

Saliency Detection via Full Convolution Neural Network and Low Rank Sparse Decomposition
-
摘要: 为了准确检测复杂背景下的显著区域,提出一种全卷积神经网络与低秩稀疏分解相结合的显著性检测方法,将图像分解为代表背景的低秩矩阵和对应显著区域的稀疏噪声,结合利用全卷积神经网络学习得到的高层语义先验知识,检测图像中的显著区域.首先,对原图像进行超像素聚类,并提取每个超像素的颜色、纹理和边缘特征,据此构成特征矩阵;然后,在MSRA数据库中,基于梯度下降法学习得到特征变换矩阵,利用全卷积神经网络学习得到高层语义先验知识;接着,利用特征变换矩阵和高层语义先验知识矩阵对特征矩阵进行变换;最后,利用鲁棒主成分分析算法对变换后的矩阵进行低秩稀疏分解,并根据分解得到的稀疏噪声计算显著图.在公开数据集上进行实验验证,并与当前流行的方法进行对比,实验结果表明,本文方法能够准确地检测感兴趣区域,是一种有效的自然图像目标检测与分割的预处理方法.Abstract: A unified saliency detection approach via the full convolution neural network (FCNN) and the low rank sparse decomposition is proposed to accurately detect the salient region in complex backgrounds. An image can be decomposed into a low rank matrix and sparse noise, indicating background and salient region, respectively. The high-level semantic prior knowledge learned by using the full convolution neural network is combined to detect the salient region in the image. Firstly, the original image is clustered into super pixels, and the feature matrix is constructed by extracting color, texture and edge features of each super pixel. Then, the feature transformation matrix is learned with the gradient descent method and the high-level semantic prior knowledge is learned with the full convolution neural network by using the MSRA database. Furthermore, the feature matrix is transformed using the feature transformation matrix and the high-level semantic prior knowledge matrix. Finally, the transformed feature matrix is decomposed into a low rank matrix and a sparse matrix by the robust principal component analysis method, and the saliency map is calculated according to the sparse matrix. The proposed method is compared with state-of-the-art algorithms on the open datasets. Experimental results demonstrate that the proposed algorithm can accurately detect the region of interest, which is an effective preprocessing means for object detection and segmentation of natural images.
-
Key words:
- Saliency detection /
- full convolution neural network (FCNN) /
- low rank sparse decomposition /
- high-level semantic prior knowledge
-
近年来, 基于随机有限集的多目标跟踪算法[1-2]引起了学者们的广泛关注.它从集值估计的角度来解决多目标跟踪问题, 避免了传统多目标跟踪算法中复杂的数据关联过程.众所周知, 数据关联一直是多目标跟踪问题的一个难点, 尤其是在目标个数较多且存在杂波的情况下, 关联过程将变得非常复杂.基于随机有限集的多目标跟踪算法利用随机有限集对多目标的状态和观测建模, 在贝叶斯滤波框架下通过递推后验多目标密度来解决多目标跟踪问题.该类算法主要包括概率假设密度(Probability hypothesis density, PHD)滤波器[3-5]、势概率假设密度(Cardinality PHD, CPHD)滤波器[6-7]和势均衡多目标多伯努利(Cardinality balanced multi-target multi-Bernoulli, CBMeMBer)滤波器[8].不同于PHD和CPHD滤波器递推多目标密度的强度和势分布估计, CBMeMBer滤波器直接近似递推后验多目标密度, 使得多目标跟踪问题的求解显得更为直观.随后, 学者们对CBMeMBer滤波器进行了深入地研究, 并取得了一些研究成果[9-13].
基于随机有限集的多目标跟踪算法主要包括高斯混合(Gaussian mixture, GM)和序贯蒙特卡洛(Sequential Monte Carlo, SMC)两种实现方法.这两种实现方法的前提条件是目标的状态和观测模型为隐马尔科夫模型(Hidden Markov model, HMM), 即目标的状态演化过程是一个马尔科夫过程, 而k时刻目标的量测只与当前时刻目标的状态有关.但在实际应用中, 目标模型不一定满足HMM隐含的马尔科夫假设和独立性假设条件.例如过程噪声与量测噪声相关或量测噪声为有色噪声的情况[14].文献[15-18]等提出一种比HMM更为一般化的Pairwise马尔科夫模型(Pairwise Markov model, PMM), 它将目标的状态和量测整体看作一个马尔科夫过程.与HMM的区别在于: 1)目标的状态不一定为马尔科夫过程; 2)目标的量测不仅与当前时刻的状态有关, 而且与该目标上一时刻的量测也有关系[15].因此, 在解决一些实际问题时采用PMM比采用HMM的效果更好.例如在分割问题中, 采用PMM代替HMM可以有效地降低误差率[19].
本文的研究目的是在PMM框架下利用随机有限集解决杂波环境下的多目标跟踪问题.文献[[20-21]已经给出了在PMM框架下的PHD滤波器及其GM实现.但是当目标数较多时, 该滤波器对目标个数的估计会出现欠估计的情况, 且估计精度和效率较差.本文给出了PMM框架下CBMeMBer滤波器的递推过程, 并给出它在线性高斯PMM条件下的GM实现.最后, 采用文献[21]提出的一种满足HMM局部物理特性的线性高斯PMM, 将本文所提算法与GM-PMM-PHD滤波器进行比较.实验结果表明, 本文所提算法对目标数的估计是无偏的, 不存在GM-PMM-PHD滤波器在目标数较多时出现欠估计的情况, 并且本文所提算法的估计精度和效率也优于GM-PMM-PHD滤波器.
1. HMM和PMM
1.1 HMM
在信号处理过程中, 一个重要问题是根据可观测的量测$y\!=\!{{\left\{ {{\mathit{\boldsymbol{y}}}_{k}} \right\}}_{k\in \rm{IN}}}$估计不可观测的状态$x\!=\!{{\left\{ {{\mathit{\boldsymbol{x}}}_{k}} \right\}}_{k\in \rm{IN}}}$, IN表示整数.在HMM中, 假设x为马尔科夫过程, 且k时刻的量测${{\mathit{\boldsymbol{y}}}_{k}}$只与当前时刻的状态${{\mathit{\boldsymbol{x}}}_{k}}$有关, 即[15]
\begin{equation}\label{} p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{0:k-1}} \right)=p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}} \right) \end{equation}
(1) \begin{equation}\label{} p\left( {{\mathit{\boldsymbol{y}}}_{0:k}}|{{\mathit{\boldsymbol{x}}}_{0:k}} \right)=\prod\limits_{i=0}^{k}{p\left( {{\mathit{\boldsymbol{y}}}_{i}}|{{\mathit{\boldsymbol{x}}}_{0:k}} \right)} \end{equation}
(2) \begin{equation}\label{} p\left( {{\mathit{\boldsymbol{y}}}_{i}}|{{\mathit{\boldsymbol{x}}}_{0:k}} \right)=p\left( {{\mathit{\boldsymbol{y}}}_{i}}|{{\mathit{\boldsymbol{x}}}_{i}} \right), \quad 0\le i\le k \end{equation}
(3) $p\left( \cdot \right)$表示概率密度函数.状态${{\mathit{\boldsymbol{x}}}_{k}}$的后验概率密度$p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)$可由Bayes递推算法得到[22]:
\begin{equation}\label{} p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k-1}} \right)=\!\int\!{p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}} \right)p\left( {{\mathit{\boldsymbol{x}}}_{k-1}}|{{\mathit{\boldsymbol{y}}}_{0:k-1}} \right){\rm d}{{\mathit{\boldsymbol{x}}}_{k-1}}} \end{equation}
(4) \begin{equation}\label{} p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)\propto p\left( {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k}} \right)p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k-1}} \right) \end{equation}
(5) 在实际应用中, 由于Bayes公式中存在积分运算, 通常不能得到它的解析解.为了使Bayes公式能够递推运算, 考虑如下线性HMM
\begin{equation}\label{} {{\mathit{\boldsymbol{x}}}_{k}}={{F}_{k}}{{\mathit{\boldsymbol{x}}}_{k-1}}+{{\mathit{\boldsymbol{u}}}_{k}} \end{equation}
(6) \begin{equation}\label{} {{\mathit{\boldsymbol{y}}}_{k}}={{H}_{k}}{{\mathit{\boldsymbol{x}}}_{k}}+{{\mathit{\boldsymbol{v}}}_{k}} \end{equation}
(7) ${{F}_{k}}$和${{H}_{k}}$分别表示状态转移矩阵和观测矩阵. ${{\mathit{\boldsymbol{u}}}_{k}}$和${{\mathit{\boldsymbol{v}}}_{k}}$分别表示零均值的过程噪声和量测噪声, 与初始状态${{\mathit{\boldsymbol{x}}}_{0}}$相互独立.若${{\mathit{\boldsymbol{v}}}_{k}}$、${{\mathit{\boldsymbol{u}}}_{k}}$和${{\mathit{\boldsymbol{x}}}_{0}}$均为高斯变量, 则状态${{\mathit{\boldsymbol{x}}}_{k}}$的后验概率密度$p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)$为高斯分布, 可以用它的均值和协方差描述.此时, $p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)$的Bayes递推过程退化为经典的卡尔曼滤波器[23].
