

-
摘要: 针对混合属性数据集聚类精度低的问题,本文提出一种基于改进距离度量的半监督模糊均值聚类(Fuzzy C-means,FCM)算法.首先,在数据集中针对类别属性进行预处理,并设置相应的相异度阈值;将传统聚类距离度量与改进的Jaccard距离度量结合,确定混合属性数据集的距离度量函数;最后,将所得距离度量函数与传统半监督FCM算法相结合,并在滚动轴承的不同复合故障数据的特征集中进行聚类.实验表明,该算法能在含无序属性的混合属性数据集的聚类中取得更好的聚类效果.Abstract: This paper puts forward a semi-supervised fuzzy C-means (FCM) algorithm based on an improved distance measure to solve the problem of low accuracy of clustering algorithm of data sets with mixed attributes. First, the classification attributes are preprocessed in the data set, and the corresponding dissimilarity threshold is set. Then the traditional clustering distance measure is combined with the improved Jaccard distance measure to determine the distance measure function. Finally, the distance measure function is combined with the traditional semi-supervised FCM algorithm, and clustering is carried out on the characteristic data sets of different coupling fault data of rolling bearings. Simulation results show that the algorithm can achieve better clustering accuracy in mixed data sets.
-
Key words:
- Mixed attributes /
- dissimilarity threshold /
- fuzzy C-means (FCM) /
- Jaccard
-
-
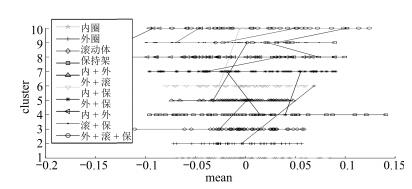
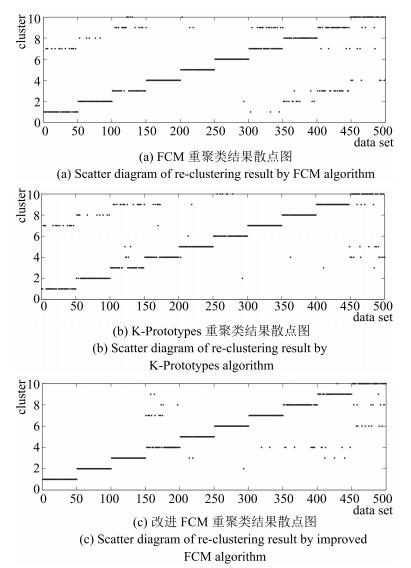
图 7 改进FCM自适应阈值调整后重聚类结果
Fig. 7 Re-clustering result by improved FCM algorithm after adaptive threshold
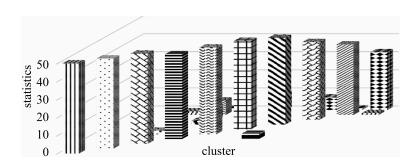
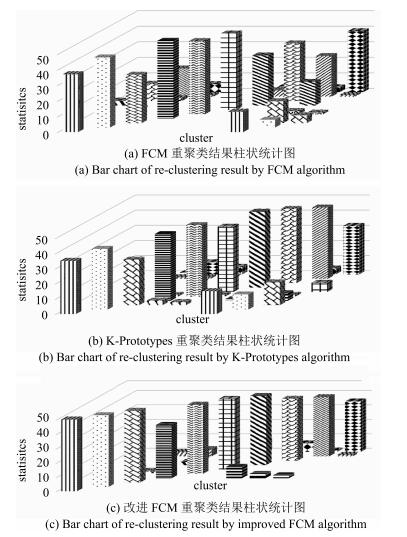
图 8 改进FCM自适应阈值调整后重聚类结果柱状统计图
Fig. 8 Bar chart of re-clustering result by improved FCM algorithm after adaptive threshold
表 1 轴承各部件故障特征频率(Hz)
Table 1 Characteristic frequency of rolling bearings (Hz)
内圈 外圈 保持架 滚动体 163.2 107.4 11.9 141.2  下载: 导出CSV
下载: 导出CSV
表 2 聚类精度对比表
Table 2 Comparison table of clustering accuracy
单故障 耦合故障 传统FCM聚类精度 0.98 0.65 改进FCM聚类精度 1.00 0.87
下载: 导出CSV
表 3 三种算法聚类精度对比表
Table 3 Comparison table of clustering accuracy by three algorithms
传统FCM K-prototypes 改进FCM 聚类精度 0.786 0.842 0.902
下载: 导出CSV
表 4 不同$\varepsilon$值下聚类精度对比表
Table 4 Comparison table of clustering accuracy by different $\varepsilon$
$\varepsilon$ 0.09 0.10 0.11 0.12 0.13 0.14 聚类精度 0.796 0.868 0.898 0.902 0.88 0.822
下载: 导出CSV
-
