

Spatio-temporal Feature Based Emotional Contagion Analysis and Prediction Model for Online Social Networks
-
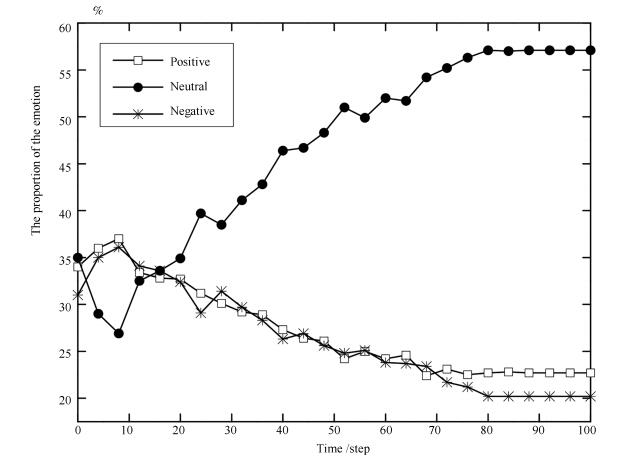
摘要: 社交网络用户情绪传播与用户的空间距离和时间跨度有关,并且受到多种交互机制的影响.从大规模社交网络数据中提取情绪传播的时空特征,研究用户行为对情绪传播的影响,对预测情绪传播趋势具有实际意义.利用线性回归获取的各行为子层的情绪传输率之间存在差异.提出一种基于多层社交网络的情绪传播模型,被称为ECM模型(Emotional contagion model).该模型包括三个行为子层,每层的拓扑结构各不相同,由该行为的交互历史决定.在真实数据上对ECM模型进行仿真分析,可以获得社交网络中情绪传播的过程与规律:1)中性情绪用户所占比例随时间逐渐增大,接近57.1%,而正向情绪与负向情绪比例始终接近.2)情绪传输率越大,用户情绪更容易受到其他用户的影响而发生变化;初始情绪越中立的用户,在演化过程中情绪波动越小,而初始情绪极性越大的用户情绪波动越大.此外,通过实验对比该模型与其他情绪传播模型,表明ECM模型更加接近真实数据,对社交网络中情绪传播具有较好的预测效果,预测准确率相比其他模型可以提高1.8%~7.8%.Abstract: Users' emotion in social networks is related to spatial distance and time span, and affected by multiple interaction mechanisms. It has practical significance to extract the spatio-temporal features from large-scale social networks and study the influence of users' behaviors on emotional contagion in order to predict the trend of emotional contagion. The transmisibility values on different behavioral layers are calculated by linear regression and the results show the differences between these values. An emotional contagion model called ECM on multilayer social networks is proposed. It consists of three behavioral layers with different topologies depending on users' interaction history. By simulation on real dataset, it is discovered that, 1) the proportion of users with neutral emotion is gradually increased with time and reaches 57.1% while the proportion of positive emotion is comparable to that of negative emotion from beginning to end; 2) users' emotion is more likely to be influenced by other users when transmissibility becomes larger and users with initial polar emotion fluctuate more drastically than users with initial neutral emotion. In order to show the advantages of the proposed model, it is compared with other emotional contagion models. The results demonstrate that the proposed model approximates to the real data of emotional contagion on social networks, and also shows better predictive performance of emotional contagion. The prediction accuracy is increased by 1.8%~7.8%.
-
Key words:
- Emotion contagion /
- multilayer networks /
- behavior analysis /
- social networks
-
视频信号在捕捉、记录和传输的过程中都可能引入噪声.引入的噪声严重降低视频画面质量, 影响观众的视觉体验.而视频去噪是将数字视频图像的特点与现有的信号处理技术相结合, 尽可能地降低视频图像中噪声干扰的一种多媒体信息处理技术.目前存在的大多数视频去噪算法的性能都不同程度地依赖于含噪视频中的噪声参数.虽然通过各种各样的算法, 可以达到很理想的去噪效果, 但大多数算法都有个假设前提, 即噪声强度是预先知道的[1-3].人为给定噪声参数或者噪声参数不准确, 都会导致去噪效果不理想.因此对于含噪视频的噪声参数估计是视频去噪研究中一个关键性问题.近年来, 图像去噪算法在空域和变换域等取得了较大发展.其中较为优秀的是Knaus等的基于空域和频域的双域滤波图像去噪算法[4], 去噪后的图像细节信息丰富, 但是需要设置与噪声有关的经验参数. Pierazzo等[5]利用非局部贝叶斯去噪替换了文献[4]中的引导层, 构造图像快速去噪算法, 但图片的适用性不高.为了实现视频噪声去除, 肖进胜等[6]将文献[4]和三维块匹配算法相结合将图像去噪拓展到了视频去噪领域, 主客观效果较好, 但对未知噪声水平时鲁棒性较差.另外Knaus等[7]基于双域滤波引入了鲁棒噪声估计, 部分解决了人为设定噪声值的问题. Dabov等[8]对视频图像进行3D稀疏变换后再滤波(Video block-matching and 3-D filtering, VBM3D), 取得了较优秀的去噪性能.但该算法耗时高, 且去噪视频存在块效应. Matteo等提出了VBM4D[9]算法, 该算法将VBM3D拓展到4维结构, 能更好地保存视频的细节.上述去噪算法均没有对噪声进行有效的估计, 对于未知噪声的视频序列不能获得其最佳的去噪效果.
