

-
摘要: 人们在自然情感交流中经常伴随着头部旋转和肢体动作,它们往往导致较大范围的人脸遮挡,使得人脸图像损失部分表情信息.现有的表情识别方法大多基于通用的人脸特征和识别算法,未考虑表情和身份的差异,导致对新用户的识别不够鲁棒.本文提出了一种对人脸局部遮挡图像进行用户无关表情识别的方法.该方法包括一个基于Wasserstein生成式对抗网络(Wasserstein generative adversarial net,WGAN)的人脸图像生成网络,能够为图像中的遮挡区域生成上下文一致的补全图像;以及一个表情识别网络,能够通过在表情识别任务和身份识别任务之间建立对抗关系来提取用户无关的表情特征并推断表情类别.实验结果表明,我们的方法在由CK+,Multi-PIE和JAFFE构成的混合数据集上用户无关的平均识别准确率超过了90%.在CK+上用户无关的识别准确率达到了96%,其中4.5%的性能提升得益于本文提出的对抗式表情特征提取方法.此外,在45°头部旋转范围内,本文方法还能够用于提高非正面表情的识别准确率.Abstract: In natural communication, people would express their expressions with head rotation and body movement, which may result in partial occlusion of face and a consequent information loss regarding facial expression. Also, most of the existing approaches to facial expression recognition are not robust enough to unseen users because they rely on general facial features or algorithms without considering differences between facial expression and facial identity. In this paper, we propose a person-independent recognition method for partially-occluded facial expressions. Based on Wasserstein generative adversarial net (WGAN), a generative network of facial image is trained to perform context-consistent image completion for partially-occluded facial expression images. With an adversarial learning strategy, furthermore, a facial expression recognition network and a facial identity recognition network are established to improve the accuracy and robustness of facial expression recognition via inhibition of intra-class variation. Extensive experimental results demonstrate that 90% average recognition accuracy of facial expression has been reached on a mixed dataset composed of CK+, Multi-PIE, and JAFFE. Moreover, our method achieves 96% accuracy of user-independent recognition on CK+. A 4.5% performance gain is achieved with the novel identity-inhibited expression feature. Our method is also capable of improving recognition accuracy for non-frontal facial expressions within a range of 45-degree head rotation.1) 本文责任编委 左旺孟
-
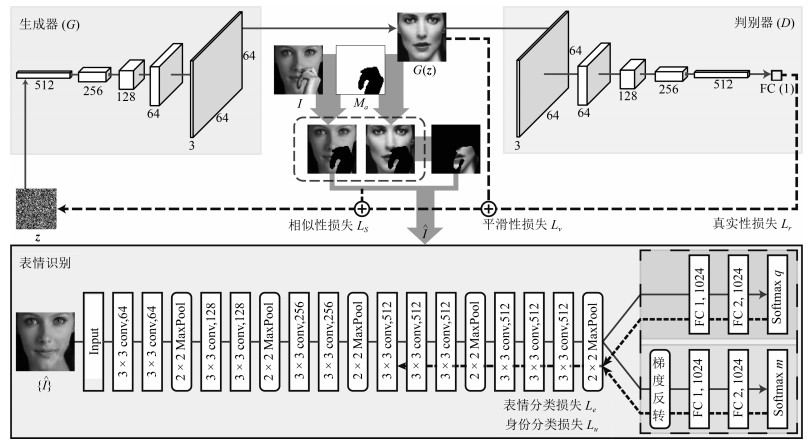
图 1 鲁棒人脸表情识别的算法框架
Fig. 1 Framework of our robust facial expression recognition algorithm

图 2 人脸补全网络在训练1, 50, 75和100轮之后的输出图像
Fig. 2 Outputs of the proposed face completion networks after training 1, 50, 75, and 100 steps
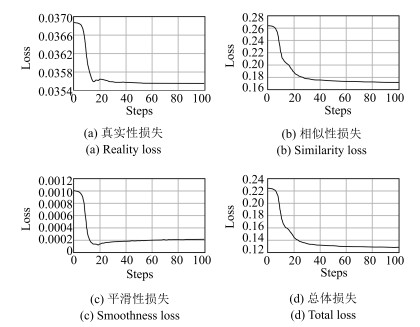
图 3 人脸补全网络的训练损失曲线
Fig. 3 Training loss curves of the proposed face completion networks

