

-
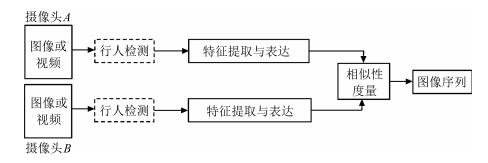
摘要: 行人再识别指的是判断不同摄像头下出现的行人是否属于同一行人, 可以看作是图像检索的子问题, 可以广泛应用于智能视频监控、安保、刑侦等领域.由于行人图像的分辨率变化大、拍摄角度不统一、光照条件差、环境变化大、行人姿态不断变化等原因, 使得行人再识别成为目前计算机视觉领域一个既具有研究价值又极具挑战性的研究热点和难点问题.早期的行人再识别方法大多基于人工设计特征, 在小规模数据集上开展研究.近年来, 大规模行人再识别数据集不断推出, 以及深度学习技术的迅猛发展, 为行人再识别技术的发展带来了新的契机.本文对行人再识别的发展历史、研究现状以及典型方法进行梳理和总结.首先阐述了行人再识别的基本研究框架, 然后分别针对行人再识别的两个关键技术(特征表达和相似性度量), 进行了归纳总结, 重点介绍了目前发展迅猛的深度学习技术在行人再识别中的应用.另外, 本文对行人再识别中代表性的数据集以及在各个数据集上可以取得优异性能的方法进行了分析和比较.最后对行人再识别技术的未来发展趋势进行了展望.Abstract: Person re-identification aims to associate the same person across different views and can be taken as a subproblem of image retrieval.It has extensive application prospects in many areas such as intelligent video surveillance, security, and criminal investigation.Due to poor illumination condition, image resolution, camera viewpoint, environment, and pedestrian pose, person re-identification has become one of the challenging problems in computer vision.Early person re-identification methods mostly rely on hand-crafted features and researches are conducted on small-scale datasets.In recent years, the emergence of large-scale datasets and rapid development of deep learning techniques provide person re-identification with new opportunities.This survey gives a detailed overview of the history, state of the art, and typical methods in this domain.Firstly, the general framework of person re-identification is presented.Then, feature representation, similarity measurement, and two key aspects of person re-identification, are further summarized, respectively.We also highlight the application of rapid developing deep learning techniques to person re-identification.Moreover, the representative datasets of person re-identification and methods of obtaining excellent performance on each dataset are analyzed and compared.Finally, the future trends of this field are discussed.
-
集束型设备已被广泛地应用于半导体制造的晶圆加工中[1-2].由于集束型设备加工晶圆时存在多重入流、驻留及资源约束等现象[3],使得集束型设备的调度变得非常复杂.近年来,为了提高设备的产能,集束型设备的结构随着不断改进也出现很多不同的变化,其中一些学者另辟蹊径,希望通过合理地设置缓冲模块来提高设备的产能[4].而对于增加缓冲模块的新型结构的集束型设备来说,现有的调度方法定然不能满足其生产要求,这就需要新的调度方法来支持其调度.
集束型设备一般由多个晶圆加工模块(Processing module,PM)、一个晶圆搬运模块(Transport module,TM)和负责晶圆输入输出的卡匣模块(Cassette modules,CM) 组成.作为晶圆加工特有的工艺要求,驻留约束限制了晶圆在加工模块完成加工后所能停留的时间上限(Upper bound) ,即当晶圆在加工完成后,必须在规定时间范围内离开加工模块,否则残余气体或不适宜温度会导致晶圆出现质量问题,甚至不良品.驻留现象广泛存在于半导体制造过程中[5].针对一般的驻留约束问题,大部分研究都是通过调整晶圆的加工开始时间来满足晶圆的驻留约束[6],一些学者通过设置缓冲模块的方法,使晶圆在加工完成后能够尽早离开加工模块,释放资源,提前下一个晶圆的加工开始时间.
目前,对于一般的集束型设备的周期调度研究已经比较成熟. Perkinson等[7] 与Venkatesh等[8]在不考虑驻留约束的情况下,分别采用推策略和交换策略来获得单臂与双臂集束型设备的最优的基本周期(Fundamental period,FP). Lim等[9] 为了有效提高整体调度周期,考虑晶圆搬运延迟,并提出了一个基于时间表技术的有效实时调度算法.
然而,前面的文献没有考虑驻留约束对集束型设备的调度影响.目前已有相关文献对带驻留约束的集束型设备调度问题进行了研究,Wu等[10]为带驻留约束的集束型设备建立了Petri-网模型,提出了一个封闭式调度算法来获得最优周期的调度.Rostami等[11]运用线性规划和启发式算法来调度带驻留约束的单集束型设备.Zhou等[12]提出了基于侦误的调度启发式算法用于解决带驻留约束的集束型设备调度问题.Rostami等[13]对集束型设备带有加工模块和搬运模块的双驻留约束模型提出了一种调度算法,得到了问题的近优解.
上述文献虽然考虑了驻留约束,却没有考虑缓冲模块对设备产能的影响.对于集束型设备的缓冲模块的研究目前正在起步,Ding等[14]在集束型设备群的研究中,对各个集束型之间的缓冲连接进行了研究.Dawande等[15]比较了制造单元里带输出缓冲和无缓冲的模型,证明带有输出缓冲的制造单元比双爪不带缓冲的制造单元的生产率提高了20%.Drobouchevitch等[16]表明在制造单元的每个机器已存在输出缓冲的基础上增加一个输入缓冲不会提高设备的产能.
上述文献表明,目前对同时带驻留约束和缓冲模块的集束型设备调度问题尚无人研究.本文旨在上述文献的研究基础上,对带驻留约束的集束型设备进行了研究,通过在加工模块之间设置缓冲模块的方法,提高系统产能.该调度问题主要是确定优化的搬运顺序和搬运时间点以获得最小的周期调度.首先,对调度问题在不同搬运模式下建立了相应数学模型;再提出两种不同的调度算法;最后,评价算法的同时,分析缓冲对系统产能的影响.
1. 问题描述
集束型设备里,晶圆由卡匣模块进入,按顺序到每个加工模块加工,完成所有加工后回到卡匣模块.本文的研究对象为加工模块之间带有缓冲模块的单臂集束型设备,如图 1所示.
为有效地描述带缓冲的集束型晶圆制造设备的调度问题,做如下的基本定义与假设:1) 加工模块,搬运模块和缓冲模块在同一时间均只能处理一个晶圆.2) 加工模块上存在驻留约束现象.3) 搬运模块搬运晶圆的时间和装卸时间是确定的.4) 每个晶圆的加工工艺流程都相同.5) 若晶圆进入缓冲模块,缓冲模块被视作虚拟的加工模块,其加工时间为零,且不存在驻留约束;否则,晶圆跳过缓冲模块直接到下一个加工模块进行加工.6) 晶圆在卡匣模块供应充足,晶圆完成最后一道加工工序后直接被搬运到卡匣模块.
为了清晰地表述调度问题,现定义如下符号与变量:
$m$ : 集束型设备加工模块的数量.
$p_i$ : 晶圆 $j$ 在加工模块 $i$ 上的加工时间.
$\delta_i$ : 搬运模块把晶圆从 $M_i$ 搬运到 $M_{i+1}$ 的时间,包括装载和卸载晶圆的时间 $\delta_i=\delta$ .