高斯白噪声是视频图像采集中最常见的一种噪声, 针对该噪声的估计主要分为空域、时域和空时域[10]三种.空域法通常分为基于块[11-12], 基于滤波[13]和变换域三种方法[14]. Amer等[15]采用自适应平均的方法对所有块的方差进行选取和平均, 基于块进行噪声估计, 但该算法对平滑块的数量有严格的要求.基于图像块的算法估计结果受图像内容和噪声强度影响很大, 而Pyatykh等[16]提出的基于主成分分析(Principal component analysis, PCA)的方法则对含噪图像没有严格的要求, 且估计结果较精确.柳薇[17]利用PCA的思想对图像块进行噪声估计, 图像块的协方差矩阵最小特征值作为噪声方差的估计值, 该方法无需图像含有许多同种类区域. Aditya等[18]是一种基于奇异值分解的比较稳定的噪声估计方法, 用奇异值的尾部数据进行噪声强度估计, 降低图像信息对噪声估计的干扰.而时域的方法主要考虑帧与帧之间的关系, 对视频的整体运动较难把握, 因此需要进行运动检测或者运动补偿. Yin等[19]提出基于运动估计的视频噪声估计算法, 考虑到了视频编码, 该算法能对各类型的视频信号进行准确的估计.目前主要有算法[10, 20-21]利用了时空域的信息对视频噪声估计, Zlokolica等[20]主要用小波变换系数对空时域进行分析, 然而该方法计算复杂性较高. Ghazal等[10]利用5个域来探索空时域的信息, 每个域的局部相似性主要利用了高斯拉普拉斯算子, 该算法估计效果较好. Yang等[21]利用Sobel梯度作为同种类块的衡量标准, 利用了3个域进行噪声估计, 计算复杂性降低.总体上说, 噪声估计算法的效果都有待提高.
考虑到PCA对含噪图像和噪声类型的鲁棒性, 本文提出一种基于PCA的分块视频噪声估计.本文所提出的方法有如下创新: 1)首先通过前后帧块匹配寻找相似块, 充分利用了视频序列的相关性, 并进行前后帧的差分运算以消除视频运动的影响. 2)使用正态分布函数作为选择弱纹理块的阈值函数, 使得计算复杂度降低, 同时简化了算法模型. 3)设置了明确的迭代指标, 使得最终结果更加精确.通过理论分析和实验结果表明本文的视频噪声估计算法具有较大的应用范围, 成功的运用于盲视频去噪.
1. 基于PCA的图像噪声估计
文献[14]提出的基于PCA的图像噪声水平估计算法, 对于纹理信息丰富的噪声图, 基于PCA的噪声估计会高估其噪声水平.若先选择噪声图中的弱纹理块, PCA则可以精确地估计出噪声水平, 因此本文算法首先选择含噪图中的弱纹理块, 再基于弱纹理块估计图像的噪声水平.含噪图像块模型为
$ \begin{equation} \label{eq1} {y_i}={z_i}+{n_i} \end{equation} $
(1) 其中, $z_i$是原始图像第$i$个矢量块, $y_i$是观测到的矢量块, $n_i$是零均值高斯噪声.图像块可以认为是欧氏空间的数据, 利用PCA计算最小方差向量.协方差矩阵定义如下:
$ \begin{equation} \label{eq2} \Sigma_y=\frac{1}{M}\sum\limits_{i=1}^{N}(y_i-\mu)(y_i-\mu )^{\rm T} \end{equation} $
(2) 其中, $M$是数据数目, $\mu$是数据集$y_i$的平均数.投影到最小方差方向数据的方差与协方差矩阵最小特征值相等, 可得到下述公式:
$ \begin{equation} \label{eq3} \lambda_{\min}(\Sigma_y)=\lambda_{\min}(\Sigma_z)+\sigma_n^2 \end{equation} $
(3) $\Sigma_y$和$\Sigma_z$分别指噪声块y和不含噪块z的协方差矩阵, $\lambda_{\min}$表示最小特征值.对于一般的图像块, $\lambda_{\min}(\Sigma_z)$是未知的.弱纹理块只适用于低维子空间, 它的协方差矩阵的最小特征值约为零, 对于弱纹理块噪声水平$\hat{\sigma }_{n}^{2}$可以简化为
$ \begin{equation} \label{eq4} \hat{\sigma }_{n}^{2}={{\lambda}_{\min }}({{\Sigma }_{y'}}) \end{equation} $
(4) ${{\sum }_{y'}}$为噪声图中所有弱纹理块的协方差矩阵.因此, 只要从噪声图像中选择出弱纹理块就能估计出噪声水平.梯度协方差矩阵能反应出图像的纹理信息, $N\times N$的含噪图像块$n$表示成列向量形式为${{N}^{2}}\times 1$.若${{D}_{h}}$和${{D}_{v}}$是由3阶滤波算子构造的水平和垂直方向的算子, 均为${{N}^{2}}\times {{N}^{2}}$的常对角矩阵, 从而梯度矩阵为
$ \begin{equation} \label{eq5} {{G}_{n}}=[{{D}_{h}}n\quad {{D}_{v}}n] \end{equation} $
(5) 梯度协方差矩阵$C_n=G_n^{\rm T} G_n$的期望为
$ \begin{align} \label{eq6} {\rm E}({{C}_{n}})=\left[\begin{matrix} {\rm E}({{n}^{\rm T}}D_{h}^{\rm T}{{D}_{h}}n)&0 \\ 0&{\rm E}({{n}^{\rm T}}D_{v}^{\rm T}{{D}_{v}}n) \\ \end{matrix} \right] \end{align} $
(6) 含噪块的梯度矩阵如下(其中${z_f}$是不含噪的平坦块)
$ \begin{align} \label{eq7} {{G}_{y}}=\, &[{{D}_{h}}({{z}_{f}}+n)\ {{D}_{v}}({{z}_{f}}+n)]=\nonumber\\ &[D_h n \ D_v n]=G_n \end{align} $
(7) 对角线的元素有相同的特性, 设
$ \begin{equation} \label{eq8} \varepsilon(n) ={{n}^{\rm T}}D_{h}^{\rm T}{{D}_{h}}n+{{n}^{\rm T}}D_{v}^{\rm T}{{D}_{v}}n \end{equation} $
(8) $\varepsilon (n)$的生成函数决定了其分布[15], 且$\varepsilon(n)$的生成函数与伽马(Gamma)分布的生成函数形式一致, 因此对应的Gamma分布的形状参数$\alpha$和尺度参数$\beta $, 分别为
$ \begin{equation} \label{eq9} \begin{cases} \alpha =\displaystyle\frac{N^2}{2} \\[2mm] \beta =\displaystyle\frac{2}{N^2} \sigma_n^2{\rm tr}(D_h^{\rm T} D_h+D_v^{\rm T} D_v) = 2\sigma_n^2 \\ \end{cases} \end{equation} $
(9) 该算法主要通过Gamma函数来逼近从而求得最终的阈值函数, 但Gamma函数形式较复杂, 不利于广泛的应用.同时原算法文献[14]中设置经验的迭代次数作为迭代停止条件, 虽然效果不错, 但始终存在适应性[22-23]的隐患.
