrix} {\pmb B}^{\rm T}({\pmb B}{\pmb B}^{\rm T})^{-1} \end{equation} $
(19) 则$M$即是我们需要的姿态模型.通过该姿态模型, 我们可以使用形状参数直接求出对应的投影姿态参数.给定一幅图像目标脊椎的形状参数$b$, 则其对应的姿态参数为
$ \begin{equation} \begin{bmatrix} r_u \\ r_v \end{bmatrix} =Mb \end{equation} $
(20) 1.4 配准
如图 5所示, 在术前, 针对由CT投影生成的DRR图像, 首先用AAM模型分割目标脊椎得到其形状参数, 然后建立姿态模型, 即形状参数与投影角度之间的关系; 在术中, 先对X-ray图像使用AAM模型分割目标脊椎得到形状参数, 然后通过术前得到的姿态模型求取投影参数.具体如下:
对于术中待配准的X-ray图像$I_{ \mbox{X-ray}}$, 我们使用AAM模型分割目标脊椎(需手动指定初始位置)并获得其形状参数$b_{ \mbox{X-ray}}$, 则其对应的姿态参数为
$ \begin{equation} \begin{bmatrix} r_u \\ r_v \end{bmatrix} =Mb_{ \mbox{X-ray}} \end{equation} $
(21) 获得了姿态参数后, 使用此姿态参数生成对应的DRR图像.利用生成的DRR图像和X-ray图像上标志点的几何变换关系, 我们可以求出几何参数.具体如下:
我们根据得出的姿态参数对目标CT图像$I_{\rm CT}$进行DRR投影, 得到对应的DRR图像$I_{\rm DRR}$, 有:
$ \begin{equation} I_{\rm DRR}={P(T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0)) \end{equation} $
(22) $x_{ \mbox{X-ray}}$是$I_{\mbox{X-ray}}$中一点(齐次坐标下), $x_{\rm DRR}$是$I_{\rm DRR}$中的$x_{ \mbox{X-ray}}$的对应点(齐次坐标下).
$ \begin{equation} x_{ \mbox{X-ray}}=kRSx_{\rm DRR} \end{equation} $
(23) 对于$I_{\mbox{X-ray}}$中目标脊椎的标志点的点集为$X_{ \mbox{X-ray}}$, 和$I_{\rm DRR}$中目标脊椎的标志点的点集为$X_{\rm DRR}$. $X_{ \mbox{X-ray}}$的重心在二维投影平面的坐标为$(cx, cy)$; 由于CT中目标脊椎的中心在投影初始位置, 所以我们可以通过$X_{ \mbox{X-ray}}$重心的位置求出$\theta$和$\phi$,
$ \begin{equation} \theta ={\rm arctan}\left(-\frac{cx}{{h}}\right), \quad \phi={\rm arctan}\left(\frac{cy}{{h}}\right) \end{equation} $
(24) 通过$\theta$和$\phi$我们可以得到$R$, 于是我们可以消除球面旋转的影响:
$ \begin{equation} k^{-1}R^{-1}x_{ \mbox{X-ray}}=Sx_{\rm DRR} \end{equation} $
(25) 此时, 我们只需要求出相似矩阵$S$的旋转系数和放缩系数就可以求出X-ray图像与CT的配准关系.我们使用以下目标函数来求相似矩阵$S$的旋转系数$r_z$和放缩系数$s$.
$ \begin{equation} \begin{aligned} (r_z, s)= \arg \min\limits_{(r_z, s)}\left(\sum\limits_{i=1}^{n}\parallel {k_i}^{-1}R^{-1}x_i-Sy_i\parallel \right), \\ x_i\in X_{ \mbox{X-ray}}, \ y_i\in X_{\rm DRR} \end{aligned} \end{equation} $
(26) 得到$(r_z, s)$之后, 我们可以使用$s$和$r_0$求出$\delta r$
$ \begin{equation} \frac{r_0}{(r_0+\Delta r)}=s\Rightarrow \Delta r=\frac{r_0(1-s)}{s} \end{equation} $
(27) 这样我们就求出了和X-ray相对应的DRR图像的所有投影参数, 即完成了配准.
2. 实验
2.1 实验数据和实验环境
CT数据由北京医院提供. CT采集设备为GE公司的Discovery HD720, CT数据分辨率为0.24 mm × 0.24 mm × 0.7 mm.有6组CT数据和与其对应的冠状面X光图像, 构建统计形状模型时, 本文又同时使用没有对应图像的另外5个CT数据和20个X-ray冠状面图像.处理数据和运行算法是在一台个人电脑上进行的, 配置为Intel(R) Core(TM) i5-2400 CPU @ 3.10 GHz, 4 GB内存.运行算法平台为Matlab R2014b.
2.2 生成DRR投影图像
对于有6组有对应冠状面X-ray图像的CT图像, 本文使用式(7)所示的投影方式, 投影参数$r_u\in(-5^\circ , 5^\circ) $, $r_v\in(-10^\circ , 10^\circ )$, 且以$1°$为间隔, 其他参数$r_w\in(-45^\circ , 45^\circ )$, $\Delta r\in(-50 mm, 50 mm)$, $\theta \in(-10^\circ , 10^\circ )$, $\phi \in(-10^\circ , 10^\circ )$, 在区间内随机指定, 每个CT投影生成$11 \times 21=231$张图像.对于没有对应冠状面X-ray图像的CT, 本文投影参数的范围控制在$r_u\in(-5^\circ , 5^\circ )$, $r_v\in(-10^\circ , 10^\circ )$, $r_w\in(-45^\circ , 45^\circ )$, $\Delta r\in(-50 mm, 50 mm)$, $\theta \in(-10^\circ , 10^\circ )$, $\phi \in(-10^\circ , 10^\circ )$, 在这个投影参数空间中随机投影生成15张DRR图像.在进行DRR投影时, 投影源到投影平面的距离$h=1 000$ mm, 投影对象的初始距离$r_0=500$ mm.