$\theta_{ij}$ : 搬运模块从 $M_i$ 到 $M_j$ 的空移动的时间 $\theta_{ij}=\min(|i-j|,2m-|i-j|)\cdot\theta$ .
$λ_k$ : 表示晶圆 $j$ 是否经过模块 $M_k$ ,如果是,那么 $λ_k=1$ ;否则, $λ_k=0$ .
$\varphi(i)$ : 表示搬运模块从第 $\varphi(i)$ 模块搬运到 $(\varphi(i)+2-λ_{\varphi(i)+1})$ 模块.
$s_j$ : 搬运模块的搬运模式.
$T$ : 生产每个晶圆的周期时间.
定义 1. 一个单元搬运模式(One-unit TM move style)是指一个晶圆进入加工模块到下一个晶圆开始进入加工模块之间的搬运模块的所有搬运动作.可以通过如下形式来表示: $s=[\varphi(0) ,\varphi(1) ,\varphi(2) ,\cdots,\varphi(m)]$ ,其中 $s$ 是由 $\{0,1,2,\cdots,m\}$ 的排列组成.
由于搬运模式的重复性,假设 $\varphi(0)=0$ ,不失一般性, $\varphi[i\pm(\sum_{k=0}^{2m-1}\lambda_k+1)]=\varphi(i)$ . 两个加工模块的单集束型设备的搬运模式包括如下: $s_1=[0,1,3]$ , $s_2=[0,3,1]$ , $s_3=[0,1,2,3]$ , $s_4=[0,1,3,2]$ , $s_5=[0,2,1,3]$ , $s_6=[0,2,3,1]$ , $s_7=[0,3,1,2]$ , $s_8=[0,3,2,1]$ .
定义 2. 给定一个搬运模式 $s$ ,其中 $\varphi(k)=i$ ,那么 $\varphi(k)$ 的反函数为 $\varphi^-(k)$ , $0\leq\varphi^-(k)\leq m$ , $k=0,1,\cdots,m$ , $\varphi^-(\varphi(i))=i$ ,且 $\varphi(\varphi^-(k))=k$ .
从定义可知,对给定的搬运模式来说,如果搬运模块从 $M_k$ 卸载晶圆,该搬运动作处于单元搬运模式的 $\varphi^-(k)$ th位置,那么当存在 $\varphi^-(k)>\varphi^-(k-2+λ_{k-1})$ 时,从 $M_k$ 装载和卸载的同一片晶圆的搬运动作处于同一个单元搬运模式内;当存在 $\varphi^-(k)<\varphi^-(k-2+λ_{k-1})$ 时,从 $M_k$ 装载和卸载的同一片晶圆的搬运动作却分别处于两个先后的单元搬运模式内.所以 $u_k$ 被定义如下:
\begin{align}u_k=\left\{\begin{array}{c}1,\quad \varphi^-(k)<\varphi^-(k-2+λ_{k-1})\\0,\quad \varphi^-(k)>\varphi^-(k-2+λ_{k-1})\end{array} \right. \end{align}
(1) 任何单元搬运模式内都存在一些不可避免的搬运动作,如晶圆卸载和装载、晶圆的搬运等,用 $IC(s)$ 来表示给定单元搬运模式 $s$ 中必然存在的搬运动作,其表达式如下:
$IC(s)=\sum\limits_{i=0}^{2m-1}{(}{{\delta }_{\varphi (i)}}+{{\theta }_{\varphi (i)}}+2-{{\lambda }_{\varphi (i)+1}},\varphi (i+2-{{\lambda }_{i+1}}))\text{ }$
(2) 在单元搬运模式 $s$ 下,一片晶圆从装载至模块 $M_k$ 到加工完后被卸载这段时间内,搬运模块所耗费的所有的繁忙时间用 $z_k(s)$ 表示:
${{z}_{k}}(s)={{\theta }_{k,{{\tau }_{k}}(s)}}+\sum\limits_{i}^{{{b}_{k}}}{(}{{\delta }_{\varphi (i)}}+{{\theta }_{\varphi (i)}}+2-{{\lambda }_{\varphi (i)+1}},\varphi (i+2-{{\lambda }_{i+1}}))$
(3) 其中, $\tau_k(s)$ 为搬运动作 $k-1$ 的下一搬运动作,即 $\tau_k(s)=\varphi[\varphi^-(k-2+λ_{k-1})+1]$ ,而 $i$ 的初始值为: $\varphi^-(k-2+λ_{k-1})+1$ ,且 $b_k=\varphi^-(k)-1+u_k(\sum_{j=0}^{2m}λ_j+1) $ .
若存在常数 $T$ 使得集束型设备生产状态经 $T$ 时间回到相同的状态,则该时间 $T$ 被称作周期时间.
令 $w_{kj}$ 是指搬运模块在 $M_k$ 等待搬运晶圆 $j$ 的时间.由于周期生产的性质,假设 $\sigma(j\pm n)=\sigma(j)$ , $w_{k,\sigma(j\pm n)}=w_{k,\sigma(j)}$ ,从假设5) 和6) 可知,当 $k$ 是偶数时, $w_{kj}=0$ .
若 $T(s)$ 是相应的搬运模式 $s$ 的周期时间,则目标函数 $T(s)$ 就有:
\begin{align}T(s)=\min\left(IC(s)+\sum_{j=1}^n\sum_{k=0}^mw_{kj}\right) \end{align}
(4) 由加工时间需求的约束与假设1) 可知,晶圆在 $M_k$ 上加工需满足如下约束:
$\sum\limits_{i}^{{{\varphi }^{-}}(k)}{{{w}_{\varphi (i)}}}\ge \max ({{p}_{k}}-{{z}_{k}},0),{{u}_{k}}=0$
(5) $\sum\limits_{i=1}^{\Sigma {{\lambda }_{l}}}{+}\sum\limits_{i}^{{{\varphi }^{-}}(k)}{{{w}_{\varphi (i)}}}\ge \max ({{p}_{k}}-{{z}_{k}},0),{{u}_{k}}=1$
(6) 其中,式(5) 和式(6) 中 $i$ 的初始值为: $i=\varphi^-(k-2+λ_{k-1})+2-λ_{\varphi^-(k-2+λ_{k-1})+1}$ .
由假设2) 的驻留约束有:
\begin{align}z_k-p_k\leq a_k \end{align}
(7) 搬运模块的等待时需满足非负:
\begin{align}w_k\geq 0 \end{align}
(8) 所以,对于给定的搬运模式 $s$ ,要优化目标函数(4) ,服从约束(5) $\sim$ (8) .其中的 $IC(s)$ 与决策变量 $w_{kj}$ 相互独立.
本文是在搬运模式下建立相应的数学模型,在前面数学建模里,该模型的复杂度为 ${\rm O}(m× n)$ ,是多项式内可以求解. 而搬运模式的规模为 ${\rm O}((m+2) m!)$ ,那么整个问题解空间的规模为 ${\rm O}(n(m^2+2m)m!)$ .所以对于问题的求解分为两个阶段:加工等待时间优化和晶圆搬运顺序优化.然后分别构建全局搜索算法和分枝搜索算法对问题进行求解.
2. 全局搜索算法
在集束型设备中,为了方便构建算法,提出以下引理:
引理 1. 生产单晶圆类型的集束型设备,使用超过两个单元搬运模式一般都不是最优的搬运策略.