1.2 PMM
在过程噪声与量测噪声相关或量测噪声为有色噪声的情况下, 目标模型不满足HMM隐含的马尔科夫假设和独立性假设条件.此时, 再利用HMM建模是不合适的.文献[15]提出一种比HMM更为一般化的PMM, 它将状态和量测整体$\varepsilon \!=\!\left( x, y \right)$看作马尔科夫过程, 即
\begin{equation}\label{} p\left( {{\mathit{\boldsymbol{\varepsilon }}}_{k}}|{{\mathit{\boldsymbol{\varepsilon }}}_{0:k-1}} \right)=p\left( {{\mathit{\boldsymbol{\varepsilon }} }_{k}}|{{\mathit{\boldsymbol{\varepsilon }} }_{k-1}} \right)=p\left( {{\mathit{\boldsymbol{x}}}_{k}}, {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}}, {{\mathit{\boldsymbol{y}}}_{k-1}} \right) \end{equation}
(8) 可以有效地处理上述复杂的目标跟踪场景.
在PMM中, x不一定为马尔科夫过程, 且${{\mathit{\boldsymbol{y}}}_{k}}$不仅与当前时刻的状态${{\mathit{\boldsymbol{x}}}_{k}}$有关, 同时与${{\mathit{\boldsymbol{x}}}_{k-1}}$和${{\mathit{\boldsymbol{y}}}_{k-1}}$也有关系.当$p\left( {{\mathit{\boldsymbol{x}}}_{k}}, {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}}, {{\mathit{\boldsymbol{y}}}_{k-1}} \right)$满足
\begin{equation}\label{} p\left( {{\mathit{\boldsymbol{x}}}_{k}}, {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}}, {{\mathit{\boldsymbol{y}}}_{k-1}} \right)=p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}} \right)p\left( {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k}} \right) \end{equation}
(9) 时, PMM就退化为HMM, 即HMM是PMM的一种特殊情况.在PMM框架下, 状态${{\mathit{\boldsymbol{x}}}_{k}}$的后验概率密度$p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)$的Bayes公式为[15]
\begin{equation}\label{} p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{y}}}_{0:k}} \right)\propto \int{p\left( {{\mathit{\boldsymbol{\varepsilon }}}_{k}}|{{\mathit{\boldsymbol{\varepsilon }} }_{k-1}} \right)p\left( {{\mathit{\boldsymbol{x}}}_{k-1}}|{{\mathit{\boldsymbol{y}}}_{0:k-1}} \right){\rm d}{{\mathit{\boldsymbol{x}}}_{k-1}}} \end{equation}
(10) 与HMM框架下的Bayes递推算法的不同之处在于它采用$p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}}, {{\mathit{\boldsymbol{y}}}_{k-1}} \right)$和$p\left( {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k}}, {{\mathit{\boldsymbol{x}}}_{k-1}}, {{\mathit{\boldsymbol{y}}}_{k-1}} \right)$分别代替$p\left( {{\mathit{\boldsymbol{x}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k-1}} \right)$和$p\left( {{\mathit{\boldsymbol{y}}}_{k}}|{{\mathit{\boldsymbol{x}}}_{k}} \right)$.同样, 上式没有解析解.
在线性高斯条件下, PMM模型可以描述为
\begin{equation}\label{} \underbrace{\left[\begin{matrix} {{\mathit{\boldsymbol{x}}}_{k}} \\ {{\mathit{\boldsymbol{y}}}_{k}} \\ \end{matrix} \right]}_{{{\mathit{\boldsymbol{\varepsilon }}}_{k}}}=\underbrace{\left[\begin{matrix} F_{k}^{1}&F_{k}^{2} \\ H_{k}^{1}&H_{k}^{2} \\ \end{matrix} \right]}_{{{B}_{k}}}\underbrace{\left[\begin{matrix} {{\mathit{\boldsymbol{x}}}_{k-1}} \\ {{\mathit{\boldsymbol{y}}}_{k-1}} \\ \end{matrix} \right]}_{{{\mathit{\boldsymbol{\varepsilon }} }_{k-1}}}+{{\mathit{\boldsymbol{w}}}_{k}} \end{equation}
(11) 其中, ${{\left\{ {{\mathit{\boldsymbol{w}}}_{k}} \right\}}_{k\in \rm{IN}}}$表示零均值的高斯白噪声, 它的协方差为
\begin{equation}\label{} {\rm{E}}\left( {{\mathit{\boldsymbol{w}}}_{k}}\mathit{\boldsymbol{w}}_{k}^{\rm{T}} \right)={{\Sigma }_{k}}=\left[\begin{matrix} \Sigma _{k}^{11}&\Sigma _{k}^{12} \\ \Sigma _{k}^{21}&\Sigma _{k}^{22} \\ \end{matrix} \right] \end{equation}
(12) ${{\left\{ {{\mathit{\boldsymbol{w}}}_{k}} \right\}}_{k\in \rm{IN}}}$与初始状态${{\mathit{\boldsymbol{\varepsilon }}}_{0}}$相互独立. ${{\mathit{\boldsymbol{\varepsilon }} }_{0}}$服从正态分布N$\left( \cdot ;{{\mathit{\boldsymbol{m}}}_{0}}, {{P}_{0}} \right)$, ${{\mathit{\boldsymbol{m}}}_{0}}$和${{P}_{0}}$分别表示它的均值和协方差.文献[15]给出了在PMM框架下的卡尔曼滤波器.
2. PMM-CBMeMBer滤波器及其GM实现
文献[8]已经给出在HMM框架下CBMeMBer滤波器的递推过程, 这里不再赘述.下面将直接给出在PMM框架下CBMeMBer滤波器的递推过程, 以及它在线性高斯PMM条件下的GM实现.
2.1 PMM-CBMeMBer滤波器
k时刻监控区域内${{M}_{k}}$个目标的状态集合记为${{X}_{k}}\!\!=\!\!\left\{ \mathit{\boldsymbol{\varepsilon }} _{k}^{\left( i \right)} \right\}_{i=1}^{{{M}_{k}}}$, 其中${{\mathit{\boldsymbol{\varepsilon }}}_{k}}\!\!=\!\!{{\left[\mathit{\boldsymbol{x}}_{k}^{\rm{T}}, \mathit{\boldsymbol{y}}_{k}^{\rm{T}} \right]}^{\rm{T}}}$, ${\mathit{\boldsymbol{x}}_{k}}$和${\mathit{\boldsymbol{y}}_{k}}$分别表示目标的动力学状态和量测.在PMM框架下, $\varepsilon $是一个马尔科夫过程, 它的状态转移概率密度$p\left( {{\mathit{\boldsymbol{\varepsilon }} }_{k}}|{{\mathit{\boldsymbol{\varepsilon }} }_{k-1}} \right)$包含目标的动力学演化模型$p\left( {\mathit{\boldsymbol{x}}_{k}}|{\mathit{\boldsymbol{x}}_{k-1}}, {\mathit{\boldsymbol{y}}_{k-1}} \right)$和传感器的量测模型$p\left( {\mathit{\boldsymbol{y}}_{k}}|{\mathit{\boldsymbol{x}}_{k}}, {\mathit{\boldsymbol{x}}_{k-1}}, {\mathit{\boldsymbol{y}}_{k-1}} \right)$.根据目标的物理特性, 假设目标的存活概率仅与目标的动力学状态有关, 记为${{p}_{s, k}}\left( {\mathit{\boldsymbol{x}}_{k}} \right)$.
k时刻传感器的量测集合记为${{Z}_{k}}\!=\!\left\{ \mathit{\boldsymbol{z}}_{k}^{\left( i \right)} \right\}_{i=1}^{{{N}_{k}}}$, ${{N}_{k}}$表示量测的个数. ${{Z}_{k}}$由源于目标的量测和杂波量测构成, 两者不可区分.根据传感器的物理特性, 假设传感器的检测概率仅与目标的动力学状态有关, 记为${{p}_{d, k}}\left( {\mathit{\boldsymbol{x}}_{k}} \right)$.
在满足如下假设条件下:
1) ${\varepsilon}$为马尔科夫过程, 目标之间相互独立;
2) 新生目标为多伯努利随机有限集, 与存活目标相互独立;
3) 杂波量测与目标产生的量测相互独立, 杂波数服从泊松分布.
