

Multi-view Learning and Reconstruction Algorithms via Generative Adversarial Networks
-
摘要: 同一事物通常需要从不同角度进行表达.然而,现实应用经常引出复杂的场景,导致完整视图数据很难获得.因此研究如何构建事物的完整视图具有重要意义.本文提出一种基于生成对抗网络(Generative adversarial networks,GAN)的多视图学习与重构算法,利用已知单一视图,通过生成式方法构建其他视图.为构建多视图通用的表征,提出新型表征学习算法,使得同一实例的任意视图都能映射至相同的表征向量,并保证其包含实例的重构信息.为构建给定事物的多种视图,提出基于生成对抗网络的重构算法,在生成模型中加入表征信息,保证了生成视图数据与源视图相匹配.所提出的算法的优势在于避免了不同视图间的直接映射,解决了训练数据视图不完整问题,以及构造视图与已知视图正确对应问题.在手写体数字数据集MNIST,街景数字数据集SVHN和人脸数据集CelebA上的模拟实验结果表明,所提出的算法具有很好的重构性能.Abstract: Generally, objects often require to represent in different views. However, real-world applications in complex scenarios can hardly have complete views of a given object. In this paper, we propose generative adversarial network (GAN) based multi-view learning and reconstruction algorithms. A novel representation learning algorithm is proposed, which guarantees different views of the same object are mapped to the same representation. Meanwhile, the algorithm guarantees the representation carries enough reconstructed information. To construct multi-views of a given object, a generative adversarial network based reconstruction algorithm is proposed, which includes the representation information in the generation and discrimination models to guarantee the constructed views perfectly map the source view. The merits of the proposed algorithms lie in the fact that they avoid direct mapping among different views, and can solve the problem of missing views in training data and the problem of mapping between constructed views and the source views. Simulated experiments on handwritten digit dataset (MNIST), street view house numbers dataset (SVHN) and CelebFaces attributes dataset (CelebA) indicate that the proposed algorithms yield satisfactory reconstruction performances.1) 本文责任编委 王坤峰
-
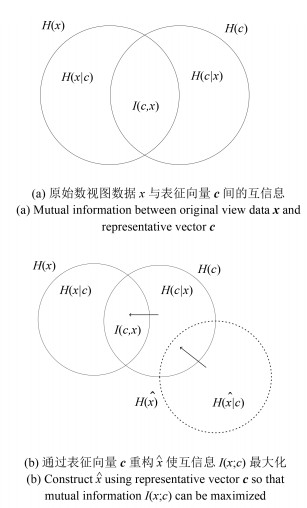
图 2 原始视图数据$x$, 表征向量$\pmb c$, 重构视图数据$\hat{x}$间的互信息示意图
Fig. 2 Schematic diagram of mutual information among original view data $x$, representative vector $\pmb c$, reconstructed data $\hat{x}$
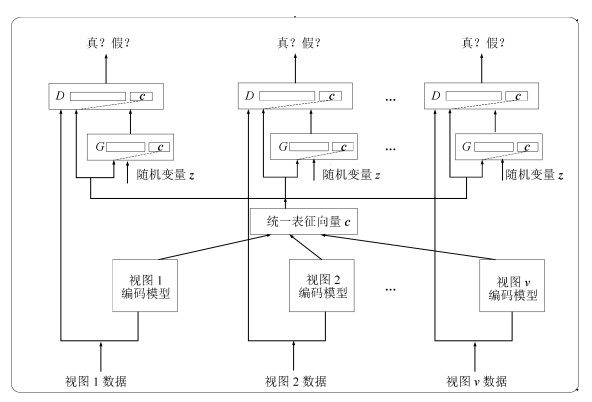
图 3 基于生成对抗网络的多视图数据生成框架
Fig. 3 Framework of the generative adversarial network based multi-view data generation

图 5 以视图2为源数据在MNIST上的重构结果
Fig. 5 Reconstruction results that take view 2 as source data on MNIST