证明. 假设 $T_i^h$ 是在 $s_i$ 搬运模式下的周期时间, $T_i^h$ 表示在 $s_i$ 搬运模式下的周期时间,且有 $T_i^h=T_j^h$ .那么 $2T_i^h$ 就是在 $s_i$ 下生产两个晶圆的时间,而 $2T_j^h$ 为在 $s_j$ 下生产两个晶圆的时间.如果有 $T_i^h\geq T_j^h$ ,则 $2T_i^h\geq T_i^h+T_j^h\geq 2T_j^h$ ;否则,如果 $T_i^h\leq T_j^h$ ,则有 $2T_i^h\leq T_i^h+T_j^h\leq 2T_j^h$ .可知 $T_i^h+T_j^h$ 不可能小于 $\min(2T_i^h,2T_j^h)$ 的,即两种搬运模式的组合一般不是最优策略.对于超过两个周期的情况证法相似.
定理 1.生产单晶圆类型的集束型设备,最优的搬运策略必定是单一的搬运模式.
证明. 假设 $\Omega$ 为所有的搬运策略集合, $\Omega$ 由 $k$ 个集合即 $\{\Omega_1,\Omega_2,\cdots,\Omega_k\}$ 组成,其中 $\Omega_k$ 表示 $k$ 种不同搬运模式组成的搬运策略集合,那么必有最优策略 $X\in\Omega$ .假设定理1不成立,那么有 $X\in\Omega$ . 由引理1可知, $X\in\Omega|k\geq2$ ,则 $X\in {\bf C}_\Omega(\Omega_k)$ , ${\bf C}_\Omega(\Omega_k)$ ,即 $X\in\Omega_1$ ,与假设矛盾.所以定理成立.
由定理1可知,最优搬运模式 $s_i$ 必然存在于有限搬运模式集合 $\{s\}$ .给定的晶圆搬运模式 $s_i$ 里,问题可被描述为前一部分提出的模型.分别用 $u_{ki}$ , $z_{ki}$ 和 $w_{ki}$ 表示在搬运模式 $s_i$ 下的 $u_k$ , $z_k$ 和 $w_k$ .
单晶圆类型的调度搜索算法描述如下:
输入. 搬运时间 $\delta$ 与 $\theta$ ,加工晶圆 $W_j$ 的加工时间 $p_k$ 和驻留约束时间 $a_k$ .
输出. 晶圆 $W_j$ 的最优搬运策略周期时间 $T_j$ .
步骤 1. 载入相关参数,比如 $m$ , $p_k$ , $a_k$ , $\delta$ 和 $\theta$ . 令 $i=0$ , $k=0$ 和 $T=+\infty$ .
步骤 2.令 $i=i+1$ ,如果有 $italic>(m+2) m!||italic>G$ ,那么转到步骤7;否则,转到步骤3.
步骤 3.令 $k=k+1$ ,如果 $k>2m+1$ ,那么转到步骤5;否则,搬运模式为 $s_i$ ,利用式(2) 计算出 $IC(s_i)$ ,利用式(3) 计算出 $z_{ki}$ .
步骤 4.如果满足 $z_{ki}-p_k>a_k$ ,那么转到步骤2;否则,转到步骤3.
步骤 5. 如果 $k$ 为偶数,就令 $w_{ki}=0$ .
步骤 6. 优化的目标函数(4) ,服从约束(5) $\sim$ (8) ,求得所有 $w_{kt}$ 和 $T(s_i)$ .如果 $T(s_i)<T$ ,那么 $T=T(s_i)$ 且 $h=i$ ;否则, $T$ 保持不变.然后转回步骤2.
步骤 7. $s_h$ 就是晶圆 $W_j$ 的最优搬运策略.
3. 下界估算
问题的下界首先被用于提高分枝算法的速度,再被用来验证近似最优解的优劣.该部分松弛驻留约束(7) ,那么原问题就转换为以式(4) 为优化目标函数,并服从约束(5) 、(6) 和(8) 的松弛问题.按照文献 [7-8]的拉式与推式策略结合得到下界估算算法:
步骤 1. 初始化数据,如果 $p_{\max} {\geq2m(\delta+\theta)}$ ,则 $T=p_{\max}+2(\delta+\theta)$ ; 否则,转到步骤2.
步骤 2. 令 $i=1$ , $j=1$ , $K$ 取最大值下标.
步骤 3. $n=i+j$ ,当 $n\leq m$ 时,转步骤4; 否则,当 $j\geq2$ 时转步骤8, $j=1$ 转步骤10.
步骤 4. 若 $n=K$ ,则转步骤6; 否则,转步骤5.
步骤 5. 若 $\sum_i^n{p_i}+(n-i)\delta\leq p_{\max}$ ,则 $j=j+1$ ,转到步骤3;否则,若 $\sum_i^{n-1}{p_i}+(n-1-i)\delta<p_{\max}$ ,转到步骤9;否则, $i=i+1$ , $j=1$ ,转步骤3.
步骤 6. 如果 $\sum_i^{n-1}{p_i}+(n-1-i)\delta\leq p_{\max}$ ,转到步骤7.
步骤 7. $p_i=\sum_i^{K-1}{p_i}+(K-1-i)\delta$ , $p_{i+k}=p_{K-1+k}$ , $m=m+i-K+1$ , $K=i+1$ , $i=K+1$ , $j=1$ ,转到步骤3.
步骤 8.若 $\sum_i^{n-1}{p_i}+(n-1-i)\delta<p_{\max}$ ,转到步骤9,否则 $i=i+1$ , $j=1$ ,转步骤3.
步骤 9. $p_i=\sum_i^{n-1}{p_i}+(n-1-i)\delta$ , $p_{i+k}=p_{n-1+k}$ , $m=m+i-n+1$ , $K=K+i-n+1$ ,若 $p_{\max}\geq2m(\delta+\theta)$ ,则 $T=p_{\max}+2(\delta+\theta)$ ; 否则, $i=i+1$ , $j=1$ ,转到步骤3.
步骤 10. 如果当 $p_{\max}\geq 2m(\delta+\theta)$ ,那么有 $T=p_{\max}+2(\delta+\theta)$ ; 否则, $T=2(m+1) (\delta+\theta)$ .
最后算法得到的最优解即为原问题的下界.
4. 分枝搜索算法
本节对带缓冲的两加工模块的集束型设备详细分析,根据第一节的模型建立数学模型,得到每种搬运模式的周期时间的表达式,最后分析比较各自的周期时间.
当 $s=s_5$ 时, $\varphi(k)$ 、 $\varphi^-(k)$ 、 $u_{k5}$ 和 $λ_k$ 的值如表 1所示.