PMM-CBMeMBer滤波器的递推过程如下:
步骤1.预测步
假设$k-1$时刻后验多目标密度为多伯努利形式:
\begin{equation}\label{} {{\pi }_{k-1}}=\left\{ \left( r_{k-1}^{\left( i \right)}, p_{k-1}^{\left( i \right)} \right) \right\}_{i=1}^{{{M}_{k-1}}} \end{equation}
(13) $r_{k-1}^{\left( i \right)}\in \left[0, 1 \right]$, 表示$k-1$时刻第i个目标的存在概率, $p_{k-1}^{\left( i \right)}\left( {\mathit{\boldsymbol{\varepsilon }}_{i}} \right)$表示${\mathit{\boldsymbol{\varepsilon }}_{i}}$的概率密度, ${{M}_{k-1}}$表示$k-1$时刻可能出现的最大目标数.则预测多目标密度也为多伯努利形式:
\begin{equation}\label{} {{\pi }_{k|k-1}}\!\!=\!\!\left\{ \!\left( \!r_{P, k|k-1}^{\left( i \right)}, p_{P, k|k-1}^{\left( i \right)} \!\right) \!\right\}_{i=1}^{{{M}_{k-1}}}\!\!\bigcup\! \left\{ \!\left( \!r_{\Gamma, k}^{\left( i \right)}, p_{\Gamma, k}^{\left( i \right)} \!\right) \!\right\}_{i=1}^{{{M}_{\Gamma, k}}} \end{equation}
(14) 前一项表示存活目标的密度, 后一项表示k时刻新生目标的密度.
\begin{equation}\label{} r_{P, k|k-1}^{\left( i \right)}=r_{k-1}^{\left( i \right)}\left\langle p_{k-1}^{\left( i \right)}, {{p}_{s, k}} \right\rangle \end{equation}
(15) \begin{equation}\label{} p_{P, k|k-1}^{\left( i \right)}\left( \mathit{\boldsymbol{\varepsilon }} \right)=\frac{\left\langle {{p}_{k|k-1}}\left( \mathit{\boldsymbol{\varepsilon }} |\cdot \right), p_{k-1}^{\left( i \right)}{{p}_{s, k}} \right\rangle }{\left\langle p_{k-1}^{\left( i \right)}, {{p}_{s, k}} \right\rangle } \end{equation}
(16) $\left\langle \cdot, \cdot \right\rangle $表示内积运算, 如$\left\langle \alpha, \beta \right\rangle =\int{\alpha \left( x \right)\beta \left( x \right){\rm d}x}$.
步骤2.更新步
假设k时刻预测多目标密度为多伯努利形式
\begin{equation}\label{} {{\pi }_{k|k-1}}=\left\{ \left( r_{k|k-1}^{\left( i \right)}, p_{k|k-1}^{\left( i \right)} \right) \right\}_{i=1}^{{{M}_{k|k-1}}} \end{equation}
(17) 则后验多目标密度可由如下多伯努利形式近似
\begin{equation}\label{} {{\pi }_{k}}\!\approx \!\left\{ \!\left( r_{L, k}^{\left( i \right)}, p_{L, k}^{\left( i \right)} \right) \!\right\}_{i=1}^{{{M}_{k|k-1}}}\!\!\bigcup\! {{\left\{ \!\left( {{r}_{U, k}}\left( \mathit{\boldsymbol{z}} \right)\!, {{p}_{U, k}}\!\left( \cdot ;\mathit{\boldsymbol{z}} \right)\! \right) \!\right\}}_{\mathit{\boldsymbol{z}}\in {{Z}_{k}}}} \end{equation}
(18) 前一项表示漏检部分的多目标密度, 后一项表示量测更新部分的多目标密度.
\begin{equation}\label{} r_{L, k}^{\left( i \right)}=r_{k|k-1}^{\left( i \right)}\frac{1-\left\langle p_{k|k-1}^{\left( i \right)}, {{p}_{d, k}} \right\rangle }{1-r_{k|k-1}^{\left( i \right)}\left\langle p_{k|k-1}^{\left( i \right)}, {{p}_{d, k}} \right\rangle } \end{equation}
(19) \begin{equation}\label{} p_{L, k}^{\left( i \right)}\left( \mathit{\boldsymbol{\varepsilon }} \right)=p_{k|k-1}^{\left( i \right)}\left( \mathit{\boldsymbol{\varepsilon }} \right)\frac{1-{{p}_{d, k}}\left( \mathit{\boldsymbol{x}} \right)}{1-\left\langle p_{k|k-1}^{\left( i \right)}, {{p}_{d, k}} \right\rangle } \end{equation}
(20) \begin{equation}\label{} {{r}_{U, k}}\left( \mathit{\boldsymbol{z}} \right)\!=\!\frac{\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}\left( 1-r_{k|k-1}^{\left( i \right)} \right)\left\langle p_{k|k-1}^{\left( i \right)}, {{\psi }_{k, \mathit{\boldsymbol{z}}}} \right\rangle }{{{\left( 1-r_{k|k-1}^{\left( i \right)}\left\langle p_{k|k-1}^{\left( i \right)}, {{p}_{d, k}} \right\rangle \right)}^{2}}}}}{{{\kappa }_{k}}\left( \mathit{\boldsymbol{z}} \right)\!+\!\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}\left\langle p_{k|k-1}^{\left( i \right)}, {{\psi }_{k, \mathit{\boldsymbol{z}}}} \right\rangle }{1-r_{k|k-1}^{\left( i \right)}\left\langle p_{k|k-1}^{\left( i \right)}, {{p}_{d, k}} \right\rangle }}} \end{equation}
(21) \begin{equation}\label{} {{p}_{U, k}}\left( \mathit{\boldsymbol{\varepsilon }} ;\mathit{\boldsymbol{z}} \right)\!=\!\frac{\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}}{1-r_{k|k-1}^{\left( i \right)}}p_{k|k-1}^{\left( i \right)}\left( \mathit{\boldsymbol{\varepsilon }} \right){{\psi }_{k, \mathit{\boldsymbol{z}}}}\left( \mathit{\boldsymbol{\varepsilon }} \right)}}{\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}}{1-r_{k|k-1}^{\left( i \right)}}\left\langle p_{k|k-1}^{\left( i \right)}{{\psi }_{k, \mathit{\boldsymbol{z}}}} \right\rangle }} \end{equation}
(22) ${{\psi }_{k, \mathit{\boldsymbol{z}}}}\left( \mathit{\boldsymbol{\varepsilon }} \right)={{p}_{d, k}}\left( \mathit{\boldsymbol{x}} \right){g_k}\left( {\mathit{\boldsymbol{z}}|\mathit{\boldsymbol{x}}} \right)$
${{\kappa }_{k}}\left( \cdot \right)$表示k时刻杂波的强度, ${g_k}\left( {\mathit{\boldsymbol{z}}|\mathit{\boldsymbol{x}}} \right)$表示目标$\mathit{\boldsymbol{x}}$的似然函数.
在上述递推过程中, 若状态转移函数${{p}_{k|k-1}}$满足式(9), 并且新生目标模型满足:
\begin{equation}\label{} {{\gamma }_{\Gamma, k}}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)={{g}_{k}}\left( \mathit{\boldsymbol{y}}|\mathit{\boldsymbol{x}} \right){{\tilde{\gamma }}_{\Gamma, k}}\left( \mathit{\boldsymbol{x}} \right) \end{equation}
(23) ${{\tilde{\gamma }}_{\Gamma, k}}\left( \mathit{\boldsymbol{x}} \right)$表示仅与目标动力学状态相关的新生目标密度函数.此时, PMM-CBMeMBer滤波算法就退化为HMM-CBMeMBer滤波算法.
2.2 PMM-CBMeMBer滤波器的GM实现
下面给出PMM-CBMeMBer滤波器在线性高斯条件下的GM实现.