2. 基于正态分布阈值的视频噪声估计
本文视频噪声估计算法首先通过前后帧块匹配寻找相似块, 对匹配效果最佳的块(弱纹理块)进行噪声估计, 并进行前后帧的差分运算以消除视频运动的影响.其次修改了选择弱纹理块的阈值函数, 使得判断标准更加精确, 减少图像纹理信息对估计结果的干扰.
2.1 基于帧间块匹配的视频噪声估计
视频图像序列前后两帧图像在时间上具有很强的相关性.原本拥有很多纹理和细节信息的块, 如果它在前后两帧具有较强的相关性, 那么差分的结果仍然会产生一个平滑块, 降低了图像信息对噪声估计的影响, 同时降低了噪声水平对估计结果的影响.算法首先对当前帧图像进行块划分, 然后对于每一图像块在前一帧图像内进行块匹配寻找相似块, 并根据最小代价得到最佳匹配块, 所有块与最佳匹配块的差值块合并得到帧间差分图像, 接下来将差分图像作为原始含噪图像进行噪声估计.较朱磊等[24]对整幅图像进行差分运算, 本文算法的效率和精确度得到了提高.
假设观察到的视频图像为
$ \begin{equation} \label{eq10} I(i, j, n)=S(i, j, n)+N(i, j, n) \end{equation} $
(10) 其中, $S(i, j, n)$为原始不含噪的视频帧, $N(i, j, n)$为噪声信号, $n$为帧编号, $i$, $j$是像素坐标.经过块匹配, 我们选择的是匹配效果最佳的块(弱纹理块)进行噪声估计.通过选择弱纹理块, 降低了图像纹理对噪声估计的干扰, 对于最佳匹配块有:
$ \begin{equation} \label{eq11} S(i, j, n)=S({{i}^\prime}, {{j}^\prime}, n+1) \end{equation} $
(11) 此时的差分图像可以表示为:
$ \begin{align} \label{eq12} D(i, j, n)=\, &I(i, j, n)-I({{i}^\prime}, {{j}^\prime}, n+1)= \nonumber\\ &N(i, j, n)-N({{i}^\prime}, {{j}^\prime}, n+1) \end{align} $
(12) 假如原始图像的实际噪声方差为$\sigma _N^2$, 根据概率计算式(12)中差分图像的噪声方差$\sigma _D^2$有:
$ \begin{equation} \label{eq13} \sigma _{D}^{2}=2\sigma _{N}^{2} \end{equation} $
(13) 因此, 如果原始图像中前后两帧的最佳匹配块足够接近, 那么差分图像块将会变为平滑块, 该平滑块的方差可以认为是噪声造成的, 可以用式(13)进行噪声方差的估计.
2.2 基于正态分布的阈值函数
对于伽马(Gamma)分布, 通过如下图 1所示可以得到:当形状参数$\alpha $越大其峰值越远离$Y$轴, 同时越逼近正态分布.当$\alpha$为正整数时, 分布可看作$\alpha $个独立的指数分布之和, 当$\alpha $趋向于较大数值时, 分布近似于正态分布.普通参数的Gamma分布可以看作多个独立的Gamma分布之和.按照中心极限定理, 独立同分布的随机变量之和趋于正态分布[25].