[1] 徐明亮, 王士同, 杭文龙.一种基于同类约束的半监督近邻反射传播聚类方法.自动化学报, 2016, 42(2):255-269 http://www.aas.net.cn/CN/abstract/abstract18815.shtmlXu Ming-Liang, Wang Shi-Tong, Hang Wen-Long. A semi-supervised affinity propagation clustering method with homogeneity constraint. Acta Automatica Sinica, 2016, 42(2):255-269 http://www.aas.net.cn/CN/abstract/abstract18815.shtml [2] 赵慧珍, 刘付显, 李龙跃. K-近邻估计协同系数的协同模糊C均值算法.计算机工程与应用, 2016, 52(19):19-24 doi: 10.3778/j.issn.1002-8331.1601-0312Zhao Hui-Zhen, Liu Fu-Xian, Li Long-Yue. Novel collaboration fuzzy C-means algorithm with K-nearest neighbor method determined Collaboration Coefficient. Computer Engineering and Applications, 2016, 52(19):19-24 doi: 10.3778/j.issn.1002-8331.1601-0312 [3] Huang Z X. Clustering large data sets with mixed numeric and categorical values. In: Proceedings of the 1st Pacific-Asia Conference on Knowledge Discovery and Data Mining. Singapore, Singapore: PAKDD, 1997. 21-34 [4] 陈晋音, 何辉豪.基于密度和混合距离度量方法的混合属性数据聚类研究.控制理论与应用, 2015, 32(8):993-1002 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201508001Chen Jin-Yin, He Hui-Hao. Density-based clustering algorithm for numerical and categorical data with mixed distance measure methods. Control Theory and Applications, 2015, 32(8):993-1002 http://d.old.wanfangdata.com.cn/Periodical/kzllyyy201508001 [5] 黄德才, 李晓畅.基于相对密度的混合属性数据增量聚类算法.控制与决策, 2013, 28(6):815-822 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201306005Huang De-Cai, Li Xiao-Chang. Incremental relative density-based clustering algorithm for mixture data sets. Control and Decision, 2013, 28(6):815-822 http://d.old.wanfangdata.com.cn/Periodical/kzyjc201306005 [6] 陈晋音, 何辉豪.基于密度的聚类中心自动确定的混合属性数据聚类算法研究.自动化学报, 2015, 41(10):1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtmlChen Jin-Yin, He Hui-Hao. Research on density-based clustering algorithm for mixed data with determine cluster centers automatically. Acta Automatica Sinica, 2015, 41(10):1798-1813 http://www.aas.net.cn/CN/abstract/abstract18754.shtml [7] 陈新泉.面向混合属性数据集的双重聚类方法.计算机工程与科学, 2013, 35(2):127-132 doi: 10.3969/j.issn.1007-130X.2013.02.022Chen Xin-Quan. Dual clustering method of mixed data set. Computer Engineering and Science, 2013, 35(2):127-132 doi: 10.3969/j.issn.1007-130X.2013.02.022 [8] Gardner A, Kanno J, Duncan C A, Selmic R. Measuring distance between unordered sets of different sizes. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA: IEEE, 2014. 137-143 [9] 李城梁, 马芸, 张锐, 魏伟.基于半监督谱核聚类的转子系统故障诊断.振动、测试与诊断, 2016, 36(3):562-567 http://d.old.wanfangdata.com.cn/Periodical/zdcsyzd201603026Li Cheng-Liang, Ma Yun, Zhang Rui, Wei Wei. Rotor system fault diagnosis based on semi-supervised spectrum kernel clustering. Journal of Vibration, Measurement and Diagnosis, 2016, 36(3):562-567 http://d.old.wanfangdata.com.cn/Periodical/zdcsyzd201603026 [10] 嵇威华, 吕国芳.