2.3 实验过程
为了充分利用数据, 我们对6组有配套CT和X-ray图像的数据使用留一交叉验证.每次我们使用这6组数据中的5组作为训练集, 剩下的一组作为测试集.我们使用训练集的5组数据和没有对应图像的另外5个CT和20个X-ray数据来建立AAM模型, 使用测试集的CT数据来建立姿态模型, 使用测试集的X-ray数据来与测试集的CT数据进行配准来验证本文方法的性能.
在建立AAM模型时, 本文从每个CT投影生成的DRR图像中随机不重复的抽取15张图像, 并和其他的X-ray图像一起建立AAM模型, 这样用来建立AAM模型的图像共有$(5+5) \times 15+5+20=175$幅图像.我们对每幅图像手动提取93个标志点, 如图 2所示.
在建立姿态模型时, 本文使用测试集的CT投影生成的DRR图像来建立姿态模型.同时为了比较线性模型和更高阶模型如二次、三次、四次模型, 本文也做了对比实验.为了比较$r_u$和$rv$在不同采样间隔下建立的姿态模型的性能, 本文也对1°、2°、3°采样间隔下建立的姿态模型做了对比.
2.4 评价准则
对于最终的配准性能的评价, 本文使用平均目标误差(Mean target register error, mTRE).对X-ray图像和配准得到的其对应的DRR图像, 手动分割出目标脊椎的轮廓, 衡量两个轮廓之间的误差来衡量配准的性能.若$G$为X-ray图像的脊椎轮廓点集, $H$为配准得到的DRR图像的脊椎轮廓的点集, 则$G$和$H$的mTRE为
$ \begin{equation} \begin{aligned} m(G, H)=\frac{\sum\limits_{i=1}^{n}{\rm min}_{j=1}^{m}d(g_i, h_j)}{n}, \\ g_i\in G, h_j\in H \end{aligned} \end{equation} $
(28) 其中, $d(g_i, h_j)$为$g_i$和$h_j$的欧氏距离.
3. 结果
图 6(a)和(b)展示了在建立姿态模型时, 分别使用线性、二次、三次和四次的模型在采样间隔为1°和2°时对$r_u$和$r_v$进行拟合时的预测误差. 图 6(c)和(d)展示了使用线性模型时, 训练样本使用1°、2°、3°采样间隔的$r_u$和$r_v$来进行拟合时的$r_u$和$r_v$的预测误差.其表明相比之下在1°采样间隔和使用线性模型来建立姿态模型时, 具有较好的性能.
 图 6 线性和高阶拟合((a)和(b))与不同采样间隔下预测误差的变化((c)和(d))Fig. 6 The difference of prediction error between linear model and high order model (a), (b) and by difference sampling intervals (c), (d)
图 6 线性和高阶拟合((a)和(b))与不同采样间隔下预测误差的变化((c)和(d))Fig. 6 The difference of prediction error between linear model and high order model (a), (b) and by difference sampling intervals (c), (d)图 7是配准结果, 第一行是每个病人的X-ray图像, 黑线是目标脊椎的轮廓; 第二行是配准后对应的DRR图像, 白线是目标脊椎的轮廓; 第三行是配准结果, 底图是X-ray图像, 黑线是X-ray图像中目标脊椎的轮廓, 白线是DRR中目标脊椎轮廓对应到X-ray图像中的显示.
表 1是每组CT在采样间隔为1°和使用线性模型下的姿态预测误差, 配准的平均轮廓距离和配准(包含分割)所耗费时间, 其中可以看出本文的方法精度较高, 实时性好. 表 2为本文方法与其他方法在配准精度和时间上的对比, 可以看出本文方法具有一定的优越性.
表 1 配准结果Table 1 Results of registration对象 姿态误差ru(°) 姿态误差rv(°) mTRE (mm) 时间(s) PA1 0.92±0.69 0.88±0.71 0.88±0.73 0.96 PA2 0.62±0.51 0.70±0.62 1.13±0.75 0.88 PA3 0.52±0.44 0.70±0.58 1.01±0.62 0.88 PA4 1.43±1.05 1.13±0.92 0.77±0.58 0.89 PA5 0.78±0.61 0.62±0.48 0.73±0.45 0.88 PA6 0.76±0.63 0.81±0.64 0.68±0.46 0.88 平均 0.84 0.81 0.87 0.90 表 2 各种方法对比Table 2 Comparison with other methods作者 方法框架 相似度度量 mTRE (mm) 时间(s) Russakof 基于搜索 互信息 1.3 - Russakof 基于搜索 交叉相关 1.5 - Russakof 基于搜索 梯度相关 1.3 - Russakof 基于搜索 灰度模式 1.6 - Russakof 基于搜索 梯度差 1.3 - Russakof 基于搜索 Diff.图像熵 1.9 - Otake 基于搜索 NGI - 6.3 ~ 54 Philipp 基于学习 纹理 1.05 0.02 本文 基于学习 形状 0.87 0.90 4. 讨论
如图 6所示, 在建立姿态模型时, 本文同时实验了使用线性、二次、三次、四次的模型来拟合姿态模型, 但是其预测结果却并不如简单的线性模型好, 说明形状参数与姿态参数之间具有较好的线性关系, 使用高次的模型反而容易过拟合.同时我们测试了在线性模型下使用不同的采样间隔的预测性能, 在测试范围内的趋势为采样越密集模型的预测性能就越好, 在采样间隔为1°时既能有较好的预测性能又不用生成过多的投影图像.在1°采样间隔下, 使用线性模型的预测平均误差$r_u$仅为0.84°, $r_v$仅为0.81° (表 1), 这说明了用线性模型来回归学习形状参数和姿态参数的关系是有效的.因此本文配准采用的姿态模型为1°采样间隔和线性回归学习下的模型.