图 6 以视图3为源数据在MNIST上的重构结果
Fig. 6 Reconstruction results that take view 3 as source data on MNIST

图 7 以视图2为源数据在SVHN上的重构结果
Fig. 7 Reconstruction results that take view 2 as source data on SVHN

图 8 以视图3为源数据在SVHN上的重构结果
Fig. 8 Reconstruction results that take view 3 as source data on SVHN

图 9 以视图2为源数据在CelebA上的重构结果
Fig. 9 Reconstruction results that take view 2 and view 3 as source data respectively on CelebA
表 1 MNIST数据集上的SSIM和PSNR比较结果
Table 1 Comparison results of SSIM and PSNR on MNIST
算法 SSIM值 PSNR值(dB) MVGAN (视图2重构视图1) 0.8520±0.0001 16.3135±0.0880 MVGAN (视图3重构视图1) 0.6474±0.0013 12.2109±0.1442 CGAN 0.7414±0.0001 12.0301±0.0512 CVAE 0.7912±0.0031 12.1184±0.0013  下载: 导出CSV
下载: 导出CSV
表 2 SVHN数据集上的SSIM和PSNR比较结果
Table 2 Comparison results of SSIM and PSNR on SVHN
算法 SSIM值 PSNR值(dB) MVGAN (视图2重构视图1) 0.4140±0.0022 18.7987±0.1475 MVGAN (视图3重构视图1) 0.1848±0.0020 15.8026±0.1306 CGAN 0.3357±0.0017 14.8910±0.0002 CVAE 0.3465±0.0028 15.0137±0.0071
下载: 导出CSV
表 3 CelebA视图2和视图3对应选中的10维属性
Table 3 The chosen attributes for view 2 and view 3 (10 dimensions)
图片编号 秃顶 刘海 黑发 眼镜 男性 嘴微张 窄眼 无胡须 苍白肤色 戴帽 a -1 -1 -1 1 1 -1 -1 -1 -1 -1 b -1 -1 1 -1 1 -1 -1 -1 -1 -1 c -1 -1 1 -1 1 -1 -1 1 -1 -1 d -1 -1 1 -1 1 1 -1 1 -1 -1 e -1 -1 -1 -1 -1 -1 -1 1 -1 -1 f -1 -1 -1 -1 -1 -1 -1 1 1 -1 g -1 -1 -1 -1 1 -1 -1 1 -1 -1 h -1 -1 -1 -1 -1 1 -1 1 -1 -1 i -1 -1 -1 -1 -1 -1 -1 1 -1 -1 j -1 -1 -1 -1 1 1 1 1 1 -1 k -1 1 -1 -1 1 -1 -1 1 -1 -1 l -1 -1 -1 -1 -1 1 -1 1 -1 -1 m -1 -1 -1 -1 -1 1 -1 1 -1 -1 n -1 -1 -1 -1 1 1 -1 -1 -1 -1 o -1 1 1 -1 1 1 -1 1 -1 -1
下载: 导出CSV
表 4 CelebA数据集上的SSIM和PSNR比较结果
Table 4 Comparison results of SSIM and PSNR on CelebA
算法 SSIM值 PSNR值(dB) MVGAN (视图2重构视图1) 0.1143±0.0023 10.0574±0.0605 MVGAN (视图3重构视图1) 0.1132±0.0022 10.0342±0.0587 CGAN 0.0512±0.0036 9.5312±0.0012 CVAE 0.0716±0.0058 9.7881±0.0020
下载: 导出CSV
-
[1] Chaudhuri K, Kakade S M, Livescu K, Sridharan K. Multi-view clustering via canonical correlation analysis. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Canada: ACM, 2009. 129-136 [2] Kumar A, Daume Ⅲ H. A co-training approach for multi-view spectral clustering. In: Proceedings of the 28th International Conference on Machine Learning. Washington, USA: Omnipress, 2011. 393-400 [3] Wang W R, Arora R, Livescu K, Bilmes J. On deep multi-view representation learning. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: ICML, 2015. 1083-1092 [4] Sun S L. A survey of multi-view machine learning. Neural Computing and Applications, 2013, 23(7-8):2031-2038 doi: 10.1007/s00521-013-1362-6 [5] White M, Yu Y L, Zhang X H, Schuurmans D. Convex multi-view subspace learning. In: Proceedings of the 25th Annual Conference on Neural Information Processing Systems. Lake Tahoe, USA: NIPS, 2012. 1673-1681 [6] Guo Y H. Convex subspace representation learning from multi-view data. In: Proceedings of the 27th AAAI Conference on Artificial Intelligence. Washington, USA: AIAA, 2013. 