基于广义Jaccard系数处理冲突证据方法.控制工程, 2015, 22(1):98-101 http://d.old.wanfangdata.com.cn/Periodical/jczdh201501017Ji Wei-Hua, Lv Guo-Fang. Conflicting evidence combination method based on generalized Jaccard coefficient. Control Engineering of China, 2015, 22(1):98-101 http://d.old.wanfangdata.com.cn/Periodical/jczdh201501017 [11] 周晨曦, 梁循, 齐金山.基于约束动态更新的半监督层次聚类算法.自动化学报, 2015, 41(7):1253-1263 http://www.aas.net.cn/CN/abstract/abstract18699.shtmlZhou Chen-Xi, Liang Xun, Qi Jin-Shan. A semi-supervised agglomerative hierarchical clustering method based on dynamically updating constraints. Acta Automatica Sinica, 2015, 41(7):1253-1263 http://www.aas.net.cn/CN/abstract/abstract18699.shtml [12] 袁杰, 王福利, 王姝, 赵露平.基于D-S融合的混合专家知识系统故障诊断方法.自动化学报, 2017, 43(9):1580-1587 http://www.aas.net.cn/CN/abstract/abstract19134.shtmlYuan Jie, Wang Fu-Li, Wang Shu, Zhao Lu-Ping. A fault diagnosis approach by D-S fusion theory and hybrid expert knowledge system. Acta Automatica Sinica, 2017, 43(9):1580-1587 http://www.aas.net.cn/CN/abstract/abstract19134.shtml [13] 张超, 陈建军, 郭迅.基于第2代小波和EMMD的转子系统复合故障诊断.振动、测试与诊断, 2011, 31(1):98-103 doi: 10.3969/j.issn.1004-6801.2011.01.022Zhang Chao, Chen Jian-Jun, Guo Xun. Complex fault diagnosis for rotor systems using the second generation wavelet and extremum field mean mode decomposition. Journal of Vibration, Measurement and Diagnosis, 2011, 31(1):98-103 doi: 10.3969/j.issn.1004-6801.2011.01.022 [14] Hao H, Wang H L, Rehman N U. A joint framework for multivariate signal denoising using multivariate empirical mode decomposition. Signal Processing, 2017, 135:263-273 doi: 10.1016/j.sigpro.2017.01.022 期刊类型引用(8)
1. 张梦琇. EM算法对不完全数据下指数分布的参数估计. 科技风. 2023(08): 64-66+70 .  百度学术
百度学术2. 魏纯,徐玲,丁锋. 反馈非线性系统随机梯度辨识算法及其收敛性. 控制理论与应用. 2023(10): 1757-1764 . 百度学术3. Jing-Dong DIAO,Jin GUO,Changyin SUN. A compensation method for the packet loss deviation in system identification with event-triggered binary-valued observations. Science China(Information Sciences). 2020(12): 266-268 . 必应学术4. 宋樱. 基于CSA-RLS算法的Wiener模型辨识. 计算机与数字工程. 2020(12): 2938-2941 . 百度学术5. 李云,孙书利,郝钢. 基于Gauss-Hermite逼近的非线性加权观测融合无迹Kalman滤波器. 自动化学报. 2019(03): 593-603 . 本站查看6. 周平,刘记平. 基于数据驱动多输出ARMAX建模的高炉十字测温中心温度在线估计. 自动化学报. 2018(03): 552-561 . 本站查看7. 谢莉,杨慧中,丁锋. 非均匀采样数据系统的新型模型描述方法. 自动化学报. 2017(05): 806-813 . 本站查看8. 李珍,魏利胜,程运昌. 基于样条插值的不完备信息系统参数估计. 安徽工程大学学报. 2015(05): 69-77 . 百度学术其他类型引用(6)
-


计量
- 文章访问数: 2245
- HTML全文浏览量: 257
- PDF下载量: 548
- 被引次数: 14