在新生目标模型中, 若$p_{\Gamma, k}^{\left( i \right)}$为GM形式:
\begin{equation}\label{} p_{\Gamma, k}^{\left( i \right)}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)\!=\!\sum\limits_{j=1}^{J_{\Gamma, k}^{\left( i \right)}}{\omega _{\Gamma, k}^{\left( i, j \right)}N\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{m}}_{\Gamma, k}^{\left( i, j \right)}, P_{\Gamma, k}^{\left( i, j \right)} \right)} \end{equation}
(24) 其中, $J_{\Gamma, k}^{\left( i \right)}$表示第i个目标对应的高斯项个数, $\omega _{\Gamma , k}^{\left( i, j \right)}$、$\mathit{\boldsymbol{m}}_{\Gamma, k}^{\left( i, j \right)}$和$P_{\Gamma, k}^{\left( i, j \right)}$分别表示第i个目标中第j个高斯项的权重、均值和协方差.则GM-PMM-CBMeMBer滤波器的递推过程如下:
步骤1.预测步
假设$k-1$时刻后验多目标密度
\begin{equation}\label{} {{\pi }_{k-1}}\!=\!\left\{\! \left( r_{k-1}^{1, \left( i \right)}, p_{k-1}^{1, \left( i \right)} \right)\! \right\}_{i=1}^{M_{k-1}^{1}}\!\bigcup\! \left\{\! \left( r_{k-1}^{2, \left( i \right)}, p_{k-1}^{2, \left( i \right)} \right)\! \right\}_{i=1}^{M_{k-1}^{2}} \end{equation}
(25) 已知, $p_{k-1}^{\ell, \left( i \right)}$, $\ell =\left\{ 1, 2 \right\}$, 为如下GM形式,
\begin{equation}\label{} p_{k-1}^{1, \left( i \right)}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)=\sum\limits_{j=1}^{J_{k-1}^{1, \left( i \right)}}{\omega _{k-1}^{1, \left( i, j \right)}{\rm N}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{m}}_{k-1}^{1, \left( i, j \right)}, P_{k-1}^{1, \left( i, j \right)} \right)} \end{equation}
(26) \begin{equation}\label{} p_{k-1}^{2, \left( i \right)}\!\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)\!=\!\!\sum\limits_{j=1}^{J_{k-1}^{2, \left( i \right)}}\!{\omega _{k-1}^{2, \left( i, j \right)}\!{\rm N}\!\!\left( \!\mathit{\boldsymbol{x}};\mathit{\boldsymbol{m}}_{k-1}^{2, \left( i, j \right)}\!, P_{k-1}^{2, \left( i, j \right)} \!\right)\!{{\delta }_{{{\mathit{\boldsymbol{z}}}^{\left( i \right)}}}}\!\left( \mathit{\boldsymbol{y}} \right)} \end{equation}
(27) ${{\delta }_{{{\mathit{\boldsymbol{z}}}^{\left( i \right)}}}}\!\left( \mathit{\boldsymbol{y}} \right)$为Dirac delta函数[2], ${{\mathit{\boldsymbol{z}}}^{\left( i \right)}}\in {{Z}_{k-1}}$, ${\mathit{\boldsymbol{y}}}$表示状态为${\mathit{\boldsymbol{x}}}$对应的量测.若${{\mathit{\boldsymbol{z}}}^{\left( i \right)}}=\mathit{\boldsymbol{y}}$, 说明${{\mathit{\boldsymbol{z}}}^{\left( i \right)}}$是由$\mathit{\boldsymbol{x}}$产生的量测; 否则, $\mathit{\boldsymbol{z}}^{\left( i \right)}$不是由${\mathit{\boldsymbol{x}}}$产生的量测.则预测多目标密度
\begin{align} {\pi _{k|k - 1}} \!=&\! \left\{ {\!\left( {r_{P, k|k - 1}^{1, \left( i \right)}, p_{P, k|k - 1}^{1, \left( i \right)}} \right)} \!\right\}_{i = 1}^{M_{k - 1}^1} \cup \nonumber\\ &\left\{ {\!\left( {r_{P, k|k - 1}^{2, \left( i \right)}, p_{P, k|k - 1}^{2, \left( i \right)}} \right)} \!\right\}_{i = 1}^{M_{k - 1}^2} \!\cup\!\nonumber\\ &\left\{ {\!\left( {r_{\Gamma, k}^{\left( i \right)}, p_{\Gamma, k}^{\left( i \right)}} \right)} \!\right\}_{i = 1}^{{M_{\Gamma, k}}} \end{align}
(28) 可由如下公式得到:
\begin{align} &r_{P, k|k-1}^{\ell, \left( i \right)}={{p}_{s, k}}r_{k-1}^{\ell , \left( i \right)}, \quad \ell =\left\{ 1, 2 \right\} \end{align}
(29) \begin{align} &p_{P, k|k-1}^{1, \left( i \right)}\!\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)\!=\nonumber\\ &\qquad\sum\limits_{j=1}^{J_{k-1}^{1, \left( i \right)}}\!\!{\omega _{k-1}^{1, \left( i, j \right)}\!{\rm N}\!\!\left(\! \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{m}}_{P, k|k-1}^{1, \left( i, j \right)}, P_{P, k|k-1}^{1, \left( i, j \right)} \!\right)}\end{align}
(30) \begin{align} &p_{P, k|k-1}^{2, \left( i \right)}\!\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)\!=\nonumber\\ &\qquad\sum\limits_{j=1}^{J_{k-1}^{2, \left( i \right)}}\!\!{\omega _{k-1}^{2, \left( i, j \right)}\!{\rm N}\!\!\left( \!\mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{m}}_{P, k|k-1}^{2, \left( i, j \right)}, P_{P, k|k-1}^{2, \left( i, j \right)} \!\right)} \end{align}
(31) 其中
\begin{equation}\label{} \mathit{\boldsymbol{m}}_{P, k|k-1}^{1, \left( i, j \right)}\!=\!{{B}_{k}}\mathit{\boldsymbol{m}}_{k-1}^{1, \left( i, j \right)}, \mathit{\boldsymbol{m}}_{P, k|k-1}^{2, \left( i, j \right)}\!=\!{{B}_{k}}\!\left[\begin{matrix} \mathit{\boldsymbol{m}}_{k-1}^{2, \left( i, j \right)} \\ {{\mathit{\boldsymbol{z}}}^{\left( i \right)}} \\ \end{matrix} \right] \end{equation}
(32) \begin{equation}\label{} P_{P, k|k-1}^{1, \left( i, j \right)}={{\Sigma }_{k}}+{{B}_{k}}P_{k-1}^{1, \left( i, j \right)}B_{k}^{\rm{T}} \end{equation}
(33) \begin{equation}\label{} P_{P, k|k-1}^{2, \left( i, j \right)}={{\Sigma }_{k}}+\left[\begin{matrix} F_{k}^{1} \\ H_{k}^{1} \\ \end{matrix} \right]P_{k-1}^{2, \left( i, j \right)}\left[\begin{matrix} {{\left( F_{k}^{1} \right)}^{\rm{T}}}&{{\left( H_{k}^{1} \right)}^{\rm{T}}} \\ \end{matrix} \right] \end{equation}
(34) 新生目标模型已知, $p_{\Gamma, k}^{\left( i \right)}$见式(24).