由图 1, $\alpha $, $\beta$的变化也可看出当$\alpha$足够大时Gamma分布近似正态分布.通过计算可以得到:
$ \begin{eqnarray*} \label{eq14} \underset{\alpha \to \infty }{\mathop{\lim}}\Gamma(\alpha, \beta ) =N(\mu, {{\sigma }^{2}}), \mu=\alpha \beta, \sigma ^2=\alpha \beta ^2 \end{eqnarray*} $
(14) 由于梯度算子的大小只与块的大小有关, 不受含噪图像的影响, 因此当用3阶滤波算子时, 水平和垂直梯度算子为常矩阵, $D_{h}^{\rm T}{{D}_{h}}+D_{v}^{\rm T}{{D}_{v}}$也为常矩阵.本文中, $\alpha$值为${N}^{2}/{2}$, 块的大小为5, 可以用正态分布近似Gamma分布, 于是由式(9)和(14)可得到正态分布的均值和方差为
$ \begin{equation} \label{eq15} \mu =\sigma_{n}^{2}{{N}^{2}}, {{\sigma }^{2}}=2{{N}^{2}}\sigma _{n}^{4} \end{equation} $
(15) 可得到本文的阈值为
$ \begin{equation} \label{eq16} \tau =\sigma _n^2{{F}^{-1}}(\delta, {{N}^{2}}, \sqrt{2}N) \end{equation} $
(16) 其中, $F^{-1}(\delta, \alpha, \beta)$是正态分布的逆累加分布函数, $\delta$是人为给定的显著性水平(本文为0.99).当显著性水平和噪声水平给定时, 阈值随之确定.这里经过推导简化了Gamma分布的形状参数$\alpha $和尺度参数$\beta$, 同时用正态分布替换了Gamma分布, 对算法的运算函数也进行了简化.而当图像块梯度协方差矩阵的最大特征值小于上述阈值时, 即为选定的弱纹理块, 再对图像中的弱纹理区域利用PCA进行噪声估计.实验结果表明当块大小小于5时, 同样可以达到较好的估计效果.改进的正态分布函数和Gamma分布的噪声估计准确度(单位: dB)对比如下表所示:
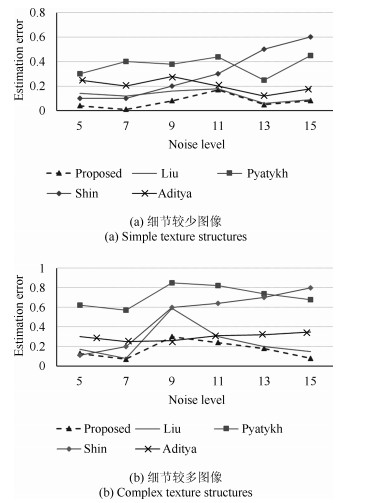
表 1 不同分布函数噪声估计对比Table 1 Comparison of noise estimation for different functionNoise level (dB) Lena Akiyo Bus Coastguard ${{\sigma }_{n}}=10$ Liu等[14] 9.68 9.88 9.69 9.79 ${{\sigma }_{n}}=10$ Proposed 9.86 9.79 9.97 9.93 ${{\sigma }_{n}}=20$ Liu等[14] 19.56 19.61 19.64 19.67 ${{\sigma }_{n}}=20$ Proposed 19.72 19.65 19.78 19.74 ${{\sigma }_{n}}=30$ Liu等[14] 29.54 29.54 29.13 29.59 ${{\sigma }_{n}}=30$ Proposed 29.65 29.81 29.50 29.67 ${{\sigma }_{n}}=40$ Liu等[14] 38.43 39.34 38.99 39.37 ${{\sigma }_{n}}=40$ Proposed 39.50 39.38 39.64 39.60 由上表可以看出, 替换后的函数估计效果更好.因此噪声估计采用的分布函数改为正态分布完全可行且取得更好的估计效果.大量实验结果表明迭代次数达到6次时, 噪声水平可基本达到稳定.但是为了进一步提高噪声估计算法的稳定性, 对于迭代次数的设置, 本文采用经验次数和前后两次噪声估计水平的差值比例也可确定来决定迭代停止条件.下面将讨论一下针对不同噪声水平, 改进算法相对于其他算法噪声估计的效果.当噪声强度小于10 dB时, 大部分图像算法的有效性都会降低, 但Shin等[26]算法例外, 它仅在低噪环境下工作稳定可靠.由于Shin等提出的自适应高斯滤波的算法只适用于低噪环境, 因此仅在$\sigma<15$的情况下比较Liu等[14]、Pyatykh等[16]、Shin等[26]和本文算法的实验结果.在低噪声强度下噪声估计对比结果如图 2所示, 噪声估计的误差定义为$\delta (\sigma )=|\hat{\sigma }-\sigma |$ (dB).分别选取了Lena (含有细节较少)和Baboon (含有细节较多)等图片进行测试.由图可以看出本文算法比Pyatykh等[16]、Aditya等[18]和Shin等[26]误差较小.对于Liu等[14], 本文算法在$\sigma <10$时也明显误差较小.当图像含有复杂的纹理结构, 图像块的最小特征值大于0, 估计误差较大.由图 2 (a)和(b)对比看出, 细节较少的图片噪声估计更为精确.本文算法的噪声强度估计结果对细节较少和细节较多的图片均较对比算法精确, 说明本文的噪声估计算法在低噪条件下有较高的准确性.
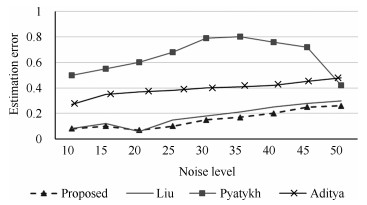
在较高噪声水平情况下, Pyatykh等[16]是目前广为应用的基于主成分分析的噪声估计方法, 有较高的精确性和较快的速度.由曲线图可以看出, Pyatykh等[16]估计误差随着噪声水平增加, 当误差大于40 dB时逐渐减小, Aditya等[18]估计误差相对较稳定, Liu等[14]算法估计误差较小, 本文算法估计误差比这3种算法小.因此, 本文算法在高噪声水平下对噪声的估计结果较其他算法精确, 受噪声强度的影响较小.通常一段视频噪声的分布是均匀的, 每帧的噪声水平是类似的.考虑到视频噪声的突变情况, 本文在对视频进行噪声估计时, 利用前后帧信息和PCA得到当前帧的噪声水平, 因此当下一帧出现噪声突变时, 对估计结果没有影响.