387-393 [7] Shekhar S, Patel V M, Nasrabadi N M, Chellappa R. Joint sparse representation for robust multimodal biometrics recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(1):113-126 doi: 10.1109/TPAMI.2013.109 [8] Gangeh M J, Fewzee P, Ghodsi A, Kamel M S, Karray F. Multiview supervised dictionary learning in speech emotion recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(6):1056-1068 doi: 10.1109/TASLP.2014.2319157 [9] Zhai D M, Chang H, Shan S G, Chen X L, Gao W. Multiview metric learning with global consistency and local smoothness. ACM Transactions on Intelligent Systems and Technology, 2012, 3(3):Article No. 53 https://dl.acm.org/citation.cfm?doid=2168752.2168767 [10] Kumar A, Rai P, Daumé Ⅲ H. Co-regularized multi-view spectral clustering. In: Proceedings of the 24th Annual Conference on Neural Information Processing Systems. Granada, Spain: Curran Associates Inc., 2011. 1413-1421 [11] Chen M M, Weinberger K Q, Blitzer J C. Co-training for domain adaptation. In: Proceedings of the 24th Annual Conference on Neural Information Processing Systems. Granada, Spain: Curran Associates Inc., 2011. 2456-2464 [12] Eaton E, desJardins M, Jacob S. Multi-view constrained clustering with an incomplete mapping between views. Knowledge and Information Systems, 2014, 38(1):231-257 doi: 10.1007/s10115-012-0577-7 [13] Zhang X C, Zong L L, Liu X Y, Yu H. Constrained NMF-based multi-view clustering on unmapped data. In: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA: AIAA Press, 2015. 3174-3180 [14] Yu S, Tranchevent L C, Liu X H, Glanzel W, Suykens J A K, De Moor B, et al. Optimized data fusion for kernel k-means clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(5):1031-1039 doi: 10.1109/TPAMI.2011.255 [15] 余凯, 贾磊, 陈雨强, 徐伟.深度学习的昨天、今天和明天.计算机研究与发展, 2013, 50(9):1799-1804 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jfyz201309002&dbname=CJFD&dbcode=CJFQYu Kai, Jia Lei, Chen Yu-Qiang, Xu Wei. Deep learning:yesterday, today, and tomorrow. Journal of Computer Research and Development, 2013, 50(9):1799-1804 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jfyz201309002&dbname=CJFD&dbcode=CJFQ [16] 郭丽丽, 丁世飞.深度学习研究进展.计算机科学, 2015, 42(5):28-33 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsja201505007&dbname=CJFD&dbcode=CJFQGuo Li-Li, Ding Shi-Fei. Research progress on deep learning. Computer Science, 2015, 42(5):28-33 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsja201505007&dbname=CJFD&dbcode=CJFQ [17] 胡长胜, 詹曙, 吴从中.基于深度特征学习的图像超分辨率重建.自动化学报, 2017, 43(5):814-821 http://www.aas.net.cn/CN/abstract/abstract19059.shtmlHu Chang-Sheng, Zhan Shu, Wu Cong-Zhong. Image super-resolution based on deep learning features. Acta Automatica Sinica, 2017, 43(5):814-821 http://www.aas.net.cn/CN/abstract/abstract19059.shtml [18] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5876):504-507 http://www.ncbi.nlm.nih.gov/pubmed/16873662 [19] Farquhar J D R, Hardoon D R, Meng H Y, Shawe-Taylor J, Szedmak S. Two view learning: SVM-2k, theory and practice. In: Proceedings of the 18th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2005. 355-362 [20] Sindhwani V, Rosenberg D S. An RKHS for multi-view learning and manifold co-regularization. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 976-983 [21] Yu S P, Krishnapuram B, Rosales R, Rao R B. Bayesian co-training. The Journal of Machine Learning Research, 2011, 12:2649-2680 https://dl.acm.org/citation.cfm?id=2078190 [22] Andrew G, Arora R, Bilmes J, Livescu K. Deep canonical correlation analysis. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, GA, USA: JMLR. org, 2013. 1247-1255 [23] Westerveld T, de Vries A, de Jong F. Generative probabilistic models. Multimedia Retrieval, Berlin:Springer, 2007. 177-198 [24] Rezende D J, Mohamed S, Wierstra D. Stochastic backpropagation and approximate inference in deep generative models. arXiv preprint arXiv: 1401.4082, 2014. [25] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7):1527-1554 doi: 10.1162/neco.2006.18.7.1527 [26] van den Oord A, Kalchbrenner N, Kavukcuoglu K. Pixel recurrent neural networks. arXiv preprint arXiv: 1601.06759, 2016. [27] van den Oord A, Kalchbrenner N, Vinyals O, Espeholt L, Graves A, Kavukcuoglu K. Conditional image generation with pixelCNN decoders. In: Proceedings of the 30th Annual Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 4790-4798 [28] Kingma D P, Welling M. Auto-encoding variational Bayes. In: Proceedings of the 2014 International Conference on Learning Representations. Banff, Canada: ICLR, 2014. [29] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th Annual Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [30] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [31] 陈伟宏, 安吉尧, 李仁发, 李万里.深度学习认知计算综述.自动化学报, 2017, 43(11):1886-1897 http://www.aas.net.cn/CN/abstract/abstract19164.shtmlChen Wei-Hong, An Ji-Yao, Li Ren-Fa, Li Wan-Li. Review on deep-learning-based cognitive computing. Acta Automatica Sinica, 2017, 43(11):1886-1897 http://www.aas.net.cn/CN/abstract/abstract19164.shtml [32] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [33] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11):2278-2324 doi: 10.1109/5.726791 [34] Sermanet P, Chintala S, LeCun Y. Convolutional neural networks applied to house numbers digit classification. In: Proceedings of the 21st International Conference on Pattern Recognition (ICPR). Tsukuba, Japan: IEEE, 2012. 3288-3291 [35] Liu Z W, Luo P, Wang X G, Tang X O. Deep learning face attributes in the wild. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3730-3738 [36] Wang Z, Bovik A C, Sheikh H R, Simoncelli E P. Image quality assessment:from error visibility to structural similarity. IEEE Transactions on Image Processing, 2004, 13(4):600-612 doi: 10.1109/TIP.2003.819861 [37] Huynh-Thu Q, Ghanbari M. Scope of validity of PSNR in image/video quality assessment. Electronics Letters, 2008, 44(13):800-801 doi: 10.1049/el:20080522 [38] 向征, 谭恒良, 马争鸣.改进的HOG和Gabor, LBP性能比较.计算机辅助设计与图形学学报, 2012, 24(6):787-792 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjf201206011&dbname=CJFD&dbcode=CJFQXiang Zheng, Tan Heng-Liang, Ma Zheng-Ming. Performance comparison of improved HoG, Gabor and LBP. Journal of Computer-Aided Design and Computer Graphics, 2012, 24(6):787-792 http://kns.cnki.net/KCMS/detail/detail.aspx?filename=jsjf201206011&dbname=CJFD&dbcode=CJFQ [39] Kingma D P, Rezende D J, Mohamed S, Weling M. Semi-supervised learning with deep generative models. In: Proceedings of the 27th Annual Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3581-3589 -

 下载:
下载:


计量
- 文章访问数: 3571
- HTML全文浏览量: 867
- PDF下载量: 1552
- 被引次数: 0