步骤2.更新步
在式(28)中, 由于组成预测多目标密度的三个部分形式相同, 令${{M}_{k|k-1}}=M_{k-1}^{1}+M_{k-1}^{2}+{{M}_{\Gamma, k}}$, 它们可以重写为
\begin{equation}\label{} {{\pi }_{k|k-1}}=\left\{ \left( r_{k|k-1}^{\left( i \right)}, p_{k|k-1}^{\left( i \right)} \right) \right\}_{i=1}^{{{M}_{k|k-1}}} \end{equation}
(35) \begin{equation}\label{} p_{k|k-1}^{\left( i \right)}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)\!=\!\sum\limits_{j=1}^{J_{k|k-1}^{\left( i \right)}}\!{\omega _{k|k-1}^{\left( i, j \right)}{\rm N}\!\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{m}}_{k|k-1}^{\left( i, j \right)}, P_{k|k-1}^{\left( i, j \right)} \right)} \end{equation}
(36) \begin{equation}\label{} \mathit{\boldsymbol{m}}_{k|k-1}^{\left( i, j \right)}\!=\!\left[\begin{matrix} \mathit{\boldsymbol{m}}_{k|k-1}^{\mathit{\boldsymbol{x}}, \left( i, j \right)} \\ \mathit{\boldsymbol{m}}_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)} \\ \end{matrix} \right]\!, P_{k|k-1}^{\left( i, j \right)}\!=\!\left[\begin{matrix} P_{k|k-1}^{\mathit{\boldsymbol{x}}, \left( i, j \right)} \!&\! P_{k|k-1}^{\mathit{\boldsymbol{xy}}, \left( i, j \right)} \\ P_{k|k-1}^{\mathit{\boldsymbol{yx}}, \left( i, j \right)} \!&\! P_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)} \\ \end{matrix} \right] \end{equation}
(37) 则更新多目标密度
\begin{align} {{\pi }_{k}}\!=&\!\left\{ \!\left( r_{L, k}^{\left( i \right)}, p_{L, k}^{\left( i \right)} \right) \!\right\}_{i=1}^{{{M}_{k|k-1}}}\!\bigcup\!\nonumber\\&{{\left\{ \!\left( {{r}_{U, k}}\!\left( \mathit{\boldsymbol{z}} \right)\!, {{p}_{U, k}}\!\left( \cdot ;\mathit{\boldsymbol{z}} \right) \right) \!\right\}}_{\mathit{\boldsymbol{z}}\in {{Z}_{k}}}} \end{align}
(38) 可由如下公式得到:
\begin{equation}\label{} r_{L, k}^{\left( i \right)}=r_{k|k-1}^{\left( i \right)}\frac{1-{{p}_{d, k}}}{1-r_{k|k-1}^{\left( i \right)}{{p}_{d, k}}} \end{equation}
(39) \begin{equation}\label{} p_{L, k}^{\left( i \right)}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right)=p_{k|k-1}^{\left( i \right)}\left( \mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}} \right) \end{equation}
(40) \begin{equation}\label{} {{r}_{U, k}}\left( \mathit{\boldsymbol{z}} \right)=\frac{\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}\left( 1-r_{k|k-1}^{\left( i \right)} \right)\rho _{U, k}^{\left( i \right)}\left( \mathit{\boldsymbol{z}} \right)}{{{\left( 1-r_{k|k-1}^{\left( i \right)}{{p}_{d, k}} \right)}^{2}}}}}{{{\kappa }_{k}}\left( \mathit{\boldsymbol{z}} \right)+\sum\limits_{i=1}^{{{M}_{k|k-1}}}{\frac{r_{k|k-1}^{\left( i \right)}\rho _{U, k}^{\left( i \right)}\left( \mathit{\boldsymbol{z}} \right)}{1-r_{k|k-1}^{\left( i \right)}{{p}_{d, k}}}}} \end{equation}
(41) \begin{equation}\label{} {p_{U, k}}\!\left( \!{\mathit{\boldsymbol{x}}, \mathit{\boldsymbol{y}};\mathit{\boldsymbol{z}}} \!\right)\! =\! \frac{{\sum\limits_{i = 1}^{{M_{k|k - 1}}}\! {\sum\limits_{j = 1}^{J_{k|k - 1}^{\left( i \right)}} \!\!{\omega _{U, k}^{\left( {i, j} \right)}\!\!\left( \mathit{\boldsymbol{z}} \right)\!{\rm N}\!\!\left( \! {\mathit{\boldsymbol{x}};\mathit{\boldsymbol{m}}_{U, k}^{\left( {i, j} \right)}\!, P_{U, k}^{\left( {i, j} \right)}} \!\right)} } }}{{\sum\limits_{i = 1}^{{M_{k|k - 1}}} {\sum\limits_{j = 1}^{J_{k|k - 1}^{\left( i \right)}} {\omega _{U, k}^{\left( {i, j} \right)}\left( \mathit{\boldsymbol{z}} \right)} } }} \end{equation}
(42) 其中
\begin{equation}\label{} \rho _{U, k}^{\left( i \right)}\left( \mathit{\boldsymbol{z}} \right)={{p}_{d, k}}\sum\limits_{j=1}^{J_{k|k-1}^{\left( i \right)}}{\omega _{k|k-1}^{\left( i, j \right)}q_{k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}} \right)} \end{equation}
(43) \begin{equation}\label{} q_{k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}} \right)={\rm N}\left( \mathit{\boldsymbol{z}};\mathit{\boldsymbol{m}}_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)}, P_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)} \right) \end{equation}
(44) \begin{equation}\label{} \omega _{U, k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}} \right)=\frac{r_{k|k-1}^{\left( i \right)}}{1-r_{k|k-1}^{\left( i \right)}}{{p}_{d, k}}\omega _{k|k-1}^{\left( i, j \right)}q_{k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}} \right) \end{equation}
(45) \begin{equation}\label{} \mathit{\boldsymbol{m}}_{U, k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}} \right)=\mathit{\boldsymbol{m}}_{k|k-1}^{\mathit{\boldsymbol{x}}, \left( i, j \right)}+K_{U, k}^{\left( i, j \right)}\left( \mathit{\boldsymbol{z}}-\mathit{\boldsymbol{m}}_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)} \right) \end{equation}
(46) \begin{equation}\label{} P_{U, k}^{\left( i, j \right)}=P_{k|k-1}^{\mathit{\boldsymbol{x}}, \left( i, j \right)}-K_{U, k}^{\left( i, j \right)}{{\left( P_{k|k-1}^{\mathit{\boldsymbol{xy}}, \left( i, j \right)} \right)}^{\rm{T}}} \end{equation}
(47) \begin{equation}\label{} K_{U, k}^{\left( i, j \right)}=P_{k|k-1}^{\mathit{\boldsymbol{xy}}, \left( i, j \right)}{{\left( P_{k|k-1}^{\mathit{\boldsymbol{y}}, \left( i, j \right)} \right)}^{-1}} \end{equation}
(48) 在更新步中, 漏检部分的状态包括动力学状态和相应的量测, 协方差也是动力学状态和量测整体的协方差; 量测更新部分给出了动力学状态的求解, 式(46)中的$\mathit{\boldsymbol{z}}$表示该动力学状态对应的量测, 式(47)为目标动力学状态的协方差, 不包括量测以及量测与动力学状态的协方差.即算法中漏检部分和量测更新部分对应的多目标密度的表示形式不同, 故在$k-1$时刻将多目标密度假设为相应的两部分.
根据GM-HMM-PHD滤波器得到的后验多目标强度的高斯项个数[5], 不难得到在不考虑衍生目标的情况下GM-HMM-CBMeMBer滤波器的后验多目标密度的高斯项个数为$\left(\! \sum\nolimits_{i=1}^{{{M}_{k-1}}}\!\!{J_{k-1}^{\left( i \right)}}\!+\!\sum\nolimits_{i=1}^{{{M}_{\Gamma, k}}}\!\!{J_{\Gamma , k}^{\left( i \right)}} \!\right)\!\left( \!1\!+\!\left| {{Z}_{k}} \right|\! \right)$, GM-PMM-CBMeMBer滤波器的后验多目标密度的高斯项个数为$\left( \! \sum\nolimits_{i=1}^{M_{k-1}^{1}}\!\!{J_{k-1}^{1, \left( i \right)}}\!+\!\sum\nolimits_{i=1}^{M_{k-1}^{2}}\!\!{J_{k-1}^{2, \left( i \right)}}\!+\!\sum\nolimits_{i=1}^{{{M}_{\Gamma , k}}}\!\!{J_{\Gamma, k}^{\left( i \right)}} \!\right)\!$ $(\! 1\!+\!| {{Z}_{k}} | \!)$.在相同场景下, GM-PMM-CBMeMBer滤波器和GM-HMM-CBMeMBer滤波器的计算复杂度为同一数量级.但由于GM-PMM-CBMeMBer滤波器状态维数的增加, 计算量会相应增大.
由于新生目标的出现和更新步中假设轨迹的平均化, 航迹个数和每条航迹对应的高斯项会逐渐增加, 需要采用剪切和合并技术[5]进行处理: 1)剪切.一是航迹的剪切, 去掉存在概率小于阈值为${{T}_{r}}$的航迹; 二是航迹对应的高斯项的剪切, 去掉权值小于阈值为${{T}_{\omega }}$的高斯项. 2)合并.在每条航迹中, 将距离小于阈值为U的高斯项进行合并.由于在后验多目标密度中漏检部分和量测更新部分对应的高斯项的形式不同, 在合并过程中需要加以区分.同时, 设定航迹数的最大值为${{M}_{\max }}$, 每条航迹对应的高斯项个数的最大值为${{J}_{\max }}$.最后, 对目标的状态进行提取.若航迹的存在概率大于给定阈值(如0.5), 则认为它是一个目标, 选择它对应的权值最大的高斯项作为目标的状态.
3. 仿真
3.1 一种满足HMM局部物理特性的PMM
文献[21]总结了过程噪声与量测噪声相关和量测噪声为有色噪声对应的PMM, 并提出一种满足HMM局部物理特性的PMM.为了与HMM框架下的CBMeMBer滤波器的性能进行比较, 本文采用上述满足HMM局部物理特性的PMM进行仿真实验.并将本文所提算法的跟踪性能与PHD滤波器[21]进行比较.下面首先给出该PMM的描述.