2.3 算法整体流程
本文视频噪声估计算法首先通过前后帧块匹配寻找相似块, 充分利用了视频序列的相关性, 并进行前后帧的差分运算以消除视频运动的影响.其次修改了选择弱纹理块的阈值函数, 用正态分布函数简化了计算复杂度降低.最后设置了明确的迭代指标, 使得估计结果更加精确.本文的视频噪声水平估计过程如下图 4所示:
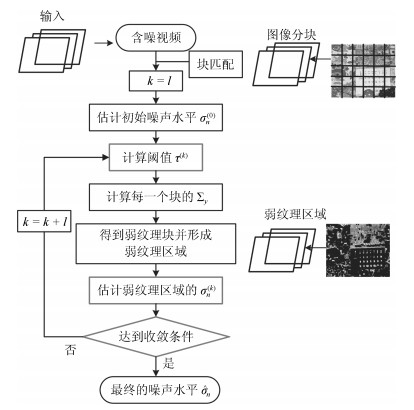 图 4 本文算法迭代噪声水平估计流程图Fig. 4 Flowchart of the iterative noise level estimation for proposed algorithm
图 4 本文算法迭代噪声水平估计流程图Fig. 4 Flowchart of the iterative noise level estimation for proposed algorithm3. 实验结果
为验证本文算法对视频进行噪声估计的效果, 使用两个CIF格式的标准测试视频, 两个测试视频为: Flowergarden和Football.算法运行环境为Windows XP, CPU-Intel Core i5-2500 K, 主频3.30 GHz, 内存3 GB, 32 bit.由于Shin等[26]数据取自原文, 因此本文对这两个测试视频同样加入均值为0, 标准差为20, 30, 40的高斯白噪声与算法Amer等[15]、Pyatykh等[16]、Liu等[14]进行对比. 图 5~图 7是本文算法和其他算法在视频序列前40帧不同噪声水平的估计误差, 对于不同的视频序列和噪声水平, 本文算法的估计误差较低.
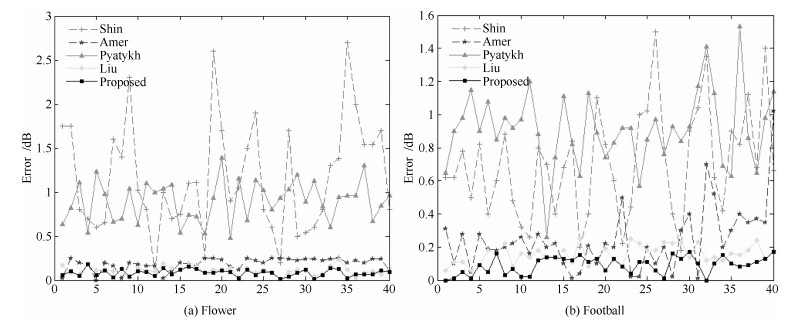 图 5 加噪20 dB视频序列(Flower, Football)估计误差Fig. 5 Noise estimation error for 20 dB noisy sequences (Flower, Football)
图 5 加噪20 dB视频序列(Flower, Football)估计误差Fig. 5 Noise estimation error for 20 dB noisy sequences (Flower, Football)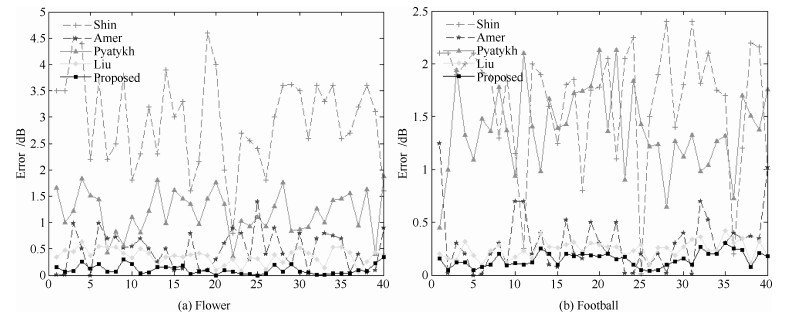 图 6 加噪30 dB视频序列(Flower, Football)估计误差Fig. 6 Noise estimation error for 30 dB noisy sequences (Flower, Football)
图 6 加噪30 dB视频序列(Flower, Football)估计误差Fig. 6 Noise estimation error for 30 dB noisy sequences (Flower, Football)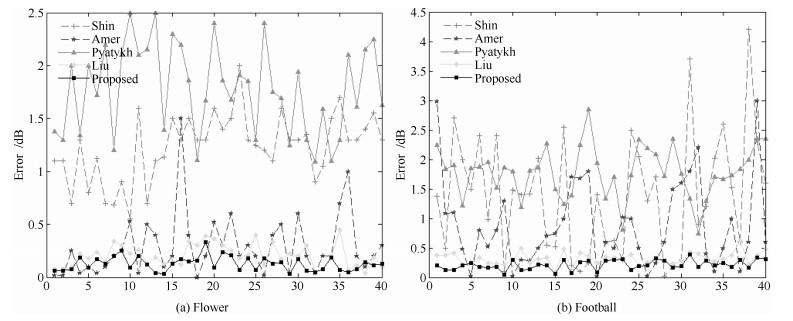 图 7 加噪40 dB视频序列(Flower, Football)估计误差Fig. 7 Noise estimation error for 40 dB noisy sequences (Flower, Football)
图 7 加噪40 dB视频序列(Flower, Football)估计误差Fig. 7 Noise estimation error for 40 dB noisy sequences (Flower, Football)PSNR和SSIM是两个比较常用的评价去噪效果的客观指标, 本文选用这两个指标来对VBM3D算法、PID算法、VBM4D算法和文献[6]算法加噪声估计进行对比.由于VBM3D和VBM4D未加入噪声估计, 因此测试程序中设定随机取真实值附近的噪声水平进行视频去噪.不同噪声水平下各算法的去噪效果的PSNR和SSIM对比如表 2所示:
表 2 VBM3D、PID、VBM4D和本文算法的PSNR和SSIM对比Table 2 The comparisons of PSNR and SSIM results of VBM3D, PID, VBM4D and proposed algorithmNoise level (dB) Algorithm Akiyo PSNR/SSIM Mobile PSNR/SSIM Flowergarden PSNR/SSIM Foreman PSNR/SSIM Football PSNR/SSIM ${{\sigma }_{n}}=10$ VBM3D 35.488/0.877 32.374/0.954 34.250/0.984 34.313/0.902 33.048/0.951 ${{\sigma }_{n}}=10$ PID 31.396/0.763 29.538/0.917 31.276/0.962 31.094/0.844 30.048/0.921 ${{\sigma }_{n}}=10$ VBM4D 30.290/0.730 29.727/0.915 29.972/0.842 30.078/0.813 29.833/0.923 ${{\sigma }_{n}}=10$ Proposed 37.842/0.944 32.454/0.972 33.675/0.983 36.295/0.938 33.488/0.960 ${{\sigma }_{n}}=20$ VBM3D 30.239 /0.715 27.653/0.897 29.444/0.961 29.587/0.786 28.171/0.868 ${{\sigma }_{n}}=20$ PID 26.011/0.836 24.572/0.833 25.945/0.896 25.937/0.675 24.889/0.793 ${{\sigma }_{n}}=20$ VBM4D 29.594/0.767 27.249/0.898 27.599/0.852 28.904/0.797 27.727/0.885 ${{\sigma }_{n}}=20$ Proposed 34.986/0.925 28.322/0.936 29.386/0.957 33.098/0.878 29.890/0.894 ${{\sigma }_{n}}=30$ VBM3D 27.463/0.609 25.025/0.853 26.611/0.932 26.934/0.698 25.406/0.783 ${{\sigma }_{n}}=30$ PID 23.051/0.815 21.803/0.769 22.895/0.825 23.017/0.565 21.929/0.676 ${{\sigma }_{n}}=30$ VBM4D 29.026/0.780 25.884/0.883 26.185/0.848 28.208/0.782 26.557/0.842 ${{\sigma }_{n}}=30$ Proposed 32.579/0.866 26.045/0.898 27.098/0.932 31.379/0.835 27.995/0.825 从表 2中的对比结果可以看出, 本文算法的PSNR和SSIM比VBM3D算法在大多数情况下高出很多, 主要是因为VBM3D处理过后像素值减小, 图像的亮度降低, 导致PSNR与SSIM均较低.对于Flowergarden视频序列, 本文客观效果在噪声水平较低情况下比VBM3D略低, 主要因为在对视频去噪时, 本文指定的是真实噪声水平利用VBM3D进行测试, 而实际情况中并不可能准确获取图像的真实噪声水平. PID算法中加入了噪声估计, 但综合而言, 本文的客观指标在各种噪声水平均比PID略高.上述表格表明, 本文算法与VBM3D、PID、VBM4D进行对比时, 客观效果优势较明显.因此说明本文算法不仅去除了图像中的噪声, 而且较好地保持了图像本身结构的信息, 去噪效果较为优秀, 同时加入了噪声估计应用范围更广.
4. 结论
本文提出了一种新颖的视频噪声估计算法, 充分利用了视频序列的相关性, 利用帧间进行相似块的搜索, 基于最小代价准则获得帧间的差分图像, 消除了视频运动的影响, 得到初步的弱纹理差分图像:引入基于块的噪声估计, 能自适应地获取噪声水平参数, 并提出正态分布函数作为文中选择弱纹理块的阈值函数, 降低了计算复杂度, 另设置了明确的迭代指标使得估计的噪声水平更加精确.最后考虑像素会受到噪声饱和效应的影响, 避免了在高噪声水平下的低估现象.通过理论分析和实验结果表明本文提出的视频噪声估计算法估计精确, 可运用到盲视频去噪领域, 具有广阔的应用前景.