表 1展示了拟合姿态模型的误差和配准误差, 可以看出本文使用学习的策略来预测投影姿态的角度误差在0.5°度到1.4°度之间, 平均预测误差$r_u$为0.84°, $r_v$为0.81°.其中第4组数据的误差比较大, 主要在于第4组数据的图像质量明显不如其他的几组数据, 因此其角度误差有明显增大.若除去第4组数据, 投影姿态角度预测误差在0.5°到0.9°之间, 平均为0.72°和0.74°.配准误差在0.6 mm ~ 1.2 mm之间, 平均0.87 mm, 配准速度平均为0.9 s, 可以看出本方法具有精度较高.传统的基于搜索策略的2D/3D配准, 搜索空间的复杂度为O($n^6$), 很难达到实时配准, 而本文的方法仅需要0.9 s, 能够满足实际应用的实时配准需求.
总体来说, 本文使用机器学习的方法, 通过建立姿态模型, 即形状参数与投影角度之间的关系, 来进行2D/3D配准, 避免了繁重的搜索.在计算投影参数时, 使用机器学习和几何变换相结合的方法, 使用几何变换的方法计算出6个投影参数中的4个, 使用机器学习的方法学习剩余的两个, 大大减小了要学习的参数空间.因此, 本方法具有实时性好, 准确性高, 鲁棒性强的优点.本文的配准方法在普通PC配置, 没有GPU加速, 以及使用计算效率并不高的MATLAB且并未对代码进行太多优化的情况下依然能够在1 s以内完成配准, 完全可以达到实时配准.
在建立DRR图像与投影参数的关系时, 本文并没有使用DRR图像的灰度信息作为学习的对象, 而是使用了形状信息, 由于形状信息与投影参数有非常好的线性相关性, 所以能够得到较好的配准结果.在学习投影参数时, 本文使用了新的投影方式, 使直接的投影图像空间和需要定位标志点的图像空间均从O($n^6$)减少到了O($n^2$), 大大减少了术前的工作量.在新的投影方式下, 几何参数和姿态参数相互独立, 因此可以用几何的方法求几何参数, 用学习的方法求姿态参数, 两者之间不会交叉影响, 也使得配准更加有效率, 结果也更准确.
本文的方法是基于分割与标志点的定位之上的, 标志点定位的效果对配准的影响较大, 本文的方法时间开销也主要耗费在分割和标志点定位上, 如果分割和标志点定位能够更加准确、快速, 本文的方法也能够更准确, 实时性更好.
附录. A
本文构建的投影方式可以表示为
$ \begin{equation} I={P(T}(I_{3{\rm D}};r_u, r_v, r_w, r, \theta, \phi )) \end{equation} $
(A1) 对象的姿态坐标系(图 3(b)所示)的基底$\beta$在世界坐标系下的表示为
$ \begin{align} \begin{aligned} \beta _E= & \begin{bmatrix} u & v & w \end{bmatrix} =\nonumber\\ &\begin{bmatrix} \cos \theta & - \sin \theta \cos \phi & \sin \theta \sin \phi \\ 0 & \sin \phi & \cos \phi \\ \sin \theta & \cos \theta \cos \phi & - \cos \theta \sin \phi \end{bmatrix} \end{aligned} \end{align} $
(A2) 在实际的操作中, 由于我们可以得到X-ray投影时投影对象与X-ray光源的大致距离$r_0$, 因此对$I_3D$进行DRR投影时可令$r$的初始值为$r_0$, 而$r$的实际影值可表示为为$r_0+\Delta r$, 投影过程可以表示为
$ \begin{equation} I={P(T}(I_{3{\rm D}};r_u, r_v, r_w, r_0+\Delta r, \theta, \phi )) \end{equation} $
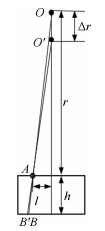
(A3) 由于$\Delta r\ll r_0$, 因此我们可以近似认为$\Delta r$的改变并不引起图像结构的变化.如图A1所示, 从$O$点发出的X-ray射线经过$A$点从$B$点穿出, 当$O$点移动$\Delta r$到$O'$时, X-ray射线经过$A$点从$B'$点穿出.则
$ \begin{equation} BB'=\frac{\Delta rlh}{(r-\Delta r)r} \end{equation} $
(A4) 脊椎的厚度和宽度均远远小于投影距离, 因此$l\ll r, h\ll r$, 有$BB'\approx 0$, 这样可以近似地认为放射源经过$Delta r$的移动经过$A$点在脊椎内部通过的路径并没有发生变化, 即经过$A$点成的像的灰度值没有变化.
由于我们近似地认为$\Delta r$的变化并不引起投影图像的灰度值的变化, 那么$\Delta r$的改变仅引起投影图像大小的变化(A2), 大小的变化可以使用一个放缩变换来代替.