假设线性高斯HMM为
\begin{equation}\label{} p\left( {\mathit{\boldsymbol{x}}_{0}} \right)={\rm N}\left( {\mathit{\boldsymbol{x}}_{0}};{\mathit{\boldsymbol{m}}_{0}}, {{P}_{0}} \right) \end{equation}
(49) \begin{equation}\label{} {{f}_{k|k-1}}\left( {\mathit{\boldsymbol{x}}_{k}}|{\mathit{\boldsymbol{x}}_{k-1}} \right)={\rm N}\left( {\mathit{\boldsymbol{x}}_{k}};{{F}_{k}}{\mathit{\boldsymbol{x}}_{k-1}}, {{Q}_{k}} \right) \end{equation}
(50) \begin{equation}\label{} {{g}_{k}}\left( {\mathit{\boldsymbol{y}}_{k}}|{\mathit{\boldsymbol{x}}_{k}} \right)={\rm N}\left( {\mathit{\boldsymbol{y}}_{k}};{{H}_{k}}{\mathit{\boldsymbol{x}}_{k}}, {{R}_{k}} \right) \end{equation}
(51) 则满足$p\left( {\mathit{\boldsymbol{x}}_{k}}|{\mathit{\boldsymbol{x}}_{k-1}} \right)={{f}_{k|k-1}}\left( {\mathit{\boldsymbol{x}}_{k}}|{\mathit{\boldsymbol{x}}_{k-1}} \right)$, $p( {\mathit{\boldsymbol{y}}_{k}}|{\mathit{\boldsymbol{x}}_{k}})={{g}_{k}}\left( {\mathit{\boldsymbol{y}}_{k}}|{\mathit{\boldsymbol{x}}_{k}} \right)$, 且${{p}_{k|k-1}}=\left( {\mathit{\boldsymbol{x}}_{k}}, {\mathit{\boldsymbol{y}}_{k}}|{\mathit{\boldsymbol{x}}_{k-1}}, {\mathit{\boldsymbol{y}}_{k-1}} \right)$不依赖于参数$\left( {\mathit{\boldsymbol{m}}_{0}}, {{P}_{0}} \right)$的线性高斯PMM为
\begin{equation}\label{} p\left( {\mathit{\boldsymbol{\varepsilon }}_{0}} \right)\!=\!{\rm N}\left( {\mathit{\boldsymbol{\varepsilon }}_{0}};\left[\begin{matrix} {\mathit{\boldsymbol{m}}_{0}} \\ {{H}_{0}}{\mathit{\boldsymbol{m}}_{0}} \\ \end{matrix} \right]\!, \left[\begin{matrix} {{P}_{0}} \!&\! {{\left( {{H}_{0}}{{P}_{0}} \right)}^{\rm{T}}} \\ {{H}_{0}}{{P}_{0}}\! &\! {{R}_{0}}\!+\!{{H}_{0}}{{P}_{0}}H_{0}^{\rm{T}} \\ \end{matrix} \right] \right) \end{equation}
(52) \begin{equation}\label{} {{p}_{k|k-1}}\left( {\mathit{\boldsymbol{\varepsilon }}_{k}}|{\mathit{\boldsymbol{\varepsilon }}_{k-1}} \right)={\rm N}\left( {\mathit{\boldsymbol{\varepsilon }}_{k}};{{B}_{k}}{\mathit{\boldsymbol{\varepsilon }}_{k-1}}, {{\Sigma }_{k}} \right) \end{equation}
(53) 其中
\begin{equation}\label{} {{B}_{k}}=\left[\begin{matrix} {{F}_{k}}-F_{k}^{2}{{H}_{k-1}}&F_{k}^{2} \\ {{H}_{k}}{{F}_{k}}-H_{k}^{2}{{H}_{k-1}}&H_{k}^{2} \\ \end{matrix} \right] \end{equation}
(54) \begin{equation}\label{} {{\Sigma }_{k}}=\left[\begin{matrix} \Sigma _{k}^{11}&\Sigma _{k}^{12} \\ \Sigma _{k}^{21}&\Sigma _{k}^{22} \\ \end{matrix} \right] \end{equation}
(55) \begin{equation}\label{} \Sigma _{k}^{11}={{Q}_{k}}-F_{k}^{2}{{R}_{k-1}}{{\left( F_{k}^{2} \right)}^{\rm{T}}} \end{equation}
(56) \begin{equation}\label{} \Sigma _{k}^{21}={{\left( \Sigma _{k}^{12} \right)}^{\rm{T}}}={{H}_{k}}{{Q}_{k}}-H_{k}^{2}{{R}_{k-1}}{{\left( F_{k}^{2} \right)}^{\rm{T}}} \end{equation}
(57) \begin{equation}\label{} \Sigma _{k}^{22}={{R}_{k}}-H_{k}^{2}{{R}_{k-1}}{{\left( H_{k}^{2} \right)}^{\rm{T}}}+{{H}_{k}}{{Q}_{k}}H_{k}^{\rm{T}} \end{equation}
(58) 在满足${{\Sigma }_{k}}$为正定矩阵的情况下, $F_{k}^{2}$和$H_{k}^{2}$可以任意选取.
3.2 仿真分析
为了与PHD滤波器的跟踪性能进行比较, 依据文献[21]对上述PMM的参数进行设置.
\begin{equation}\label{} {{F}_{k}}=\left[\begin{matrix} 1&t&0&0 \\ 0&1&0&0 \\ 0&0&1&t \\ 0&0&0&1 \\ \end{matrix} \right], \quad {{H}_{k}}=\left[\begin{matrix} 1&0&0&0 \\ 0&0&1&0 \\ \end{matrix} \right] \end{equation}
(59) \begin{equation}\label{} {{Q}_{k}}=\left[\begin{matrix} 100&1&0&0 \\ 1&10&0&0 \\ 0&0&100&1 \\ 0&0&1&10 \\ \end{matrix} \right], \quad {{R}_{k}}=\left[\begin{matrix} {{10}^{2}}&0 \\ 0&{{10}^{2}} \\ \end{matrix} \right] \end{equation}
(60) \begin{equation}\label{} F_{k}^{2}=\left[\begin{matrix} a&0 \\ 0&0 \\ 0&b \\ 0&0 \\ \end{matrix} \right], \quad H_{k}^{2}=\left[\begin{matrix} c&0 \\ 0&d \\ \end{matrix} \right] \end{equation}
(61) 令$t=1$, $a=b=0.7$, $c=d=0.1$.仿真硬件环境为Matlab R2013b, Windows 10 64bit, Intel Core i5-4570 CPU 3.20GHz, RAM 4.00GB.
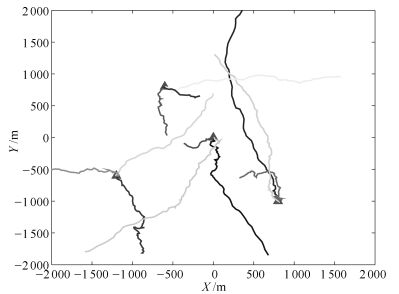
监控区域内有12个目标:目标1、2和3在$k=1$时出现, 4、5和6在$k=20$时出现, 7和8在$k=40$时出现, 9和10在$k=60$时出现, 11和12在$k=80$时出现, 而目标1和2在$k=70$时消失, 其他目标不消失.目标的状态为${\mathit{\boldsymbol{x}}_{k}}={{\left[ {{x}_{k}}, {{{\dot{x}}}_{k}}, {{y}_{k}}, {{{\dot{y}}}_{k}} \right]}^{\rm{T}}}$, ${{x}_{k}}$和${{y}_{k}}$表示二维笛卡尔坐标系下目标的位置, ${{\dot{x}}_{k}}$和${{\dot{y}}_{k}}$分别表示对应方向的速度.在监控区域$V=\left[-2000, ~2000 \right]\rm{m}\times \left[ -2000, ~2000 \right]m$中, 各采样时刻的杂波个数服从均值为20的泊松分布, 杂波量测在监控区域内均匀分布. 图 1是基于上述线性高斯PMM的目标运动轨迹, 红色三角形表示目标的初始位置.
CBMeMBer滤波器中新生目标的模型参数${{\pi }_{\Gamma }}\!\!=\!\!\left\{ \left( {{r}_{\Gamma }}, p_{\Gamma }^{\left( i \right)} \right) \right\}_{i=1}^{4}$设置如下:在HMM中, ${{r}_{\Gamma }}\!\!=\!\!0.01$, $p_{\Gamma }^{\left( i \right)}\left( x \right) \!\!=\!\!{\rm N}\left( \mathit{\boldsymbol{x}};\mathit{\boldsymbol{m}}_{\Gamma }^{\left( i \right)}, {{P}_{\Gamma }} \right)$, $\mathit{\boldsymbol{m}}_{\Gamma }^{\left( 1 \right)}\!\!=\!\!{{\left[0, 0, 0, 0 \right]}^{\rm{T}}}$, $\mathit{\boldsymbol{m}}_{\Gamma }^{\left( 2 \right)}\!\!=\!\!{{\left[400, 0, -600, 0 \right]}^{\rm{T}}}$, $\mathit{\boldsymbol{m}}_{\Gamma }^{\left( 3 \right)}\!\!=\!\!{{\left[-800, 0, -200, 0 \right]}^{\rm{T}}}$, $\mathit{\boldsymbol{m}}_{\Gamma }^{\left( 4 \right)}\!\!=\!\!{{\left[-200, 0, 800, 0 \right]}^{\rm{T}}}$, ${{P}_{\Gamma }}\!\!=\!\!\rm{diag}\left\{\!1000, 400, 1000, 400 \right\}$; 在PMM中, ${{r}_{\Gamma }}=0.01$,
$p_\Gamma ^{\left( i \right)}\left( \mathit{\boldsymbol{\varepsilon }} \right) = {\rm{N}}\left( {\mathit{\boldsymbol{\varepsilon }};\left[ {\begin{array}{*{20}{c}} {\mathit{\boldsymbol{m}}_\Gamma ^{\left( i \right)}}\\ {{H_k}\mathit{\boldsymbol{m}}_\Gamma ^{\left( i \right)}} \end{array}} \right],\left[ {\begin{array}{*{20}{c}} {{P_\Gamma }}&{{{\left( {{H_k}{P_\Gamma }} \right)}^{\rm{T}}}}\\ {{H_k}{P_\Gamma }}&{{R_k} + {H_k}{P_\Gamma }H_k^{\rm{T}}} \end{array}} \right]} \right)$
$i=\left\{ 1, \cdots, 4 \right\}$.目标的存活概率为${{p}_{s, k}}=0.98$, 传感器的检测概率为${{p}_{d, k}}=0.9$.在剪切和合并过程中, 设航迹存在概率的阈值为${{T}_{r}}={{10}^{-3}}$, 高斯项权值的阈值为${{T}_{\omega }}={{10}^{-5}}$, 合并阈值为$U=4\rm{m}$, 航迹的最大值为${{M}_{\max }}=100$, 每条航迹对应高斯项个数的最大值为${{J}_{\max }}=30$. PHD滤波器新生目标的模型参数见文献[21].