-
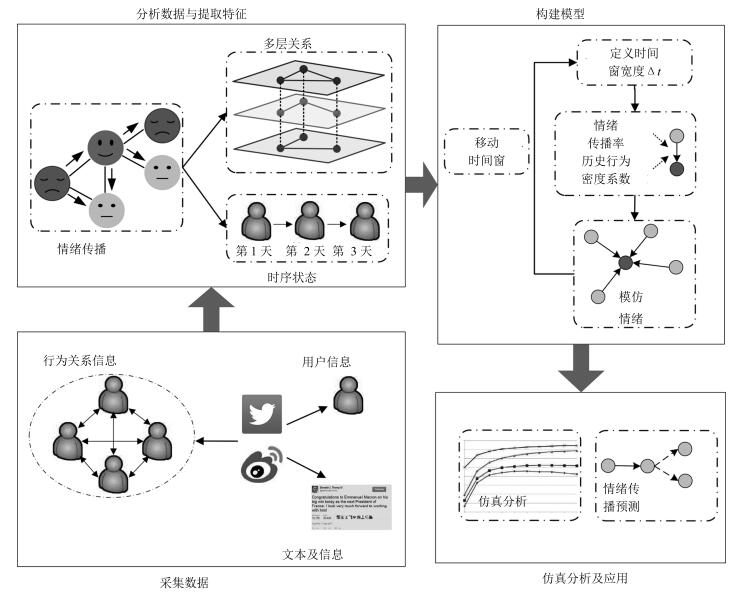
图 1 社交网络中情绪传播分析及模型构建示意图
Fig. 1 Analysis and modeling of emotion contagion in social networks

图 4 情绪转换数随用户初始情绪与节点度乘积的变化
Fig. 4 The relation between the number of individual emotional tendency changes, the degree and the initial emotion

图 5 三种模型与真实数据的对比(Twitter数据集)
Fig. 5 The comparison of the three models and the real data (Twitter dataset)

图 6 三种模型分类度量值的对比
Fig. 6 The comparison of classification measurements of the three models
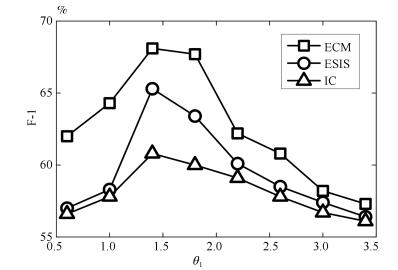
图 7 三种模型中的F-1值随$\theta_1$的变化规律(Twitter数据集)
Fig. 7 F-1 changes with $\theta_1$ for the three models (Twitter dataset)
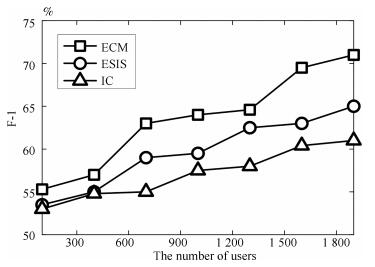
图 8 三种模型中的F-1值随用户数的变化规律(Twitter数据集)
Fig. 8 F-1 changes with the number of users for the three models (Twitter dataset)
表 1 数据集统计信息
Table 1 The statistical information of the datasets
Higgs数据集 数据堂数据集 新采集Twitter 新采集新浪微博 数据来源 Twitter 新浪微博 Twitter 新浪微博 用户(节点)数 456 626 63 641 33 070 6 344 好友关系数 14 855 842 1 391 718 185 393 54 093 转发次数 328 132 27 759 88 677 24 027 提及次数 150 818 未采集 41 245 10 428 回复次数 32 523 未采集 12 174 4 207 是否包含文本 否 是 是 是  下载: 导出CSV
下载: 导出CSV
表 2 两个数据集不同子层的情绪传输率
Table 2 The transimisibilities on different layers in the two datasets
Twitter数据集 新浪微博数据集 转发 0.27 0.31 提及 0.95 1.07 回复 0.44 0.45
下载: 导出CSV
-
[1] Gabriel A S, Cheshin A, Moran C M, van Kleef G A. Enhancing emotional performance and customer service through human resources practices:a systems perspective. Human Resource Management Review, 2016, 26(1):14-24 http://www.sciencedirect.com/science/article/pii/S1053482215000510 [2] Xiong X B, Zhou G, Huang Y Z, Chen H Y, Xu K. Dynamic evolution of collective emotions in social networks:a case study of Sina weibo. Science China Information Sciences, 2013, 56(7):1-18 doi: 10.1007/s11432-013-4892-8 [3] Lo S C, Huang K P. The smiling mask in service encounters:the impact of surface and deep acting. International Journal of Management, Economics and Social Sciences, 2017, 6(1):40-55 http://www.econstor.eu/handle/10419/157922 [4] Wang Q Y, Lin Z, Jin Y H, Cheng S D, Yang T. ESIS:emotion-based spreader-ignorant-stifler model for information diffusion. Knowledge-Based Systems, 2015, 81:46-55 doi: 10.1016/j.knosys.2015.02.006 [5] Wang Q Y, Jin Y H, Yang T, Cheng S D. An emotion-based independent cascade model for sentiment spreading. Knowledge-Based Systems, 2017, 116:86-93 doi: 10.1016/j.knosys.2016.10.029 [6] Dignath D, Janczyk M, Eder A B. Phasic valence and arousal do not influence post-conflict adjustments in the Simon task. Acta Psychologica, 2017, 174:31-39 doi: 10.1016/j.actpsy.2017.01.004 [7] Lloyd-Jones D M, Larson M G, Leip E P, Beiser A, D'Agostino R B, Kannel W B, et al. Lifetime risk for developing congestive heart failure:the Framingham Heart Study. Circulation, 2002, 106(24):3068-3072 doi: 10.1161/01.CIR.0000039105.49749.6F [8] Coviello L, Sohn Y, Kramer A D I, Marlow C, Franceschetti M, Christakis N A, et al. Detecting emotional contagion in massive social networks. PLoS One, 2014, 9(3): Article No. e90315 [9] Del Vicario M, Vivaldo G, Bessi A, Zollo F, Scala A, Caldarelli G, et al. Echo chambers: emotional contagion and group polarization on Facebook. Scientific Reports, 2016, 6: Article No. 37825 [10] Guille A, Hacid H, Favre C, Zighed D A. Information diffusion in online social networks:a survey. ACM SIGMOD Record, 2013, 42(2):17-28 http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1310.0505 [11] Bozorgi A, Samet S, Kwisthout J, Wareham T. Community-based influence maximization in social networks under a competitive linear threshold model. Knowledge-Based Systems, 2017, 134:149-158 doi: 10.1016/j.knosys.2017.07.029 [12] Liu L J. A delayed SIR model with general nonlinear incidence rate. Advances in Difference Equations, 