图 4 较大范围局部遮挡图像的补全结果
Fig. 4 Image completion results on images with large-scale occlusion

图 6 在COFW测试集上的补全结果
Fig. 6 Image completion results on images taken from the COFW test set

图 7 不同方法补全CelebA测试集图像的结果
Fig. 7 Comparisons of different image completion methods on images taken from the CelebA test set
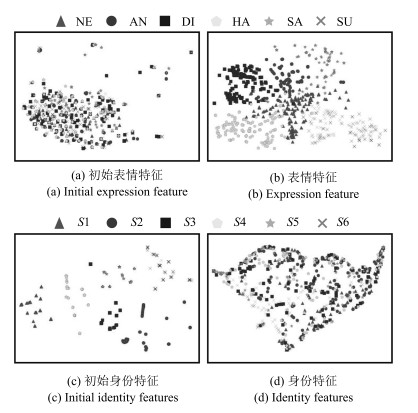
图 8 人脸表情特征和人脸身份特征的t-SNE可视化
Fig. 8 t-SNE visualization of facial expression features and facial identity features
表 1 混合数据集中的统一表情分类
Table 1 Unified expression categories in the mixed dataset
CK + Multi-PIE JAFFE 统一分类 neutral neutral NE NE (中性) anger - AN AN (愤怒) contempt, disgust squint, disgust DI DI (厌恶) happy smile HA HA (高兴) sadness - SA SA (悲伤) surprise surprise SU SU (惊讶) fear - FE - - scream - -  下载: 导出CSV
下载: 导出CSV
表 2 在混合数据集上的人脸表情识别准确率(%)
Table 2 Results of recognition accuracy (%) on the mixed dataset
数据库名称 设置 NE AN DI HA SA SU 平均识别率 混合数据集 PD 95.41 98.85 94.12 96.55 100.00 97.54 97.07 PI 87.78 95.52 93.15 93.91 82.57 90.82 90.62 CK + PD 100.00 97.64 100.00 100.00 97.37 98.35 99.05 PI 98.60 96.43 94.37 100.00 73.40 100.00 92.35 Multi-PIE PD 87.50 - 91.43 95.45 - 95.35 93.10 PI 85.00 - 86.36 94.34 - 93.94 90.13 JAFFE PD 97.87 100.00 98.73 99.13 100.00 97.80 98.84 PI 90.91 100.00 96.77 100.00 87.14 87.88 93.75
下载: 导出CSV
表 3 混合数据集上人脸表情识别的混淆矩阵
Table 3 Confusion matrix for the mixed dataset
NE AN DI HA SA SU NE 87.77 1.06 5.32 3.19 0.53 2.13 AN 0 95.52 3.14 0 1.35 0 DI 3.65 0 93.15 0.04 3.16 0 HA 4.78 0.43 0.43 93.91 0.43 0 SA 0.92 11.93 4.59 0 82.57 0 SU 2.55 2.04 2.04 1.02 1.53 90.82
下载: 导出CSV
表 4 在Multi-PIE上针对不同头部姿态和图像补全设置的人脸表情识别准确率(%)
Table 4 Comparisons of recognition accuracy (%) between settings of face completion for different head poses on Multi-PIE
0 $ \pm 15^\circ$ $\pm 30^\circ$ $\pm 45^\circ$ w/o人脸补全 93.24 88.42 86.85 83.33 w/人脸补全 93.24 91.31 89.70 82.20
下载: 导出CSV
表 5 比较不同方法在CK +表情数据集上的识别准确率
Table 5 Comparisons of average recognition accuracy among different methods on CK +
下载: 导出CSV
表 6 不同特征和识别方法在CK +上的识别准确率(%)
Table 6 Comparisons of different descriptors and methods on CK + (%)
下载: 导出CSV
-
[1] Zeng Z H, Pantic M, Roisman G I, Huang T S. A survey of affect recognition methods:audio, visual, and spontaneous expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(1):39-58 doi: 10.1109/TPAMI.2008.52 [2] Valstar M, Pantic M, Patras I. Motion history for facial action detection in video. In: Proceedings of the 2004 IEEE International Conference on Systems, Man, and Cybernetics. The Hague, The Netherlands: IEEE, 2004. 635-640 [3] Sandbach G, Zafeiriou S, Pantic M, Yin L J. Static and dynamic 3D facial expression recognition:a comprehensive survey. Image and Vision Computing, 2012, 30(10):683-697 doi: 10.1016/j.imavis.2012.06.005 [4] Gunes H, Schuller B. Categorical and dimensional affect analysis in continuous input:current trends and future directions. Image and Vision Computing, 2013, 31(2):120-136 doi: 10.1016/j.imavis.2012.06.016 [5] Yang M, Zhang L, Yang J, Zhang D. Robust sparse coding for face recognition. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, USA: IEEE, 2011. 625-632 [6] Li Y J, Liu S F, Yang J M, Yang M H. Generative face completion. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5892-5900 [7] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: ACM, 2012. 1097-1105 [8] Yu Z D, Zhang C. Image based static facial expression recognition with multiple deep network learning. In: Proceedings of the 2015 ACM on International Conference on Multimodal Interaction. Seattle, USA: ACM, 2015. 435-442 [9] Kim B K, Dong S Y, Roh J, Kim G, Lee S Y. Fusing aligned and non-aligned face information for automatic affect recognition in the wild: a deep learning approach. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1499-1508 [10] Mollahosseini A, Chan D, Mahoor M H. Going deeper in facial expression recognition using deep neural networks. In: Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision. Lake Placid, USA: IEEE, 2016. 1-10 [11] 孙晓, 潘汀, 任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtmlSun Xiao, Pan Ting, Ren Fu-Ji. Facial expression recognition using ROI-KNN deep convolutional neural networks. Acta Automatica Sinica, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtml [12] Kan M N, Shan S G, Chang H, Chen X L. Stacked progressive auto-encoders (SPAE) for face recognition across poses. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 1883-1890 [13] Zhu Z Y, Luo P, Wang X G, Tang X O. Deep learning identity-preserving face space. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 113-120 [14] Yim J, Jung H, Yoo B, Choi C, Park D S, Kim J. Rotating your face using multi-task deep neural network. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 676-684 [15] Zhang J, Kan M N, Shan S G, Chen X L. Occlusion-free face alignment: deep regression networks coupled with de-corrupt AutoEncoders. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 3428-3437 [16] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: 2014. 2672-2680 [17] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract19012.shtml [18] Wright J, Yang A Y, Ganesh A, Sastry S S, Ma Y. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2):210-227 doi: 10.1109/TPAMI.2008.79 [19] Zafeiriou S, Petrou M. Sparse representations for facial expressions recognition via l1 optimization. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 32-39 [20] Chen H, Li J D, Zhang F J, Li Y, Wang H G. 3D model-based continuous emotion recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1836-1845 [21] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[Online], available: https://arxiv.org/abs/1409.1556, February 11, 2018 [22] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions[Online], available: https://arxiv.org/abs/1409.4842, February 11, 2018 [23] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770-778 [24] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[Online], available: https: //arxiv. org/abs/1511. 06434, February 11, 2018 [25] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN[Online], available: https://arxiv.org/abs/1701.07875, February 11, 2018 [26] Ding L, Ding X Q, Fang C. Continuous pose normalization for pose-robust face recognition. Signal Processing Letters, 2012, 19(11):721-724 doi: 10.1109/LSP.2012.2215586 [27] Li S X, Liu X, Chai X J, Zhang H H, Lao S H, Shan S G. Morphable displacement field based image matching for face recognition across pose. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 102-115 [28] Zhu X Y, Lei Z, Yan J J, Yi D, Li S Z. High-fidelity pose and expression normalization for face recognition in the wild. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 787-796 [29] Pathak D, Krähenbühl P, Donahue J, Darrell T, Efros A A. Context encoders: feature learning by inpainting. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2536-2544 [30] Yeh R A, Chen C, Lim T Y, Schwing A G, Hasegawa-Johnson M, Do M N. Semantic image inpainting with deep generative models[Online], available: https://arxiv.org/abs/1607.07539, February 11, 2018 [31] Lee S H, Plataniotis K N, Ro Y M. Intra-class variation reduction using training expression images for sparse representation based facial expression recognition. IEEE Transactions on Affective Computing, 2014, 5(3):340-351 doi: 10.1109/TAFFC.2014.2346515 [32] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: IEEE, 2015. 