表 1 $s=s_5$ 时相应参数的值Table 1 The relevant parameter when $s=s_5$$k$ 0 1 2 3 $\varphi(k)$ 0 2 1 3 $\varphi^-(k)$ 0 2 1 3 $u_k5$ $\setminus$ 0 1 0 ${{\lambda }_{k}}$ 1 1 1 1 那么问题可以转化为目标函数:
$\min \sum\limits_{i=1}^{3}{({{w}_{i5}})}$
约束条件为
${{w}_{15}}+{{w}_{25}}\ge \max ({{p}_{1}}-{{z}_{15}},0)\text{ }$
(9) ${{w}_{25}}+{{w}_{35}}\ge \max ({{p}_{2}}-{{z}_{25}},0)\text{ }$
(10) ${{w}_{15}}+{{w}_{35}}\ge \max ({{p}_{3}}-{{z}_{35}},0)\text{ }$
(11) ${{z}_{15}}-{{p}_{1}}\le {{a}_{1}}$
(12) ${{z}_{25}}-{{p}_{2}}\le {{a}_{2}}$
(13) ${{z}_{35}}-{{p}_{3}}\le {{a}_{3}}$
(14) 解得:
${{w}_{15}}=\max ({{p}_{1}}-{{z}_{15}},0)\text{ }$
(15) ${{w}_{25}}=0\text{ }$
(16) ${{w}_{35}}=\max ({{p}_{3}}-{{z}_{35}}-{{w}_{15}},{{p}_{2}}-{{z}_{25}},0)\text{ }$
(17) 搬运模式 $s_5$ 的周期时间为 $T_5$ ,由式(4) 可知:
\begin{align}T_5=IC(s_5) +\sum_{i=1}^3w_{i5} \end{align}
(18) 其中
\begin{align}IC(s_5) =4\delta+4\theta \end{align}
(19) 把式(15) $\sim$ (17) 、(19) 带入式(18) 可得:
\begin{align*}&T_5=4\delta+4\theta+w_{15}+w_{25}+w_{35}=\\&\quad 4\delta+4\theta+w_{15}+\max(p_3-\delta-3\theta-w_{15},0) =\\&\quad 4\delta+4\theta+\max(p_3-\delta-3\theta,w_{15})=\\&\quad 4\delta+4\theta+\max(p_3-\delta-3\theta,\max(p_3-\delta-3\theta,0) )=\\&\quad 3\delta+\theta+\max(p_3,\max(p_1,\delta+3\theta))=\\&\quad 3\delta+\theta+\max(p_3,p_1,\delta+3\theta)\end{align*}
整理后:
\begin{align}T_5=3\delta+\theta+\max(p_3,p_1,\delta+3\theta) \end{align}
(20) 相似地,能分别得到各种搬运模式 $s_1$ , $s_2$ , $s_3$ , $s_4$ , $s_5$ , $s_6$ , $s_7$ , $s_8$ 的周期时间 $T_1$ , $T_2$ , $T_3$ , $T_4$ , $T_5$ , $T_6$ , $T_7$ , $T_8$ 为
${{T}_{1}}=3\delta +{{p}_{1}}+{{p}_{3}}\text{ }$
(21) ${{T}_{2}}=2\delta +\theta +\max ({{p}_{1}},{{p}_{3}},\delta +3\theta )$
(22) ${{T}_{3}}=4\delta +{{p}_{1}}+{{p}_{3}}$
(23) ${{T}_{4}}=2\delta +2\theta +\max ({{p}_{1}}+2\delta +2\theta ,{{p}_{3}})$
(24) ${{T}_{6}}=2\delta +2\theta +\max ({{p}_{1}},{{p}_{3}}+2\delta +2\theta )$
(25) ${{T}_{7}}=3\delta +\theta +\max ({{p}_{1}},{{p}_{3}},\delta +3\theta )$
(26) ${{T}_{8}}=2\delta +2\theta +\max ({{p}_{1}},{{p}_{3}},2\delta +6\theta )$
(27) 定义 3. 若搬运模式 $s_i$ 下的周期时间 $T_i$ 大于或者等于搬运模式 $s_j$ 下的周期时间 $T_j$ ,则可说搬运模式 $s_i$ 受支配于搬运模式 $s_j$ ,即搬运模式 $s_j$ 相对于搬运模式 $s_i$ 具有一定优势.
定理 2. 对于任意的晶圆,在满足驻留约束的前提下,搬运模式 $s_3$ 受支配于搬运模式 $s_1$ ,搬运模式 $s_7$ 受支配于搬运模式 $s_2$ .
证明. 搬运模式 $s_3$ 与搬运模式 $s_1$ 的搬运动作相似,不同之处仅为搬运模式 $s_3$ 比搬运模式 $s_1$ 多了缓冲模块与加工模块之间的搬运.对周期时间进行分析, $T_1=3\delta+p_1+p_3$ 且 $T_3=4\delta+p_1+p_3$ ,有 $T_1<T_3$ ,则对于任意的晶圆,搬运模式 $s_3$ 受支配于搬运模式 $s_1$ .搬运模式 $s_7$ 里搬运模块到缓冲模块进行装卸,而搬运模式 $s_2$ 的晶圆直接跳过缓冲模块,对周期的表达式分析,有 $T_7=T_2+\delta>T_2$ ,则对于任意的晶圆,在满足时间驻留约束的前提下,搬运模式 $s_7$ 受支配于搬运模式 $s_2$ .
定理 3. 对于任意晶圆,在满足驻留约束的前提下,搬运模式 $s_4$ , $s_5$ , $s_6$ , $s_8$ 受支配于搬运模式 $s_2$ .
证明. 将各个搬运模式分别与搬运模式 $s_2$ 进行比较:
1) 由式(22) 与(24) 可知,明显地,有不等式 $\max(p_1,p_3,\delta+3\theta)\leq\max(p_1+2\delta+3\theta,p_3+\theta)$ 成立,可推出 $T_2\leq T_4$ .
2) 由式(22) 与(20) 可得, $T_5=T_2+\delta\geq T_2$ .
3) 推理同1) 类似,由式(22) 与(25) 推得 $T_2\leq T_6$ .
4) 由式(22) 与(27) 可知,明显地,有不等式 $\max(p_1,p_3,\delta+3\theta)\leq\max(p_1+\theta,p_3+\theta,2\delta+7\theta)$ 成立,可以推出 $T_2\leq T_8$ .
总之,在满足驻留约束的前提下,搬运模式 $s_4$ , $s_5$ , $s_6$ , $s_8$ 受支配于搬运模式 $s_2$ .
为更加方便地描述复杂条件,定义了如下的逻辑表达:
\begin{align*}&A(x)=\{x\leq 4\theta\}\\[1mm]&B(x)=\{x\geq 4\theta\}\\[1mm]&C(x,y)=\{\max(x,y)\leq 2\delta+6\theta\}\\[1mm]&D(x,y)=\{\max(x,y)\geq 2\delta+6\theta\}\\[1mm]&E(x,y)=\{(x-y)\leq 2\delta+6\theta\}\\[1mm]&F(x,y)=\{(x-y)\geq 2\delta+6\theta\}\\[1mm]&g(x,y)=\{[A(y)\cap C(x,y)\cap E(x,y)]\cup\\[1mm]&\qquad [C(x,y)\cap F(x,y)]\}\\[1mm]&h(x,y)=\{D(x,y)\cup[B(y)\cap C(x,y)\cap E(x,y)]\}\end{align*}
定理 4. 搬运模式之间的周期时间存在如下的大小关系:
1) $T_1\leq T_2\Leftrightarrow p_1+p_3\leq 4\theta$ 而 $T_1\geq T_2\Leftrightarrow p_1+p_3\geq 4\theta$ .
2) $T_1\leq T_4\Leftrightarrow p_1\leq 2\theta-\delta\Arrowvert p_3\leq 4\theta+\delta$ 而 $T_1\geq T_4\Leftrightarrow p_1\geq2\theta-\delta~\&~p_3\geq 4\theta+\delta$ .