2015, 2015:329 doi: 10.1186/s13662-015-0619-z [13] Zhang X H, Jiang D Q, Alsaedi A, Hayat T. Stationary distribution of stochastic SIS epidemic model with vaccination under regime switching. Applied Mathematics Letters, 2016, 59:87-93 doi: 10.1016/j.aml.2016.03.010 [14] Xiong F, Liu Y, Zhang Z J, Zhu J, Zhang Y. An information diffusion model based on retweeting mechanism for online social media. Physics Letters A, 2012, 376(30):2103-2108 http://www.sciencedirect.com/science/article/pii/S037596011200566X [15] Boccaletti S, Bianconi G, Criado R, del Genio C I, Gómez-Gardeñes J, Romance M, et al. The structure and dynamics of multilayer networks. Physics Reports, 2014, 544(1):1-122 doi: 10.1016/j.physrep.2014.07.001 [16] KivelaM, Arenas A, Barthelemy M, Gleeson J P, Moreno Y, Porter M A. Multilayer networks. Journal of Complex Networks, 2013, 2(3):261-268 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz200606008 [17] Yaǧan O, Qian D J, Zhang J S, Cochran D. Information diffusion in overlaying social-physical networks. In: Proceedings of the 201246th Annual Conference on Information Sciences and Systems (CISS). Princeton, NJ, USA: IEEE, 2012. 1038-1048 [18] Zhuang Y, Yagan O. Information propagation in clustered multilayer networks. IEEE Transactions on Network Science and Engineering, 2016, 3(4):211-224 doi: 10.1109/TNSE.2016.2600059 [19] Kim M, Newth D, Christen P. Modeling dynamics of diffusion across heterogeneous social networks:news diffusion in social media. Entropy, 2013, 15(15):4215-4242 http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2255707 [20] Xiong X, Li Y Y, Qiao S J, Han N, Wu Y, Peng J, et al. An emotional contagion model for heterogeneous social media with multiple behaviors. Physica A:Statistical Mechanics and its Applications, 2018, 490:185-202 doi: 10.1016/j.physa.2017.08.025 [21] Ferrara E, Yang Z Y. Measuring emotional contagion in social media. PLoS One, 2015, 10(11): Article No. e0142390 [22] Kramer A D I. The spread of emotion via Facebook. in: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. Austin, Texas, USA: ACM, 2012. 767-770 [23] De Domenico M, Lima A, Mougel P, Musolesi M. The anatomy of a scientific rumor. Scientific Reports, 2013, 3: Article No. 2980 [24] Thelwall M, Buckley K, Paltoglou G. Sentiment strength detection for the social web. Journal of the Association for Information Science and Technology, 2012, 63(1):163-173 doi: 10.1002/asi.21662/full [25] 张云.基于开源软件的中文学术文献计量软件的开发实践.现代图书情报技术, 2010, 26(4):87-91 http://www.cnki.com.cn/Article/CJFDTOTAL-XDTQ201004023.htmZhang Yun. The practice on the development of software on the Chinese academic bibliometrics based on the open source software. New Technology of Library and Information Service, 2010, 26(4):87-91 http://www.cnki.com.cn/Article/CJFDTOTAL-XDTQ201004023.htm [26] The Boson Data. Sentiment analysis[Online], available: http://docs.bosonnlp.com/sentiment.html, 2017. [27] Powers D M W. Evaluation:from precision, recall and F-measure to ROC, informedness, markedness & correlation. Journal of Machine Learning Technologies, 2011, 2(1):37-63 期刊类型引用(8)
1. 董良振,田建艳,杨胜强,陈海滨. 基于光照校正和图像融合的零件表面图像增强. 计算机工程. 2024(06): 245-254 .  百度学术
百度学术2. 王琛,张凌云,刘波,张航. 基于无人机图像的城市道路停车巡检方法. 交通信息与安全. 2024(04): 90-101 . 百度学术3. 徐少平,林珍玉,陈孝国,李芬,杨晓辉. 采用多通道浅层CNN构建的多降噪器最优组合模型. 自动化学报. 2022(11): 2797-2811 . 本站查看4. 苏素平,李虹,孙志毅,孙前来,王银. 无人机图像的输电线断股检测方法研究. 太原科技大学学报. 2021(01): 32-36 . 百度学术5. 索岩,崔智勇. 基于中国剩余定理的高动态图像可逆数据隐藏. 计算机仿真. 2021(01): 167-171 . 百度学术6. 张媛媛,张红英. 结合饱和度调节的单曝光HDR图像生成方法. 吉林大学学报(理学版). 2021(02): 309-318 . 百度学术7. 曹义亲,何恬,刘龙标. 基于改进LSD直线检测算法的钢轨表面边界提取. 华东交通大学学报. 2021(03): 95-101 . 百度学术8. 吴卓钊,范科峰,莫玮. 多尺度权重评估的MSRCR混合曝光成像算法. 计算机工程与应用. 2021(17): 224-229 . 百度学术其他类型引用(14)
-

 下载:
下载:
计量
- 文章访问数: 2802
- HTML全文浏览量: 638
- PDF下载量: 684
- 被引次数: 22