448-456 [33] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: JMLR, 2011. 315-323 [34] Hinton G, Srivastava N, Swersky K. Neural networks for machine learning: overview of mini-batch gradient descent[Online], available: http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf, February 11, 2018 [35] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S A, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3):211-252 doi: 10.1007/s11263-015-0816-y [36] Ganin Y, Lempitsky V S. Unsupervised domain adaptation by backpropagation. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: IEEE, 2015. 1180-1189 [37] Liu Z W, Luo P, Wang X G, Tang X O. Deep learning face attributes in the wild. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 3730-3738 [38] Lucey P, Cohn J F, Kanade T, Saragih J, Ambadar Z, Matthews I. The extended Cohn-Kanade dataset (CK+): a complete dataset for action unit and emotion-specified expression. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 94-101 [39] Gross R, Matthews I, Cohn J, Kanade T, Baker S. Multi-PIE. Image and Vision Computing, 2010, 28(5):807-813 doi: 10.1016/j.imavis.2009.08.002 [40] Lyons M, Akamatsu S, Kamachi M, Gyoba J. Coding facial expressions with gabor wavelets. In: Proceedings of the 3rd IEEE International Conference on Automatic Face and Gesture Recognition. Nara, Japan: IEEE, 1998. 200-205 [41] Zhao G Y, Pietikäinen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6):915-928 doi: 10.1109/TPAMI.2007.1110 [42] Ptucha R, Tsagkatakis G, Savakis A. Manifold based sparse representation for robust expression recognition without neutral subtraction. In: Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops. Barcelona, Spain: IEEE, 2011. 2136-2143 [43] Liu M Y, Li S X, Shan S G, Wang R P, Chen X L. Deeply learning deformable facial action parts model for dynamic expression analysis. In: Proceedings of the 12th Asian Conference on Computer Vision. Singapore, Singapore: Springer, 2014. 143-157 [44] Jung H, Lee S, Yim J, Park S, Kim J. Joint fine-tuning in deep neural networks for facial expression recognition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2983-2991 [45] Zhang K H, Huang Y Z, Du Y, Wang L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Transactions on Image Processing, 2017, 26(9):4193-4203 doi: 10.1109/TIP.2017.2689999 [46] Kim Y, Yoo B, Kwak Y, Choi C, Kim J. Deep generative-contrastive networks for facial expression recognition[Online], available: https: //arxiv. org/abs/1703. 07140, February 11, 2018 [47] Burgos-Artizzu X P, Perona P, Dollár P. Robust face landmark estimation under occlusion. In: Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 1513-1520 [48] Zhang S Q, Zhao X M, Lei B C. Robust facial expression recognition via compressive sensing. Sensors, 2012, 12(3):3747-3761 doi: 10.3390/s120303747 [49] Ojansivu V, Heikkilä J. Blur insensitive texture classification using local phase quantization. In: Proceedings of the 3rd International Conference on Image and Signal Processing. Cherbourg-Octeville, France: Springer, 2008. 236-243 [50] Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2):91-110 doi: 10.1023/B:VISI.0000029664.99615.94 [51] van der Maaten L, Hinton G. Visualizing data using t-SNE. Journal of Machine Learning Research, 2008, 9(11):2579-2605 http://www.mendeley.com/catalog/visualizing-data-using-tsne/ [52] Huang M W, Wang Z W, Ying Z L. A new method for facial expression recognition based on sparse representation plus LBP. In: Proceedings of the 3rd International Congress on Image and Signal Processing. Yantai, China: IEEE, 2010. 1750-1754 -

 下载:
下载:



计量
- 文章访问数: 4380
- HTML全文浏览量: 1016
- PDF下载量: 1388
- 被引次数: 0