3) $T_1\leq T_5\Leftrightarrow p_1\leq\theta\Arrowvert p_3\leq\theta\Arrowvert p_1+p_3\leq\delta+3\theta$ 而 $T_1\geq T_5\Leftrightarrow p_1\geq\theta~\&~ p_3\geq\theta ~\&~p_1+p_3\geq\delta+3\theta$ .
4) $T_1\leq T_6\Leftrightarrow p_1\leq4\theta+\delta\Arrowvert p_3\leq 2\theta-\delta$ 而 $T_1\geq T_6\Leftrightarrow p_1\geq4\theta+\delta~\&~ p_3\geq 2\theta-\delta$ .
5) $T_1\leq T_8\Leftrightarrow \max(p_1,p_3) \leq2\theta-\delta\Arrowvert p_1+p_3\leq\delta+8\theta$ 而 $T_1\geq T_8\Leftrightarrow \max(p_1,p_3) \geq 2\theta-\delta~\&~p_1+p_3\geq\delta+8\theta$ .
6) $T_4\leq T_5\Leftrightarrow p_3-p_1\geq3\theta+\delta$ 而 $T_4\geq T_5\Leftrightarrow p_3-p_1\leq3\theta+\delta$ .
7) $T_4\leq T_6\Leftrightarrow p_1\leq p_3$ 而 $T_4\leq T_6\Leftrightarrow p_1\leq p_3$ .
8) $T_4\leq T_7\Leftrightarrow p_3-p_1\geq3\theta+\delta$ 而 $T_4\geq T_7\Leftrightarrow p_3-p_1\leq3\theta+\delta$ .
9) $T_4\leq T_8\Leftrightarrow g(p_3,p_1) $ 而 $T_4\geq T_8\Leftrightarrow h(p_3,p_1) $ .
10) $T_5\leq T_6\Leftrightarrow p_1-p_3\leq2\theta+2\delta$ 而 $T_5\geq T_6\Leftrightarrow p_1-p_3\geq2\theta+2\delta$ .
11) $T_5\leq T_8\Leftrightarrow \max(p_1,p_3) \leq2\theta+6\delta$ 而 $T_5\geq T_8\Leftrightarrow \max(p_1,p_3) \geq2\theta+6\delta$ .
12) $T_6\leq T_8\Leftrightarrow g(p_1,p_3) $ 而 $T_6\leq T_8\Leftrightarrow h(p_1,p_3) $ .
证明. 1) 从式(21) 与(22) 可知,若有 $T_1\leq T_2\Rightarrow\delta+p_1+p_3\leq\max(p_1+\theta,p_3+\theta,\delta+4\theta)$ ,由于 $\delta$ 表示晶圆移动时间而 $\theta$ 表示机械手空移动,存在 $\delta\geq\theta$ .由于 $\delta+p_1+p_3\leq\max(p_1+\theta,p_3+\theta)$ 始终成立,则需有 $\delta+p_1+p_3\leq \delta +4\theta\Rightarrow p_1+p_3\leq4\theta$ . 相似地, $T_1\geq T_2$ 需满足条件 $p_1+p_3\geq 4\theta$ .其他2) $\sim$ 12) 都可用类似的方法推理得到.
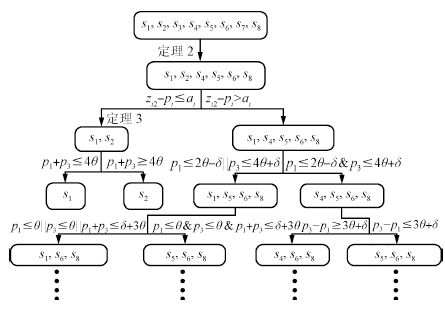
根据定理2 $\sim$ 4,结合单晶圆类型调度的全局搜索算法,首先利用驻留约束确定 $s_2$ 的可行性得到两个分枝,其中的第一分枝利用定理2和定理3里的支配关系排除了 $s_4$ , $s_5$ , $s_6$ , $s_7$ , $s_8$ ,第二分枝利用定理4的条件分析再进行分枝.图 2为改进型搜索决策树示例.
5. 实验分析
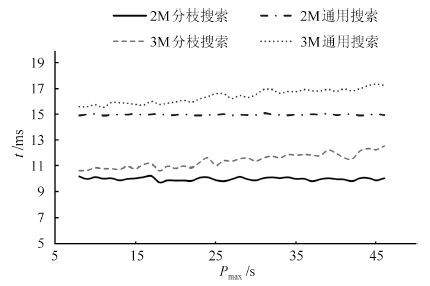
为了对带缓冲的集束型设备进行评价,把不带缓冲的集束型设备用于对比分析. 运用量化的分析方法,为带有缓冲的单臂集束型设备相对于无缓冲的集束型设备的产能提高提供了较为可靠的数据.本节中假设 $\delta=4$ , $\theta=2$ , $a_i=5$ 为最基本的实验条件.由于增加缓冲的优势主要体现在最大加工时间的加工模块上,所以有 $p_{\max}=\max_{1\leq i\leq 2m}\{p_i\}$ .用C++分别对两种算法进行编程,统计50组算例数据,求得平均的结果,并对比两种算法的数值实验结果. 图 3为两种算法所需的时间,可以看出分枝搜索的速度会比全局搜索算法更加优越.但图 4表明在小规模时,两种算法都能得到较好的结果.
将本文提出的算法与文献[13]的算法进行比较. 取加工时间为 $p_i\sim{\rm N}(60,2.5^2) $ ,如图 5所示为算法之间调度结果的比较.
由图 5可知,在小规模问题时,本文的算法与文献的算法得到的解基本相同,但随着规模的增加,本文的算法呈现出较为明显的优势,得到的解更优.
本文定义了提高率 $R$ 来评价带缓冲模块相对于无缓冲模块的系统之间产量提高:
$R=\frac{C{{T}_{G}}-C{{T}_{B}}}{C{{T}_{B}}}\times 100\%$
上式表示的是带缓冲的集束型设备与无缓冲的设备的集束型设备产能的提高率.其中 $R$ 越大,表示提高率越大.其中 $CT_B$ 代表带缓冲的集束型设备的周期时间,而 $CT_G$ 为无缓冲的集束型设备的周期时间. $Bd={p_{\max}}/{(\delta+\theta)}$ 表示搬运模块的繁忙程度, $Bd$ 越大表示搬运块模块越空闲.
5.1 生产率的提高与机械手的繁忙程度的关系
令机械手繁忙程度 $Bd$ 取[0,10]的均匀分布,通过仿真分析,得到如图 6的结果.
 图 6 生产率提高与搬运模块繁忙程度的关系Fig. 6 The relationship of improvement rates with the busy degree of TM
图 6 生产率提高与搬运模块繁忙程度的关系Fig. 6 The relationship of improvement rates with the busy degree of TM分析图 6可知,对于两集束型而言,仅当 $Bd\geq3$ 时,产能的提高率为正数,即仅当搬运模块繁忙程度 $Bd\geq3$ 时,缓冲模块能提高集束型设备的产能. 相反,当搬运模块繁忙程度 $Bd\leq3$ 时,产能提高率小于零,说明缓冲模块不提高产能,而对于三集束型而言, $Bd$ 的临界值为 $3.1$ .同时随着产能提高率的减少,最大加工时间 $p_{\max}$ 也相应减少,故TM在PM上等待时间也相应减少,直到晶圆加工完毕.若晶圆在PM上的等待搬运的时间大于驻留约束,那么搬运模块的搬运模式必须改变; 否则,晶圆会出现质量问题.无论搬运模块的繁忙程度如何的变化,最后TM都会处于搬运模式 $s_1$ ,说明在缓冲模块上的晶圆增加了额外的搬运.