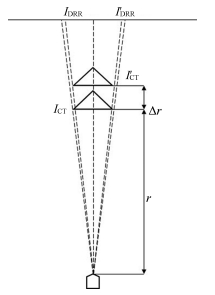 图 A2 $\Delta r$近似等效于相似变换Fig. A2 The effect of $\Delta r$ approximate to similar transformation
图 A2 $\Delta r$近似等效于相似变换Fig. A2 The effect of $\Delta r$ approximate to similar transformation为了方便证明$r_w, \Delta r, \theta, \phi$的改变引起的投影图像的变化可以使用几何变换来代替, 我们将投影变换拆解成3部分(如图A 3所示):
首先, 如图A3(a)所示, 初始化投影对象的位置为球形坐标系中$r=r_0, \theta =0, \phi =0$.然后对投影对象沿$u$轴旋转$r_u$, 沿$v$轴旋转$r_v$.投影过程可以表示为
$ \begin{equation} I^a={P(T}(I_{\rm CT};r_u, r_v, 0, r_0, 0, 0 )) \end{equation} $
(A5) 如图A3所示, 在图A3(b)的基础上, 对投影对象沿$w$轴旋转$r_w$, 并沿径向方向向外移动$\Delta r$.投影过程可以表示为
$ \begin{equation} I^b={P(T}(I_{\rm CT};r_u, r_v, r_w, r_0+\Delta r, 0, 0 )) \end{equation} $
(A6) 如图A3(c)所示, 在图A3(b)的基础上, 对投影对象沿$x$轴旋转$\theta$, 然后沿$y$轴旋转$\phi$.投影过程可以表示为
$ \begin{equation} I^c={P(T}(I_{\rm CT};r_u, r_v, r_w, r_0+\Delta r, \theta, \phi )) \end{equation} $
(A7) 我们令$x^a$为$I^a$某点的坐标, $x^b$为$I^b$中$x^a$的对应点的坐标, $x^c$为$I^c$中$x^b$的对应点的坐标, 我们把二维的投影坐标系下的坐标点增广到齐次坐标系下则有$x^A={bmatrix} x^a \\ {h} {bmatrix}$, $x^B={bmatrix} x^b \\ {h} {bmatrix}$ $x^C={bmatrix} x^c \\ {h} {bmatrix}$. $h$是光源到投影平面原点的距离.
图A3(b)过程可以使用一个旋转变换和一个放缩变换来代替. $x^A$和$x^B$之间的关系可以表示为
$ \begin{equation} x^B=Sx^A \end{equation} $
(A8) 其中
$ \begin{align} \begin{aligned} &S= \begin{bmatrix} s & 0 & 0 \\ 0 & s & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0 \\ - \sin r_w & \cos r_w & 0 \\ 0 & 0 & 1 \end{bmatrix} , \\ &s=\frac{r_0}{(r_0+\Delta r)} \end{aligned} \end{align} $
(A9) 图A3(c)过程可以等价为成像平面以相同的坐标轴为轴沿相反的方向旋转, 这个过程可以等价为计算机视觉中的相机纯旋转. $x^B$和$x^C$之间的关系可以表示为
$ \begin{equation} x^C=kRx^B \end{equation} $
(A10) 其中
$ \begin{align} \begin{aligned} R= &[E]_{\beta }=([\beta]_E)^{\rm T}=\beta^{\rm T} =\\ &\begin{bmatrix} \cos \theta & 0 & \sin \theta \\ - \sin \theta \cos \phi & \sin \phi & \cos \theta \cos \phi \\ \sin \theta \sin \phi & \cos \theta & - \cos \theta \sin \phi \end{bmatrix} \end{aligned} \end{align} $
(A11) $E$为世界坐标系的基底, $k$为一个平衡系数使得$x^C$的第三维为$h$.
从以上可得:
$ \begin{equation} x^C=kRSx^A \end{equation} $
(A12) 其中
$ \begin{align} \begin{aligned} &S= \begin{bmatrix} s & 0 & 0 \\ 0 & s & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \cos r_w & \sin r_w & 0 \\ - \sin r_w & \cos r_w & 0 \\ 0 & 0 & 1 \end{bmatrix} \\ &s=\frac{r_0}{(r_0+\Delta r)} \end{aligned} \end{align} $
(A13) $ \begin{equation} R= \begin{bmatrix} \cos \theta & 0 & \sin \theta \\ - \sin \theta \cos \phi & \sin \phi & \cos \theta \cos \phi \\ \sin \theta \sin \phi & \cos \theta & - \cos \theta \sin \phi \end{bmatrix} \end{equation} $
(A14)
-
表 1 多视角步态库
Table 1 Databases for multiview gait
库名 建立机构 样本容量 具体角度 示例 USF[3] 南佛罗里达大学 122人, 1 870序列(地面、鞋子、负重和时间) 在摄像机前(左右两个)绕椭圆路线行走 
CASIA-A[13] 中国科学院自动化研究所 20人×3视角× 4序列= 240 3个(侧面的3个点) 
CASIA-B[14] 中国科学院自动化研究所 124人× 11视角× (8正常+2背包+ 2外套) = 13 640 11个($180^{\circ}$每间隔$18^{\circ}$度一个视角) 
HID-UMD[15] 马里兰大学 1: 25人× 4个视角= 100 正面(走向、走出)、侧面(向左、向右) 
2: 55人× 4 (2视角) = 220 T形路径(正面、侧面) 
CMU MoBo[16] 卡耐基梅隆大学 25人× 6视角× (3速度+1抱球+ 1上坡) = 600 6个($360^{\circ}$圆周每$60^{\circ}$一个视角) 
OU-ISIR Treadmill[17] 大阪大学 168人 25个(12个方位角× 2个倾斜角度+1个俯视) 
OU-ISIR LP[18] 大阪大学 4 007人 8个(2摄像机$\times $ 4个侧面角度) 
SZU RBG-D[19] 深圳大学 99人× 2视角× 4序列= 792 $90^{\circ}$和$30^{\circ} \sim 60^{\circ}$之间的一个角度 
 下载: 导出CSV
下载: 导出CSV
表 2 类能量图构造方法与性能分析
Table 2 The construction methods and performances analysis of class energy image

表 3 CASIA-B数据集上现有步态识别方法的准确率对比
Table 3 Recognition accuracy of existing approaches on CASIA-B datasets
方法 识别率(%) $54^{\circ}$ $72^{\circ}$ $90^{\circ}$ $108^{\circ}$ $126^{\circ}$ 3D模型局部能量图投影[31] 86.1 98.1 - 92.3 90.4 下肢姿态重构[47] 74.4 72.6 86.5 69.2 67.4 聚类AGI +SRML[48] 68.3 92.7 - 93.4 70.3 聚类EDI +IT2FKNN[49] 72.2 94.8 - 95.3 74.9 GEI+CCA[53] 52.0 94.6 - 93.8 78.3 C3A[55] 86.6 98.7 - 95.4 86.0 GEI+TSVD[59] 53.7 81.8 - 86.3 45.7 低秩GEI+SVD[61] 42.5 86.2 - 88.3 49.8 JSL[68] 71.4 91.7 - 90.5 73.6 KCDML[75] 76.7 94.3 - 88.1 88.4 GEI+SPAE[88] 82.3 94.4 96.0 96.0 86.3
下载: 导出CSV
表 4 现有多视角步态识别方法
Table 4 Existing approaches for multiview gait recognition
模板 方法 实现途径 优点 缺点 三维模板 建立三维步态模型 利用多摄像机对人体结构或人体运动进行3D建模[22, 27-35] 更准确地表达人体各个部位的物理空间; 能够降低遮挡等因素的负面影响. 需要全可控的多摄像机协作的识别环境; 摄像机平衡视角和建模计算复杂. 提取视角不变性特征 提取局部特征[44-47]; 聚类图像估计视角[48, 49]; 其他[38, 51]. 直接提取不随着角度而改变的步态特征进行身份识别, 避免轮廓差异; 思路直观, 计算简单, 易于理解和实现. 仅仅适用于视角变化有限的情况下; 易受到遮挡因素或服饰变化的破坏. 二维图像或视频序列特征 学习不同视角下的映射或投影关系 典范相关分析(CCA)[53-57]; 视角转换模型(VTM)[58-65]; 其他(LDA、CML、MPCA与核扩展等)[66-77]. 投影到子空间中获得步态的视角不变特征, 减小同一行人不同视角下的类内方差; 具有相对较高的识别精度. 步态图像转换成向量后维数常高达上万维, 计算量很大; 视角变化较大时效果不理想; CCA和CML类的方法仅能利用两个视角间的互补信息, 处理N个视角时要重复N次来学习N对特征映射; VTM方法在进行模型构建和视角转化时容易造成噪声传播, 致使识别性能退化. 基于深度神经网络 CNN[80-86]与AutoEncoder[88] 无图像的预处理过程; 有效提取步态特征; 具有相对较高的识别精度. 需要大量数据用于训练; 卷积神经网络缺乏对时间序列信号的记忆功能; 基于自动编码的VTM也有在转化时容易造成噪声传播使识别性能退化的问题.
下载: 导出CSV
-