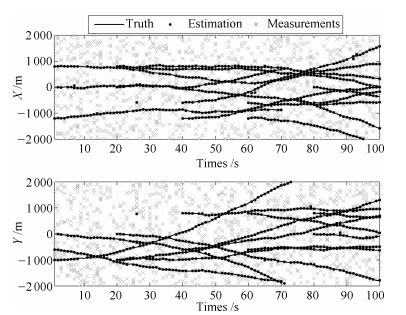
图 2给出了GM-PMM-CBMeMBer滤波器单次仿真的结果, 两个子图分别对应不同时刻X轴和Y轴的状态估计.整体来看, 所提算法可以比较准确地估计目标的状态.在某些时刻会出现虚假目标或目标跟踪丢失的情况, 但随着时间推移, 算法自身可以很快地进行修正.
本文采用OSPA (Optimal subpattern assignment)距离[24]评估算法的跟踪性能.设多目标真实状态的集合为$X=\left\{ {\mathit{\boldsymbol{x}}_{1}}, \cdots , {\mathit{\boldsymbol{x}}_{m}} \right\}$, 估计状态的集合为$\hat{X}=\left\{ {{{\hat{\mathit{\boldsymbol{x}}}}}_{1}}, \cdots, {{{\hat{\mathit{\boldsymbol{x}}}}}_{n}} \right\}$, 若$m\le n$, 则OSPA距离为
\begin{equation}\label{} \begin{array}{l} \bar d_p^{\left( c \right)}\left( {X, \hat X} \right) = \\ \quad {\left( {\frac{1}{n}\left( {\mathop {\min }\limits_{\pi \in {\Pi _n}} \sum\limits_{i = 1}^m {{d^{\left( c \right)}}{{\left( {{\mathit{\boldsymbol{x}}_i}, {{\hat {\mathit{\boldsymbol{x}}}}_{\pi \left( i \right)}}} \right)}^p} + {c^p}\left( {n - m} \right)} } \right)} \right)^{\frac{1}{p}}} \end{array} \end{equation}
(62) 其中, ${{d}^{\left( c \right)}}\left( {\mathit{\boldsymbol{x}}_{i}}, {{{\hat{\mathit{\boldsymbol{x}}}}}_{\pi \left( i \right)}} \right)=\min \left( c, \left\| \mathit{\boldsymbol{x}}-\hat{\mathit{\boldsymbol{x}}} \right\| \right)$, ${{\Pi }_{n}}$表示$\left\{ 1, \cdots, n \right\}$的所有排列集合.若$m>n$, 则$\bar d_p^{\left( c \right)}\left( {X, \hat X} \right) = \bar d_p^{\left( c \right)}\left( {\hat X, X} \right)$.令距离阶次$p=1$, 截断系数$c=20\rm {m}$.
本例做了500次蒙特卡洛(Monte carlo, MC)仿真实验, 分析结果如下:
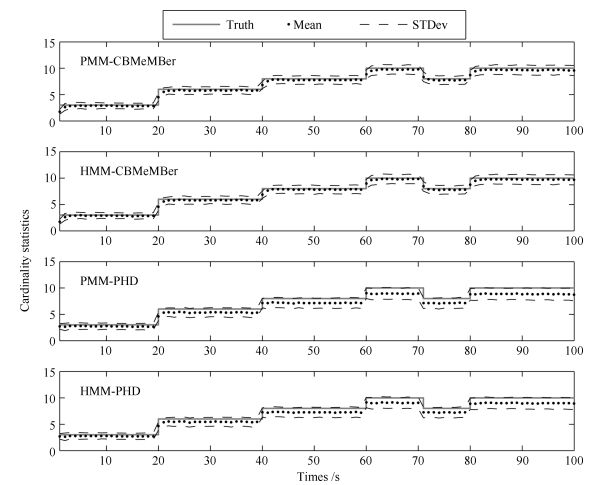
1) 图 3为不同算法对目标数估计的均值和标准差.可以看出, 在PMM或HMM框架下, CBMeMBer滤波器对目标数的估计是无偏的, PHD滤波器随着目标数的增加, 会出现欠估计的情况.说明本文所提算法对目标数的估计优于PHD滤波器[21].相比不同框架下的CBMeMBer滤波器和PHD滤波器, 它们对目标数估计的统计特性非常接近.
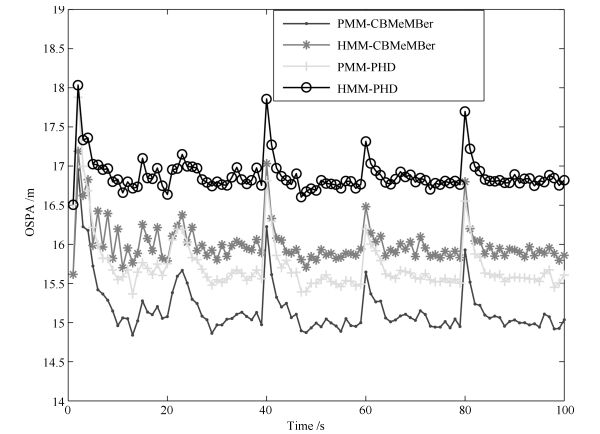
2) 图 4为不同算法对应的OSPA距离.可以看出, CBMeMBer滤波器在PMM和HMM框架下的OSPA距离评价指标均优于PHD滤波器. CBMeMBer滤波器和PHD滤波器在PMM框架下的OSPA距离评价指标优于HMM框架下相应的OSPA距离评价指标.
3) 表 1为不同杂波环境下4种算法的性能比较.不同杂波环境下, CBMeMBer滤波器和PHD滤波器在PMM框架下的OSPA距离评价指标优于HMM框架下的OSPA距离评价指标, 但单步运行时间的均值会变大.由于GM-CBMeMBer滤波器是将每个目标的密度分别用GM表示, 而GM-PHD滤波器是将多目标密度的强度整体用GM表示.因此, 它们的高斯项个数不同, 比较运行时间也就没有意义.但从表 1可以看出, 相比GM-PMM-PHD滤波器, GM-PMM-CBMeMBer滤波器以更小的时间代价可以得到更优的OSPA距离评价指标.
表 1 不同杂波环境下的性能比较Table 1 Tracking performance verses clutter's number$\lambda $ 0 5 10 20 PMM-CBMeMBer OSPA(m) 15.173 15.196 15.202 15.390 时间(s) 0.0203 0.0221 0.0237 0.0244 HMM-CBMeMBer OSPA(m) 16.010 16.065 16.086 16.234 时间(s) 0.0179 0.0194 0.0211 0.0228 PMM-PHD OSPA(m) 15.631 15.654 15.698 15.739 时间(s) 0.0203 0.0280 0.0350 0.0476 HMM-PHD OSPA(m) 16.806 16.817 16.855 16.889 时间(s) 0.0084 0.0118 0.0132 0.0191 4. 结论
本文提出一种在PMM框架下的CBMeMBer滤波器, 并给出了它在线性高斯PMM条件下的GM实现.该算法放宽了HMM隐含的马尔科夫假设和独立性假设限制.在仿真实验中, 采用一种满足HMM局部物理特性的PMM, 将本文所提算法与文献[21]所提的GM-PMM-PHD滤波器进行比较, 仿真结果表明本文所提算法的跟踪性能优于GM-PMM-PHD滤波器.本文考虑的是PMM在线性高斯条件下的多目标跟踪问题, 而非线性条件下的多目标跟踪问题有待进一步研究.