5.2 生产率的提高与加工模块的加工时间的关系
设置变量 $P={p_t}/{(\delta+\theta)}$ ,然后令 $Bd$ 分布取均匀分布[3, 9]. 经过仿真分析,得到结果如图 7所示.
 图 7 生产率提高与加工时间之间的关系Fig. 7 The relationship of improvement rates with processing time of PMs
图 7 生产率提高与加工时间之间的关系Fig. 7 The relationship of improvement rates with processing time of PMs由图 7可知,在所有的搬运模块繁忙程度中,产能提高率从不稳定改变到达稳定的状态.主要原因在于随着模块加工时间的增加,搬运模块空闲使得加工模块的驻留约束的影响被降低.
6. 结论
本文针对带缓冲模块的集束型设备的调度问题建立了数学模型,构建全局搜索算法. 再通过具体分析两集束型设备,提出了分枝搜索算法.最后经仿真表明,分枝搜索算法比全局搜索算法更加迅速.同时通过和文献[13]的调度算法进行对比,表明本文的算法在加工模块比较少的时候调度结果提高不多,但随着规模增大,本文所得到的结果有明显的优势.通过对比带缓冲的集束型设备与无缓冲的集束型设备,证明了在加工模块之间增加缓冲,在一定程度上可以提高单臂集束型设备的产能.基于实验数据,仅当搬运模块TM的繁忙程度 $Bd$ 大于阈值时,设备产能才会提高.实验还表明驻留约束对于产能提高的影响是通过约束限制状态的改变产生的.随着加工模块的加工时间不断增加,产能提高越来越不显著,系统产能渐渐趋于平稳状态.
-

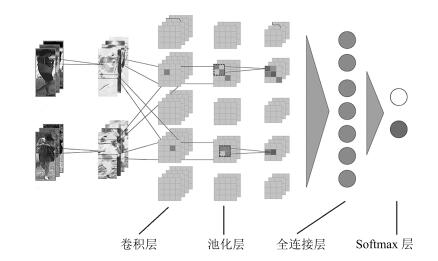
图 5 基于深度学习的行人再识别方法的三种方式
Fig. 5 Three ways of deep learning-based person re-identification
表 1 典型行人图像分割方法
Table 1 Typical segmentation methods of pedestrian image
分割方式 对应文献 主要思想 上下半身分割 [3, 5] 提取行人的前景图像, 分成头部、躯干和腿部三部分.对后两部分计算垂直对称轴.对提取的特征根据与垂直对称轴的距离进行加权, 从而减少行人姿态变化的影响.缺点是分割过程过于复杂. 条纹分割 [6-7] 分成六个水平条, 分别对应于行人头部、水平躯干的上下部、腿部的上下部分.然后提取水平条内的ELF特征, 减少了视角变化对识别的影响.缺点是会造成水平条内空间细节信息的损失. 滑动窗分割 [8] 利用滑动窗来描述行人图像的局部细节信息, 在每个滑动窗内提取颜色和纹理特征.缺点是特征维数过大. 三角形分割 [2] 利用局部运动特征对行人图像进行三角形时空分割.缺点是分割结果不够准确.  下载: 导出CSV
下载: 导出CSV
表 2 Market-1501数据集上不同深度模型对首轮识别率的影响
Table 2 Rank-1 matching rates of different deep models in Market-1501
下载: 导出CSV
表 5 行人再识别图像数据集上取得优异性能的方法对比
Table 5 Comparison of state-of-the-art methods on image-based person re-identification datasets
数据集 算法 人工设计/深度学习 rank-1(%) rank-5(%) rank-10(%) rank-20(%) 年份 SCSP[66] 人工 53.5 82.6 91.5 96.6 2016年 VIPeR FFN[50] 深度 51.1 81 91.4 96.9 2016年 HIPHOP[58] 深度 54.2 82.4 91.5 96.9 2017年 Zhang等[63] 人工 65 85 89.9 94.4 2016年 CUHK01 FFN 深度 55.5 78.4 83.7 92.6 2016年 HIPHOP 深度 78.8 92.6 95.3 97.8 2017年 Zheng等[64] 深度 85.8 94.4 96.4 97.5 2016年 Market-1501 SOMAnet[67] 深度 81.3 92.6 95.3 97.1 2017年 WARCA[68] 人工 45.1 68.1 76 84 2016年
下载: 导出CSV
表 6 行人再识别视频数据集上取得优异性能的方法对比
Table 6 Comparison of state-of-the-art methods on video-based person re-identification datasets
数据集 算法 人工设计/深度学习 rank-1 (%) rank-5 (%) rank-10 (%) rank-20 (%) 年份 zhang等[60] 深度 83.3 93.3 - 96.7 2017年 PRID-2011 McLaughlin等[45] 深度 70 90 95 97 2016年 TAPR[24] 人工 68.6 94.6 97.4 98.9 2016年 Zhang等[60] 深度 60.2 85.1 - 94.2 2017年 iLIDS-VID McLaughlin等[45] 深度 58 84 91 96 2016年 TAPR 人工 55 87.5 93.8 97.2 2016年 Zhang等[60] 深度 55.5 70.2 - 80.2 2017年 MARS CNN+XQDA[4] 深度 65.3 80.2 - 89 2016年 LOMO+XQDA[4] 人工 30.7 46.6 - 60.9 2016年
下载: 导出CSV
-
[1] Porikli F.Inter-camera color calibration by correlation model function.In: Proceedings of the 2003 International Conference on Image Processing.Barcelona, Spain: IEEE, 2003.Ⅱ-133-6 [2] Gheissari N, Sebastian T B, Hartley R.Person reidentification using spatiotemporal appearance.In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.New York, USA: IEEE, 2006.1528-1535 [3] Farenzena M, Bazzani L, Perina A, Murino V, Cristani M.Person re-identification by symmetry-driven accumulation of local features.In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition.San Francisco, CA, USA: IEEE, 2010.2360-2367 [4] Zheng L, Bie Z, Sun Y F, Wang J D, Su C, Wang S J, et al.MARS: a video benchmark for large-scale person re-identification.In: Proceedings of the 14th European Conference on Computer Vision.Amsterdam, Netherlands: Springer, 2016.868-884 [5] Bazzani L, Cristani M, Murino V.Symmetry-driven accumulation of local features for human characterization and re-identification.Computer Vision and Image Understanding, 2013, 117 (2):130-144 doi: 10.1016/j.cviu.2012.10.008 [6] Gray D, Tao H.Viewpoint invariant pedestrian recognition with an ensemble of localized features.In: Proceedings of the 10th European Conference on Computer Vision.Marseille, France: Springer, 2008.262-275 [7] Zheng W S, Gong S G, Xiang T.Reidentification by relative distance comparison.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (3):653-668 doi: 10.1109/TPAMI.2012.138 [8] Liao S C, Hu Y, Zhu X Y, Li S Z.Person re-identification by local maximal occurrence representation and metric learning.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, MA, USA: IEEE, 2015.2197-2206 [9] Zeng M Y, Wu Z M, Tian C, Zhang L, Hu L.Efficient person re-identification by hybrid spatiogram and covariance descriptor.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops.Boston, MA, USA: IEEE, 2015.48-56 [10] Ma B P, Su Y, Jurie F.Covariance descriptor based on bio-inspired features for person re-identification and face verification.Image and Vision Computing, 2014, 32(6-7):379-390 doi: 10.1016/j.imavis.2014.04.002 [11] Matsukawa T, Okabe T, Suzuki E, Sato Y.Hierarchical Gaussian descriptor for person re-identification.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1363-1372 [12] Zhao R, Ouyang W L, Wang X G.Person re-identification by saliency learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (2):356-370 doi: 10.1109/TPAMI.2016.2544310 [13] Kviatkovsky I, Adam A, Rivlin E.Color invariants for person reidentification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35 (7):1622-1634 doi: 10.1109/TPAMI.2012.246 [14] 齐美彬, 檀胜顺, 王运侠, 刘皓, 蒋建国.基于多特征子空间与核学习的行人再识别.自动化学报, 2016, 42 (2):229-308 http://www.aas.net.cn/CN/abstract/abstract18819.shtmlQi Mei-Bin, Tan Sheng-Shun, Wang Yun-Xia, Liu Hao, Jiang Jian-Guo.Multi-feature subspace and kernel learning for person re-identification.Acta Automatica Sinica, 2016, 42 (2):229-308 http://www.aas.net.cn/CN/abstract/abstract18819.shtml [15] Zhao R, Ouyang W L, Wang X G.Unsupervised salience learning for person re-identification.In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland, OR, USA: IEEE, 2013.3586-3593 [16] Zhao R, Ouyang W L, Wang X G.Learning mid-level filters for person re-identification.In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus, OH, USA: IEEE, 2014.144-151 [17] Gong S G, Cristani M, Yan S C, Loy C C.Person Re-Identification.London:Springer, 2014.139-160 [18] Layne R, Hospedales T M, Gong S G.Person re-identification by attributes.In: Proceedings of the 2012 British Machine Vision Conference.Surrey, UK: BMVA Press, 2012. [19] Shi Z Y, Hospedales T M, Xiang T.Transferring a semantic representation for person re-identification and search.