[1] Phillips P J. Human identification technical challenges. In: Proceedings of the 2002 International Conference on Image Processing. New York, USA: IEEE, 2002. I-49-I-52 [2] Tariq M, Shah M A. Review of model-free gait recognition in biometrie systems. In: Proceedings of the 23rd International Conference on Automation and Computing. Huddersfield, UK: IEEE, 2017. 1-7 [3] Sarkar S, Phillips P J, Liu Z, Vega, I R, Grother P, Bowyer K W. The humanID gait challenge problem:data sets, performance, and analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(2):162-177 doi: 10.1109/TPAMI.2005.39 [4] Liu Z, Sarkar S. Effect of silhouette quality on hard problems in gait recognition. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2005, 35(2):170-183 doi: 10.1109/TSMCB.2004.842251 [5] Kale A, Sundaresan A, Rajagopalan A N, Cuntoor N P, Roy-Chowdhury A K, Kruger V, et al. Identification of humans using gait. IEEE Transactions on Image Processing, 2004, 13(9):1163-1173 doi: 10.1109/TIP.2004.832865 [6] Masood H, Farooq H. A proposed framework for vision based gait biometric system against spoofing attacks. In: Proceedings of the 2017 International Conference on Communication, Computing and Digital Systems. Islamabad, Pakistan: IEEE, 2017. 357-362 [7] Arseneau S, Cooperstock J R. Real-time image segmentation for action recognition. In: Proceedings of the 1999 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing. British Columbia, Canada: IEEE, 1999. 86-89 [8] Verlekar T T, Correia P L, Soares L D. View-invariant gait recognition system using a gait energy image decomposition method. IET Biometrics, 2017, 6(4):299-306 doi: 10.1049/iet-bmt.2016.0118 [9] Niyogi S A, Adelson E H. Analyzing gait with spatiotemporal surfaces. In: Proceedings of the 1994 IEEE Workshop on Motion of Non-Rigid and Articulated Objects. Texas, USA: IEEE, 1994. 64-69 [10] 王科俊, 侯本博.步态识别综述.中国图象图形学报, 2007, 12(7):1152-1160 doi: 10.3969/j.issn.1006-8961.2007.07.002Wang Ke-Jun, Hou Ben-Bo. A survey of gait recognition. Journal of Image and Graphics, 2007, 12(7):1152-1160 doi: 10.3969/j.issn.1006-8961.2007.07.002 [11] Sugandhi K, Wahid F F, Raju G. Feature extraction methods for human gait recognition——a survey. In: Proceedings of the 2017 Advances in Computing and Data Sciences. Communications in Computer and Information Science, vol. 721. Singapore: Springer, 2017. 377-385 [12] Lv Z W, Xing X L, Wang K J, Guan D H. Class energy image analysis for video sensor-based gait recognition:a review. Sensors, 2015, 15(1):932-964 [13] Wang L, Tan T N, Ning H Z, Hu W M. Silhouette analysis-based gait recognition for human identification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(12):1505-1518 doi: 10.1109/TPAMI.2003.1251144 [14] Yu S Q, Tan D L, Tan T N. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In: Proceedings of 18th International Conference on Pattern Recognition. Hong Kong, China: IEEE, 2006. 441-444 [15] Chalidabhongse T, Kruger V, Chellappa R. The UMD Database for Human Identification at a Distance, Technical Report, University of Maryland, USA, 2001 [16] Gross R, Shi J B. The CMU Motion of Body (MoBo) Database, Technical Report CMU-RI-TR-01-18, Carnegie Mellon University, USA, 2001 [17] Makihara Y, Mannami H, Yagi Y. Gait analysis of gender and age using a large-scale multi-view gait database computer vision. In: Proceedings of Asian Conference on Computer Vision. Queenstown, New Zealand: ACM, 2010. 440-451 [18] Iwama H, Okumura M, Makihara Y, Yagi Y. The OU-ISIR gait database comprising the large population dataset and performance evaluation of gait recognition. IEEE Transactions on Information Forensics and Security, 2012, 7(5):1511-1521 doi: 10.1109/TIFS.2012.2204253 [19] Yu S Q, Wang Q, Huang Y Z. A large RGB-D gait dataset and the baseline algorithm. In: Biometric Recognition. Lecture Notes in Computer Science, vol. 8232. Cham: Springer, 2013. 417-424 [20] Seely R D, Samangooei S, Lee M, Carter J N, Nixon M S. The University of Southampton Multi-Biometric Tunnel and introducing a novel 3D gait dataset. In: Proceedings of IEEE 2nd International Conference on Biometrics: Theory, Applications and Systems. Virginia USA: IEEE, 2008. 1-6 [21] Anguelov D, Koller D, Pang H C, Srinivasan P, Thrun S. Recovering articulated object models from 3D range data. In: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. Banff, Canada: ACM, 2004. 18-26 [22] López-Fernández D, Madrid-Cuevas F J, Carmona-Poyato A, Muñoz-Salinas R, Medina-Carnicer R. A new approach for multi-view gait recognition on unconstrained paths. Journal of Visual Communication and Image Representation, 2016, 38:396-406 doi: 10.1016/j.jvcir.2016.03.020 [23] Hofmann M, Sural S, Rigoll G. Gait recognition in the presence of occlusion: a new dataset and baseline algorithms. In: Proceedings of the 19th International Conference in Central Europe Computer Graphics, Visualization and Computer Vision. Plzen, Czech Republic: Václav Skala UNION Agency, 2011. 