-

图 4 FCNN高层语义先验知识及显著性检测结果图比较
Fig. 4 The FCNN high-level semantic prior knowledge and the comparison of saliency detection results

图 8 对本文结果进行线性拉伸后与DS方法的MAE值比较
Fig. 8 The comparison of MAE between the results of linear stretching in this paper and the results of the DS method
表 1 本文方法与传统方法的MAE比较
Table 1 The comparison of MAE between the proposed method and traditional methods
算法 MSRA-test1000 PASCAL-S FT 0.2480 0.3066 SR 0.2383 0.2906 CA 0.2462 0.2994 SF 0.1449 0.2534 GR 0.2524 0.2992 MR 0.1855 0.2283 BSCA 0.1859 0.2215 LRMR 0.2442 0.2759 本文算法 0.0969 0.1814  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与其他方法的平均运行时间比较
Table 2 The comparison of average running time between the proposed method and other methods
算法 时间(s) 代码类型 MSRA-test1000 PASCAL-S FT 0.080 0.111 MATLAB SR 0.024 0.030 MATLAB CA 20.587 22.299 MATLAB SF 0.138 0.217 MATLAB GR 0.636 0.905 MATLAB MR 0.559 0.759 MATLAB BSCA 1.101 1.475 MATLAB LRMR 7.288 9.674 MATLAB 本文方法 6.916 9.154 MATLAB
下载: 导出CSV
表 3 FCNN分割的前景目标与本文最终分割得到的二值感兴趣区域的MAE比较
Table 3 The comparison of MAE between the segmented foreground object by FCNN and the segmented binary ROI by the proposed method
算法 MSRA-test1000 PASCAL-S FCNN高层先验知识 0.0531 0.1040 本文方法(二值化) 0.0516 0.0964
下载: 导出CSV
表 4 本文方法与深度学习方法的指标比较
Table 4 The comparison of evaluation indexs between the proposed method and deep learning methods
算法 F-measure MAE RFCN 0.7468 - DS 0.7710 0.1210 本文方法 0.7755 0.1814
下载: 导出CSV
-
[1] Mahadevan V, Vasconcelos N. Saliency-based discriminant tracking. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 1007-1013 [2] Siagian C, Itti L. Rapid biologically-inspired scene classification using features shared with visual attention. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(2):300-312 doi: 10.1109/TPAMI.2007.40 [3] 钱生, 陈宗海, 林名强, 张陈斌.基于条件随机场和图像分割的显著性检测.自动化学报, 2015, 41(4):711-724 http://www.aas.net.cn/CN/abstract/abstract18647.shtmlQian Sheng, Chen Zong-Hai, Lin Ming-Qiang, Zhang Chen-Bin. Saliency detection based on conditional random field and image segmentation. Acta Automatica Sinica, 2015, 41(4):711-724 http://www.aas.net.cn/CN/abstract/abstract18647.shtml [4] Sun J, Ling H B. Scale and object aware image retargeting for thumbnail browsing. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1511-1518 [5] 张慧, 王坤峰, 王飞跃.深度学习在目标视觉检测中的应用进展与展望.自动化学报, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtmlZhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtml [6] Marchesotti L, Cifarelli C, Csurka G. A framework for visual saliency detection with applications to image thumbnailing. In:Proceedings of the IEEE 12th International Conference on Computer Vision. Kyoto, Japan:IEEE, 2009. 2232-2239 [7] Yang J M, Yang M H. Top-down visual saliency via joint CRF and dictionary learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(3):576-588 doi: 10.1109/TPAMI.2016.2547384 [8] Li J, Rajan D, Yang J. Locality and context-aware top-down saliency. IET Image Processing, 2018, 12(3):400-407 doi: 10.1049/iet-ipr.2017.0251 [9] Itti L, Kouch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254-1259 doi: 10.1109/34.730558 [10] Hou X D, Zhang L Q. Saliency detection: a spectral residual approach. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN, USA: IEEE, 2007. 1-8 [11] Achanta R, Hemami S, Estrada F, Susstrunk S. Frequency-tuned salient region detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 1597-1604 [12] Cheng M M, Zhang G X, Mitra N J, Huang X L, Hu S M. Global contrast based salient region detection. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2011. 409-416 [13] Perazzi F, Krähenbühl P, Pritch Y, Hornung A. Saliency filters: contrast based filtering for salient region detection. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012. 733-740 [14] Goferman S, Zelnikmanor L, Tal A. Context-aware saliency detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10):1915-1926 doi: 10.1109/TPAMI.2011.272 [15] Yang C, Zhang L H, Lu H C. Graph-regularized saliency detection with convex-hull-based center prior. IEEE Signal Processing Letters, 2013, 20(7):637-640 doi: 10.1109/LSP.2013.2260737 [16] Yang C, Zhang L H, Lu H C, Ruan X, Yang M H. Saliency detection via graph-based manifold ranking. In: Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition. Portland OR, USA: IEEE, 2013. 3166-3173 [17] Qin Y, Lu H C, Xu Y Q, Wang H. Saliency detection via cellular automata. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015. 110-119 [18] Yan J C, Zhu M Y, Liu H X, Liu Y C. Visual saliency detection via sparsity pursuit. IEEE Signal Processing Letters, 2010, 17(8):739-742 doi: 10.1109/LSP.2010.2053200 [19] Lang C Y, Liu G C, Yu J, Yan S C. Saliency detection by multitask sparsity pursuit. IEEE Transactions on Image Processing, 2012, 21(3):1327-1338 doi: 10.1109/TIP.2011.2169274 [20] Shen X H, Wu Y. A unified approach to salient object detection via low rank matrix recovery. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence RI, USA: IEEE, 2012. 853-860 [21] 李岳云, 许悦雷, 马时平, 史鹤欢.深度卷积神经网络的显著性检测.中国图象图形学报, 2016, 21(1):53-59 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201601007Li Yue-Yun, Xu Yue-Lei, Ma Shi-Ping, Shi He-Huan. Saliency detection based on deep convolutional neural network. Journal of Image and Graphics, 2016, 21(1):53-59 http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201601007 [22] Wang L Z, Wang L J, Lu H C, Zhang P P, Ruan X. Saliency detection with recurrent fully convolutional networks. In: Proceedings of the Computer Vision-ECCV 2016. Lecture Notes in Computer Science, vol. 9908. Amsterdam, Netherlands: Springer, 2016. 825-841 [23] Lee G, Tai Y W, Kim J. Deep saliency with encoded low level distance map and high level features. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 660-668 [24] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston MA, USA: IEEE, 2015. 3431-3440 [25] Simoncelli E P, Freeman W T. The steerable pyramid: a flexible architecture for multi-scale derivative computation. In: Proceedings of International Conference on Image Processing. Washington DC, USA: IEEE, 1995. 444-447 [26] 王晓红, 赵于前, 廖苗, 邹北骥.基于多尺度2D Gabor小波的视网膜血管自动分割.自动化学报, 2015, 41(5):970-980 http://www.aas.net.cn/CN/abstract/abstract18671.shtmlWang Xiao-Hong, Zhao Yu-Qian, Liao Miao, Zou Bei-Ji. Automatic segmentation for retinal vessel based on multi-scale 2D Gabor wavelet. Acta Automatica Sinica, 2015, 41(5):970-980 http://www.aas.net.cn/CN/abstract/abstract18671.shtml [27] Comaniciu D, Meer P. Mean shift:a robust approach toward feature space analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(5):603-619 doi: 10.1109/34.1000236 [28] Dong C, Loy C C, He K M, Tang X O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2):295-307 doi: 10.1109/TPAMI.2015.2439281 [29] Matan O, Burges C J C, LeCun Y, Denker J S. Multi-digit recognition using a space displacement neural network. In: Proceedings of Neural Information Processing Systems. San Mateo, CA: Morgan Kaufmann, 1992. 488-495 [30] Wright J, Peng Y G, Ma Y, Ganesh A, Rao S. Robust principal component analysis: exact recovery of corrupted low-rank matrices by convex optimization. In: Proceedings of Neural Information Processing Systems. Vancouver, British Columbia, Canada: NIPS, 2009. 2080-2088 期刊类型引用(3)
1. 王国良,宋歌. 基于观测器的离散马氏跳变系统的故障估计. 南京信息工程大学学报(自然科学版). 2021(05): 517-525 .  百度学术
百度学术2. 刘江义,王春平,王暐. 基于双马尔可夫链的SMC-CBMeMBer滤波. 系统工程与电子技术. 2019(08): 1686-1691 . 百度学术3. 郎波,樊一娜. 基于深度神经网络的个性化学习行为评价方法. 计算机技术与发展. 2019(07): 6-10 . 百度学术其他类型引用(7)
-

 下载:
下载:






计量
- 文章访问数: 4113
- HTML全文浏览量: 1194
- PDF下载量: 321
- 被引次数: 10