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, MA, USA: IEEE, 2015.4184-4193 [20] Su C, Yang F, Zhang S L, Tian Q, Davis L S, Gao W.Multi-task learning with low rank attribute embedding for person re-identification.In: Proceedings of the 2015 IEEE International Conference on Computer Vision.Santiago, Chile: IEEE, 2015.3739-3747 [21] Caruana R A.Multitask learning: a knowledge-based source of inductive bias.In: Proceedings of the 10th International Conference on Machine Learning.Amherst, USA: Elsevier, 1993.41-48 [22] Gray D, Brennan S, Tao H.Evaluating appearance models for recognition, reacquisition, and tracking.In: Proceedings of the 10th International Workshop on Performance Evaluation for Tracking and Surveillance.Rio de Janeiro, Brazil: IEEE, 2007.1-7 [23] You J J, Wu A C, Li X, Zheng W S.Top-push video-based person re-identification.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1345-1353 [24] Gao C X, Wang J, Liu L Y, Yu J G, Sang N.Temporally aligned pooling representation for video-based person re-identification.In: Proceedings of the 2016 International Conference on Image Processing.Phoenix, AZ, USA: IEEE, 2016.4284-4288 [25] Wang T Q, Gong S G, Zhu X T, Wang S J.Person re-identification by video ranking.In: Proceedings of the 13th European Conference on Computer Vision.Zurich, Switzerland: Springer, 2014.688-703 [26] Man J, Bhanu B.Individual recognition using gait energy image.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28 (2):316-322 doi: 10.1109/TPAMI.2006.38 [27] Klaser A, Marszalek M, Schmid C.A spatio-temporal descriptor based on 3D-gradients.In: Proceedings of the 19th British Machine Vision Conference.Leeds, UK: British Machine Vision Association, 2008, 275: 1-10 [28] Bhattachayya A.On a measure of divergence between two statistical populations defined by their probability distributions.Bulletin Calcutta Mathematical Society, 1943, 35:99-109 https://www.sciencedirect.com/science/article/pii/0022247X89903351 [29] De Maesschalck R, Jouan-Rimbaud D, Massart D L.The mahalanobis distance.Chemometrics and Intelligent Laboratory Systems, 2000, 50 (1):1-18 doi: 10.1016/S0169-7439(99)00047-7 [30] Xing E P, Ng A Y, Jordan M I, Russell S J.Distance metric learning, with application to clustering with side-information.In: Proceedings of the 15th International Conference on Neural Information Processing Systems.Cambridge, MA, USA: MIT Press, 2002.521-528 [31] Zheng W S, Gong S G, Xiang T.Person re-identification by probabilistic relative distance comparison.In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition.Colorado Springs, CO, USA: IEEE, 2011.649-656 [32] Weinberger K Q, Saul L K.Fast solvers and efficient implementations for distance metric learning.In: Proceedings of the 25th International Conference on Machine Learning.Helsinki, Finland: ACM, 2008.1160-1167 [33] Davis J V, Kulis B, Jain P, Sra S, Dhillon I S.Information-theoretic metric learning.In: Proceedings of the 24th International Conference on Machine Learning.Corvalis, Oregon, USA: ACM, 2007.209-216 [34] Guillaumin M, Verbeek J, Schmid C.Is that you? Metric learning approaches for face identification.In: Proceedings of the 12th International Conference on Computer Vision.Kyoto, Japan: IEEE, 2009.498-505 [35] Köestinger M, Hirzer M, Wohlhart P, Roth P M, Bischof H.Large scale metric learning from equivalence constraints.In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition.Providence, RI, USA: IEEE, 2012.2288-2295 [36] Karanam S, Li Y, Radke R J.Sparse re-id: block sparsity for person re-identification.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops.Boston, MA, USA: IEEE, 2015.33-40 [37] Karanam S, Li Y, Radke R J.Person re-identification with discriminatively trained viewpoint invariant dictionaries.In: Proceedings of the 2015 IEEE International Conference on Computer Vision.Santiago, Chile: IEEE, 2015.4516-4524 [38] Krizhevsky A, Sutskever I, Hinton G E.Imagenet classification with deep convolutional neural networks.In: Proceedings of the 25th International Conference on Neural Information Processing Systems.Lake Tahoe, Nevada, USA: Curran Associates Inc., 2012.1097-1105 [39] 管皓, 薛向阳, 安志勇.深度学习在视频目标跟踪中的应用进展与展望.自动化学报, 2016, 42 (6):834-847 http://www.aas.net.cn/CN/abstract/abstract18874.shtmlGuan Hao, Xue Xiang-Yang, An Zhi-Yong.Advances on application of deep learning for video object tracking.Acta Automatica Sinica, 2016, 42 (6):834-847 http://www.aas.net.cn/CN/abstract/abstract18874.shtml [40] 常亮, 邓小明, 周明全, 武仲科, 袁野, 杨硕, 等.图像理解中的卷积神经网络.自动化学报, 2016, 42 (9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtmlChang Liang, Deng Xiao-Ming, Zhou Ming-Quan, Wu Zhong-Ke, Yuan Ye, Yang Shuo, et al.Convolutional neural networks in image understanding.Acta Automatica Sinica, 2016, 42 (9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtml [41] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃.深度学习在控制领域的研究现状与展望.自动化学报, 2016, 42 (5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtmlDuan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue.Deep learning for control:the state of the art and prospects.Acta Automatica Sinica, 2016, 42 (5):643-654 http://www.aas.net.cn/CN/abstract/abstract18852.shtml [42] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊.深度学习在手写汉字识别中的应用综述.