99-104 [24] Cho C W, Chao W H, Lin S H, Chen Y Y. A vision-based analysis system for gait recognition in patients with Parkinson's disease. Expert Systems with Applications, 2009, 36(3):7033-7039 doi: 10.1016/j.eswa.2008.08.076 [25] Stevenage S V, Nixon M S, Vince K. Visual analysis of gait as a cue to identity. Applied Cognitive Psychology, 1999, 13(6):513-526 doi: 10.1002/(ISSN)1099-0720 [26] Lai D T H, Begg R K, Palaniswami M. Computational intelligence in gait research:a perspective on current applications and future challenges. IEEE Transactions on Information Technology in Biomedicine, 2009, 13(5):687-702 doi: 10.1109/TITB.2009.2022913 [27] Shakhnarovich G, Lee L, Darrell T. Integrated face and gait recognition from multiple views. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2001. 439-446 [28] Bodor R, Drenner A, Fehr D, Masoud O, Papanikolopoulos N. View-independent human motion classification using image-based reconstruction. Image and Vision Computing, 2009, 27(8):1194-1206 doi: 10.1016/j.imavis.2008.11.008 [29] Zhang Z H, Troje N F. View-independent person identification from human gait. Neurocomputing, 2005, 69(1-3):250-256 doi: 10.1016/j.neucom.2005.06.002 [30] Tang J, Luo J, Tjahjadi T, Gao Y. 2.5D multi-view gait recognition based on point cloud registration. Sensors, 2014, 14(4):6124-6143 doi: 10.3390/s140406124 [31] Tang J, Luo J, Tjahjadi T, Guo F. Robust arbitrary-view gait recognition based on 3D partial similarity matching. IEEE Transactions on Image Processing, 2017, 26(1):7-22 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=db1c9453b08e2468c550f2b43633a9b4 [32] Zhao G Y, Liu G Y, Li H, Pietikinen M. 3D gait recognition using multiple cameras. In: Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition. Southampton, UK: IEEE, 2006. 529-534 [33] Deng M Q, Wang C, Chen Q F. Human gait recognition based on deterministic learning through multiple views fusion. Pattern Recognition Letters, 2016, 78:56-63 doi: 10.1016/j.patrec.2016.04.004 [34] Deng M Q, Wang C, Cheng F J, Zeng W. Fusion of spatial-temporal and kinematic features for gait recognition with deterministic learning. Pattern Recognition, 2017, 67:186-200 doi: 10.1016/j.patcog.2017.02.014 [35] Iwashita Y, Ogawara K, Kurazume R. Identification of people walking along curved trajectories. Pattern Recognition Letters, 2014, 48:60-69 doi: 10.1016/j.patrec.2014.04.004 [36] Bobick A F, Davis J W. The recognition of human movement using temporal templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3):257-267 doi: 10.1109/34.910878 [37] Han J, Bhanu B. Individual recognition using gait energy image. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(2):316-323 doi: 10.1109/TPAMI.2006.38 [38] Lam T H W, Lee R S T. A new representation for human gait recognition: motion silhouettes image (MSI). In: Advances in Biometrics. Lecture Notes in Computer Science, vol. 3832. Berlin, Heidelberg: Springer-Verlag, 2005. 612-618 [39] Liu J Y, Zheng N N. Gait history image: a novel temporal template for gait recognition. In: Proceedings of the 2007 IEEE International Conference on Multimedia and Expo. Beijing, China: IEEE, 2007. 663-666 [40] Zhang E H, Zhao Y W, Xiong W. Active energy image plus 2DLPP for gait recognition. Signal Processing, 2010, 90(7):2295-2302 doi: 10.1016/j.sigpro.2010.01.024 [41] Bashir K, Xiang T, Gong S G. Gait recognition without subject cooperation. Pattern Recognition Letters, 2010, 31(13):2052-2060 doi: 10.1016/j.patrec.2010.05.027 [42] Chen C H, Liang J M, Zhu X C. Gait recognition based on improved dynamic Bayesian networks. Pattern Recognition, 2011, 44(4):988-995 doi: 10.1016/j.patcog.2010.10.021 [43] Wang C, Zhang J P, Wang L, Pu J, Yuan X R. Human identification using temporal information preserving gait template. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11):2164-2176 doi: 10.1109/TPAMI.2011.260 [44] Jean F, Albu A B, Bergevin R. Towards view-invariant gait modeling:computing view-normalized body part trajectories. Pattern Recognition, 2009, 42(11):2936-2949 doi: 10.1016/j.patcog.2009.05.006 [45] Ng H, Tan W H, Abdullah J, Tong H L. Development of vision based multiview gait recognition system with MMUGait database. The Scientific World Journal, 2014, 2014:Article ID 376569 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=Doaj000003705025 [46] 彭彰, 吴晓娟, 杨军.基于肢体长度参数的多视角步态识别算法.自动化学报, 2007, 33(2):210-213 http://www.aas.net.cn/CN/abstract/abstract13832.shtmlPeng Zhang, Wu Xiao-Juan, Yang Jun. A multi-view method for gait recognition based on the length of body's parts. Acta Automatica Sinica, 2007, 33(2):210-213 http://www.aas.net.cn/CN/abstract/abstract13832.shtml [47] Goffredo M, Bouchrika I, Carter J N, Nixon M S. Self-calibrating view-invariant gait biometrics. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2010, 40(4):997-1008 doi: 10.1109/TSMCB.2009.2031091 [48] Lu J W, Wang G, Moulin P. Human identity and gender recognition from gait sequences with arbitrary walking directions. IEEE Transactions on Information Forensics and Security, 2014, 9(1):51-61 doi: 10.1109/TIFS.2013.2291969 [49] Darwish S M. Design of adaptive biometric gait recognition algorithm with free walking directions. IET Biometrics, 2017, 6(2):53-60 doi: 10.1049/iet-bmt.2015.0082 [50] Ma Q Y, Wang S K, Nie D D, Qiu J F. Gait recognition at a distance based on energy deviation image. In: Proceedings of the 1st International Conference on Bioinformatics and Biomedical Engineering. Wuhan, China: IEEE, 2007. 621-624 [51] Kale A, Chowdhury A K R, Chellappa R. Towards a view invariant gait recognition algorithm. In: Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance. Miami, Florida, USA: IEEE, 2003. 143-150 [52] Hotelling H. Relations between two sets of variates. Biometrika, 1936, 28(3-4):321-377 doi: 10.1093/biomet/28.3-4.321 [53] Bashir K, Xiang T, Gong S G. Cross-view gait recognition using correlation strength. In: Proceedings of the British Machine Vision Conference. Aberystwyth, UK: BMVA Press, 2010. 109.1-109.11 [54] Hu H F. Multiview gait recognition based on patch distribution features and uncorrelated multilinear sparse local discriminant canonical correlation analysis. IEEE Transactions on Circuits and Systems for Video Technology, 2014, 24(4):617-630 doi: 10.1109/TCSVT.2013.2280098 [55] Xing X L, Wang K J, Yan T, Lv Z W. Complete canonical correlation analysis with application to multi-view gait recognition. Pattern Recognition, 2016, 50:107-117 doi: 10.1016/j.patcog.2015.08.011 [56] Wang K J, Yan T. An improved kernelized discriminative canonical correlation analysis and its application to gait recognition. In: Proceedings of the 10th World Congress on Intelligent Control and Automation. Beijing, China: IEEE, 2012. 4869-4874 [57] Luo C, Xu W J, Zhu C Y. Robust gait recognition based on partitioning and canonical correlation analysis. In: Proceedings of the 2015 IEEE International Conference on Imaging Systems and Techniques. Macau, China: IEEE, 2015. 1-5 [58] Makihara Y, Sagawa R, Mukaigawa Y, Echigo T, Yagi Y. Gait recognition using a view transformation model in the frequency domain. In: Proceedings of European Conference on Computer Vision. Graz, Austria: Springer-Verlag, 2006. 151-163 [59] Kusakunniran W, Wu Q, Li H D, Zhang J. Multiple views gait recognition using view transformation model based on optimized gait energy image. In: Proceedings of the 12th International Conference on Computer Vision Workshops. Kyoto, Japan: IEEE, 2009. 1058-1064 [60] Kusakunniran W, Wu Q, Zhang J, Li H D. Gait recognition under various viewing angles based on correlated motion regression. IEEE Transactions on Circuits and Systems for Video Technology, 2012, 22(6):966-980 doi: 10.1109/TCSVT.2012.2186744 [61] Zheng S, Zhang J G, Huang K Q, He R, Tan T. Robust view transformation model for gait recognition. In: Proceedings of the 18th International Conference on Image Processing. Brussels, Belgium: IEEE, 2011. 2073-2076 [62] Hu M D, Wang Y H, Zhang Z X. Cross-view gait recognition with short probe sequences:from view transformation model to view-independent stance-independent identity vector. International Journal of Pattern Recognition and Artificial Intelligence, 2013, 27(6):1350017 doi: 10.1142/S0218001413500171 [63] Muramatsu D, Shiraishi A, Makihara Y, Uddin M Z, Yagi Y. Gait-based person recognition using arbitrary view transformation model. IEEE Transactions on Image Processing, 2015, 24(1):140-54 doi: 10.1109/TIP.2014.2371335 [64] Muramatsu D, Makihara Y, Yagi Y. Cross-view gait recognition by fusion of multiple transformation consistency measures. IET Biometrics, 2015, 4(2):62-73 doi: 10.1049/iet-bmt.2014.0042 [65] Muramatsu D, Makihara Y, Yagi Y. View transformation model incorporating quality measures for cross-view gait recognition. IEEE Transactions on Cybernetics, 2016, 46(7):1602-1615 doi: 10.1109/TCYB.2015.2452577 [66] Choudhury S D, Tjahjadi T. Robust view-invariant multiscale gait recognition. Pattern Recognition, 2015, 48(3):798-811 doi: 10.1016/j.patcog.2014.09.022 [67] Liu N, Tan Y P. View invariant gait recognition. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. Texas USA: IEEE, 2010. 1410-1413 [68] Liu N N, Lu J W, Tan Y P. Joint subspace learning for view-invariant gait recognition. IEEE Signal Processing Letters, 2011, 18(7):431-434 doi: 10.1109/LSP.2011.2157143 [69] Shawe-Taylor J, Cristianini N. Properties of kernels. Kernel Methods for Pattern Analysis. Cambridge:Cambridge University Press, 2004. 