自动化学报, 2016, 42 (8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtmlJin Lian-Wen, Zhong Zhuo-Yao, Yang Zhao, Yang Wei-Xin, Xie Ze-Cheng, Sun Jun.Applications of deep learning for handwritten Chinese character recognition:a review.Acta Automatica Sinica, 2016, 42 (8):1125-1141 http://www.aas.net.cn/CN/abstract/abstract18903.shtml [43] Li W, Zhao R, Xiao T, Wang X G.DeepReID: deep filter pairing neural network for person re-identification.In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus, OH, USA: IEEE, 2014.152-159 [44] Ahmed E, Jones M, Marks T K.An improved deep learning architecture for person re-identification.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, MA, USA: IEEE, 2015.3908-3916 [45] McLaughlin N, Martinez Del Rincon J, Miller P.Recurrent convolutional network for video-based person re-identification.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1325-1334 [46] Yan Y C, Ni B B, Song Z C, Ma C, Yan Y, Yang X K.Person re-identification via recurrent feature aggregation.In: Proceedings of the 14th European Conference on Computer Vision.Amsterdam, Netherlands: Springer, 2016.701-716 [47] Cheng D, Gong Y H, Zhou S P, Wang J J, Zheng N N.Person re-identification by multi-channel parts-based CNN with improved triplet loss function.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1335-1344 [48] Wu S X, Chen Y C, Li X, Wu A C, You J J, Zheng W S.An enhanced deep feature representation for person re-identification.In: Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision.Lake Placid, NY, USA: IEEE, 2016.1-8 [49] Li Y J, Zhuo L, Hu X C, Zhang J.A combined feature representation of deep feature and hand-crafted features for person re-identification.In: Proceedings of the 2016 International Conference on Progress in Informatics and Computing.Shanghai, China: IEEE, 2016.224-227 [50] Chan T H, Jia K, Gao S H, Lu J W, Zeng Z N, Ma Y.PCANet:a simple deep learning baseline for image classification? IEEE Transactions on Image Processing, 2015, 24 (12):5017-5032 http://d.old.wanfangdata.com.cn/Periodical/dianzixb201608028 [51] Zheng L, Wang S J, Tian L, He F, Liu Z Q, Tian Q.Query-adaptive late fusion for image search and person re-identification.In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston, MA, USA: IEEE, 2015.1741-1750 [52] Zheng L, Huang Y J, Lu H C, Yang Y.Pose invariant embedding for deep person re-identification.arXiv preprint, arXiv: 1701.07732, 2017. [53] He K M, Zhang X Y, Ren S Q, Sun J.Deep residual learning for image recognition.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.770-778 [54] Zheng L, Zhang H H, Sun S Y, Chandraker M, Yang Y, Tian Q.Person re-identification in the wild.arXiv preprint, arXiv: 1604.02531, 2016. [55] Zheng L, Shen L Y, Tian L, Wang S L, Wang J D, Tian Q.Scalable person re-identification: a benchmark.In: Proceedings of the 2015 IEEE International Conference on Computer Vision.Santiago, Chile: IEEE, 2015.1116-1124 [56] Simonyan K, Zisserma A.Very deep convolutional networks for large-scale image recognition.arXiv preprint, arXiv: 1409.1556, 2014. [57] Hermans A, Beyer L, Leibe B.In defense of the triplet loss for person re-identification.arXiv preprint, arXiv: 1703.07737, 2017. [58] Chen Y C, Zhu X T, Zheng W S, Lai J H.Person re-identification by camera correlation aware feature augmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40 (2):392-408 doi: 10.1109/TPAMI.2017.2666805 [59] Li W, Zhao R, Wang X G.Human reidentification with transferred metric learning.In: Proceedings of the 11th Asian Conference on Computer Vision.Daejeon, Korea: Springer, 2012.31-44 [60] Zhang W, Hu S N, Liu K.Learning compact appearance representation for video-based person re-identification.arXiv preprint, arXiv: 1702.06294, 2017. [61] Su C, Zhang S L, Xing J L, Gao W, Tian Q.Deep attributes driven multi-camera person re-identification.In: Proceedings of the 14th European Conference on Computer Vision.Amsterdam, Netherlands: Springer, 2016.475-491 [62] Zhu J Q, Liao S C, Yi D, Lei Z, Li S Z.Multi-label CNN based pedestrian attribute learning for soft biometrics.In: Proceedings of the 2015 International Conference on Biometrics.Phuket, Thailand: IEEE, 2015.535-540 [63] Zhang L, Xiang T, Gong S G.Learning a discriminative null space for person re-identification.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1239-1248 [64] Zheng Z D, Zheng L, Yang Y.A discriminatively learned CNN embedding for person re-identification.arXiv preprint, arXiv: 1611.05666, 2016. [65] Hirzer M, Beleznai C, Roth P M, Bischof H.Person re-identification by descriptive and discriminative classification.In: Proceedings of the 17th Scandinavian Conference on Image Analysis.Ystad, Sweden: Springer, 2011.91-102 [66] Chen D P, Yuan Z J, Chen B D, Zheng N N.Similarity learning with spatial constraints for person re-identification.In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas, NV, USA: IEEE, 2016.1268-1277 [67] Barbosa I B, Cristani M, Caputo B, Rognhaugen A, Theoharis T.Looking beyond appearances: synthetic training data for deep CNNs in re-identification.arXiv preprint, arXiv: 1701.03153, 2017. [68] Jose C, Fleuret F.Scalable metric learning via weighted approximate rank component analysis.In: Proceedings of the 14th European Conference on Computer Vision.Amsterdam, Netherlands: Springer, 2016.875-890 [69] Yu D, Li J.Recent progresses in deep learning based acoustic models.IEEE/CAA Journal of Automatica Sinica, 2017, 4(3), 396-409 doi: 10.1109/JAS.2017.7510508 期刊类型引用(6)
1. 黄年昌,杨阳,张强,韩军功. 基于深度学习的RGB-D图像显著性目标检测前沿进展. 计算机学报. 2025(02): 284-316 .  百度学术
百度学术2. 闫梦凯,钱建军,杨健. 弱对齐的跨光谱人脸检测. 自动化学报. 2023(01): 135-147 . 本站查看3. 王利锋,辛丽平,刘家硕,鞠莲. 基于热红外视频图像监测的海面溢油识别技术研究. 海洋学报. 2022(05): 148-160 . 百度学术4. 蔺素珍,张海松,禄晓飞,李大威,李毅. RBNSM:一种复杂背景下红外弱小目标检测新方法. 红外技术. 2022(07): 667-675 . 百度学术5. 刘晓玲,牛海春,宋海燕,秦富贞. 复杂环境下弱信号中的红外小目标自动检测. 激光杂志. 2020(10): 82-86 . 百度学术6. 刘松涛,姜康辉,刘振兴. 基于区域协方差和目标度的航空侦察图像舰船目标检测. 系统工程与电子技术. 2019(05): 972-980 . 百度学术其他类型引用(2)
-


 下载:
下载:




计量
- 文章访问数: 3799
- HTML全文浏览量: 2403
- PDF下载量: 2247
- 被引次数: 8