47-84 [70] Alzate C, Suykens J A K. Multiway spectral clustering with out-of-sample extensions through weighted kernel PCA. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(2):335-347 doi: 10.1109/TPAMI.2008.292 [71] Yang J, Frangi A F, Yang J Y, Zhang D, Jin Z. KPCA Plus LDA:a complete kernel Fisher discriminant framework for feature extraction and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(2):230-244 doi: 10.1109/TPAMI.2005.33 [72] Connie T, Goh K O M, Teoh A B J. Multi-view gait recognition using a doubly-kernel approach on the Grassmann manifold. Neurocomputing, 2016, 216:534-542 doi: 10.1016/j.neucom.2016.08.002 [73] Xu W J, Luo C, Ji A M, Zhu C Y. Coupled locality preserving projections for cross-view gait recognition. Neurocomputing, 2017, 224:37-44 doi: 10.1016/j.neucom.2016.10.054 [74] Ben X Y, Meng W X, Yan R, Wang K J. An improved biometrics technique based on metric learning approach. Neurocomputing, 2012, 97(1):44-51 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=4492014b0866d51f7d2415c3699c60d8 [75] Ben X Y, Meng W X, Yan R, Wang K J. Kernel coupled distance metric learning for gait recognition and face recognition. Neurocomputing, 2013, 120:577-589 doi: 10.1016/j.neucom.2013.04.012 [76] Wang K J, Xing X L, Yan T, Lv Z W. Couple metric learning based on separable criteria with its application in cross-view gait recognition. In: Proceedings of the Biometric Recognition. Lecture Notes in Computer Science, vol. 8833. Shenyang, China: Springer, 2014. 347-356 [77] Al-Tayyan A, Assaleh K, Shanableh T. Decision-level fusion for single-view gait recognition with various carrying and clothing conditions. Image and Vision Computing, 2017, 61:54-69 doi: 10.1016/j.imavis.2017.02.004 [78] 陈伟宏, 安吉尧, 李仁发, 李万里.深度学习认知计算综述.自动化学报, 2017, 43(11):1886-1897 http://www.aas.net.cn/CN/abstract/abstract19164.shtmlChen Wei-Hong, An Ji-Yao, Li Ren-Fa, Li Wan-Li. Review on deep-learning-based cognitive computing. Acta Automatica Sinica, 2017, 43(11):1886-1897 http://www.aas.net.cn/CN/abstract/abstract19164.shtml [79] LeCun Y, Kavukcuoglu K, Farabet C. Convolutional networks and applications in vision. In: Proceedings of the 2010 IEEE International Symposium on Circuits and Systems. Paris, France: IEEE, 2010. 253-256 [80] Yan C, Zhang B L, Coenen F. Multi-attributes gait identification by convolutional neural networks. In: Proceedings of the 8th International Congress on Image and Signal Processing. Shenyang, China: IEEE, 2015. 642-647 [81] Wu Z F, Huang Y Z, Wang L. Learning representative deep features for image set analysis. IEEE Transactions on Multimedia, 2015, 17(11):1960-1968 doi: 10.1109/TMM.2015.2477681 [82] Zhang C, Liu W, Ma H D, Fu H Y. Siamese neural network based gait recognition for human identification. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 2832-2836 [83] Tan T N, Wang L, Huang Y Z, Wu Z F. A Gait Recognition Method Based on Depth Learning, CN Patent 201410587758, June 2017 [84] Wu Z F, Huang Y Z, Wang L, Wang X G, Tan T N. A comprehensive study on cross-view gait based human identification with deep CNNs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(2):209-226 doi: 10.1109/TPAMI.2016.2545669 [85] Wolf T, Babaee M, Rigoll G. Multi-view gait recognition using 3D convolutional neural networks. In: Proceedings of the 2016 IEEE International Conference on Image Processing. Arizona USA: IEEE, 2016. 4165-4169 [86] Li C, Min X, Sun S Q, Lin W Q, Tang Z C. DeepGait:a learning deep convolutional representation for view-invariant gait recognition using joint Bayesian. Applied Sciences, 2017, 7(3):210 doi: 10.3390/app7030210 [87] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2015 International Conference on Pattern Recognition. California, USA: ICPR, 2015. 212-218 [88] Yu S Q, Chen H F, Wang Q, Shen L L, Huang Y Z. Invariant feature extraction for gait recognition using only one uniform model. Neurocomputing, 2017, 239:81-93 doi: 10.1016/j.neucom.2017.02.006 [89] Gers F A, Schraudolph N N, Schmidhuber J. Learning precise timing with LSTM recurrent networks. Journal of Machine Learning Research, 2002, 3:115-143 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=89ea080d0ed753eb233a54138e933da4 [90] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:The state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [91] Cao Z, Simon T, Wei S E, Sheikh Y. Realtime multi-person 2D pose estimation using part affinity fields. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: CCPR, 2017. 1302-1310 -

 下载:
下载:





计量
- 文章访问数: 3068
- HTML全文浏览量: 936
- PDF下载量: 1315
- 被引次数: 0
